吳恩達《神經網路和深度學習》—用一層隱藏層的神經網路分類二維資料
- 1 安裝包
- 2 資料集
- 3 簡單Logistic回歸
- 4 神經網路模型
- 4.1 定義神經網路結構
- 4.2 初始化模型的引數
- 4.3 回圈
- 4.3.1 前向傳播
- 4.3.2 計算成本
- 4.3.3 后向傳播
- 4.3.4 使用梯度下降演算法實作引數更新
- 4.4 集成
- 4.5 預測
- 4.6 調整隱藏層大小
- 5 模型在其他資料集上的性能
※※※※※上一篇:【用神經網路思想實作邏輯回歸】※※※※※
??現在是時候建立你的第一個神經網路了,它將具有一層隱藏層,你將看到此模型與你使用邏輯回歸實作的模型之間的巨大差異,
做完該作業將掌握的技能:
?? ? \bullet ? 實作具有單個隱藏層的二分類神經網路
?? ? \bullet ? 使用具有非線性激活函式的神經元,例如tanh
?? ? \bullet ? 計算交叉熵損失
?? ? \bullet ? 實作前向和后向傳播
??本文所使用的資料:【點擊下載】,提取碼:rc4u,請在開始之前下載好所需資料,然后將檔案解壓到你的代碼檔案同一級目錄下,請確保你的代碼那里有planar_utils.py和testCases.py檔案夾,
1 安裝包
??讓我們首先匯入在作業程序中需要的所有軟體包,
??
?
\bullet
? numpy:是Python科學計算的基本包,
??
?
\bullet
? sklearn:提供了用于資料挖掘和分析的簡單有效的工具,
??
?
\bullet
? matplotlib:是一個著名的Python圖形庫,
??
?
\bullet
? testCases:提供了一些測驗示例來評估函式的正確性,參見下載的資料或者在底部查看它的代碼,
??
?
\bullet
? planar_utils:提供了在這個任務中使用的各種有用的功能,參見下載的資料或者在底部查看它的代碼,
??如果你沒有以上的庫,請自行安裝,并且在需要時按如下方式加載到程式中,
# Package imports
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
#%matplotlib inline #如果你使用用的是Jupyter Notebook的話請取消注釋,
np.random.seed(1) #設定一個固定的隨機種子,以保證接下來的步驟中我們的結果是一致的,
2 資料集
??首先,讓我們獲取處理的資料集,以下代碼會將flower 二分類資料集加載到變數
X
X
X 和
Y
Y
Y 中,
X, Y = load_planar_dataset()
??把資料集加載完成了,然后使用matplotlib可視化資料集,代碼如下:
【代碼】:
# Visualize the data:
plt.scatter(X[0, :], X[1, :], c=Y.reshape(X[0,:].shape), s=40, cmap=plt.cm.Spectral)
【結果】:
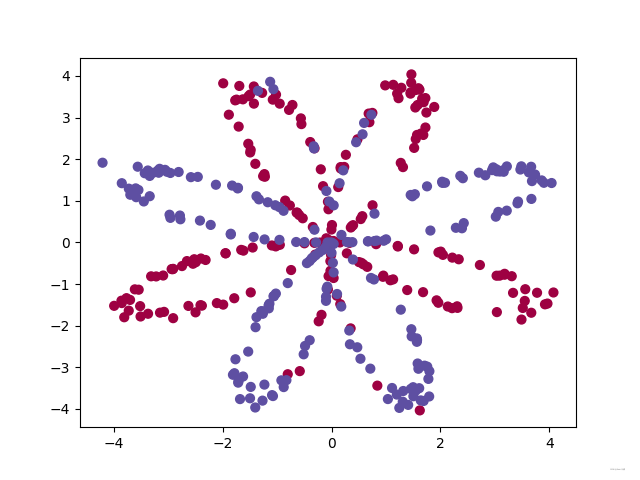
??資料看起來像是帶有一些紅色(標簽 y y y = 0)和一些藍色( y y y = 1)點的“花”,我們的目標是建立一個適合該資料的分類模型,現在,我們已經有了以下的東西:
??
?
\bullet
?
X
X
X:包含特征(
x
1
x1
x1,
x
2
x2
x2)的numpy陣列(矩陣)
??
?
\bullet
?
Y
Y
Y:包含標簽(紅色:0,藍色:1)的numpy陣列(向量)
??接著,讓我們深入地了解一下我們的資料,
【代碼】:
shape_X = X.shape
shape_Y = Y.shape
m = Y.shape[1] # 訓練集里面的數量
print("X的維度為: " + str(shape_X))
print("Y的維度為: " + str(shape_Y))
print("資料集里面的資料有:" + str(m) + " 個")
【結果】:
X的維度為: (2, 400)
Y的維度為: (1, 400)
資料集里面的資料有:400 個
3 簡單Logistic回歸
??在構建完整的神經網路之前,首先讓我們看看邏輯回歸在此問題上的表現,你可以使用sklearn的內置函式來執行此操作,運行以下代碼以在資料集上訓練邏輯回歸分類器,
【代碼】:
# 訓練邏輯回歸分類器
clf = sklearn.linear_model.LogisticRegressionCV()
clf.fit(X.T, Y.T)
【結果】:
??這里會列印出以下的資訊(不同的機器提示大同小異):
DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
??現在,可以運行下面的代碼以繪制此模型的決策邊界:
【代碼】:
# 繪制邏輯回歸分類器的決策邊界
plot_decision_boundary(lambda x: clf.predict(x), X, Y) # 繪制決策邊界
plt.title("Logistic Regression") # 圖示題
LR_predictions = clf.predict(X.T) # 預測結果
print('邏輯回歸的準確性: %d ' % float((np.dot(Y, LR_predictions) +
np.dot(1-Y, 1-LR_predictions))/float(Y.size)*100) +
'% ' + "(正確標記的資料點所占的百分比)")
【結果】:
邏輯回歸的準確性: 47 % (正確標記的資料點所占的百分比)
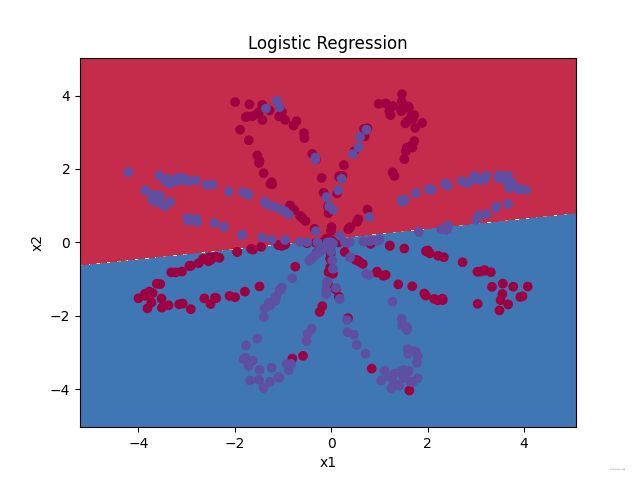
??可以看到,利用邏輯回歸分類器得到的準確性只有47%,這主要是因為資料集不是線性可分類的,而邏輯回歸分類器是線性分類器,因此邏輯回歸效果不佳, 讓我們試試是否神經網路會做得更好吧!
4 神經網路模型
??從上面我們可以得知Logistic回歸不適用于flower資料集,現在你將訓練帶有單個隱藏層的神經網路,
【模型】:
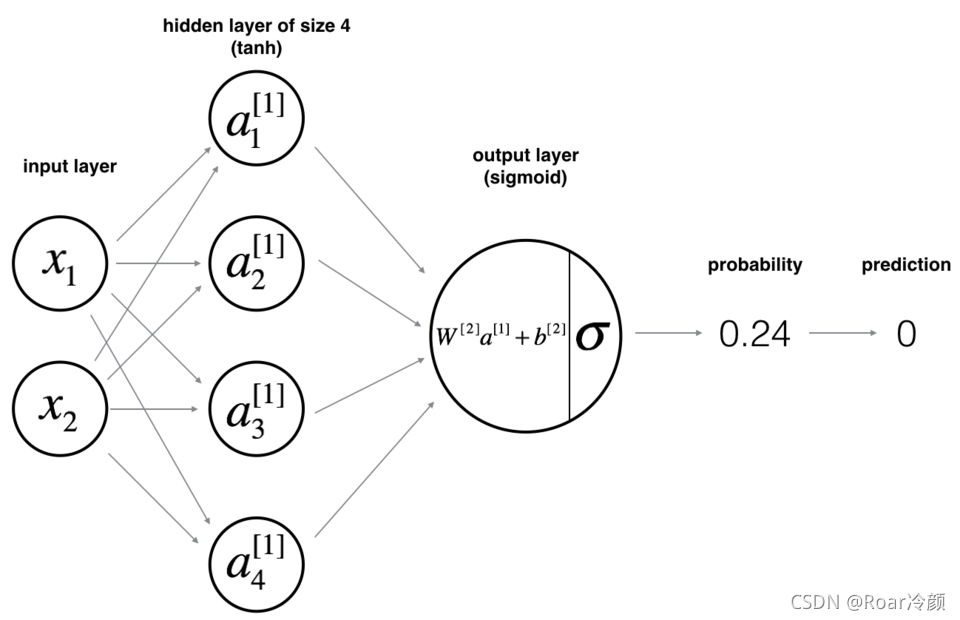
【數學原理】:
??對于樣本
x
(
i
)
x^{\left ( i \right )}
x(i),
z
[
1
]
(
i
)
=
W
[
1
]
x
(
i
)
+
b
[
1
]
(
i
)
(1)
z^{\left [ 1 \right ]\left ( i \right )} = W^{\left [ 1 \right ]}x^{\left ( i \right )}+b^{\left [ 1 \right ]\left ( i \right )} \tag{1}
z[1](i)=W[1]x(i)+b[1](i)(1)
a
[
1
]
(
i
)
=
t
a
n
h
(
z
[
1
]
(
i
)
)
(2)
a^{\left [ 1 \right ]\left ( i \right )}=tanh\left ( z^{\left [ 1 \right ]\left ( i \right )} \right )\tag{2}
a[1](i)=tanh(z[1](i))(2)
z
[
2
]
(
i
)
=
W
[
2
]
a
[
1
]
(
i
)
+
b
[
2
]
(
i
)
(3)
z^{\left [ 2 \right ]\left ( i \right )} = W^{\left [ 2 \right ]}a^{\left [ 1 \right ] \left ( i \right )}+b^{\left [ 2 \right ]\left ( i \right )} \tag{3}
z[2](i)=W[2]a[1](i)+b[2](i)(3)
y
^
(
i
)
=
a
[
2
]
(
i
)
=
σ
(
z
[
2
]
(
i
)
)
(4)
\hat{y}^{\left ( i \right )}=a^{\left [ 2 \right ]\left ( i \right )}=\sigma \left ( z^{\left [ 2 \right ]\left ( i \right )} \right ) \tag{4}
y^?(i)=a[2](i)=σ(z[2](i))(4)
y
p
r
e
d
i
c
t
i
o
n
(
i
)
=
{
1
if
a
[
2
]
(
i
)
>
0.5
0
o
t
h
e
r
w
i
s
e
(5)
y_{prediction}^{\left ( i \right )}=\begin{cases} 1 & \text{ if } a^{\left [ 2 \right ]\left ( i \right )}>0.5 \\ 0 & otherwise \end{cases} \tag{5}
yprediction(i)?={10? if a[2](i)>0.5otherwise?(5)
??根據所有的樣本資料,可以根據下式計算損失
J
J
J:
J
=
?
1
m
∑
i
=
1
m
(
y
(
i
)
l
o
g
(
a
[
2
]
(
i
)
)
+
(
1
?
y
(
i
)
)
l
o
g
(
1
?
a
[
2
]
(
i
)
)
)
(6)
J = -\frac{1}{m}\sum_{i=1}^{m}\left ( y^{\left ( i \right )}log\left ( a^{\left [ 2 \right ]\left ( i \right )} \right ) + \left ( 1-y^{\left ( i \right )} \right )log\left ( 1-a^{\left [ 2 \right ]\left ( i \right )} \right ) \right ) \tag{6}
J=?m1?i=1∑m?(y(i)log(a[2](i))+(1?y(i))log(1?a[2](i)))(6)
【構建神經網路的步驟】:
??1. 定義神經網路結構(輸入單元數,隱藏單元數等)
??2. 初始化模型的引數
??3. 回圈:
????
?
\bullet
? 實作前向傳播
????
?
\bullet
? 計算成本
????
?
\bullet
? 后向傳播以獲得梯度
????
?
\bullet
? 更新引數(梯度下降)
??我們通常會構建輔助函式來計算第1-3步,然后將它們合并為nn_model()函式,一旦構建了nn_model()并學習了正確的引數,就可以對新資料進行預測,
4.1 定義神經網路結構
??首先,我們需要宣告以下3個變數來定義神經網路的結構:
??
?
\bullet
? n_x:輸入層的大小
??
?
\bullet
? n_h:隱藏層的大小(將其設定為4)
??
?
\bullet
? n_y:輸出層的大小
【代碼】:
def layer_sizes(X, Y):
"""
Arguments:
X -- input dataset of shape (input size, number of examples)
Y -- labels of shape (output size, number of examples)
Returns:
n_x -- the size of the input layer
n_h -- the size of the hidden layer
n_y -- the size of the output layer
"""
n_x = X.shape[0] # size of input layer
n_h = 4
n_y = Y.shape[0] # size of output layer
return n_x, n_h, n_y
【測驗】:
# 測驗layer_sizes
print("=========================測驗layer_sizes=========================")
X_asses, Y_asses = layer_sizes_test_case()
(n_x, n_h, n_y) = layer_sizes(X_asses, Y_asses)
print("輸入層的節點數量為: n_x = " + str(n_x))
print("隱藏層的節點數量為: n_h = " + str(n_h))
print("輸出層的節點數量為: n_y = " + str(n_y))
【結果】:
=========================測驗layer_sizes=========================
輸入層的節點數量為: n_x = 5
隱藏層的節點數量為: n_h = 4
輸出層的節點數量為: n_y = 2
4.2 初始化模型的引數
??接下來,我們需要實作初始化模型引數的函式initialize_parameters(),
【說明】:
??
?
\bullet
? 請確保引數大小正確, 如果需要,也可參考上面的神經網路圖,
??
?
\bullet
? 使用隨機值初始化權重矩陣:使用:np.random.randn(a,b)* 0.01隨機初始化維度為(a,b)的矩陣,
??
?
\bullet
? 將偏差向量初始化為零:使用:np.zeros((a,b))初始化維度為(a,b)零的矩陣,
【代碼】:
def initialize_parameters(n_x, n_h, n_y):
"""
Argument:
n_x -- size of the input layer
n_h -- size of the hidden layer
n_y -- size of the output layer
Returns:
params -- python dictionary containing your parameters:
W1 -- weight matrix of shape (n_h, n_x)
b1 -- bias vector of shape (n_h, 1)
W2 -- weight matrix of shape (n_y, n_h)
b2 -- bias vector of shape (n_y, 1)
"""
np.random.seed(2) # 指定一個隨機種子,以便你的輸出與我們的一樣,
W1 = np.random.randn(n_h, n_x) * 0.01
b1 = np.zeros((n_h, 1))
W2 = np.random.randn(n_y, n_h) * 0.01
b2 = np.zeros((n_y, 1))
assert (W1.shape == (n_h, n_x))
assert (b1.shape == (n_h, 1))
assert (W2.shape == (n_y, n_h))
assert (b2.shape == (n_y, 1))
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
【測驗】:
# 測驗initialize_parameters
print("=========================測驗initialize_parameters=========================")
n_x, n_h, n_y = initialize_parameters_test_case()
parameters = initialize_parameters(n_x, n_h, n_y)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
【結果】:
=========================測驗initialize_parameters=========================
W1 = [[-0.00416758 -0.00056267]
[-0.02136196 0.01640271]
[-0.01793436 -0.00841747]
[ 0.00502881 -0.01245288]]
b1 = [[0.]
[0.]
[0.]
[0.]]
W2 = [[-0.01057952 -0.00909008 0.00551454 0.02292208]]
b2 = [[0.]]
4.3 回圈
4.3.1 前向傳播
??在這一步中,我們需要根據以下說明來實作前向傳播函式forward_propagation(),
??
?
\bullet
? 可以使用sigmoid()函式,也可以使用np.tanh()函式,
??
?
\bullet
? 使用parameters [“..”]從字典 parameters(這是initialize_parameters()的輸出)中檢索出每個引數,
??
?
\bullet
? 實作正向傳播,計算
Z
[
1
]
,
?
A
[
1
]
,
?
Z
[
2
]
,
?
Z
[
2
]
Z^{\left [ 1 \right ]},\, A^{\left [ 1 \right ]},\,Z^{\left [ 2 \right ]},\,Z^{\left [ 2 \right ]}
Z[1],A[1],Z[2],Z[2](所有訓練資料的預測結果向量),
??
?
\bullet
? 向后傳播所需的值存盤在cache中, cache將作為反向傳播函式的輸入,
【代碼】:
def forward_propagation(X, parameters):
"""
Argument:
X -- input data of size (n_x, m)
parameters -- python dictionary containing your parameters (output of initialization function)
Returns:
A2 -- The sigmoid output of the second activation
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2"
"""
# Retrieve each parameter from the dictionary "parameters"
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Implement Forward Propagation to calculate A2 (probabilities)
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
assert (A2.shape == (1, X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
【測驗】:
# 測驗forward_propagation
print("=========================測驗forward_propagation=========================")
X_assess, parameters = forward_propagation_test_case()
A2, cache = forward_propagation(X_assess, parameters)
print(np.mean(cache["Z1"]), np.mean(cache["A1"]), np.mean(cache["Z2"]), np.mean(cache["A2"]))
【結果】:
=========================測驗forward_propagation=========================
-0.0004997557777419913 -0.0004969633532317802 0.0004381874509591466 0.500109546852431
4.3.2 計算成本
??現在,我們已經計算了包含每個示例的
a
[
2
]
(
i
)
a^{\left [ 2 \right ]\left ( i \right )}
a[2](i) 的
A
[
2
]
A^{\left [ 2 \right ]}
A[2](在Python變數“A2”中),然后就可以根據公式(6)來實作成本函式compute_cost(),
【說明】:
??有很多的方法都可以計算交叉熵損失,比如對于下面的這個公式,
?
∑
i
=
1
m
y
(
i
)
l
o
g
(
a
[
2
]
(
i
)
)
-\sum_{i=1}^{m}y^{\left ( i \right )}log\left ( a^{\left [ 2 \right ]\left ( i \right )} \right )
?i=1∑m?y(i)log(a[2](i))
我們在python中可以這么實作:
logprobs = np.multiply(np.log(A2),Y)
cost = - np.sum(logprobs) # 不需要使用回圈就可以直接算出來,
??當然,我們也可以直接使用np.dot()來進行計算,
【代碼】:
def compute_cost(A2, Y, parameters):
"""
Computes the cross-entropy cost given in equation (13)
Arguments:
A2 -- The sigmoid output of the second activation, of shape (1, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
parameters -- python dictionary containing your parameters W1, b1, W2 and b2
Returns:
cost -- cross-entropy cost given equation (13)
"""
m = Y.shape[1] # number of example
# Compute the cross-entropy cost
logprobs = Y * np.log(A2) + (1 - Y) * np.log(1 - A2)
cost = -1 / m * np.sum(logprobs)
cost = np.squeeze(cost) # makes sure cost is the dimension we expect.
# E.g., turns [[17]] into 17
assert (isinstance(cost, float))
return cost
【測驗】:
# 測驗compute_cost
print("=========================測驗compute_cost=========================")
A2, Y_assess, parameters = compute_cost_test_case()
print("cost = " + str(compute_cost(A2, Y_assess, parameters)))
【結果】:
=========================測驗compute_cost=========================
cost = 0.6929198937761265
4.3.3 后向傳播
??接下來,就可以使用在正向傳播期間計算的快取,來實作后向傳播backward_propagation(),
【數學原理】:
??反向傳播通常是深度學習中最難(數學)的部分,為了幫助你更好地了解,你可以借助以下六個方程式來構建向量化實作,

【說明】:
??
?
\bullet
?
?
\ast
? 表示對應元素相乘,
??
?
\bullet
? 使用在深度學習中很常見的編碼表示方法:
d
W
1
=
?
J
?
W
1
dW1=\frac{\partial J}{\partial W_1}
dW1=?W1??J?
d
b
1
=
?
J
?
b
1
db1=\frac{\partial J}{\partial b_1}
db1=?b1??J?
d
W
2
=
?
J
?
W
2
dW2=\frac{\partial J}{\partial W_2}
dW2=?W2??J?
d
b
2
=
?
J
?
b
2
db2=\frac{\partial J}{\partial b_2}
db2=?b2??J???
?
\bullet
? 要計算
d
Z
1
dZ1
dZ1,首先需要計算
g
[
1
]
′
(
z
[
1
]
)
g^{\left [ 1 \right ]'}\left ( z^{[1]} \right )
g[1]′(z[1]),由于
g
[
1
]
(
?
)
g^{\left [ 1 \right ]}\left ( \cdot \right )
g[1](?) 是tanh激活函式,因此如果
a
=
g
[
1
]
(
z
)
a = g^{\left [ 1 \right ]}\left ( z \right )
a=g[1](z),則
g
[
1
]
′
(
z
)
=
1
?
a
2
g^{\left [ 1 \right ]'}\left ( z \right ) = 1-a^{2}
g[1]′(z)=1?a2,所以,可以使用(1 - np.power(A1, 2))計算
g
[
1
]
′
(
z
[
1
]
)
g^{\left [ 1 \right ]'}\left ( z^{[1]} \right )
g[1]′(z[1]),
【代碼】:
def backward_propagation(parameters, cache, X, Y):
"""
Implement the backward propagation using the instructions above.
Arguments:
parameters -- python dictionary containing our parameters
cache -- a dictionary containing "Z1", "A1", "Z2" and "A2".
X -- input data of shape (2, number of examples)
Y -- "true" labels vector of shape (1, number of examples)
Returns:
grads -- python dictionary containing your gradients with respect to different parameters
"""
m = X.shape[1]
# First, retrieve W1 and W2 from the dictionary "parameters".
W1 = parameters["W1"]
W2 = parameters["W2"]
# Retrieve also A1 and A2 from dictionary "cache".
A1 = cache["A1"]
A2 = cache["A2"]
# Backward propagation: calculate dW1, db1, dW2, db2.
dZ2 = A2 - Y
dW2 = 1 / m * np.dot(dZ2, A1.T)
db2 = 1 / m * np.sum(dZ2, axis=1, keepdims=True)
dZ1 = np.dot(W2.T, dZ2) * (1 - np.power(A1, 2))
dW1 = 1 / m * np.dot(dZ1, X.T)
db1 = 1 / m * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2}
return grads
【測驗】:
# 測驗backward_propagation
print("=========================測驗backward_propagation=========================")
parameters, cache, X_assess, Y_assess = backward_propagation_test_case()
grads = backward_propagation(parameters, cache, X_assess, Y_assess)
print("dW1 = " + str(grads["dW1"]))
print("db1 = " + str(grads["db1"]))
print("dW2 = " + str(grads["dW2"]))
print("db2 = " + str(grads["db2"]))
【結果】:
=========================測驗backward_propagation=========================
dW1 = [[ 0.01018708 -0.00708701]
[ 0.00873447 -0.0060768 ]
[-0.00530847 0.00369379]
[-0.02206365 0.01535126]]
db1 = [[-0.00069728]
[-0.00060606]
[ 0.000364 ]
[ 0.00151207]]
dW2 = [[ 0.00363613 0.03153604 0.01162914 -0.01318316]]
db2 = [[0.06589489]]
4.3.4 使用梯度下降演算法實作引數更新
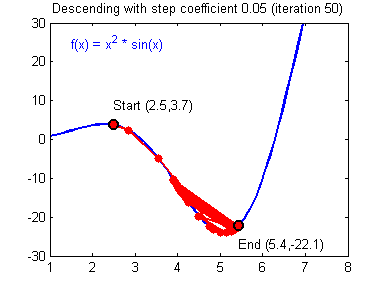
??現在,我們就可以利用梯度下降演算法來實作引數的更新了,使用梯度下降,必須使用 ( d W 1 , d b 1 , d W 2 , d b 2 ) (dW1,db1,dW2,db2) (dW1,db1,dW2,db2)才能更新 ( W 1 , b 1 , W 2 , b 2 ) (W1,b1,W2,b2) (W1,b1,W2,b2),一般的梯度下降規則為: θ = θ ? α ? J ? θ \theta =\theta -\alpha\frac{\partial J}{\partial \theta } θ=θ?α?θ?J?其中 α \alpha α 是學習率,而 θ \theta θ 代表一個引數,
??下面兩幅圖展示了具有良好的學習速率(收斂)和較差的學習速率(發散)的梯度下降演算法,
【代碼】:
def update_parameters(parameters, grads, learning_rate=1.2):
"""
Updates parameters using the gradient descent update rule given above
Arguments:
parameters -- python dictionary containing your parameters
grads -- python dictionary containing your gradients
Returns:
parameters -- python dictionary containing your updated parameters
"""
# Retrieve each parameter from the dictionary "parameters"
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Retrieve each gradient from the dictionary "grads"
dW1 = grads["dW1"]
db1 = grads["db1"]
dW2 = grads["dW2"]
db2 = grads["db2"]
# Update rule for each parameter
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
【測驗】:
# 測驗update_parameters
print("=========================測驗update_parameters=========================")
parameters, grads = update_parameters_test_case()
parameters = update_parameters(parameters, grads)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
【結果】:
=========================測驗update_parameters=========================
W1 = [[-0.00643025 0.01936718]
[-0.02410458 0.03978052]
[-0.01653973 -0.02096177]
[ 0.01046864 -0.05990141]]
b1 = [[-1.02420756e-06]
[ 1.27373948e-05]
[ 8.32996807e-07]
[-3.20136836e-06]]
W2 = [[-0.01041081 -0.04463285 0.01758031 0.04747113]]
b2 = [[0.00010457]]
4.4 集成
??最后,通過按照正確的順序組合上述創建的函式就可以在nn_model()函式中建立神經網路模型,
【代碼】:
def nn_model(X, Y, n_h, num_iterations=10000, print_cost=False):
"""
Arguments:
X -- dataset of shape (2, number of examples)
Y -- labels of shape (1, number of examples)
n_h -- size of the hidden layer
num_iterations -- Number of iterations in gradient descent loop
print_cost -- if True, print the cost every 1000 iterations
Returns:
parameters -- parameters learnt by the model. They can then be used to predict.
"""
np.random.seed(3)
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
# Initialize parameters,
# then retrieve W1, b1, W2, b2. Inputs: "n_x, n_h, n_y". Outputs = "W1, b1, W2, b2, parameters".
parameters = initialize_parameters(n_x, n_h, n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
# Loop (gradient descent)
for i in range(0, num_iterations):
# Forward propagation. Inputs: "X, parameters". Outputs: "A2, cache".
A2, cache = forward_propagation(X, parameters)
# Cost function. Inputs: "A2, Y, parameters". Outputs: "cost".
cost = compute_cost(A2, Y, parameters)
# Backpropagation. Inputs: "parameters, cache, X, Y". Outputs: "grads".
grads = backward_propagation(parameters, cache, X, Y)
# Gradient descent parameter update. Inputs: "parameters, grads". Outputs: "parameters".
parameters = update_parameters(parameters, grads)
# Print the cost every 1000 iterations
if print_cost and i % 1000 == 0:
print("Cost after iteration %i: %f" % (i, cost))
return parameters
【測驗】:
# 測驗nn_model
print("=========================測驗nn_model=========================")
X_assess, Y_assess = nn_model_test_case()
parameters = nn_model(X_assess, Y_assess, 4, num_iterations=10000, print_cost=False)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
【結果】:
=========================測驗nn_model=========================
W1 = [[-4.18494714 5.33206444]
[-7.53806726 1.20753857]
[-4.19262445 5.32638718]
[ 7.53804391 -1.20755126]]
b1 = [[ 2.3293681 ]
[ 3.80995835]
[ 2.33015051]
[-3.80999435]]
W2 = [[-6033.82336187 -6008.1427588 -6033.08758194 6008.07912558]]
b2 = [[-52.67942084]]
4.5 預測
??為了驗證我們模型的準確性,我們可以根據nn_model()函式輸出的引數,利用正向傳播來預測結果(參考公式(5)),
【代碼】:
def predict(parameters, X):
"""
Using the learned parameters, predicts a class for each example in X
Arguments:
parameters -- python dictionary containing your parameters
X -- input data of size (n_x, m)
Returns
predictions -- vector of predictions of our model (red: 0 / blue: 1)
"""
# Computes probabilities using forward propagation, and classifies to 0/1 using 0.5 as the threshold.
A2, cache = forward_propagation(X, parameters)
predictions = np.round(A2)
return predictions
【測驗】:
# 測驗predict
print("=========================測驗predict=========================")
parameters, X_assess = predict_test_case()
predictions = predict(parameters, X_assess)
print("預測的平均值 = " + str(np.mean(predictions)))
【結果】:
=========================測驗predict=========================
預測的平均值 = 0.6666666666666666
??至此,所有的作業都完成了,現在我們可以正式利用我們搭建的神經網路模型來訓練flower 二分類資料集,
【代碼】:
# Build a model with a n_h-dimensional hidden layer
parameters = nn_model(X, Y, n_h=4, num_iterations=10000, print_cost=True)
# Plot the decision boundary
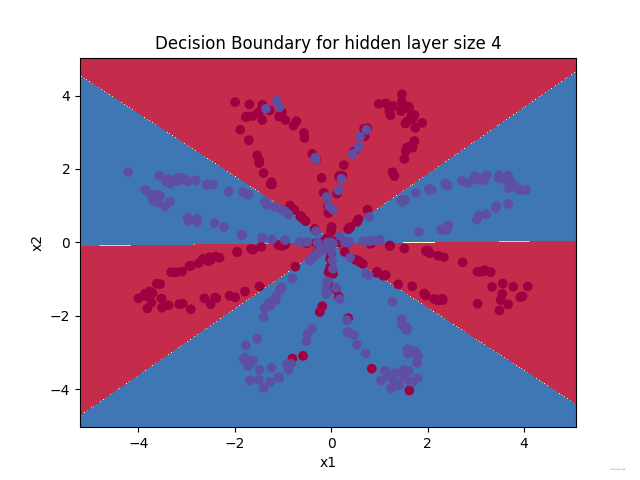
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
plt.show()
【結果】:
Cost after iteration 0: 0.693048
Cost after iteration 1000: 0.288083
Cost after iteration 2000: 0.254385
Cost after iteration 3000: 0.233864
Cost after iteration 4000: 0.226792
Cost after iteration 5000: 0.222644
Cost after iteration 6000: 0.219731
Cost after iteration 7000: 0.217504
Cost after iteration 8000: 0.219449
Cost after iteration 9000: 0.218605
??還可以利用以下代碼來查看該訓練好的神經網路模型的預測準確性,
【代碼】:
# Print accuracy
predictions = predict(parameters, X)
print('Accuracy: %d' % float((np.dot(Y, predictions.T) + np.dot(1-Y, 1-predictions.T))/float(Y.size)*100) + '%')
【結果】:
Accuracy: 90%
??與Logistic回歸相比,準確性確實更高, 該模型學習了flower的葉子圖案!與邏輯回歸不同,神經網路甚至能夠學習非線性的決策邊界,
4.6 調整隱藏層大小
??我們上面的實驗把隱藏層定為4個節點,現在我們更改隱藏層里面的節點數量,看一看節點數量是否會對結果造成影響,
【代碼】:
plt.figure(figsize=(16, 32))
hidden_layer_sizes = [1, 2, 3, 4, 5, 10, 20]
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(4, 2, i+1)
plt.title('Hidden Layer of size %d' % n_h)
parameters = nn_model(X, Y, n_h, num_iterations=5000)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y, predictions.T) + np.dot(1-Y, 1-predictions.T))/float(Y.size)*100)
print("Accuracy for {} hidden units: {} %".format(n_h, accuracy))
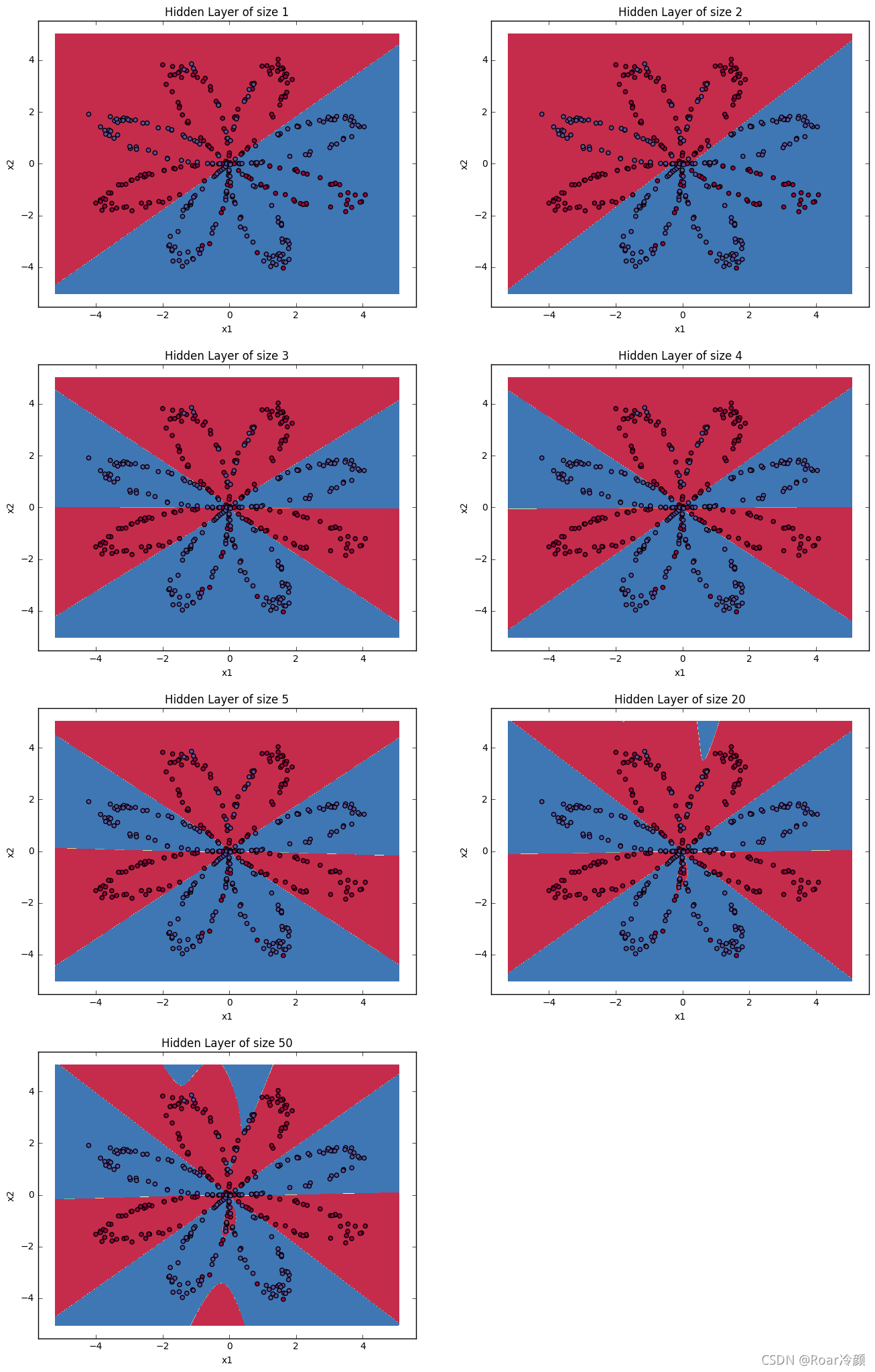
【說明】:根據上述結果可以看出:
??
?
\bullet
? 較大的模型(具有更多隱藏的單元)能夠更好地擬合訓練集,直到最終最大的模型過擬合資料為止,
??
?
\bullet
? 隱藏層的最佳大小似乎在n_h = 5左右,的確,此值似乎很好地擬合了資料,而又不會引起明顯的過度擬合,
??
?
\bullet
? 之后的教程還將學習正則化,幫助構建更大的模型(例如n_h = 50)而不會過度擬合,
??
?
\bullet
? 在上述代碼中,plt.figure(figsize=(16, 32)) 此行代碼需要根據自己的電腦解析度進行設定,否則畫出來的圖不好看,
5 模型在其他資料集上的性能
??如果需要,可以為以下每個資料集重新運行構建的神經網路模型(除去資料集部分),
??首先,來看一下該模型在noisy_circles資料集的運行效果(只需要把原來處理資料集的部分修改成以下代碼就可以,不需要修改其他部分):
【代碼】:
noisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structure = load_extra_datasets()
datasets = {"noisy_circles": noisy_circles,
"noisy_moons": noisy_moons,
"blobs": blobs,
"gaussian_quantiles": gaussian_quantiles}
dataset = "noisy_circles" # 修改不同的資料集
X, Y = datasets[dataset]
X, Y = X.T, Y.reshape(1, Y.shape[0])
# make blobs binary
if dataset == "blobs":
Y = Y%2
【結果】:
X的維度為: (2, 200)
Y的維度為: (1, 200)
資料集里面的資料有:200 個
Cost after iteration 0: 0.693150
Cost after iteration 1000: 0.371229
Cost after iteration 2000: 0.360047
Cost after iteration 3000: 0.355231
Cost after iteration 4000: 0.352771
Cost after iteration 5000: 0.351263
Cost after iteration 6000: 0.351428
Cost after iteration 7000: 0.354861
Cost after iteration 8000: 0.354747
Cost after iteration 9000: 0.354317
Accuracy: 81%
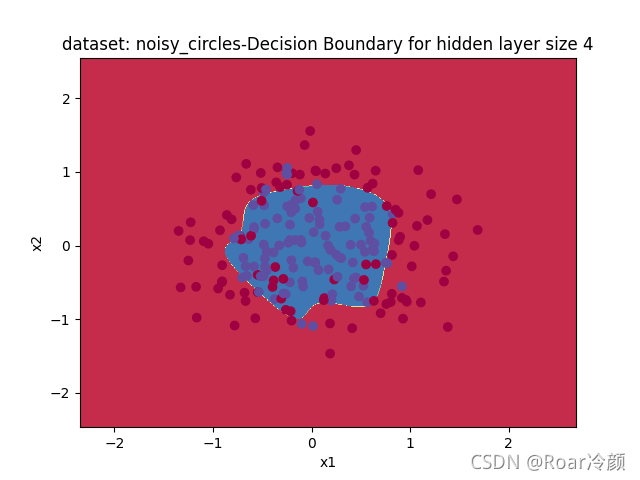
??接著,來看一下該模型在noisy_moons資料集的運行效果:
【結果】:
X的維度為: (2, 200)
Y的維度為: (1, 200)
資料集里面的資料有:200 個
Cost after iteration 0: 0.693001
Cost after iteration 1000: 0.316565
Cost after iteration 2000: 0.317008
Cost after iteration 3000: 0.316195
Cost after iteration 4000: 0.099350
Cost after iteration 5000: 0.094745
Cost after iteration 6000: 0.093920
Cost after iteration 7000: 0.093484
Cost after iteration 8000: 0.093183
Cost after iteration 9000: 0.093618
Accuracy: 96%
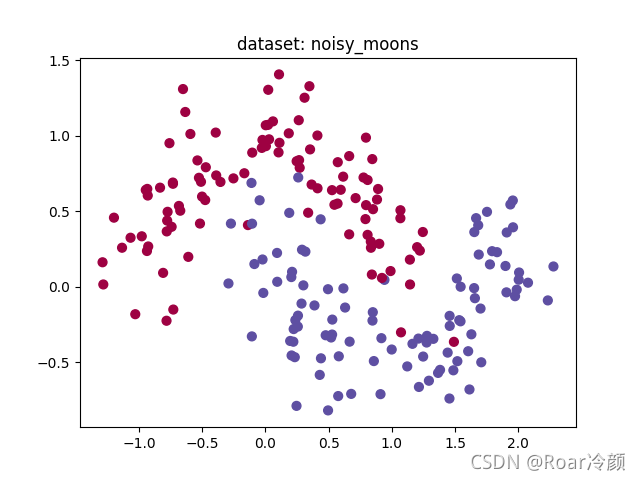
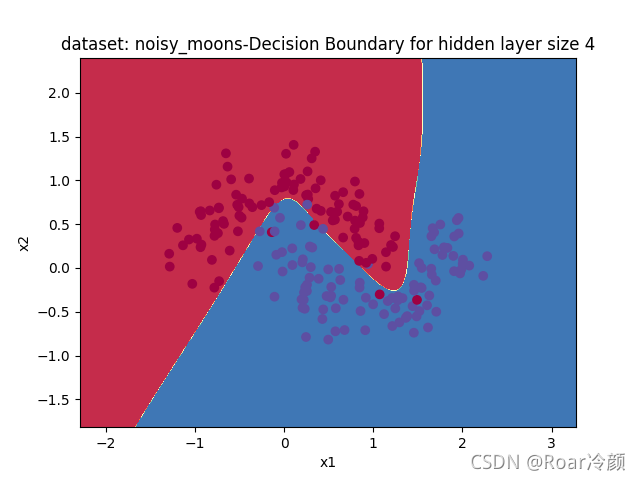
??然后,來看一下該模型在blobs資料集的運行效果:
【結果】:
X的維度為: (2, 200)
Y的維度為: (1, 200)
資料集里面的資料有:200 個
Cost after iteration 0: 0.693527
Cost after iteration 1000: 0.324217
Cost after iteration 2000: 0.323287
Cost after iteration 3000: 0.323032
Cost after iteration 4000: 0.322912
Cost after iteration 5000: 0.322842
Cost after iteration 6000: 0.322796
Cost after iteration 7000: 0.322764
Cost after iteration 8000: 0.322739
Cost after iteration 9000: 0.322721
Accuracy: 83%
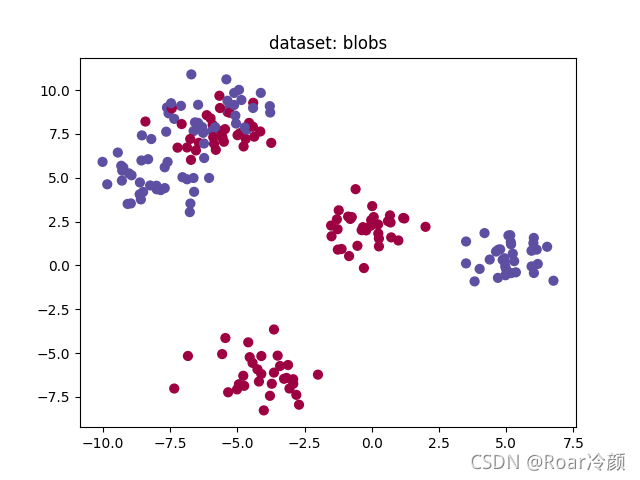
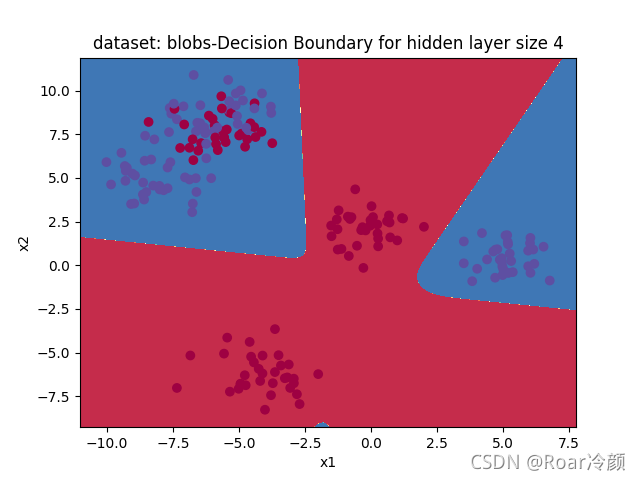
??最后,來看一下該模型在gaussian_quantiles資料集的運行效果:
【結果】:
X的維度為: (2, 200)
Y的維度為: (1, 200)
資料集里面的資料有:200 個
Cost after iteration 0: 0.693149
Cost after iteration 1000: 0.100718
Cost after iteration 2000: 0.077908
Cost after iteration 3000: 0.067646
Cost after iteration 4000: 0.062900
Cost after iteration 5000: 0.059589
Cost after iteration 6000: 0.057225
Cost after iteration 7000: 0.055425
Cost after iteration 8000: 0.054002
Cost after iteration 9000: 0.052850
Accuracy: 98%
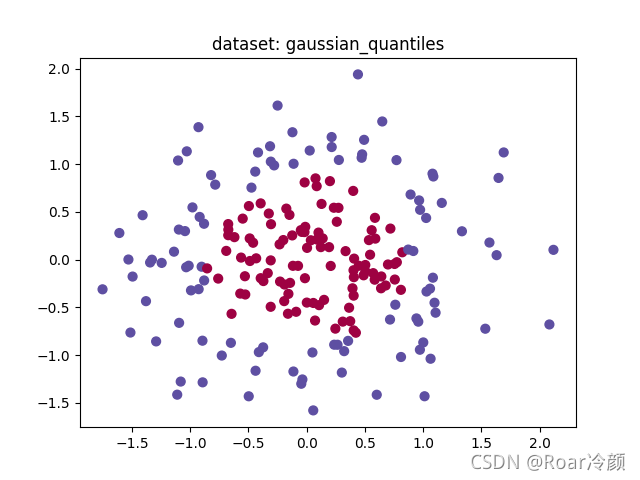
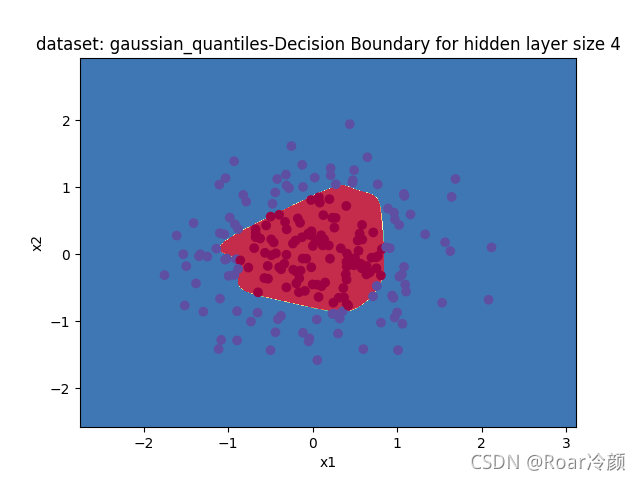
??綜合上述可以看出,我們構建的單隱層神經網路模型對該四個資料集都能夠訓練出較好的結果,準確率相對較高,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356710.html
標籤:AI
上一篇:元學習深度決議