前言
經過了差不多一個月的不斷實驗資料工程又跑模型,最侄訓是發現診斷文本單特征最靠譜了,其他特征與flag關聯都挺一般的,官方是根據評分來劃分flag的:>5為1,<5為0.由此鎖定Caprini模型評估表格中高分重點指標即可預測評分指數從而預測風險,本文提供做標簽化文本預測和做文本分析預測思路,但僅提供處理思路,后續比賽結束代碼開源,可參考,

提示:以下是本篇文章正文內容,下面案例可供參考
一、診斷文本標簽化預測
| 診斷 |
| 結締組織病 |
| 高血壓腎損害 |
| 脊椎源性痛綜合征 |
| 結腸惡性腫瘤 |
| 開角型青光眼 |
| 肺惡性腫瘤 |
| 胃炎 |
| 肺惡性腫瘤 |
| 胃惡性腫瘤 |
| 肺繼發惡性腫瘤 |
| 腦梗死 |
| 軀干三度燒傷 |
| 特發性腎積水 |
| 肝硬化伴食管靜脈曲張破裂出血 |
| 冠狀動脈粥樣硬化 |
| 胃炎 |
| 腹痛 |
| 頭位順產 |
| 為腫瘤化學治療療程 |
等這些單文本特征,由于這些特征符合Caprini模型表格:
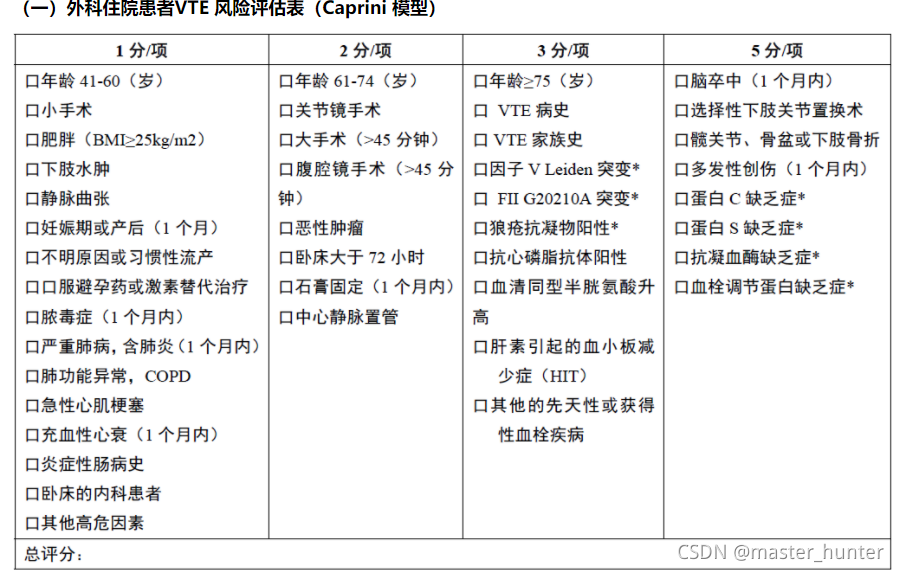
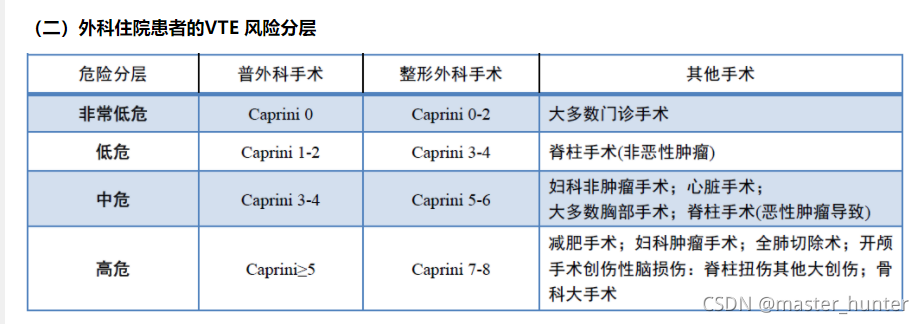
進行評分等級風險的,而對于其他資料特征如D二聚體或凝血酶時間等特征來說關聯性太小,和其他flag為0的資料拉不開太大差距(這就是人工標簽和演算法標簽的差距,如果不能讓人工標簽做到盡可能精確,那只能讓演算法更趨近于人工的演算法) ,
對這些特征進行標簽化:
| 診斷 |
| 0 |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 5 |
| 7 |
| 8 |
| 9 |
| 10 |
| 11 |
| 12 |
| 13 |
| 6 |
| 14 |
如上述對整個文本診斷特征進行處理(得和預測文本一起進行標簽化),當然預測文本也是一樣進行標簽化處理,
隨后進行你們想使用的機器學習模型或是深度學習模型進行預測即可,
二、詞袋模型文本特征預測
此方法和上文思路僅是多了一個參考Caprini模型表格進行文本詞向量劃分,這里提供python處理方法:
首先利用jieba庫進行詞性劃分:
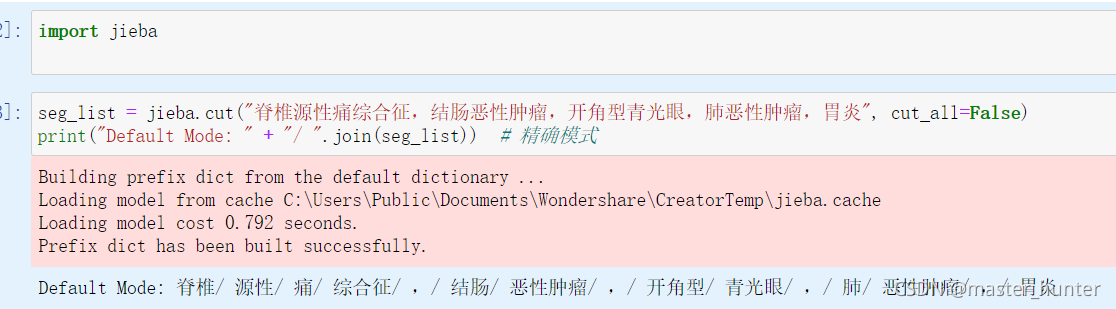
例如這個效果進行詞向量分類從而構建詞袋模型分類,
#創建一個空集
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) #創建兩個集合的并集 劃掉重復出現的單詞
return list(vocabSet)
#處理樣本輸出為向量形式
def setOfWords2Vec(vocaList , inputSet):
returnVec = [0]*len(vocaList)#創建一個其中所含元素全為0的向量代替文本
for word in inputSet:
if word in vocaList:
returnVec[vocaList.index(word)] += 1
else:
print("the word:%s is not in my Vocabulary!"" % word")
return returnVec如果對文本詞向量處理不是很了解的話可以看我另一篇文章:
機器學習:基于概率的樸素貝葉斯分類器詳解--Python實作以及專案實戰![]() https://blog.csdn.net/master_hunter/article/details/109630661?spm=1001.2014.3001.5502之后構建完詞袋模型對不同詞向量根據其標簽打上即可完成,隨后進行預測調引數即可,
https://blog.csdn.net/master_hunter/article/details/109630661?spm=1001.2014.3001.5502之后構建完詞袋模型對不同詞向量根據其標簽打上即可完成,隨后進行預測調引數即可,
三、總結
總之我覺得挺遺憾的,最后卷的居然是單特征,而其他給的二十多個維度的特征資料全部浪費了沒用用上去,當然第二總方法肯定會比第一種方法得分更高但是第一種更快出結果,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357245.html
標籤:AI