文章目錄
- 前言
- 1. 認知服務
- 2. 環境配置
- 2.1 創建資源
- 2.2 創建python環境
- 3. 代碼實作
- 3.1 圖片檢測
- 3.2 視頻檢測
- 4. 檢測效果
- 結束語
前言
??博主參與了由CSDN和微軟共同舉辦的0元試用Azure人工智能認知服務的活動,體驗了一下Azure的計算機視覺方面的服務,在這里記錄一下如何基于Azure計算機視覺服務快速搭建一個目標檢測平臺,
1. 認知服務
??認知服務使每個開發人員和資料科學家都可以使用 AI,借助領先的模型,可以解鎖各種用例,只需要一個 API 呼叫,就可以將看、聽、說、搜索、理解和加快高級決策制定的能力嵌入到應用中,讓所有技能水平的開發人員和資料科學家都能輕松在其應用中添加 AI 功能,
<iframe id="ZkFlDBsM-1636424624267" src="https://player.bilibili.com/player.html?aid=421589206" allowfullscreen="true" data-mediaembed="bilibili"></iframe>
Azure認知服務簡介
??Azure的計算機視覺服務具體包括以下服務:
| 服務 | 說明 |
|---|---|
光學字符識別 (OCR) | 光學字符識別 (OCR) 服務從影像中提取文本, 可以使用新讀取 API 從影像和檔案中提取印刷體文本和手寫文本, 此 API 使用基于深度學習的模型,并處理各種表面和后臺上的文本,包括業務檔案、發票、收據、海報、名片、信件和白板,并且支持提取多種語言的印刷體文本 |
影像分析 | 影像分析服務從影像中提取許多視覺特征,例如物件、人臉、成人內容和自動生成的文本說明 |
空間分析 | 空間分析服務會分析視頻源上人員的狀態和移動,并生成其他系統可以回應的事件 |
??本篇主要介紹的是影像分析服務中的目標檢測功能,Azure的計算機視覺服務對輸入影像的要求如下:
- 影像檔案格式必須是
JPEG、PNG、GIF或BMP - 影像的檔案大小不能超過
4 MB - 影像的尺寸必須大于
50 x 50像素,對于讀取API,影像的尺寸必須介于50 x 50和10000 x 10000像素之間,
2. 環境配置
2.1 創建資源
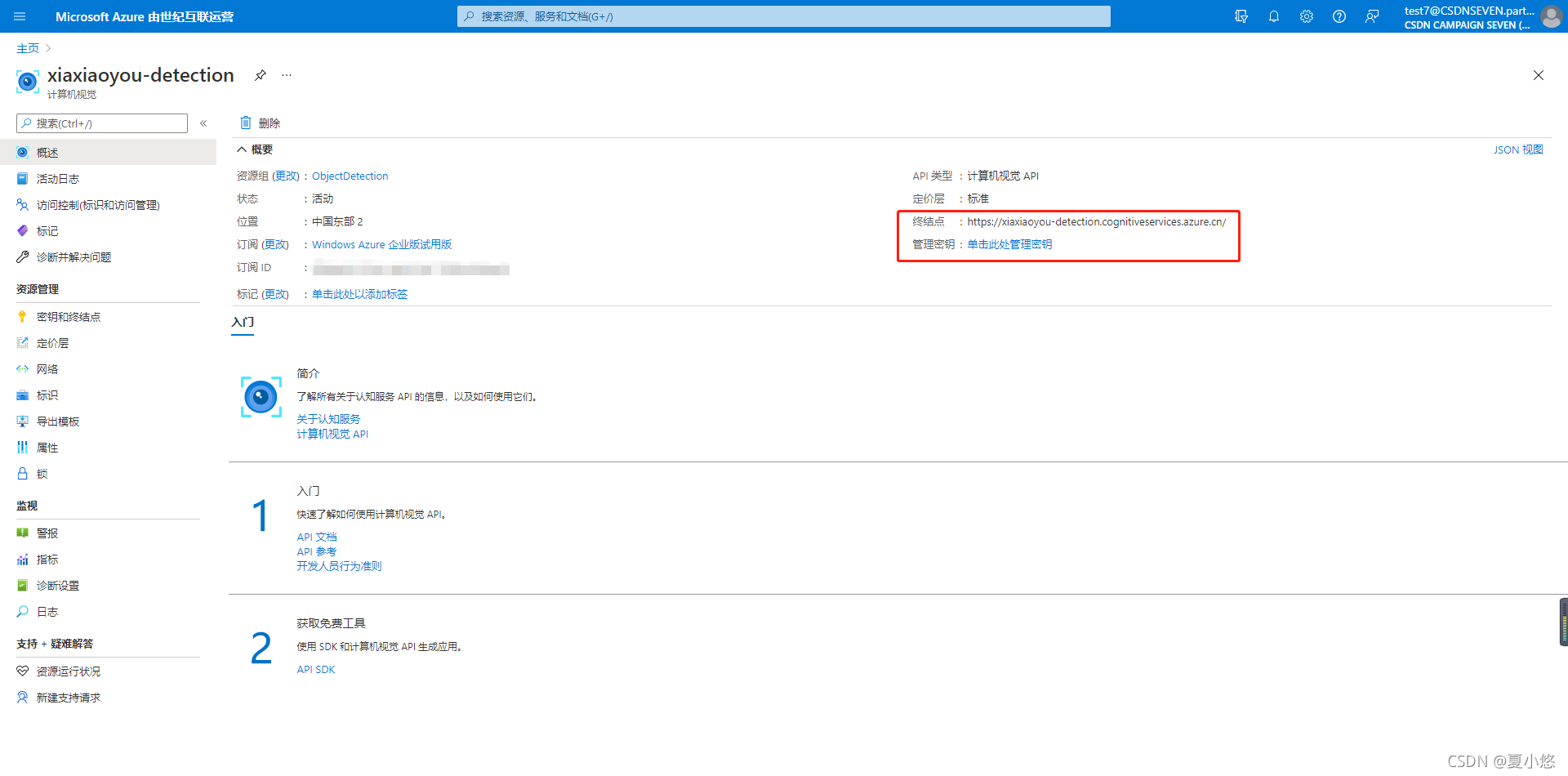
??按照下圖所示步驟來添加計算機視覺所需要的資源:
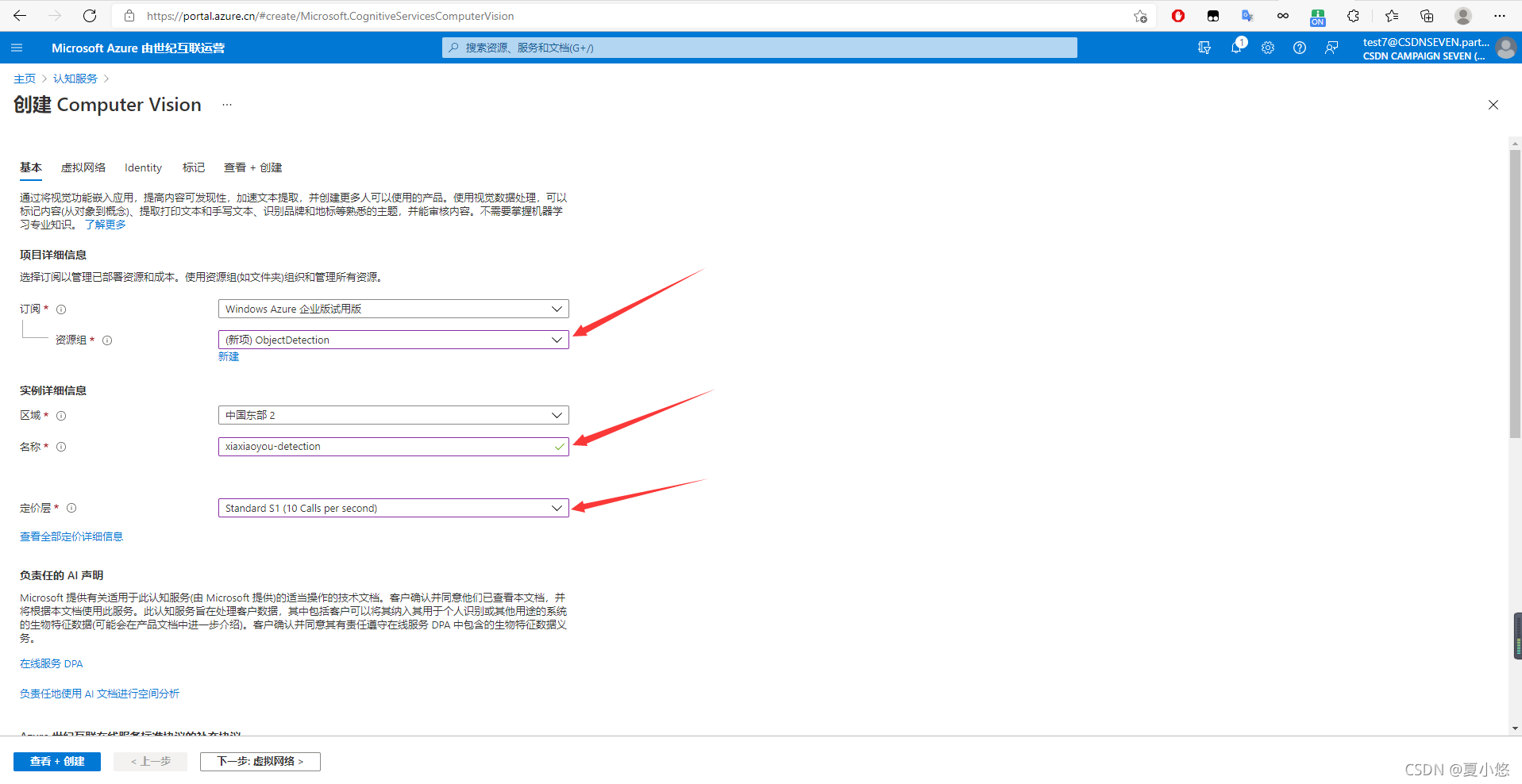
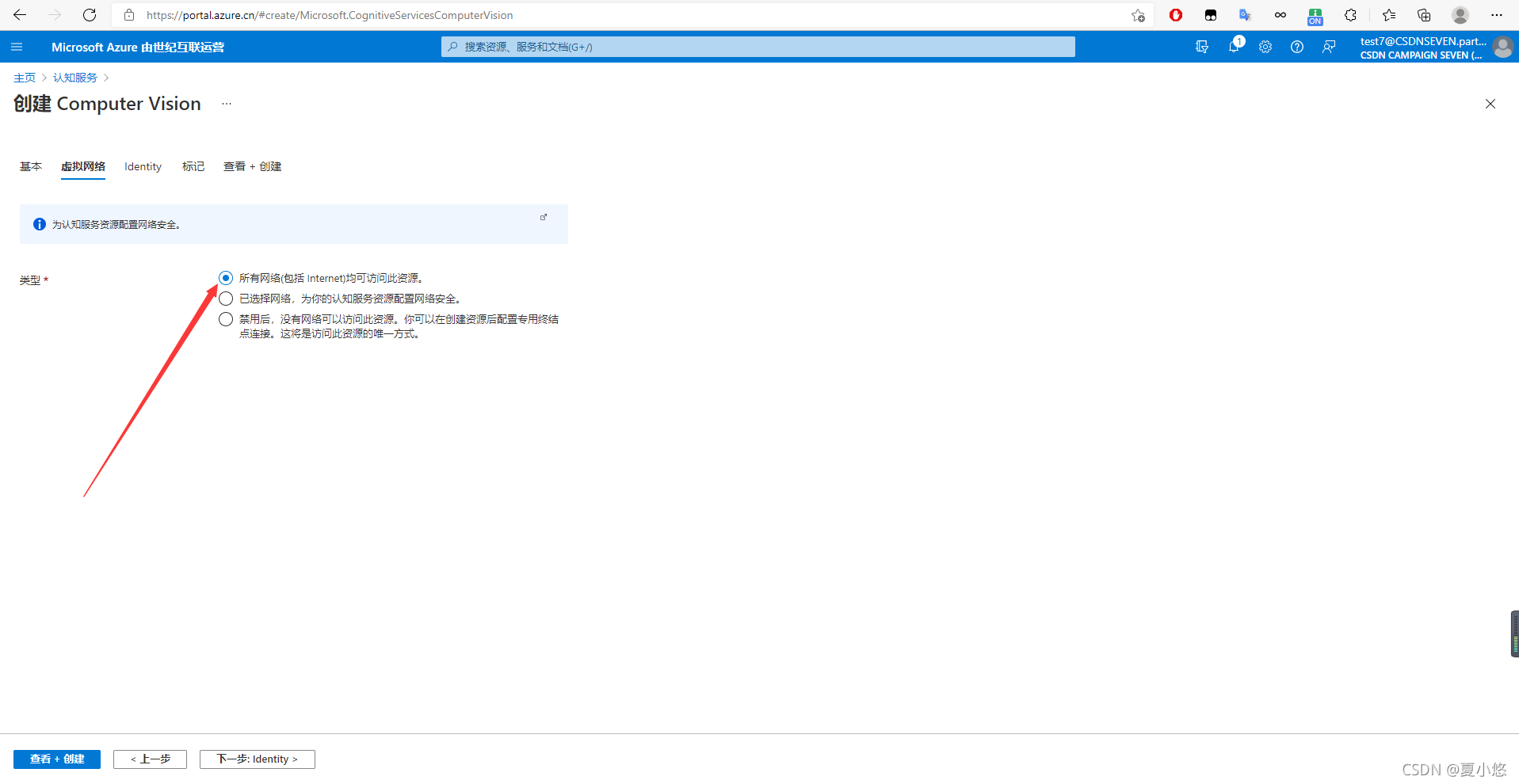
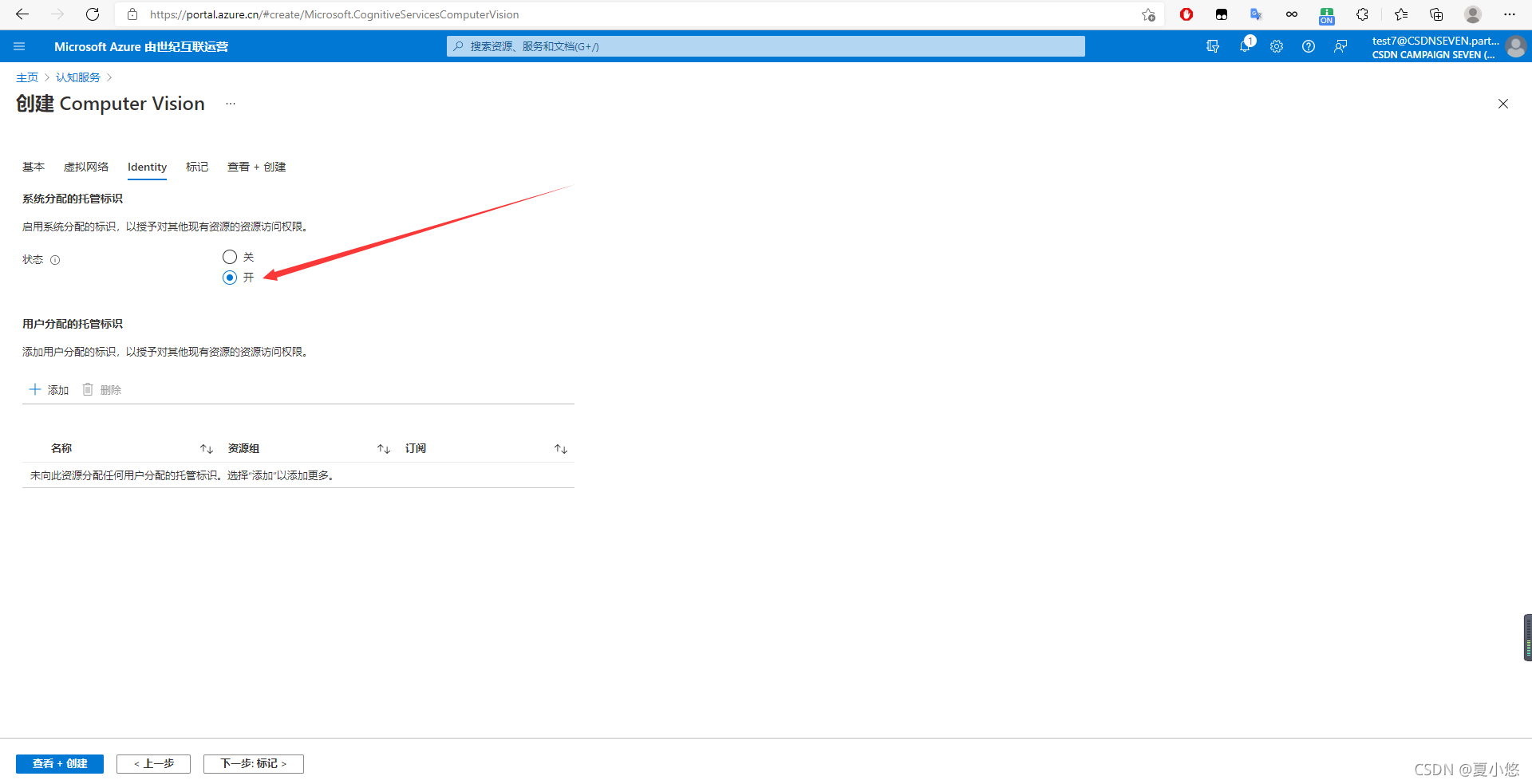
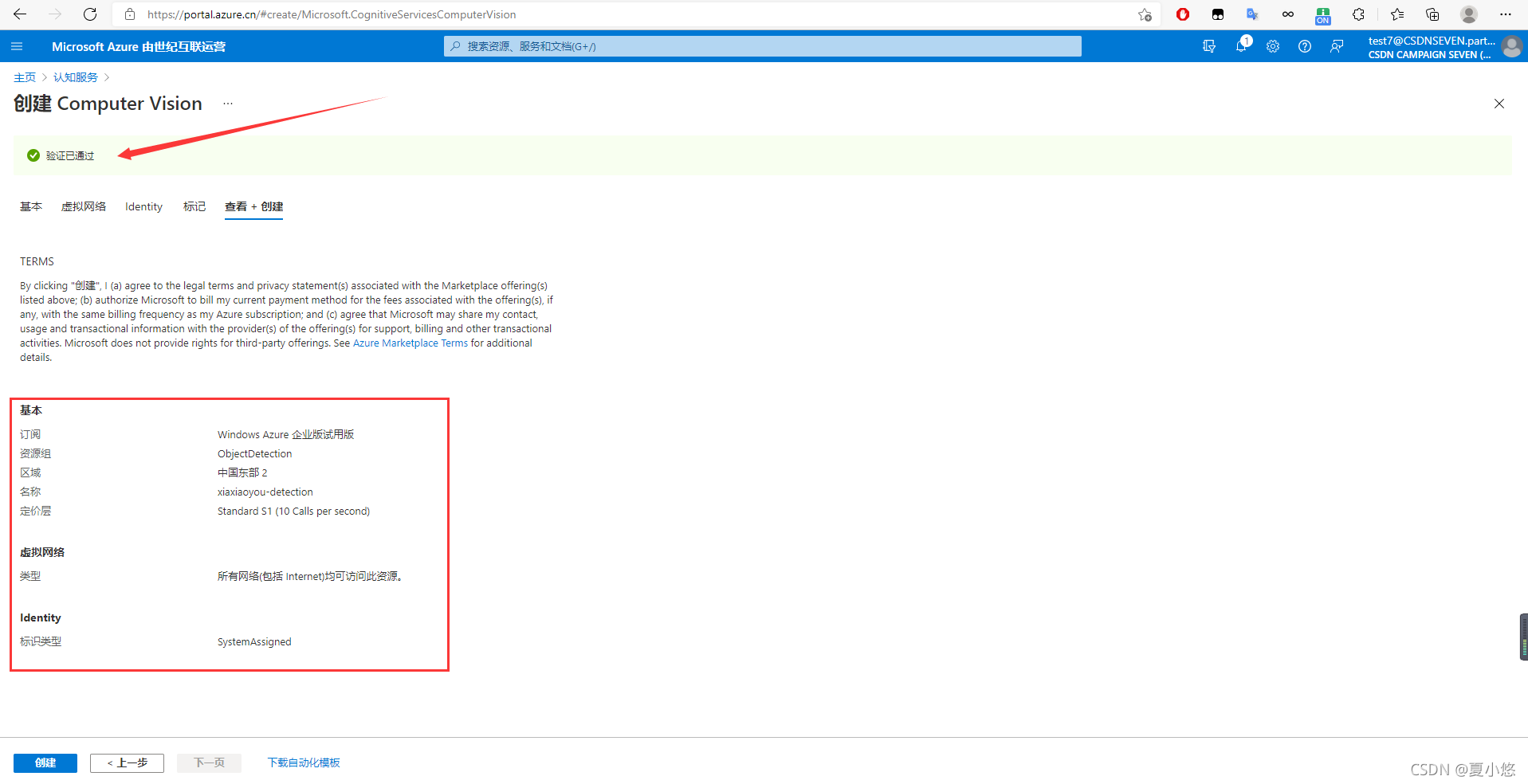
??創建完畢后,進入資源可以看到自己的終結點endpoint和密鑰subscription key:
2.2 創建python環境
# 安裝Azure Computer Vision庫
pip install --upgrade azure-cognitiveservices-vision-computervision
# 安裝pillow庫
pip install pillow
# 安裝 matplotlib庫
pip install matplotlib
# 安裝opencv庫
pip install opencv-python
# 安裝ffmpeg庫
pip install ffmpeg
3. 代碼實作
3.1 圖片檢測
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from azure.cognitiveservices.vision.computervision.models import OperationStatusCodes
from azure.cognitiveservices.vision.computervision.models import VisualFeatureTypes
from msrest.authentication import CognitiveServicesCredentials
from PIL import Image
import matplotlib.patches as patches
import matplotlib.pyplot as plt
import numpy as np
import cv2
import glob
subscription_key = "xxxxxxxxxxx" # your subscription key
endpoint = "https://xiaxiaoyou-detection.cognitiveservices.azure.cn/" # your endpoint
# create computer vision client
computervision_client = ComputerVisionClient(endpoint, CognitiveServicesCredentials(subscription_key))
# test image
img_file = 'iu.png'
print("===== Detect Objects - local =====")
# Get local image with different objects in it
local_image_objects = open(img_file, "rb")
# Call API with local image
detect_objects_results_local = computervision_client.detect_objects_in_stream(local_image_objects)
object_dict = {}
count = 0
# Print detected objects results with bounding boxes
print("Detecting objects in local image:")
if len(detect_objects_results_local.objects) == 0:
print("No objects detected.")
else:
for object in detect_objects_results_local.objects:
# print(object)
object_dict[count] = {
'object_property': object.object_property,
'rectangle': [(object.rectangle.x, object.rectangle.y), object.rectangle.w, object.rectangle.h],
'confidence': object.confidence
}
count += 1
print("object at location {}, {}, {}, {}".format(
object.rectangle.x, object.rectangle.x + object.rectangle.w,
object.rectangle.y, object.rectangle.y + object.rectangle.h))
# create random color
colors = plt.cm.hsv(np.linspace(0, 1, 10)).tolist()
img = Image.open(img_file)
fig = plt.figure()
plt.imshow(img)
plt.axis('off')
currentAxis = plt.gca()
color_dict = {}
for i, info in enumerate(object_dict.items()):
print(info)
color = color_dict.get(info[1]['object_property'], None)
if not color:
color = colors[i]
color_dict[info[1]['object_property']] = color
rect = patches.Rectangle(*info[1]['rectangle'], edgecolor=color, linewidth=3, fill=False)
currentAxis.add_patch(rect)
currentAxis.text(info[1]['rectangle'][0][0], info[1]['rectangle'][0][1], info[1]['object_property'] + ' ' + str(info[1]['confidence']),
color='white', size=20, weight='bold', backgroundcolor=color, family='cursive')
# remove blank
fig.set_size_inches(img.size[0]/100, img.size[1]/100)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
plt.subplots_adjust(top=1, bottom=0, left=0, right=1, hspace=0, wspace=0)
plt.margins(0, 0)
plt.savefig('object-detection-iu.png')
plt.show()
3.2 視頻檢測
??相比圖片檢測,視頻檢測多了兩個視頻轉圖片和圖片轉視頻的操作,具體如下:
def toimg(video_file):
if not os.path.exists('imgs'):
os.mkdir('imgs')
cap = cv2.VideoCapture(video_file)
isopened = cap.isOpened
fps = cap.get(cv2.CAP_PROP_FPS) # 幀率
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
print('fps: {0}, width: {1}, height: {2}'.format(fps, width, height))
i = 0
while isopened:
if i == 1000:
break
(flag, frame) = cap.read() # 讀取每一張 flag frame
filename = 'imgs/' + str(i).zfill(5) + '.png'
if flag == True:
cv2.imwrite(filename, frame, [cv2.IMWRITE_JPEG_QUALITY, 100])
i += 1
cap.release()
def tovideo(img_path):
if not os.path.exists('video'):
os.mkdir('video')
fourcc = cv2.VideoWriter_fourcc(*'mp4v')
videoWrite = cv2.VideoWriter('video/iu.mp4', fourcc, 30, (1920, 1080))
files = sorted(glob.glob(os.path.join(img_path, '*.png')))
for file in files:
img = cv2.imread(file)
videoWrite.write(img)
videoWrite.release()
4. 檢測效果
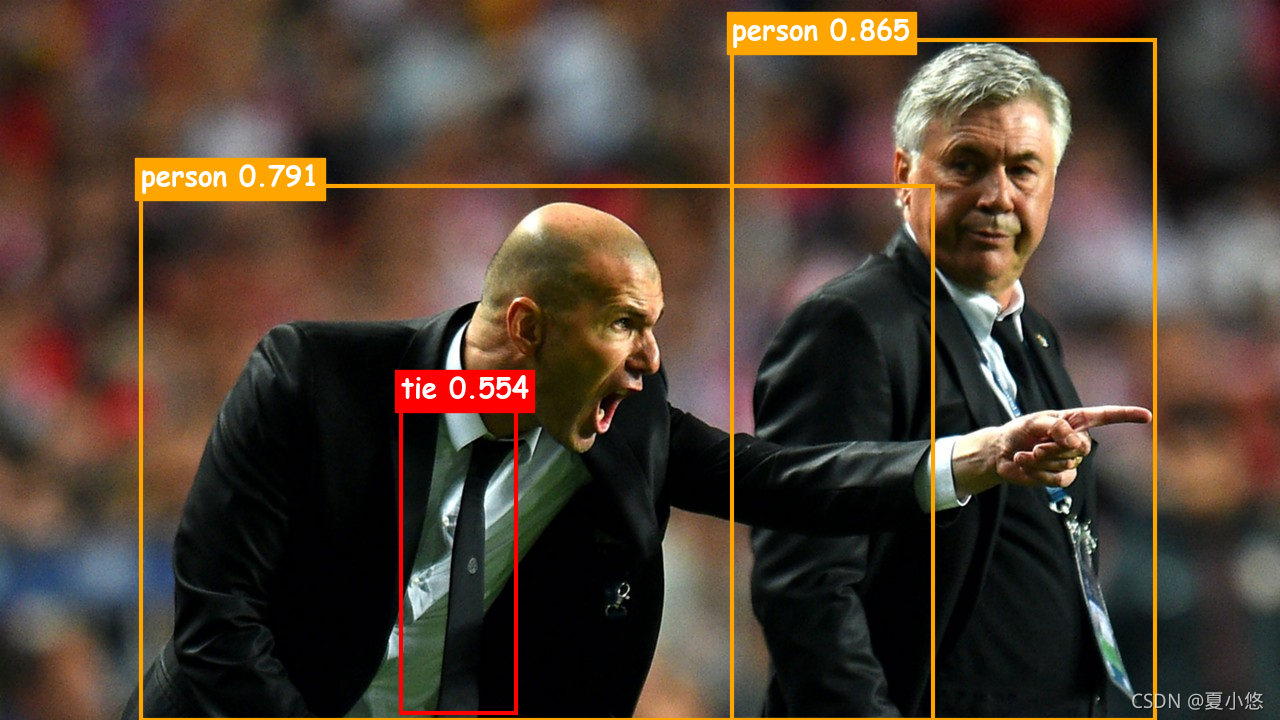
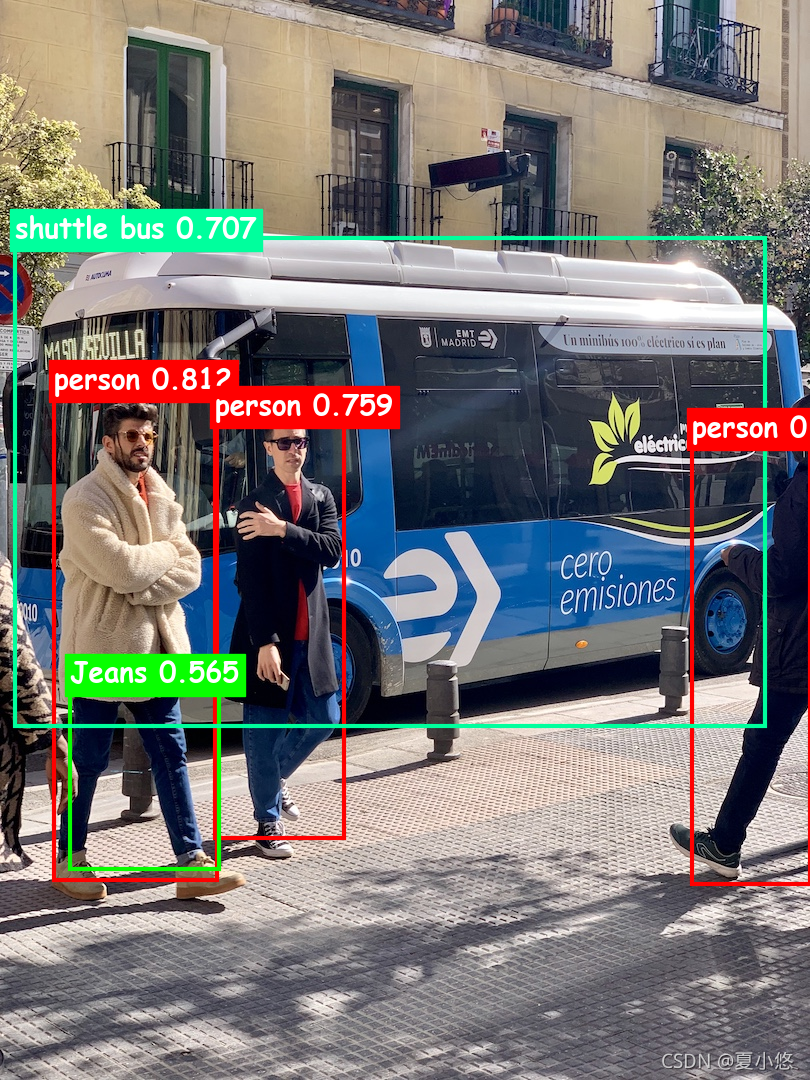
??博主測驗了幾張圖片,效果還是非常不錯的:

<iframe id="dbofsW2d-1636424574271" src="https://player.bilibili.com/player.html?aid=976539823" allowfullscreen="true" data-mediaembed="bilibili"></iframe>
德魯納酒店-目標檢測
結束語
??總體感覺檢測的準確率還是挺高的,雖然不知道Azure基于的什么模型,但就某些細節來看,種類還挺豐富,比如上述圖片的牛仔褲,視頻中IU的唇膏(化妝品)都可以檢測到,而且速度也很棒,可能這就是商用的叭,很不戳!!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354788.html
標籤:其他
上一篇:通過 “貓片” 認識生成對抗網路思想(Make Your First GAN With PyTorch 第五章)
下一篇:CV學習筆記-數字影像概述