- 前置設定: 資料均衡帶寬優化
#引數說明:設定balance工具在運行中所能占用的帶寬,需反復除錯設定為合理值, 過大反而會造成MapReduce流程運行緩慢
#CDH集群上默認值為10M, 案例中設定為1G
hdfs dfsadmin -setBalancerBandwidth 104857600
CDH集群默認值:
- Hadoop集群節點間的資料均衡
hadoop_hdfsdata_rebalancer.sh 清單:
nohup hdfs balancer \
-D "dfs.balancer.movedWinWidth=300000000" \
-D "dfs.datanode.balance.bandwidthPerSec=2000m" \
-threshold 5 > my-hadoop-balancer-v2021u1109.log &
引數說明:
- -threshold 5
集群平衡的條件,datanode間磁盤使用率差異的閾值,區間選擇:0~100; Threshold引數為集群是否處于均衡狀態設定了一個預期目標.
threshold 默認設定:10,引數取值范圍:0-100,引數含義:判斷集群是否平衡的目標引數,每一個 datanode 存盤使用率和集群總存盤使用率的差值都應該小于這個閥值 ,
理論上,該引數設定的越小,整個集群就越平衡,但是在線上環境中,hadoop集群在進行balance時,還在并發的進行資料的寫入和洗掉,所以有可能無法到達設定的平衡引數值,
這個命令中-threshold 引數后面跟的是HDFS達到平衡狀態的磁盤使用率偏差值,如果機器與機器之間磁盤使用率偏差小于10%,那么我們就認為HDFS集群已經達到了平衡的狀態,- -policy datanode
默認為datanode,datanode級別的平衡策略- -exclude -f /tmp/ip1.txt
默認為空,指定該部分ip不參與balance, -f:指定輸入為檔案- -include -f /tmp/ip2.txt
默認為空,只允許該部分ip參與balance,-f:指定輸入為檔案- -idleiterations 5
迭代次數,默認為 5
- 某個節點內各磁盤間的資料均衡:
> hdfs diskbalancer -plan $IP -bandwidth 1000 -v 2> /dev/null | egrep ^/ | xargs hdfs diskbalancer -execute
均衡期間, 查看磁盤的均衡情況或進度情況:
> hdfs diskbalancer -query $IP
- 資料均衡的原理:
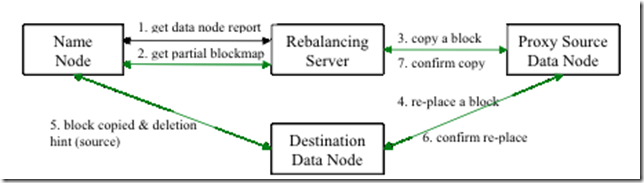
Rebalance程式作為一個獨立的行程與name node進行分開執行:
.
1 Rebalance Server從Name Node中獲取所有的Data Node情況:每一個Data Node磁盤使用情況,
2 Rebalance Server計算哪些機器需要將資料移動,哪些機器可以接受移動的資料,并且從Name Node中獲取需要移動的資料分布情況,
3 Rebalance Server計算出來可以將哪一臺機器的block移動到另一臺機器中去,
4,5,6 需要移動block的機器將資料移動的目的機器上去,同時洗掉自己機器上的block資料,
7 Rebalance Server獲取到本次資料移動的執行結果,并繼續執行這個程序,一直沒有資料可以移動或者HDFS集群以及達到了平衡的標準為止,
資料均衡需遵循如下原則:
- 1.在執行資料重分布的程序中,必須保證資料不能出現丟失,不能改變資料的備份數,不能改變每一個rack中所具備的block數量,
- 2.系統管理員可以通過一條命令啟動資料重分布程式或者停止資料重分布程式,
- 3.Block在移動的程序中,不能暫用過多的資源,如網路帶寬,
- 4.資料重分布程式在執行的程序中,不能影響name node的正常作業,
資料均衡的推出條件:
- 集群已達到均衡狀態;
- 沒有block能被移動;
- 連續5次迭代移動沒有任何一個block被移動;
- 當與namenode互動式出現了IOException;
- 另一個balancer已經在運行中,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355269.html
標籤:其他