文章目錄
- 1、為什么要磁區?
- 2、如何磁區以及細節
- 3、創建磁區
- 4、靜態磁區
- 5、動態磁區
① Hive 資料管理、內外表、安裝模式操作
② Hive:用SQL對資料進行操作,匯入資料、清洗臟資料、統計資料訂單
③ Hive:多種方式建表,需求操作
④ Hive:磁區原因、創建磁區、靜態磁區 、動態磁區
⑤ Hive:分桶的簡介、原理、應用、創建
⑥ Hive:優化 Reduce,查詢程序;判斷資料傾斜,MAPJOIN
1、為什么要磁區?
1、在Hive Select查詢中一般會掃描整個表內容,會消耗很多時間做沒必要的作業,有時候只需要掃描表中關心的一部分資料,因此建表時引入了partition概念,
2、磁區表指的是在創建表時指定的partition的磁區空間,
3、如果需要創建有磁區的表,需要在create表的時候呼叫可選引數partitioned by,
2、如何磁區以及細節
根據業務磁區,(完全看業務場景)選取id、年、月、日、男女性別、年齡段 或者是能平均將資料分到不同檔案中最好,磁區不好將直接導致查詢結果延遲,
磁區細節:
- 一個表可以擁有一個或者多個磁區,每個磁區以檔案夾的形式單獨存在表檔案夾的目錄下;
- 表和列名不區分大小寫;
- 磁區是以欄位的形式在表結構中存在,但是該欄位不存放實際的資料內容,僅僅是磁區的表示;
- 磁區有一級、二級設定一般設定為一級磁區;
- 磁區分為動態磁區和靜態磁區,
3、創建磁區
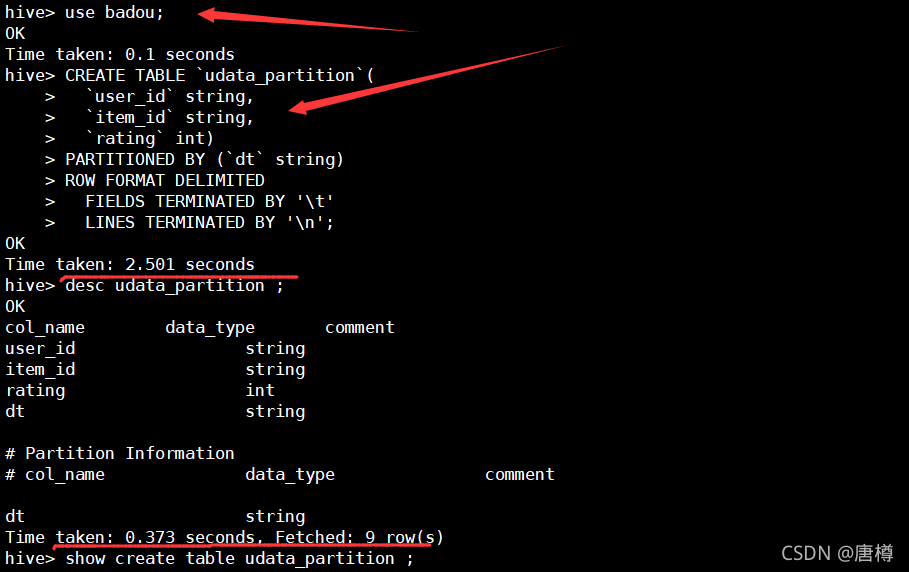
接著上一篇博文用的資料 udata,進行磁區操作,
-- 1、創建磁區,磁區欄位為 dt
CREATE TABLE `udata_partition`(
`user_id` string,
`item_id` string,
`rating` int)
PARTITIONED BY (`dt` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LINES TERMINATED BY '\n'
-- 2、查看表結構
show create table udata_partition ;
desc udata_partition ;
4、靜態磁區
每個磁區要寫一個load data,缺點:load data 效率低下,非常繁瑣,不常用靜態磁區在業務中,
應用場景: 資料量不大,同時要知道磁區的資料型別
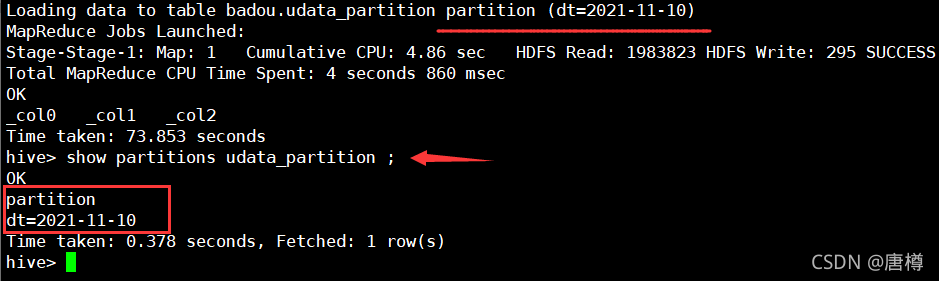
--1、靜態磁區設定
insert overwrite table udata_partition partition (dt='2021-11-10')
select user_id, item_id, rating from udata where user_id='242';
--2、查看磁區
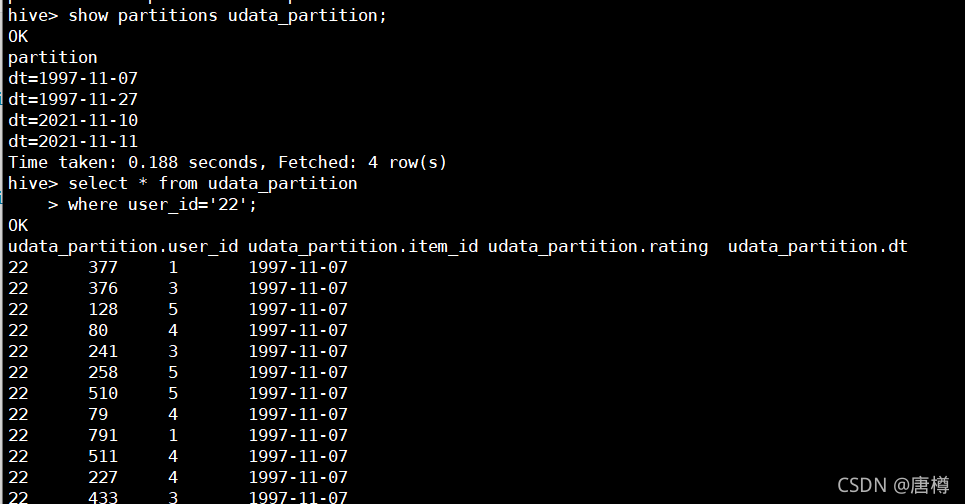
show partitions udata_partition;
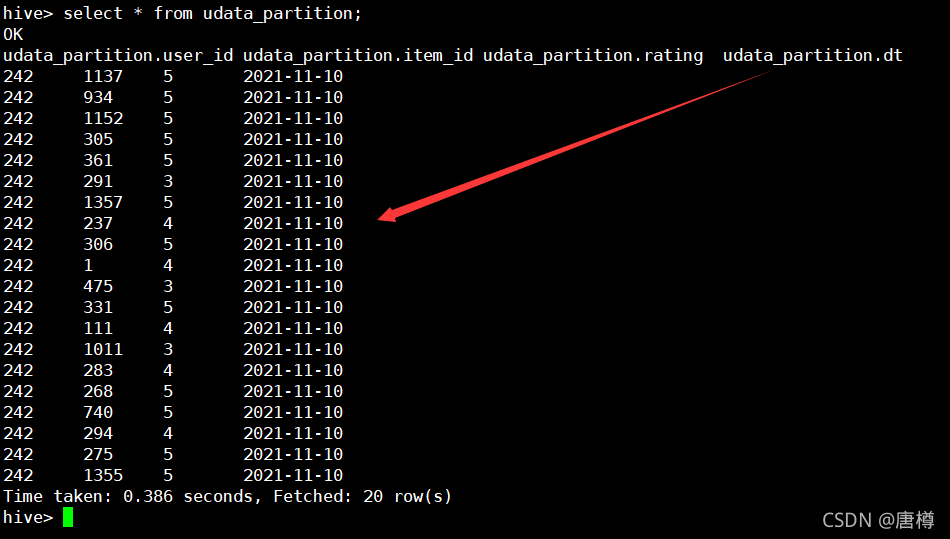
--3、查看udata_partition資料
select * from udata_partition;
-- 1、再插入資料
insert overwrite table udata_partition partition (dt='2021-11-11')
select user_id, item_id, rating from udata where user_id='222';
--2、查看磁區
show partitions udata_partition;
--3、查看udata_partition資料
select * from udata_partition;
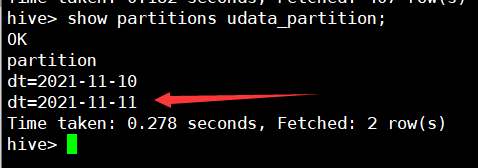
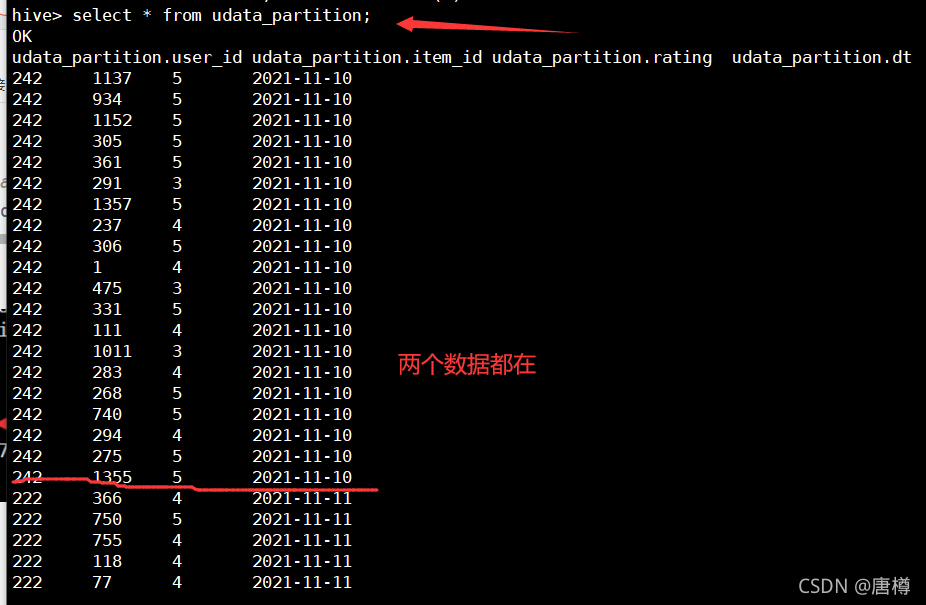
我們再去HDFS目錄查看,在udata_partition檔案有是否有兩個磁區檔案,
-- 1、查看udata_partition檔案目錄下的檔案是否是那兩個磁區
hadoop fs -ls /user/hive/warehouse/badou.db/udata_partition/
-- 2、查看磁區檔案:dt=2021-11-10 下的檔案
hadoop fs -ls /user/hive/warehouse/badou.db/udata_partition/dt=2021-11-10
-- 3、cat dt=2021-11-10檔案里的資料,
hadoop fs -cat /user/hive/warehouse/badou.db/udata_partition/dt=2021-11-10/00*

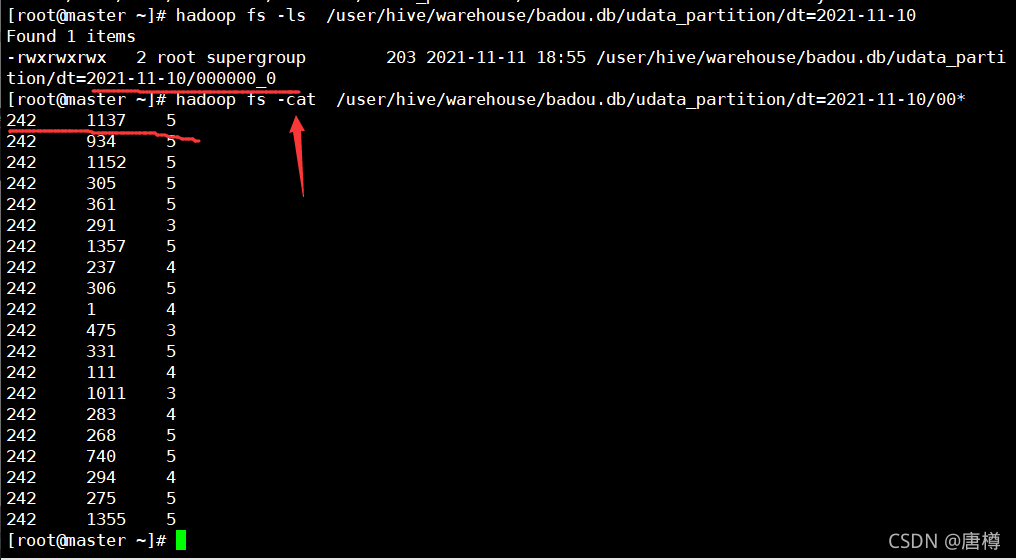
上圖資料顯示結果 == select user_id, item_id, rating from udata where user_id=‘242’; 保存的磁區檔案,
5、動態磁區
應用場景: 不確定磁區數量,資料量也不是很大,使用動態磁區
實際作業中趨向于使用動態磁區!!!
--注意:以下設定,只在當前的會話視窗有效
-- 1.打開動態磁區模式:
set hive.exec.dynamic.partition=true;
-- 2.設定磁區模式為非嚴格模式
set hive.exec.dynamic.partition.mode=nonstrict;

我們知道udata的內容,我們要把時間戳轉為年月日,與上面靜態磁區的格式一致,
-- 1、把時間戳case為 bigint
cast(`timestamp` as bigint)
-- 2、from_unixtime()是實作格式轉換
from_unixtime(cast(`timestamp` as bigint), 'yyyy-MM-dd HH:mm:ss')
-- 3、顯示結果
select user_id, item_id, rating, from_unixtime(cast(`timestamp` as bigint), 'yyyy-MM-dd HH:mm:ss') from udata limit 15;
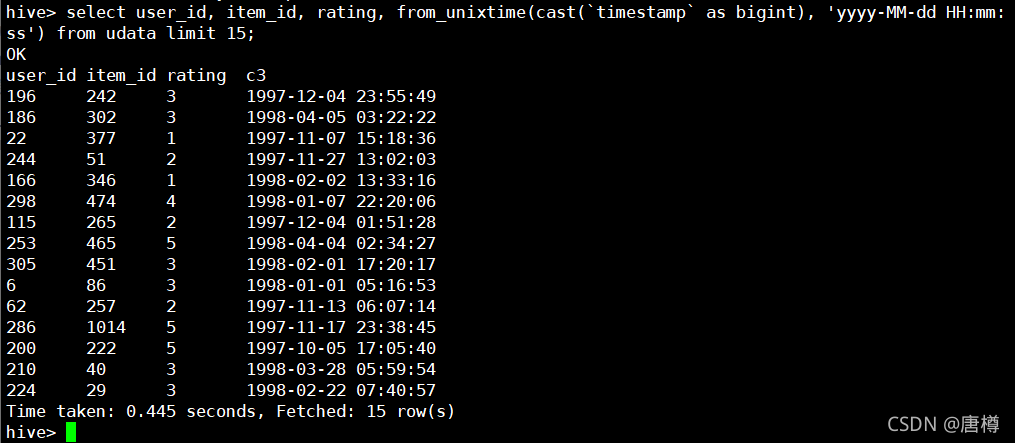
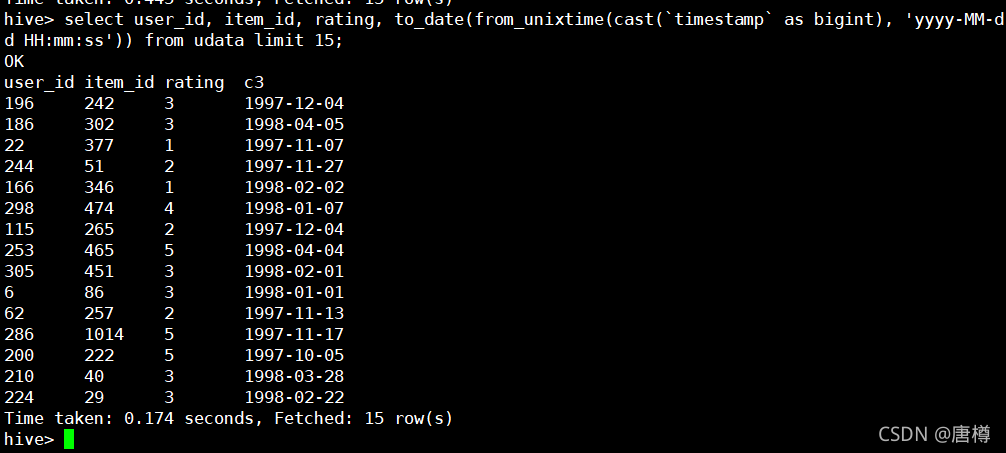
我們不需要時分秒,用to_data(from_unixtime(...)) as res
-- 4、取消時分秒
select user_id, item_id, rating, to_date(from_unixtime(cast(`timestamp` as bigint), 'yyyy-MM-dd HH:mm:ss')) from udata limit 15;
實作磁區動態加載:
insert overwrite table udata_partition partition (dt)
select user_id, item_id, rating,
to_date(from_unixtime(cast(`timestamp` as bigint), 'yyyy-MM-dd HH:mm:ss'))
as res from udata
where user_id='22';
-- udata_partition dt資料=res資料;
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356755.html
標籤:其他
上一篇:Hadoop使用MapReduce求ncdc氣象資料中的最低溫度
下一篇:大資料之路——資料同步