老鐵,你還在為9點半開市時的資料陡增導致的資料積壓問題而煩惱頭禿嗎?
你還在為資料傳遞時的訊息阻塞而手足無措嗎?
你還在為無法保障訊息順序性及回溯消費而寢食難安嗎?
不要慫,不要怕,請允許筆者為你推薦一款實時資料開發必備良藥——Kafka,

01 Kafka簡介
Kafka是一個分布式的基于發布/訂閱模式的訊息佇列,主要應用于大資料實時處理領域,不同于點對點模式的訊息佇列,Kafka發布到topic的訊息會被所有訂閱者消費,
02 Kafka基礎架構
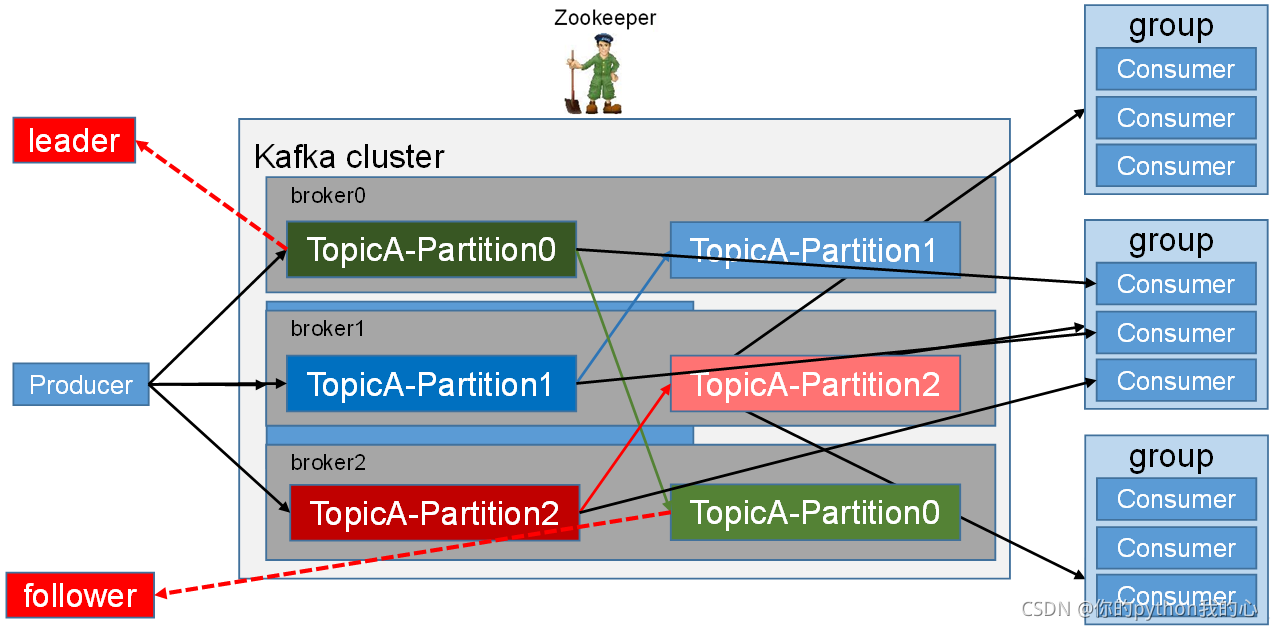
- Topic:
可以理解為一個佇列,生產者和消費者面向的都是一個topic, - Partition:
為了實作擴展性,一個非常大的topic可以分布到多個broker(即服務器)上,一個topic可以分為多個partition,每個partition是一個有序的佇列, - Producer:
訊息生產者,就是向kafka broker發訊息的客戶端, - Consumer:
訊息消費者,向kafka broker取訊息的客戶端,多個consumer組成消費者組,消費者組內每個消費者負責消費不同磁區的資料,一個磁區只能由一個消費者消費;消費者組之間互不影響,所有的消費者都屬于某個消費者組,即消費者組是邏輯上的一個訂閱者, - Broker :
一臺kafka服務器就是一個broker,一個集群由多個broker組成,一個broker可以容納多個topic, - Replica:
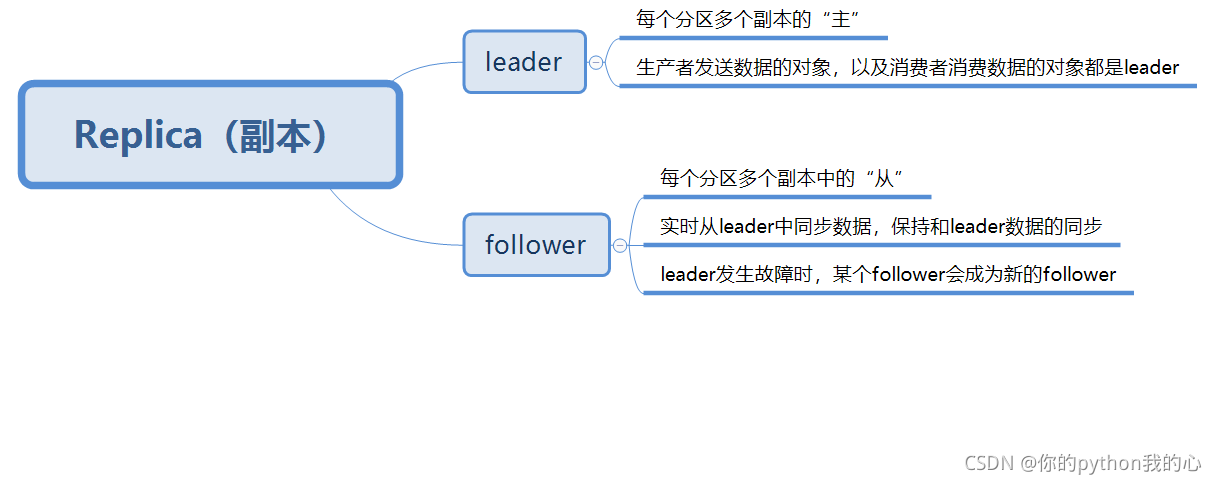
副本,為保證集群中的某個節點發生故障時,該節點上的partition資料不丟失,且kafka仍然能夠繼續作業,kafka提供了副本機制,一個topic的每個磁區都有若干個副本,一個leader和若干個follower,
03 Kafka生產者
3.1 磁區策略
為了方便在集群中擴展,且提高并發度,所以考慮磁區,
① 指明 partition 的情況下,直接將指明的值直接作為 partiton 值
②沒有指明 partition 值但有 key 的情況下,將 key 的 hash 值與 topic的 partition 數進行取余得到 partition 值
③既沒有 partition 值又沒有 key 值的情況下,第一次呼叫時隨機生成一個整數(后面每次呼叫在這個整數上自增),將這個值與 topic 可用的 partition 總數取余得到 partition 值,也就是常說的 round-robin 演算法
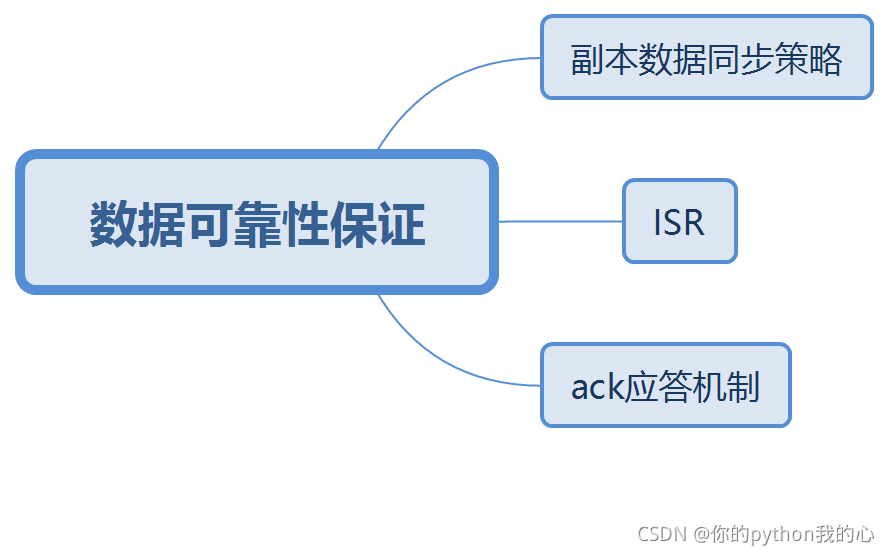
3.2 資料可靠性保證
為保證producer發送的資料,能可靠的發送到指定的topic,topic的每個partition收到producer發送的資料后,都需要向producer發送ack(acknowledgement確認收到),如果producer收到ack,就會進行下一輪的發送,否則重新發送資料,
3.3 Exactly Once語意
對于某些比較重要的訊息,我們需要保證exactly once語意,即保證每條訊息被發送且僅被發送一次,
04 Kafka消費者
consumer采用pull(拉)模式從broker中讀取資料,相比于push模式,pull模式則可以根據consumer的消費能力以適當的速率消費訊息,請記得設定timeout 引數,
4.1 磁區分配策略
Kafka有兩種分配策略,一是roundrobin,一是range,
4.2 offset的維護
由于consumer在消費程序中可能會出現斷電宕機等故障,consumer恢復后,需要從故障前的位置的繼續消費,所以consumer需要實時記錄自己消費到了哪個offset,以便故障恢復后繼續消費,
Kafka 0.9版本之前,consumer默認將offset保存在Zookeeper中,從0.9版本開始,consumer默認將offset保存在Kafka一個內置的topic中,該topic為__consumer_offsets,
05 應用中常見的坑
后續文章,筆者會分享Kafka在實際應用中常見的坑,敬請期待喲
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/357266.html
標籤:其他