SparkStreaming Bulkload入Hyperbase–應用與原理
一、環境準備
見《Spark3.1.2 on TDH622》
二、補充jar包
三、關鍵代碼說明
-
接入kafka資料
JavaInputDStream<ConsumerRecord<String, String>> stream = KafkaUtils.createDirectStream( ssc, LocationStrategies.PreferConsistent(), ConsumerStrategies.<String, String>Subscribe(topics, kafkaParams)); -
kafka訊息拆包,決議為單條資料
JavaDStream<String> messages = stream.repartition(shuffleNum).map(new GetValueFunc());public class GetValueFunc implements Function<ConsumerRecord<String, String>, String>, Serializable { @Override public String call(ConsumerRecord<String, String> consumerRecord) throws Exception { return consumerRecord.value(); } } -
決議資料,生產hbase的KeyValue物件
JavaPairDStream<ImmutableBytesWritable, KeyValue> putStream = messages.flatMapToPair(new StringToKeyValueFunc());public class StringToKeyValueFunc implements PairFlatMapFunction<String, ImmutableBytesWritable, KeyValue>, Serializable { Random random = null; @Override public Iterator<Tuple2<ImmutableBytesWritable, KeyValue>> call(String s) throws Exception { if (random == null) { random = new Random(); } String[] line = s.split(","); String rowkey = line[0]; String name = line[1]; String age = line[2]; List<Tuple2<ImmutableBytesWritable, KeyValue>> puts = new LinkedList<>(); KeyValue kv1 = new KeyValue(Bytes.toBytes(rowkey), Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes(name)); String key = Bytes.toString(Bytes.toBytes(rowkey)) + "\001" + "cf" + "\001" + "name" + "\001" + random.nextInt(9997); puts.add(new Tuple2<ImmutableBytesWritable, KeyValue>(new ImmutableBytesWritable(Bytes.toBytes(key)), kv1)); KeyValue kv2 = new KeyValue(Bytes.toBytes(rowkey), Bytes.toBytes("cf"), Bytes.toBytes("age"), Bytes.toBytes(age)); String key2 = Bytes.toString(Bytes.toBytes(rowkey)) + "\001" + "cf" + "\001" + "age" + "\001" + "\001" + random.nextInt(9997); puts.add(new Tuple2<ImmutableBytesWritable, KeyValue>(new ImmutableBytesWritable(Bytes.toBytes(key2)), kv2)); return puts.iterator(); } } -
生成HFile,bulkload入庫
putStream.foreachRDD(new BulkloadFunc(shuffleNum));public class BulkloadFunc implements VoidFunction<JavaPairRDD<ImmutableBytesWritable, KeyValue>>, Serializable { private int sortNum; public BulkloadFunc(int sortNum) { this.sortNum = sortNum; } @Override public void call(JavaPairRDD<ImmutableBytesWritable, KeyValue> rdd) throws Exception { DateTime currentTime = new DateTime(); String day = currentTime.toString("yyyyMMdd"); String tableName = "default:testbulk2"; Configuration conf = new Configuration(false); conf.setClassLoader(BulkloadFunc.class.getClassLoader()); conf.addResource("hbase-site.xml"); conf.addResource("hdfs-site.xml"); conf.addResource("core-site.xml"); conf.setStrings("io.serializations", conf.get("io.serializations"), KeyValueSerialization.class.getName(), WritableSerialization.class.getName()); Job job = Job.getInstance(conf); job.setMapOutputKeyClass(ImmutableBytesWritable.class); job.setMapOutputValueClass(KeyValue.class); HTable table = new HTable(conf, tableName); HFileOutputFormat.configureIncrementalLoad(job, table); String path = "hdfs://nameservice1/tmp/lsk2/" + currentTime.toString("yyyyMMddHHmmss"); job.getConfiguration().set("mapred.output.dir", path); rdd.sortByKey(new MyComparator(), true, sortNum).saveAsNewAPIHadoopDataset(job.getConfiguration()); load(conf,path,tableName); } private void load(Configuration conf,String path,String tableName) throws Exception { HTable table = new HTable(conf,tableName); LoadIncrementalHFiles bulkLoader = new LoadIncrementalHFiles(conf); bulkLoader.doBulkLoad(new Path(path),table); FileSystem fileSystem = FileSystem.get(conf); fileSystem.delete(new Path(path)); } }
四、原理決議
1.HBase存盤原理
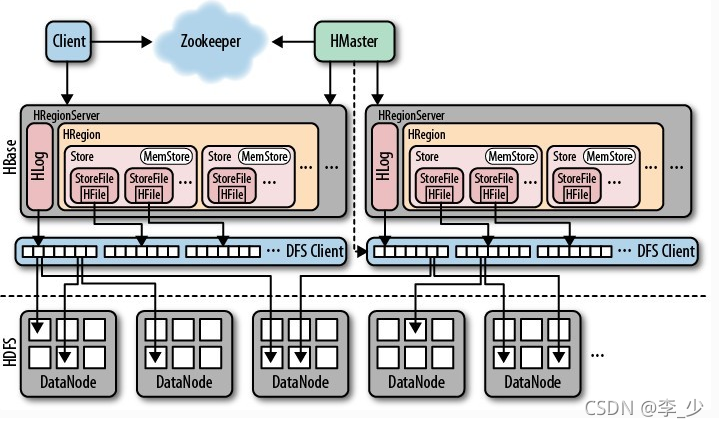
從HBase的架構圖上可以看出,HBase中的存盤包括HMaster、HRegionSever、HRegion、HLog、Store、MemStore、StoreFile、HFile等,HBase是Google的BigTable的開源實作,底層存盤引擎是基于LSM-Tree資料結構設計的,寫入資料時會先寫WAL日志,再將資料寫到寫快取MemStore中,等寫快取達到一定規模后或滿足其他觸發條件才會flush刷寫到磁盤,這樣就將磁盤隨機寫變成了順序寫,提高了寫性能,每一次刷寫磁盤都會生成新的HFile檔案,
2.MemStore的主要作用
- 更新資料存盤在 MemStore 中,使用 LSM(Log-Structured Merge Tree)資料結構存盤,在記憶體內進行排序整合,即保證寫入資料有序(HFile中資料都按照RowKey進行排序),同時可以極大地提升HBase的寫入性能,
- 作為記憶體快取,讀取資料時會優先檢查 MemStore,根據區域性原理,新寫入的資料被訪問的概率更大,
- 在持久化寫入前可以做某些優化,例如:保留資料的版本設定為1,持久化只需寫入最新版本,
3.HFile原理
-
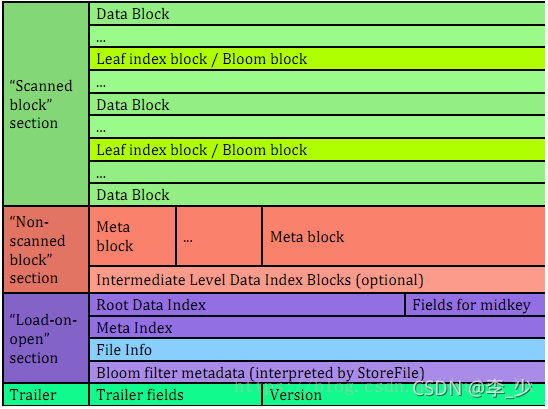
HFile主要分為四個部分:Scanned block section,Non-scanned block section,Opening-time data section和Trailer,
- Scanned block section:表示順序掃描HFile時(包含所有需要被讀取的資料)所有的資料塊將會被讀取,包括Leaf Index Block和Bloom Block;
- Non-scanned block section:HFile順序掃描的時候該部分資料不會被讀取,主要包括Meta Block和Intermediate Level Data Index Blocks兩部分;
- Load-on-open-section:這部分資料在HBase的region server啟動時,需要加載到記憶體中,包括FileInfo、Bloom filter block、data block index和meta block index;
- Trailer:這部分主要記錄了HFile的基本資訊、各個部分的偏移值和尋址資訊,
-
HFile生成程序
- 起初資料存在于MemStore中,Flush發生時,創建HFile Writer,MemStore中的KeyValues被一個個append到位于記憶體中的Data Block
- append時,會對Cell進行排序,(注:KeyValue是Cell的一種實作)
- 針對有序的Cell,HFile會生成三級索引:Root Index – Intermediate Level Data Index Block – Leaf Index Block
-
HFile中KeyValue的排序規則
org.apache.hadoop.hbase.CellComparator類中的compare()方法是KeyValue排序的核心方法public static int compare(final Cell a, final Cell b, boolean ignoreSequenceid) { // row int c = compareRows(a, b); if (c != 0) return c; c = compareWithoutRow(a, b); if(c != 0) return c; if (!ignoreSequenceid) { // Negate following comparisons so later edits show up first // mvccVersion: later sorts first return Longs.compare(b.getMvccVersion(), a.getMvccVersion()); } else { return c; } }compareRows()方法是比較rowkey的大小,保證rowkey按照字典順序排列,若rowkey相同,則進入compareWithoutRow()方法,compareWithoutRow()方法的核心邏輯如下:boolean sameFamilySize = (leftCell.getFamilyLength() == rightCell.getFamilyLength()); if (!sameFamilySize) { // comparing column family is enough. return Bytes.compareTo(leftCell.getFamilyArray(), leftCell.getFamilyOffset(), leftCell.getFamilyLength(), rightCell.getFamilyArray(), rightCell.getFamilyOffset(), rightCell.getFamilyLength()); } int diff = compareColumns(leftCell, rightCell); if (diff != 0) return diff; diff = compareTimestamps(leftCell, rightCell); if (diff != 0) return diff; // Compare types. Let the delete types sort ahead of puts; i.e. types // of higher numbers sort before those of lesser numbers. Maximum (255) // appears ahead of everything, and minimum (0) appears after // everything. return (0xff & rightCell.getTypeByte()) - (0xff & leftCell.getTypeByte());若列族的(位元組)長度不一致,則按照欄位順序去比較列族就可以回傳了,若長度一致,則會根據字典順序比較列族,若列族一致,則繼續比較列名、時間戳(按大小)、cell的type,直到結果不為0或者以上項都相同,
sequenceId是關聯WAL、HFile、MemStore三者內容的機制,此處略,
4.Spark生成HFile
核心思想:將kafka的資料組裝成KeyValue物件,保證KeyValue有序,且必須和上節講述的排序規則一致,
-
將kafka資料決議,組裝成KeyValue物件,如:
String[] line = s.split(","); String rowkey = line[0]; String name = line[1]; String age = line[2]; KeyValue kv1 = new KeyValue(Bytes.toBytes(rowkey), Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes(name)); KeyValue kv2 = new KeyValue(Bytes.toBytes(rowkey), Bytes.toBytes("cf"), Bytes.toBytes("age"), Bytes.toBytes(age)); -
根據排序規則,構造用來排序的key,
String key = Bytes.toString(Bytes.toBytes(rowkey)) + "\001" + "cf" + "\001" + "name" + "\001" + random.nextInt(9997); String key2 = Bytes.toString(Bytes.toBytes(rowkey)) + "\001" + "cf" + "\001" + "age" + "\001" + random.nextInt(9997); -
根據排序規則,自定義排序演算法
String[] keyLeft = Bytes.toString(left.get()).split("\001"); String[] keyRight = Bytes.toString(right.get()).split("\001"); int compareResult = 0; for (int i = 0; i < size; i++) { compareResult = Bytes.compareTo(Bytes.toBytes(keyLeft[i]), Bytes.toBytes(keyRight[i])); if (compareResult != 0) { return compareResult; } } return compareResult; -
將rdd排序并生產HFile至HDFS
rdd.sortByKey(new MyComparator(), true, sortNum).saveAsNewAPIHadoopDataset(job.getConfiguration());
5.HBase表Load HFile
private void load(Configuration conf,String path,String tableName) throws Exception {
HTable table = new HTable(conf,tableName);
LoadIncrementalHFiles bulkLoader = new LoadIncrementalHFiles(conf);
bulkLoader.doBulkLoad(new Path(path),table);
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.delete(new Path(path));
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355268.html
標籤:其他