本案例源自ML-Agents官方的示例,Github地址:https://github.com/Unity-Technologies/ml-agents
本文基于我前面發的兩篇文章,需要對ML-Agents有一定的了解,詳情請見:Unity強化學習之ML-Agents的使用、ML-Agents命令及配置大全,
參考資料:ML-Agents(八)PushBlock、訓練ML-Agents玩躲避球、ML-Agents 2.0:合作行為訓練
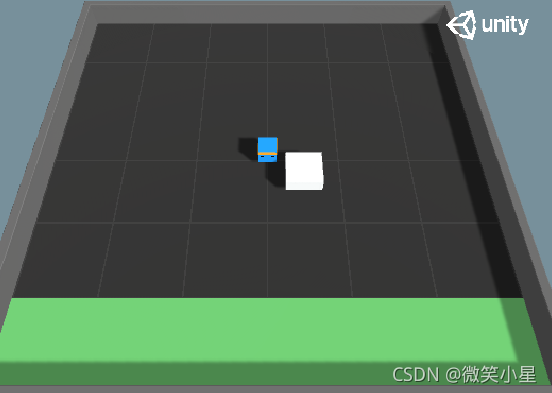
游戲目標:智能體把白色的方塊推到指定的綠色區域為游戲勝利,
推箱子游戲分為單人模式和多人模式,
單人模式
腳本代碼
由于推箱子在環境上的設定較簡單,我們可以直接來查看掛載在Agent本體的腳本有什么,
首先是正常的Behavior Parameters,Decision Requester,Model Overrider三件套,Behavior Parameters的觀測維度直接設定為0,這是由于我們采用了Ray Perception Sensor3D腳本來采集觀測資料,輸出的空間是離散的,只有一個輸出,這就表示移動和旋轉共用一個輸出且移動方向固定,
射線感知器Ray Perception Sensor Component 3D組件
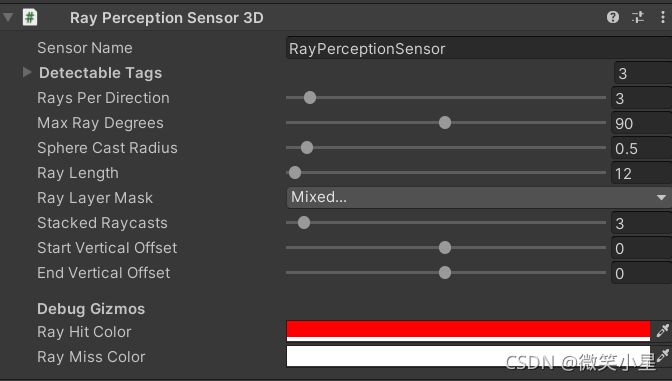
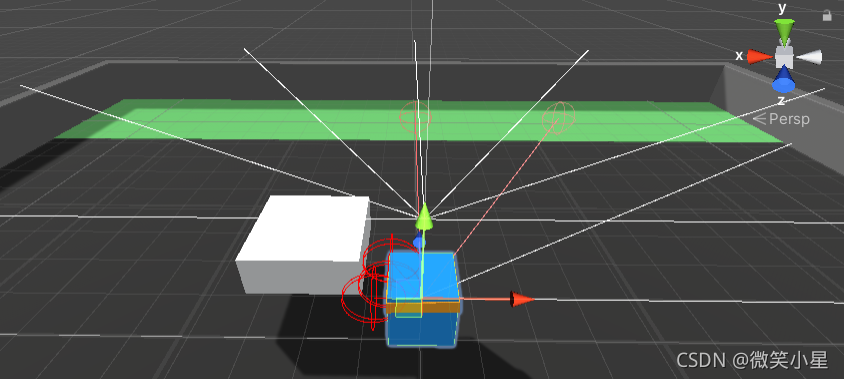
可以看到一個智能體上掛了兩個Ray Perception Sensor Component 3D組件,第一個在腳下,主要用來探測方塊和目標點,第二個在頭頂,主要是為了越過方塊探測到方塊后有沒有墻體,兩個傳感器的引數只在兩個offset上有差異,
- Sensor Name:該Sensor的名字,類似于ID,
- Detectable Tags:設定射線能檢測到物體的Tag集合,這里設定了3個Tag,分別代表了場景中的目標小白塊、目標區域和墻體,
- Rays Per Direction:每個方向射線的條數,智能體正前方固定有一條射線,這里設定為3表示左右各3條,加上中間一條一共七條,
- Max Ray Degrees:射線覆寫的角度最大范圍,90指的是左右兩邊各90,一共覆寫180度,
- Sphere Cast Radius:設定投射出去的碰撞球體的半徑,也指射線的粗細,設為0代表一條線,
- Ray Length:設定射線投射的最遠距離,
- Ray Layer Mask:設定射線可以檢測到的Layer,
- Observation Stacks:堆疊之前觀察的結果的數量,若設定為1則表示不堆疊以前的觀察,
- Start Vertical Offset:調整射線發出的高度,
- End Vertical Offset:設定射線尾部的高度,這兩個offset一起調整可以達到任意從上往下或從下往上的射線,
- Ray Hit Color:射線發生碰撞的顏色,
- Ray Miss Color:射線沒有發生碰撞的顏色,
這里可以計算輸維度了,我們有兩個傳感器,每個傳感器七條射線,每條射線檢測三個標簽(one-hot向量表示),再加上射線自帶的兩個維度(碰撞距離的標準化和碰撞與否),在此基礎上,疊加3次的觀察資訊就是3 * 2 * 7 * (2 + 3) = 210個觀察維度,
把輸入提交給智能體的方法有三種,這里用了最難的一種,也就是繼承了一個ISensor的介面,其中的Write方法被用于實際生成觀察,相機傳感器,渲染貼圖傳感器,射線傳感器,棋盤傳感器,網格傳感器都繼承了這個介面,
詳細內容查看檔案:https://github.com/Unity-Technologies/ml-agents/blob/main/docs/Learning-Environment-Design-Agents.md
接下來看看主腳本Push Agent Basic:
先看看初始化時做了什么:
void Awake()
{
// 找到掛載訓練引數的腳本
m_PushBlockSettings = FindObjectOfType<PushBlockSettings>();
}
public override void Initialize()
{
goalDetect = block.GetComponent<GoalDetect>();
goalDetect.agent = this;
m_AgentRb = GetComponent<Rigidbody>();
m_BlockRb = block.GetComponent<Rigidbody>();
// 獲取碰撞器的世界空間邊界體積(只讀),
areaBounds = ground.GetComponent<Collider>().bounds;
// 獲取地面渲染器,便于更換材質
m_GroundRenderer = ground.GetComponent<Renderer>();
// 初始材質
m_GroundMaterial = m_GroundRenderer.material;
// 獲取組態檔中的引數
m_ResetParams = Academy.Instance.EnvironmentParameters;
//設定引數
SetResetParameters();
}
void SetResetParameters()
{
// 設定方塊動摩擦和靜摩擦系數
SetGroundMaterialFriction();
// 設定方塊的大小,以及空氣阻力
SetBlockProperties();
}
public void SetGroundMaterialFriction()
{
var groundCollider = ground.GetComponent<Collider>();
groundCollider.material.dynamicFriction = m_ResetParams.GetWithDefault("dynamic_friction", 0);
groundCollider.material.staticFriction = m_ResetParams.GetWithDefault("static_friction", 0);
}
public void SetBlockProperties()
{
var scale = m_ResetParams.GetWithDefault("block_scale", 2);
//Set the scale of the block
m_BlockRb.transform.localScale = new Vector3(scale, 0.75f, scale);
// Set the drag of the block
m_BlockRb.drag = m_ResetParams.GetWithDefault("block_drag", 0.5f);
}
最為關鍵的OnActionReceived函式:
public void MoveAgent(ActionSegment<int> act)
{
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
// 獲取一個離散輸出,范圍是0~6
var action = act[0];
// 根據離散的輸出判斷六種運動可能分別是前后左右移動和左右旋轉,0是什么都不做,
switch (action)
{
case 1:
dirToGo = transform.forward * 1f;
break;
case 2:
dirToGo = transform.forward * -1f;
break;
case 3:
rotateDir = transform.up * 1f;
break;
case 4:
rotateDir = transform.up * -1f;
break;
case 5:
dirToGo = transform.right * -0.75f;
break;
case 6:
dirToGo = transform.right * 0.75f;
break;
}
transform.Rotate(rotateDir, Time.fixedDeltaTime * 200f);
// 注意這里要對剛體施加力的方式讓其前進,不能直接改變其位置,否則不能達到一個智能體推不動大方塊的效果
m_AgentRb.AddForce(dirToGo * m_PushBlockSettings.agentRunSpeed,
ForceMode.VelocityChange);
}
// 每個step都呼叫的函式,每次都扣除微量分數,這就鼓勵智能體完成得越快越好
public override void OnActionReceived(ActionBuffers actionBuffers)
{
MoveAgent(actionBuffers.DiscreteActions);
AddReward(-1f / MaxStep);
}
Heuristic方法,可以由玩家手動控制智能體:
public override void Heuristic(in ActionBuffers actionsOut)
{
var discreteActionsOut = actionsOut.DiscreteActions;
if (Input.GetKey(KeyCode.D))
{
discreteActionsOut[0] = 3;
}
else if (Input.GetKey(KeyCode.W))
{
discreteActionsOut[0] = 1;
}
else if (Input.GetKey(KeyCode.A))
{
discreteActionsOut[0] = 4;
}
else if (Input.GetKey(KeyCode.S))
{
discreteActionsOut[0] = 2;
}
}
每個episode開始時呼叫的OnEpisodeBegin方法:
public override void OnEpisodeBegin()
{
// 場地四個角度任意旋轉
var rotation = Random.Range(0, 4);
var rotationAngle = rotation * 90f;
area.transform.Rotate(new Vector3(0f, rotationAngle, 0f));
// 重置方塊的引數,速度和角速度歸零,位置隨機
ResetBlock();
// 重置智能體引數,速度和角速度歸零,位置隨機
transform.position = GetRandomSpawnPos();
m_AgentRb.velocity = Vector3.zero;
m_AgentRb.angularVelocity = Vector3.zero;
// 設定方塊動摩擦和靜摩擦系數,方塊大小,空氣阻力
SetResetParameters();
}
void ResetBlock()
{
block.transform.position = GetRandomSpawnPos();
m_BlockRb.velocity = Vector3.zero;
m_BlockRb.angularVelocity = Vector3.zero;
}
public Vector3 GetRandomSpawnPos()
{
var foundNewSpawnLocation = false;
var randomSpawnPos = Vector3.zero;
while (foundNewSpawnLocation == false)
{
var randomPosX = Random.Range(-areaBounds.extents.x * m_PushBlockSettings.spawnAreaMarginMultiplier,
areaBounds.extents.x * m_PushBlockSettings.spawnAreaMarginMultiplier);
var randomPosZ = Random.Range(-areaBounds.extents.z * m_PushBlockSettings.spawnAreaMarginMultiplier,
areaBounds.extents.z * m_PushBlockSettings.spawnAreaMarginMultiplier);
randomSpawnPos = ground.transform.position + new Vector3(randomPosX, 1f, randomPosZ);
// checkBox檢查生成的地方是否與其他碰撞體碰撞,第一個引數是中心,第二個是cube范圍半徑
if (Physics.CheckBox(randomSpawnPos, new Vector3(2.5f, 0.01f, 2.5f)) == false)
{
foundNewSpawnLocation = true;
}
}
return randomSpawnPos;
}
最后就是看看掛載在方塊上檢測碰撞的腳本了:
public class GoalDetect : MonoBehaviour
{
[HideInInspector]
public PushAgentBasic agent;
void OnCollisionEnter(Collision col)
{
// 呼叫agent中的函式
if (col.gameObject.CompareTag("goal"))
{
agent.ScoredAGoal();
}
}
}
在主腳本Push Agent Basic中有:
public void ScoredAGoal()
{
// 方塊到達指定區域加5分
AddReward(5f);
// 結束本輪
EndEpisode();
// 改變材質
StartCoroutine(GoalScoredSwapGroundMaterial(m_PushBlockSettings.goalScoredMaterial, 0.5f));
}
組態檔
PPO演算法:
behaviors:
PushBlock:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 2000000
time_horizon: 64
summary_freq: 60000
SAC演算法:
behaviors:
PushBlock:
trainer_type: sac
hyperparameters:
learning_rate: 0.0003
learning_rate_schedule: constant
batch_size: 128
buffer_size: 50000
buffer_init_steps: 0
tau: 0.005
steps_per_update: 10.0
save_replay_buffer: false
init_entcoef: 0.05
reward_signal_steps_per_update: 10.0
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 2000000
time_horizon: 64
summary_freq: 100000
多人模式
接下來就是重頭戲多人模式了:
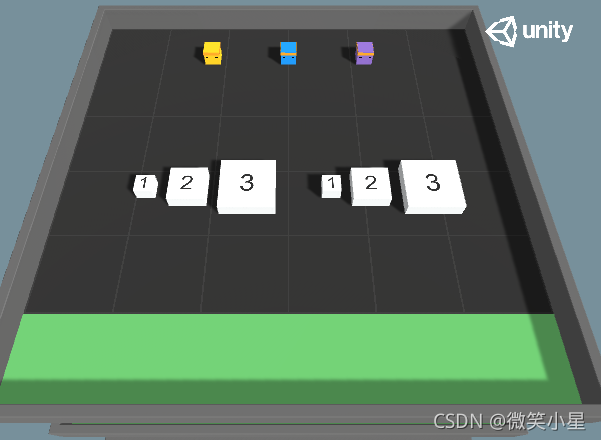
這個模式擁有三個智能體,六個大小不一的方塊隨機放置在不靠近墻體邊緣的地方,小方塊一個人能推動,中等方塊需要兩個人才能推動,大的方塊需要三個人才能推動,推的方塊越大,獎勵越高,如何把所有的方塊都推到指定目標,并且用時最短是我們追求的目標,
由于擁有多個智能體,所有團隊協作是我們需要考慮的重要因素之一,因此單智能體演算法已經滿足不了我們的需求了,這里ML-Agents官方示例使用了一種多智能體演算法MA-POCA,這也是ML-Agents目前新推出的唯一一種多智能體演算法,在版本16之后,我們可以定義具有共同目標的多智能體了,MA-POCA是一個多智能體訓練器,是所有智能體的“教練”,教練向整個團隊發放獎勵,智能體們也可以學習如何更好為共同目標做出貢獻,每個智能體可以獲得個人的reward,這樣它們可以很好地保持積極性,并幫助彼此實作目標,即使有個智能體死亡(被移除),也依然可以采集資訊,理解它們的行為是否可以有助于獲得勝利,把群體放在第一位,能夠通過自我犧牲來獲取游戲的勝利,
這種新演算法采用了集中式學習與分散式執行,一個中心裁判負責評估所有智能體的狀態,進而對其表現進行打分,而多個分散的執行程式(每個智能體一個)負責控制智能體,如此一來,每個智能體可根據自己的感知進行決策,同時評估其行為在整個群體中的作用,下圖展示了MA-POCA的集中式學習和分散式執行,
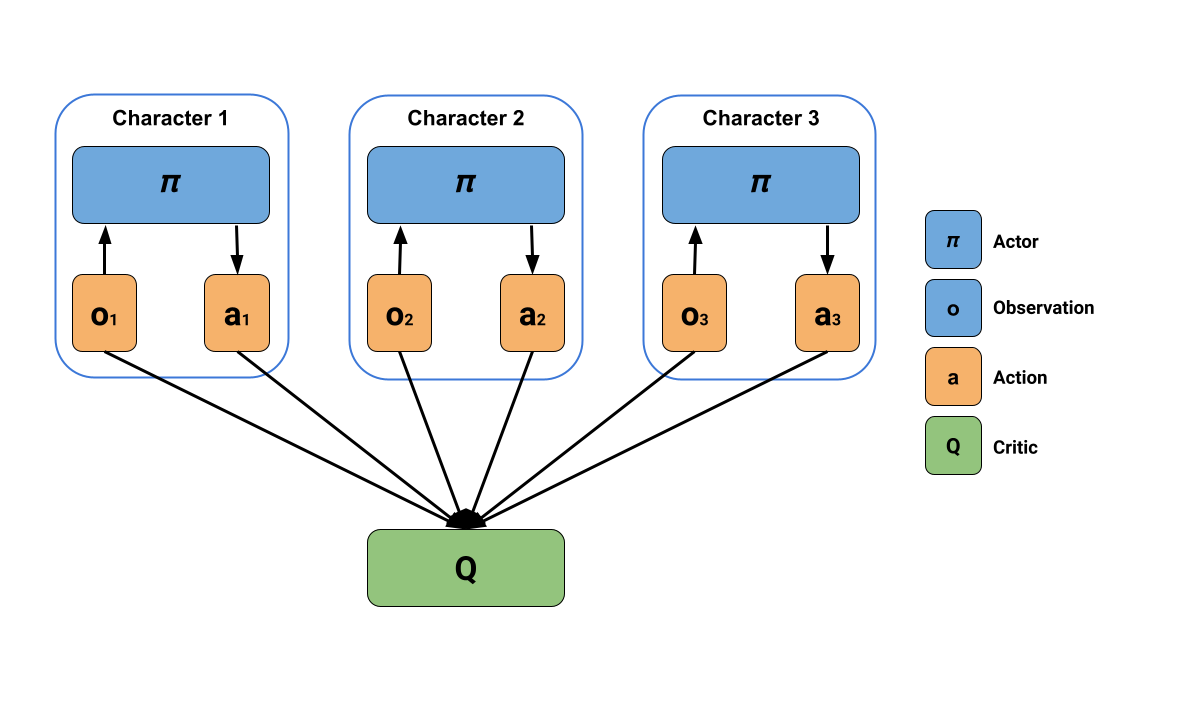
MA-POCA演算法的一個新穎之處在于,它使用了一種稱為attention networks(注意力網路)的特殊神經網路結構,可以處理不定量輸入,這意味著裁判可以評估任意數量的智能體,而MA-POCA也因此特別適用于游戲中的合作行為,智能體可在任何時候加入或退出小組——類似于游戲角色在團戰中的復活與死亡,MA-POCA的設計是為了讓智能體能夠做出利他性決定,讓團隊利益最大化,這種利他行為很難通過人工編程實作,但可在其他智能體為團隊做貢獻的先例中學習,最后,大多數多智能體強化學習演算法默認讓所有智能體在同一時間點選擇下一個行動,但在真實游戲中,多智能體同時決策很有可能會產生掉幀,這也是為什么MA-POCA不會采取這種方法,而是支持異步的智能體行為決策,
MA-POCA 使用與 PPO 相同的配置,并且沒有額外的 POCA 特定引數,
對比單人模式的推箱子,多人模式的機制并沒有太大的改變,
腳本代碼
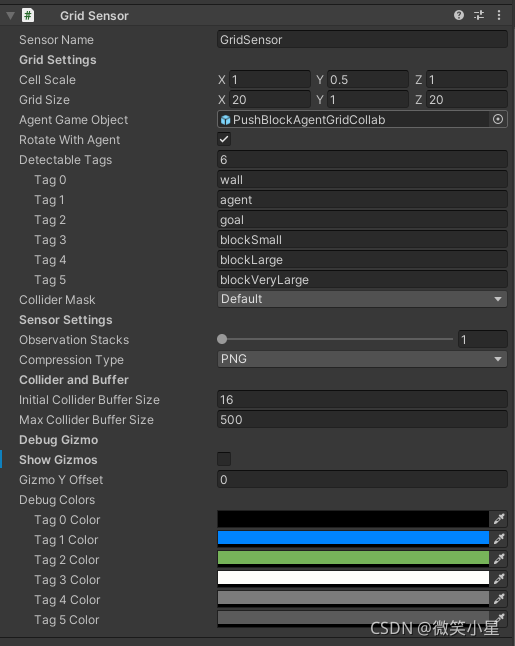
Grid Sensor
多人模式的腳本甚至可以說變得更為簡單了,Behavior Parameter的設定和單智能體一致,在獲取觀測值的方面,沒有采用單智能體的射線傳感器,而是采用了Grid Sensor(網格傳感器),這個傳感器并沒有直接掛在智能體下,而是掛在智能體的子物體(空物體)下,這是為了使得這個傳感器的中心不要放在智能體上,這樣就能訓練出一個只能探測到180度范圍的傳感器,現在我們來看看Grid Sensor,
Grid Sensor使用一組網格形狀的框查詢作為觀察,
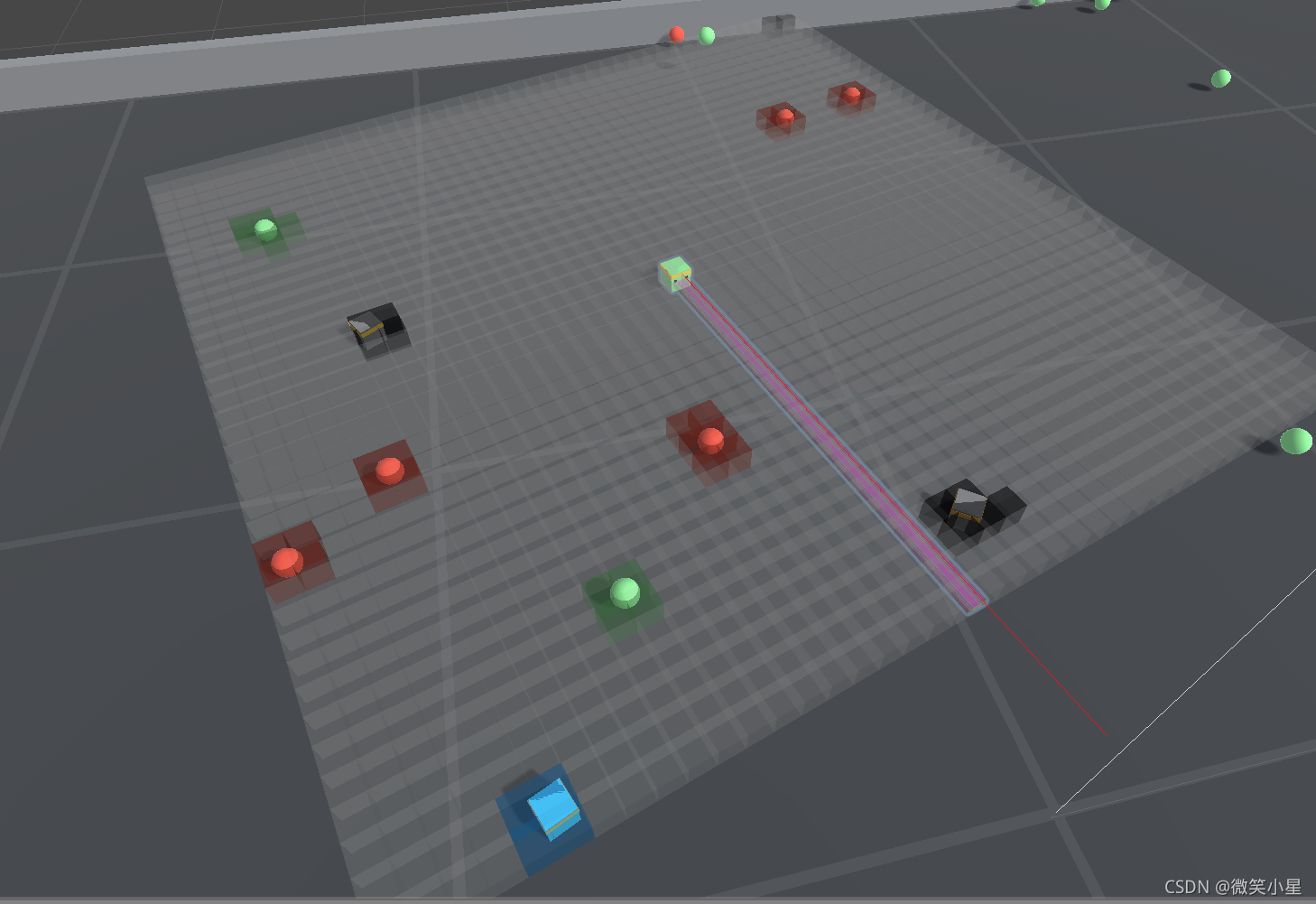
基于網格的觀測結合了視覺觀測中二維空間表示的優勢和RayCast 觀測中定義可檢測物件的靈活性,傳感器使用一組網格形狀的框查詢,并提供圍繞智能體的自上而下的 2D 視圖,
在觀察程序中,傳感器檢測每個單元格中可檢測物體的存在,并將其編碼為 one-hot 表示,從每個單元收集的資訊形成一個 3D 張量觀察,并將像視覺觀察一樣饋入代理策略的卷積神經網路 (CNN),對應標簽的物體只要于網格發生碰撞,這個網格就會打上相應的標簽,
因此,在平面2D的觀察下,輸入的維度就是網格的數量乘以標簽數,也就是20 * 20 * 6 = 2400維的輸入,
其中的引數屬性如下:
- Cell Scale表示網格中每個單元格的比例,
- Grid Size表示每一側的單元格數,
- Agent Game Object表示搭載該組件的智能體物體,便于把自己從檢測范圍排除,
- Rotate With Agent決定了網格是否隨著智能體而轉動,在相對變化較小的環境可以固定網格達到更好的訓練效果,
- Detectable Tags是一個標簽的串列,可以填上我們需要檢測到的物體的標簽,
- Collider Mask決定了檢測碰撞的層級(layer),決定了哪些層的物體是能夠檢測的,
- Compression Type:壓縮型別,可以選擇PNG或者不壓縮,
- Initial Collider Buffer Size在每個單元的非分配物理呼叫中使用的碰撞器經驗池的初始大小,
- Max Collider Buffer Size在每個單元的非分配物理呼叫中使用的碰撞器經驗池的最大大小,
- Show Gizmos可以可視化傳感器的具體效果,
- Gizmo Y offset:Gizmo在Y軸上的偏移量,
- Debug Colors:檢測到物體后回應的格子標注的顏色,
可檢測的標簽的數量和網格的數量要盡可能小,以減少資料量,這需要在觀察精度和訓練速度直接權衡,
注意:這個組件只使用3D環境,2D環境下無法運行,
智能體腳本
初始化:
void Awake()
{
m_PushBlockSettings = FindObjectOfType<PushBlockSettings>();
}
public override void Initialize()
{
m_AgentRb = GetComponent<Rigidbody>();
}
動作執行(和單智能體一樣):
public void MoveAgent(ActionSegment<int> act)
{
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
var action = act[0];
switch (action)
{
case 1:
dirToGo = transform.forward * 1f;
break;
case 2:
dirToGo = transform.forward * -1f;
break;
case 3:
rotateDir = transform.up * 1f;
break;
case 4:
rotateDir = transform.up * -1f;
break;
case 5:
dirToGo = transform.right * -0.75f;
break;
case 6:
dirToGo = transform.right * 0.75f;
break;
}
transform.Rotate(rotateDir, Time.fixedDeltaTime * 200f);
m_AgentRb.AddForce(dirToGo * m_PushBlockSettings.agentRunSpeed,
ForceMode.VelocityChange);
}
public override void OnActionReceived(ActionBuffers actionBuffers)
{
MoveAgent(actionBuffers.DiscreteActions);
}
人工操作(和單智能體一樣):
public override void Heuristic(in ActionBuffers actionsOut)
{
var discreteActionsOut = actionsOut.DiscreteActions;
if (Input.GetKey(KeyCode.D))
{
discreteActionsOut[0] = 3;
}
else if (Input.GetKey(KeyCode.W))
{
discreteActionsOut[0] = 1;
}
else if (Input.GetKey(KeyCode.A))
{
discreteActionsOut[0] = 4;
}
else if (Input.GetKey(KeyCode.S))
{
discreteActionsOut[0] = 2;
}
}
掛載在物塊上的腳本:
public class GoalDetectTrigger : MonoBehaviour
{
[Header("Trigger Collider Tag To Detect")]
public string tagToDetect = "goal"; //collider tag to detect
[Header("Goal Value")]
public float GoalValue = 1;
private Collider m_col;
// 繼承了一個泛型事件
[System.Serializable]
public class TriggerEvent : UnityEvent<Collider, float>
{
}
// 實體化了三個事件,訂閱事件要到Unity編輯器中
[Header("Trigger Callbacks")]
public TriggerEvent onTriggerEnterEvent = new TriggerEvent();
public TriggerEvent onTriggerStayEvent = new TriggerEvent();
public TriggerEvent onTriggerExitEvent = new TriggerEvent();
private void OnTriggerEnter(Collider col)
{
if (col.CompareTag(tagToDetect))
{
onTriggerEnterEvent.Invoke(m_col, GoalValue);
}
}
private void OnTriggerStay(Collider col)
{
if (col.CompareTag(tagToDetect))
{
onTriggerStayEvent.Invoke(m_col, GoalValue);
}
}
private void OnTriggerExit(Collider col)
{
if (col.CompareTag(tagToDetect))
{
onTriggerExitEvent.Invoke(m_col, GoalValue);
}
}
// Start is called before the first frame update
void Awake()
{
m_col = GetComponent<Collider>();
}
}
事件是一種方便呼叫其他腳本函式的方法,訂閱事件:
訂閱事件對應的方法,位于環境腳本中(下面會講):
public void ScoredAGoal(Collider col, float score)
{
print($"Scored {score} on {gameObject.name}");
// 場上剩余物體計數
m_NumberOfRemainingBlocks--;
// 是否結束游戲
bool done = m_NumberOfRemainingBlocks == 0;
// 把物體暫時從場景中洗掉
col.gameObject.SetActive(false);
// 添加集體獎勵
m_AgentGroup.AddGroupReward(score);
// Swap ground material for a bit to indicate we scored.
StartCoroutine(GoalScoredSwapGroundMaterial(m_PushBlockSettings.goalScoredMaterial, 0.5f));
if (done)
{
//重新開始一輪游戲
m_AgentGroup.EndGroupEpisode();
ResetScene();
}
}
注意了,多智能體的不同點顯現出來了,添加獎勵使用的是AddGroupReward函式添加的是集體獎勵
環境控制腳本
這個腳本掛載在空物體上運行,智能體作為子物體,
using System.Collections;
using System.Collections.Generic;
using Unity.MLAgents;
using UnityEngine;
public class PushBlockEnvController : MonoBehaviour
{
// 智能體資訊類
[System.Serializable]
public class PlayerInfo
{
public PushAgentCollab Agent;
[HideInInspector]
public Vector3 StartingPos;
[HideInInspector]
public Quaternion StartingRot;
[HideInInspector]
public Rigidbody Rb;
}
// 物塊資訊類
[System.Serializable]
public class BlockInfo
{
public Transform T;
[HideInInspector]
public Vector3 StartingPos;
[HideInInspector]
public Quaternion StartingRot;
[HideInInspector]
public Rigidbody Rb;
}
[Header("Max Environment Steps")] public int MaxEnvironmentSteps = 25000;
// 區域邊界
[HideInInspector]
public Bounds areaBounds;
public GameObject ground;
public GameObject area;
Material m_GroundMaterial; //cached on Awake()
Renderer m_GroundRenderer;
// 智能體資訊的串列
public List<PlayerInfo> AgentsList = new List<PlayerInfo>();
// 物塊資訊的串列
public List<BlockInfo> BlocksList = new List<BlockInfo>();
public bool UseRandomAgentRotation = true;
public bool UseRandomAgentPosition = true;
public bool UseRandomBlockRotation = true;
public bool UseRandomBlockPosition = true;
private PushBlockSettings m_PushBlockSettings;
private int m_NumberOfRemainingBlocks;
// 注意了,這是一個多智能體類
private SimpleMultiAgentGroup m_AgentGroup;
private int m_ResetTimer;
void Start()
{
// Get the ground's bounds
areaBounds = ground.GetComponent<Collider>().bounds;
// Get the ground renderer so we can change the material when a goal is scored
m_GroundRenderer = ground.GetComponent<Renderer>();
// Starting material
m_GroundMaterial = m_GroundRenderer.material;
m_PushBlockSettings = FindObjectOfType<PushBlockSettings>();
// Initialize Blocks
foreach (var item in BlocksList)
{
item.StartingPos = item.T.transform.position;
item.StartingRot = item.T.transform.rotation;
item.Rb = item.T.GetComponent<Rigidbody>();
}
// Initialize TeamManager
m_AgentGroup = new SimpleMultiAgentGroup();
foreach (var item in AgentsList)
{
item.StartingPos = item.Agent.transform.position;
item.StartingRot = item.Agent.transform.rotation;
item.Rb = item.Agent.GetComponent<Rigidbody>();
// 把單智能體都添加到多智能體中
m_AgentGroup.RegisterAgent(item.Agent);
}
ResetScene();
}
void FixedUpdate()
{
m_ResetTimer += 1;
// 到時間了并到達最大訓練步數就結束訓練
if (m_ResetTimer >= MaxEnvironmentSteps && MaxEnvironmentSteps > 0)
{
m_AgentGroup.GroupEpisodeInterrupted();
ResetScene();
}
// 存在懲罰
m_AgentGroup.AddGroupReward(-0.5f / MaxEnvironmentSteps);
}
//回傳在場地內沒物體的位置,同單智能體
public Vector3 GetRandomSpawnPos()
{
var foundNewSpawnLocation = false;
var randomSpawnPos = Vector3.zero;
while (foundNewSpawnLocation == false)
{
var randomPosX = Random.Range(-areaBounds.extents.x * m_PushBlockSettings.spawnAreaMarginMultiplier,
areaBounds.extents.x * m_PushBlockSettings.spawnAreaMarginMultiplier);
var randomPosZ = Random.Range(-areaBounds.extents.z * m_PushBlockSettings.spawnAreaMarginMultiplier,
areaBounds.extents.z * m_PushBlockSettings.spawnAreaMarginMultiplier);
randomSpawnPos = ground.transform.position + new Vector3(randomPosX, 1f, randomPosZ);
if (Physics.CheckBox(randomSpawnPos, new Vector3(1.5f, 0.01f, 1.5f)) == false)
{
foundNewSpawnLocation = true;
}
}
return randomSpawnPos;
}
// 重置物塊
void ResetBlock(BlockInfo block)
{
block.T.position = GetRandomSpawnPos();
block.Rb.velocity = Vector3.zero;
block.Rb.angularVelocity = Vector3.zero;
}
// 攜程,任務完成時短暫切換地面材質
IEnumerator GoalScoredSwapGroundMaterial(Material mat, float time)
{
m_GroundRenderer.material = mat;
yield return new WaitForSeconds(time); // Wait for 2 sec
m_GroundRenderer.material = m_GroundMaterial;
}
// 當物塊觸碰到目標時,被物塊腳本中的事件呼叫,上面已經解釋過
public void ScoredAGoal(Collider col, float score)
{
print($"Scored {score} on {gameObject.name}");
m_NumberOfRemainingBlocks--;
bool done = m_NumberOfRemainingBlocks == 0;
col.gameObject.SetActive(false);
m_AgentGroup.AddGroupReward(score);
StartCoroutine(GoalScoredSwapGroundMaterial(m_PushBlockSettings.goalScoredMaterial, 0.5f));
if (done)
{
m_AgentGroup.EndGroupEpisode();
ResetScene();
}
}
// 回傳任意的旋轉四元數
Quaternion GetRandomRot()
{
return Quaternion.Euler(0, Random.Range(0.0f, 360.0f), 0);
}
// 重置場景
public void ResetScene()
{
m_ResetTimer = 0;
// 場景四個角度任意旋轉
var rotation = Random.Range(0, 4);
var rotationAngle = rotation * 90f;
area.transform.Rotate(new Vector3(0f, rotationAngle, 0f));
// 重置智能體們
foreach (var item in AgentsList)
{
var pos = UseRandomAgentPosition ? GetRandomSpawnPos() : item.StartingPos;
var rot = UseRandomAgentRotation ? GetRandomRot() : item.StartingRot;
item.Agent.transform.SetPositionAndRotation(pos, rot);
item.Rb.velocity = Vector3.zero;
item.Rb.angularVelocity = Vector3.zero;
}
// 重置物塊們
foreach (var item in BlocksList)
{
var pos = UseRandomBlockPosition ? GetRandomSpawnPos() : item.StartingPos;
var rot = UseRandomBlockRotation ? GetRandomRot() : item.StartingRot;
item.T.transform.SetPositionAndRotation(pos, rot);
item.Rb.velocity = Vector3.zero;
item.Rb.angularVelocity = Vector3.zero;
item.T.gameObject.SetActive(true);
}
// 重置物塊計數
m_NumberOfRemainingBlocks = BlocksList.Count;
}
}
多智能體訓練注意事項
ML-Agents 中的協作行為可以通過實體化來啟用SimpleMultiAgentGroup,通常在環境控制器或類似腳本中,并使用該RegisterAgent方法向其中添加智能體,請注意,添加到同一個的所有智能體SimpleMultiAgentGroup 必須在Behavior Parameters中具有相同的Behavior Name和引數,使用SimpleMultiAgentGroup使組內的智能體能夠學習實作共同目標(最大化團體獎勵),即使一個或多個組成員在episode結束之前被移除,也同樣可以添加團體獎勵,可以使用AddGroupReward(),`SetGroupReward(),EndGroupEpisode(),和 GroupEpisodeInterrupted()方法,
這種多智能體的用法要與MA-POCA演算法一起使用,
- 一個智能體一次只能注冊到一個 MultiAgentGroup,如果要將智能體從一個組重新分配到另一個組,則必須先將其從當前組中取消注冊,
- 不支持同一組中具有不同行為名稱的智能體,
- 組內的智能體應始終將
Max Steps智能體腳本中的引數設定為 0,通過使用GroupEpisodeInterrupted() 結束整個組的episode, EndGroupEpisode并GroupEpisodeInterrupted在游戲中做同樣的作業,但對訓練的影響略有不同,如果該episode已完成,您將需要使用EndGroupEpisode,但是如果episode還沒有結束但它已經運行了足夠多的步數,即達到最大步數,會呼叫GroupEpisodeInterrupted.- 如果智能體提前完成,例如已完成的任務/在游戲中被移除/被殺死,請不要呼叫
EndEpisode()代理,應該禁用智能體并在下一個episode開始時重新啟用它,或者完全銷毀智能體,這是因為呼叫EndEpisode()會呼叫OnEpisodeBegin(),這將立即重置智能體,雖然可以通過EndEpisode()這種方式呼叫,但不推薦, - 如果需要重新啟用在場景中禁用的智能體,則必須將其重新注冊到 MultiAgentGroup,
- 群體獎勵旨在加強智能體按照群體而非個人的最佳利益行事,并且在訓練期間的處理方式與個體智能體獎勵不同,所以呼叫
AddGroupReward()不等同于對組中的每個智能體呼叫agent.AddReward(), - 我們仍然可以使用Agent.AddReward()對在一個組中的智能體添加獎勵,這個作為個人的獎勵,智能體激活時才能收到,
- 使用多智能體的環境可以使用 PPO 或 SAC 進行訓練,但智能體將無法在停用/洗掉后從組獎勵中學習,也不會有合作的表現,
組態檔
在配置上,MA-POCA演算法和PPO演算法的配置引數一致,
behaviors:
PushBlockCollab:
trainer_type: poca
hyperparameters:
batch_size: 1024
buffer_size: 10240
learning_rate: 0.0003
beta: 0.01
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: false
hidden_units: 256
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 15000000
time_horizon: 64
summary_freq: 60000
個人改進想法
- 物塊上可以加上一個物理材質,靜摩擦力設定到合理水平,防止一個人就能稍微推動大的方塊,
- 可以加上個人獎勵,方塊到達終點時出力最多的加更多的分數,
- 把稀疏獎勵變得稠密,把方塊和終點的距離作為獎勵之一,同時只有推動方塊的人才能獲得個人獎勵,
- 網格感知器有不合理的地方,第一是穿墻,能夠無障礙物觀察,第二是現在不能觀察到背后的資訊,建議改為在智能體近距離的周圍采用網格感知,遠距離的前方采用射線感知,
- 三個智能體訓練出來的是同一個神經網路,能否訓練三個不同的神經網路滿足不同的作業要求?
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355489.html
標籤:其他
上一篇:寫在程式員節(1024)來到之際