編譯 | 核子可樂、褚杏娟
一邊是剛過 35 歲就丟掉作業的老鳥,另一邊則是無知無畏、什么都敢往 schema 里塞的新人......
程式員犯了一個無知的錯誤,應該被原諒嗎?近期,這個話題被廣泛討論,而引起這個話題的原因便是 PlanetScale 犯的一個“小錯誤”,
1
學會資料庫索引技術原理,需要花費 5000 美元
軟體工程師 Brian Anglin 所在的團隊計劃在 Superwall 開發一個 SDK,其中的一項作業是需要跟蹤客戶所有的服務物件,即最終用戶,團隊預先估算了資料量:假設與 5 家公司合作,每家公司的日均下載量約為 5000 次,那么單日下載量就在 25000 次左右,單月之內用戶數量為 75 萬,
Anglin 所在公司使用的是便是 PlanetScale 的無服務器資料庫產品,他們為用戶分配了一個隨機 ID,為了可以在明確用戶身份之前就開始進行跟蹤,Anglin 團隊設定了兩個表:ApplicationUser 與 ApplicationUserAlias,其中 ApplicationUserAlias 與 ApplicationUser 屬于多對一的關系,
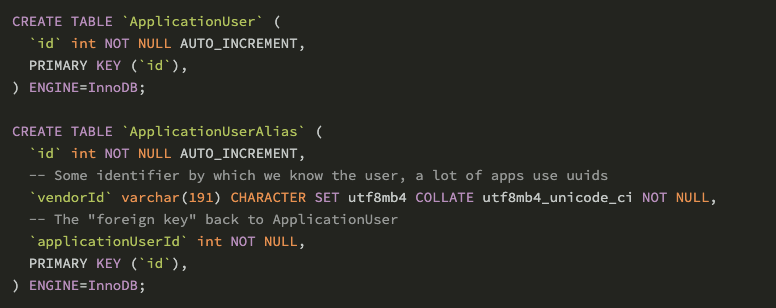
但有個問題是,PlantScale 的 Vitess 不支持 foreign key,這導致了系統無法自動創建索引,為了查找用戶的所有別名,Anglin 團隊運行了以下查詢:

如果僅通過 applicationUserId 查找,操作成本是極低的,但是,PlanetScale 的計費模式以“讀取的行”為基礎,而 Anglin 將其理解為“回傳的行”,他認為最多只會回傳 100 個 ApplicationUserAlias 行,按每讀取 1000 萬行收費 1.5 美元來算,100 行的成本基本可以忽略不計,
但實際上,PlanetScale 對“讀取行”的定義是“在查詢或對您的 PlanetScale 資料庫進行任何型別的突變期間,檢索或檢查的行數,”這里的關鍵詞是“檢查”,團隊查找 100 個別名的簡單查詢實際上是檢查了整個 users 表,而這個表在服務上線短短一個月內就已經超過了 100 萬行,這不僅使查詢速度變慢,更重要的是每一項執行此查詢的請求都會花掉 0.15 美元,
“從統計資料來看,我們每小時大約會向端點發出 280 項請求,折合每天 1000 美元左右,跟 PlanetScale 提供的計費結果基本匹配,”Anglin 表示,
解決辦法也不復雜,只要手動創建原本由 MySQL 自動創建的索引就可以了,但作業人員并沒有意識到問題,直至“天價賬單”的出現,

2
“無知”程式員寫出的可怕 schema
如今,PlanetScale 目前已經修正了這個問題,Anglin 團隊的月度查詢成本又回歸了較為合理的 150 美元/月水平,但這件事已經在不少論壇上引發了熱議,尤其是擴展到了對基礎能力不夠的初級程式員身上,
“我覺得索引是一個非常基本的資料庫知識,這也應該是你該具備的常識,此外,知道 ForeignKeys 通常將索引應用于列也是我的基本認識,對你的遭遇感到抱歉,但也恭喜你學到了一課,其實你可以通過谷歌搜索 MySql ForeignKeys 獲得這些的知識,并為自己省去這些麻煩,”有網友說道,
程式員“rachelbythebay”也專門撰寫了一篇文章來指責一些無知的程式員,
“這是個人人能寫文章、能表達自己觀點的時代,哪怕我們的水平再差,提出的是一套緩慢、臃腫、任何有經驗的人一看就知道完全荒謬的 SQL 資料庫使用方案,恐怕也會有人直接照搬,同時還慶幸自己省掉了不少麻煩事,”rachelbythebay 表示,如果是那個程式員把大量原始字串(也就是 varchar)塞進 schema,而且還對 foreign key 關系毫無概念,問題最侄訓惡化到何種地步?
rachelbythebay 用自己的親身經歷表明了無知會對系統造成多大的損害,
2002 年時,“rachelbythebay”所在公司為了級訓和阻斷眾多垃圾郵件的傳播速度設計了一套系統,雖然團隊可以能拿到開放代理主機的串列,但正常發送郵件的合法組織也被莫名其妙地添加進了黑名單,
經過排查發現,原來每行都包含有原始字串,所以資料庫的匹配檢查負擔特別重,舊系統將 IP 地址、HELP 字串、FROM 地址以及 TO 地址整合在單一表內,并在第一次收到特定元組(「四元組」)時回傳 4xx“臨時故障”錯誤,能夠正確執行 SMTP 的真實郵件服務器會在稍后重試,一般間隔是 15 分鐘到 1 個小時之間,如果對方確實重試而且間隔時間合理,那么下一次就會被允許通過,
雖然聽起來可行,但這背后還隱藏了一個很大的問題,團隊用的是純標準版 MySQL,所以這份表中的各行的顯示形式如下:
id | ip | helo | m_from | m_to | time | ...
這些內容都是字串(也就是資料庫中的 varchar),所以這個四元組表中的每一行都如下所示:
1 | ip1 | blahblah | evil@spammer.somewhere | victim1@our.domain | ...
2 | ip2 | foobar | another@evil.spammer | victim2@our.domain | ...
3 | ip3 | MAILSERV | legit@person | user@our.domain | ...
4 | ip4 | foobar | another@evil.spammer | victim1@our.domain | ...
所以,整個匹配程序相當于:
SELECT whatever FROM quads WHERE ip='ip1' AND HELO='thing_they_sent_us' AND m_from='whatever' AND m_to='some_user'
這個恐怖的資料庫 schema 一旦開始運行,就會不斷對表中各行執行字串比較,它需要讀取表中的各個行,再將查詢中的字符與當前行內找到的字符進行比較,雖然只要某列不匹配就會被中止,但整個程序仍然緩慢、令人頭痛,
“當初負責設計和編程的家伙把活兒搞砸了,而且問題一直持續了幾個月,最終我不得不翻查日志記錄,看看系統到底是怎么熬過那段時光的,”rachelbythebay 寫道,
rachelbythebay 感嘆道,每個人都要經歷青澀的階段,迫切需要他人給予引導、說明或者參考,但這與殘酷的現實形成了鮮明的對比:一邊是剛過 35 歲就丟掉作業、不知道接下來該干什么的老鳥,另一邊則是無知無畏、什么都敢往 schema 里塞的新人……這個世界到底怎么了?
3
初級程式員應該被指責嗎?
rachelbythebay 表達了初級程式員莽撞無知的指責,但在他的帖子下邊,很多人表達了反對,
“即使是具有 Rachel 經驗水平的人仍然不了解資料庫優化的所有細節,初級程式員需要被更有經驗的工程師指導,而非被一味批評,”有網友說道,
有一句話在開發人員圈子廣為流傳:“初級開發人員的標志就是需要在中級和高級開發人員的指導下完成作業,”每個開發人員都是從初級到中級、再到高級的一個程序,但在很多資深開發者眼里,高級開發人員是各項能力的綜合體現,而非僅僅寫代碼的能力,
有開發者指出,撰寫優秀軟件的挑戰不是要做到每個細節的完美,而是培養判斷力并專注在真正重要的細節上,對初級程式員的不屑一顧和傲慢會讓他們害怕犯錯,進而使他們的發展停滯不前,
印度 IT 專案經理 Ravi Shankar Rajan 認為,高級開發人員所為人稱道的是專業性,而不是具備多少年經驗,也不是從來不犯錯,從初級程式員到高級開發人員,需要培養各種技能,單純的經驗積累也不意味著會成為高級開發人員,
Rajan 給初級程式員提出了以下三個建議:
-
克服鄧寧 - 克魯格效應,即不要高估自己,初級程式員和高級程式員的區別在于初級程式員認為自己什么都懂,而高級程式員則知道自己還有很多東西要學,
-
優秀的高級程式員清楚地知道什么時候不應該做什么,關鍵不在于規避風險,而在于謹慎選擇正確的戰場,
-
抱有瘋狂的好奇心,好奇心是一種可以越用就會變得越好的工具,這也是人們對優秀高級程式員的期望,
在很多人看來,初級、高級程式員是一個年齡劃分,但實際上,更多的是對能力的劃分,“學會學習”和“尊重以前的東西”是與開發一樣重要的技能,
相關鏈接:
https://briananglin.me/posts/spending-5k-to-learn-how-database-indexes-work/
http://rachelbythebay.com/w/2021/11/06/sql/

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354561.html
標籤:其他