在學習Hadoop時,我發現網上的各種安裝的資料要不不全,要不前后不匹配(比如有的是偽分布式,有的是完全分布式),此篇文章,我總結了身邊的同學在安裝Hadoop時遇到的毛病,在前面安裝配置環節,盡可能使用最優化的處理方式,以便于我們后續hbase的安裝和使用,
前言:我所使用的Hadoop版本為Hadoop 2.10.1,jdk版本為jdk1.8.0_112, hbase版本為hbase2.3.3,在版本選擇時,你們可以選擇與我不同的版本,但記得一定要考慮版本的兼容性,說不多說,我們開始進行Hadoop單機偽分布安裝吧!
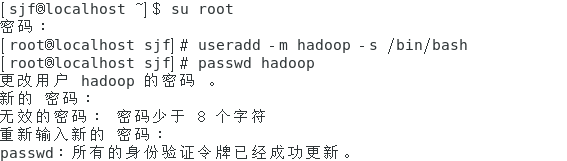
一、創建Hadoop用戶并設定密碼
[用戶名@localhost ~] $ su root
[root@localhost 用戶名] # useradd –m hadoop –s /bin/bash
[root@localhost 用戶名] # passwd hadoop
二、安裝jdk
(1) 查看jdk版本
[root@localhost 用戶名] # rpm –qa | grep jdk

(2)洗掉原先自帶的jdk
[root@localhost 用戶名] # rpm –qa | grep –i java | xargs -n1 rpm -e --nodeps
[root@localhost 用戶名] # rpm –qa | grep –i java
[root@localhost 用戶名] # reboot

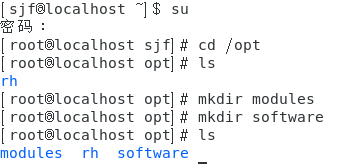
(3)在/opt目錄下分別新建modules和software目錄,
建兩個檔案夾的原因是:software檔案夾存放要解壓的檔案,modules檔案夾存放解壓之后的檔案,
[root@localhost 用戶名] # cd /opt
[root@localhost opt] # mkdir modules
[root@localhost opt] # mkdir software
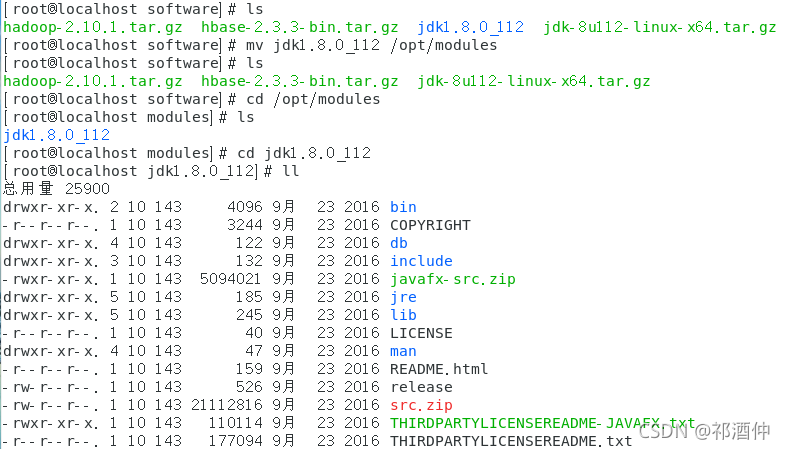
(4)將要用到的壓縮包移到/opt/software檔案夾下,解壓縮jdk,并移動到modules目錄下
[root@localhost software] # tar –zxvf jdk-8u112-linux –x64.tar.gz


查看一下jdk解壓之后的版本,并將其移動到/opt/modules檔案夾里
[root@localhost software] # mv jdk1.8.0_112 /opt/modules
(5)配置Java環境變數
[root@localhost modules] # vi /etc/profile
#要增加的內容:
export JAVA_HOME=/opt/modules/jdk1.8.0_112
export PATH=$JAVA_HOME/bin:$PATH

[root@localhost modules] # cat /etc/profile
#添加了JAVA_HOME和PATH路徑,用cat命令查看檔案內容修改成功,


用source命令在當前bash環境下讀取并執行/etc/profille中的命令,用java-version檢查環境變數配置成功,
[root@localhost modules] # source /etc/profile
[root@localhost modules] # java -version

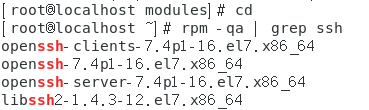
三、安裝配置SSH
(1) 檢查SSH是否安裝
[root@localhost ~] # rpm -qa| grep ssh
 (2) 修改sshd組態檔
(2) 修改sshd組態檔
[root@localhost ~] # vim /etc/ssh/sshd_config

以下圖片是需要修改的地方

(3) 重啟sshd服務
[root@localhost ~] # service sshd restart

(4) 生成公鑰和私鑰
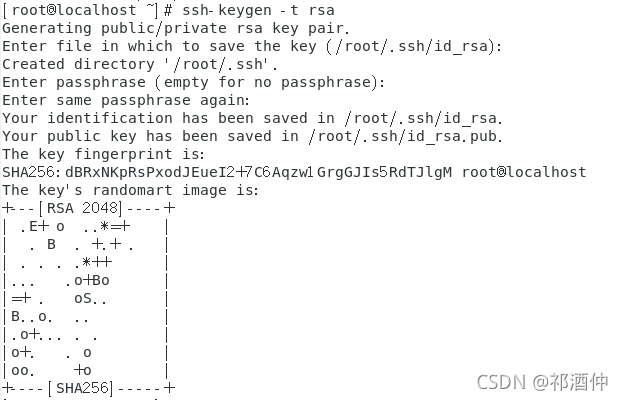
[root@localhost ~] # ssh-keygen -t rsa
[root@localhost ~] # cd .ssh
[root@localhost .ssh] # ls
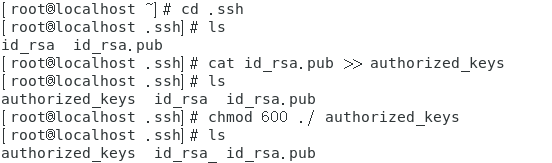
 生成authorized_keys并查看
生成authorized_keys并查看
[root@localhost .ssh]# cat id_rsa.pub >> authorized_keys
修改密鑰檔案的相應權限
[root@localhost .ssh]# chmod 600 ./ authorized_keys
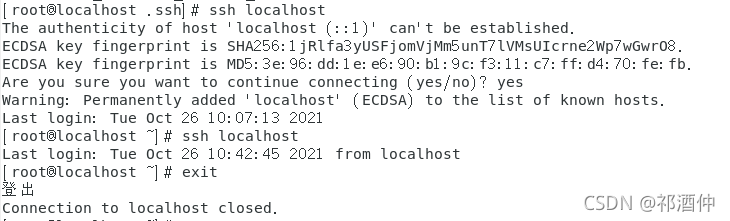
(5) 使用ssh localhost登錄,測驗是否可以免密登錄
[root@localhost .ssh]# ssh localhost (第一次免密登錄,看是否成功)
[root@localhost .ssh]# ssh localhost (第二次免密登錄,測驗是否穩定)
[root@localhost .ssh]# exit (退出)
 四、安裝hadoop
四、安裝hadoop
(1)在software里解壓Hadoop
[root@localhost ~]# cd /opt/software
[root@localhost software]# ls
[root@localhost software]# tar zxvf hadoop-2.10.1.tar.gz

解壓之后的檔案重命名為hadoop,以便于后續使用
[root@localhost software]# ls (查看解壓之后的結果)
[root@localhost software]# mv hadoop 2.10.1 hadoop (解壓包重命名為hadoop)
[root@localhost software]# mv hadoop /opt/modules (將hadoop移動到modules檔案夾內)
 (2)為Hadoop用戶賦予hadoop檔案夾的權限
(2)為Hadoop用戶賦予hadoop檔案夾的權限
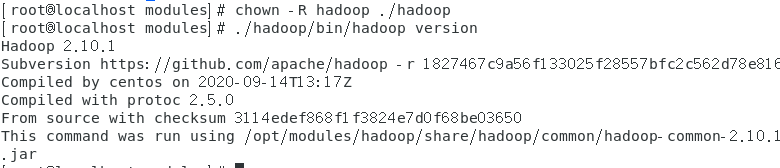
[root@localhost modules]# chown –R hadoop ./hadoop
(3) 查看hadoop版本資訊
[root@localhost modules]# ./hadoop/bin/hadoop version
五、Hadoop的偽分布式安裝
(1)切換用戶到hadoop用戶,編輯~/.bashrc檔案
[root@localhost modules]# su hadoop
[hadoop@localhost modules]$ vim ~/.bashrc

#要增加的內容:
export HADOOP_HOME=/opt/modules/hadoop
export HADOO_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export JAVA_HOME=/opt/modules/jdk1.8.0_112

Source命令使檔案配置生效,
[hadoop@localhost modules]$ source ~/.bashrc
 (2)修改core-site.xml和hdfs-site.xml組態檔
(2)修改core-site.xml和hdfs-site.xml組態檔

[hadoop@localhost hadoop]$ vim ./etc/hadoop/core-site.xml
#要增加的內容:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
 >[hadoop@localhost hadoop]$ vim ./etc/hadoop/hdfs-site.xml
>[hadoop@localhost hadoop]$ vim ./etc/hadoop/hdfs-site.xml
#要增加的內容:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/modules/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/modules/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
 (3)格式化namenode
(3)格式化namenode
[hadoop@localhost hadoop]$ ./bin/hdfs namenode -format


(4) 配置hadoop用戶下的免密登錄
1、 在Hadoop用戶下重啟sshd服務
[hadoop@localhost hadoop]$ service sshd restart

2、 生成公鑰和私鑰
[hadoop@localhost hadoop]$ ssh –keygen -t rsa
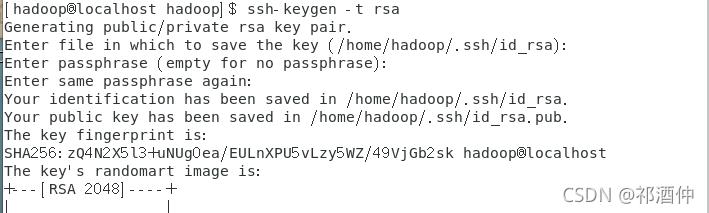
3、生成authorized_keys并查看
[hadoop@localhost hadoop]$ cat id_rsa.pub >> authorized_keys
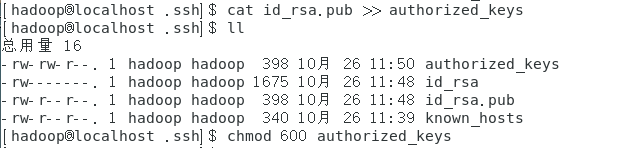
4、修改密鑰檔案的相應權限
[hadoop@localhost hadoop]$ chmod 600 ./ authorized_keys

此時Hadoop用戶就可以實作免密登錄了
(5)啟動hadoop
[hadoop@localhost hadoop]$ ./sbin/start-dfs.sh

關閉Hadoop
[hadoop@localhost hadoop]$ ./sbin/stop-dfs.sh

Hadoop單機偽分布式安裝就這樣完成了,安裝成功的你是不是成就滿滿呢,如果這篇文章對你有幫助的話,歡迎一鍵三連,我們一起進步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/355509.html
標籤:其他