課題背景

經過一學期的大資料導論學習后,我們突然接到了結業大作業——進行一次大資料分析專案的通知,
剛剛學習了一些大綱型別的知識的我們自然是不知所措的,經過資料查閱后我們決定通過虛擬機搭建Hadoop集群進行偽分布式計算完成該專案,
然后就開始了安裝了20次虛擬機的折磨之路本來打算錄視頻全程教程的,奈何時間緊迫,只能寫一個博客幫助學弟學妹少走彎路
文中環境:
- Hadoop-v3.3.1
- JDK-8u202-linux-x64(1.8.202)
- CentOS-7-2009
我對Hadoop的理解
鄙人知識淺薄,這部分還在寫
Hadoop 安裝與配置
Ⅰ 環境搭建
-
虛擬機環境:VMWare Workstation 16 Player
- 選擇該軟體的原因有
- 普適性強:網路上有很多相關資料可供查閱
- 免費:支持正版!苦逼大學生自然是用不起企業級的Pro版本的~~(如果家境優渥可以考慮一下)~~
- 該軟體的問題:沒有虛擬網路編輯器,DHCP動態分配可能導致后續網段不穩定
- 選擇該軟體的原因有
-
系統選擇:CentOS 7 64-bit
- CentOS,大家的選擇!穩定又輕量!而且還免費!
- 安裝的時候可以選擇最小安裝,畢竟安一個桌面沒啥用
-
安裝步驟
虛擬機安裝
- 在VMWare Player(以下簡稱Player)中新建一個虛擬機,在選項中選擇“稍后安裝”
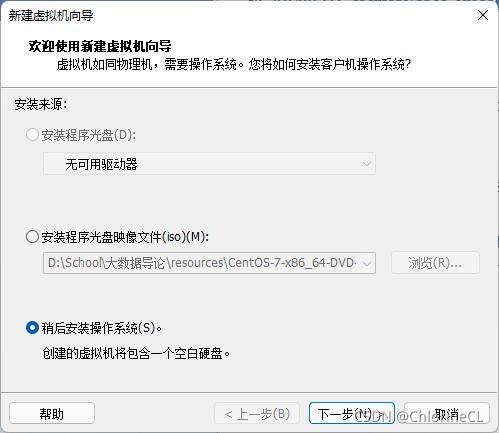
【如果此時選擇直接安裝會默認安裝桌面GUI,會占用大量資源且沒有作用當然如果你電腦強到可以隨便霍霍當我沒說】
- 在VMWare Player(以下簡稱Player)中新建一個虛擬機,在選項中選擇“稍后安裝”
-
一路下一步,命名和路徑自己選擇,硬體都用默認的就可以【此處僅針對課題的需求,實際需求請根據自己的需要自定義】
-
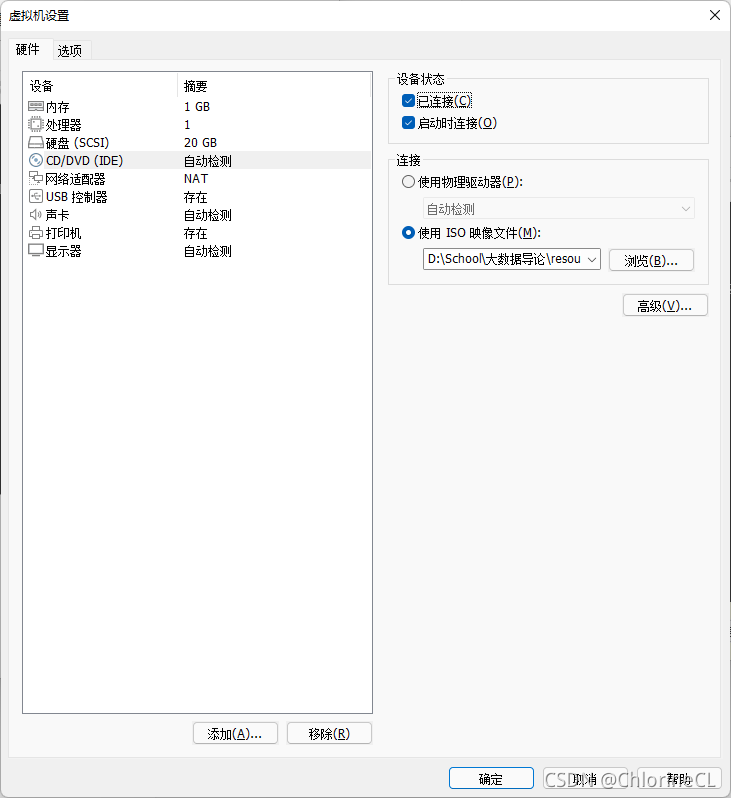
創建完畢后進入虛擬機,在左上角選擇 Player》可移動設備》CD/DVD》設定
在彈出視窗中,勾選已連接并打開下載的系統鏡像
CentOS國內下載鏡像(THU鏡像站)
隨便找一個你喜歡的版本下就行:Index of /centos/
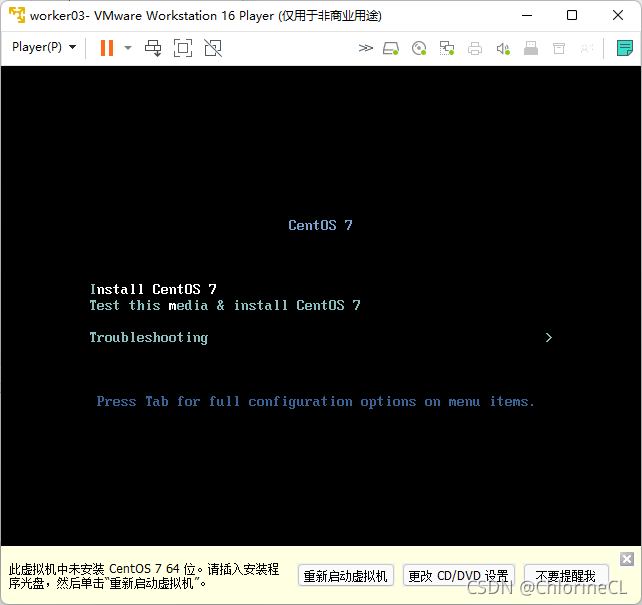
安裝系統
-
選擇Install CentOS 7
-
選擇中文(最下面)
- 點安裝位置然后點右上角完成

- 點下面的 網路和主機名,然后打開網路
- 開始安裝,然后點ROOT用戶,并輸入密碼,之后等待安裝完成后點擊右下角的重啟按鈕
- 進入系統后用 root 賬戶登錄(注意Linux終端輸入密碼是沒有占位符提示的)
- 安裝ifconfig來查詢IP(cent OS最小安裝是不包含net-tools的)
yum search ifconfig #在線查詢與ifconfig相關的軟體包yum install net-tools.x86_64 -y #安裝查詢到的軟體包(這里應該是你查到的包名)-y表示全部同意ifconfig #查詢IP地址如果出現連接超時可通過ping命令查詢網路,按ctrl+c退出ping
ping www.baidu.com
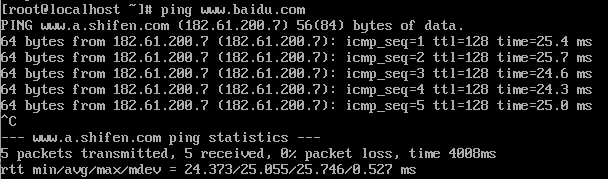
-
通過XShell進行遠程終端控制虛擬機【此步為可選,以下操作都可以直接通過虛擬機操作,但Xshell好用而且免費啊~】
-
XShell安裝:省略,直接百度XShell就行
-
獲取ifconfig獲得的ip地址:下圖中 inet
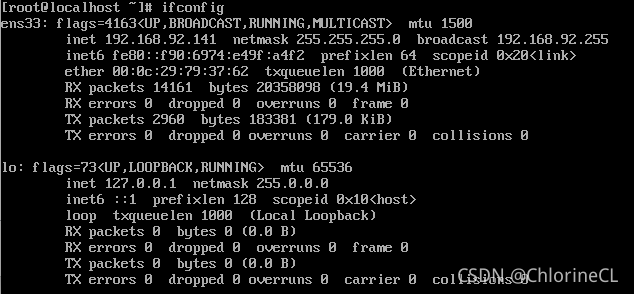
-
點擊新建
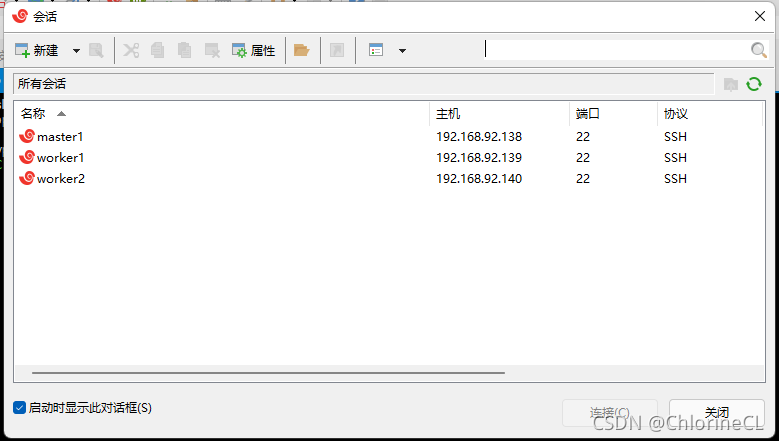
-
自己命名會話,主機改成剛剛inet得到的IP地址
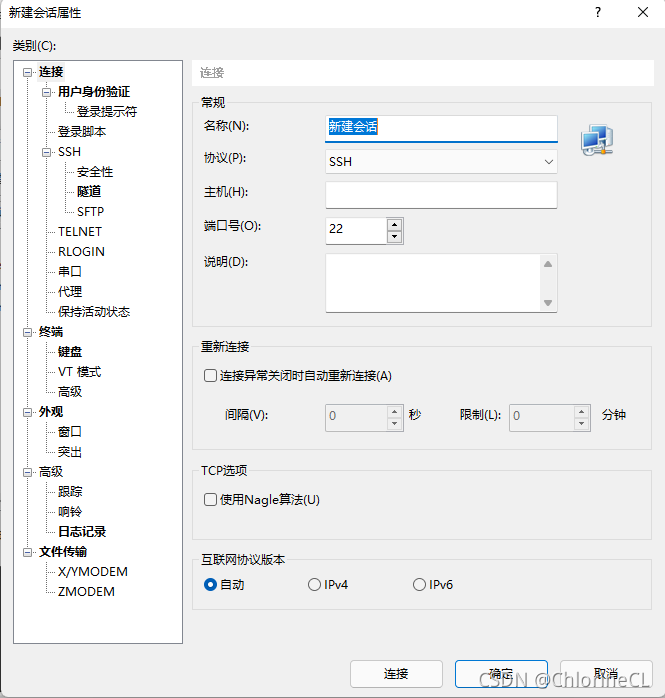
-
點接受并保存(一次性接受以后每次都會讓你確認)
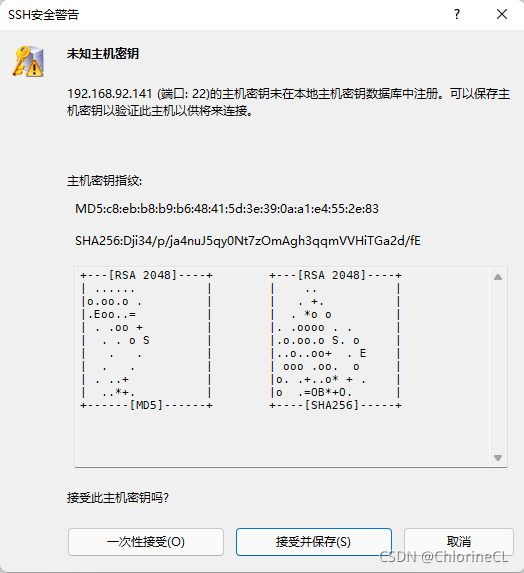
-
后續視窗輸入剛剛設定的root賬戶和密碼
-
出現下述界面表示連接成功
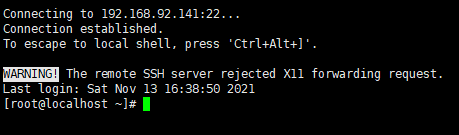
-
- 點安裝位置然后點右上角完成
配置 Linux 系統:每臺虛擬機都需要設定
-
關閉防火墻:防火墻會阻止結點之間的連接
`systemctl stop firewalld` `systemctl disable firewalld`

- 設定主機名并重啟(也可以所有都配置完了再重啟)
hostnamectl set-hostname NAME #此處NAME自己取
- 修改hosts:方便通過主機名登錄,避免每次都敲IP
vi /etc/hosts #呼叫vi編輯器
-
進入編輯器后按i鍵,下方的提示會變為 -編輯模式-
-
通過方向鍵進行移動,除了不能使用數字小鍵盤和滑鼠操作和其他文本編輯器相同
-
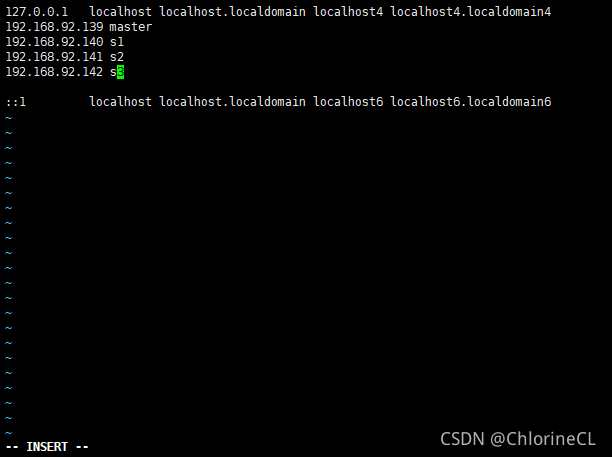
在hosts中應錄入你所有虛擬機結點的IP和你取的名字(名字盡量和設定的主機名相同)
-
錄入完后按ESC,然后輸入:wq(可以自行百度了解更多vim命令)
-
后期你也可以在一臺主機上配置完hosts后通過scp復制到其他主機上
-
定義完成后可以通過相同的ping主機名方法檢查是否設定成功和連通
- 配置ssh登錄
ssh-keygen -b 1024 -t rsa #在本機生成密鑰和公鑰,一路回車即可
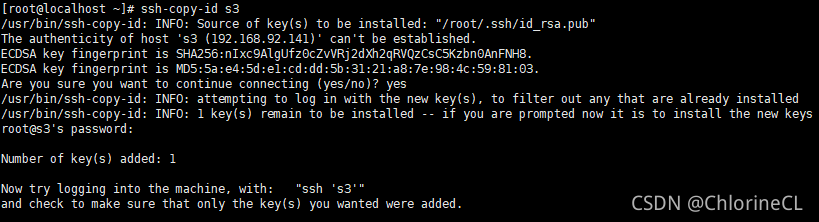
ssh-copy-id HOST-NAME #HOST-NAME是你在hosts中定義的主機名,也可以直接輸入IP
- copy-id命令需要根據提示輸入root密碼
- 在本機copy-id將本機公鑰發送給目標機器,表示可以從本機免密登錄目標機器
- 根據需要我們只需要配置主機到每個從機、自身到自身的免密登錄即可
- 設定密鑰訪問權限
chmod 600 /root/.ssh/authorized_keys #可以自己百度chmod命令說明
Ⅱ Hadoop 配置
【只用在主機配置,從機復制即可】
下載連接
? Hadoop-3.3.1 THU 下載地址:hadoop-3.3.1.tar.gz
? Java 官方下載地址【請下載jdk8的linux版本 *.tar.gz】:jdk downlowds
JAVA配置
-
安裝rz包:方便從宿主機傳檔案到虛擬機,也可以通過FTP軟體實作
但我感覺rz會快一點-
安裝命令
yum search rzyum install lrzsz.x86_64 -y -
呼叫命令
rz #上傳檔案到當前目錄sz FILE-NAME #下載這個檔案到宿主機 -
注意:不要使用rz上傳除了單檔案外的任何檔案(包括檔案夾和多個檔案),這可能導致檔案系統錯亂
被這樣搞壞了好多個虛擬機嗚嗚 -
如果你改了名字沒有重啟一定要重啟來再用rz,會報錯的!
-
-
上傳本地jdk包和hadoop包到虛擬機
-
使用tar命令解壓兩個包
tar -xzvf FILE.tar.gz #可以自己搜一下tar命令的用法【可以使用ls命令看看目錄里有啥,藍色的就是檔案夾啦】

-
配置環境變數:免得后面再改一次就放在hadoop部分一起配置了
Hadoop配置
-
進入組態檔夾
cd /root/hadoop-3.3.1/etc/hadoop #這里hadoop-3.3.1是你自己的檔案夾的名字 -
挨個用vim修改組態檔
yum install vim-enhanced.x86_64 -y #這里推薦裝一個vim包會舒服一點需要修改的組態檔都列在下面了【添加在的標簽里!】
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hdtmp</value>
</property>hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
以下不是必須配置
<property>
<name>dfs.namenode.rpc-address</name>
<value>master:9000</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdtmp/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdtmp/data<value>
</property>mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property> -
修改啟動腳本
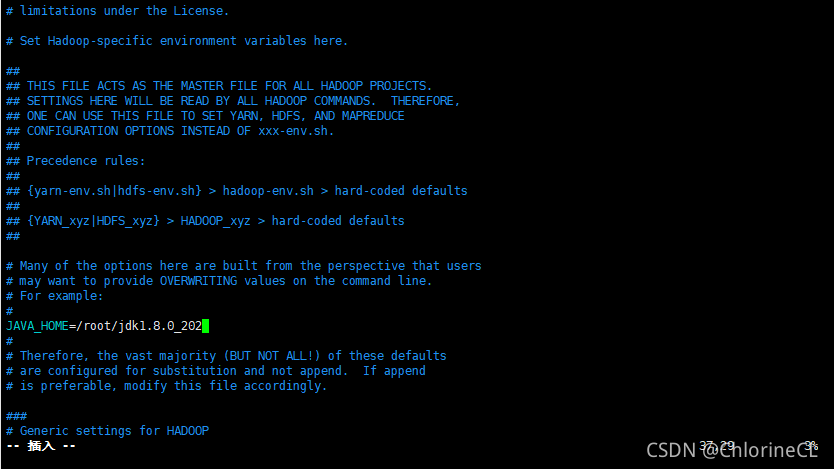
- etc/hadoop/hadoop-env.sh
- 找到JAVA_HOME這個選項(默認是被注釋的)
- 修改為你解壓的JAVA的絕對路徑(偷懶用環境變數可能會報錯)
- etc/hadoop/hadoop-env.sh
-
cd到hadoop根目錄下的sbin檔案夾,在以下檔案的開頭添加下面的陳述句
start-dfs.sh,stop-dfs.sh
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=rootstart-yarn.sh,stop-yarn.sh
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
-
修改etc/hadoop/workers檔案【hadoop2.x版本為slaves 3.x版本為workers】
- 添加你所有的主機名到其中(hosts中定義的),也可以輸入IP
- 一定要洗掉自帶的專案
-
修改環境變數
-
進入環境變數檔案
vim /root/.bash_profile -
添加下述配置:按照你自己的目錄進行修改【可以自己百度環境變數的語法】
export JAVA_HOME=/root/jdk1.8.0_202
export HADOOP_HOME=/root/hadoop-3.3.1
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$JAVA_HOME/bin:$PATH. -
重繪環境變數
source /root/.bash_profile
-
-
創建臨時檔案目錄:記住剛剛core-site.xml中的hadoop.tmp.dir指定的目錄
- 以文中的目錄為例
- 切換到root目錄
cd ~ - 創建檔案夾
mkdir hdtmp
-
重新啟動虛擬機后配置就完成了!
-
復制到其他虛擬機
-
復制命令:可以直接復制整個檔案夾,配置了ssh免密登錄后不需要輸入密碼
scp -r FILE root@HOST-NAME: DIR -
需要復制的檔案有
- jdk 目錄:必須
- hadoop 目錄:必須
- .bash_profile:不復制可以自己設定
- hosts:不復制可以自己設定(但是需要確保囊括了所有主機)
-
Hadoop實戰演練
-
測驗Hadoop安裝情況:分別輸入hadoop,java,若沒有出現無法識別說明配置成功
-
格式化Hadoop
-
只能在你指定的主機進行格式化(通常命名為master),格式化后該節點稱為namenode,負責任務的分配
-
切記只能格式化一次,如果不清空臨時檔案就再次格式化會導致clusterID不相同,dataNode和nameNode無法連接的情況
-
格式化命令:
hadoop namenode -format -
如果要重置集群(重新格式化),需要洗掉每個節點hadoop目錄下的log檔案夾和指定的hdtmp檔案夾
-
-
Hadoop 集群!啟動!
- 啟動集群
start-all.sh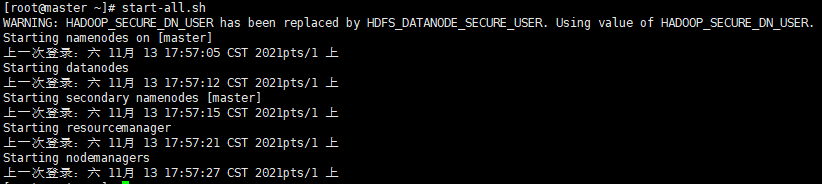
- 檢查主機啟動情況
jps
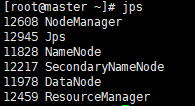
- 檢查從機啟動情況
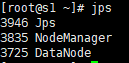
- 如果運行狀態和截圖一致,說明啟動成功惹!
- 啟動集群
-
運行一個測驗算例吧!
- hadoop內置了很多測驗算例(可以自己百度看一看有哪些),存放在share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar 中
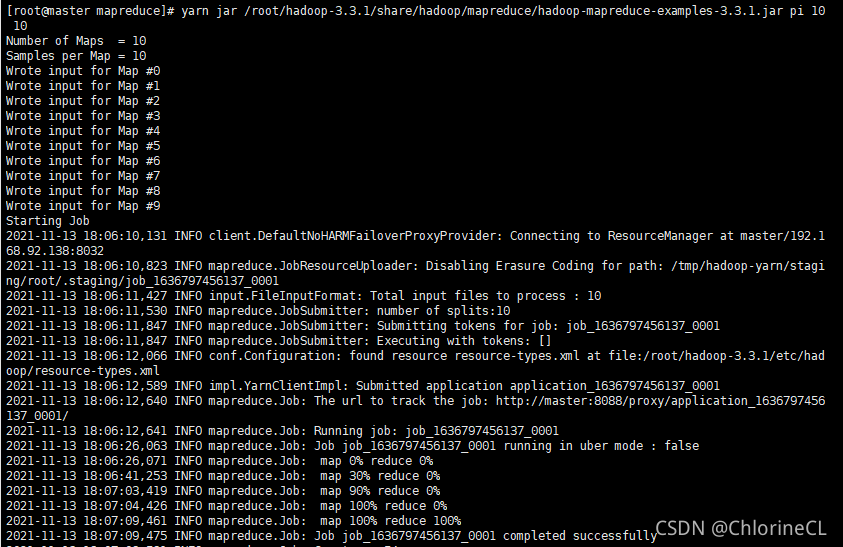
- 呼叫一個內置的PI算例
yarn jar /root/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar pi 10 10
-
開頭的命令yarn表示集群模式,hadoop表示單機模式,一般就用yarn
-
jar表示執行后面路徑的jar檔案
-
pi表示指定上面那么多算例中的pi算例
-
10 10表示計算精度
-
若終端回傳如下圖結果表示集群正式搭建成功
終于成功了,想起曾經的苦逼程序我都要寫淚目了
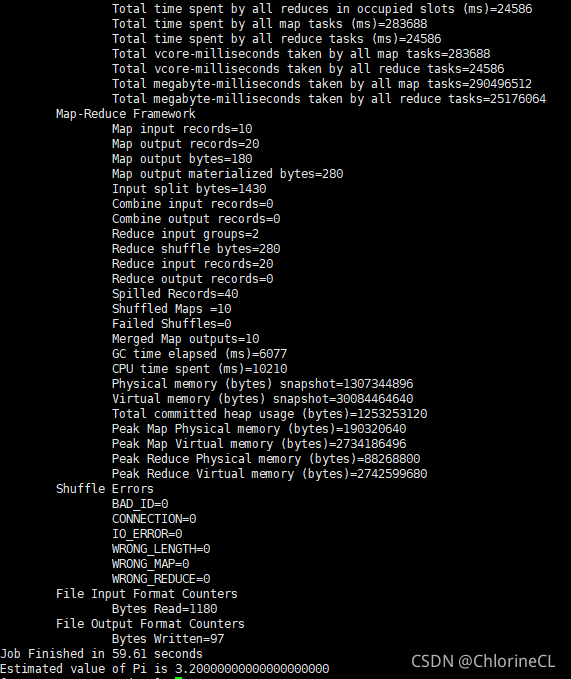
- 來!試試看HDFS和WordCount!
-
HDFS的理解:詳見上面的理解部分或者自己百度
-
HDFS是Hadoop的檔案格式,和yarn的資源分配一同提供了一個多節點的集群化計算平臺,說人話就是hadoop用hdfs(檔案管理系統)和yarn(資源分配系統)將很多個計算機虛擬成了一個計算機來方便運算
-
剛剛我們的pi算例呼叫了yarn行程,利用mapreduce將一個運算任務分配給了所有結點(map)最后統合起來(reduce)【嚴格地來說yarn的作業原理不是簡單的分配任務】,但是沒有呼叫hdfs(至少看起來沒有),所以現在我們的wordcount示例就用hdfs試一試
-
-
HDFS操作命令:HDFS的默認路徑也是/root,我們也可以使用絕對路徑(獨立于任何機器的本地目錄)
hdfs dfs -mkdir DIR在對應路徑創建目錄hdfs dfs -cat DIR讀取對應路徑的檔案hdfs dfs -ls DIR列舉對應目錄的檔案hdfs dfs -put FILE DIR上傳檔案到對應目錄hdfs dfs -get DIR下載對應目錄的檔案到本地目錄 -
試著運行wordcount算例
自己在任意本地目錄新建或者上傳一個文本檔案(任何文本檔案都行)
hdfs dfs -mkdir wctest
hdfs dfs -put test wctesttest是你自己的文本檔案
yarn jar /root/hadoop-3.3.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar wordcount wctest/test wctest/test.outputwctest/test.output是輸出的目錄 -
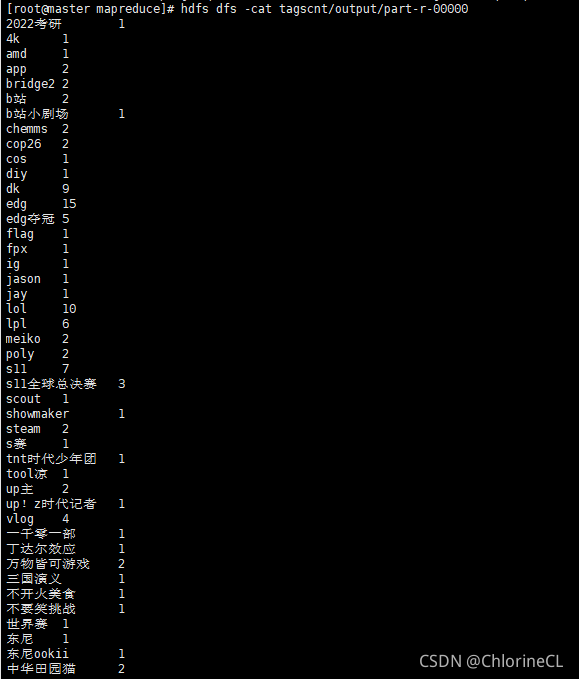
運行結果:運行完畢后在test.output會生成如下檔案

-
_SUCCESS是空檔案,表示運算成功
-
part-r-00000是運行結果的檔案,可以使用
hdfs dfs -cat訪問
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357064.html
標籤:其他
上一篇:大資料開發基礎入門與專案實戰(三)Hadoop核心及生態圈技術堆疊之4.Hive DDL、DQL和資料操作
下一篇:pandas生成新的累積連乘資料列(cumprod)、pandas生成新的累積連乘cumprod資料列(資料列中包含NaN的情況)、pandas計算整個dataframe的所有資料列的累積連乘