-
隨機森林演算法簡介:
-
隨機森林(Random Forest)是一種靈活性很高的機器學習演算法,
-
它的底層是利用多棵樹對樣本進行訓練并預測的一種分類器,在機器學習的許多領域都有廣泛地應用,
-
例如構建醫學疾病監測和病患易感性的預測模型,筆者自己曾經將RF演算法應用于癌變細胞的檢測和分析上,
-
-
隨機森林演算法原理:
-
隨機森林的本質就是通過集成學習(Ensemble Learning)將多棵決策樹集成的一種演算法,
-
那么我們先簡單了解集成學習,
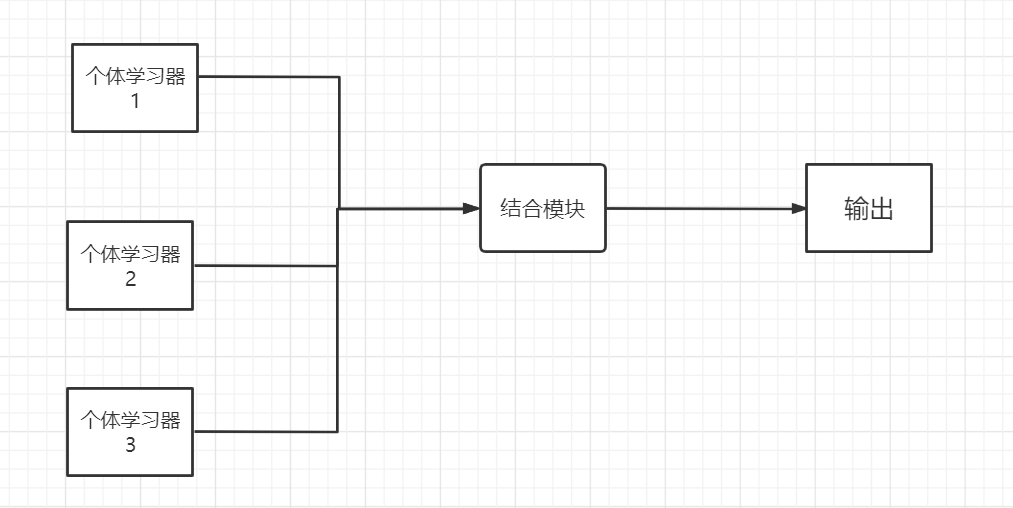
- 繼承學習的意義是構建并結合多個學習器來完成學習任務,也被稱為多分類器系統,
-
集成學習分為 序列集成方法與 并行集成方法,隨機森林演算法屬于后者的典型代表,
-
使用這種方法的集成學習,優點在于充分利用了基礎學習器之間的獨立性,通過對結果進行平均顯著降低錯誤的概率,
-
下面再簡單說下決策樹的原理
-
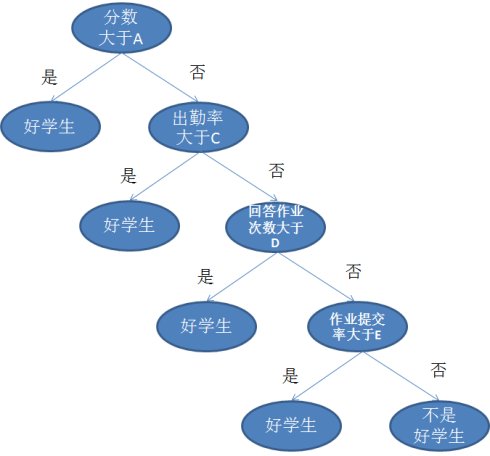
決策樹是一種資料集劃分的方法
-
資料劃分為具有相似值的子集來構建出一個完整的樹,決策樹上每一個非葉節點是它對應的特征屬性的測驗集合,
-
經過每個特征屬性的測驗,產生了多個分支,而每個分支就是對于特征屬性測驗中某個值域的輸出子集,
-
決策樹上每個葉子節點就是表達輸出結果的資料,
- 綜合上面對集成學習和決策樹的介紹,我們可以得出結論:隨機森林是由很多的相互不關聯的決策樹組成的,利用集成學習思想搭建的一種機器學習演算法 它的準確率要遠高于單一決策樹,
- 隨機森林演算法搭建步驟:
1.用N來表示訓練用例(樣本)的個數,M表示特征數目,
2.輸入特征數目m,用于確定決策樹上一個節點的決策結果;其中m應遠小于M,
3. 從N個訓練用例(樣本)中以有放回抽樣的方式,取樣N次,形成一個訓練集(即bootstrap取樣),并用未抽到的用例(樣本)作預測,評估其誤差,
4. 對于每一個節點,隨機選擇m個特征,決策樹上每個節點的決定都是基于這些特征確定的,根據這m個特征,計算其最佳的分裂方式,每棵樹都會完整成長而不會剪枝,這有可能在建完一棵正常樹狀分類器后會被采用),

- 隨機森林的優點:
- 可以判斷出不同特征之間的相互影響
- 因為是并行演算法,所以訓練速度較快,
- 不容易過擬合,
- 隨機森林的缺點:
- 隨機森林已經被證明在某些噪音較大的分類或回歸問題上會過擬合,
- Python代碼實作
'''
演算法原理:
隨機森林是一個包含多個決策樹的分類器, 并且其輸出的類別是由個別樹輸出的類別的眾數而定,
'''
from random import seed
from random import randint
import numpy as np
# 建立一棵CART樹
def data_split(index, value, dataset):
left, right = list(), list()
for row in dataset:
if row[index] < value:
left.append(row)
else:
right.append(row)
return left, right
# 計算基尼指數
def calc_gini(groups, class_values):
gini = 0.0
total_size = 0
for group in groups:
total_size += len(group)
for group in groups:
size = len(group)
if size == 0:
continue
for class_value in class_values:
proportion = [row[-1] for row in group].count(class_value) / float(size)
gini += (size / float(total_size)) * (proportion * (1.0 - proportion))
return gini
# 找最佳分叉點
def get_split(dataset, n_features):
class_values = list(set(row[-1] for row in dataset))
b_index, b_value, b_score, b_groups = 999, 999, 999, None
features = list()
while len(features) < n_features:
# 往features添加n_features個特征(n_feature等于特征數的根號),特征索引從dataset中隨機取
index = randint(0, len(dataset[0]) - 2)
if index not in features:
features.append(index)
for index in features:
for row in dataset:
groups = data_split(index, row[index], dataset)
gini = calc_gini(groups, class_values)
if gini < b_score:
b_index, b_value, b_score, b_groups = index, row[index], gini, groups
# 每個節點由字典組成
return {'index': b_index, 'value': b_value, 'groups': b_groups}
# 多數表決
def to_terminal(group):
outcomes = [row[-1] for row in group]
return max(set(outcomes), key=outcomes.count)
# 分枝
def split(node, max_depth, min_size, n_features, depth):
left, right = node['groups']
del (node['groups'])
if not left or not right:
node['left'] = node['right'] = to_terminal(left + right)
return
if depth >= max_depth:
node['left'], node['right'] = to_terminal(left), to_terminal(right)
return
if len(left) <= min_size:
node['left'] = to_terminal(left)
else:
node['left'] = get_split(left, n_features)
split(node['left'], max_depth, min_size, n_features, depth + 1)
if len(right) <= min_size:
node['right'] = to_terminal(right)
else:
node['right'] = get_split(right, n_features)
split(node['right'], max_depth, min_size, n_features, depth + 1)
# 建立一棵樹
def build_one_tree(train, max_depth, min_size, n_features):
root = get_split(train, n_features)
split(root, max_depth, min_size, n_features, 1)
return root
# 用一棵樹來預測
def predict(node, row):
if row[node['index']] < node['value']:
if isinstance(node['left'], dict):
return predict(node['left'], row)
else:
return node['left']
else:
if isinstance(node['right'], dict):
return predict(node['right'], row)
else:
return node['right']
# 隨機森林類
class randomForest:
def __init__(self,trees_num, max_depth, leaf_min_size, sample_ratio, feature_ratio):
self.trees_num = trees_num # 森林的樹的數目
self.max_depth = max_depth # 樹深
self.leaf_min_size = leaf_min_size # 建立樹時,停止的分枝樣本最小數目
self.samples_split_ratio = sample_ratio # 采樣,創建子集的比例(行采樣)
self.feature_ratio = feature_ratio # 特征比例(列采樣)
self.trees = list() # 森林
# 有放回的采樣,創建資料子集
def sample_split(self, dataset):
sample = list()
n_sample = round(len(dataset) * self.samples_split_ratio)
while len(sample) < n_sample:
index = randint(0, len(dataset) - 2)
sample.append(dataset[index])
return sample
# 建立隨機森林
def build_randomforest(self, train):
max_depth = self.max_depth
min_size = self.leaf_min_size
n_trees = self.trees_num
# 列采樣,從M個feature中,選擇m個(m遠小于M)
n_features = int(self.feature_ratio * (len(train[0])-1))
for i in range(n_trees):
sample = self.sample_split(train)
tree = build_one_tree(sample, max_depth, min_size, n_features)
self.trees.append(tree)
return self.trees
# 隨機森林預測的多數表決
def bagging_predict(self, onetestdata):
predictions = [predict(tree, onetestdata) for tree in self.trees]
return max(set(predictions), key=predictions.count)
# 計算建立的森林的精確度
def accuracy_metric(self, testdata):
correct = 0
for i in range(len(testdata)):
predicted = self.bagging_predict(testdata[i])
if testdata[i][-1] == predicted:
correct += 1
return correct / float(len(testdata)) * 100.0
# 資料處理
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# 劃分訓練資料與測驗資料,默認取20%的資料當做測驗資料
def split_train_test(dataset, ratio=0.2):
num = len(dataset)
train_num = int((1-ratio) * num)
dataset_copy = list(dataset)
traindata = list()
while len(traindata) < train_num:
index = randint(0,len(dataset_copy)-1)
traindata.append(dataset_copy.pop(index))
testdata = dataset_copy
return traindata, testdata
# 測驗
if __name__ == '__main__':
train_feat = np.load("train_feat.npy")
train_label = np.load("train_label.npy")
test_feat = np.load("test_feat.npy")
test_label = np.load("test_label.npy")
train_label = np.expand_dims(train_label, 1)
test_label = np.expand_dims(test_label, 1)
traindata = np.concatenate((train_feat, train_label), axis=1)
testdata = np.concatenate((train_feat, train_label), axis=1)
# 決策樹深度不能太深,不然容易導致過擬合
max_depth = 20
min_size = 1
sample_ratio = 1
trees_num = 20
feature_ratio = 0.3
RF = randomForest(trees_num, max_depth, min_size, sample_ratio, feature_ratio)
RF.build_randomforest(traindata)
acc = RF.accuracy_metric(testdata[:-1])
print('模型準確率:', acc, '%')
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357237.html
標籤:AI
下一篇:自動控制原理復習——第一章緒論