學習總結
- 上次學習的一坨推薦系統的離線評估指標和方法,離線評估不能還原線上的所有變數,如視頻網站需要提高的【用戶觀看時長】指標等,幾乎所有的互聯網公司,線上 A/B 測驗都是驗證新模型、新功能、新產品是否能夠提升效果的主要測驗方法,
- 線上 A/B 測驗的基本原理和評估指標,并且在 SparrowRecsys 上實作了 A/B 測驗的模塊:模塊的基本框架就是針對不同的
userId,隨機分配給不同的實驗桶,每個桶對應著不同的實驗設定(實驗組和對照組),
分別了解 A/B 測驗的定義和優勢、設計原則以及在線評估指標(如下3點),
- A/B 測驗,又叫“分流測驗”或“分桶測驗”,它把被測物件隨機分成 A、B 兩組,通過對照測驗的方法得出實驗結論,在線上評估指標的制定程序中,要盡量保證這些指標與線上業務的核心指標保持一致,從而知道是否達成了公司的商業目標,
- 相比于離線評估,A/B 測驗有三個優勢:實驗環境就是線上的真實生產環境;可以直接得到線上的商業指標;不受離線資料“資料有偏”現象的影響,
- 在 A/B 測驗的設計程序中,要遵循google提出的層與層之間的流量“正交”,同層之間的流量“互斥”原則,這樣才能既正確又高效地同時完成多組 A/B 測驗,
文章目錄
- 學習總結
- 一、理解A/B測驗
- 1.1 還原線上環境
- 1.2 模型相關的其他指標
- 1.3 資料有偏現象
- 二、A/B 測驗的“分桶”和“分層”原則
- 2.1 分桶
- 2.2 分層,做對照實驗
- 2.3 正交與互斥
- (1)層間流量正交
- (2)層內流量互斥
- 三、線上 A/B 測驗的評估指標
- 四、SparrowRecSys 中 A/B 測驗的實作方法
- 4.1 A/B測驗模塊
- 4.2 具體的業務邏輯中
- 五、作業
- Reference
一、理解A/B測驗
A/B 測驗又被稱為“分流測驗”或“分桶測驗”,它通過把被測物件隨機分成 A、B 兩組,分別對它們進行對照測驗的方法得出實驗結論,具體到推薦模型測驗的場景下,它的流程:
- 先將用戶隨機分成實驗組和對照組,
- 然后給實驗組的用戶施以新模型,給對照組的用戶施以舊模型,
- 再經過一定時間的測驗后,計算出實驗組和對照組各項線上評估指標,來比較新舊模型的效果差異,
- 最后挑選出效果更好的推薦模型,
A/B測驗的三大優點:
1.1 還原線上環境
離線評估無法完全還原線上的工程環境,
離線評估往往不考慮線上環境的延遲、資料丟失、標簽資料缺失等情況,或者說很難還原線上環境的這些細節(如變數,ex:視頻網站需要提高的【用戶觀看時長】指標等),因此,離線評估環境只能說是理想狀態下的工程環境,得出的評估結果存在一定的失真現象,
1.2 模型相關的其他指標
線上系統的某些商業指標在離線評估中無法計算,
離線評估一般是針對模型本身進行評估的,無法直接獲得與模型相關的其他指標,特別是商業指標,離線評估關注的往往是 ROC 曲線、PR 曲線的改進,而線上評估卻可以全面了解推薦模型帶來的用戶點擊率、留存時長、PV 訪問量這些指標的變化,
這些指標才是最重要的商業指標,跟公司要達成的商業目標緊密相關,而它們都要由 A/B 測驗進行更全面準確的評估,
1.3 資料有偏現象
離線評估無法完全消除資料有偏(Data Bias)現象的影響,
什么叫“資料有偏”呢?因為離線資料都是系統利用當前演算法生成的資料,因此這些資料本身就不是完全客觀中立的,它是用戶在當前模型下的反饋,所以說,用戶本身有可能已經被當前的模型“帶跑偏了”,你再用這些有偏的資料來衡量你的新模型,得到的結果就可能不客觀,
二、A/B 測驗的“分桶”和“分層”原則
A/B 測驗的原理就是把用戶分桶后進行對照測驗,
問題:比如到底怎樣才能對用戶進行一個公平公正的分桶呢?如果有多組實驗在同時做 A/B 測驗,怎樣做才能讓它們互不干擾?
樣本的獨立性和分桶程序的無偏性,
“獨立性”:指的是同一個用戶在測驗的全程只能被分到同一個桶中,
“無偏性”:指的是在分桶程序中用戶被分到哪個實驗桶中應該是一個純隨機的程序,
2.1 分桶
舉栗:把用戶 ID 是奇數的用戶分到對照組,把用戶 ID 是偶數的用戶分到實驗組,這個策略只有在用戶 ID 完全是隨機生成的前提下才能說是無偏的,如果用戶 ID 的奇偶分布不均的前提,我們就無法保證分桶程序的無偏性,所以在實踐的時候,我們經常會使用一些比較復雜的 Hash 函式,讓用戶 ID 盡量隨機地映射到不同的桶中,
2.2 分層,做對照實驗
問題:要知道,在實際的 A/B 測驗場景下,同一個網站或應用往往要同時進行多組不同型別的 A/B 測驗,比如,前端組正在進行不同 app 界面的 A/B 測驗的時候,后端組也在進行不同中間件效率的 A/B 測驗,同時演算法組還在進行推薦場景 1 和推薦場景 2 的 A/B 測驗,這個時候問題就來了,這么多 A/B 測驗同時進行,我們怎么才能讓它們互相不干擾呢?
低效方法:全部并行地做這些實驗,線上測驗資源非常緊張,如果不合理設計,很快所有流量資源都會被A/B測驗占滿,
2.3 正交與互斥
Google 在一篇關于實驗測驗平臺的論文《Overlapping Experiment Infrastructure: More, Better, Faster Experimentation》中,詳細介紹了 A/B 測驗分層以及層內分桶的原則,
關鍵句:層與層之間的流量“正交”,同層之間的流量“互斥”,
(1)層間流量正交
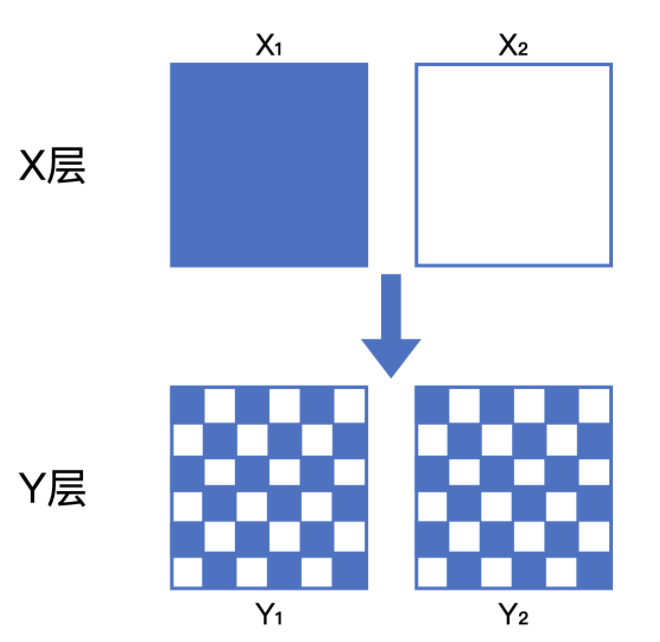
層與層之間的流量“正交”,它指的是層與層之間的獨立實驗的流量是正交的,一批實驗用的流量穿越每層實驗時,都會再次隨機打散,然后再用于下一層的實驗,
如下圖,假設在X層的實驗中,流量已經被隨機平均分為X1(藍色)和X2(白色)兩部分,當他們穿越到Y層實驗時,X1和X2的流量會被隨機且均勻地分配給Y層的兩個桶Y1和Y2——如果Y1和Y2的X層流量分配不均勻,那么Y層的樣本就是有偏的,即Y層的實驗結果會被X層的實驗影響,無法客觀地反應Y層實驗組和對照組變數的影響,
(2)層內流量互斥
同層之間的流量“互斥”,這里的“互斥”具體有 2 層含義:
- 如果同層之間進行多組 A/B 測驗,不同測驗之間的流量不可以重疊;
- 一組 A/B 測驗中實驗組和對照組的流量是不重疊的,
- 在基于用戶的 A/B 測驗中,“互斥”的含義還可以為:不同實驗之間以及 A/B 測驗的實驗組和對照組之間的用戶是不重疊的,特別是對推薦系統來說,用戶體驗的一致性是非常重要的,也就是說我們不可以讓同一個用戶在不同的實驗組之間來回“跳躍”,這樣會嚴重損害用戶的實際體驗,也會讓不同組的實驗結果相互影響,因此在 A/B 測驗中,保證同一用戶始終分配到同一個組是非常有必要的,
小結:A/B 測驗的“正交”與“互斥”原則共同保證了 A/B 測驗指標的客觀性,而且由于分層的存在,也讓功能無關的 A/B 測驗可以在不同的層上執行,充分利用了流量資源,
三、線上 A/B 測驗的評估指標

- 測驗前:在A/B測驗中需要多和產品、運營團隊溝通,在測驗開始前一期指定大家都認可的評估指標(可以參考上表中列出的電商類推薦模型、新聞類推薦模型、視頻類推薦模型的主要線上 A/B 測驗評估指標,);
- 測驗后:A/B測驗一般是模型上線前的最后一道測驗,通過該測驗后的模型一般會直接服務于用戶,
來完成公司的商業目標,因此,A/B 測驗的指標應該與線上業務的核心指標保持一致,
線上 A/B 測驗的指標和離線評估的指標(諸如 AUC、F1- score 等)之間的差異非常大,
原因:離線評估不具備直接計算業務核心指標的條件,因此退而求其次,選擇了偏向于技術評估的模型相關指標,但公司更關心的是能夠驅動業務發展的核心指標,這也是 A/B 測驗評估指標的選取原則,
四、SparrowRecSys 中 A/B 測驗的實作方法
既然是線上測驗,那我們肯定需要在推薦服務器內部來實作這個 A/B 測驗的模塊,
模塊的基本框架就是針對不同的 userId,隨機分配給不同的實驗桶,每個桶對應著不同的實驗設定,可以直接在實作過的“猜你喜歡”功能(【王喆-推薦系統】復習篇-Sparrow的個性化推薦功能)上進行實驗,實驗組的設定是演算法 NerualCF,對照組的設定是 Item2vec Embedding 演算法,
4.1 A/B測驗模塊
(1)建立一個ABTest模塊(為每個用戶分給實驗設定),并且給不在A/B測驗的用戶設定了默認模型(默認模型是不在實驗范圍內的用戶的設定),
(2)分配實驗組:
- 使用
getGonfigByUserId函式確定用戶所在的實驗組,該函式的唯一輸入引數是userId; - 然后利用
userId的hashCode把數值型的ID打散; - 再利用userId的
hashCode和trafficSplitNumber引數進行余數操作,根據余數值確定userId在哪一個實驗組里,
A/B 測驗模塊的主要實作:
public class ABTest {
final static int trafficSplitNumber = 5;
final static String bucketAModel = "emb";
final static String bucketBModel = "nerualcf";
final static String defaultModel = "emb";
public static String getConfigByUserId(String userId){
if (null == userId || userId.isEmpty()){
return defaultModel;
}
if(userId.hashCode() % trafficSplitNumber == 0){
System.out.println(userId + " is in bucketA.");
return bucketAModel;
}else if(userId.hashCode() % trafficSplitNumber == 1){
System.out.println(userId + " is in bucketB.");
return bucketBModel;
}else{
System.out.println(userId + " isn't in AB test.");
return defaultModel;
}
}
}
trafficSplitNumber引數:指把我們的全部用戶分成幾份,
分流操作:比如把所有用戶分成了 5 份,讓第 1 份用戶參與 A 組實驗,第 2 份用戶參與 B 組實驗,其余用戶繼續使用系統的默認設定,把流量劃分之后,選取一部分參與 A/B 測驗,
4.2 具體的業務邏輯中
在實際要進行 A/B 測驗的業務邏輯中,需要呼叫 A/B 測驗模塊來獲得正確的實驗設定,比如,下面選用了《猜你喜歡》功能進行 A/B 測驗,就需要在相應的實作 RecForYoService 類中添加 A/B 測驗的代碼,具體的實作如下:
(1)呼叫 ABTest.getConfigByUserId 函式獲取用戶對應的實驗設定;
(2)然后把得到的引數 model 傳入后續的業務邏輯代碼,
注意:這里設定了一個全域的 A/B 測驗使能標識 Config.IS_ENABLE_AB_TEST,在測驗這部分代碼的時候,要把這個使能標識改為 true,
if (Config.IS_ENABLE_AB_TEST){
model = ABTest.getConfigByUserId(userId);
}
//a simple method, just fetch all the movie in the genre
List<Movie> movies = RecForYouProcess.getRecList(Integer.parseInt(userId), Integer.parseInt(size), model);
上面就是經典的 A/B 測驗核心代碼的實作,在實際的應用中,A/B 測驗的實作當然要更復雜一些:
- 不同實驗的設定往往是存盤在資料庫中的,需要我們從資料庫中拿到它,
- 為了保證分組時的隨機性,往往會創建一些復雜的
hashCode函式,保證能夠均勻地把用戶分到不同的實驗桶中, - 盡管實作會更復雜,但整個 A/B 測驗的核心邏輯沒有變化,
五、作業
學習了A/B 測驗的分層和分桶的原則,如果我們在測驗模型的時候,一個實驗是在首頁測驗新的推薦模型,另一個實驗是在內容頁測驗新的推薦模型,你覺得這兩個實驗應該放在同一層,還是可以放在不同的層呢?為什么?
【答】對于問題,應該放在同一層,因為首頁推薦可能會把一些有興趣偏好的用戶匯入到對應的內容頁,比如首頁推薦球鞋,對于想購買球鞋的就會進入到球鞋內容頁,這樣對于內容頁推薦來說 ,用戶不是隨機,是有偏的,
Reference
(1)https://github.com/wzhe06/Reco-papers
(2)《深度學習推薦系統實戰》,王喆
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357231.html
標籤:其他
上一篇:linux面試題
下一篇:樹莓派入門(保姆級)