基于 Weka 的資料庫挖掘及資料預處理
關于作者
- 作者介紹
🍓 博客主頁:作者主頁
🍓 簡介:JAVA領域優質創作者🥇、一名在校大三學生🎓、在校期間參加各種省賽、國賽,斬獲一系列榮譽🏆,
🍓 關注我:關注我學習資料、檔案下載統統都有,每日定時更新文章,勵志做一名JAVA資深程式猿👨?💻,
文章目錄
- 基于 Weka 的資料庫挖掘及資料預處理
- 關于作者
- 1、雙擊下面的 exe 程式進行安裝
- 2、出現歡迎視窗
- 3、單擊 next 按鈕進入下一步
- 4、進入選擇安裝組件,默認選擇 **FULL**,再單擊 **next**
- 5、 選擇安裝路徑
- 6、選擇開始選單檔案夾名稱
- 7、安裝完成后,可生成如下檔案
- 8、data 檔案夾
- 9、weka 的初步使用
- 10、單擊 weka3.8.4啟動 weka 界面,并選擇探索者界面 Explorer
- 11、為了可以挖掘資料庫中的資料,我們要將 Weka 和 MySQL 進行連接
- (1)組態檔
- (2)資料庫設定
- (3)查詢 Weka 資料庫中 student 表中的資料
- 12、使用 weka 進行資料預處理
- (1)加載資料
- (2)使用資料集編輯器修改資料
- (3)使用過濾器洗掉屬性
- (4)使用過濾器添加屬性
- (5)使用過濾器洗掉實體
- A.選擇
- B.選擇
- C.選擇
- 應用:使用 weka 將資料離散化
- 1、無監督離散化有等寬和等頻離散化,
- 等寬離散化
- 等頻離散化
- 2、有監督離散化
1、雙擊下面的 exe 程式進行安裝
網盤鏈接:https://pan.baidu.com/s/1pTNWBHq5qdL1GaeZUh4uSQ 提取碼:wpzr
2、出現歡迎視窗
3、單擊 next 按鈕進入下一步
同意 GNU GPL 協議,選擇 I Agree 按鈕
4、進入選擇安裝組件,默認選擇 FULL,再單擊 next
5、 選擇安裝路徑
6、選擇開始選單檔案夾名稱
這里是 weka 3.8.4,沒有特殊要求不需更改,單擊 Install 安裝完成即可,
7、安裝完成后,可生成如下檔案
8、data 檔案夾
這里需要看一下 data 檔案夾,里面是 weka 自帶 25個arff 檔案作為測驗資料集,
9、weka 的初步使用
在電腦的開始選單里找到 Weka3.8.4 的子選單,下面有三個選單項,如下圖,第一個選單項:Documentation,提供weka 的參考資料,包括 Weka 手冊、Java 包 API 檔案及一些線資源,下面兩個選單項都可以啟動Weka 界面,不同的是后者帶有一個控制臺的輸出,而前者沒有,
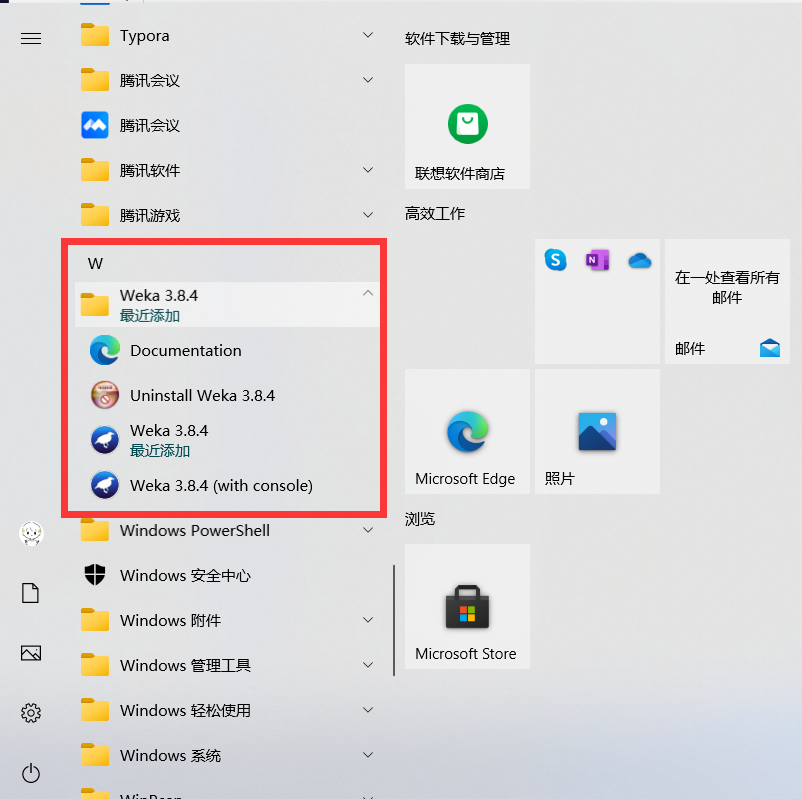
10、單擊 weka3.8.4啟動 weka 界面,并選擇探索者界面 Explorer
進入探索者界面如下:
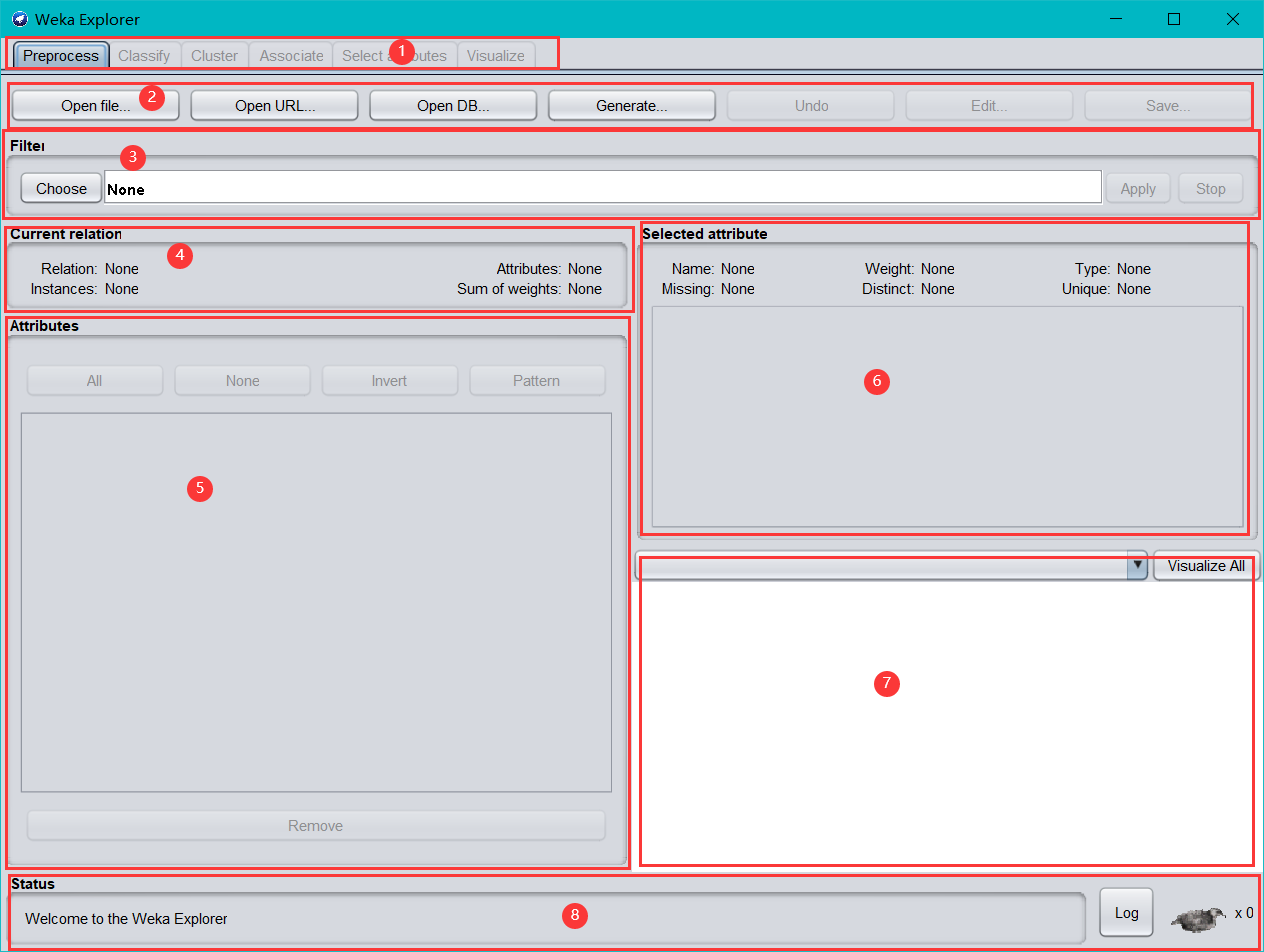
根據不同的功能把這個界面分成 8 個區域,
區域1 的幾個選項卡是用來切換不同的挖掘任務面板,這一節用到的只有**“Preprocess”**,其他面板的功能將在以后介紹,
主界面最左上角(標題欄下方)的是標簽欄,分為 6 個部分,功能
依次是:
Preprocess(資料預處理):選擇和修改要處理的資料;
Classify(分類):訓練和測驗關于分類或回歸的學習方案;
Cluster(聚類):從資料中學習聚類;
Associate(關聯):從資料中學習關聯規則;
Select attributes(屬性選擇):選擇資料中最相關的屬性;
Visualize(可視化):查看資料的互動式二維影像,
區域2是一些常用按鈕,包括打開資料,保存及編輯功能、載入、編
輯資料
標簽欄下方是載入資料欄,功能如下:
Open file:打開一個對話框,允許你瀏覽本地檔案系統上的資料文
件(.dat);
Open URL:請求一個存有資料的 URL 地址;
Open DB:從資料庫中讀取資料;
Generate:從一些資料生成器中生成人造資料,
區域 3 中“Choose”某個“Filter”,可以實作篩選資料或者對資料進行某種變換,資料預處理主要就利用它來實作,
區域 4 展示了資料集的一些基本情況,
區域 5 中列出了資料集的所有屬性,勾選一些屬性并“Remove”就可以洗掉它們,洗掉后還可以利用區域 2 的“Undo”按鈕找回,區域 5上方的一排按鈕是用來實作快速勾選的,
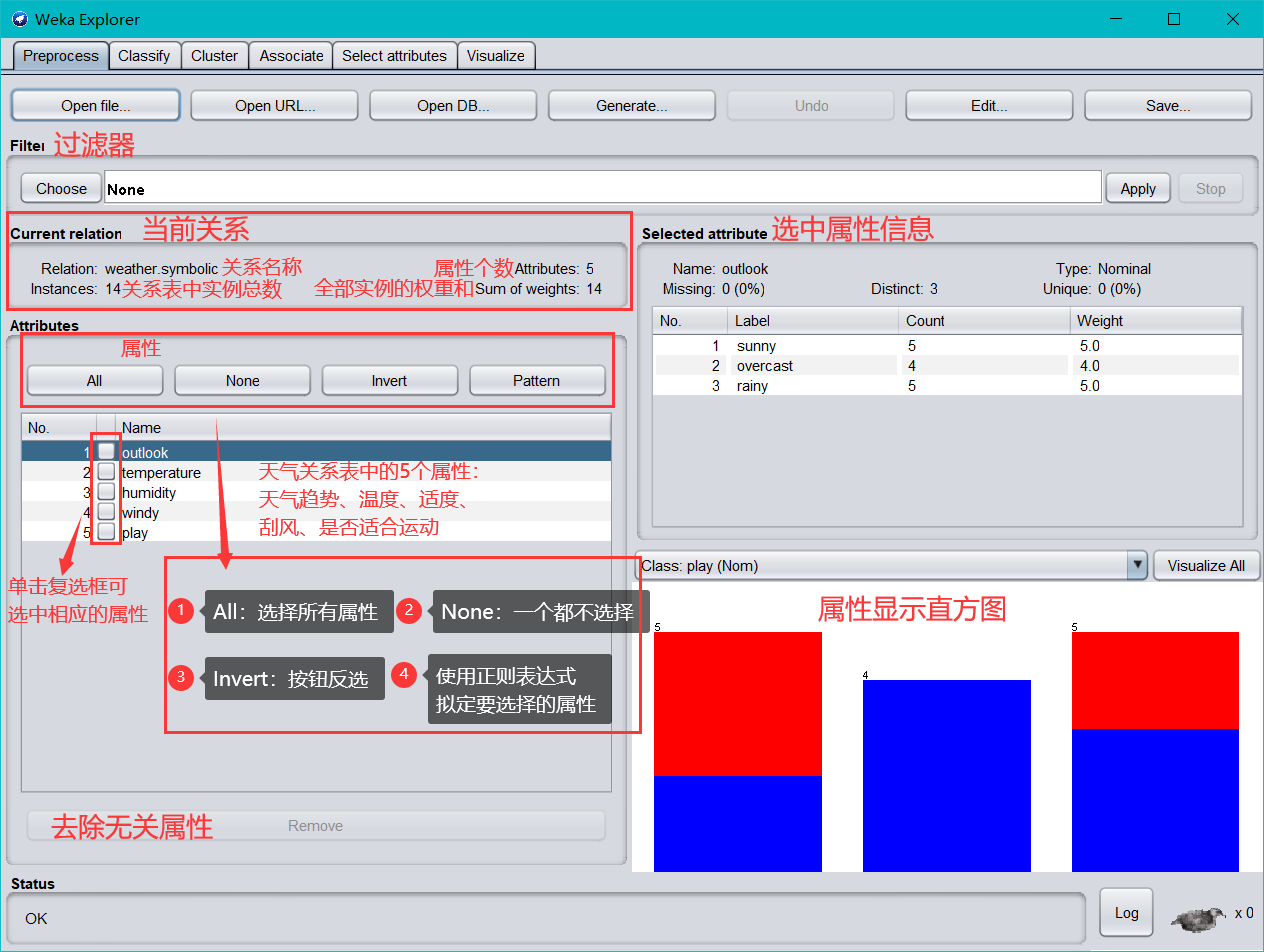
在區域 5 中選中某個屬性,則區域 6 中有關于這個屬性的摘要,注意對于數值屬性和分類屬性,摘要的方式是不一樣的,圖中顯示的是對數值屬性“income”的摘要,
區域 7 是區域 5 中選中屬性的直方圖,若資料集的最后一個屬性(我們說過這是分類或回歸任務的默認目標變數)是分類變數(這里的“pep”正好是),直方圖中的每個長方形就會按照該變數的比例分成不同顏色的段,要想換個分段的依據,在區域 7 上方的下拉框中選個不同的分類屬性就可以了,下拉框里選上“No Class”或者一個數值屬性會變成黑白的直方圖,
區域 8 是狀態欄,可以查看 Log 以判斷是否有錯,右邊的 weka 鳥在動的話說明 WEKA 正在執行挖掘任務,右鍵點擊狀態欄還可以執行JAVA 記憶體的垃圾回收,
11、為了可以挖掘資料庫中的資料,我們要將 Weka 和 MySQL 進行連接
(1)組態檔
-
如果 Weka 正在運行,先關閉 weka
-
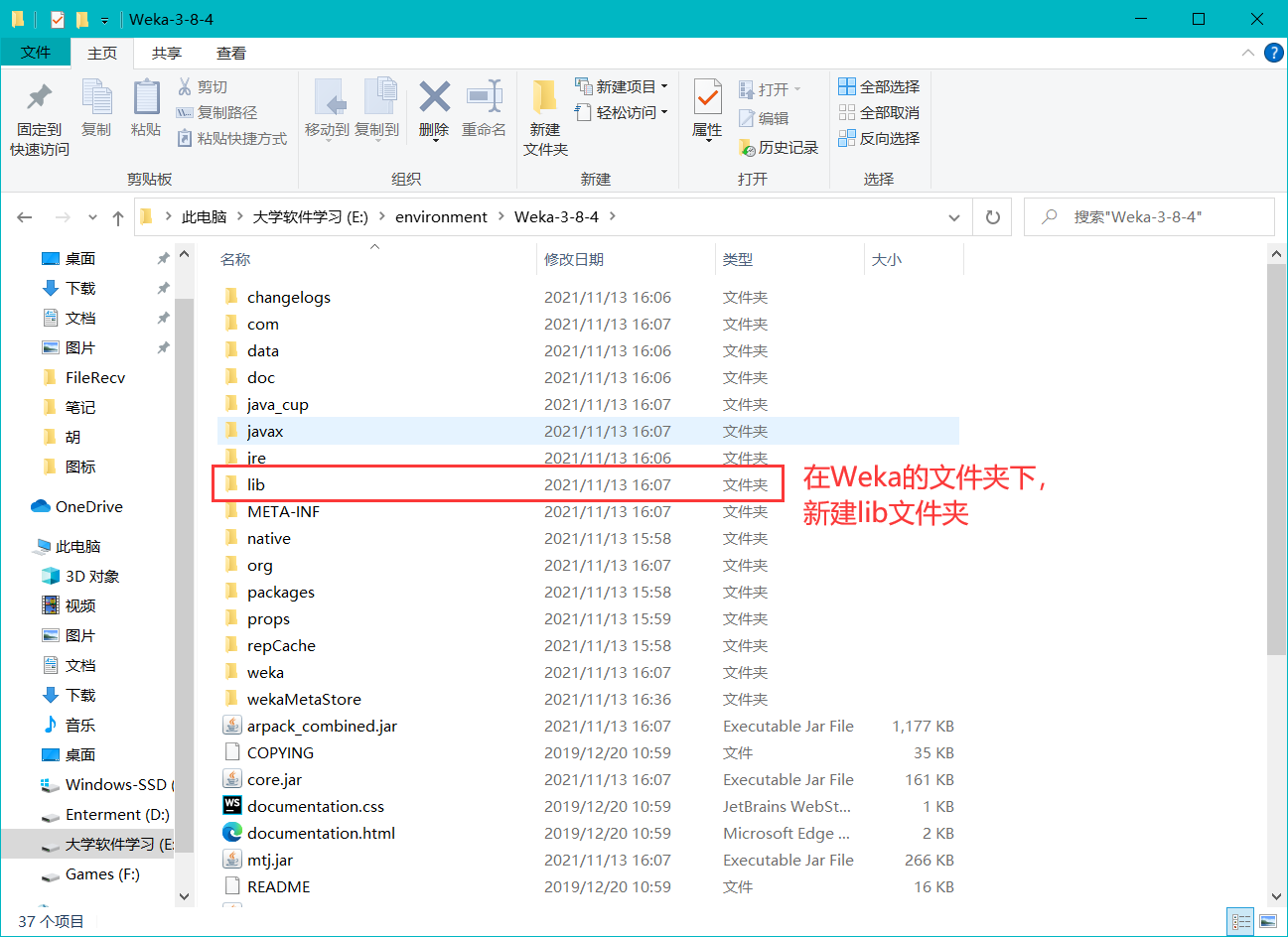
在Weka下新建lib目錄
-
查看自己資料庫所兼容的jar包,這里我用的是5.1.49

-
配置環境變數
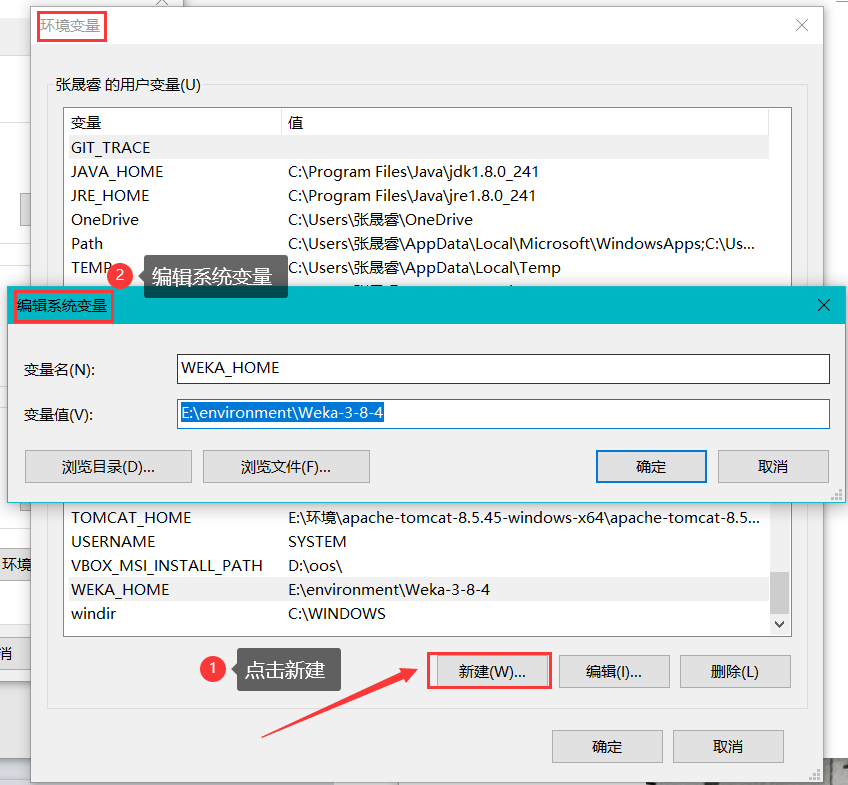
WEKA_HOME E:\environment\Weka-3-8-4 -
修改系統變數CLASSPATH
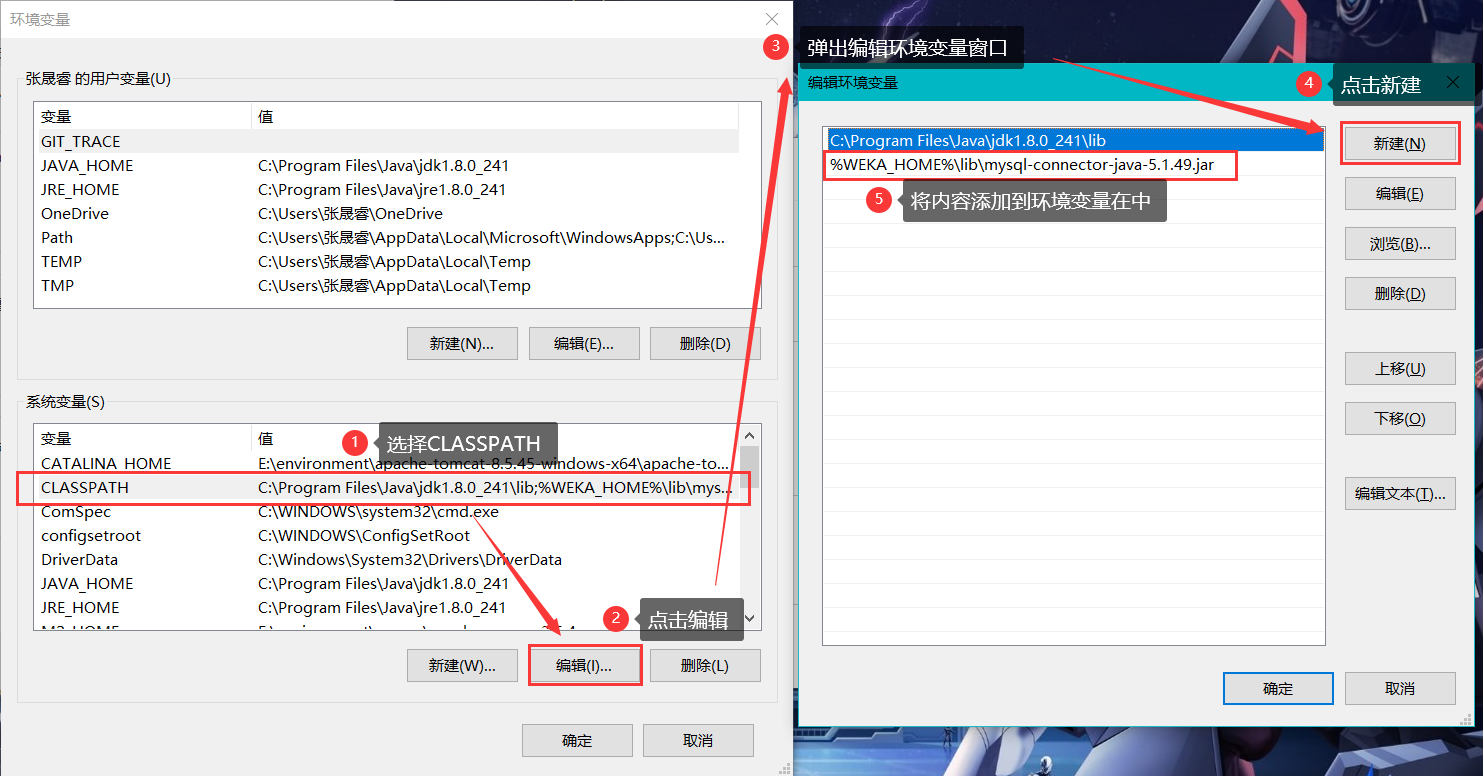
%WEKA_HOME%\lib\mysql-connector-java-5.1.49.jar
-
啟動資料庫運行,確保已建立名稱為 weka 的資料庫,并自行建表
-
修改以下目錄中的 DatabaseUtils.props 檔案(需要提前將 weka-3-8-4 檔案夾下的 weka.jar 包解壓才能找到)
以記事本打開該檔案,檔案內容如下:
# General information on database access can be found here:
# https://waikato.github.io/weka-wiki/databases/
#
# Version: $Revision: 15255 $
# The comma-separated list of jdbc drivers to use
#jdbcDriver=RmiJdbc.RJDriver,jdbc.idbDriver
#jdbcDriver=jdbc.idbDriver
#jdbcDriver=RmiJdbc.RJDriver,jdbc.idbDriver,org.gjt.mm.mysql.Driver,com.mckoi.JDBCDriver,org.hsqldb.jdbcDriver
jdbcDriver=com.mysql.jdbc.Driver
# The url to the experiment database
#jdbcURL=jdbc:rmi://expserver/jdbc:idb=experiments.prp
jdbcURL=jdbc:mysql://localhost:3306/weka
#jdbcURL=jdbc:mysql://mysqlserver/username
# the method that is used to retrieve values from the db
# (java datatype + RecordSet.<method>)
# string, getString() = 0; --> nominal
# boolean, getBoolean() = 1; --> nominal
# double, getDouble() = 2; --> numeric
# byte, getByte() = 3; --> numeric
# short, getByte()= 4; --> numeric
# int, getInteger() = 5; --> numeric
# long, getLong() = 6; --> numeric
# float, getFloat() = 7; --> numeric
# date, getDate() = 8; --> date
# text, getString() = 9; --> string
# time, getTime() = 10; --> date
# timestamp, getTime() = 11; --> date
# the original conversion: <column type>=<conversion>
#char=0
#varchar=0
#longvarchar=0
#binary=0
#varbinary=0
#longvarbinary=0
#bit=1
#numeric=2
#decimal=2
#tinyint=3
#smallint=4
#integer=5
#bigint=6
#real=7
#float=2
#double=2
#date=8
#time=10
#timestamp=11
#mysql-conversion
CHAR=0
TEXT=0
VARCHAR=0
LONGVARCHAR=9
BINARY=0
VARBINARY=0
LONGVARBINARY=9
BIT=1
NUMERIC=2
DECIMAL=2
FLOAT=2
DOUBLE=2
TINYINT=3
SMALLINT=4
#SHORT=4
SHORT=5
INTEGER=5
BIGINT=6
LONG=6
REAL=7
DATE=8
TIME=10
TIMESTAMP=11
#mappings for table creation
CREATE_STRING=TEXT
CREATE_INT=INT
CREATE_DOUBLE=DOUBLE
CREATE_DATE=DATETIME
DateFormat=yyyy-MM-dd HH:mm:ss
#database flags
checkUpperCaseNames=false
checkLowerCaseNames=false
checkForTable=true
setAutoCommit=true
createIndex=false
# All the reserved keywords for this database
Keywords=\
AND,\
ASC,\
BY,\
DESC,\
FROM,\
GROUP,\
INSERT,\
ORDER,\
SELECT,\
UPDATE,\
WHERE
# The character to append to attribute names to avoid exceptions due to
# clashes between keywords and attribute names
KeywordsMaskChar=_
#flags for loading and saving instances using DatabaseLoader/Saver
nominalToStringLimit=50
idColumn=auto_generated_id
修改完之后,可將 DatabaseUtils.props 檔案放在如下兩個目錄之一
A. 當前目錄即可,即不改變它的位置
B. 若第一個目錄不行,則把它放在用戶目錄中,若不知道自己的用戶目錄,在命 令 行 輸 入 echo %USERPROFILE%, 即 可 找 到 用 戶 目 錄 路 徑 , 將DatabaseUtils.props 檔案放在用戶目錄的下的 wekafiles\props 子目錄中,并把原來路徑中的 DatabaseUtils.props 刪掉,
(2)資料庫設定
- 進入 weka 的探索者界面,單擊 OPEN DB,進入 SQL 查看器,可以看到 URL 文本框的內容已變成前文修改的組態檔中的 jdbcURL 值,
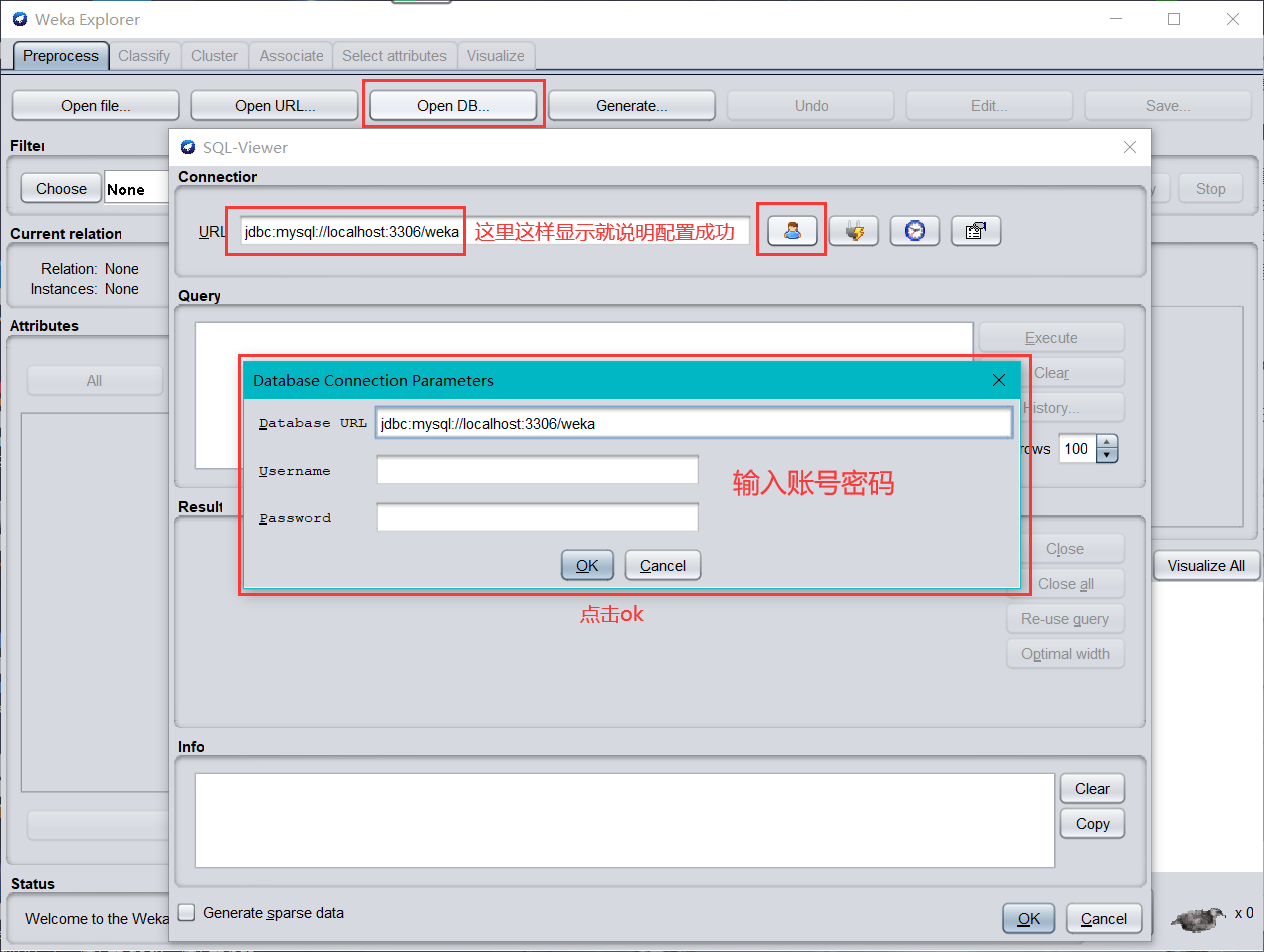
- 單擊如下按鈕,連接資料庫,如果前面設定無誤,會在 SQL 查看器下,出現資料庫連接成功的提示

(3)查詢 Weka 資料庫中 student 表中的資料
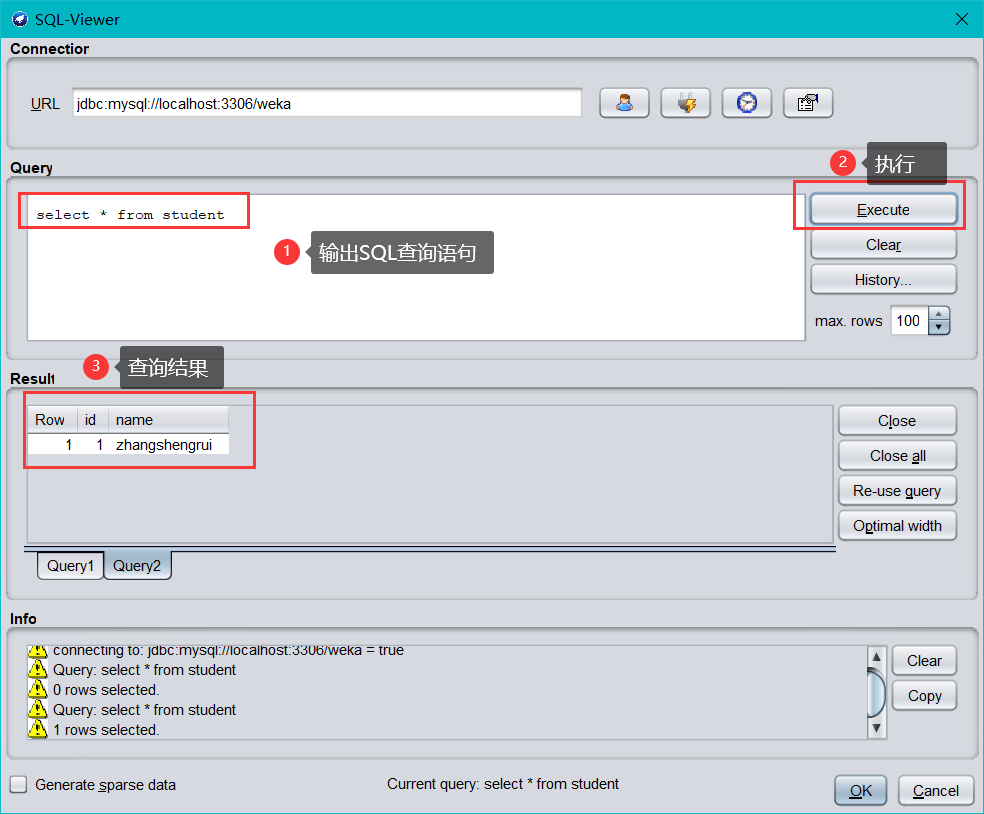
 注意:如果連接不上資料庫,可按如下順序依次查找:資料庫驅動程式是否正確;CLASSPATH 的設定是否正確(用戶變數);組態檔中的 jdbcDriver 和 jdbcURL 兩項配置的拼寫是否正確;組態檔是否放到了正確的路徑;資料庫用戶名和密碼是否正確;該資料庫用戶是否擁有足夠的權限;資料庫是否已經啟動等其他問題,
注意:如果連接不上資料庫,可按如下順序依次查找:資料庫驅動程式是否正確;CLASSPATH 的設定是否正確(用戶變數);組態檔中的 jdbcDriver 和 jdbcURL 兩項配置的拼寫是否正確;組態檔是否放到了正確的路徑;資料庫用戶名和密碼是否正確;該資料庫用戶是否擁有足夠的權限;資料庫是否已經啟動等其他問題,
12、使用 weka 進行資料預處理
Preprocess 標簽可用于從檔案、URL 或資料庫中加載資料集,并且根據應用要求或領域知識過濾掉不需要進行處理或不符合要求的數
據,
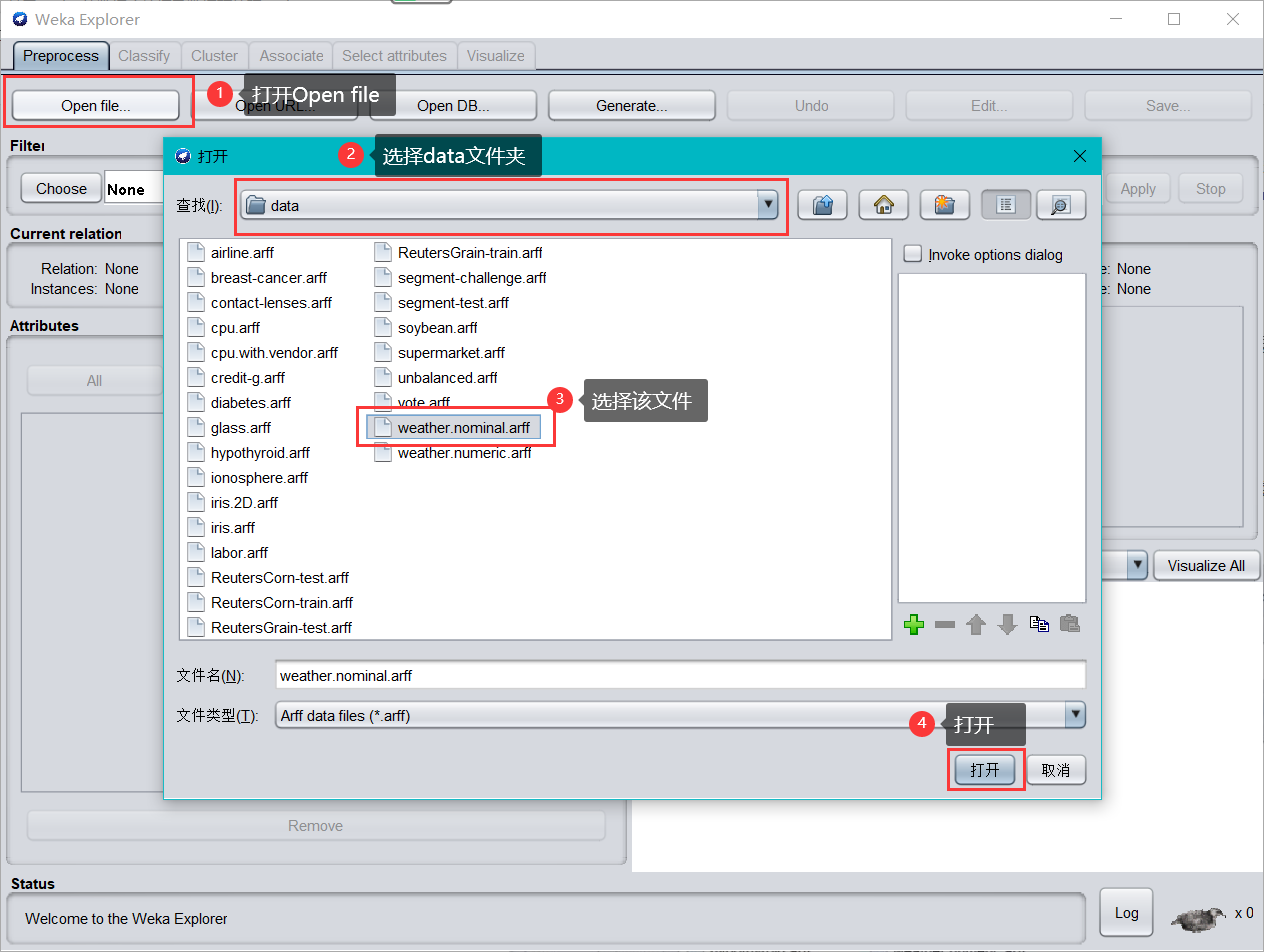
(1)加載資料
- 單擊 open file ,在 weka 的安裝目錄下選擇 data 檔案,打開 data 檔案,選擇 weather.nominal.arff 資料集,
- 加載資料后,出現如下資料資訊:
(2)使用資料集編輯器修改資料
加載天氣資料集后,單擊 Preprocess 標簽頁中的 Edit 按鈕,彈出如下對話框,列出全部天氣資料,
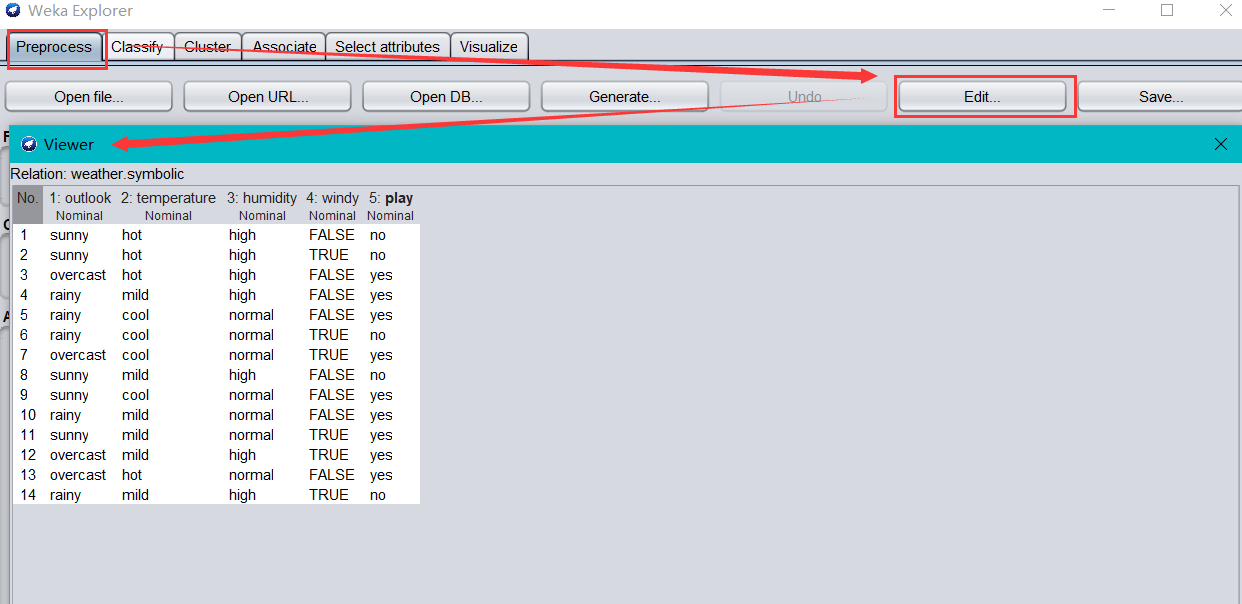
在這個界面可以手動洗掉一些屬性或者實體,或者修改資料
(3)使用過濾器洗掉屬性
-
加載天氣資料后,在 Filter 下單擊 Choose 按鈕
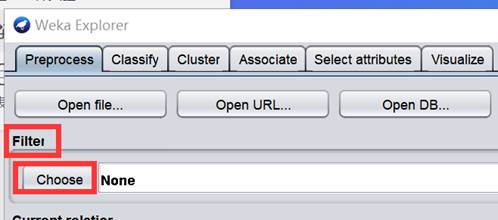
-
打開過濾器分層串列,如下圖,有兩種過濾演算法,一種有監督,一種無監督,前者使用類別屬性,后者不使用,繼續往下是屬性和實體,前者主要處理有關屬性的過濾,后者處理有關實體的過濾,
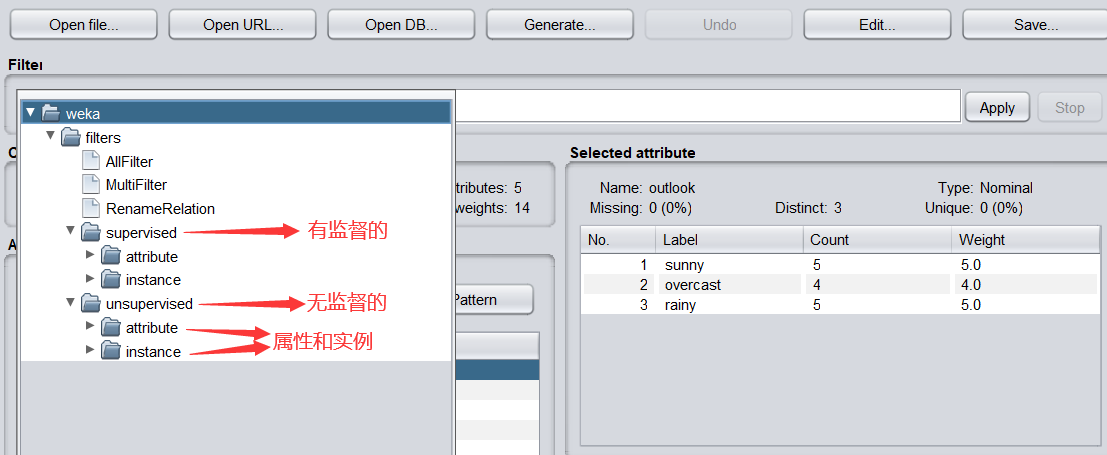
-
適合洗掉屬性的的過濾器是 Remove,我們在unsupervised(無監督)—>attribute—> Remove 條目,單擊選擇該過濾器,Choose 右側文本框就會顯示,Remove,如下圖
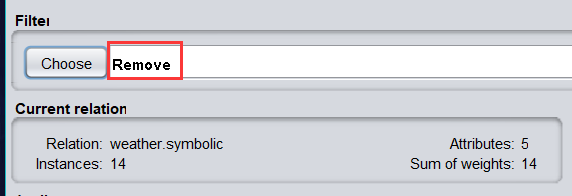
- 再單擊該文本框,打開通用物件編輯器對話框以設定引數,如下圖
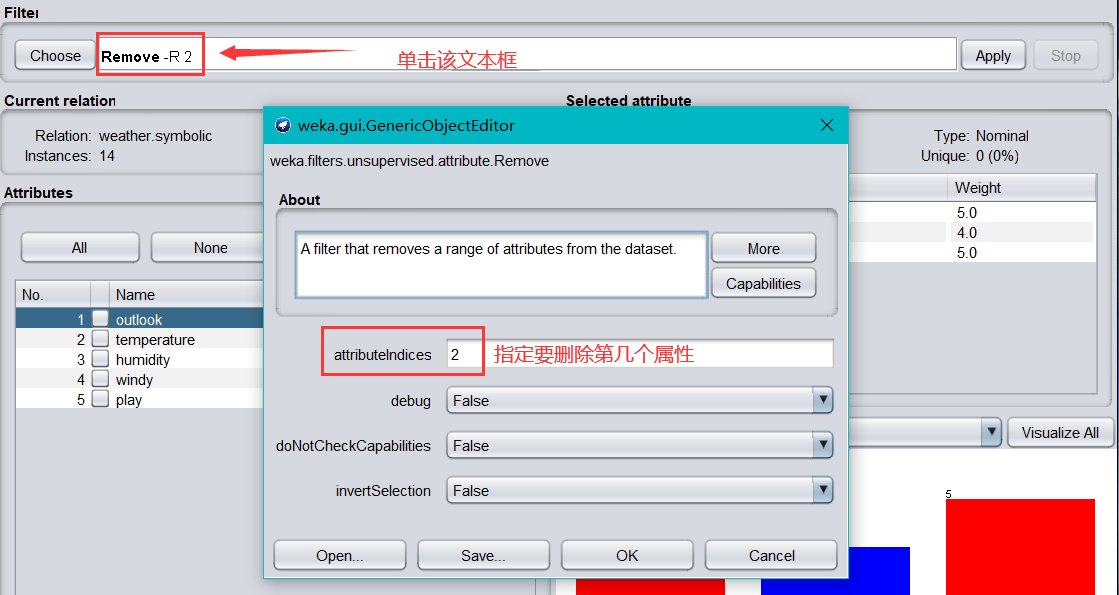
- 設定完引數,點擊 Ok,回到以下界面,文本框顯示:remove -R 2,含義是洗掉資料集中的第二個屬性,單擊右邊的 Apply 過濾器生效,

- 可單擊 edit 按鈕,查看洗掉屬性后的結果,但這種方法只能改變記憶體中的資料,不會影響資料集檔案中的內容,要想保存該檔案,可通過 save 按鈕保存洗掉屬性后的檔案,
(4)使用過濾器添加屬性
- 仍然是單擊 Choose 按鈕,依次 weka—>filter—>unsupervised(無監督)—>attribute—>AddUserFiledss過濾器
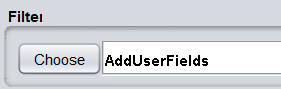
- 單擊 Choose 旁邊的文本框,打開通用物件編輯器對話框以設定引數,單擊 New 按鈕,設定屬性名稱為 mode,屬性型別為 Nominal,其他不設定,單擊 Ok
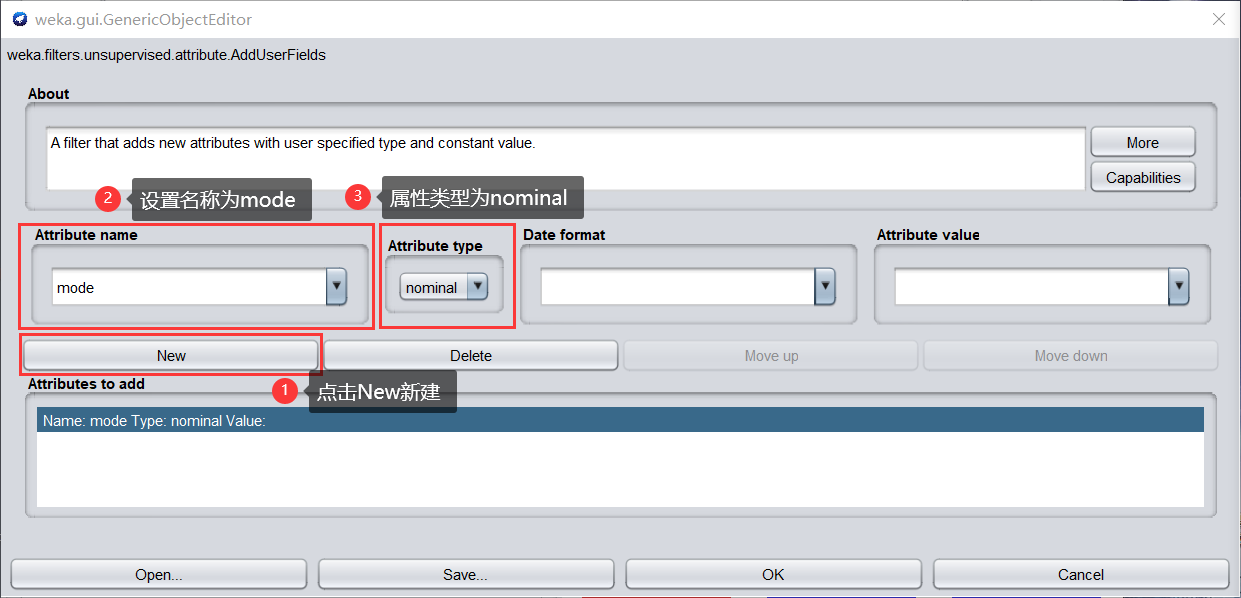
- 單擊 Ok,出現如下,再單擊 Apply,會發現屬性選項組的屬性表格中多了一個 mode 屬性,

- 單擊 Edit,打開 Vierwer 對話框,可以看到新增的屬性并沒有值
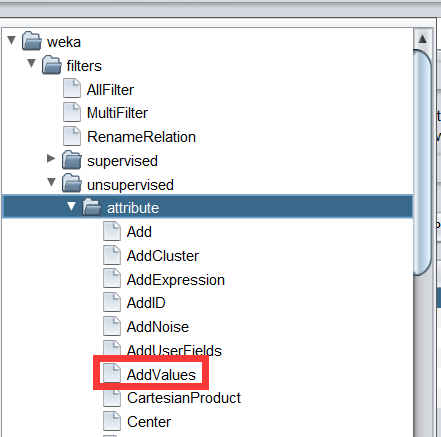
- 繼續單擊 Choose 按鈕,選擇unsupervised(無監督)—>attribute—>AddValues過濾器,單擊該文本框,出現如下對話框,在 labels 標簽設定 mode 的取值,
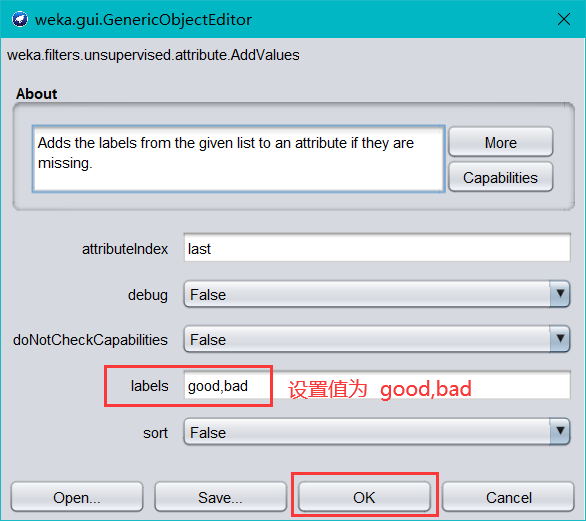
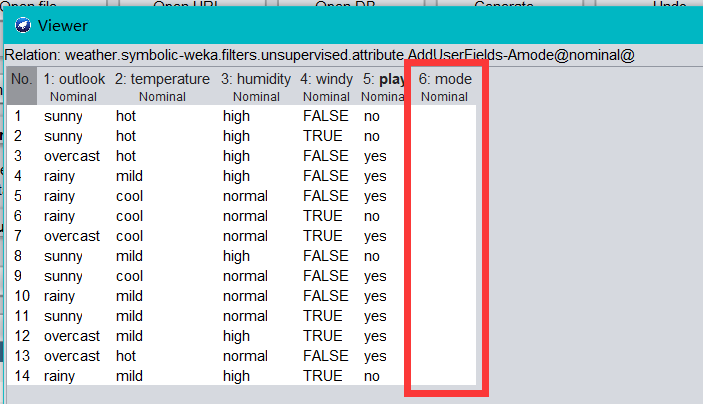
- 再次單擊 Edit 按鈕,打開 Viewer 對話框,如下圖,可以看到新增的屬性下拉串列框有取值了,
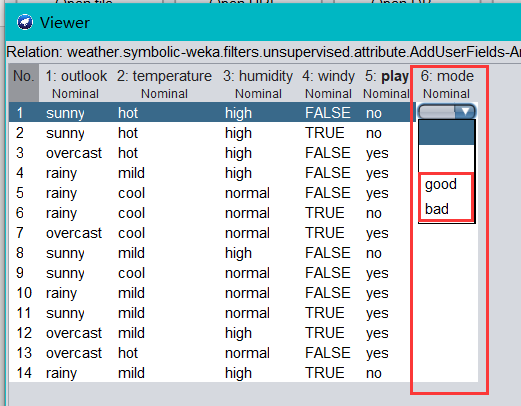
? 我們可以看到上表中 mode 屬性在最后一列,這個天氣資料集的最后一列應該是類別屬性 play,根據其他條件屬性的取值,比如晴天,溫度/濕度適宜,沒風等條件來判斷是否適合外出運動,所以這里我們需要將 mode 屬性和 play 屬性調換一下位置,繼續選擇unsupervised(無監督)—>attribute—>Reorder過濾器,再單擊 choose 旁邊的文本框,彈出如下圖,設定引數為 1,2,3,4,6,5 相當于將第五列和四列調換位置,
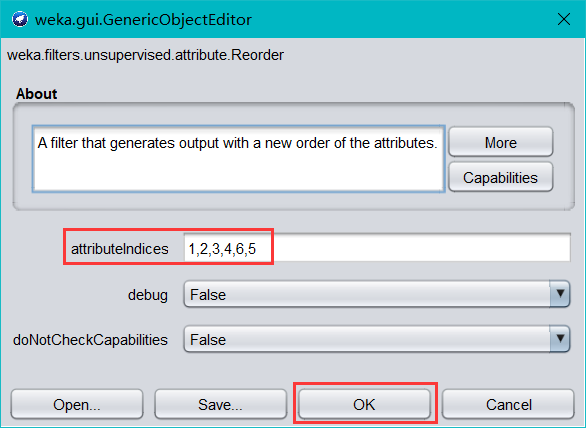
- 最后再單擊 Edit 按鈕,打開 Viewer 對話框,如下圖,可以看到 mode 和 play 交換了位置,

(5)使用過濾器洗掉實體
A.選擇
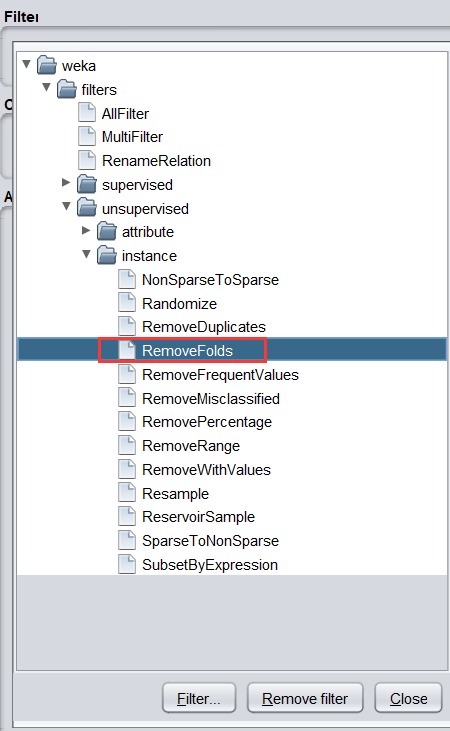
- choose—>weka—>filter—>unsupervised—>instance—>RemoveFolds過濾器
-
過濾器將資料集分割為給定的交叉驗證折數,并指定輸出第幾折,點擊Choose 旁邊的文本框,彈出如下對話框
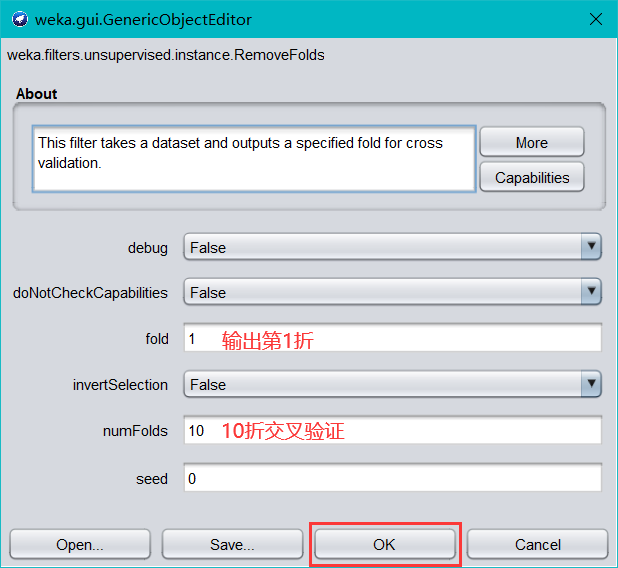
-
單擊 ok-Apply,然后查看資料會發現,14 條資料只剩兩條了
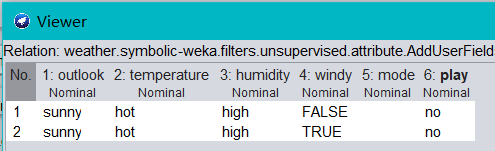
B.選擇
-
choose—>weka—>filter—>unsupervised—>instance—>RemovePercentage過濾器
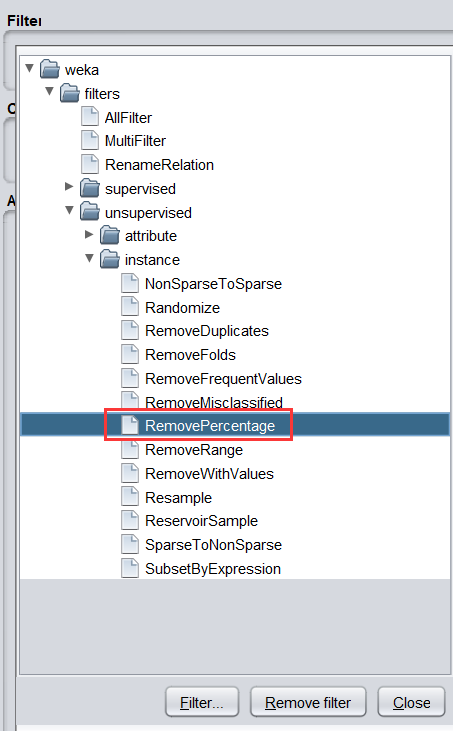
-
過濾器洗掉資料集中給定百分比的實體,點擊 Choose 旁邊的文本框,彈出如下對話框
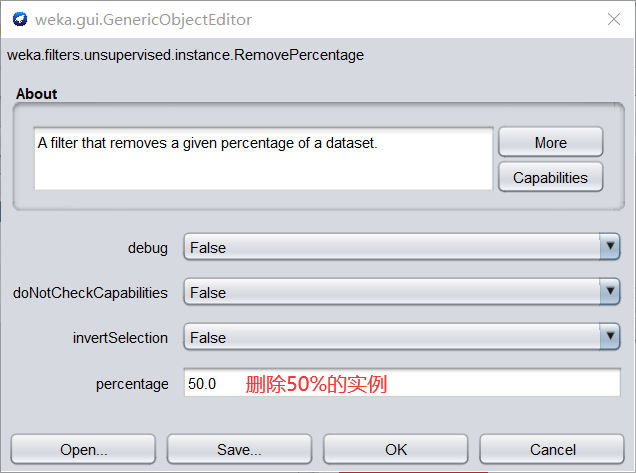
-
單擊 ok-Apply,然后查看資料會發現,14 條資料只剩 7 條了,
C.選擇
-
choose—>weka—>filter—>unsupervised—>instance—>RemoveRange過濾器
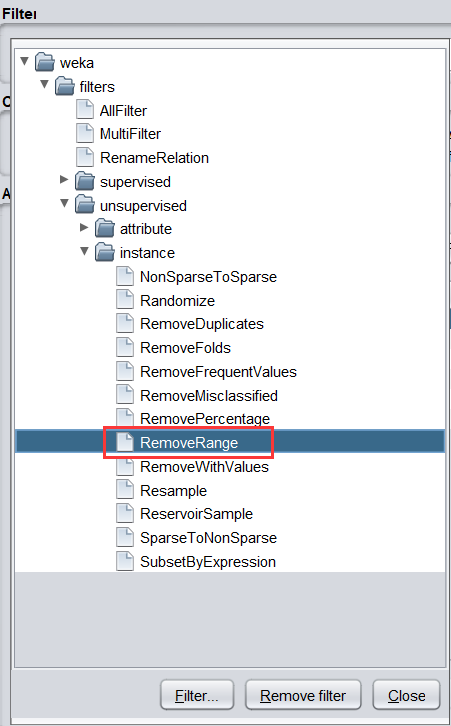
-
過濾器洗掉資料集中給定范圍的實體,點擊 Choose 旁邊的文本框, 彈出如下:
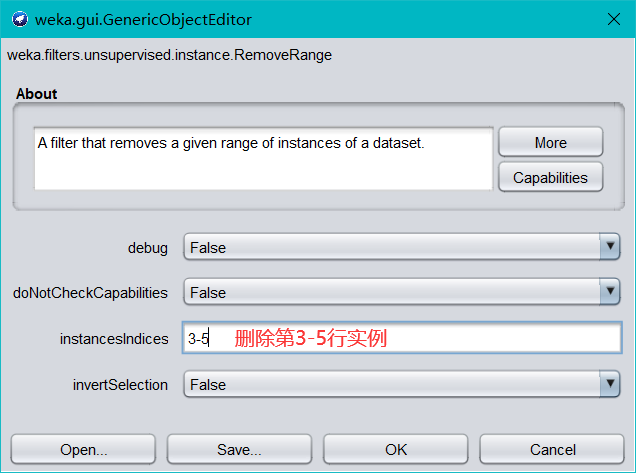
-
單擊 ok-Apply,然后查看資料會發現,14 條資料只剩 11 條了,第 3-5條資料被刪掉了,
應用:使用 weka 將資料離散化
? Weka 中資料型別有標稱型(nominal),只能取預定義值串列中的一個;數值型(numeric),只能是實數或整數;字串型別(String),由雙引號參考的任意長度的字串列;還有日期型(Date)和 關系型(Relational),
? 如果資料集包含數值型屬性,所用的學習方案只能處理標稱型屬性的分類,則將數值型屬性離散化是必要的,有兩種型別的離散化技術-無監督離散和有監督離散化,前者不需要也不關注類別屬性值,后者在創建間隔時考慮實體的類別屬性值,離散化數值型屬性的直觀方法是將值域分隔為多個預先設定的間隔區間,
1、無監督離散化有等寬和等頻離散化,
等寬離散化(等寬分箱):將數值型屬性從最小值到最大值平均分為十份,即將數值從最小值到最大值分成 10 個區間,這樣每個區間所包含的實體數量就各不相等,從而造成實體分布不均勻,有的間隔區域內包含很多個實體,但有的卻很少甚至沒有,
等頻離散化:按數值型屬性的大小順序將全部實體平均分成十份,如 200 條實體,先按取值大小排好順序,再每 20 條一份,分成十份,
下面以實體說明這兩種方法的差異,首先,在 data 目錄中找到玻璃資料集glass.arff 檔案,如下圖是玻璃資料集中各屬性的含義,

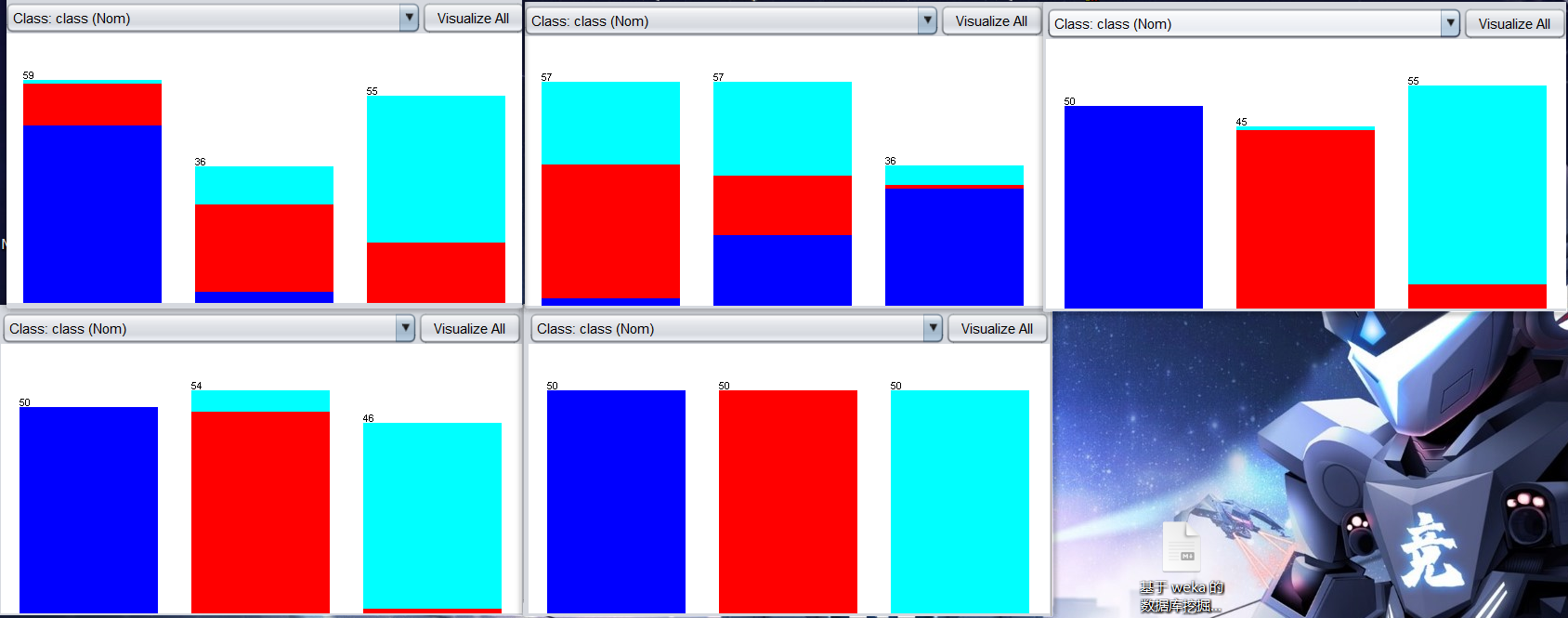
將其加載至探索者界面,在 Preprocess標簽頁中查看 RI 屬性直方圖如下:
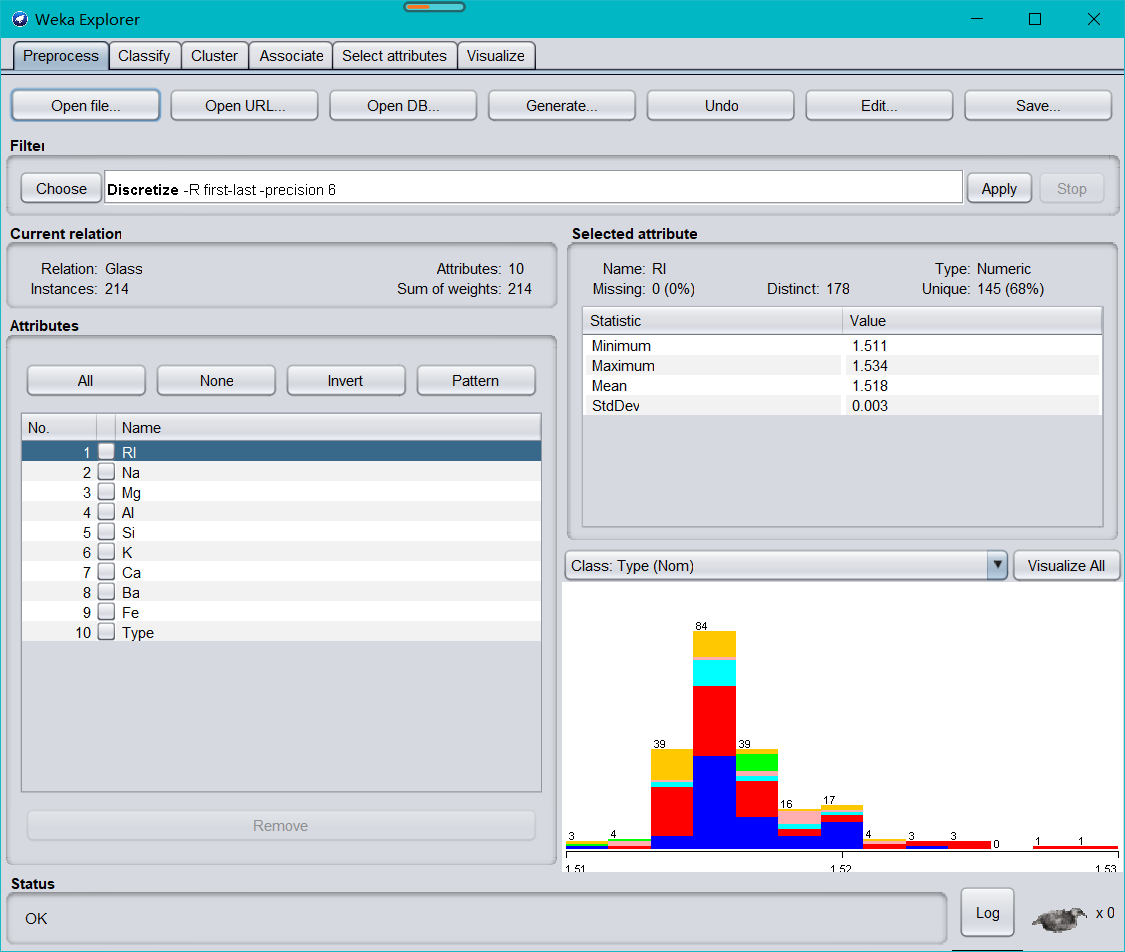
思考:RI 屬性的直方圖中各種顏色和各種數值代表什么?
等寬離散化
依次打開choose—>weka—>filters—>unsupervised—>attribute—>Discretize過濾器,保持默認引數不變,點擊 Apply,出現如下圖:
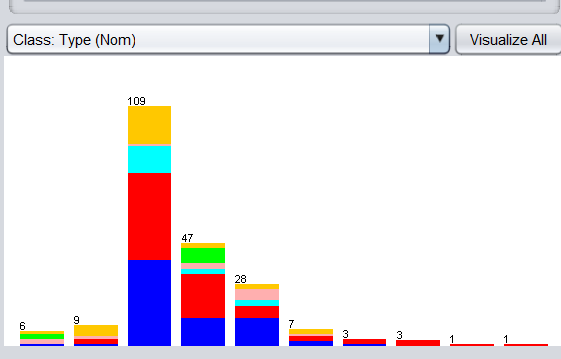
等頻離散化
設定 Discretize 中的 值為 true,得到等頻離散化后的 RI 屬性,如下圖:
值為 true,得到等頻離散化后的 RI 屬性,如下圖:
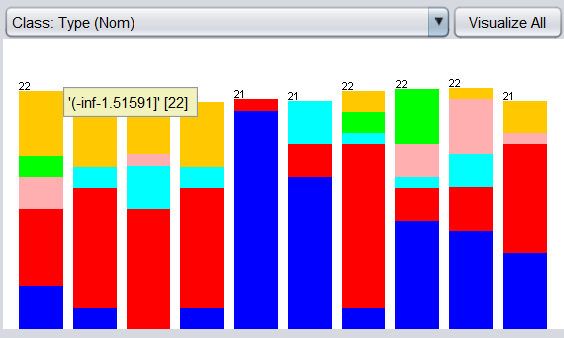
我們可能會產生錯覺,等頻離散化后形成的直方圖似憾訓等高,但是有興趣的可以自行看看 Ba,Fe 屬性的等頻離散化,是否會等高,思考為什么會這樣,
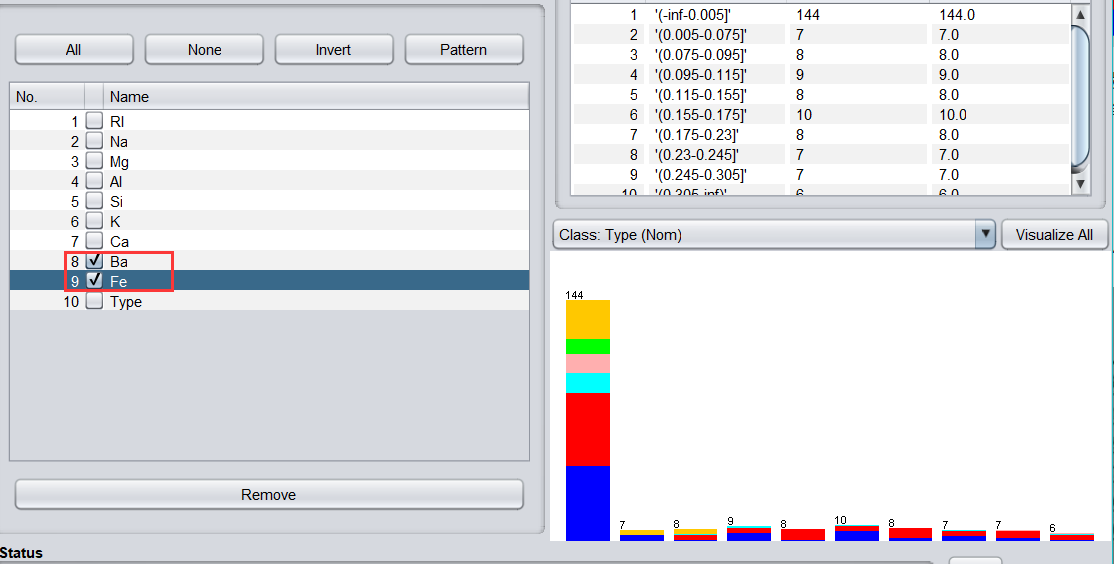
2、有監督離散化
首先打開 data 資料集中的鳶尾花資料集,即 iris.arff 檔案,資料集中各屬性如下:
Weka 中打開 iris 資料集,顯示如下圖
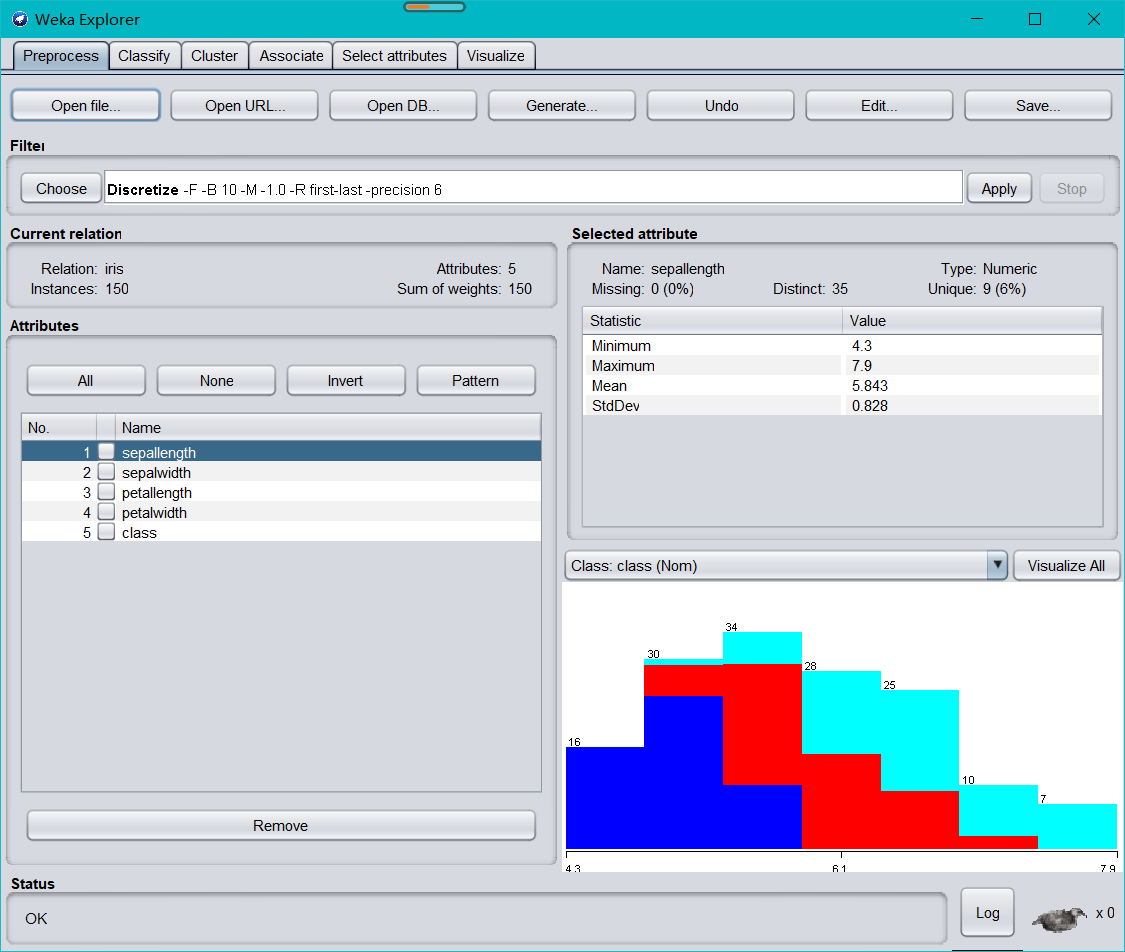
依次點開choose—>weka—>filters—>supervised—>attribute—>Discretize,點擊 Apply,,打開可視化視窗,發現各個屬性的取值范圍如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357243.html
標籤:AI
上一篇:R語言計算回歸模型每個樣本(觀察、observation、sample)的DFFITS度量實戰:忽略單個觀察(樣本)時,回歸模型所做的預測會發生多大的變化