三、資料技術篇—— 資料同步
- 3.1 資料同步基礎 @
- 3.1.1 直連同步
- 3.1.2 資料檔案同步
- 3.1.3 資料庫日志決議同步
- 3.2 資料倉庫同步方式
- 3.2.1 批量資料同步
- 3.2.2 實時資料同步
- 3.3 同步遇到的問題
- 3.3.1 分庫分表
- 3.3.2 增量全量同步的合并@
- 3.3.3 資料漂移的處理 @
有多種不同應用場景:主資料庫和備份資料庫之間的資料備份,主系統和子系統的資料更新,不用地域、資料庫型別的資料傳輸交換
3.1 資料同步基礎 @
關系型資料庫,結構化資料:MySQL、Oracle、DB2
非關系型資料庫,非結構化:OceanBase、HBase、MongoDB
物件存盤:OSS
檔案存盤:NAS
| 名稱 | 實作方式 |
|---|---|
| 直連同步 | - 通過定義好的規范介面API和基于元件的方式直接連接業務庫, - 配置簡單,容易實作,但是對性能影響較大,不太適合, |
| 資料檔案同步 | - 通過約定好的檔案編碼等,直接從源系統(包含多個異構的資料庫系統)生成資料的文本檔案,由專門的檔案服務器傳輸到目標系統, - 由于通過檔案上傳、下載會造成丟包,且需要上傳校驗檔案(資料量及檔案大小) - 可以增加壓縮和加密功能 |
| 資料庫日志決議同步 | - 日志檔案資訊豐富,資料格式穩定,通過決議日志檔案獲取變化的資料,滿足增量資料同步需求 - 通過源系統的行程(作業系統層面,不過資料庫),讀取日志檔案中變化并決議道目標資料檔案中, - 網路協議,保障資料檔案正確接收、正確資料、網路傳輸冗余、檔案完整性 - 實時和準實時的能力,毫秒級別延遲 - 缺點:資料延遲(補錄資料超出峰值)、投入大、資料漂移 |
3.1.1 直連同步

- 通過定義好的規范介面API和基于元件的方式直接連接業務庫,
- 配置簡單,容易實作,但是對性能影響較大,不太適合,
3.1.2 資料檔案同步
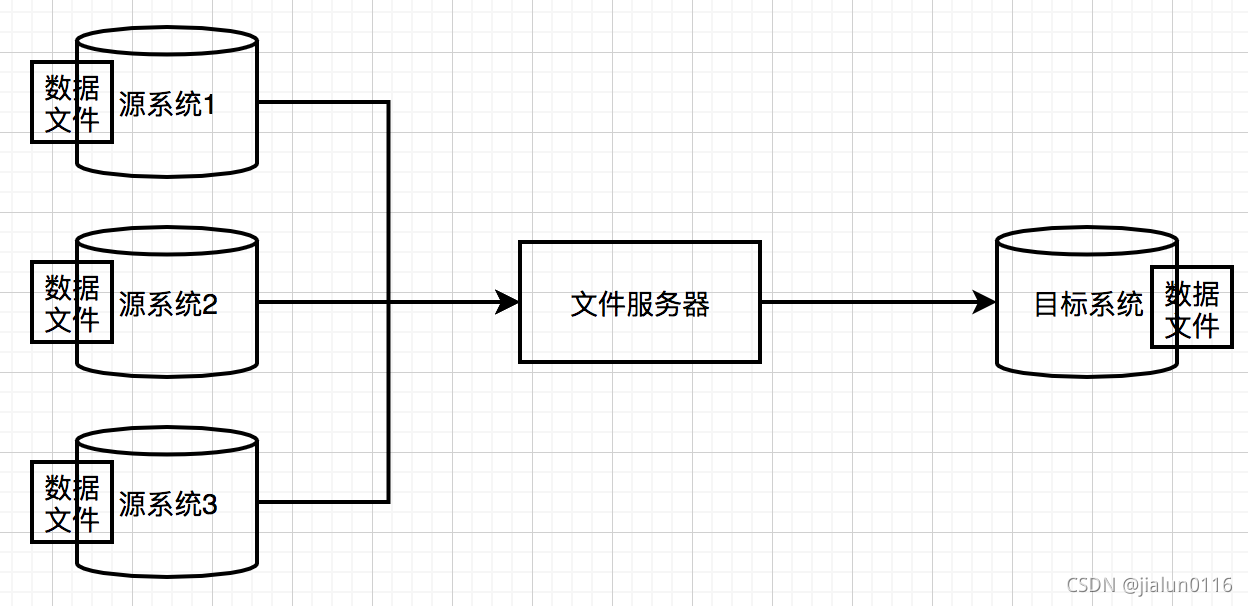
- 通過約定好的檔案編碼等,直接從源系統(包含多個異構的資料庫系統)生成資料的文本檔案,由專門的檔案服務器傳輸到目標系統,
- 由于通過檔案上傳、下載會造成丟包,且需要上傳校驗檔案(資料量及檔案大小)
- 可以增加壓縮和加密功能
3.1.3 資料庫日志決議同步
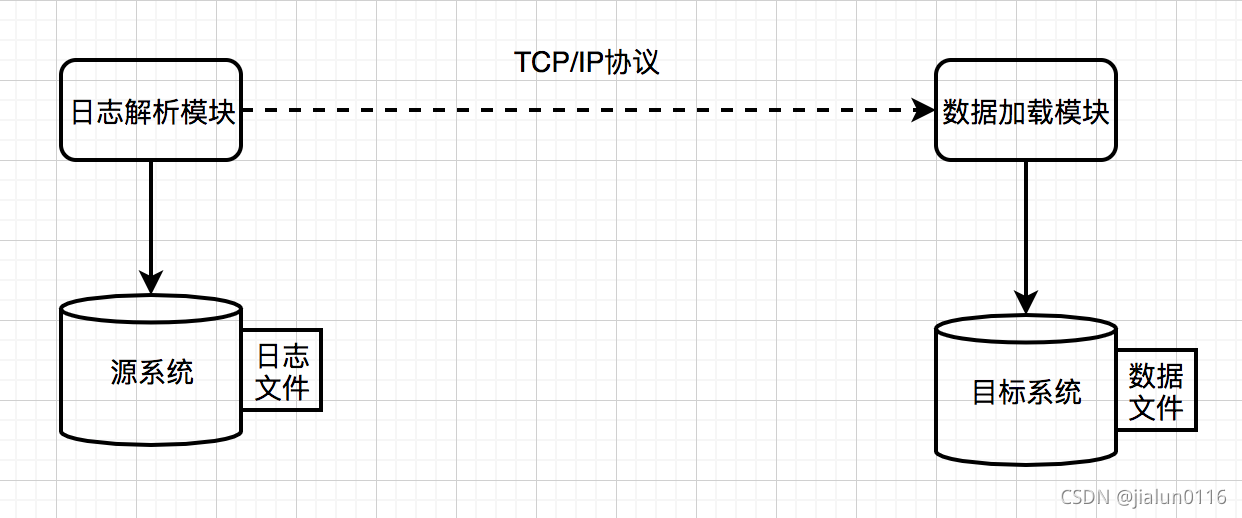
- 日志檔案資訊豐富,資料格式穩定,通過決議日志檔案獲取變化的資料,滿足增量資料同步需求
- 通過源系統的行程(作業系統層面,不過資料庫),讀取日志檔案中變化并決議道目標資料檔案中,
- 網路協議,保障資料檔案正確接收、正確資料、網路傳輸冗余、檔案完整性
- 實時和準實時的能力,毫秒級別延遲
- 缺點:資料延遲(補錄資料超出峰值)、投入大、資料漂移
3.2 資料倉庫同步方式
資料來源的多樣性、資料量大
3.2.1 批量資料同步
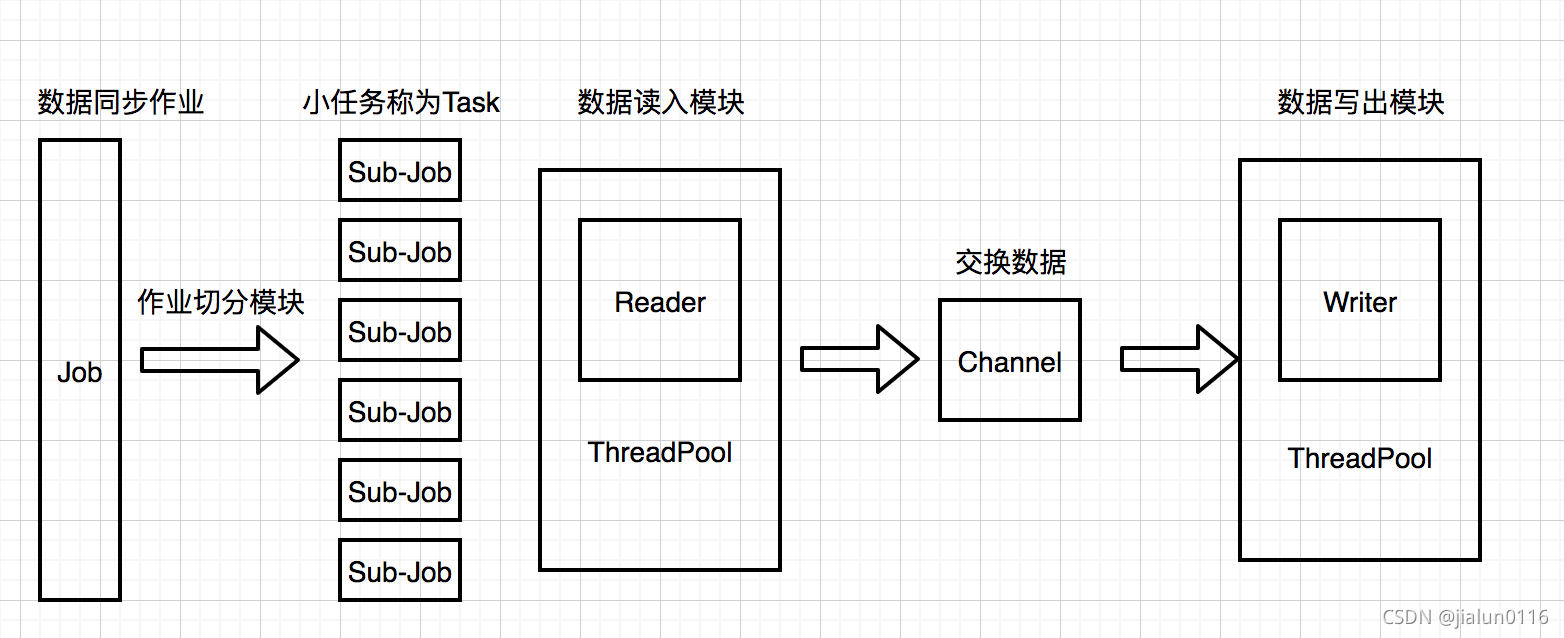
主要針對于離線型別的資料倉庫,定期批量同步,資料倉庫系統是集成各類資料源的地方,資料型別是統一的,需要將資料轉換為中間狀態,統一資料格式,由于是結構化的,支持標準的SQL查詢,所以所有的資料型別都可以轉換成字串型別,資料傳輸全記憶體操作,不讀寫磁盤,
3.2.2 實時資料同步
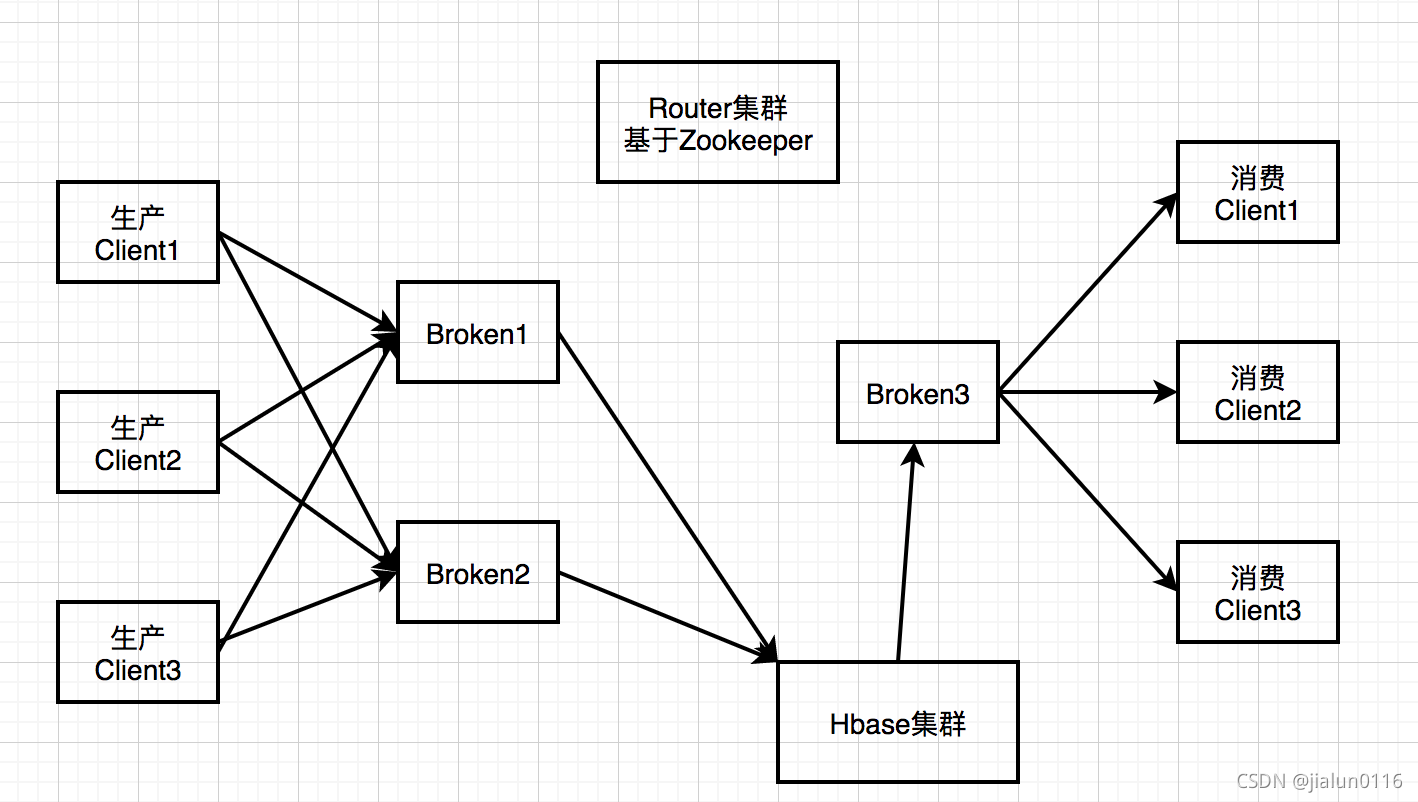
所產生的日志盡快以資料流的方式不斷同步到資料倉庫,實作秒級別的重繪,(可以通過決議Mysql的binlog日志來實時獲取增量的資料更新,通過訊息訂閱模式來實作資料的實時同步)
3.3 同步遇到的問題
3.3.1 分庫分表
為了使系統有靈活的擴展能力和高并發大資料量的處理能力,資料庫系統提供分庫分表方案,
我們需要一個分布式資料庫的訪問引擎,通過建立中間狀態的邏輯表來整合統一的分庫分表的訪問,
- 在持久層框架之下,JDBC驅動之上的中間件
- 與JDBC規范保持一致,解決規則引擎問題
- 實作了SQL決議、規則計算、表名替換、選擇執行單元并合并結果集的功能
- 解決讀寫分離和高性能主備切換的問題
3.3.2 增量全量同步的合并@
資料量比較大時,按周期全量同步的方式會影響處理效率,可以每次只同步新變更的增量資料,然后與上一個同步周期獲得的全量資料合并,從而獲得最新版本的全量資料,
傳統的資料整合方案,合并技術以merge方法為主(update+insert),現在大資料平臺基本不支持update,比較推薦全外連接(full outer join)+ 資料全量覆寫重新加載(insert overwrite),如日調度,當天的增量資料和前一天的全量資料做全外連接,重新加載最新全量資料,可以采用磁區方式,每天保存一個最新的全量版本,
提出了基于負載均衡思想的資料同步方案:
- 通過目標資料庫的元資料 估算 同步任務的總執行緒數
- 系統預先定義的期望同步速度 估算 首輪同步的執行緒數
- 業務優先級決定同步執行緒的優先級,
3.3.3 資料漂移的處理 @
資料漂移時ODS資料的一個頑疾,指ODS表中的同一個業務日期資料中包含前一天或者后一天凌晨附近的資料或者丟失當天的變更資料,
為什么會出現呢?ODS需要承接面向歷史的細節資料查詢需求,需要物理落地到資料倉庫的表按時間段來切分進行磁區存盤,通常按照某些時間戳欄位來切分,實際上由于時間戳欄位的準確性問題導致資料漂移
時間戳欄位分為四類:
- 資料庫表中用來標識資料記錄更新時間的時間戳欄位 ,modified_time
- 資料庫日志中用來標識資料記錄更新時間的時間戳欄位 ,log_time
- 資料庫表中用來記錄具體業務程序發生時間的時間戳欄位 ,proc_time
- 標識資料記錄被抽取到的時間戳欄位 ,extract_time
理論上這幾個時間應該一致,但是實際上會有差異
- 資料抽取需要時間,extract_time晚于前三個
- 前臺業務系統手工修正資料時未更新 modified_time
- 網路、系統壓力等問題,log_time或modified_time晚于proc_time
根據一個欄位來切分的問題
- extract_time限制,來獲取資料,漂移的問題最明顯
- modified_time限制,會出現不更新時間而導致的資料遺漏,資料記錄漂移到后一天
- log_time限制,網路、系統壓力等問題,晚于proc_time,資料記錄漂移到后一天
- proc_time限制,獲取到包含一個業務程序所產生的記錄,遺漏很多程序變化記錄,違背ODS和業務系統保持一致的設計原則
處理方法
- 多獲取后一天的資料,向后多冗余一些資料,具體時間按照不同業務場景用業務時間proc_time來限制,但是如果在第二天凌晨修改,這條訂單的狀態就會更新(可能多次更新),變得不準,
- 多個時間戳欄位來限制時間獲取相對準確,
舉例
雙11時,交易訂單漂移到12日,因為下單付錢的時候用支付寶的介面有延遲,導致訂單最終生產時間跨天了,log_time和modified_time晚于proc_time,
難點:如果訂單只有一個支付業務程序,可以用支付時間來限制就能獲取正確資料,但是訂單有多個業務程序“下單、支付、成功,每個程序都有相應的時間戳欄位,并不只有支付才會漂移,
解決方案:
- 根據實際情況獲取后一天15分鐘的資料,限制多個業務程序的時間戳欄位都是雙11當天的,按照主鍵根據log_time做升序排列去重,獲取每個訂單首次資料變更的那條記錄,
- 根據log_time冗余前一天最后15分鐘和后一天凌晨15分鐘的資料,用modified_time過濾非當天的資料,每個訂單按照log_time做降序排列,獲取每個訂單當天最后一次資料變更的那條記錄,
- 兩份資料按照訂單做全連接,把漂移資料補回當天資料中
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/356756.html
標籤:其他
下一篇:Hadoop學習之旅