引言
?元學習( m e t a \mathrm{meta} meta- l e a r n i n g \mathrm{learning} learning)是過去幾年最火爆的學習方法之一,各式各樣的 p a p e r \mathrm{paper} paper都是基于元學習展開的,深度學習模型訓練模型特別吃計算硬體,尤其是人為調超引數時候,更需要大量的計算,另一個頭疼的問題是在某個任務下大量資料訓練的模型,切換到另一個任務后,模型就需要重新訓練,這樣非常耗時耗力,工業界財大氣粗有大量的GPU可以承擔起這樣的計算成本,但是學術界因為經費有限經不起這樣的消耗,元學習可以有效的緩解大量調參和任務切換模型重新訓練帶來的計算成本問題,
元學習介紹
?元學習希望使得模型獲取一種學會學習調參的能力,使其可以在獲取已有知識的基礎上快速學習新的任務,機器學習是先人為調參,之后直接訓練特定任務下深度模型,元學習則是先通過其它的任務訓練出一個較好的超引數,然后再對特定任務進行訓練,
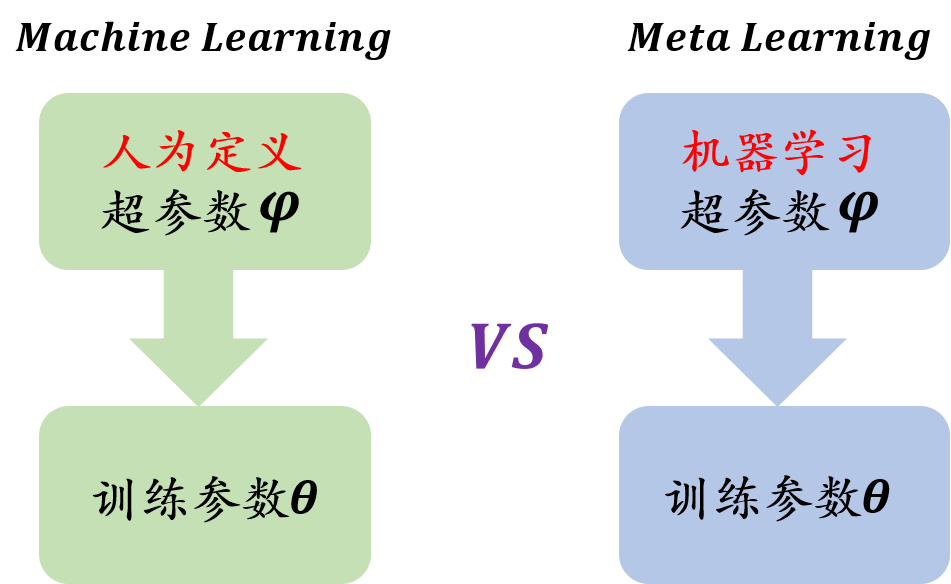
?在機器學習中,訓練單位是樣本資料,通過資料來對模型進行優化;資料可以分為訓練集、測驗集和驗證集,在元學習中,訓練單位是任務,一般有兩個任務分別是訓練任務( T r a i n T a s k s \mathrm{Train\text{ }Tasks} Train Tasks)亦稱跨任務( A c r o s s T a s k s \mathrm{Across\text{ }Tasks} Across Tasks)和測驗任務( T e s t T a s k \mathrm{Test\text{ }Task} Test Task)亦稱單任務( W i t h i n T a s k \mathrm{Within\text{ }Task} Within Task),訓練任務要準備許多子任務來進行學習,目的是學習出一個較好的超引數,測驗任務是利用訓練任務學習出的超引數對特定任務進行訓練,訓練任務中的每個任務的資料分為 S u p p o r t s e t \mathrm{Support\text{ }set} Support set和 Q u e r y s e t \mathrm{Query\text{ }set} Query set; T e s t T a s k \mathrm{Test\text{ }Task} Test Task中資料分為訓練集和測驗集,
?令
φ
\varphi
φ表示需要設定的超引數,
θ
\theta
θ表示神經網路待訓練的引數,元學習的目的就是讓函式
F
φ
,
θ
F_{\varphi,\theta}
Fφ,θ?在訓練任務中自動訓練出
φ
?
\varphi^{*}
φ?,再利用
φ
?
\varphi^{*}
φ?這個先驗知識在測驗任務中訓練出特定任務下模型
f
θ
f_\theta
fθ?中的引數
θ
\theta
θ,如下所示的依賴關系:
F
φ
,
θ
?
T
r
a
i
n
T
a
s
k
s
(
F
φ
?
,
θ
?
f
θ
)
?
T
e
s
t
T
a
s
k
(
F
φ
?
,
θ
?
?
f
θ
?
)
F_{\varphi,\theta} \xmapsto{\mathrm{Train\text{ }Tasks}}(F_{\varphi^{*},\theta}\Leftrightarrow{} f_{\theta}) \xmapsto{\mathrm{Test\text{ }Task}}(F_{\varphi^{*},\theta^*}\Leftrightarrow{}f_{\theta^*})
Fφ,θ?Train Tasks
?(Fφ?,θ??fθ?)Test Task
?(Fφ?,θ???fθ??)當訓練一個神經網路的時候,具體一般步驟有,預處理資料集
D
D
D,選擇網路結構
N
N
N,設定超引數
γ
\gamma
γ,初始化引數
θ
0
\theta_0
θ0?,選擇優化器
O
O
O,定義損失函式
L
L
L,梯度下降更新引數
θ
\theta
θ,具體步驟如下圖所示
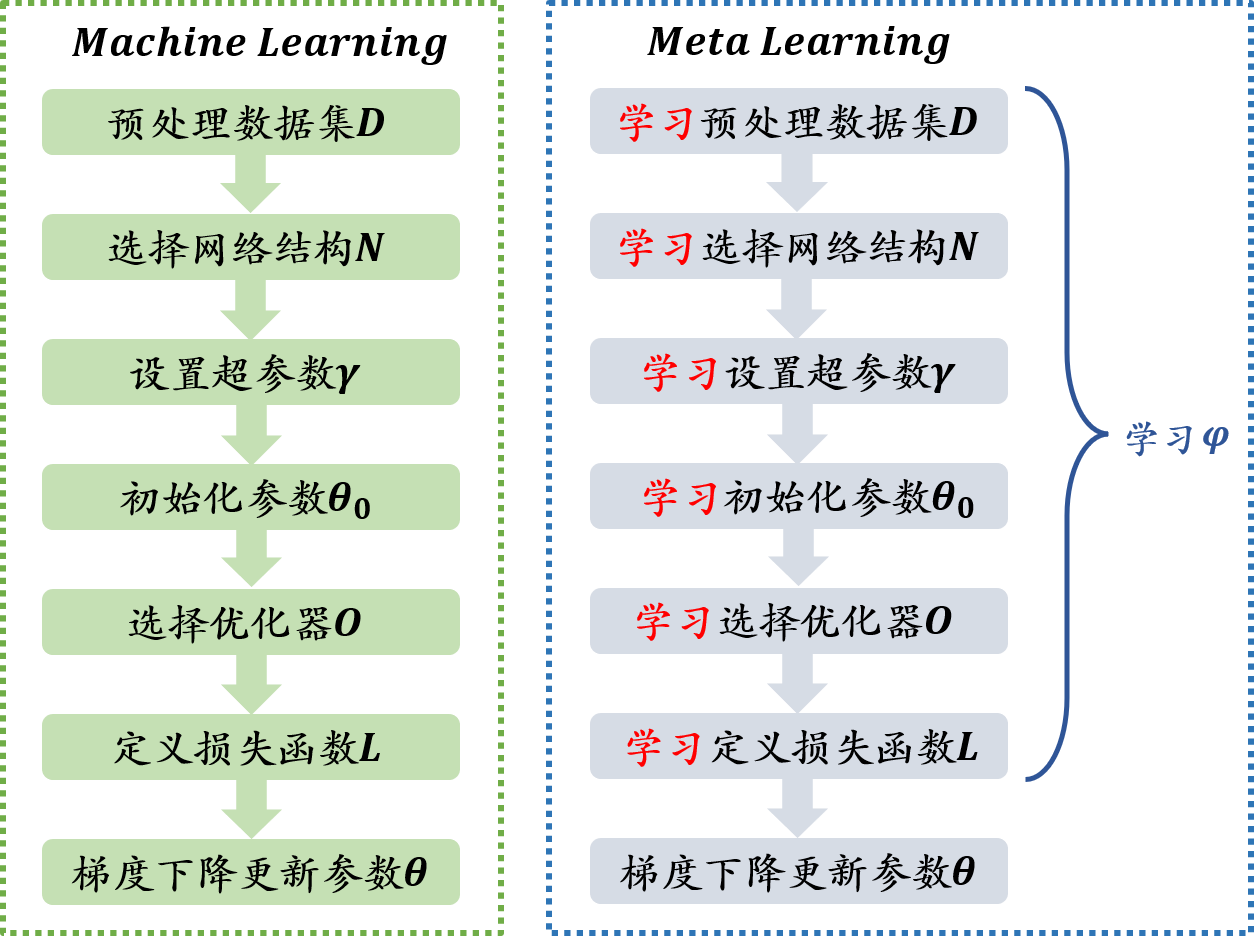
元學習會去學習所有需要由人去設定和定義的引數變數
φ
\varphi
φ,在這里引數變數
φ
\varphi
φ屬于集合為
Φ
\Phi
Φ,則有
φ
∈
Φ
=
{
D
,
N
,
γ
,
θ
0
,
O
,
L
}
\varphi\in \Phi=\{D,N,\gamma,\theta_0,O,L\}
φ∈Φ={D,N,γ,θ0?,O,L}不同的元學習,就要去學集合
Φ
\Phi
Φ中不同的元素,相應的就會有不同的研究領域,
-
學習預處理資料集 D D D:對資料進行預處理的時候,資料增強會增加模型的魯棒性,一般的資料增強方式比較死板,只是對影像進行旋轉,顏色變換,伸縮變換等,元學習可以自動地,多樣化地為資料進行增強,相關的代表作為 D A D A \mathrm{DADA} DADA,
論文名稱:DADA: Differentiable Automatic Data Augmentation
論文鏈接:https://arxiv.org/pdf/2003.03780v1.pdf
論文詳情:ECCV, 2020 -
學習初始化引數 θ 0 \theta_0 θ0?:權重引數初始化的好壞可以影響模型最后的分類性能,元學習可以通過學出一個較好的權重初始化引數有助于模型在新的任務上進行學習,元學習學習初始化引數的代表作是 M A M L \mathrm{MAML} MAML( M o d e l \mathrm{Model} Model- A g n o s t i c \mathrm{Agnostic} Agnostic- M e t a \mathrm{Meta} Meta- L e a r n i n g \mathrm{Learning} Learning),它專注于提升模型整體的學習能力,而不是解決某個具體問題的能力,訓練時,不停地在不同的任務上切換,從而達到初始化網路引數的目的,最終得到的模型,面對新的任務時可以學習得更快,
論文名稱:Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks
論文鏈接:https://arxiv.org/pdf/1703.03400.pdf
論文詳情:ICML, 2017 -
學習網路結構 N N N:神經網路的結構設定是一個很頭疼的問題,網路的深度是多少,每一層的寬度是多少,每一層的卷積核有多少個,每個卷積核的大小又該怎么定,需不需要 d r o p o u t \mathrm{dropout} dropout等等問題,到目前為止沒有一個定論或定理能夠清晰準確地回答出以上問題,所以神經網路結構搜索 N A S \mathrm{NAS} NAS運營而生,歸根結底,神經網路結構搜索其實是元學習地一個子類領域,值得注意的是,網路結構的探索不能通過梯度下降法來獲得,這是一個不可導問題,一般情況下會采用強化學習或進化演算法來解決,
論文名稱:Neural Architecture Search with Reinforcement Learning
論文鏈接:https://arxiv.org/abs/1611.01578
論文詳情:ICLR, 2017 -
學習選擇優化器 O O O:神經網路訓練的程序中很重要的一環就是優化器的選取,不同的優化器會對優化引數時對梯度的走向有很重要的影響,熟知的優化器有 A d a m \mathrm{Adam} Adam, R M s p r o p \mathrm{RMsprop} RMsprop, S G D \mathrm{SGD} SGD, N A G \mathrm{NAG} NAG等,元學習可以幫我們在訓練特定任務前選擇一個好的的優化器,其代表作有
論文名稱:Learning to learn by gradient descent by gradient descent
論文鏈接:https://arxiv.org/pdf/1606.04474.pdf
論文詳情:NIPS, 2016
元學習訓練
?元學習分為兩個階段,階段一是訓練任務訓練;階段二為測驗任務訓練,對應于一些論文的演算法流程圖,訓練任務是在 o u t e r l o o p \mathrm{outer \text{ } loop } outer loop里,測驗任務任務是在 i n n e r l o o p \mathrm{inner \text{ } loop } inner loop里,
階段一:訓練任務訓練
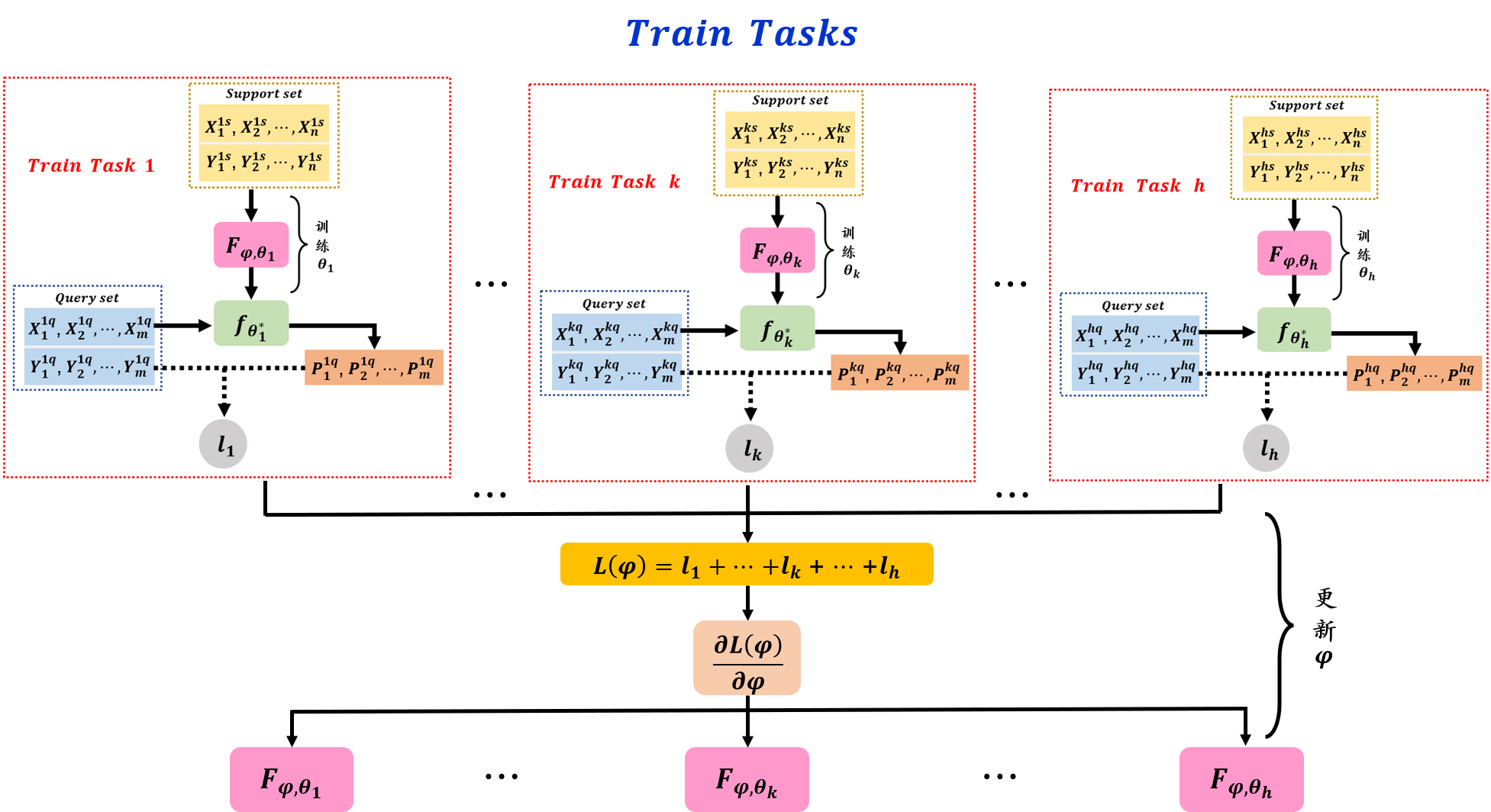
?在訓練任務中給定
h
h
h個子訓練任務,每個子訓練任務的資料集分為
S
u
p
p
o
r
t
s
e
t
\mathrm{Support\text{ }set}
Support set和
Q
u
e
r
y
s
e
t
\mathrm{Query\text{ }set}
Query set,首先通過這
h
h
h個子任務的
S
u
p
p
o
r
t
s
e
t
\mathrm{Support\text{ }set}
Support set訓練
F
φ
,
θ
F_{\varphi,\theta}
Fφ,θ?,分別訓練出針對各自子任務的模型引數
θ
i
?
(
1
≤
i
≤
h
)
\theta_i^{*}(1\le i \le h)
θi??(1≤i≤h),然后用不同子任務中的
Q
u
e
r
y
s
e
t
\mathrm{Query\text{ }set}
Query set分別去測驗
f
θ
i
?
f_{\theta_i^{*}}
fθi???的性能,并計算出預測值和真實標簽的損失
l
i
(
1
≤
i
≤
h
)
l_{i}(1\le i \le h)
li?(1≤i≤h),接著整合這
h
h
h個損失函式為
L
(
φ
)
L(\varphi)
L(φ):
L
(
φ
)
=
l
1
+
?
+
l
k
+
?
+
l
h
L(\varphi)=l_1+\cdots+l_k+\cdots+l_h
L(φ)=l1?+?+lk?+?+lh?最后利用梯度下降法去求出
?
L
(
φ
)
?
φ
\frac{\partial L(\varphi)}{\partial \varphi}
?φ?L(φ)?去更新引數
φ
\varphi
φ,從而找到最優的超參設定;如果
?
L
(
φ
)
?
φ
\frac{\partial L(\varphi)}{\partial \varphi}
?φ?L(φ)?不可求,則可以采用強化學習或者進化演算法去解決,階段一中訓練任務的訓練程序被整理在如下的框圖中,
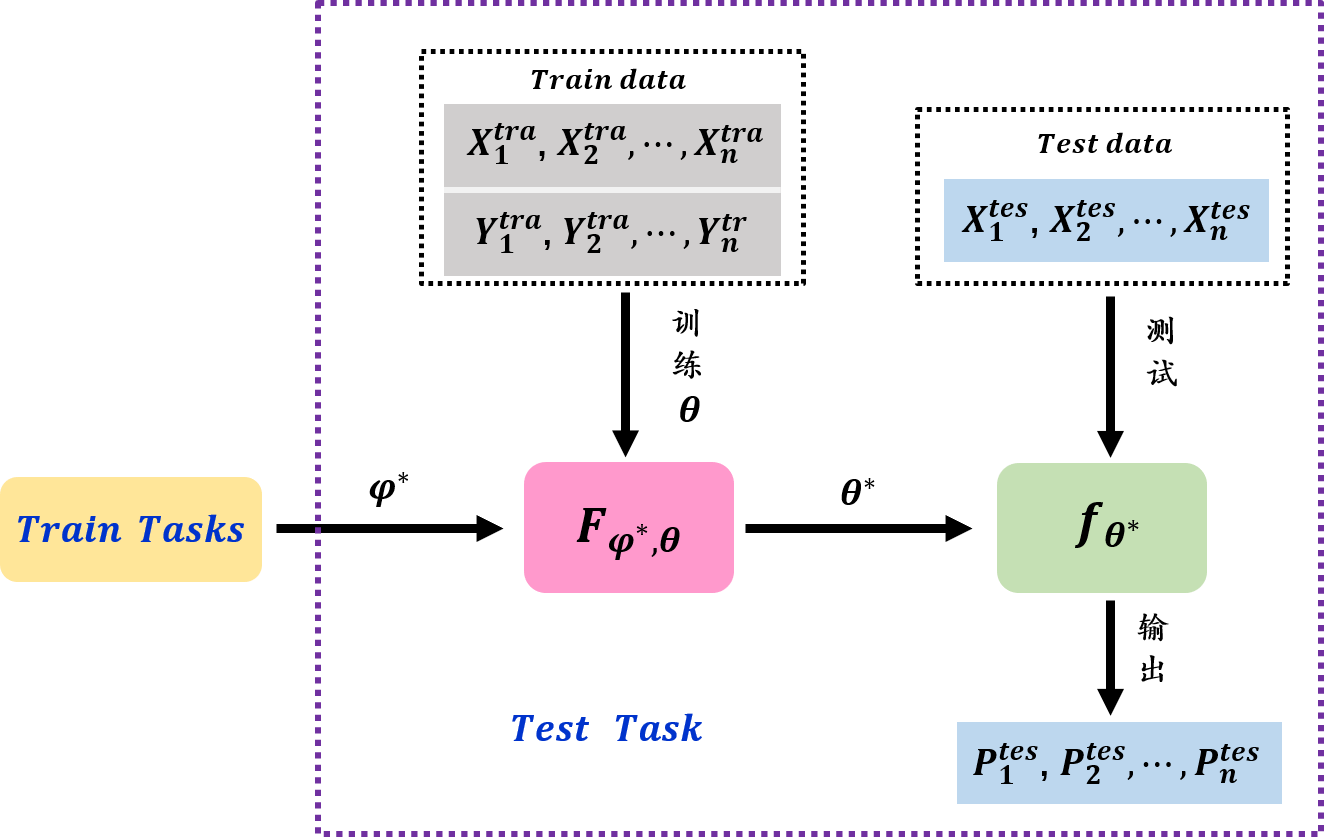
階段二:測驗任務訓練
?測驗任務就是正常的機器學習的程序,它將資料集劃分為訓練集和測驗集,階段一中訓練任務的目的是找到一個好的超參設定
φ
?
\varphi^{*}
φ?,利用這個先驗知識可以對特定的測驗任務進行更好的進行訓練,階段二中測驗任務的訓練程序被整理在如下的框圖中,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356709.html
標籤:AI