- 本文是 Make Your First GAN With PyTorch 的第 5 章,本書的介紹詳見這篇文章,
本文目錄
- 1.如何生成影像?
- 2.對抗性訓練(Adversarial Training)
- 3.訓練 GAN
- 3.1 ☆☆☆步驟一☆☆☆
- 3.2 ☆☆☆步驟二☆☆☆
- 3.3 ☆☆☆步驟三☆☆☆
- 4. GAN 并不容易被訓練
- 5. 學習要點
在探索生成對抗網路(GAN)前,先設定一些場景進行基礎的認識,
1.如何生成影像?
一般而言,使用神經網路是為了約簡、凝練、總結資訊,比如 MNIST 分類器 是一個很好的例子,網路有 784 個輸入,輸出 10 個值,輸出比輸入的數量少很多,
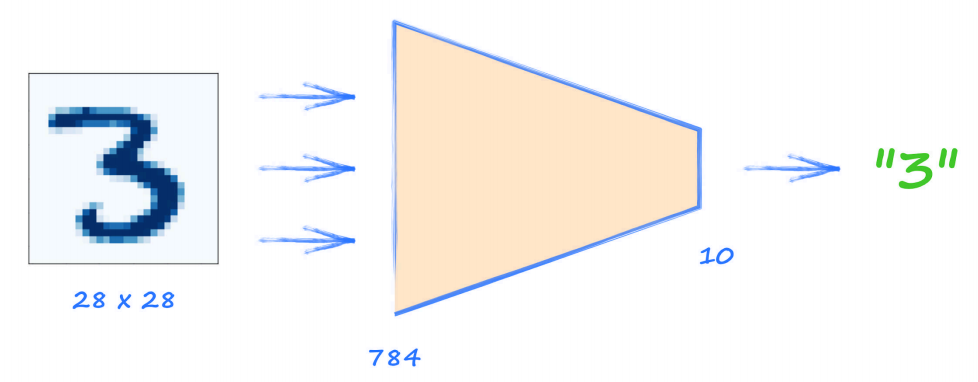
下面來完成一個思想實驗,如果將這些網路從前到后反轉,將完成約簡的相反作業,也就是擴展少量資料到大量資料,在這種情況下,將能生成影像,
事實上,如果將上面訓練好的網路反向,將代表數字的向量輸入,可以產生 28??28 的影像:
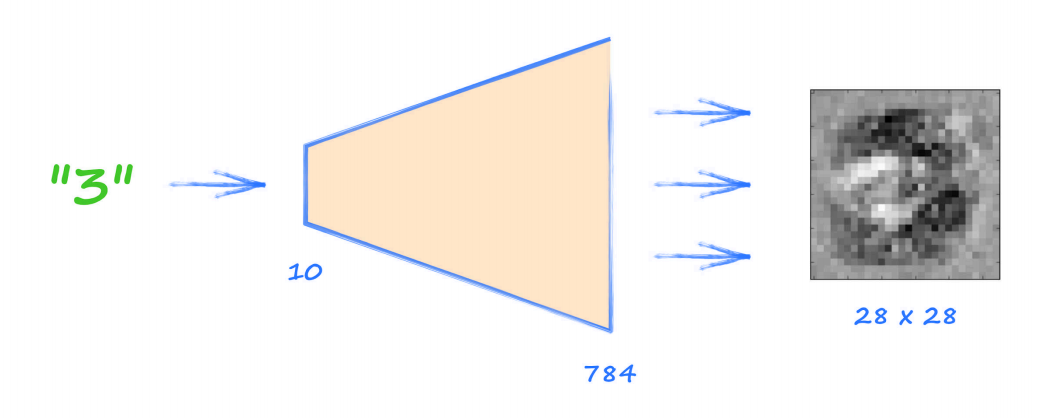
但是上述程序創建的影像有如下特點(或者叫問題):
- 給定的輸入,輸出的影像總是相同的;
- 輸出影像是對應標簽所有訓練影像的某種平均,(看上圖似乎像 3 又不完全是 3)
考慮上面的問題,其實使用網路來生成影像的想法很好,但是理想的網路應能夠:
- 創建的影像不能完全一致;
- 生成的影像應該 “更真實”,而不是訓練影像的平均值,
這兩個問題對生成真實和有用的影像很重要,簡單的網路反向方法并不能解決這些挑戰,需要一種新的網路架構,
2.對抗性訓練(Adversarial Training)
2014 年,Ian Goodfellow 提出了一種不同型別的網路架構,該網路架構并沒有更復雜,也沒有使用更花哨的激活函式或更高級的優化技術;但是,這個網路的架構完全不同,
下面一步步進行解釋,
下圖顯示了對影像進行 貓 和 非貓 分類的神經網路:
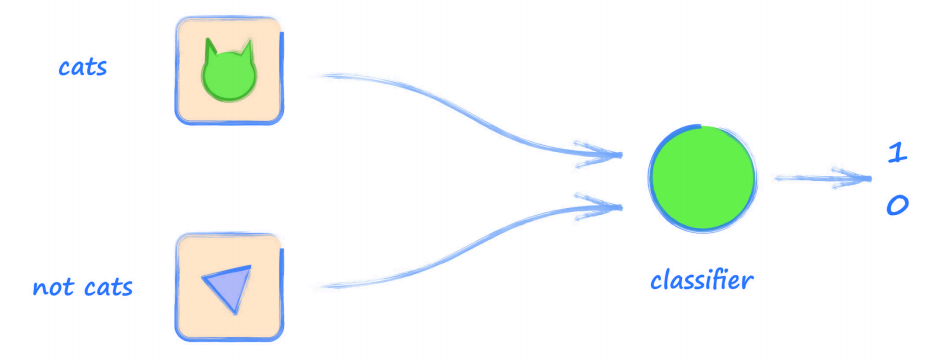
如果輸入到網路的影像是一只貓,則輸出值應為 1,代表 True;如果影像不是貓,則輸出為 0,代表 False,
- 上圖這個架構與之前 MNIST 例子區別不大,唯一的區別是分類輸出值是單獨一個值,而不是 10 個,
對任務作出一點小改變,改變分類器試圖分辨 貓 和 非貓 的情況,制作一個分類器來分辨 真實貓 的圖片和自己畫的 假貓 的圖片(下圖所示):
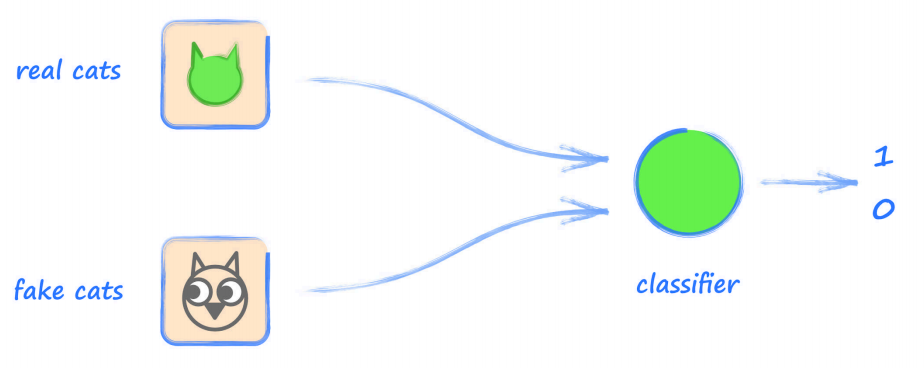
- 看起來這個架構并沒有什么值得注意的變化,輸入仍然有兩種影像,且神經網路分類器可以訓練來分類這兩類,
可以將這個分類器看作一個 偵探(detective),在進行訓練前,這個偵探并不擅長分辨 真貓 和 假貓;隨著訓練的開展,偵探將逐漸擅長從 真貓 中分辨 假貓,
下面,假設有一個能生成 假貓 圖片的生成器:
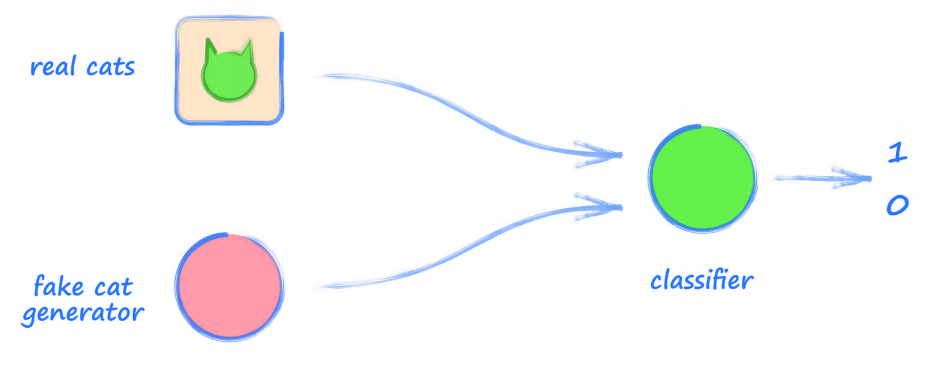
這省了準備各種 假貓 圖片,而是使用代碼生成它們,
其實,生成一點都不像貓的垃圾影像很容易,比如我們可以簡單地畫出隨機的三角形,
但是,我們不滿足于一個只能生成垃圾影像的生成器,假設有一個神經網路,可以通過訓練來產生相對真實的影像,將這個神經網路稱之為 生成器(generator),同時,稱分類器為 鑒別器(discriminator),這是類似網路中的公認名稱,

下面考慮如何訓練這個 生成器,所謂訓練,是關于獎勵哪種行為,懲罰哪種行為的作業,這也是損失函式完成的作業:
- 如果生成器生成了能 通過 鑒別器的影像,我們就 獎勵 它;
- 如果生成器生成的影像 未能 通過鑒別器,我們就 懲罰 它,
先不考慮損失函式,回過頭看一下整體考慮,下面略微有點繞,需要認真閱讀,
- 鑒別器 的作業是分辨真實影像和生成的影像,如果 生成器 并不太好,這項作業將很簡單,
- 但是如果訓練 生成器(先不管怎么訓練)效果很好,可以使得影像看起來越來越真實,
- 另一方面,如果 鑒別器 隨著訓練變得越來越好,為了能夠更有效地 “騙過” 鑒別器,生成器 必須也變得越來越好,
- 最后的結果,就是 生成器 可以變得擅長創造影像,使得生成的影像不能被 鑒別器 所區分,
- 鑒別器 和 生成器 設定為彼此競爭,作為 對手(adversaries),每個都試圖超過另一個,隨著這個程序,鑒別器 和 生成器 都變得越來越好,這個架構稱之為 對抗生成網路(Generative Adversarial Network) ,或簡稱為 GAN,
這是一個聰明的架構,并不僅僅因為它使用了競爭來驅動改進,而且因為 不需要 定義詳細的規則來描述損失函式中的真實影像,
機器學習的歷史已經表明,我們并 不善于 定義這些規則,取而代之的是讓 GAN 自主學習真實影像是什么,
上面所描述的是真正令人興奮的,世界領先的機器學習研究者之一 Yann LeCun 稱 對抗式學習(adversarial training) 是 “過去二十年機器學習中最酷的想法” ,
3.訓練 GAN
在一個 GAN 中,生成器 和 鑒別器 都需要訓練,而且,不要 先訓練一個,之后然后再訓練另一個,而是期望 生成器 和 鑒別器 能同時學習,
下面的三步訓練回圈是完成這個的一個方法:
- 第一步: 向 鑒別器 展示一個真實的影像,然后,告訴 鑒別器 ,這個樣本的分類應該是 1;
- 第二步: 向 鑒別器 展示一個 生成器 的輸出,然后,告訴 鑒別器 ,這個樣本的分類應該是 0;
- 第三步: 向 鑒別器 展示一個 生成器 的輸出,然后,告訴 生成器 ,這個樣本的分類應該是 1,
上面三個步驟是絕大多數 GAN 訓練方案的核心,可能很難理解,下面通過一些圖片解釋這些步驟的含義,
- 下面的介紹中,鑒別器 和 生成器 都加粗,需要認真注意,避免混淆,
3.1 ☆☆☆步驟一☆☆☆
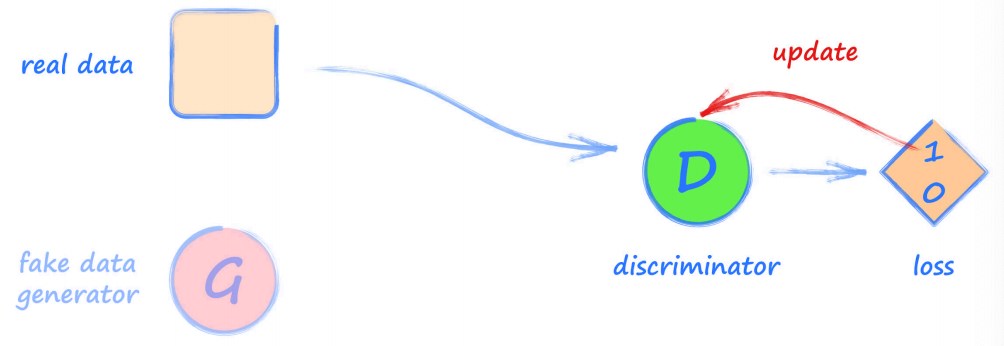
步驟一 是最簡單的,主要是向 鑒別器 展示一個來自真實資料集的影像,請求它對樣本影像進行分類(輸出 0 或者 1),
由于這里的 預期輸出 應該是 1,所以,我們可以使用 損失值來更新 鑒別器,
3.2 ☆☆☆步驟二☆☆☆
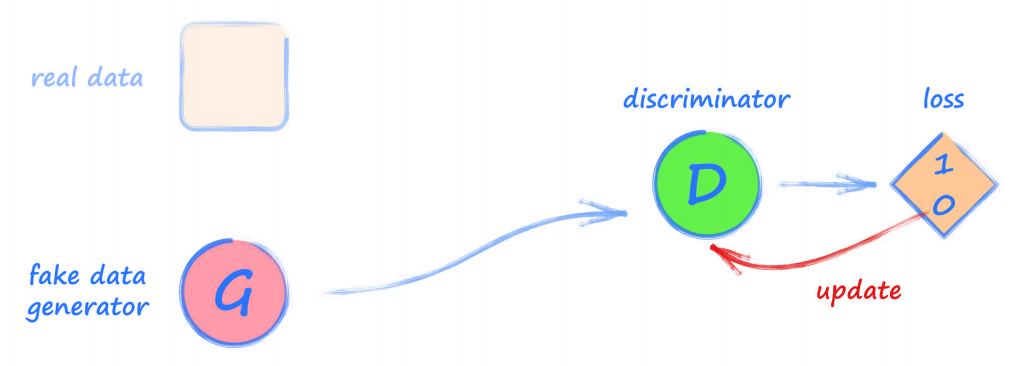
步驟二 同樣是對 鑒別器 進行訓練,
但這次是由 鑒別器 對一個來自 生成器 的影像進行分類(輸出 0 或者 1),
由于這時 鑒別器 的 預期輸出 應該是 0,所以也可以使用 損失值 來更新 鑒別器,
- 這里操作必須很小心, 不要在這步更新 生成器,因為我們并不想在 生成器 生成的虛假影像被 鑒別器 查獲假的影像時,仍給 生成器 獎勵,
- 下面對 GAN 編程時,將展示如何防止通過計算圖回傳更新 生成器,
3.3 ☆☆☆步驟三☆☆☆
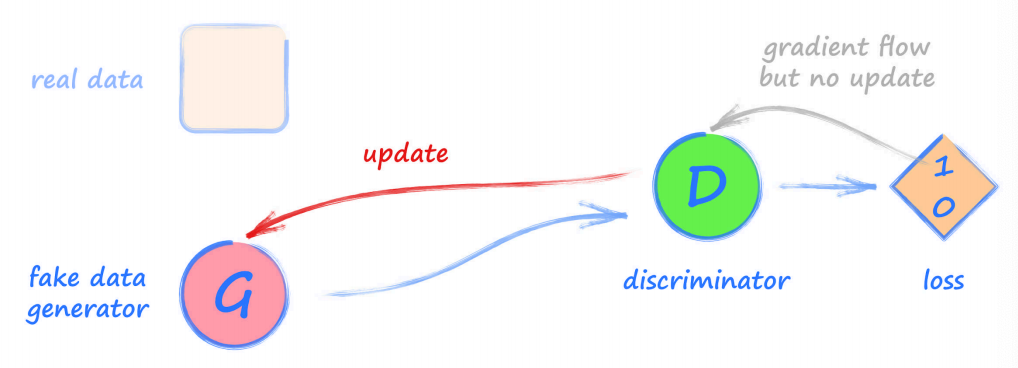
步驟三 是對 生成器 進行訓練,
使用 生成器 來產生 虛假影像,用于展示給 鑒別器 來分類(輸出 0 或者 1),
這時 鑒別器 的期望輸出應該是 1,也就是我們希望 生成器 能夠生成足夠迷惑 鑒別器 的影像,
與 步驟二 的區別在于,這里的 損失值 僅僅用來更新 生成器,而并不想在 鑒別器 分類錯誤時卻仍然鼓勵它,所以這一步并不更新鑒別器,
- 前面幾個步驟看起來很復雜,但只要結合示意圖認真理解,后面對 GAN 編程時, 將看到操作起來很簡單,
4. GAN 并不容易被訓練
上面剛討論了 GAN 的訓練框架,但實際上訓練 GAN 可能很困難,
由于生成器和鑒別器在訓練時 相互對抗,如果它們平衡的很好,那么它們將互相改進并不難;但如果鑒別器變好的太快,生成器可能永遠跟不上;相反的,如果鑒別器學習的太慢,生成器將由于劣質的影像而得到獎勵(訓練效果同樣不好),
- 其實, GAN 是機器學習中一個新想法,目前對如何使得它更好作業的理解還處在初級階段,這經常導致訓練網路失敗,
- 當然,先將 GAN 可能失效的理論討論放到一邊,首先開始構建 GAN ,當各種問題在訓練中浮現時,我們再探索它,
5. 學習要點
- 分類(Classification) 是資料的約簡,分類神經網路會把很多輸入值減少 到一個數量少很多的輸出值,每個輸出值對應一類;
- 生成(Generation) 一般是資料的擴展,生成神經網路會將少數的輸入 種子(seed) 值擴展到數量多很多的輸出值(比如影像的像素值);
- 生成對抗網路(GAN) 有兩個神經網路:一個 生成器(generator) 和一個 鑒別器(discriminator);兩個網路相互競爭,稱為 對手(adversaries):鑒別器 通過將訓練集里面的資料分類為 真實(real),將生成器產生的資料分類為 虛假(fake) 而得到訓練;生成器 則通過創建看起來足夠真的資料,使得資料騙過鑒別器而得到訓練;
- 可靠地設計和訓練 GAN 成功很難,GAN 是新的技術,而且形容它如何 作業、為何會訓練失敗的理論目前還不成熟;
- 標準的 GAN 訓練回圈有 3 個步驟:① 使用真實的資料樣本訓練鑒別器;② 使用生成的資料樣本訓練鑒別器;③ 通過鑒別器將生成器生成的影像識別為真的影像,來訓練生成器,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/354786.html
標籤:其他
上一篇:OpenCV 繪制形狀與文字