認識elasticsearch
最近在做一個關于spark整合Elasticsearch的專案,閑暇時便在自己機器上安裝了一下elasticsearch集群,關于elasticserarch,這里簡單做一下介紹:它 是一個實時分布式搜索和分析引擎,它讓你以前所未有的速度處理大資料成為可能,它的底層是基于Lucene實作的一個搜索引擎,關于Lucene知識,我在四年前寫過幾篇文章,大家可以看一下,
Luncen介紹
Luncen分詞器的使用
安裝
環境: JDK1.7.55+
elasticsearch-2.3.1.tar.gz
- 安裝jdk(1.7.55以上)建議直接jdk1.8.20或更高
- 上傳elasticsearch-2.3.1.tar.gz安裝包
- 利用tar命令解壓到指定的目錄下
- 利用vim 修改config/elasticsearch.yml檔案,修改內容主要有一下幾點
a.#集群名稱,通過組播的方式通信,通過名稱判斷屬于哪個集群
cluster.name: bigdata(這里是集群名稱)
b.#節點名稱,要唯一
node.name: hadoop-master(這里填寫別名,一般寫自己的機器名即可)
c.#資料存放位置
path.data: /data/es/data (存放資料的路徑)
d.#日志存放位置 (這里也可不用修改,有一個默認位置)
path.logs: /data/es/logs
e.#es系結的ip地址
network.host: 192.168.2.852
f.#初始化時可進行選舉的節點 (這里填寫參加選舉的節點即可,我只有三臺,就全部列上去了)
discovery.zen.ping.unicast.hosts: ["hadoop-master", "hadoop-node1", "hadoop-node2"]
- 復制到其他主機,然后修改上邊改動的東西 network.host: node.name:等
scp -r elasticsearch-2.3.1 hadoop-node1:/usr/local/
scp -r elasticsearch-2.3.1 hadoop-node2:/usr/local/
- 啟動服務(多臺都要啟動)
/usr/local/elasticsearch-2.3.1/bin/elasticsearch -d
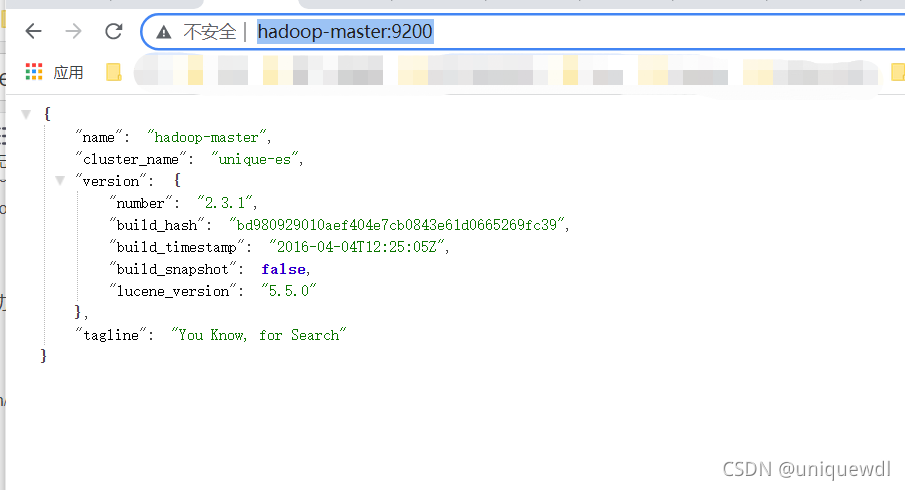
- 驗證
http://hadoop-master:9200/
安裝插件
上邊展示方式很不友好,所以需要一款圖形化界面來展示資料,這里我們需要下載一個壓縮包上傳到服務器elasticsearch-head-master.zip,然后通過離線安裝的方式來進行安裝插件,具體安裝方式如下:
1.上傳到指定位置
2.命令安裝 切換到bin目錄下
eg:./plugin install file:///home/bigdata/elasticsearch-head-master.zip
./plugin install file:///home/bigdata/elasticsearch-head-master.zip [插件上傳的目錄]
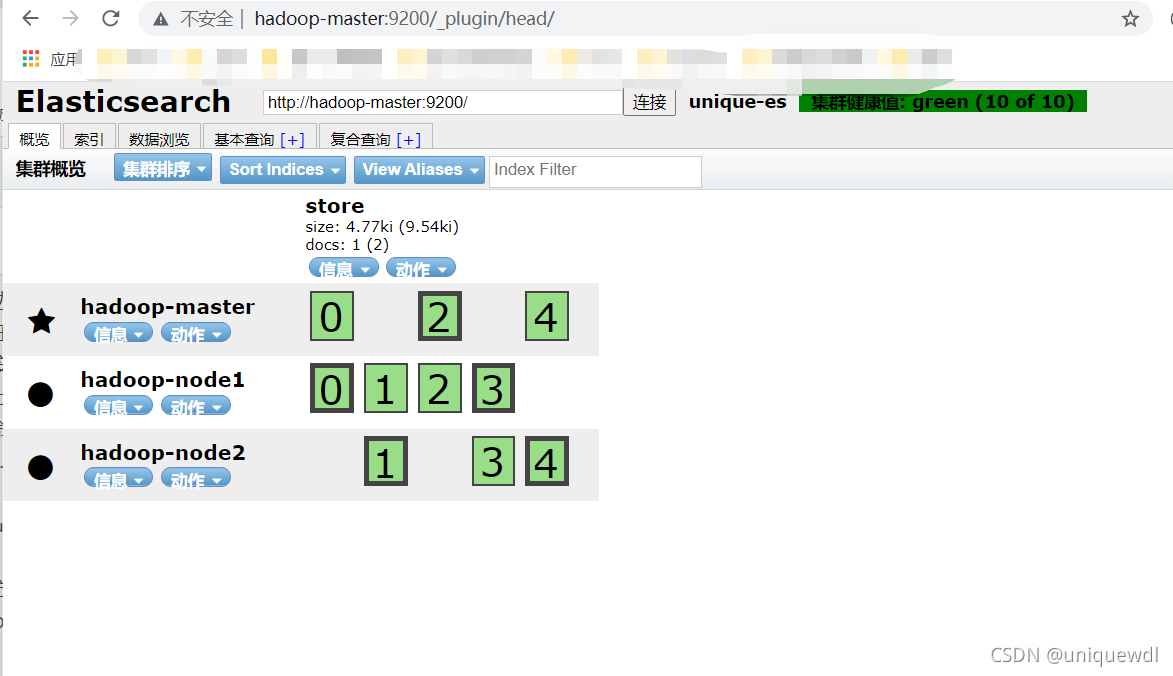
3.訪問瀏覽器可以看到管理頁面
http://hadoop-master:9200/_plugin/head
注意點
- 啟動elasticsearch不能用root賬號,我們可以通過如下操作來進行創建一個普通賬戶并授權.
- jdk版本盡量不要低于1.8
useradd unique
#為unique用戶添加密碼:
echo 123456 | passwd --stdin unique
#將unique添加到sudoers
echo "uniqueALL = (root) NOPASSWD:ALL" | tee /etc/sudoers.d/unique
chmod 0440 /etc/sudoers.d/unique
#解決sudo: sorry, you must have a tty to run sudo問題,在/etc/sudoer注釋掉 Default requiretty 一行
sudo sed -i 's/Defaults requiretty/Defaults:bigdata !requiretty/' /etc/sudoers
結束語
上述就是關于linux安裝elasticsearch集群的全部內容,如果有幫助大家可以點贊收藏,有條件的可以互粉一波哦,如有不足之處請指點,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357059.html
標籤:其他
下一篇:人工智能期末考試復習