環境:opencv_python==4.2.0.34 pytorch==1.9.0
YOLO Fastest系列是輕量級目標檢測網路,目前yolo系列最輕最快,適合全平臺通用,也可以搭載在嵌入式端做到實時識別 效果
1、準備作業
下載原始碼:GitHub上YOLO FastestV2原始碼
使用前建議先看下REAMDE.md中的說明
配置環境:
pip install -r requirements.txt測驗是否配置成功
python test.py --data data/coco.data --weights modelzoo/coco2017-0.241078ap-model.pth --img img/000139.jpg運行成功后 ,會生成圖片test_result.png
2、資料集準備:
運行以下代碼,會在當前目錄新建train和val檔案夾,資料集分割成訓練集和驗證集,分別放入兩個檔案夾中,并建立train.txt和val.txt檔案
import os
import random
import shutil
image_Path=r'C:\Users\User\Desktop\marked\data' #資料集路徑
val_num=20 #驗證集資料量
folder_txt_dir = ["train","val"]
def Creating_folder(folder_txt_dir):
'創建train和val檔案夾'
for foler in folder_txt_dir:
data_path =os.path.join(str(os.getcwd()),foler)
folder = os.path.exists(data_path)
if not folder:
os.makedirs(data_path)
print('創建train和val檔案夾成功')
def Split_datasets(paths):
'索引所有圖片'
images=[]
train_num_list=[]
val_num_list=[]
for path,folder,imgs in os.walk(paths):
for img in imgs:
if img.endswith(".jpg"):
images.append(os.path.join(path,img))
'分割資料集'
alist = random.sample(range(0,len(images)),val_num)
alist.sort(reverse=True)
for n in alist:
val_num_list.append(images[n])
images.pop(n)
train_num_list=images
'移動圖片'
train_path=os.path.join(str(os.getcwd()),'train')
val_path=os.path.join(str(os.getcwd()),'val')
for train in train_num_list:
fpath,fname=os.path.split(train)
shutil.copy(train, os.path.join(train_path,fname))
for val in val_num_list:
fpath,fname=os.path.split(val)
shutil.copy(val, os.path.join(val_path,fname))
print('分割資料集成功')
def make_txt(folder_txt_dir):
'創建train.txt和val.txt'
for txt in folder_txt_dir:
data_path =os.path.join(str(os.getcwd()),txt)
image_list=os.listdir(txt)
with open(file=txt+'.txt',mode='a+') as f:
for name in image_list:
if name.endswith(".jpg"):
item=os.path.join(data_path,name)
f.write(item)
f.write("\n")
print('創建train.txt和val.txt成功')
if __name__ =='__main__':
Creating_folder(folder_txt_dir)
Split_datasets(image_Path)
make_txt(folder_txt_dir)然后新建class.txt,寫入物體類別(一行寫一個)
標注資料集:
在Make Sense上進行標志資料集,點擊Get Started,然后點擊Click here to select them,選擇分割好的train或者val檔案夾,選中里面所有圖片,然后點擊Object Detection,點擊Load labels from file,點擊Click here to select them,選擇剛才建立好的class.txt檔案
標注圖片時注意下對應標簽,標注結束點擊Actions,點擊Export Annotations下載標志檔案,將里面的圖片.txt檔案復制到train或者val檔案夾下,
然后將class.txt改為class.namse
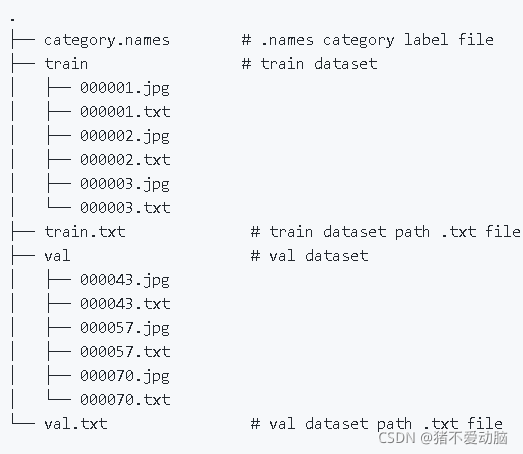
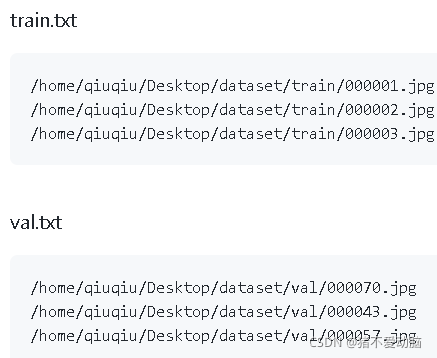
按照REAMDE.md上的描述,我可以得到如下目錄結構

3、訓練配置
生成錨點:
python genanchors.py --traintxt ./train.txt
--traintxt是上一步中生成的train.txt路徑,運行后會生成anchors6.txt
配置訓練檔案:
在data檔案夾中可以看到coco.data,我們可以仿照這個檔案,新建mytrain.data,復制coco.data的內容到里面
[name]
model_name=coco # model name
[train-configure]
epochs=300 # train epichs
steps=150,250 # Declining learning rate steps
batch_size=64 # batch size
subdivisions=1 # Same as the subdivisions of the darknet cfg file
learning_rate=0.001 # learning rate
[model-configure]
pre_weights=None # The path to load the model, if it is none, then restart the training
classes=80 # Number of detection categories
width=352 # The width of the model input image
height=352 # The height of the model input image
anchor_num=3 # anchor num
anchors=12.64,19.39, 37.88,51.48, 55.71,138.31, 126.91,78.23, 131.57,214.55, 279.92,258.87 #anchor bias
[data-configure]
train=/media/qiuqiu/D/coco/train2017.txt # train dataset path .txt file
val=/media/qiuqiu/D/coco/val2017.txt # val dataset path .txt file
names=./data/coco.names # .names category label file
注意修改里面的anchors的值,為上一步anchors6.txt的內容,另外還有model_name和classes的值以及data-configure里面的路徑,其他根據自己的需求修改即可,
4、訓練模型
python train.py --data data/mytrain.data
--data為上一步建立的組態檔路徑
如果是CPU訓練,可能會爆記憶體,關掉一些后臺,重新運行即可,正常運行如下圖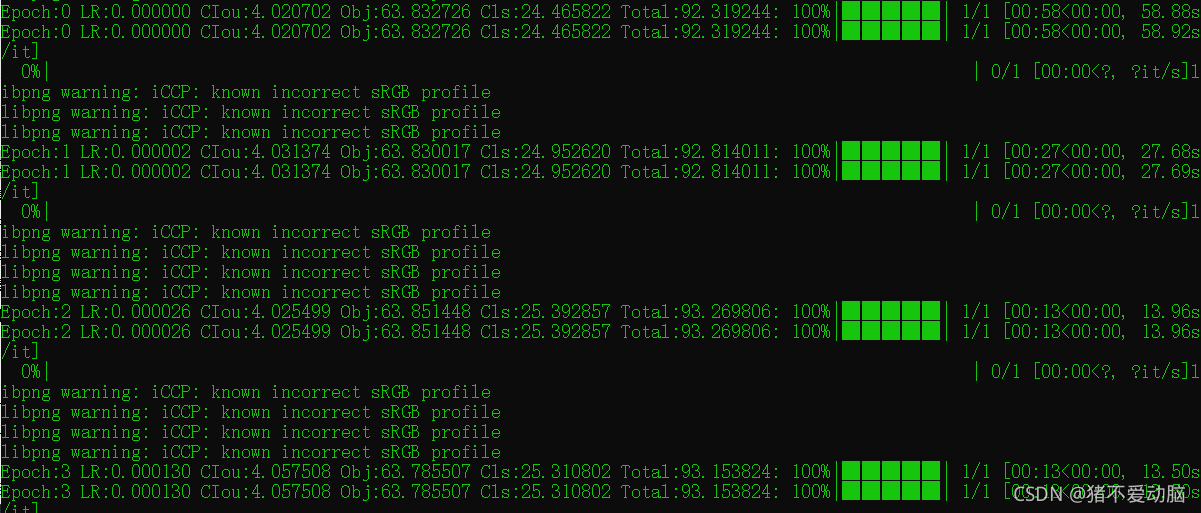
運行結束后,可以在weights檔案下看到生成的.pth檔案,我們使用最大一步的檔案即可
5、模型評估
python evaluation.py --data data/mytrain.data --weights weights/mytrain-300-epoch-0.793847ap-model.pth
--weights這個直接指向weights檔案夾中最大一步的.pth檔案即可
![]()
6、使用模型進行檢測
也是使用test.py檔案
--data指向組態檔mytrain.data --weights指向weights檔案夾中最大一步的.pth檔案 --img指向想要檢測圖片路徑,運行后也是生成test_result.png,也可以根據自己需求進行修改test.py檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356203.html
標籤:其他