今天跟大家分享的是我之前跟著做過的一門專案,非常的經典,也非常的詳細,適合作為資料分析入門的專案,以下是有關的介紹,
資料來源于CDNow網站的用戶購買明細,一共有用戶ID,購買日期,購買數量,購買金額四個欄位,
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
- 加載資料:首先需要的是加載資料,同時由于資料中缺乏表頭,所以需要賦予,且讀取時注意更改默認分隔符(資料由多個空格分隔)
columns = ['user_id', 'order_dt', 'order_products', 'order_amount']
df = pd.read_csv('CDNow_master.txt', names=columns, sep='\s+')
- 觀察資料:其中需要注意的是,order_dr為日期,格式為int64,并非我們需要的日期格式,所以后續要進行更改,同時一個用戶也可以在一天內進行多次購買,如user_id為2的用戶就在19970112那天買了兩次,
df.head()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| 0 | 1 | 19970101 | 1 | 11.77 |
| 1 | 2 | 19970112 | 1 | 12.00 |
| 2 | 2 | 19970112 | 5 | 77.00 |
| 3 | 3 | 19970102 | 2 | 20.76 |
| 4 | 3 | 19970330 | 2 | 20.76 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 69659 non-null int64
1 order_dt 69659 non-null int64
2 order_products 69659 non-null int64
3 order_amount 69659 non-null float64
dtypes: float64(1), int64(3)
memory usage: 2.1 MB
- 資料處理:沒有空值,很干凈的資料,現在需要將時間的資料型別進行轉換,
df['order_date'] = pd.to_datetime(df.order_dt, format='%Y%m%d')
df['month'] = df.order_date.values.astype('datetime64[M]')
%h是小時,%M是分鐘,注意和月的大小寫不一致,秒是%s,
另外之所以還將資料轉換成月份格式,是因為我們將月份作為消費行為的主要事件視窗,選擇哪種時間視窗取決于消費頻率,
(也可以是以天或者年來劃分)
df.head()
| user_id | order_dt | order_products | order_amount | order_date | month | |
|---|---|---|---|---|---|---|
| 0 | 1 | 19970101 | 1 | 11.77 | 1997-01-01 | 1997-01-01 |
| 1 | 2 | 19970112 | 1 | 12.00 | 1997-01-12 | 1997-01-01 |
| 2 | 2 | 19970112 | 5 | 77.00 | 1997-01-12 | 1997-01-01 |
| 3 | 3 | 19970102 | 2 | 20.76 | 1997-01-02 | 1997-01-01 |
| 4 | 3 | 19970330 | 2 | 20.76 | 1997-03-30 | 1997-03-01 |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 69659 entries, 0 to 69658
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 69659 non-null int64
1 order_dt 69659 non-null int64
2 order_products 69659 non-null int64
3 order_amount 69659 non-null float64
4 order_date 69659 non-null datetime64[ns]
5 month 69659 non-null datetime64[ns]
dtypes: datetime64[ns](2), float64(1), int64(3)
memory usage: 3.2 MB
pandas中有專門的時間序列方法tseries,它可以用來進行時間偏移,也是處理時間型別的好方法,時間格式也能作為索引,在金融、財務等領域使用較多,
# df.date - pd.tseries.offsets.MonthBegin(1)
- 按每筆訂單來統計分布由上述可得,用戶平均每單購買2.4個商品,標準差為2.3,略有波動,中位數在2.0,75分位數為3,說明絕大多部分訂單的購買力 都不多,最大值為99個,數字較高,而購買金額則同購買數量差不多情況,大部分訂單都集中在小額, 一般而言,消費類的資料分布,都是長尾形態,大部分用戶都是小額,然而小部分用戶貢獻了收入的大頭,俗稱二八法則,
df.describe()
| user_id | order_dt | order_products | order_amount | |
|---|---|---|---|---|
| count | 69659.000000 | 6.965900e+04 | 69659.000000 | 69659.000000 |
| mean | 11470.854592 | 1.997228e+07 | 2.410040 | 35.893648 |
| std | 6819.904848 | 3.837735e+03 | 2.333924 | 36.281942 |
| min | 1.000000 | 1.997010e+07 | 1.000000 | 0.000000 |
| 25% | 5506.000000 | 1.997022e+07 | 1.000000 | 14.490000 |
| 50% | 11410.000000 | 1.997042e+07 | 2.000000 | 25.980000 |
| 75% | 17273.000000 | 1.997111e+07 | 3.000000 | 43.700000 |
| max | 23570.000000 | 1.998063e+07 | 99.000000 | 1286.010000 |
- 上面的消費行為資料粒度是每筆訂單,我們轉換成每位用戶看一下,
user_grouped = df.groupby('user_id').sum()
user_grouped.head()
| order_dt | order_products | order_amount | |
|---|---|---|---|
| user_id | |||
| 1 | 19970101 | 1 | 11.77 |
| 2 | 39940224 | 6 | 89.00 |
| 3 | 119833602 | 16 | 156.46 |
| 4 | 79882233 | 7 | 100.50 |
| 5 | 219686137 | 29 | 385.61 |
用group_by創建一個新物件,
user_grouped.describe()
| order_dt | order_products | order_amount | |
|---|---|---|---|
| count | 2.357000e+04 | 23570.000000 | 23570.000000 |
| mean | 5.902627e+07 | 7.122656 | 106.080426 |
| std | 9.460684e+07 | 16.983531 | 240.925195 |
| min | 1.997010e+07 | 1.000000 | 0.000000 |
| 25% | 1.997021e+07 | 1.000000 | 19.970000 |
| 50% | 1.997032e+07 | 3.000000 | 43.395000 |
| 75% | 5.992125e+07 | 7.000000 | 106.475000 |
| max | 4.334408e+09 | 1033.000000 | 13990.930000 |
從用戶角度來看,每位用戶平均購買7張CD,最多的用戶購買了1033張CD(太瘋狂了),用戶平均的消費金額(客單價)為100,標準差為240,結合分位數和最大值看,平均值才和75分位接近,說明存在小部分的高額消費用戶,
- 接下來按月的維度來分析,
df.groupby('month').order_products.sum().plot()
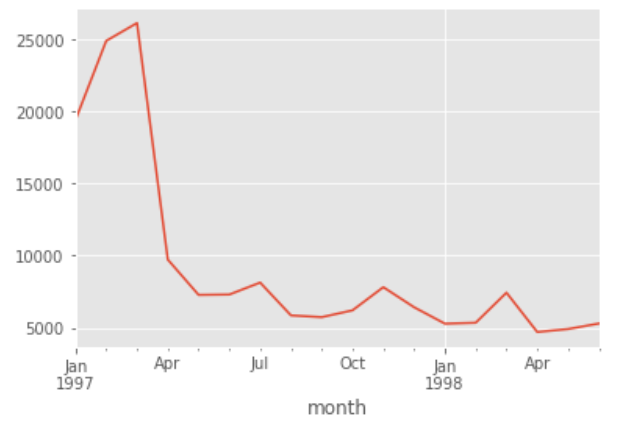
按月統計每個月的CD銷量,從圖中可以看出,前三個月銷量非常的高,但后期下降較大,并趨于平穩(平穩中也略有下降)
df.groupby('month').order_amount.sum().plot()
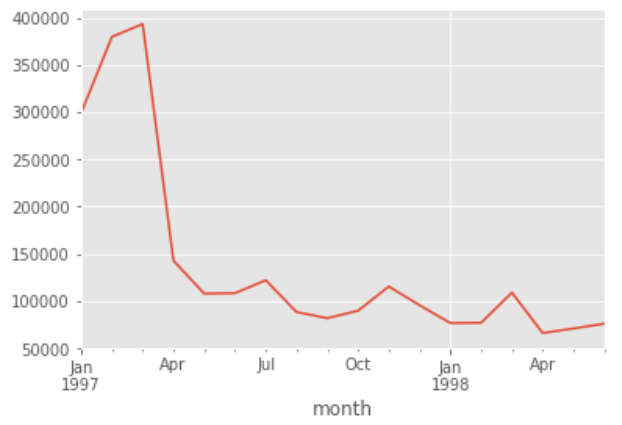
情況同銷量相同,也是前期非常多,后期平穩下降,
-
至于為什么會出現這種情況?我們假設是用戶身上出了問題,早期時間段的用戶中有例外值,第二假設是早期有各類促銷營銷,但這里只有消費資料,所以無法判斷,
-
分析是否存在例外值
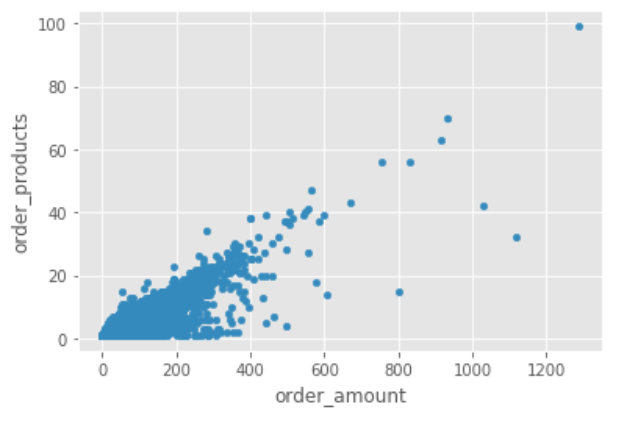
8.1 繪制每筆訂單的散點圖,從圖中觀察,訂單消費金額和訂單商品量呈規律性,每個商品十元左右,訂單的極值極少,超過1000的較少,顯然不是例外波動的罪魁禍首,
df.plot.scatter(x = 'order_amount', y = 'order_products')
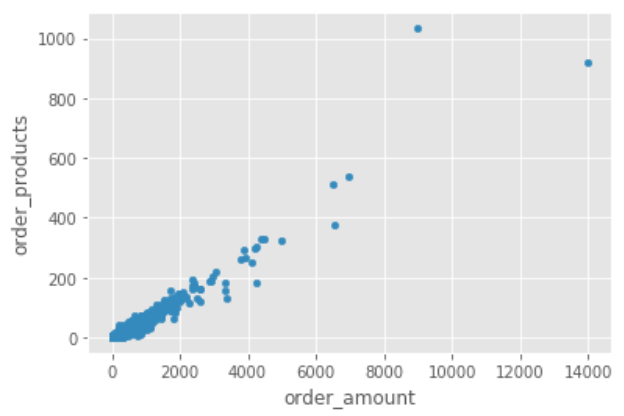
8.2 繪制用戶的散點圖,用戶也比較健康,而且規律性比訂單更強,因為這是CD網站的銷售資料,商品比較單一,金額和商品量的關系也因此呈線性,沒幾個離群點,
df.groupby('user_id').sum().plot.scatter(x = 'order_amount', y = 'order_products')
8.3 消費能力特別強的用戶有,但是數量不多,為了更好的觀察,用直方圖,
plt.figure(figsize=(12, 4))
plt.subplot(121)
df.order_amount.hist(bins = 30)
plt.subplot(122)
df.groupby('user_id').order_amount.sum().hist(bins = 30)
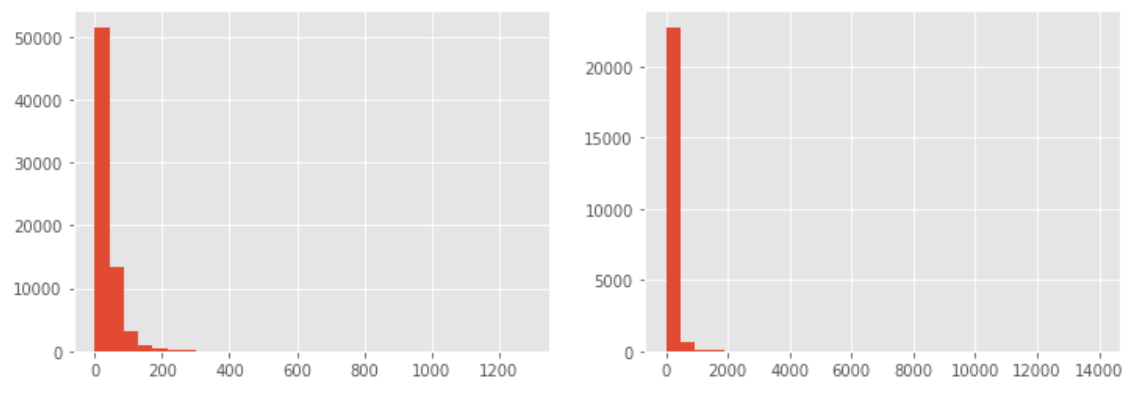
plt.subplot用于繪制子圖,子圖用數字引數表示,121表示分成1*2個圖片區域,占用第一個,即第一行第一列,122表示占用第二個,figure是尺寸函式,為了容納兩張子圖,寬設定的大一點即可,
從直方圖看,大部分用戶的消費能力確實不高,高消費用戶在圖上幾乎看不到,這也確實符合消費行為的行業規律,
8.4 觀察完用戶消費的金額和購買量,接下來看消費的時間節點,
df.groupby('user_id').month.min().value_counts()
1997-02-01 8476
1997-01-01 7846
1997-03-01 7248
Name: month, dtype: int64
從中不難發現,所有用戶的第一次消費都集中在前三個月,我們可以這樣認為,案例中的訂單資料,只是選擇了某個時間段消費的用戶在18個月內的消費行為,
df.groupby('user_id').month.max().value_counts()
1997-02-01 4912
1997-03-01 4478
1997-01-01 4192
1998-06-01 1506
1998-05-01 1042
1998-03-01 993
1998-04-01 769
1997-04-01 677
1997-12-01 620
1997-11-01 609
1998-02-01 550
1998-01-01 514
1997-06-01 499
1997-07-01 493
1997-05-01 480
1997-10-01 455
1997-09-01 397
1997-08-01 384
Name: month, dtype: int64
所有用戶的最后一次消費也主要是集中在前三個月,后續時間段內,依然有用戶在消費,但是緩慢減少,
例外趨勢的原因獲得了解釋,現在針對消費資料進一步細分,我們要明確,這只是部分用戶的訂單資料,所以有一定局限性,在這里,我們統一將資料上消費的用戶定義為新客,
- 接下來分析消費中的復購率和回購率,首先將用戶消費資料進行資料透視,
pivoted_counts = df.pivot_table(index='user_id', columns='month', values='order_dt', aggfunc='count').fillna(0)
columns_month = df.month.sort_values().astype('str').unique()
pivoted_counts.columns = columns_month
pivoted_counts.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 1.0 | 0.0 | 1.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 4 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 5 | 2.0 | 1.0 | 0.0 | 1.0 | 1.0 | 1.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.0 | 2.0 | 1.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
在pandas中,資料透視有專門的函式pivot_table,功能非常強大,
使用資料透視表,需要明確獲得什么結果,有些用戶在某月沒有進行過消費,會用NaN表示,這里用fillna填充,
生成的資料透視,月份是1997-01-01 00:00:00表示,比較丑,所以優化成標準格式,
首先求復購率,復購率的定義是在某時間視窗消費兩次及以上的用戶在總消費用戶中占比,這里的時間視窗是月,如果一個用戶在同一天內下了兩筆訂單,這里也將他算作復購用戶,
將資料轉換一下,消費兩次及以上記為1,消費一次記為0,沒有消費記為NaN,
pivoted_counts_trans = pivoted_counts.applymap(lambda x:1 if x>1 else np.NaN if x==0 else 0)
pivoted_counts_trans.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 0.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 0.0 | 0.0 | 0.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
applymap針對DataFrame里的所有資料,用lambda進行判斷,因為這里涉及了多個結果,所以要兩個if else,記住,lambda沒有elif的用法,
(pivoted_counts_trans.sum() / pivoted_counts_trans.count()).plot(figsize = (10, 4))
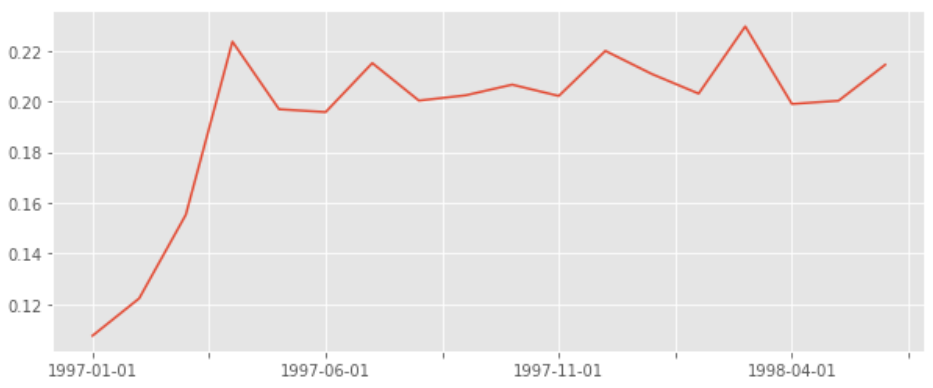
用sum和count相除即可計算出復購率,因為這兩個函式都會忽略NaN,而NaN是沒有消費的用戶,count不論是0還是1都會統計,所以是總的消費用戶數,而sum求和計算了兩次以上的消費用戶這里用了比較巧妙的替代法計算復購率,SQL中也可以用,
圖中可以看出復購率在早期,因為大量新用戶加入的關系,新客的復購率并不高,譬如1月新客們的復購率只有6%左右,而在后期,這時的用戶都是大浪淘沙剩下的老客,復購率比較穩定,在20%左右,
單看新客和老客,復購率有三倍左右的差距,
- 接下來計算回購率,回購率是某一個時間視窗內消費的用戶,在下一個時間視窗仍舊消費的占比,比方說我1月消費用戶為1000,他們中有300個人在2月份依然消費,回購率是30%,
回購率的計算比較難,因為它設計了時間視窗的對比,
pivoted_amount = df.pivot_table(index='user_id', columns='month', values='order_amount', aggfunc='mean').fillna(0)
columns_month = df.month.sort_values().astype('str').unique()
pivoted_amount.columns = columns_month
pivoted_amount.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 11.77 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 | 0.000 | 0.000 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 |
| 2 | 44.50 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 | 0.000 | 0.000 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 |
| 3 | 20.76 | 0.0 | 20.76 | 19.54 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.0 | 39.205 | 0.000 | 0.00 | 0.0 | 0.0 | 0.0 | 16.99 | 0.0 |
| 4 | 29.53 | 0.0 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 14.96 | 0.00 | 0.0 | 0.000 | 26.480 | 0.00 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 |
| 5 | 21.65 | 38.9 | 0.00 | 45.55 | 38.71 | 26.14 | 28.14 | 0.00 | 40.47 | 0.0 | 0.000 | 43.465 | 37.47 | 0.0 | 0.0 | 0.0 | 0.00 | 0.0 |
將消費金額進行資料透視,這里作為練習,使用了平均值,
pivoted_purchase = pivoted_amount.applymap(lambda x:1 if x>0 else 0)
pivoted_purchase.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 |
再次用applymap+lambda轉換資料,只要有購買過,記為1,否則為0,
def purchase_return(data):
status = []
for i in range(17):
if data[i] == 1:
if data[i+1]==1:
status.append(1)
if data[i+1]==0:
status.append(0)
else:
status.append(np.NaN)
status.append(np.NaN)
return status
pivoted_purchase_return = pivoted_purchase.apply(purchase_return, axis=1, result_type='expand')
pivoted_purchase_return.columns = columns_month
pivoted_purchase_return.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 0.0 | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN |
| 4 | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN | NaN | NaN | NaN |
| 5 | 1.0 | 0.0 | NaN | 1.0 | 1.0 | 1.0 | 0.0 | NaN | 0.0 | NaN | NaN | 1.0 | 0.0 | NaN | NaN | NaN | NaN | NaN |
新建一個判斷函式,data是輸入的資料,即用戶在18個月內是否消費的記錄,status是空串列,后續用來保存用戶是否回購的欄位,
因為有18個月,所以每個月都要濟寧一次判斷,需要用到回圈,判斷的主要邏輯是:如果用戶本月進行過消費,且下月也有消費,記為1,沒有記為0,如果本月沒有進行過消費,為NaN,后續的統計中進行消除,
用apply函式應用在所有行上,獲得想要的結果,
(pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot(figsize = (10, 4))
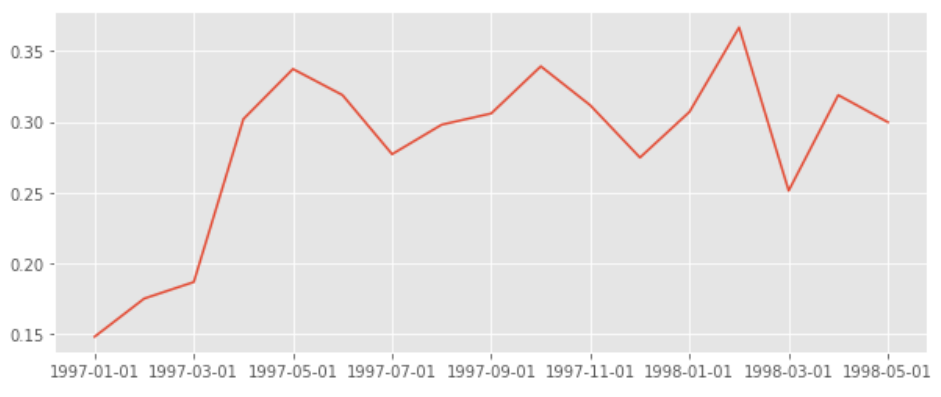
最后的計算和復購率大同小異,用count和sum求出,從圖中可以看出,用戶的回購率高于復購率,約在30%左右,波動性也比較強,新用戶的回購率在15%左右,和老客差異不大,
將回購率和復購率綜合分析,可以得出,新客整體質量低于老客,老客的忠誠度(回購率)表現較好,消費頻次稍次,這是CDNow網站的用戶消費特征,
- 接下來進行用戶分層,我們按照用戶的消費行為,簡單劃分幾個維度:新用戶、活躍用戶 、不活躍用戶和回流用戶,
新用戶的定義是第一次消費,活躍用戶即為老客,在某一個時間視窗內有過消費,不活躍用戶則是時間視窗內沒有消費過的老客,回流用戶是在上一個視窗沒有消費,而在當前時間視窗有過消費,以上時間視窗都是按月統計,
比如某用戶在1月第一次消費,那么他在1月份的分層就是新用戶;他在2月份消費過,則是活躍用戶;3月份沒有消費,此時是不活躍用戶;4月份再次消費,此時是回流用戶,5月份還是消費,是活躍用戶,
分層會涉及到比較多的邏輯判斷,
def state_return(data):
status = []
for i in range(18):
if data[i] == 0:
if len(status) == 0:
status.append('unreg')
else:
if status[i-1] == 'unreg':
status.append('unreg')
else:
status.append('unact')
else:
if len(status) == 0:
status.append('new')
else:
if status[i-1] == 'unreg':
status.append('new')
elif status[i-1] == 'unact':
status.append('return')
else:
status.append('act')
return status
函式寫得比較復雜,主要分為兩部分來判斷,如果本月沒有消費,那么先判斷這個月是不是第一個月,如果是的話必然還沒有購買過(用unreg來表示),如果不是第一個月,那么判斷上個月是不是也還沒購買過,如果是就還是unreg,如果不是這個月就是不活躍用戶unact;如果本月有消費,也是先判斷這個月是不是第一個月,如果是那么說明他是新用戶new,如果不是判斷上個月注冊過沒,沒有就是new,如果上個月是unact說明購買過那么就是回流用戶,否則就是act,
pivoted_purchase_status = pivoted_purchase.apply(state_return, axis = 1, result_type='expand')
pivoted_purchase_status.columns = columns_month
pivoted_purchase_status.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||||||||||||
| 1 | new | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact |
| 2 | new | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact | unact |
| 3 | new | unact | return | act | unact | unact | unact | unact | unact | unact | return | unact | unact | unact | unact | unact | return | unact |
| 4 | new | unact | unact | unact | unact | unact | unact | return | unact | unact | unact | return | unact | unact | unact | unact | unact | unact |
| 5 | new | act | unact | return | act | act | act | unact | return | unact | unact | return | act | unact | unact | unact | unact | unact |
從結果看,用戶每個月的分層狀態以及變化已經被我們計算出來,這個方法是根據透視過的寬表計算,其實還有另一種寫法,只提取時間視窗內的資料和上個視窗對比判斷,封裝成函式做回圈,封裝成函式做回圈,這種方法更適合ETL的增量更新,
pivoted_status_counts = pivoted_purchase_status.replace('unreg', np.NaN).apply(lambda x:pd.value_counts(x))
pivoted_status_counts.head()
| 1997-01-01 | 1997-02-01 | 1997-03-01 | 1997-04-01 | 1997-05-01 | 1997-06-01 | 1997-07-01 | 1997-08-01 | 1997-09-01 | 1997-10-01 | 1997-11-01 | 1997-12-01 | 1998-01-01 | 1998-02-01 | 1998-03-01 | 1998-04-01 | 1998-05-01 | 1998-06-01 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| act | NaN | 1155.0 | 1680 | 1773.0 | 852.0 | 747.0 | 746.0 | 604.0 | 528.0 | 532.0 | 624 | 632.0 | 512.0 | 472.0 | 569.0 | 517.0 | 458.0 | 446.0 |
| new | 7814.0 | 8455.0 | 7231 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 2 | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| return | NaN | NaN | 595 | 1049.0 | 1362.0 | 1592.0 | 1434.0 | 1168.0 | 1211.0 | 1307.0 | 1402 | 1232.0 | 1025.0 | 1079.0 | 1489.0 | 919.0 | 1030.0 | 1060.0 |
| unact | NaN | 6659.0 | 13994 | 20678.0 | 21286.0 | 21161.0 | 21320.0 | 21728.0 | 21761.0 | 21661.0 | 21474 | 21638.0 | 21965.0 | 21951.0 | 21444.0 | 22066.0 | 22014.0 | 21996.0 |
將unreg更改為NaN是為了避免被計入總數,此時已換成按月的統計量,
pivoted_status_counts.fillna(0).T.plot.area(figsize = (12, 6))
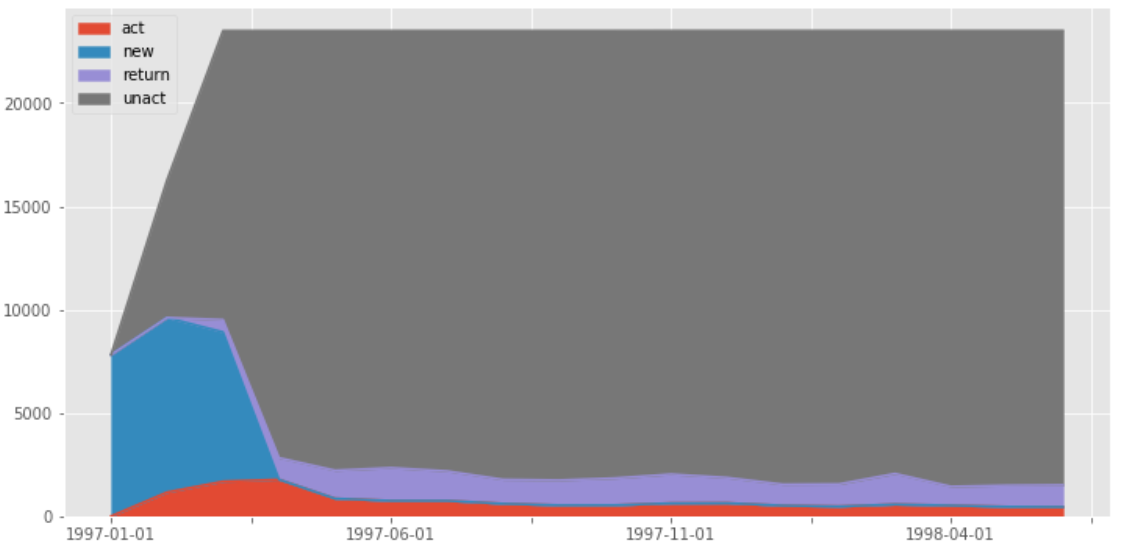
生成面積圖,因為它還是某時間段消費過的用戶的后續行為,所以藍色和灰色的區域都可以不看,只看紫色回流和紅色活躍 這兩個分層,用戶數比較穩定,這兩個分層相加,就是消費用戶占比(后期沒新客),
return_rata = pivoted_status_counts.apply(lambda x:x / x.sum(), axis = 1)
return_rata.loc['return'].plot(figsize = (12, 6))
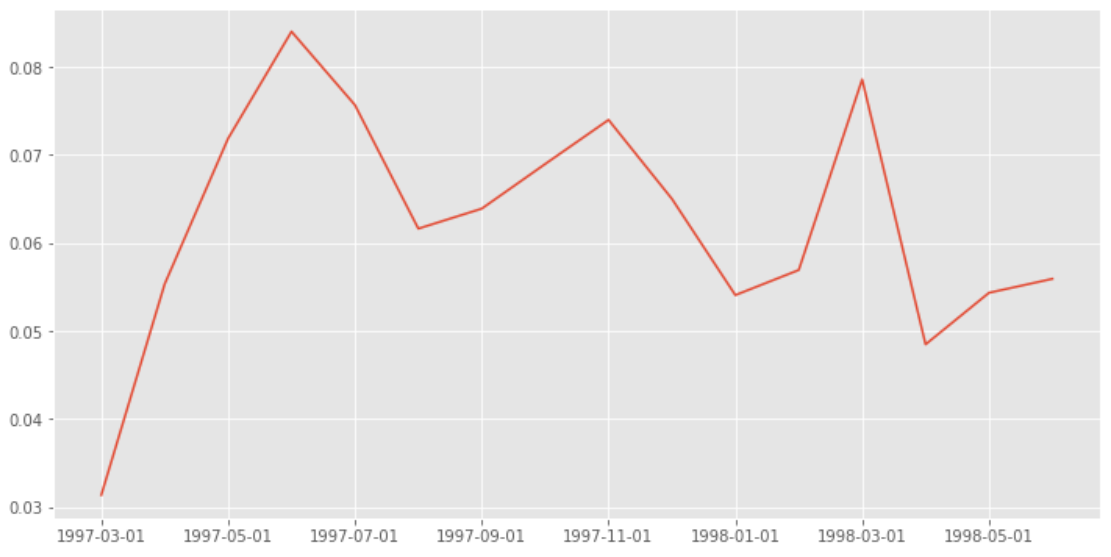
用戶回流占比在5%-8%,有下降趨勢,所謂回流占比,就是回流用戶在總用戶中的占比,另外一種指標叫回流率,指上個月多少不消費(活躍)用戶在本月消費(活躍)用戶的占比,
return_rata.loc['act'].plot(figsize = (12, 6))
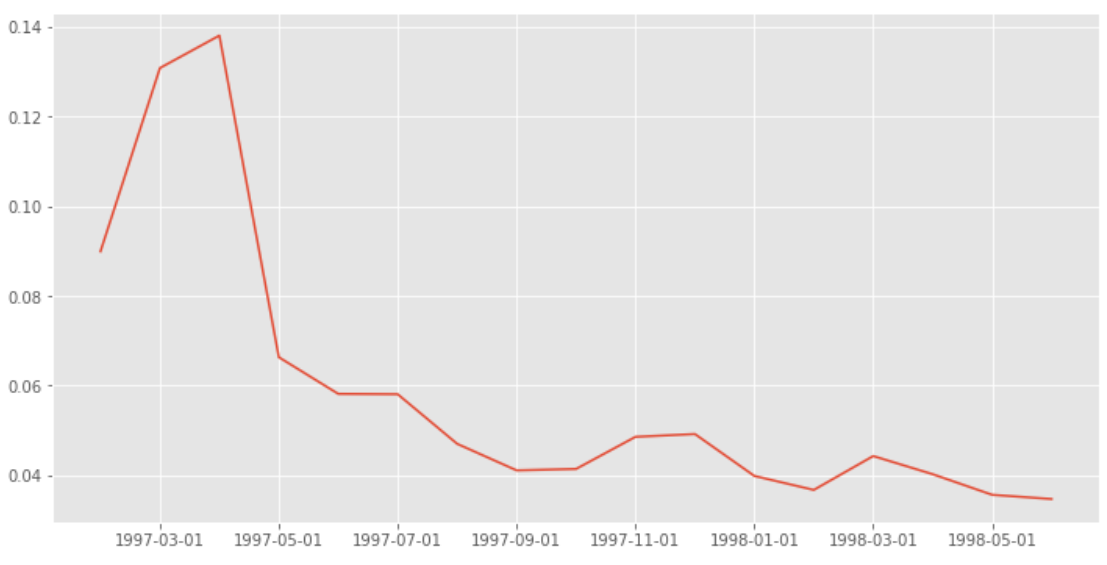
活躍用戶的下降趨勢更明顯,占比在3%~5%之間,這里的活躍用戶可以看作是連續消費用戶,質量上在一定程度上高于回流用戶,
結合回流用戶和活躍用戶來看,在后期的消費用戶中,60%是回流用戶,40%是活躍用戶(連續消費用戶),整體質量還不錯,但是針對這兩個分層依舊有改進的空間,可以繼續細化資料,
- 接下來分析用戶質量,因為消費行為有明顯的二八傾向,我們需要知道高質量用戶為消費貢獻了多少份額,
user_amount = df.groupby('user_id').order_amount.sum().sort_values().reset_index()
user_amount['amount_cumsum'] = user_amount.order_amount.cumsum()
user_amount.tail()
| user_id | order_amount | amount_cumsum | |
|---|---|---|---|
| 23565 | 7931 | 6497.18 | 2463822.60 |
| 23566 | 19339 | 6552.70 | 2470375.30 |
| 23567 | 7983 | 6973.07 | 2477348.37 |
| 23568 | 14048 | 8976.33 | 2486324.70 |
| 23569 | 7592 | 13990.93 | 2500315.63 |
新建一個物件,按用戶的消費金額升序,使用cumsum函式,即累加函式,用于逐行計算累計的金額,最后的2500315便是總金額,
total_amount = user_amount.amount_cumsum.max()
user_amount['prop'] = user_amount.amount_cumsum.apply(lambda x:x / total_amount)
user_amount.tail()
| user_id | order_amount | amount_cumsum | prop | |
|---|---|---|---|---|
| 23565 | 7931 | 6497.18 | 2463822.60 | 0.985405 |
| 23566 | 19339 | 6552.70 | 2470375.30 | 0.988025 |
| 23567 | 7983 | 6973.07 | 2477348.37 | 0.990814 |
| 23568 | 14048 | 8976.33 | 2486324.70 | 0.994404 |
| 23569 | 7592 | 13990.93 | 2500315.63 | 1.000000 |
轉換成百分比,
user_amount.prop.plot()
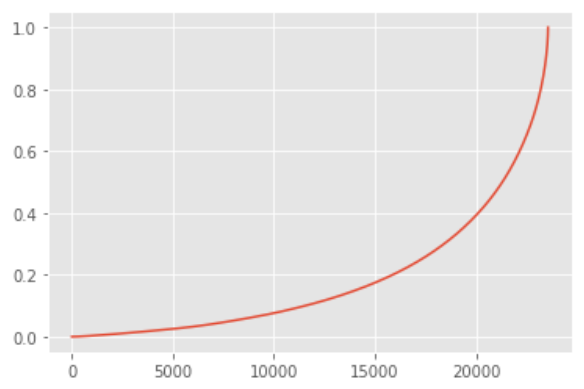
如上圖所示,橫坐標是按貢獻金額大小排序而成,縱坐標則是用戶累計貢獻,可以很清楚的看到,前20000個用戶貢獻了40%的消費,后面3000多位用戶則貢獻了60%,確實呈現二八傾向,
user_counts = df.groupby('user_id').order_dt.count().sort_values().reset_index()
user_counts['counts_cumsum'] = user_counts.order_dt.cumsum()
total_counts = user_counts.counts_cumsum.max()
user_counts['prop'] = user_counts.counts_cumsum.apply(lambda x:x / total_counts)
user_counts.prop.plot()
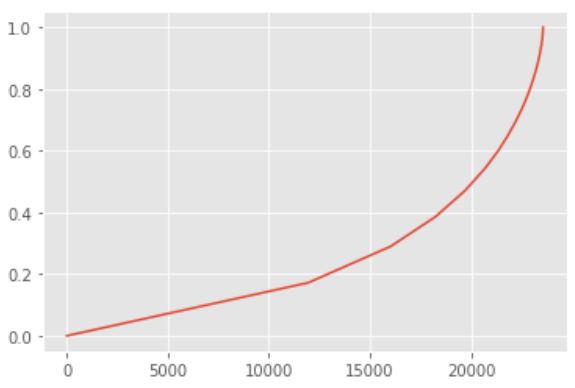
此時統計銷量,前20000位用戶貢獻了45%的銷量,剩下的高消費用戶則貢獻了55%的銷量,在消費領域中,狼抓高質量用戶是萬古不變的道理,
- 接下來計算用戶的生命周期,這里定義第一次消費至最后一次消費為整個用戶生命,
user_purchase = df[['user_id', 'order_products', 'order_amount', 'order_date']]
order_date_min = user_purchase.groupby('user_id').order_date.min()
order_date_max = user_purchase.groupby('user_id').order_date.max()
(order_date_max - order_date_min).head(10)
user_id
1 0 days
2 0 days
3 511 days
4 345 days
5 367 days
6 0 days
7 445 days
8 452 days
9 523 days
10 0 days
Name: order_date, dtype: timedelta64[ns]
先統計出了用戶的第一次消費和最后一次消費,然后相減即可,因為資料中的用戶都是前三月第一次消費,所以這里的生命周期代表的是1月~3月用戶的生命周期,因為用戶會持續消費,所以理論上,隨著后續的消費,用戶的平均生命周期會增大,
(order_date_max - order_date_min).describe()
count 23570
mean 134 days 20:55:36.987696224
std 180 days 13:46:43.039788104
min 0 days 00:00:00
25% 0 days 00:00:00
50% 0 days 00:00:00
75% 294 days 00:00:00
max 544 days 00:00:00
Name: order_date, dtype: object
求一下平均,所有用戶的平均生命周期是134天,比預想的高,但是中位數是0,說明了由很多用戶第一次購買和最后一次購買都是在同一天,
為了更清楚地查看用戶的生命周期,我們需要看一下分布,
((order_date_max - order_date_min) / np.timedelta64(1, 'D')).hist(bins = 15)
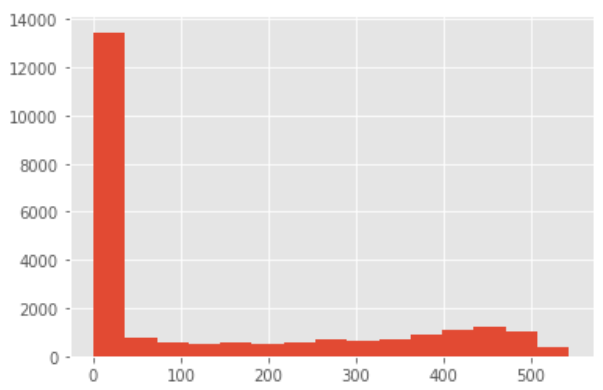
因為這里的資料型別是timedelta時間,它無法直接作出直方圖,所以先換算成數值,劃算的方式直接除timedelta函式即可,這里的np.timedelta64(1, ‘D’)即可,
從圖中可以看出,大部分用戶只消費了一次,所有生命周期的大頭都集中在了0天,但這不是我們想要的答案,不妨將只消費了一次的新客排除,來計算所有消費過兩次以上的老客的生命周期,
life_time = (order_date_max - order_date_min).reset_index() # 轉為dataframe
life_time.head()
| user_id | order_date | |
|---|---|---|
| 0 | 1 | 0 days |
| 1 | 2 | 0 days |
| 2 | 3 | 511 days |
| 3 | 4 | 345 days |
| 4 | 5 | 367 days |
life_time['life_time'] = life_time.order_date / np.timedelta64(1, 'D')
life_time[life_time.life_time > 0].life_time.hist(bins=100, figsize=(12, 6))
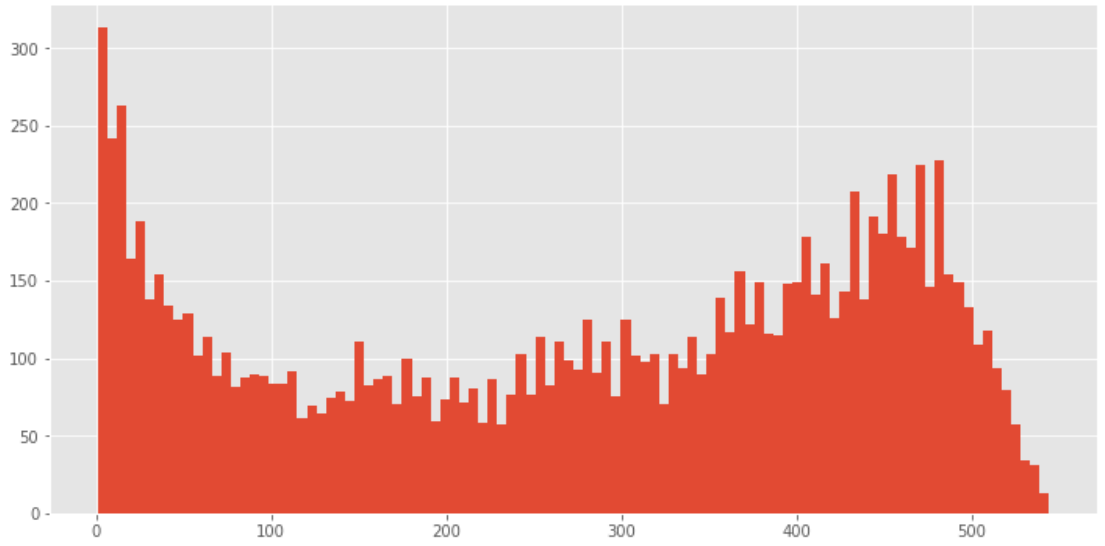
篩選出lifetime>0,即排除了僅消費了一次的那些人,做直方圖,
這個圖的價值明顯高于上圖,雖然仍舊有不少用戶生命周期靠攏0天,這是雙峰趨勢圖,部分質量差的用戶,雖然消費了兩次,但是仍舊無法持續,在用戶首次消費30天內應該盡量引導,少部分用戶集中在50天~300天,屬于普通型的生命周期,高質量用戶的生命周期,集中在400天以后,這已經屬于忠誠用戶了,
life_time[life_time.life_time > 400].life_time.count() / life_time[life_time.life_time > 0].life_time.count()
0.31703716568252865
生命周期在400天以上的用戶占老客的比例為31.7%,挺高的數值了,
life_time[life_time.life_time > 0].life_time.mean()
276.0448072247308
消費兩次以上的用戶生命周期為276天,遠高于總體,從策略上看,用戶首次消費后應該花費更多時間精力去引導其進行多次消費,延長生命周期,這會帶來2.5倍的增量,
- 再來計算留存率,留存率也是消費分析領域的經典應用,它指用戶在第一次消費后,有多少比率進行第二次消費,和回流率的區別是留存率傾向于計算第一次消費,并且有多個時間視窗,
user_purchase_retention = pd.merge(left=user_purchase, right=order_date_min.reset_index(), how='inner', on='user_id',suffixes=('', '_min'))
user_purchase_retention.head()
| user_id | order_products | order_amount | order_date | order_date_min | |
|---|---|---|---|---|---|
| 0 | 1 | 1 | 11.77 | 1997-01-01 | 1997-01-01 |
| 1 | 2 | 1 | 12.00 | 1997-01-12 | 1997-01-12 |
| 2 | 2 | 5 | 77.00 | 1997-01-12 | 1997-01-12 |
| 3 | 3 | 2 | 20.76 | 1997-01-02 | 1997-01-02 |
| 4 | 3 | 2 | 20.76 | 1997-03-30 | 1997-01-02 |
這里用到merge函式,它和SQL中的join差不多,用來將兩個dataframe進行合并,我們選擇了inner的方式,對標SQL中的inner join,
這里merge的目的是將用戶消費行為和第一次消費時間對應上,形成一個新的dataframe,
user_purchase_retention['order_date_diff'] = user_purchase_retention.order_date - user_purchase_retention.order_date_min
user_purchase_retention.head()
| user_id | order_products | order_amount | order_date | order_date_min | order_date_diff | |
|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 11.77 | 1997-01-01 | 1997-01-01 | 0 days |
| 1 | 2 | 1 | 12.00 | 1997-01-12 | 1997-01-12 | 0 days |
| 2 | 2 | 5 | 77.00 | 1997-01-12 | 1997-01-12 | 0 days |
| 3 | 3 | 2 | 20.76 | 1997-01-02 | 1997-01-02 | 0 days |
| 4 | 3 | 2 | 20.76 | 1997-03-30 | 1997-01-02 | 87 days |
這里將order_date和order_date_min想減,獲得一個新的列,為用戶每一次消費距第一次消費的時間差值,
date_trans = lambda x: x/np.timedelta64(1, 'D')
user_purchase_retention['date_diff'] = user_purchase_retention.order_date_diff.apply(date_trans)
user_purchase_retention.head(10)
| user_id | order_products | order_amount | order_date | order_date_min | order_date_diff | date_diff | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 11.77 | 1997-01-01 | 1997-01-01 | 0 days | 0.0 |
| 1 | 2 | 1 | 12.00 | 1997-01-12 | 1997-01-12 | 0 days | 0.0 |
| 2 | 2 | 5 | 77.00 | 1997-01-12 | 1997-01-12 | 0 days | 0.0 |
| 3 | 3 | 2 | 20.76 | 1997-01-02 | 1997-01-02 | 0 days | 0.0 |
| 4 | 3 | 2 | 20.76 | 1997-03-30 | 1997-01-02 | 87 days | 87.0 |
| 5 | 3 | 2 | 19.54 | 1997-04-02 | 1997-01-02 | 90 days | 90.0 |
| 6 | 3 | 5 | 57.45 | 1997-11-15 | 1997-01-02 | 317 days | 317.0 |
| 7 | 3 | 4 | 20.96 | 1997-11-25 | 1997-01-02 | 327 days | 327.0 |
| 8 | 3 | 1 | 16.99 | 1998-05-28 | 1997-01-02 | 511 days | 511.0 |
| 9 | 4 | 2 | 29.33 | 1997-01-01 | 1997-01-01 | 0 days | 0.0 |
bin = [0,3,7,15,30,60,90,180,365]
user_purchase_retention['date_diff_bin'] = pd.cut(user_purchase_retention.date_diff, bins = bin)
user_purchase_retention.head(15)
| user_id | order_products | order_amount | order_date | order_date_min | order_date_diff | date_diff | date_diff_bin | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 1 | 11.77 | 1997-01-01 | 1997-01-01 | 0 days | 0.0 | NaN |
| 1 | 2 | 1 | 12.00 | 1997-01-12 | 1997-01-12 | 0 days | 0.0 | NaN |
| 2 | 2 | 5 | 77.00 | 1997-01-12 | 1997-01-12 | 0 days | 0.0 | NaN |
| 3 | 3 | 2 | 20.76 | 1997-01-02 | 1997-01-02 | 0 days | 0.0 | NaN |
| 4 | 3 | 2 | 20.76 | 1997-03-30 | 1997-01-02 | 87 days | 87.0 | (60.0, 90.0] |
| 5 | 3 | 2 | 19.54 | 1997-04-02 | 1997-01-02 | 90 days | 90.0 | (60.0, 90.0] |
| 6 | 3 | 5 | 57.45 | 1997-11-15 | 1997-01-02 | 317 days | 317.0 | (180.0, 365.0] |
| 7 | 3 | 4 | 20.96 | 1997-11-25 | 1997-01-02 | 327 days | 327.0 | (180.0, 365.0] |
| 8 | 3 | 1 | 16.99 | 1998-05-28 | 1997-01-02 | 511 days | 511.0 | NaN |
| 9 | 4 | 2 | 29.33 | 1997-01-01 | 1997-01-01 | 0 days | 0.0 | NaN |
| 10 | 4 | 2 | 29.73 | 1997-01-18 | 1997-01-01 | 17 days | 17.0 | (15.0, 30.0] |
| 11 | 4 | 1 | 14.96 | 1997-08-02 | 1997-01-01 | 213 days | 213.0 | (180.0, 365.0] |
| 12 | 4 | 2 | 26.48 | 1997-12-12 | 1997-01-01 | 345 days | 345.0 | (180.0, 365.0] |
| 13 | 5 | 2 | 29.33 | 1997-01-01 | 1997-01-01 | 0 days | 0.0 | NaN |
| 14 | 5 | 1 | 13.97 | 1997-01-14 | 1997-01-01 | 13 days | 13.0 | (7.0, 15.0] |
pivoted_retention = user_purchase_retention.pivot_table(index='user_id', columns='date_diff_bin', values='order_amount', aggfunc=sum)
pivoted_retention.head(10)
| date_diff_bin | (0, 3] | (3, 7] | (7, 15] | (15, 30] | (30, 60] | (60, 90] | (90, 180] | (180, 365] |
|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||
| 1 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 |
| 2 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 |
| 3 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 40.3 | 0.00 | 78.41 |
| 4 | 0.0 | 0.0 | 0.00 | 29.73 | 0.00 | 0.0 | 0.00 | 41.44 |
| 5 | 0.0 | 0.0 | 13.97 | 0.00 | 38.90 | 0.0 | 110.40 | 155.54 |
| 6 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 |
| 7 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 97.43 |
| 8 | 0.0 | 0.0 | 0.00 | 0.00 | 13.97 | 0.0 | 45.29 | 104.17 |
| 9 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.0 | 30.33 | 0.00 |
| 10 | 0.0 | 0.0 | 0.00 | 0.00 | 0.00 | 0.0 | 0.00 | 0.00 |
用pivot_table資料透視,獲得的結果是用戶在第一次消費之后,在后續各時間段內的消費總額,
這里不難發現如果沒有消費的話就是0,但為方便后續我們只統計有消費的用戶,將0更改為nan,
pivoted_retention.replace(0,np.nan).mean()
date_diff_bin
(0, 3] 35.905798
(3, 7] 36.385121
(7, 15] 42.669895
(15, 30] 45.986198
(30, 60] 50.215070
(60, 90] 48.975277
(90, 180] 67.223297
(180, 365] 91.960059
dtype: float64
此時計算用戶在后續時間段的平均消費額,這里只統計有消費的平均值,雖然后面時間段的金額高,但是它的時間范圍也寬廣,從平均效果來看,用戶第一次消費后的0-3天內,更可能消費更多,
但消費更多是一個相對的概念,我們還要看整體中有多少用戶在0-3天消費,
pivoted_retention_trans = pivoted_retention.applymap(lambda x: 1 if x>0 else 0)
pivoted_retention_trans.head()
| date_diff_bin | (0, 3] | (3, 7] | (7, 15] | (15, 30] | (30, 60] | (60, 90] | (90, 180] | (180, 365] |
|---|---|---|---|---|---|---|---|---|
| user_id | ||||||||
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 |
| 4 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 |
| 5 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 |
如果有消費就記為1,沒有就是0.
(pivoted_retention_trans.sum() / pivoted_retention_trans.count()).plot.bar()
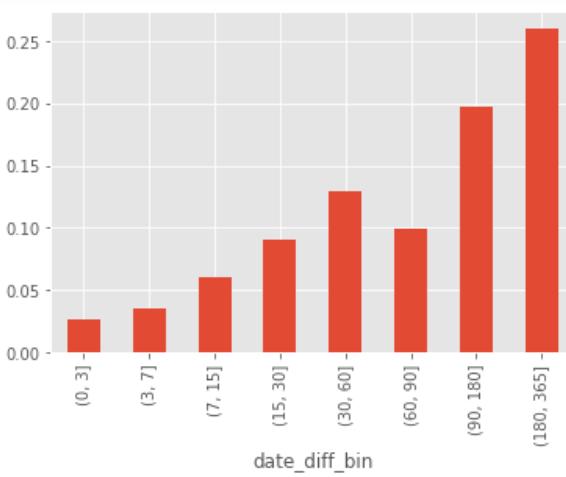
只有2.5%的用戶在第一次消費后的三天內有過消費,3%的用戶在3-7天內有過消費,數字并不好看,不過CD購買確實不是高頻消費行為,時間范圍放寬后數字好看了不少,有20%的用戶在第一次消費后的三個月到半年之間有過購買,27%的用戶在半年后到一年內有過購買,從運營角度看,CD機營銷在教育新用戶的同時,應該注重用戶忠誠度的培養,放長線釣大魚,在一定時間內召回用戶購買,
- 怎么算放長線釣大魚呢?我們計算出用戶的平均購買周期,
def diff(group):
d = group.date_diff.shift(-1) - group.date_diff
return d
last_diff = user_purchase_retention.groupby('user_id').apply(diff)
last_diff.head(10)
user_id
1 0 NaN
2 1 0.0
2 NaN
3 3 87.0
4 3.0
5 227.0
6 10.0
7 184.0
8 NaN
4 9 17.0
Name: date_diff, dtype: float64
此時已經求出了用戶的每次購買距離上次購買的時間差,
last_diff.mean()
68.97376814424265
此時求出了用戶的平均消費間隔是68天,所以想要召回用戶,在60天左右的消費間隔是比較好的,
last_diff.hist(bins = 20)
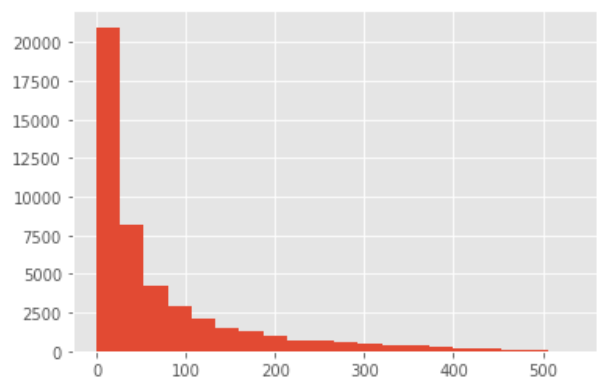
看一下直方圖,典型的長尾分布,大部分的用戶的消費間隔確實比較短,不妨將時間召回點設為消費后立即贈送優惠券,消費10天詢問用戶CD怎么樣,消費30天后提醒優惠券到期,消費60天后短信推送,這便是資料的應用了,
推薦關注的專欄
👨?👩?👦?👦 機器學習:分享機器學習實戰專案和常用模型講解
👨?👩?👦?👦 資料分析:分享資料分析實戰專案和常用技能整理
往期內容回顧
💚 學習Python全套代碼【超詳細】Python入門、核心語法、資料結構、Python進階【致那個想學好Python的你】
?? 學習pandas全套代碼【超詳細】資料查看、輸入輸出、選取、集成、清洗、轉換、重塑、數學和統計方法、排序
💙 學習pandas全套代碼【超詳細】分箱操作、分組聚合、時間序列、資料可視化
💜 學習NumPy全套代碼【超詳細】基本操作、資料型別、陣列運算、復制和試圖、索引、切片和迭代、形狀操作、通用函式、線性代數
關注我,了解更多相關知識!
CSDN@報告,今天也有好好學習
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357244.html
標籤:AI