一、環境配置
1.安裝好顯卡驅動,如:CUDA;
2.配置好pytorch1.7及以上版本的python3,盡量安裝GPU和CPU通用的pytorch
這部分我不詳細講述,各位哥可以上網找找別的教程,
二、YOLOV5的實作訓練
1.下載好YOLOv5的框架,并在python的IDE中打開,如:pycharm
這里給出最新版官方的框架下載地址:
https://github.com/ultralytics/yolov5
我也給出我使用的框架的下載地址,可能不是最新的,但是對于本教程來說是有用的
yolov5-master.zip_樹莓派部署yolov5,yolov5樹莓派-深度學習檔案類資源-CSDN下載
2.資料集獲取
個人推薦在Kaggle上找資料集,質量和數量都比較高,這里給出地址
Find Open Datasets and Machine Learning Projects | Kaggle
當然,自己制作資料集也是可以的,但是資料集的質量可能會影響到目標檢測系統的準確度,我這里就不主要說明如何制作VOC資料集了,各位哥可以上網查找,
本次我使用的是一個檢測地面坑洼的VOC資料集,這里給出下載地址:
3.開始訓練自己的資料集
1.按照以下的布局新建好對應的檔案夾,本身自帶的也不用洗掉,只增不減
├── data
│ ├── Annotations 進行 detection 任務時的標簽檔案,xml 形式,檔案名與圖片名一一對應
│ ├── images 存放 .jpg 格式的圖片檔案
│ ├── ImageSets 存放的是分類和檢測的資料集分割檔案,包含train.txt, val.txt,trainval.txt,test.txt
│ ├── labels 存放label標注資訊的txt檔案,與圖片一一對應
├── ImageSets(train,val,test建議按照8:1:1比例劃分)
│ ├── train.txt 寫著用于訓練的圖片名稱
│ ├── val.txt 寫著用于驗證的圖片名稱
│ ├── trainval.txt train與val的合集
│ ├── test.txt 寫著用于測驗的圖片名稱
將下載好的資料集解壓,得到 Annotations 和 images 檔案夾

annotations檔案夾中有 xml 檔案
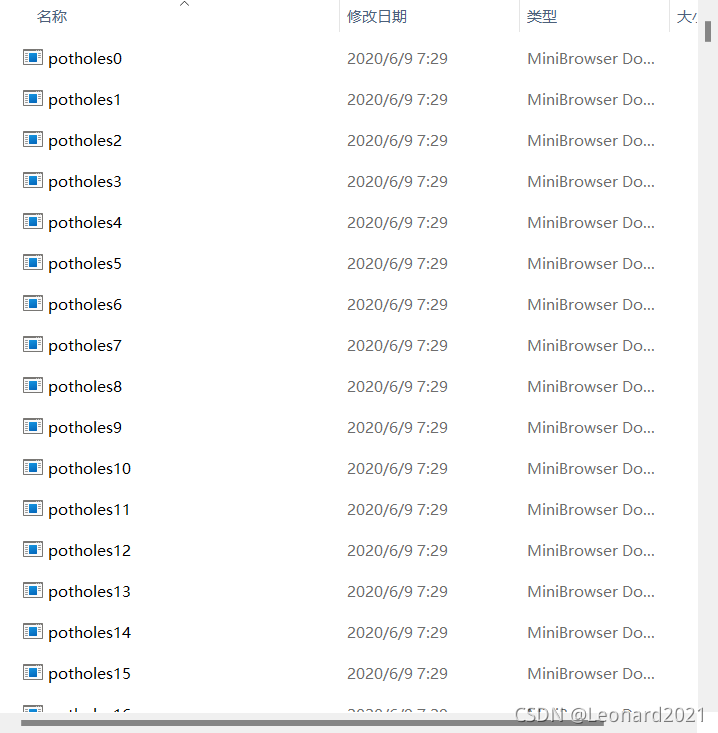
images 檔案夾 中有對應的圖片
將解壓好的檔案對號入座地復制到YOLOV5框架中Date下的Annotations 和 images 檔案夾中
2.對資料集進行初步處理
A.在yolov5的根目錄下新建一個檔案ChangeName.py,代碼如下:
import os
#任何格式的檔案都適用
path = "D:\pyCharmdata\Pothole_detection_YOLOV5\data\images"
filelist = os.listdir(path)
count=0
for file in filelist:
print(file)
for file in filelist:
Olddir=os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename=os.path.splitext(file)[0]
filetype=os.path.splitext(file)[1]
Newdir=os.path.join(path,str(count).zfill(6)+filetype)
os.rename(Olddir,Newdir)
count+=1
將path = ",,"這行分別改成YOLOv5框架的data下images和Annotations的地址,并且各運行一次,將所有的xml和圖片對應地重命名一次,得
B.在yolov5的根目錄下新建一個檔案IntoJPG.py,代碼如下:
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 19 10:39:03 2019
@author: wsb
"""
import cv2
import os
print('----------------------------------------------------')
print('程式的功能為:將該目錄下輸入的檔案內的圖片轉為指定格式') # 目前我測驗了jpg轉化為png和png轉化為jpg,
print('轉化結果保存在當前目錄下的new_picture內')
print('----------------------------------------------------')
son = 'D:\pyCharmdata\Pothole_detection_YOLOV5\data\images'
picture_type = 'jpg'
#daddir = './'
path = son
newpath = "new_picture"
if not os.path.exists(newpath):
os.mkdir(newpath)
path_list = os.listdir(path)
number = 0 # 統計圖片數量
for filename in path_list:
number += 1
portion = os.path.splitext(filename)
print('convert ' + filename + ' to ' + portion[0] + '.' + picture_type)
img = cv2.imread(path + "/" + filename)
cv2.imwrite("./" + newpath + "/" + portion[0] + '.' + picture_type, img)
print("共轉化了%d張圖片" % number)
print('轉換完畢,檔案存入 ' + newpath + ' 中')
cv2.waitKey(0)
cv2.destroyAllWindows()
這里要自己修改 son =".." 和 newpath = ".." 的路徑為要修改的圖片的地址和修改后要存放的地址,將所有的圖片都統一成 JPG 格式,
C.在yolov5的根目錄下新建一個檔案makeTxt.py,代碼如下:
import os
import random
trainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
由此,將資料集劃分,
D.接著再新建另一個檔案voc_label.py,切記,classes=[……] 中填入的一定要是自己在資料集中所標注的類別名稱,標記了幾個類別就填寫幾個類別名,我這里只有一個類別,故只填了一個'pothole',類別的查看可以用瀏覽器打開對應的XML檔案,name那一行對應的就是類別,

填寫錯誤的話會造成讀取不出xml檔案里的標注資訊,代碼如下:
# xml決議包
import xml.etree.ElementTree as ET
import pickle
import os
# os.listdir() 方法用于回傳指定的檔案夾包含的檔案或檔案夾的名字的串列
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['pothole']
# 進行歸一化操作
def convert(size, box): # size:(原圖w,原圖h) , box:(xmin,xmax,ymin,ymax)
dw = 1./size[0] # 1/w
dh = 1./size[1] # 1/h
x = (box[0] + box[1])/2.0 # 物體在圖中的中心點x坐標
y = (box[2] + box[3])/2.0 # 物體在圖中的中心點y坐標
w = box[1] - box[0] # 物體實際像素寬度
h = box[3] - box[2] # 物體實際像素高度
x = x*dw # 物體中心點x的坐標比(相當于 x/原圖w)
w = w*dw # 物體寬度的寬度比(相當于 w/原圖w)
y = y*dh # 物體中心點y的坐標比(相當于 y/原圖h)
h = h*dh # 物體寬度的寬度比(相當于 h/原圖h)
return (x, y, w, h) # 回傳 相對于原圖的物體中心點的x坐標比,y坐標比,寬度比,高度比,取值范圍[0-1]
# year ='2012', 對應圖片的id(檔案名)
def convert_annotation(image_id):
'''
將對應檔案名的xml檔案轉化為label檔案,xml檔案包含了對應的bunding框以及圖片長款大小等資訊,
通過對其決議,然后進行歸一化最終讀到label檔案中去,也就是說
一張圖片檔案對應一個xml檔案,然后通過決議和歸一化,能夠將對應的資訊保存到唯一一個label檔案中去
labal檔案中的格式:calss x y w h 同時,一張圖片對應的類別有多個,所以對應的bunding的資訊也有多個
'''
# 對應的通過year 找到相應的檔案夾,并且打開相應image_id的xml檔案,其對應bund檔案
in_file = open('data/Annotations/%s.xml' % (image_id), encoding='utf-8')
# 準備在對應的image_id 中寫入對應的label,分別為
# <object-class> <x> <y> <width> <height>
out_file = open('data/labels/%s.txt' % (image_id), 'w', encoding='utf-8')
# 決議xml檔案
tree = ET.parse(in_file)
# 獲得對應的鍵值對
root = tree.getroot()
# 獲得圖片的尺寸大小
size = root.find('size')
# 如果xml內的標記為空,增加判斷條件
if size != None:
# 獲得寬
w = int(size.find('width').text)
# 獲得高
h = int(size.find('height').text)
# 遍歷目標obj
for obj in root.iter('object'):
# 獲得difficult ??
difficult = obj.find('difficult').text
# 獲得類別 =string 型別
cls = obj.find('name').text
# 如果類別不是對應在我們預定好的class檔案中,或difficult==1則跳過
if cls not in classes or int(difficult) == 1:
continue
# 通過類別名稱找到id
cls_id = classes.index(cls)
# 找到bndbox 物件
xmlbox = obj.find('bndbox')
# 獲取對應的bndbox的陣列 = ['xmin','xmax','ymin','ymax']
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
print(image_id, cls, b)
# 帶入進行歸一化操作
# w = 寬, h = 高, b= bndbox的陣列 = ['xmin','xmax','ymin','ymax']
bb = convert((w, h), b)
# bb 對應的是歸一化后的(x,y,w,h)
# 生成 calss x y w h 在label檔案中
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
# 回傳當前作業目錄
wd = getcwd()
print(wd)
for image_set in sets:
'''
對所有的檔案資料集進行遍歷
做了兩個作業:
1.將所有圖片檔案都遍歷一遍,并且將其所有的全路徑都寫在對應的txt檔案中去,方便定位
2.同時對所有的圖片檔案進行決議和轉化,將其對應的bundingbox 以及類別的資訊全部決議寫到label 檔案中去
最后再通過直接讀取檔案,就能找到對應的label 資訊
'''
# 先找labels檔案夾如果不存在則創建
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
# 讀取在ImageSets/Main 中的train、test..等檔案的內容
# 包含對應的檔案名稱
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
# 打開對應的2012_train.txt 檔案對其進行寫入準備
list_file = open('data/%s.txt' % (image_set), 'w')
# 將對應的檔案_id以及全路徑寫進去并換行
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
# 呼叫 year = 年份 image_id = 對應的檔案名_id
convert_annotation(image_id)
# 關閉檔案
list_file.close()
# os.system(‘comand’) 會執行括號中的命令,如果命令成功執行,這條陳述句回傳0,否則回傳1
# os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
# os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")3.YOLOV5框架檔案的修改
A.下載好YOLOV5的官方yolov5s,放到YOLOv5的根目錄下
yolov5s和yolov5x.zip_yolov5s和yolov5x-深度學習檔案類資源-CSDN下載
B.首先在data目錄下,復制一份coco.yaml檔案并將其重命名為Pothole_detection.yaml,放在data目錄下,并對cat.yaml中的引數進行配置,其中train,val,test后面分別為訓練集和測驗集圖片的路徑, nc為資料集的類別數,我這里只分了1類,names為類別的名稱,這幾個引數均按照自己的實際需求來修改,代碼如下:
# COCO 2017 dataset http://cocodataset.org
# Download command: bash yolov5/data/get_coco2017.sh
# Train command: python train.py --data ./data/coco.yaml
# Dataset should be placed next to yolov5 folder:
# /parent_folder
# /coco
# /yolov5
# train and val datasets (image directory or *.txt file with image paths)
train: data/train.txt # 118k images
val: data/val.txt # 5k images
test: data/test.txt # 20k images for submission to https://competitions.codalab.org/competitions/20794
# number of classes
nc: 1
# class names
names: ['pothole']
# Print classes
# with open('data/coco.yaml') as f:
# d = yaml.load(f, Loader=yaml.FullLoader) # dict
# for i, x in enumerate(d['names']):
# print(i, x)
C.接著在models目錄下找到yolov5s.yaml檔案復制一份到date檔案夾下進行修改,這里取決于你使用了哪個模型就去修改對于的檔案,該專案中使用的是yolov5s模型,需要修改的代碼如下:
# parameters
nc: 1 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
這里只需修改nc:,,為你的種類數即可
D.修改yolov5代碼,修改檔案在 yolov5\utils\datasets.py
修改引數 num_workers為0
# Use torch.utils.data.DataLoader() if dataset.properties will update during training else InfiniteDataLoader()
dataloader = loader(dataset,
batch_size=batch_size,
num_workers=0,
sampler=sampler,
pin_memory=True,
collate_fn=LoadImagesAndLabels.collate_fn4 if quad else LoadImagesAndLabels.collate_fn)
return dataloader, dataset
E.修改train.py的一些引數
找到parse_pot函式
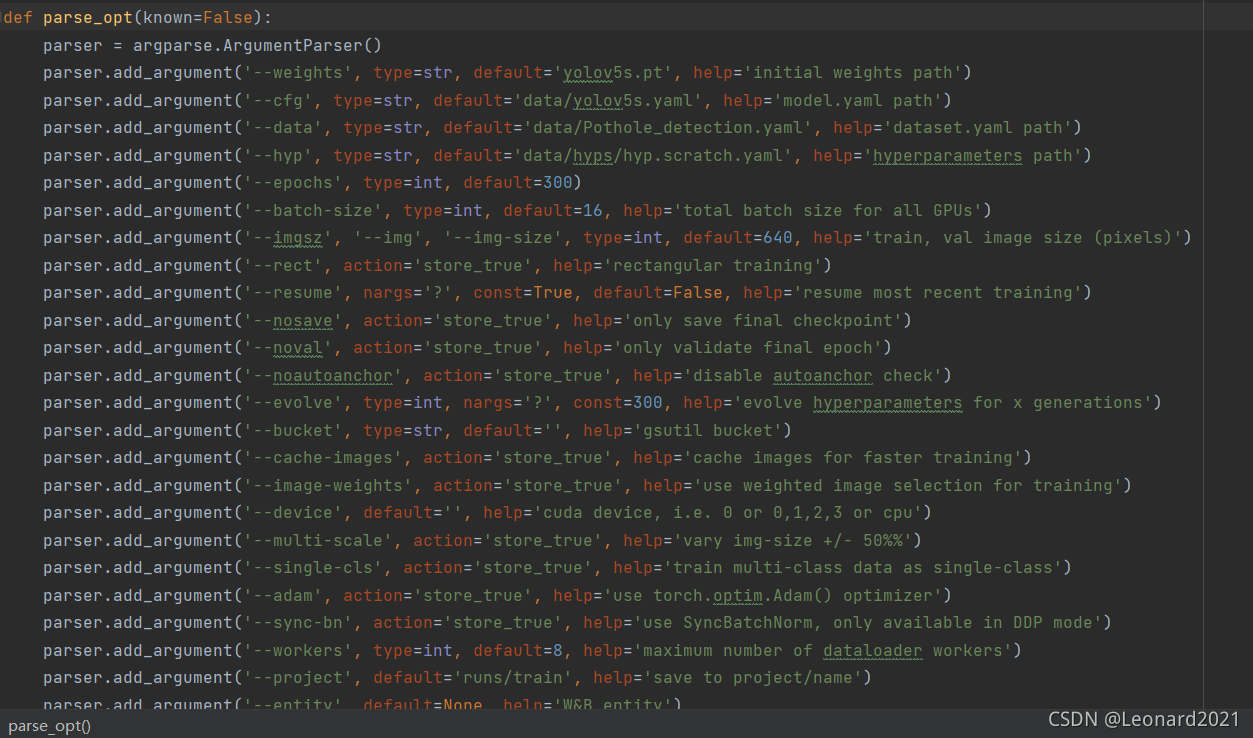
將 --cfg 和 --date 對應的兩行的default 分別修改為你存放的檔案地址,這里我是按照的地址來寫的
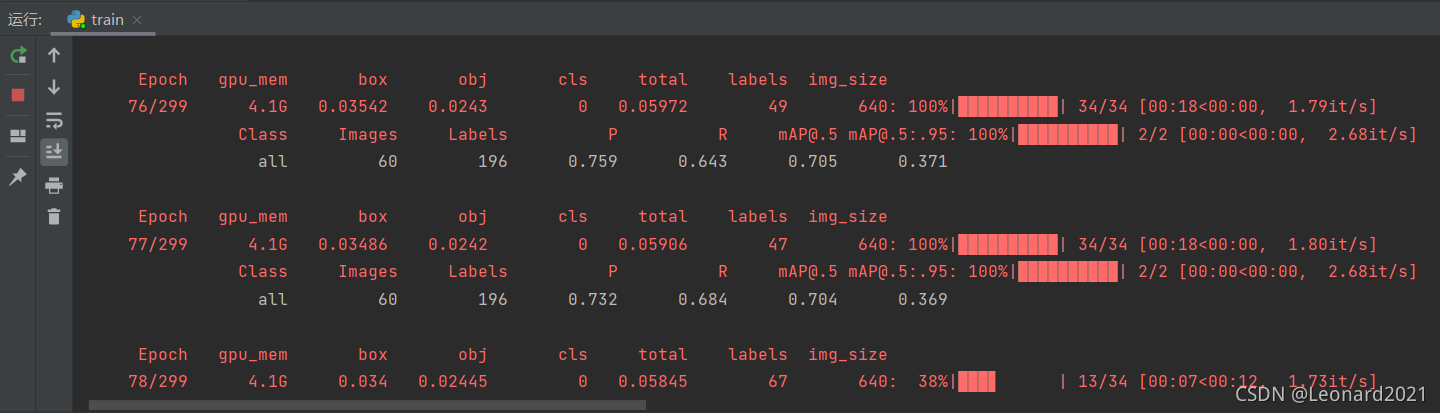
4.開始訓練
直接滑鼠右鍵開始運行train.py進行訓練
剛開始前面會報一些錯誤,但是不影響后續訓練
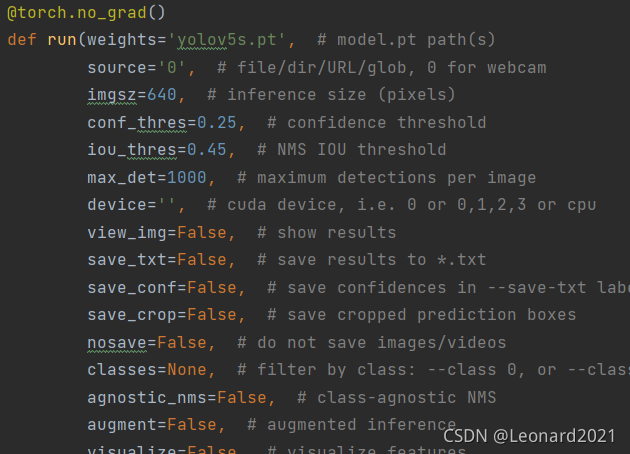
5.修改detect.py 進行目標檢測的實作
A.找到run函式,將source對應的值修改為‘0’
B.找到parse_opt函式,將--weight 對應的地址修改為runs/train/.../weights/best.pt
若想要檢測圖片或者視頻,并保存檢測結果,只需把 --source 對應的 default修改為存放視頻或者圖片的地址,結果將保存在runs/detect/..下



若想實作實時檢測,只需把 --source 對應的 default修改為對應攝像頭的號碼,若只有一個攝像頭,則只需寫‘0’即可,也可以用手機攝像頭來進行檢測,參考我的另一篇文章,
樹莓派YOLOV5連接手機攝像頭_Leonard2021的博客-CSDN博客
6.應用方向
可以在上位機(PC、樹莓派、jetson nano)中除錯這個地面坑洼檢測系統,再與下位機(如:arduino,stm32等)進行通訊,可實作簡單的無人車路面避坑(避障),如:
樹莓派官方系統與arduino通訊_Leonard2021的博客-CSDN博客_樹莓派與arduino聯合控制
到此本文結束,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355430.html
標籤:其他
上一篇:OpenCV 影像模糊原理