文章目錄
- 1.HQL操作之DDL命令
- (1)資料庫操作
- (2)建表語法
- (3)內部表及外部表
- (4)磁區表
- (5)分桶表
- (6)修改表及洗掉表
- 5.HQL操作之資料操作
- (1)load裝載資料
- (2)insert插入資料
- 6.HQL操作之DQL命令
- (1)簡單查詢
- (2)簡單子句
- (3)group by分組子句
- (4)表連接
- (5)order by排序子句
- (6)sort by排序
- (7)distribute by和cluster by排序
1.HQL操作之DDL命令
Hive資料庫的層次如下:
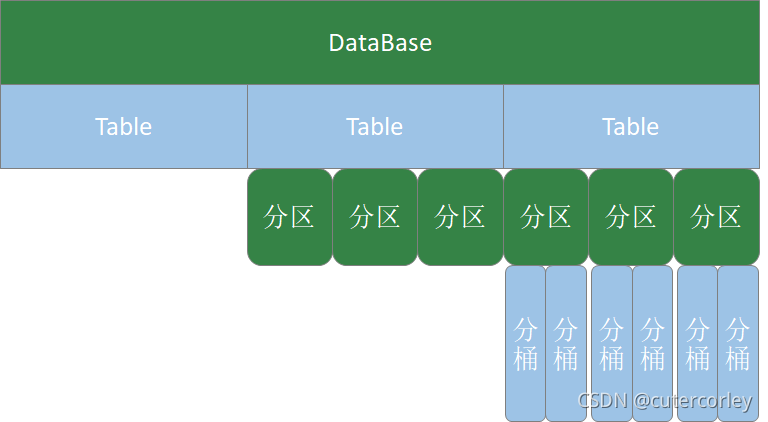
可以看到,一個資料庫可以包括多張表,一張表可以分為多個磁區,同時一個磁區還可以分為多個分桶,
DDL,即資料定義語言(data definition language),主要的操作包括CREATE、ALTER、DROP等,主要用來定義、修改資料庫物件的結構或資料型別,
要查看最完整的DDL官網命令,可以查看https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL,
(1)資料庫操作
Hive有一個默認的資料庫default,在操作HQL時,如果不明確要使用哪個庫,則使用默認資料庫,
Hive資料庫命名規則如下:
資料庫名、表名均不區分大小寫;
名字不能使用數字開頭;
不能使用關鍵字,盡量不使用特殊符號;
操作資料庫的完整語法如下:
-- 創建資料庫
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[MANAGEDLOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, ...)];
-- 查看資料庫
-- 查看所有資料庫
show database;
-- 查看資料庫資訊
desc database database_name;
desc database extended database_name;
describe database extended database_name;
-- 使用資料庫
use database_name;
-- 洗掉資料庫
-- 洗掉一個空資料庫
drop database databasename;
-- 如果資料庫不為空,使用cascade強制洗掉
drop database databasename cascade;
使用示意如下:
hive (default)> create database mydb;
OK
Time taken: 0.18 seconds
hive (default)> show databases;
OK
database_name
default
mydb
test1
Time taken: 0.049 seconds, Fetched: 3 row(s)
hive (default)> dfs -ls /user/hive/warehouse;
Found 3 items
drwxrwxrwx - root supergroup 0 2021-09-21 14:39 /user/hive/warehouse/mydb.db
drwxrwxrwx - root supergroup 0 2021-09-21 14:09 /user/hive/warehouse/s1
drwxrwxrwx - root supergroup 0 2021-09-20 18:52 /user/hive/warehouse/test1.db
hive (default)> create database if not exists mydb;
OK
Time taken: 0.078 seconds
hive (default)> create database if not exists mydb2
> comment 'this is my db2'
> location '/user/hive/mydb2.db';
OK
Time taken: 0.14 seconds
hive (default)> show databases;
OK
database_name
default
mydb
mydb2
test1
Time taken: 0.024 seconds, Fetched: 4 row(s)
hive (default)> use mydb;
OK
Time taken: 0.041 seconds
hive (mydb)> desc database mydb2;
OK
db_name comment location owner_name owner_type parameters
mydb2 this is my db2 hdfs://node01:9000/user/hive/mydb2.db root USER
Time taken: 0.029 seconds, Fetched: 1 row(s)
hive (mydb)> desc database extended mydb2;
OK
db_name comment location owner_name owner_type parameters
mydb2 this is my db2 hdfs://node01:9000/user/hive/mydb2.db root USER
Time taken: 0.025 seconds, Fetched: 1 row(s)
hive (mydb)> drop database test1;
OK
Time taken: 0.338 seconds
hive (mydb)> show databases;
OK
database_name
default
mydb
mydb2
Time taken: 0.021 seconds, Fetched: 3 row(s)
hive (mydb)> create table t1(id int);
OK
Time taken: 0.164 seconds
hive (mydb)> drop database mydb2 cascade;
OK
Time taken: 0.083 seconds
hive (mydb)> show databases;
OK
database_name
default
mydb
Time taken: 0.049 seconds, Fetched: 2 row(s)
hive (mydb)> show tables;
OK
tab_name
t1
Time taken: 0.032 seconds, Fetched: 1 row(s)
hive (mydb)>
可以看到,創建資料庫可以通過選項設定備注和自定義存放路徑;
在洗掉資料庫時,如果資料庫不為空,則不能直接洗掉,而要使用cascade指定強制洗掉,
(2)建表語法
Hive中創建表的語法如下:
-- as方式
create [external] table [IF NOT EXISTS] table_name
[(colName colType [comment 'comment'], ...)]
[comment table_comment]
[partition by (colName colType [comment col_comment], ...)]
[clustered BY (colName, colName, ...)
[sorted by (col_name [ASC|DESC], ...)] into num_buckets
buckets]
[row format row_format]
[stored as file_format]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)]
[AS select_statement];
-- like方式
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS]
[db_name.]table_name
LIKE existing_table_or_view_name
[LOCATION hdfs_path];
其中,各部分的含義如下:
| 關鍵字 | 含義 |
|---|---|
| CREATE TABLE | 按給定名稱創建表,如果表已經存在則拋出例外,可使用if not exists規避 |
| EXTERNAL | 創建外部表,否則創建的是內部表(管理表): 洗掉內部表時,資料和表的定義同時被洗掉; 洗掉外部表時,僅僅洗掉了表的定義,資料保留, 在生產環境中,多使用外部表, |
| comment | 表的注釋 |
| partition by | 對表中資料進行磁區,指定表的磁區欄位 |
| clustered by | 創建分桶表,指定分桶欄位 |
| sorted by | 對桶中的一個或多個列排序,較少使用 |
| ROW FORMAT DELIMITED | 存盤子句: 建表時可指定SerDe; 如果沒有指定ROW FORMAT或者ROW FORMAT DELIMITED,將會使用默認的 SerDe; 建表時還需要為表指定列,在指定列的同時也會指定自定義的SerDe; Hive通過SerDe確定表的具體的列的資料 |
| stored as SEQUENCEFILE | TEXTFILE |
| LOCATION | 表在HDFS上的存放位置 |
| TBLPROPERTIES | 定義表的屬性 |
| AS | 后面可以接查詢陳述句,表示根據后面的查詢結果創建表 |
| LIKE | like 表名,允許用戶復制現有的表結構,但是不復制資料 |
其中,存盤子句用于建表時指定SerDe,格式如下:
ROW FORMAT DELIMITED
-- 欄位分隔符
[FIELDS TERMINATED BY char]
-- 集合分隔符
[COLLECTION ITEMS TERMINATED BY char]
-- map的鍵值分隔符
[MAP KEYS TERMINATED BY char]
-- 行分隔符
[LINES TERMINATED BY char] | SERDE serde_name
[WITH SERDEPROPERTIES (property_name=property_value,
property_name=property_value, ...)]
SerDe是Serialize/Deserilize的簡稱,Hive使用Serde進行行物件的序列與反序列化;
如果沒有指定ROW FORMAT或者ROW FORMATDELIMITED,將會使用默認的SerDe;
建表時還需要為表指定列,在指定列的同時也會指定自定義的SerDe,Hive通過SerDe確定表的具體的列的資料,
(3)內部表及外部表
在創建表的時候,可指定表的型別,表有兩種型別,分別是內部表(管理表)、外部表:
默認情況下(不指定external關鍵字),創建內部表,如果要創建外部表,需要使用關鍵字external;
在洗掉內部表時,表的定義(元資料)和資料同時被洗掉;
在洗掉外部表時,僅洗掉表的定義,資料被保留;
在生產環境中,多使用外部表,
在測驗表之前,準備資料,vim /home/hadoop/data/t1.dat,輸入以下內容:
2;zhangsan;book,TV,code;beijing:chaoyang,shagnhai:pudong
3;lishi;book,code;nanjing:jiangning,taiwan:taibei
4;wangwu;music,book;heilongjiang:haerbin
先測驗內部表:
hive (default)> use mydb;
OK
Time taken: 0.034 seconds
hive (mydb)> show tables;
OK
tab_name
Time taken: 0.026 seconds
-- 創建內部表
hive (mydb)> create table t1(
> id int,
> name string,
> hobby array<string>,
> addr map<string, string>
> )
> row format delimited
> fields terminated by ";"
> collection items terminated by ","
> map keys terminated by ":"
> ;
OK
Time taken: 0.156 seconds
hive (mydb)> show tables;
OK
tab_name
t1
Time taken: 0.031 seconds, Fetched: 1 row(s)
-- 顯示表的定義,顯示的資訊較少
hive (mydb)> desc t1;
OK
col_name data_type comment
id int
name string
hobby array<string>
addr map<string,string>
Time taken: 0.064 seconds, Fetched: 4 row(s)
-- 顯示表的定義,顯示的資訊多,格式友好
hive (mydb)> desc formatted t1;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
hobby array<string>
addr map<string,string>
# Detailed Table Information
Database: mydb
Owner: root
CreateTime: Wed Sep 22 17:02:03 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://node01:9000/user/hive/warehouse/mydb.db/t1
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1632301323
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim ,
field.delim ;
mapkey.delim :
serialization.format ;
Time taken: 0.089 seconds, Fetched: 36 row(s)
-- 加載資料
hive (mydb)> load data local inpath "/home/hadoop/data/t1.dat" into table t1;
Loading data to table mydb.t1
OK
Time taken: 0.461 seconds
-- 查詢資料
hive (mydb)> select * from t1;
OK
t1.id t1.name t1.hobby t1.addr
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"}
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"}
4 wangwu ["music","book"] {"heilongjiang":"haerbin"}
Time taken: 0.169 seconds, Fetched: 3 row(s)
-- 查看資料檔案
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t1;
Found 1 items
-rwxrwxrwx 3 root supergroup 148 2021-09-22 17:02 /user/hive/warehouse/mydb.db/t1/t1.dat
hive (mydb)> dfs -cat /user/hive/warehouse/mydb.db/t1/t1.dat;
2;zhangsan;book,TV,code;beijing:chaoyang,shagnhai:pudong
3;lishi;book,code;nanjing:jiangning,taiwan:taibei
4;wangwu;music,book;heilongjiang:haerbin
-- 洗掉表,表和資料同時被洗掉
hive (mydb)> drop table t1;
OK
Time taken: 0.198 seconds
hive (mydb)> show tables;
OK
tab_name
Time taken: 0.025 seconds
-- 再次查詢資料檔案,已經被洗掉
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t1;
ls: `/user/hive/warehouse/mydb.db/t1': No such file or directory
Command -ls /user/hive/warehouse/mydb.db/t1 failed with exit code = 1
Query returned non-zero code: 1, cause: null
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/;
hive (mydb)>
可以看到,在創建內部表時,型別是MANAGED_TABLE;
在洗掉內部表之后,不僅表的定義被洗掉,資料(表HDFS中對應的檔案)也被洗掉,
再測驗使用外部表:
hive (mydb)> create external table t2(
> id int,
> name string,
> hobby array<string>,
> addr map<string, string>
> )
> row format delimited
> fields terminated by ";"
> collection items terminated by ","
> map keys terminated by ":"
> ;
OK
Time taken: 0.19 seconds
hive (mydb)> show tables;
OK
tab_name
t2
Time taken: 0.044 seconds, Fetched: 1 row(s)
hive (mydb)> desc formatted t2;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
hobby array<string>
addr map<string,string>
# Detailed Table Information
Database: mydb
Owner: root
CreateTime: Wed Sep 22 17:12:16 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://node01:9000/user/hive/warehouse/mydb.db/t2
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
EXTERNAL TRUE
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1632301936
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim ,
field.delim ;
mapkey.delim :
serialization.format ;
Time taken: 0.075 seconds, Fetched: 37 row(s)
hive (mydb)> load data local inpath "/home/hadoop/data/t1.dat" into table t1;
FAILED: SemanticException [Error 10001]: Line 1:61 Table not found 't1'
hive (mydb)> load data local inpath "/home/hadoop/data/t1.dat" into table t2;
Loading data to table mydb.t2
OK
Time taken: 0.463 seconds
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t2;
Found 1 items
-rwxrwxrwx 3 root supergroup 148 2021-09-22 17:15 /user/hive/warehouse/mydb.db/t2/t1.dat
hive (mydb)> dfs -cat /user/hive/warehouse/mydb.db/t2/t1.dat;
2;zhangsan;book,TV,code;beijing:chaoyang,shagnhai:pudong
3;lishi;book,code;nanjing:jiangning,taiwan:taibei
4;wangwu;music,book;heilongjiang:haerbin
hive (mydb)> select * from t2;
OK
t2.id t2.name t2.hobby t2.addr
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"}
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"}
4 wangwu ["music","book"] {"heilongjiang":"haerbin"}
Time taken: 0.192 seconds, Fetched: 3 row(s)
hive (mydb)> drop table t2;
OK
Time taken: 0.239 seconds
hive (mydb)> show tables;
OK
tab_name
Time taken: 0.022 seconds
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t2;
Found 1 items
-rwxrwxrwx 3 root supergroup 148 2021-09-22 17:15 /user/hive/warehouse/mydb.db/t2/t1.dat
hive (mydb)> dfs -cat /user/hive/warehouse/mydb.db/t2/t1.dat;
2;zhangsan;book,TV,code;beijing:chaoyang,shagnhai:pudong
3;lishi;book,code;nanjing:jiangning,taiwan:taibei
4;wangwu;music,book;heilongjiang:haerbin
hive (mydb)>
可以看到,創建了外部表后,查看表的詳細資訊時,表型別是EXTERNAL_TABLE;
同時在洗掉表之后,只是洗掉了表定義,并沒有洗掉表的資料,
內部表和外部表之間還可以進行轉換,
使用如下:
hive (mydb)> create table t1(
> id int,
> name string,
> hobby array<string>,
> addr map<string, string>
> )
> row format delimited
> fields terminated by ";"
> collection items terminated by ","
> map keys terminated by ":"
> ;
OK
Time taken: 0.111 seconds
hive (mydb)> desc formatted t1;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
hobby array<string>
addr map<string,string>
# Detailed Table Information
Database: mydb
Owner: root
CreateTime: Wed Sep 22 17:25:55 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://node01:9000/user/hive/warehouse/mydb.db/t1
Table Type: MANAGED_TABLE
Table Parameters:
...
Time taken: 0.075 seconds, Fetched: 36 row(s)
hive (mydb)> alter table t1 set tblproperties("EXTERNAL"="TRUE");
OK
Time taken: 0.176 seconds
hive (mydb)> desc formatted t1;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
hobby array<string>
addr map<string,string>
# Detailed Table Information
Database: mydb
Owner: root
CreateTime: Wed Sep 22 17:25:55 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://node01:9000/user/hive/warehouse/mydb.db/t1
Table Type: EXTERNAL_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
EXTERNAL TRUE
last_modified_by root
last_modified_time 1632302837
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1632302837
# Storage Information
...
Time taken: 0.062 seconds, Fetched: 39 row(s)
hive (mydb)> alter table t1 set tblproperties("EXTERNAL"="FALSE");
OK
Time taken: 0.111 seconds
hive (mydb)> desc formatted t1;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
hobby array<string>
addr map<string,string>
# Detailed Table Information
Database: mydb
Owner: root
CreateTime: Wed Sep 22 17:25:55 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://node01:9000/user/hive/warehouse/mydb.db/t1
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
EXTERNAL FALSE
last_modified_by root
last_modified_time 1632302857
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1632302857
# Storage Information
...
Time taken: 0.072 seconds, Fetched: 39 row(s)
hive (mydb)> drop table t1;
OK
Time taken: 0.114 seconds
hive (mydb)> show tables;
OK
tab_name
Time taken: 0.033 seconds
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/;
Found 1 items
drwxrwxrwx - root supergroup 0 2021-09-22 17:15 /user/hive/warehouse/mydb.db/t2
hive (mydb)>
可以看到,實作了兩種表型別之間的轉換,
綜上,想保留外部表時使用外部表,并且生產中多用外部表,
(4)磁區表
Hive在執行查詢時,一般會掃描整個表的資料,由于表的資料量大,全表掃描消耗時間長、效率低,
而有時候,查詢只需要掃描表中的一部分資料即可,Hive引入了磁區表的概念,將表的資料存盤在不同的子目錄中,每一個子目錄對應一個磁區,只查詢部分磁區資料時,可避免全表掃描,提高查詢效率,
在實際中,通常根據時間、地區等資訊進行磁區,
現在使用如下:
先進行磁區表創建與資料加載:
-- 創建表
hive (mydb)> create table t3(
> id int,
> name string,
> hobby array<string>,
> addr map<string, string>
> )
> partitioned by (dt string)
> row format delimited
> fields terminated by ";"
> collection items terminated by ","
> map keys terminated by ":"
> ;
OK
Time taken: 0.702 seconds
hive (mydb)> desc formatted t3;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
hobby array<string>
addr map<string,string>
# Partition Information
# col_name data_type comment
dt string
# Detailed Table Information
Database: mydb
Owner: root
CreateTime: Thu Sep 23 02:46:32 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://node01:9000/user/hive/warehouse/mydb.db/t3
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 0
numPartitions 0
numRows 0
rawDataSize 0
totalSize 0
transient_lastDdlTime 1632336392
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -1
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
colelction.delim ,
field.delim ;
mapkey.delim :
serialization.format ;
Time taken: 0.58 seconds, Fetched: 42 row(s)
-- 加載資料
hive (mydb)> load data local inpath "/home/hadoop/data/t1.dat" into table t3 partition(dt="2021-09-22");
Loading data to table mydb.t3 partition (dt=2021-09-22)
OK
Time taken: 1.841 seconds
hive (mydb)> load data local inpath "/home/hadoop/data/t1.dat" into table t3 partition(dt="2021-09-23");
Loading data to table mydb.t3 partition (dt=2021-09-23)
OK
Time taken: 0.63 seconds
hive (mydb)> select * from t3;
OK
t3.id t3.name t3.hobby t3.addr t3.dt
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-22
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-22
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-22
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-23
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-23
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-23
Time taken: 3.712 seconds, Fetched: 6 row(s)
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t3;
Found 2 items
drwxrwxrwx - root supergroup 0 2021-09-23 02:47 /user/hive/warehouse/mydb.db/t3/dt=2021-09-22
drwxrwxrwx - root supergroup 0 2021-09-23 02:47 /user/hive/warehouse/mydb.db/t3/dt=2021-09-23
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t3/dt=2021-09-22;
Found 1 items
-rwxrwxrwx 3 root supergroup 148 2021-09-23 02:47 /user/hive/warehouse/mydb.db/t3/dt=2021-09-22/t1.dat
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t3/dt=2021-09-23;
Found 1 items
-rwxrwxrwx 3 root supergroup 148 2021-09-23 02:47 /user/hive/warehouse/mydb.db/t3/dt=2021-09-23/t1.dat
hive (mydb)> show partitions t3;
OK
partition
dt=2021-09-22
dt=2021-09-23
Time taken: 0.132 seconds, Fetched: 2 row(s)
-- 新增磁區
hive (mydb)> alter table t3
> add partition(dt="2021-09-24");
OK
Time taken: 0.274 seconds
hive (mydb)> alter table t3
> add partition(dt="2021-09-25");
OK
Time taken: 0.186 seconds
hive (mydb)> show partitions t3;
OK
partition
dt=2021-09-22
dt=2021-09-23
dt=2021-09-24
dt=2021-09-25
Time taken: 0.107 seconds, Fetched: 4 row(s)
可以看到,如果表設定了磁區,會在表的詳細資訊中展示出來;
查詢資料時也顯示了每條記錄的磁區,但是磁區欄位不是表中已經存在的資料,可以將磁區欄位看成偽列,
再指定資料路徑新增磁區,如下:
-- 準備資料
hive (mydb)> dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2021-09-22 /user/hive/warehouse/mydb.db/t3/dt=2021-09-26;
hive (mydb)> dfs -cp /user/hive/warehouse/mydb.db/t3/dt=2021-09-22 /user/hive/warehouse/mydb.db/t3/dt=2021-09-27;
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/t3/;
Found 6 items
drwxrwxrwx - root supergroup 0 2021-09-23 02:47 /user/hive/warehouse/mydb.db/t3/dt=2021-09-22
drwxrwxrwx - root supergroup 0 2021-09-23 02:47 /user/hive/warehouse/mydb.db/t3/dt=2021-09-23
drwxrwxrwx - root supergroup 0 2021-09-23 02:50 /user/hive/warehouse/mydb.db/t3/dt=2021-09-24
drwxrwxrwx - root supergroup 0 2021-09-23 02:51 /user/hive/warehouse/mydb.db/t3/dt=2021-09-25
drwxr-xr-x - root supergroup 0 2021-09-23 02:53 /user/hive/warehouse/mydb.db/t3/dt=2021-09-26
drwxr-xr-x - root supergroup 0 2021-09-23 02:53 /user/hive/warehouse/mydb.db/t3/dt=2021-09-27
-- 指定路徑設定磁區
hive (mydb)> alter table t3
> add partition(dt="2021-09-26") location '/user/hive/warehouse/mydb.db/t3/dt=2021-09-26';
OK
Time taken: 0.138 seconds
hive (mydb)> select * from t3;
OK
t3.id t3.name t3.hobby t3.addr t3.dt
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-22
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-22
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-22
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-23
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-23
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-23
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-26
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-26
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-26
Time taken: 0.323 seconds, Fetched: 9 row(s)
-- 修改磁區的HDFS路徑
hive (mydb)> alter table t3 partition(dt="2021-09-26") set location "/user/hive/warehouse/mydb.db/t3/dt=2021-09-27";
OK
Time taken: 0.269 seconds
hive (mydb)> select * from t3;
OK
t3.id t3.name t3.hobby t3.addr t3.dt
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-22
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-22
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-22
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-23
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-23
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-23
2 zhangsan ["book","TV","code"] {"beijing":"chaoyang","shagnhai":"pudong"} 2021-09-26
3 lishi ["book","code"] {"nanjing":"jiangning","taiwan":"taibei"} 2021-09-26
4 wangwu ["music","book"] {"heilongjiang":"haerbin"} 2021-09-26
Time taken: 0.263 seconds, Fetched: 9 row(s)
hive (mydb)> show partitions t3;
OK
partition
dt=2021-09-22
dt=2021-09-23
dt=2021-09-24
dt=2021-09-25
dt=2021-09-26
Time taken: 0.133 seconds, Fetched: 5 row(s)
-- 洗掉磁區
hive (mydb)> alter table t3 drop partition(dt="2021-09-24");
Dropped the partition dt=2021-09-24
OK
Time taken: 0.57 seconds
hive (mydb)> alter table t3 drop partition(dt="2021-09-25"), partition(dt="2021-09-26");
Dropped the partition dt=2021-09-25
Dropped the partition dt=2021-09-26
OK
Time taken: 0.273 seconds
hive (mydb)> show partitions t3;
OK
partition
dt=2021-09-22
dt=2021-09-23
Time taken: 0.079 seconds, Fetched: 2 row(s)
hive (mydb)>
洗掉多個磁區時,用逗號隔開,
(5)分桶表
當單個的磁區或者表的資料量過大,磁區不能更細粒度的劃分資料,就需要使用分桶技術將資料劃分成更細的粒度,將資料按照指定的欄位進行分成多個桶中去,即將資料按照欄位進行劃分,資料按照欄位劃分到多個檔案當中去,
Hive中分桶的原理是分桶欄位.hashCode % 分桶個數,這與MapReduce中Shuffle時磁區的規則是類似的,即key.hashCode % reductTask,
使用如下:
-- 創建分桶表
hive (mydb)> create table course(
> id int,
> name string,
> score int
> )
> clustered by (id) into 3 buckets
> row format delimited fields terminated by "\t";
OK
Time taken: 0.105 seconds
-- 創建普通表
hive (mydb)> create table course_common(
> id int,
> name string,
> score int
> )
> row format delimited fields terminated by "\t";
OK
Time taken: 0.133 seconds
-- 普通表加載資料
hive (mydb)> load data local inpath "/home/hadoop/data/course.dat" into table course_common;
Loading data to table mydb.course_common
OK
Time taken: 0.55 seconds
hive (mydb)> select * from course_common;
OK
course_common.id course_common.name course_common.score
1 java 90
1 c 78
1 python 91
1 hadoop 80
2 java 75
2 c 76
2 python 80
2 hadoop 93
3 java 98
3 c 74
3 python 89
3 hadoop 91
5 java 93
6 c 76
7 python 87
8 hadoop 88
Time taken: 0.244 seconds, Fetched: 16 row(s)
-- 給桶表加載資料
hive (mydb)> insert into table course select * from course_common;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20210923033603_53b34c32-c8b7-4d73-ac85-f8419ca26678
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 3
...
Stage-Stage-1: Map: 1 Reduce: 3 Cumulative CPU: 9.18 sec HDFS Read: 16039 HDFS Write: 365 SUCCESS
Total MapReduce CPU Time Spent: 9 seconds 180 msec
OK
course_common.id course_common.name course_common.scorem
Time taken: 52.252 seconds
hive (mydb)> desc formatted course;
OK
col_name data_type comment
# col_name data_type comment
id int
name string
score int
# Detailed Table Information
Database: mydb
Owner: root
CreateTime: Thu Sep 23 03:34:14 CST 2021
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://node01:9000/user/hive/warehouse/mydb.db/course
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 3
numRows 16
rawDataSize 148
totalSize 164
transient_lastDdlTime 1632339416
# Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: 3
Bucket Columns: [id]
Sort Columns: []
Storage Desc Params:
field.delim \t
serialization.format \t
Time taken: 0.096 seconds, Fetched: 33 row(s)
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/course;
Found 3 items
-rwxrwxrwx 3 root supergroup 48 2021-09-23 03:36 /user/hive/warehouse/mydb.db/course/000000_0
-rwxrwxrwx 3 root supergroup 53 2021-09-23 03:36 /user/hive/warehouse/mydb.db/course/000001_0
-rwxrwxrwx 3 root supergroup 63 2021-09-23 03:36 /user/hive/warehouse/mydb.db/course/000002_0
-- 觀察分桶資料
hive (mydb)> dfs -cat /user/hive/warehouse/mydb.db/course/000000_0;
3 hadoop 91
3 python 89
3 c 74
3 java 98
6 c 76
hive (mydb)> dfs -cat /user/hive/warehouse/mydb.db/course/000001_0;
7 python 87
1 hadoop 80
1 python 91
1 c 78
1 java 90
hive (mydb)> dfs -cat /user/hive/warehouse/mydb.db/course/000002_0;
8 hadoop 88
5 java 93
2 python 80
2 c 76
2 java 75
2 hadoop 93
hive (mydb)>
可以看到,在創建分桶表之后,也可以從表的詳細資訊獲取到分桶的資訊;
并且,不能直接向分桶表中添加資料,而需要使用insert ... select ...從普通表中匯入資料;
同時,分桶的規則是分桶欄位.hashCode % 分桶數,這里設定的分桶個數是3,所以對分桶欄位的哈希碼值進行對3求余、進入不同的桶;
從Hive 2.x開始,不需要設定引數hive.enforce.bucketing=true即可支持分桶,
(6)修改表及洗掉表
HIve修改和洗掉表的操作如下:
-- 修改表名,rename
hive (mydb)> alter table course_common rename to course1;
OK
Time taken: 0.163 seconds
-- 修改列名,change column
hive (mydb)> alter table course1
> change column id cid int;
OK
Time taken: 0.139 seconds
-- 修改欄位型別,change column
hive (mydb)> alter table course1
> change column cid cid string;
OK
Time taken: 0.128 seconds
-- string不能轉為int
hive (mydb)> alter table course1
> change column cid cid int;
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. Unable to alter table. The following columns have types incompatible with the existing columns in their respective positions :
cid
hive (mydb)> desc course1;
OK
col_name data_type comment
cid string
name string
score int
Time taken: 0.16 seconds, Fetched: 3 row(s)
-- 增加欄位,add columns
hive (mydb)> alter table course1
> add columns(common string);
OK
Time taken: 0.168 seconds
hive (mydb)> select * from course1;
OK
course1.cid course1.name course1.score course1.common
1 java 90 NULL
1 c 78 NULL
1 python 91 NULL
1 hadoop 80 NULL
2 java 75 NULL
2 c 76 NULL
2 python 80 NULL
2 hadoop 93 NULL
3 java 98 NULL
3 c 74 NULL
3 python 89 NULL
3 hadoop 91 NULL
5 java 93 NULL
6 c 76 NULL
7 python 87 NULL
8 hadoop 88 NULL
Time taken: 1.531 seconds, Fetched: 16 row(s)
-- 洗掉欄位,replace columns
hive (mydb)> alter table course1
> replace columns(
> cid string, cname string, cscore int);
OK
Time taken: 0.297 seconds
hive (mydb)> desc course1;
OK
col_name data_type comment
cid string
cname string
cscore int
Time taken: 0.133 seconds, Fetched: 3 row(s)
-- 洗掉表
hive (mydb)> drop table course1;
OK
Time taken: 0.157 seconds
hive (mydb)> show tables;
OK
tab_name
course
t3
Time taken: 0.071 seconds, Fetched: 2 row(s)
hive (mydb)>
需要注意,修改欄位資料型別時,要滿足資料型別轉換的要求,如int可以轉為string,但是string不能轉為int;
洗掉欄位使用replace columns,僅僅只是在元資料中洗掉了欄位,并沒有改動HDFS上的資料檔案,
可以對Hive DDL總結如下:
主要操作物件是資料庫和表 ;
表的分類:
| 表型別 | 特點 |
|---|---|
| 內部表 | 洗掉表時,同時洗掉元資料和表資料 |
| 外部表 | 洗掉表時,僅洗掉元資料,保留表中資料;生產環境多使用外部表 |
| 磁區表 | 按照磁區欄位將表中的資料放置在不同的目錄中,提高SQL查詢的性能 |
| 分桶表 | 按照分桶欄位,將表中資料分開;分桶規則是分桶欄位.hashCode % 分桶數 |
主要命令包括create、alter 、drop,
5.HQL操作之資料操作
(1)load裝載資料
資料匯入有4種方式:
-
裝載資料(load)
-
插入資料(insert)
-
創建表并插入資料(as select)
-
使用import匯入資料
裝載資料(load)的基本語法如下:
LOAD DATA [LOCAL] INPATH 'filepath'
[OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1,
partcol2=val2 ...)]
其中,各部分的含義如下:
| 關鍵字 | 含義 |
|---|---|
| LOCAL | LOAD DATA LOCAL …:從本地檔案系統加載資料到Hive表中,本地檔案會拷貝到Hive表指定的位置; LOAD DATA …:從HDFS加載資料到Hive表中,HDFS檔案移動到Hive表指定的位置 |
| INPATH | 加載資料的路徑 |
| OVERWRITE | 覆寫表中已有資料;否則表示追加資料 |
| PARTITION | 將資料加載到指定的磁區INPATH |
現在進行測驗,先進行準備作業,準備資料檔案vim /home/hadoop/data/sourceA.txt,內容如下:
1,fish1,SZ
2,fish2,SH
3,fish3,HZ
4,fish4,QD
5,fish5,SR
再將其上傳到HDFS中,如下:
[root@node03 ~]$ hdfs dfs -mkdir -p /user/hadoop/data/
[root@node03 ~]$ hdfs dfs -put /home/hadoop/data/sourceA.txt /user/hadoop/data/
# Hive中創建資料檔案
[root@node03 ~]$ hdfs dfs -mkdir /user/hive/tabB;
[root@node03 ~]$ hdfs dfs -put /home/hadoop/data/sourceA.txt /user/hive/tabB
Hive中操作如下:
-- 創建表
hive (mydb)> CREATE TABLE tabA (
> id int
> ,name string
> ,area string
> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
OK
Time taken: 0.085 seconds
-- 加載本地檔案到Hive
hive (mydb)> load data local inpath '/home/hadoop/data/sourceA.txt'
> into table tabA;
Loading data to table mydb.taba
OK
Time taken: 0.31 seconds
-- 檢查本地檔案,仍然存在
hive (mydb)> select * from tabA;
OK
taba.id taba.name taba.area
1 fish1 SZ
2 fish2 SH
3 fish3 HZ
4 fish4 QD
5 fish5 SR
Time taken: 0.259 seconds, Fetched: 5 row(s)
-- 加載HDFS檔案到Hive
hive (mydb)> load data inpath '/user/hadoop/data/sourceA.txt'
> into table tabA;
Loading data to table mydb.taba
OK
Time taken: 0.449 seconds
-- 檢查HDFS檔案系統,檔案已經不存在
hive (mydb)> select * from tabA;
OK
taba.id taba.name taba.area
1 fish1 SZ
2 fish2 SH
3 fish3 HZ
4 fish4 QD
5 fish5 SR
1 fish1 SZ
2 fish2 SH
3 fish3 HZ
4 fish4 QD
5 fish5 SR
Time taken: 0.25 seconds, Fetched: 10 row(s)
-- 加載資料覆寫表中已有資料
hive (mydb)> load data local inpath '/home/hadoop/data/sourceA.txt'
> overwrite into table tabA;
Loading data to table mydb.taba
OK
Time taken: 0.362 seconds
hive (mydb)> select * from tabA;
OK
taba.id taba.name taba.area
1 fish1 SZ
2 fish2 SH
3 fish3 HZ
4 fish4 QD
5 fish5 SR
Time taken: 0.148 seconds, Fetched: 5 row(s)
-- 創建表時加載資料
hive (mydb)> CREATE TABLE tabB (
> id int,
> name string,
> area string
> ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
> location '/user/hive/tabB';
OK
Time taken: 0.129 seconds
hive (mydb)> select * from tabB;
OK
tabb.id tabb.name tabb.area
1 fish1 SZ
2 fish2 SH
3 fish3 HZ
4 fish4 QD
5 fish5 SR
Time taken: 0.182 seconds, Fetched: 5 row(s)
hive (mydb)>
再查看本地,如下:
[root@node03 ~]$ ls /home/hadoop/data/
course.dat s1.dat sourceA.txt t1.dat
[root@node03 ~]$ hdfs dfs -ls /user/hadoop/data
[root@node03 ~]$
可以看到,從檔案中加載資料后,本地檔案還在,但是HDFS檔案已經不存在于原路徑下;
使用overwrite加載資料時,資料表中原來的資料都會被清空,
(2)insert插入資料
insert插入資料,使用如下:
-- 創建磁區表
hive (mydb)> create table tabC(
> id int, name string, area string)
> partitioned by(month string);
OK
Time taken: 0.524 seconds
hive (mydb)> desc tabC;
OK
col_name data_type comment
id int
name string
area string
month string
# Partition Information
# col_name data_type comment
month string
Time taken: 0.733 seconds, Fetched: 9 row(s)
-- 插入單條資料
hive (mydb)> insert into tabC
> partition(month="202109")
> values(1, "Corley", "Beijing");
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_col0 _col1 _col2
Time taken: 6.384 seconds
hive (mydb)> select * from tabC;
OK
tabc.id tabc.name tabc.area tabc.month
1 Corley Beijing 202109
Time taken: 0.263 seconds, Fetched: 1 row(s)
-- 插入多條資料
hive (mydb)> insert into tabC
> partition(month="202109")
> values(2, "Jack", "Tianjin"), (3, "Bob", "Shanghai");
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_col0 _col1 _col2
Time taken: 2.749 seconds
hive (mydb)> select * from tabC;
OK
tabc.id tabc.name tabc.area tabc.month
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
Time taken: 0.362 seconds, Fetched: 3 row(s)
-- 插入查詢的結果資料
hive (mydb)> insert into tabC
> partition(month="202110")
> select id, name, area from tabC;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
id name area
Time taken: 2.727 seconds
hive (mydb)> select * from tabC;
OK
tabc.id tabc.name tabc.area tabc.month
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
1 Corley Beijing 202110
2 Jack Tianjin 202110
3 Bob Shanghai 202110
Time taken: 0.235 seconds, Fetched: 6 row(s)
-- 多表(多磁區)插入模式
hive (mydb)> from tabC
> insert overwrite table tabC partition(month="202111")
> select id, name ,area where month="202109"
> insert overwrite table tabC partition(month="202112")
> select id, name ,area where month="202109" or month="202110";
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
id name area
Time taken: 3.771 seconds
hive (mydb)> select * from tabC;
OK
tabc.id tabc.name tabc.area tabc.month
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
1 Corley Beijing 202110
2 Jack Tianjin 202110
3 Bob Shanghai 202110
1 Corley Beijing 202111
2 Jack Tianjin 202111
3 Bob Shanghai 202111
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
Time taken: 0.244 seconds, Fetched: 15 row(s)
hive (mydb)>
insert插入資料有3種方式:
-
手動插入單挑或多條資料
-
使用查詢結果資料作為插入資料
-
多表(多磁區)插入模式
還可以使用as select在創建表時插入資料:
-- 根據查詢結果創建表
hive (mydb)> create table if not exists tabD
> as select * from tabC;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 1 seconds 590 msec
OK
tabc.id tabc.name tabc.area tabc.month
Time taken: 37.142 seconds
hive (mydb)> select * from tabD;
OK
tabd.id tabd.name tabd.area tabd.month
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
1 Corley Beijing 202110
2 Jack Tianjin 202110
3 Bob Shanghai 202110
1 Corley Beijing 202111
2 Jack Tianjin 202111
3 Bob Shanghai 202111
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
Time taken: 0.163 seconds, Fetched: 15 row(s)
hive (mydb)> desc tabD;
OK
col_name data_type comment
id int
name string
area string
month string
Time taken: 0.049 seconds, Fetched: 4 row(s)
hive (mydb)>
在創建表時使用查詢結果作為插入的資料時,沒有將磁區資訊復制過來,只是復制普通的欄位資料,所以表tabD資料中沒有磁區資訊,
先使用insert overwrite匯出資料:
-- 1.將查詢結果匯出到本地
hive (mydb)> insert overwrite local directory '/home/hadoop/data/tabC'
> select * from tabC;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 1 seconds 740 msec
OK
tabc.id tabc.name tabc.area tabc.month
Time taken: 33.941 seconds
-- 2.將查詢結果格式化輸出到本地
hive (mydb)> insert overwrite local directory '/home/hadoop/data/tabC'
> row format delimited fields terminated by ' '
> select * from tabC;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 1 seconds 610 msec
OK
tabc.id tabc.name tabc.area tabc.month
Time taken: 28.068 seconds
-- 3.將查詢結果匯出到HDFS
hive (mydb)> insert overwrite directory '/user/hadoop/data/tabC'
> row format delimited fields terminated by ' '
> select * from tabC;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 1 seconds 140 msec
OK
tabc.id tabc.name tabc.area tabc.month
Time taken: 20.725 seconds
hive (mydb)>
3種匯出方式對應的檔案系統查看如下:
[root@node03 ~]$ ll -ht /home/hadoop/data/
總用量 16K
drwxr-xr-x 2 root root 43 9月 24 22:25 tabC
-rw-r--r-- 1 root root 55 9月 24 17:18 sourceA.txt
-rw-r--r-- 1 root root 164 9月 23 03:32 course.dat
-rw-r--r-- 1 root root 148 9月 22 16:58 t1.dat
-rw-r--r-- 1 root root 84 9月 21 13:59 s1.dat
[root@node03 ~]$ cat -A /home/hadoop/data/tabC/000000_0
1^ACorley^ABeijing^A202109$
2^AJack^ATianjin^A202109$
3^ABob^AShanghai^A202109$
1^ACorley^ABeijing^A202110$
2^AJack^ATianjin^A202110$
3^ABob^AShanghai^A202110$
1^ACorley^ABeijing^A202111$
2^AJack^ATianjin^A202111$
3^ABob^AShanghai^A202111$
1^ACorley^ABeijing^A202112$
2^AJack^ATianjin^A202112$
3^ABob^AShanghai^A202112$
1^ACorley^ABeijing^A202112$
2^AJack^ATianjin^A202112$
3^ABob^AShanghai^A202112$
[root@node03 ~]$ cat /home/hadoop/data/tabC/000000_0
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
1 Corley Beijing 202110
2 Jack Tianjin 202110
3 Bob Shanghai 202110
1 Corley Beijing 202111
2 Jack Tianjin 202111
3 Bob Shanghai 202111
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
[root@node03 ~]$ hdfs dfs -ls /user/hadoop/data
Found 1 items
drwxr-xr-x - root supergroup 0 2021-09-24 22:29 /user/hadoop/data/tabC
[root@node03 ~]$ hdfs dfs -cat /user/hadoop/data/tabC/000000_0
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
1 Corley Beijing 202110
2 Jack Tianjin 202110
3 Bob Shanghai 202110
1 Corley Beijing 202111
2 Jack Tianjin 202111
3 Bob Shanghai 202111
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
[root@node03 ~]$
再使用DFS命令匯出資料到本地:
hive (mydb)> dfs -ls /user/hive/warehouse/mydb.db/tabc;
Found 4 items
drwxrwxrwx - root supergroup 0 2021-09-24 21:53 /user/hive/warehouse/mydb.db/tabc/month=202109
drwxrwxrwx - root supergroup 0 2021-09-24 21:54 /user/hive/warehouse/mydb.db/tabc/month=202110
drwxrwxrwx - root supergroup 0 2021-09-24 21:59 /user/hive/warehouse/mydb.db/tabc/month=202111
drwxrwxrwx - root supergroup 0 2021-09-24 21:59 /user/hive/warehouse/mydb.db/tabc/month=202112
hive (mydb)> dfs -get /user/hive/warehouse/mydb.db/tabc/month=202109 /home/hadoop/data/tabC;
hive (mydb)>
再查看本地,如下:
[root@node03 ~]$ ll -ht /home/hadoop/data/
總用量 16K
drwxr-xr-x 3 root root 63 9月 24 22:40 tabC
-rw-r--r-- 1 root root 55 9月 24 17:18 sourceA.txt
-rw-r--r-- 1 root root 164 9月 23 03:32 course.dat
-rw-r--r-- 1 root root 148 9月 22 16:58 t1.dat
-rw-r--r-- 1 root root 84 9月 21 13:59 s1.dat
[root@node03 ~]$ cat -A /home/hadoop/data/tabC/month\=202109/000000_0
1^ACorley^ABeijing$
這種方式的本質是進行資料檔案的拷貝,
也可以在本地執行hive命令匯出資料到本地,如下:
[root@node03 ~]$ hive -e "select * from mydb.tabC" > tabc.dat
which: no hbase in (/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/opt/software/java/jdk1.8.0_231/bin:/opt/software/hadoop-2.9.2/bin:/opt/software/hadoop-2.9.2/sbin:/opt/software/hive-2.3.7/bin:/root/bin)
Logging initialized using configuration in file:/opt/software/hive-2.3.7/conf/hive-log4j2.properties Async: true
OK
Time taken: 11.372 seconds, Fetched: 15 row(s)
[root@node03 ~]$ cat tabc.dat
tabc.id tabc.name tabc.area tabc.month
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
1 Corley Beijing 202110
2 Jack Tianjin 202110
3 Bob Shanghai 202110
1 Corley Beijing 202111
2 Jack Tianjin 202111
3 Bob Shanghai 202111
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
本質是執行查詢并將查詢結果重定向到檔案,
Hive有專門的匯出命令expert,匯出資料到HDFS,如下:
hive (mydb)> export table tabC to '/user/hadoop/data/tabC2';
Copying data from file:/tmp/root/88c65aff-1880-43e6-a9c0-452b1b0f63a8/hive_2021-09-24_22-50-40_489_1035737842386809043-1/-local-10000/_metadata
Copying file: file:/tmp/root/88c65aff-1880-43e6-a9c0-452b1b0f63a8/hive_2021-09-24_22-50-40_489_1035737842386809043-1/-local-10000/_metadata
Copying data from hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202109
Copying file: hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202109/000000_0
Copying file: hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202109/000000_0_copy_1
Copying data from hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202110
Copying file: hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202110/000000_0
Copying data from hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202111
Copying file: hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202111/000000_0
Copying data from hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202112
Copying file: hdfs://node01:9000/user/hive/warehouse/mydb.db/tabc/month=202112/000000_0
OK
Time taken: 1.242 seconds
本地查看如下:
[root@node03 ~]$ hdfs dfs -ls /user/hadoop/data/tabC2
Found 5 items
-rwxr-xr-x 3 root supergroup 6086 2021-09-24 22:50 /user/hadoop/data/tabC2/_metadata
drwxr-xr-x - root supergroup 0 2021-09-24 22:50 /user/hadoop/data/tabC2/month=202109
drwxr-xr-x - root supergroup 0 2021-09-24 22:50 /user/hadoop/data/tabC2/month=202110
drwxr-xr-x - root supergroup 0 2021-09-24 22:50 /user/hadoop/data/tabC2/month=202111
drwxr-xr-x - root supergroup 0 2021-09-24 22:50 /user/hadoop/data/tabC2/month=202112
可以看到,使用export匯出資料時,不僅有資料,還有表的元資料資訊,
export匯出的資料,可以使用import命令匯入到Hive表中,如下:
hive (mydb)> create table tabE like tabC;
OK
Time taken: 0.429 seconds
hive (mydb)> desc tabE;
OK
col_name data_type comment
id int
name string
area string
month string
# Partition Information
# col_name data_type comment
month string
Time taken: 0.444 seconds, Fetched: 9 row(s)
hive (mydb)> select * from tabE;
OK
tabe.id tabe.name tabe.area tabe.month
Time taken: 2.391 seconds
hive (mydb)> import table tabE from '/user/hadoop/data/tabC2';
Copying data from hdfs://node01:9000/user/hadoop/data/tabC2/month=202109
Copying file: hdfs://node01:9000/user/hadoop/data/tabC2/month=202109/000000_0
Copying file: hdfs://node01:9000/user/hadoop/data/tabC2/month=202109/000000_0_copy_1
Copying data from hdfs://node01:9000/user/hadoop/data/tabC2/month=202110
Copying file: hdfs://node01:9000/user/hadoop/data/tabC2/month=202110/000000_0
Copying data from hdfs://node01:9000/user/hadoop/data/tabC2/month=202111
Copying file: hdfs://node01:9000/user/hadoop/data/tabC2/month=202111/000000_0
Copying data from hdfs://node01:9000/user/hadoop/data/tabC2/month=202112
Copying file: hdfs://node01:9000/user/hadoop/data/tabC2/month=202112/000000_0
Loading data to table mydb.tabe partition (month=202109)
Loading data to table mydb.tabe partition (month=202110)
Loading data to table mydb.tabe partition (month=202111)
Loading data to table mydb.tabe partition (month=202112)
OK
Time taken: 4.861 seconds
hive (mydb)> select * from tabE;
OK
tabe.id tabe.name tabe.area tabe.month
1 Corley Beijing 202109
2 Jack Tianjin 202109
3 Bob Shanghai 202109
1 Corley Beijing 202110
2 Jack Tianjin 202110
3 Bob Shanghai 202110
1 Corley Beijing 202111
2 Jack Tianjin 202111
3 Bob Shanghai 202111
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
1 Corley Beijing 202112
2 Jack Tianjin 202112
3 Bob Shanghai 202112
Time taken: 0.232 seconds, Fetched: 15 row(s)
hive (mydb)>
可以總結,使用 like tname創建的表結構與原表一致,而使用create ... as select ...結構可能不一致,例如不會攜帶磁區資訊,
truncate可以用來截斷表,也就是清空資料,如下:
hive (mydb)> truncate table tabE;
OK
Time taken: 0.833 seconds
hive (mydb)> select * from tabE;
OK
tabe.id tabe.name tabe.area tabe.month
Time taken: 0.287 seconds
hive (mydb)> alter table tabE set tblproperties("EXTERNAL"="TRUE");
OK
Time taken: 0.167 seconds
hive (mydb)> truncate table tabE;
FAILED: SemanticException [Error 10146]: Cannot truncate non-managed table tabE.
hive (mydb)>
需要注意,truncate僅能操作內部表,操作外部表時會報錯,
總結如下:
資料匯入方式如下:
-
load data
-
insert
-
create table … as select …
-
import table
資料匯出方式如下:
-
insert overwrite … diretory …
-
hdfs dfs -get
-
hive -e “select …” > file
-
export table …
除此之外,Hive的資料匯入與匯出還可以使用其他工具,包括Sqoop、DataX等,
6.HQL操作之DQL命令
DQL即Data Query Language資料查詢語言,是HQL的重點,
書寫SQL陳述句時,注意事項如下:
-
SQL陳述句對大小寫不敏感
-
SQL陳述句可以寫一行(簡單SQL),也可以寫多行(復雜SQL)
-
關鍵字不能縮寫,也不能分行
-
各子句一般要分行
-
使用縮進格式,提高SQL陳述句的可讀性
(1)簡單查詢
先準備資料檔案,vim /home/hadoop/data/emp.dat,輸入內容如下:
7369,SMITH,CLERK,7902,2010-12-17,800,,20
7499,ALLEN,SALESMAN,7698,2011-02-20,1600,300,30
7521,WARD,SALESMAN,7698,2011-02-22,1250,500,30
7566,JONES,MANAGER,7839,2011-04-02,2975,,20
7654,MARTIN,SALESMAN,7698,2011-09-28,1250,1400,30
7698,BLAKE,MANAGER,7839,2011-05-01,2850,,30
7782,CLARK,MANAGER,7839,2011-06-09,2450,,10
7788,SCOTT,ANALYST,7566,2017-07-13,3000,,20
7839,KING,PRESIDENT,,2011-11-07,5000,,10
7844,TURNER,SALESMAN,7698,2011-09-08,1500,0,30
7876,ADAMS,CLERK,7788,2017-07-13,1100,,20
7900,JAMES,CLERK,7698,2011-12-03,950,,30
7902,FORD,ANALYST,7566,2011-12-03,3000,,20
7934,MILLER,CLERK,7782,2012-01-23,1300,,10
再創建表和匯入資料,如下:
hive (mydb)> CREATE TABLE emp(
> empno int,
> ename string,
> job string,
> mgr int,
> hiredate DATE,
> sal int,
> comm int,
> deptno int
> )row format delimited fields terminated by ",";
OK
Time taken: 0.179 seconds
hive (mydb)> load data local inpath '/home/hadoop/data/emp.dat' into table emp;
Loading data to table mydb.emp
OK
Time taken: 0.712 seconds
hive (mydb)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7698 BLAKE MANAGER 7839 2011-05-01 2850 NULL 30
7782 CLARK MANAGER 7839 2011-06-09 2450 NULL 10
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7839 KING PRESIDENT NULL 2011-11-07 5000 NULL 10
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20
7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10
Time taken: 0.329 seconds, Fetched: 14 row(s)
hive (mydb)>
再進行簡單查詢,如下:
-- 省略from子句的查詢
hive (mydb)> select 123 * 321;
OK
_c0
39483
Time taken: 0.139 seconds, Fetched: 1 row(s)
hive (mydb)> select current_date;
OK
_c0
2021-09-24
Time taken: 0.113 seconds, Fetched: 1 row(s)
-- 使用列別名
hive (mydb)> select 123 * 321 as pro;
OK
pro
39483
Time taken: 0.125 seconds, Fetched: 1 row(s)
hive (mydb)> select current_date curdate;
OK
curdate
2021-09-24
Time taken: 0.124 seconds, Fetched: 1 row(s)
-- 全表查詢
hive (mydb)> select * from emp;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7698 BLAKE MANAGER 7839 2011-05-01 2850 NULL 30
7782 CLARK MANAGER 7839 2011-06-09 2450 NULL 10
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7839 KING PRESIDENT NULL 2011-11-07 5000 NULL 10
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20
7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10
Time taken: 0.277 seconds, Fetched: 14 row(s)
-- 選擇特定列查詢
hive (mydb)> select ename, sal, comm from emp;
OK
ename sal comm
SMITH 800 NULL
ALLEN 1600 300
WARD 1250 500
JONES 2975 NULL
MARTIN 1250 1400
BLAKE 2850 NULL
CLARK 2450 NULL
SCOTT 3000 NULL
KING 5000 NULL
TURNER 1500 0
ADAMS 1100 NULL
JAMES 950 NULL
FORD 3000 NULL
MILLER 1300 NULL
Time taken: 0.172 seconds, Fetched: 14 row(s)
-- 使用函式
hive (mydb)> select count(*) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
14
Time taken: 6.238 seconds, Fetched: 1 row(s)
hive (mydb)> select count(1) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
14
Time taken: 1.823 seconds, Fetched: 1 row(s)
hive (mydb)> select count(empno) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
14
Time taken: 1.697 seconds, Fetched: 1 row(s)
hive (mydb)> select count(comm) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
4
Time taken: 2.079 seconds, Fetched: 1 row(s)
hive (mydb)> select sum(sal) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
29025
Time taken: 1.746 seconds, Fetched: 1 row(s)
hive (mydb)> select max(sal) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
5000
Time taken: 1.737 seconds, Fetched: 1 row(s)
hive (mydb)> select min(sal) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
800
Time taken: 1.789 seconds, Fetched: 1 row(s)
hive (mydb)> select avg(sal) from emp;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
2073.214285714286
Time taken: 1.629 seconds, Fetched: 1 row(s)
-- 使用limit子句限制回傳的行數
hive (mydb)> select * from emp limit 3;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
Time taken: 0.338 seconds, Fetched: 3 row(s)
hive (mydb)>
需要注意,使用count函式時,如果傳入的是欄位,則不統計NULL,所以要統計資料的行數時,一般不傳入某個欄位,而是傳入*或1,
(2)簡單子句
WHERE子句緊隨FROM子句,使用WHERE子句,過濾不滿足條件的資料;
where 子句中不能使用列的別名,
where子句的簡單用法如下:
hive (mydb)> select ename name, sal from emp;
OK
name sal
SMITH 800
ALLEN 1600
WARD 1250
JONES 2975
MARTIN 1250
BLAKE 2850
CLARK 2450
SCOTT 3000
KING 5000
TURNER 1500
ADAMS 1100
JAMES 950
FORD 3000
MILLER 1300
Time taken: 0.145 seconds, Fetched: 14 row(s)
hive (mydb)> select ename name, sal from emp where length(ename)=5;
OK
name sal
SMITH 800
ALLEN 1600
JONES 2975
BLAKE 2850
CLARK 2450
SCOTT 3000
ADAMS 1100
JAMES 950
Time taken: 0.183 seconds, Fetched: 8 row(s)
hive (mydb)> select ename name, sal from emp where length(name)=5;
FAILED: SemanticException [Error 10004]: Line 1:45 Invalid table alias or column reference 'name': (possible column names are: empno, ename, job, mgr, hiredate, sal, comm, deptno)
hive (mydb)> select ename, sal from emp where sal > 2000;
OK
ename sal
JONES 2975
BLAKE 2850
CLARK 2450
SCOTT 3000
KING 5000
FORD 3000
Time taken: 0.333 seconds, Fetched: 6 row(s)
hive (mydb)>
可以看到,where子句中不能使用欄位的別名作為查詢條件,
where子句中會涉及到較多的比較運算和 邏輯運算,
常見的比較運算子如下:
| 比較運算子 | 含義 |
|---|---|
| =、==、<=> | 等于 |
| <>、!= | 不等于 |
| <、<=、>、>= | 大于等于、小于等于 |
| is [not] null | 如果A等于NULL,則回傳TRUE,反之回傳FALSE;使用NOT關鍵字結果相反 |
| in (value1, value2, …) | 匹配串列中的值 |
| LIKE | 簡單正則運算式,也稱通配符模式: ‘x%’ 表示必須以字母 ‘x’ 開頭; ’%x’表示必須以字母’x’結尾; ’%x%‘表示包含有字母’x’,可以位于字串任意位置; 使用NOT關鍵字結果相反, 其中,%代表匹配零個或多個字符(任意個字符),_ 代表匹配一個字符 |
| [NOT] BETWEEN … AND … | 范圍的判斷,使用NOT關鍵字結果相反 |
| RLIKE、REGEXP | 基于Java的正則運算式,匹配回傳TRUE,反之回傳FALSE; 匹配使用的是JDK中的正則運算式介面實作的,因為正則也依據其中的規則; 例如,正則運算式必須和整個字串A相匹配,而不是只需與其字串匹配 |
更完整的比較運算子可參考官方檔案https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF,
使用比較運算子如下:
hive (mydb)> select sal, comm, sal+comm from emp;
OK
sal comm _c2
800 NULL NULL
1600 300 1900
...
3000 NULL NULL
1300 NULL NULL
Time taken: 0.257 seconds, Fetched: 14 row(s)
hive (mydb)> select sal, comm, sal+comm from emp;
OK
sal comm _c2
800 NULL NULL
1600 300 1900
1250 500 1750
...
3000 NULL NULL
1300 NULL NULL
Time taken: 0.17 seconds, Fetched: 14 row(s)
hive (mydb)> select * from emp where comm != NULL;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 0.246 seconds
hive (mydb)> select * from emp where comm is not NULL;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
Time taken: 0.193 seconds, Fetched: 4 row(s)
Time taken: 0.192 seconds, Fetched: 1 row(s)
hive (mydb)> select * from emp where deptno in (20, 30);
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
...
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20
Time taken: 0.247 seconds, Fetched: 11 row(s)
hive (mydb)> select * from emp where ename like 'S%';
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
Time taken: 0.39 seconds, Fetched: 2 row(s)
hive (mydb)> select * from emp where ename like '%S';
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
Time taken: 0.165 seconds, Fetched: 3 row(s)
hive (mydb)> select * from emp where ename like '%S%';
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
Time taken: 0.098 seconds, Fetched: 5 row(s)
hive (mydb)> select * from emp where sal between 1000 and 2000;
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10
Time taken: 0.855 seconds, Fetched: 6 row(s)
hive (mydb)> select * from emp where ename like 'S%' or ename like '%S';
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
Time taken: 0.151 seconds, Fetched: 5 row(s)
hive (mydb)> select * from emp where ename rlike '^S.*|.*S$';
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
Time taken: 0.152 seconds, Fetched: 5 row(s)
hive (mydb)> select null=null;
OK
_c0
NULL
Time taken: 0.078 seconds, Fetched: 1 row(s)
hive (mydb)> select null==null;
OK
_c0
NULL
Time taken: 0.074 seconds, Fetched: 1 row(s)
hive (mydb)> select null<=>null;
OK
_c0
true
Time taken: 0.068 seconds, Fetched: 1 row(s)
hive (mydb)> select null is null;
OK
_c0
true
Time taken: 0.066 seconds, Fetched: 1 row(s)
hive (mydb)>
可以看到,通常情況下NULL參與運算,回傳值為NULL,并且判斷欄位(不)NULL時,不能使用=,而要使用is和is not,否則會得到例外的結果;
null<=>null和null is null的結果相同,都是true,
邏輯運算子包括and、or和not,
(3)group by分組子句
GROUP BY陳述句通常與聚組函式一起使用,按照一個或多個列對資料進行分組,對每個組進行聚合操作,
使用如下:
hive (mydb)> select avg(sal)
> from emp
> group by deptno;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
2916.6666666666665
2175.0
1566.6666666666667
Time taken: 2.428 seconds, Fetched: 3 row(s)
-- 計算emp表每個部門的平均工資
hive (mydb)> select deptno, avg(sal)
> from emp
> group by deptno;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
deptno _c1
10 2916.6666666666665
20 2175.0
30 1566.6666666666667
Time taken: 1.921 seconds, Fetched: 3 row(s)
-- 計算emp每個部門中每個崗位的最高薪水
hive (mydb)> select deptno, job , max(sal)
> from emp
> group by deptno, job;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
deptno job _c2
20 ANALYST 3000
10 CLERK 1300
20 CLERK 1100
30 CLERK 950
10 MANAGER 2450
20 MANAGER 2975
30 MANAGER 2850
10 PRESIDENT 5000
30 SALESMAN 1600
Time taken: 1.587 seconds, Fetched: 9 row(s)
hive (mydb)> select deptno, max(sal)
> from emp
> group by deptno;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
deptno _c1
10 5000
20 3000
30 2850
Time taken: 1.719 seconds, Fetched: 3 row(s)
-- 求每個部門的平均薪水大于2000的部門
hive (mydb)> select deptno, avg(sal) avgsal
> from emp
> group by deptno
> having avgsal > 2000;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
deptno avgsal
10 2916.6666666666665
20 2175.0
Time taken: 1.881 seconds, Fetched: 2 row(s)
hive (mydb)> [root@node03 ~]$
現在對where和having進行總結:
-
where子句針對表中的資料發揮作用;having針對查詢結果(聚組以后的結果)發揮作用
-
where子句不能有分組函式;having子句可以有分組函式
-
having一般只用于group by分組統計之后
(4)表連接
Hive支持通常的SQL JOIN陳述句,默認情況下,僅支持等值連接,不支持非等值連接,
JOIN 陳述句中經常會使用表的別名,使用別名可以簡化SQL陳述句的撰寫,使用表名前綴可以提高SQL的決議效率,
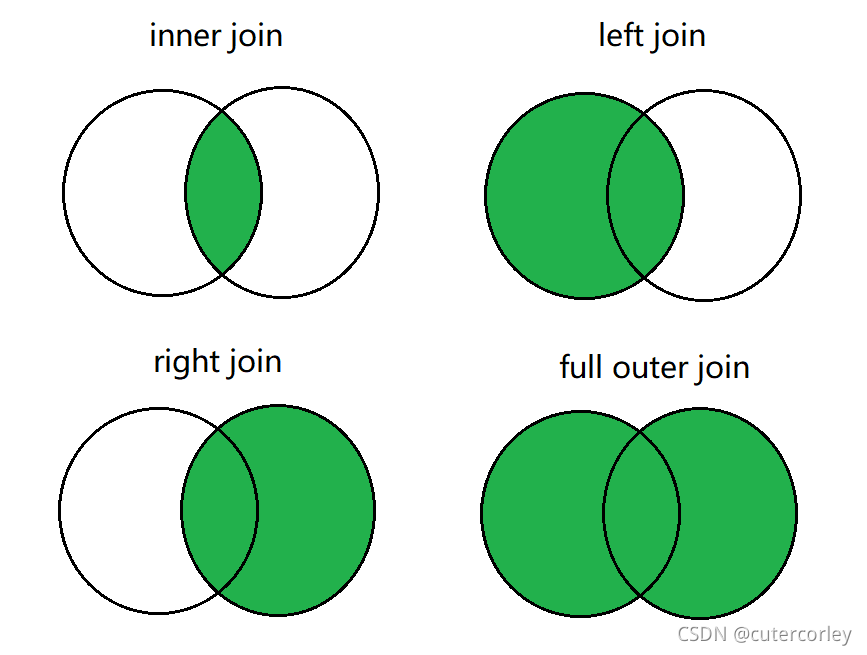
連接查詢操作分為兩大類,內連接和外連接,而外連接可進一步細分為三種型別,如下:
-
內連接[inner] join
-
外連接outer join
????- 左外連接left [outer] join,左表的資料全部顯示
????- 右外連接right [outer] join,右表的資料全部顯示
????- 全外連接full [outer] join,兩張表的資料都顯示
圖示如下:
先準備資料,vim /home/hadoop/data/u1.txt,輸入如下:
1,a
2,b
3,c
4,d
5,e
6,f
vim /home/hadoop/data/u2.txt,輸入如下:
4,d
5,e
6,f
7,g
8,h
9,i
創建表并加載資料,如下:
hive (mydb)> create table if not exists u1(
> id int,
> name string)
> row format delimited fields terminated by ',';
OK
Time taken: 0.823 seconds
hive (mydb)> create table if not exists u2(
> id int,
> name string)
> row format delimited fields terminated by ',';
OK
Time taken: 0.143 seconds
hive (mydb)> load data local inpath '/home/hadoop/data/u1.txt' into table u1;
Loading data to table mydb.u1
OK
Time taken: 0.949 seconds
hive (mydb)> load data local inpath '/home/hadoop/data/u2.txt' into table u2;
Loading data to table mydb.u2
OK
Time taken: 0.773 seconds
hive (mydb)> select * from u1;
OK
u1.id u1.name
1 a
2 b
3 c
4 d
5 e
6 f
Time taken: 1.587 seconds, Fetched: 6 row(s)
hive (mydb)> select * from u2;
OK
u2.id u2.name
4 d
5 e
6 f
7 g
8 h
9 i
Time taken: 0.205 seconds, Fetched: 6 row(s)
hive (mydb)>
再測驗4種連接方式:
-- 內連接
hive (mydb)> select * from u1 join u2 on u1.id = u2.id;
Automatically selecting local only mode for query
...
2021-09-25 01:40:36 Uploaded 1 File to: file:/tmp/root/8c73cb74-4529-401a-a664-93c1ea29f8d0/hive_2021-09-25_01-40-19_146_1199023122301087997-1/-local-10004/HashTable-Stage-3/MapJoin-mapfile00--.hashtable (386 bytes)
2021-09-25 01:40:36 End of local task; Time Taken: 2.182 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2021-09-25 01:40:40,275 Stage-3 map = 100%, reduce = 0%
Ended Job = job_local250415828_0001
MapReduce Jobs Launched:
Stage-Stage-3: HDFS Read: 72 HDFS Write: 195 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
u1.id u1.name u2.id u2.name
4 d 4 d
5 e 5 e
6 f 6 f
Time taken: 21.206 seconds, Fetched: 3 row(s)
-- 左外連接
hive (mydb)> select * from u1 left join u2 on u1.id = u2.id;
Automatically selecting local only mode for query
...
2021-09-25 01:41:27 Uploaded 1 File to: file:/tmp/root/8c73cb74-4529-401a-a664-93c1ea29f8d0/hive_2021-09-25_01-41-11_852_942067958094048095-1/-local-10004/HashTable-Stage-3/MapJoin-mapfile11--.hashtable (386 bytes)
2021-09-25 01:41:27 End of local task; Time Taken: 1.788 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2021-09-25 01:41:30,494 Stage-3 map = 100%, reduce = 0%
Ended Job = job_local794342130_0002
MapReduce Jobs Launched:
Stage-Stage-3: HDFS Read: 243 HDFS Write: 408 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
u1.id u1.name u2.id u2.name
1 a NULL NULL
2 b NULL NULL
3 c NULL NULL
4 d 4 d
5 e 5 e
6 f 6 f
Time taken: 18.726 seconds, Fetched: 6 row(s)
-- 右外連接
hive (mydb)> select * from u1 right join u2 on u1.id = u2.id;
Automatically selecting local only mode for query
...
2021-09-25 01:41:55 Uploaded 1 File to: file:/tmp/root/8c73cb74-4529-401a-a664-93c1ea29f8d0/hive_2021-09-25_01-41-41_317_899584510973126689-1/-local-10004/HashTable-Stage-3/MapJoin-mapfile20--.hashtable (386 bytes)
2021-09-25 01:41:55 End of local task; Time Taken: 1.925 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2021-09-25 01:41:58,864 Stage-3 map = 100%, reduce = 0%
Ended Job = job_local644970176_0003
MapReduce Jobs Launched:
Stage-Stage-3: HDFS Read: 480 HDFS Write: 621 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
u1.id u1.name u2.id u2.name
4 d 4 d
5 e 5 e
6 f 6 f
NULL NULL 7 g
NULL NULL 8 h
NULL NULL 9 i
Time taken: 17.577 seconds, Fetched: 6 row(s)
-- 全外連接
hive (mydb)> select * from u1 full join u2 on u1.id = u2.id;
Automatically selecting local only mode for query
...
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2021-09-25 01:42:16,604 Stage-1 map = 100%, reduce = 100%
Ended Job = job_local905853098_0004
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 2199 HDFS Write: 2142 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
u1.id u1.name u2.id u2.name
1 a NULL NULL
2 b NULL NULL
3 c NULL NULL
4 d 4 d
5 e 5 e
6 f 6 f
NULL NULL 7 g
NULL NULL 8 h
NULL NULL 9 i
Time taken: 1.802 seconds, Fetched: 9 row(s)
hive (mydb)>
除此之外,還可以進行多表連接;
連接 n張表,至少需要 n-1 個連接條件,例如連接四張表至少需要三個連接條件,
舉例,多表連接查詢,查詢老師對應的課程,以及對應的分數,對應的學生,如下:
select *
from techer t left join course c on t.t_id = c.t_id
left join score s on s.c_id = c.c_id
left join student stu on s.s_id = stu.s_id;
Hive總是按照從左到右的順序執行,Hive會對每對 JOIN 連接物件啟動一個MapReduce 任務,
上面的例子中會首先啟動一個MapReduce Job對表t和表c進行連接操作;然后再啟動一個MapReduce Job將第一個MapReduce Job的輸出和表s進行連接操作;然后再繼續啟動一個MapReduce Job將第二個MapReduce Job的輸出和表stu進行連接操作,所以總共會有3個MapReduce Job,
可以看到,連接條件會占用較多的連接資源,
Hive種也可以產生笛卡爾積,滿足以下條件將會產生笛卡爾積:
-
沒有連接條件
-
連接條件無效
-
所有表中的所有行互相連接
如果表A、B分別有M、N條資料,其笛卡爾積的結果將有 M*N 條資料,預設條件下HIve不支持笛卡爾積運算,需要設定引數hive.strict.checks.cartesian.product=false才能進行笛卡爾積運算,
使用如下:
hive (mydb)> select * from u1, u2;
FAILED: SemanticException Cartesian products are disabled for safety reasons. If you know what you are doing, please sethive.strict.checks.cartesian.product to false and that hive.mapred.mode is not set to 'strict' to proceed. Note that if you may get errors or incorrect results if you make a mistake while using some of the unsafe features.
hive (mydb)> set hive.strict.checks.cartesian.product;
hive.strict.checks.cartesian.product=true
hive (mydb)> set hive.strict.checks.cartesian.product=false;
hive (mydb)> select * from u1, u2;
Warning: Map Join MAPJOIN[9][bigTable=?] in task 'Stage-3:MAPRED' is a cross product
Automatically selecting local only mode for query
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20210925015241_c38361bc-8bd1-4473-8e2c-ec9479516299
Total jobs = 1
2021-09-25 01:52:55 Starting to launch local task to process map join; maximum memory = 518979584
2021-09-25 01:52:57 Dump the side-table for tag: 0 with group count: 1 into file: file:/tmp/root/8c73cb74-4529-401a-a664-93c1ea29f8d0/hive_2021-09-25_01-52-41_759_493077905194279454-1/-local-10004/HashTable-Stage-3/MapJoin-mapfile30--.hashtable
2021-09-25 01:52:57 Uploaded 1 File to: file:/tmp/root/8c73cb74-4529-401a-a664-93c1ea29f8d0/hive_2021-09-25_01-52-41_759_493077905194279454-1/-local-10004/HashTable-Stage-3/MapJoin-mapfile30--.hashtable (320 bytes)
2021-09-25 01:52:57 End of local task; Time Taken: 1.549 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2021-09-25 01:53:00,570 Stage-3 map = 100%, reduce = 0%
Ended Job = job_local1556109485_0005
MapReduce Jobs Launched:
Stage-Stage-3: HDFS Read: 1044 HDFS Write: 1707 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
u1.id u1.name u2.id u2.name
1 a 4 d
2 b 4 d
3 c 4 d
4 d 4 d
5 e 4 d
6 f 4 d
1 a 5 e
2 b 5 e
3 c 5 e
4 d 5 e
5 e 5 e
6 f 5 e
1 a 6 f
2 b 6 f
3 c 6 f
4 d 6 f
5 e 6 f
6 f 6 f
1 a 7 g
2 b 7 g
3 c 7 g
4 d 7 g
5 e 7 g
6 f 7 g
1 a 8 h
2 b 8 h
3 c 8 h
4 d 8 h
5 e 8 h
6 f 8 h
1 a 9 i
2 b 9 i
3 c 9 i
4 d 9 i
5 e 9 i
6 f 9 i
Time taken: 18.844 seconds, Fetched: 36 row(s)
hive (mydb)> select count(*) from u1, u2;
Warning: Map Join MAPJOIN[15][bigTable=?] in task 'Stage-2:MAPRED' is a cross product
Automatically selecting local only mode for query
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20210925015310_41ce7307-4ea7-41f3-8c40-6c1927d3feb7
Total jobs = 1
2021-09-25 01:53:25 Starting to launch local task to process map join; maximum memory = 518979584
2021-09-25 01:53:27 Dump the side-table for tag: 0 with group count: 1 into file: file:/tmp/root/8c73cb74-4529-401a-a664-93c1ea29f8d0/hive_2021-09-25_01-53-10_349_6581783439017176314-1/-local-10005/HashTable-Stage-2/MapJoin-mapfile40--.hashtable
2021-09-25 01:53:27 Uploaded 1 File to: file:/tmp/root/8c73cb74-4529-401a-a664-93c1ea29f8d0/hive_2021-09-25_01-53-10_349_6581783439017176314-1/-local-10005/HashTable-Stage-2/MapJoin-mapfile40--.hashtable (296 bytes)
2021-09-25 01:53:27 End of local task; Time Taken: 1.715 sec.
Execution completed successfully
MapredLocal task succeeded
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Job running in-process (local Hadoop)
2021-09-25 01:53:30,449 Stage-2 map = 100%, reduce = 100%
Ended Job = job_local480461869_0006
MapReduce Jobs Launched:
Stage-Stage-2: HDFS Read: 3750 HDFS Write: 3516 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
_c0
36
Time taken: 20.145 seconds, Fetched: 1 row(s)
hive (mydb)>
(5)order by排序子句
Hive中的order by子句與MySQL中存在一定的區別,
order by子句用于對最終的結果進行排序,一般出現在select陳述句的結尾;
默認使用升序(ASC),可以使用DESC,跟在欄位名之后表示降序;
ORDER BY執行全域排序 ,只有一個reduce任務,
使用如下:
hive (mydb)> select * from emp order by deptno;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10
7839 KING PRESIDENT NULL 2011-11-07 5000 NULL 10
7782 CLARK MANAGER 7839 2011-06-09 2450 NULL 10
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7698 BLAKE MANAGER 7839 2011-05-01 2850 NULL 30
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
Time taken: 7.211 seconds, Fetched: 14 row(s)
hive (mydb)> select empno, ename, job, mgr, sal+comm salsum, deptno
> from emp
> order by salsum desc;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
empno ename job mgr salsum deptno
7654 MARTIN SALESMAN 7698 2650 30
7499 ALLEN SALESMAN 7698 1900 30
7521 WARD SALESMAN 7698 1750 30
7844 TURNER SALESMAN 7698 1500 30
7934 MILLER CLERK 7782 NULL 10
7902 FORD ANALYST 7566 NULL 20
7900 JAMES CLERK 7698 NULL 30
7876 ADAMS CLERK 7788 NULL 20
7839 KING PRESIDENT NULL NULL 10
7788 SCOTT ANALYST 7566 NULL 20
7782 CLARK MANAGER 7839 NULL 10
7698 BLAKE MANAGER 7839 NULL 30
7566 JONES MANAGER 7839 NULL 20
7369 SMITH CLERK 7902 NULL 20
Time taken: 2.068 seconds, Fetched: 14 row(s)
hive (mydb)> select empno, ename, job, mgr, sal+nvl(comm, 0) salsum, deptno
> from emp
> order by salsum desc;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
empno ename job mgr salsum deptno
7839 KING PRESIDENT NULL 5000 10
7902 FORD ANALYST 7566 3000 20
7788 SCOTT ANALYST 7566 3000 20
7566 JONES MANAGER 7839 2975 20
7698 BLAKE MANAGER 7839 2850 30
7654 MARTIN SALESMAN 7698 2650 30
7782 CLARK MANAGER 7839 2450 10
7499 ALLEN SALESMAN 7698 1900 30
7521 WARD SALESMAN 7698 1750 30
7844 TURNER SALESMAN 7698 1500 30
7934 MILLER CLERK 7782 1300 10
7876 ADAMS CLERK 7788 1100 20
7900 JAMES CLERK 7698 950 30
7369 SMITH CLERK 7902 800 20
Time taken: 1.739 seconds, Fetched: 14 row(s)
hive (mydb)> select empno, ename, job, mgr, sal+nvl(comm, 0) salsum, deptno
> from emp
> order by deptno, salsum desc;
Automatically selecting local only mode for query
...
Total MapReduce CPU Time Spent: 0 msec
OK
empno ename job mgr salsum deptno
7839 KING PRESIDENT NULL 5000 10
7782 CLARK MANAGER 7839 2450 10
7934 MILLER CLERK 7782 1300 10
7788 SCOTT ANALYST 7566 3000 20
7902 FORD ANALYST 7566 3000 20
7566 JONES MANAGER 7839 2975 20
7876 ADAMS CLERK 7788 1100 20
7369 SMITH CLERK 7902 800 20
7698 BLAKE MANAGER 7839 2850 30
7654 MARTIN SALESMAN 7698 2650 30
7499 ALLEN SALESMAN 7698 1900 30
7521 WARD SALESMAN 7698 1750 30
7844 TURNER SALESMAN 7698 1500 30
7900 JAMES CLERK 7698 950 30
Time taken: 1.849 seconds, Fetched: 14 row(s)
hive (mydb)> select empno, ename, job, mgr, sal+nvl(comm, 0) salsum
> from emp
> order by deptno, salsum desc;
FAILED: SemanticException [Error 10004]: Line 3:9 Invalid table alias or column reference 'deptno': (possible column names are: empno, ename, job, mgr, salsum)
hive (mydb)>
其中,nvl函式的作用是在傳入的欄位的值為空時,將欄位的值設定為第二個引數的值,一般在欄位參與運算時,會用到該函式;
同時需要保證,排序欄位要出現在select子句中,否則查詢陳述句無法執行,上面的查詢陳述句因為select子句中缺少deptno、而order by子句中存在deptno,所以不能正常執行,
(6)sort by排序
對于大規模資料而言order by效率低;
在很多業務場景,我們并不需要全域有序的資料、而只需要區域有序的資料即可,此時可以使用sort by;
sort by可以為每個reduce產生一個排序檔案,在reduce內部進行排序,得到區域有序的結果,
現在使用如下:
-- 設定reduce個數
hive (mydb)> set mapreduce.job.reduces;
mapreduce.job.reduces=-1
hive (mydb)> set mapreduce.job.reduces=2;
hive (mydb)> set mapreduce.job.reduces;
mapreduce.job.reduces=2
-- 按照工資降序查看員工資訊
hive (mydb)> select * from emp sort by sal desc;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 7 seconds 860 msec
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
7839 KING PRESIDENT NULL 2011-11-07 5000 NULL 10
7698 BLAKE MANAGER 7839 2011-05-01 2850 NULL 30
7782 CLARK MANAGER 7839 2011-06-09 2450 NULL 10
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10
Time taken: 42.303 seconds, Fetched: 14 row(s)
-- 將查詢結果匯入到檔案中(按照工資降序),生成兩個輸出檔案,每個檔案內部資料按工資降序排列
hive (mydb)> insert overwrite local directory '/home/hadoop/output/sortsal'
> select * from emp sort by sal desc;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 9 seconds 50 msec
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
Time taken: 46.032 seconds
hive (mydb)>
運行后,查看本地,如下:
[root@node03 ~]$ ll /home/hadoop/output/sortsal/
總用量 8
-rw-r--r-- 1 root root 411 9月 25 15:20 000000_0
-rw-r--r-- 1 root root 230 9月 25 15:20 000001_0
[root@node03 ~]$ cat -A /home/hadoop/output/sortsal/000000_0
7902^AFORD^AANALYST^A7566^A2011-12-03^A3000^A\N^A20$
7788^ASCOTT^AANALYST^A7566^A2017-07-13^A3000^A\N^A20$
7566^AJONES^AMANAGER^A7839^A2011-04-02^A2975^A\N^A20$
7844^ATURNER^ASALESMAN^A7698^A2011-09-08^A1500^A0^A30$
7521^AWARD^ASALESMAN^A7698^A2011-02-22^A1250^A500^A30$
7654^AMARTIN^ASALESMAN^A7698^A2011-09-28^A1250^A1400^A30$
7876^AADAMS^ACLERK^A7788^A2017-07-13^A1100^A\N^A20$
7900^AJAMES^ACLERK^A7698^A2011-12-03^A950^A\N^A30$
7369^ASMITH^ACLERK^A7902^A2010-12-17^A800^A\N^A20$
[root@node03 ~]$ cat -A /home/hadoop/output/sortsal/000001_0
7839^AKING^APRESIDENT^A\N^A2011-11-07^A5000^A\N^A10$
7698^ABLAKE^AMANAGER^A7839^A2011-05-01^A2850^A\N^A30$
7782^ACLARK^AMANAGER^A7839^A2011-06-09^A2450^A\N^A10$
7499^AALLEN^ASALESMAN^A7698^A2011-02-20^A1600^A300^A30$
7934^AMILLER^ACLERK^A7782^A2012-01-23^A1300^A\N^A10$
[root@node03 ~]$
可以看到,reduce個數(mapreduce.job.reduces引數的值)默認為-1,此時Hive可以自行計算reduce的個數,當資料很小時就會只計算出一個reduce,所以要想有多個reduce,需要手動設定;
此時有多個reduce,不能再啟用本地模式,而是使用多個MR Job;
在查詢的結果中,無論是列印出來到控制臺,還是輸出到檔案,在區域都是有序的,
(7)distribute by和cluster by排序
distribute by用于磁區排序;
distribute by 將特定的行發送到特定的reducer中,便于后繼的聚合與排序操作;
distribute by 類似于MR中的磁區操作,可以結合sort by操作,使磁區資料有序,結合使用時distribute by 要寫在sort by之前,
使用如下:
-- 啟動2個reduce task
hive (mydb)> set mapreduce.job.reduces=2;
-- 先按deptno磁區,在磁區內按sal+comm排序,將結果輸出到檔案,觀察輸出結果
hive (mydb)> insert overwrite local directory '/home/hadoop/output/distBy'
> select empno, ename, deptno, job, sal+nvl(comm, 0) salsum
> from emp
> distribute by deptno
> sort by salsum desc;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 6 seconds 310 msec
OK
empno ename deptno job salsum
Time taken: 39.482 seconds
hive (mydb)> select distinct deptno from emp;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 7 seconds 730 msec
OK
deptno
10
20
30
Time taken: 38.173 seconds, Fetched: 3 row(s)
-- 啟動3個reduce task,將資料分到3個區中
hive (mydb)> set mapreduce.job.reduces=3;
hive (mydb)> insert overwrite local directory '/home/hadoop/output/distby'
> select empno, ename, deptno, job, sal+nvl(comm, 0) salsum
> from emp
> distribute by deptno
> sort by salsum desc;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 10 seconds 890 msec
OK
empno ename deptno job salsum
Time taken: 36.433 seconds
hive (mydb)>
查看本地,如下:
# 2個reduce task
[root@node03 ~]$ ll /home/hadoop/output/distBy/
總用量 4
-rw-r--r-- 1 root root 374 9月 25 15:34 000000_0
-rw-r--r-- 1 root root 0 9月 25 15:34 000001_0
[root@node03 ~]$ cat -A /home/hadoop/output/distBy/000000_0
7839^AKING^A10^APRESIDENT^A5000$
7902^AFORD^A20^AANALYST^A3000$
7788^ASCOTT^A20^AANALYST^A3000$
7566^AJONES^A20^AMANAGER^A2975$
7698^ABLAKE^A30^AMANAGER^A2850$
7654^AMARTIN^A30^ASALESMAN^A2650$
7782^ACLARK^A10^AMANAGER^A2450$
7499^AALLEN^A30^ASALESMAN^A1900$
7521^AWARD^A30^ASALESMAN^A1750$
7844^ATURNER^A30^ASALESMAN^A1500$
7934^AMILLER^A10^ACLERK^A1300$
7876^AADAMS^A20^ACLERK^A1100$
7900^AJAMES^A30^ACLERK^A950$
7369^ASMITH^A20^ACLERK^A800$
[root@node03 ~]$ cat -A /home/hadoop/output/distBy/000001_0
# 3個reduce task
[root@node03 ~]$ ll /home/hadoop/output/distby/
總用量 12
-rw-r--r-- 1 root root 164 9月 25 15:42 000000_0
-rw-r--r-- 1 root root 81 9月 25 15:42 000001_0
-rw-r--r-- 1 root root 129 9月 25 15:42 000002_0
[root@node03 ~]$ cat -A /home/hadoop/output/distby/000000_0
7698^ABLAKE^A30^AMANAGER^A2850$
7654^AMARTIN^A30^ASALESMAN^A2650$
7499^AALLEN^A30^ASALESMAN^A1900$
7521^AWARD^A30^ASALESMAN^A1750$
7844^ATURNER^A30^ASALESMAN^A1500$
7900^AJAMES^A30^ACLERK^A950$
[root@node03 ~]$ cat -A /home/hadoop/output/distby/000001_0
7839^AKING^A10^APRESIDENT^A5000$
7782^ACLARK^A10^AMANAGER^A2450$
7934^AMILLER^A10^ACLERK^A1300$
[root@node03 ~]$ cat -A /home/hadoop/output/distby/000002_0
7788^ASCOTT^A20^AANALYST^A3000$
7902^AFORD^A20^AANALYST^A3000$
7566^AJONES^A20^AMANAGER^A2975$
7876^AADAMS^A20^ACLERK^A1100$
7369^ASMITH^A20^ACLERK^A800$
[root@node03 ~]$
可以看到,因為磁區規則是磁區欄位.hashCode % 磁區數,并且磁區欄位deptno的值包括10、20、30,磁區數為2,計算得到的磁區編號都是0,所以設定reduce為2時最后得到的資料都在第一個磁區檔案000000_0中,設定reduce為3時,查詢結果會分布到不同的檔案中,
當distribute by與sort by是同一個欄位時,可使用cluster by簡化語法;
cluster by只能是升序,不能指定排序規則,
使用如下:
hive (mydb)> select * from emp distribute by deptno sort by deptno;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 10 seconds 130 msec
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
7698 BLAKE MANAGER 7839 2011-05-01 2850 NULL 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10
7839 KING PRESIDENT NULL 2011-11-07 5000 NULL 10
7782 CLARK MANAGER 7839 2011-06-09 2450 NULL 10
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
Time taken: 43.018 seconds, Fetched: 14 row(s)
hive (mydb)> select * from emp cluster by deptno;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
...
Total MapReduce CPU Time Spent: 8 seconds 650 msec
OK
emp.empno emp.ename emp.job emp.mgr emp.hiredate emp.sal emp.comm emp.deptno
7654 MARTIN SALESMAN 7698 2011-09-28 1250 1400 30
7900 JAMES CLERK 7698 2011-12-03 950 NULL 30
7698 BLAKE MANAGER 7839 2011-05-01 2850 NULL 30
7521 WARD SALESMAN 7698 2011-02-22 1250 500 30
7844 TURNER SALESMAN 7698 2011-09-08 1500 0 30
7499 ALLEN SALESMAN 7698 2011-02-20 1600 300 30
7934 MILLER CLERK 7782 2012-01-23 1300 NULL 10
7839 KING PRESIDENT NULL 2011-11-07 5000 NULL 10
7782 CLARK MANAGER 7839 2011-06-09 2450 NULL 10
7788 SCOTT ANALYST 7566 2017-07-13 3000 NULL 20
7566 JONES MANAGER 7839 2011-04-02 2975 NULL 20
7876 ADAMS CLERK 7788 2017-07-13 1100 NULL 20
7902 FORD ANALYST 7566 2011-12-03 3000 NULL 20
7369 SMITH CLERK 7902 2010-12-17 800 NULL 20
Time taken: 36.315 seconds, Fetched: 14 row(s)
hive (mydb)>
可以看到,兩種方式效果相同,但是這里沒有實際的意義,
現在對排序總結如下:
-
order by:執行全域排序,效率低,生產環境中慎用
-
sort by:使資料區域有序(在reduce內部有序)
-
distribute by:按照指定的條件將資料分組,常與sort by聯用,使資料區域有序
-
cluster by:當distribute by與sort by是同一個欄位時,可使用cluster by簡化語法
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357063.html
標籤:其他