??LSM Tree(log-structured merge-tree)是一種檔案組織結構的資料結構,目前在不少資料庫中都有使用到,如SQLite、LevelDB、HBase在Mongodb中也有一個LSM引擎;
??在傳統的關系型資料庫中使用的是B-/B+ tree作為索引的資料結構,B tree的查詢性能很高,為O(log n)復雜度,但其寫性能并達不到O(log n),而在傳統資料庫中每次插入、洗掉資料都要更新索引,每次更新索引都會有一次磁盤IO,頻繁寫時其性能較低;
??LSM Tree查詢性能達不到理論的O(log n),但效率并不慢,且其避免了頻繁寫時的磁盤IO,使得非常適用于KV與日志型資料庫;
LSM快的原因
??磁盤、記憶體的順序讀寫性能遠高于隨機讀寫性能,LSM通過消除更新操作(改、刪)在其結構中資料無法改、刪改,只能夠順序的新增追加,從而達到避免了隨機寫的性能問題;
??寫的情況解決了,但此時還必須解決隨機讀的性能問題,或者說怎么能夠避免隨機讀;在目前順序追加的兩個場景中通過其特性消除了隨機讀的問題:
??1、在WAL(write-ahead log)中場景中其資料是被整體訪問的不存在隨機讀問題;
??2、在Kafka中其沒有隨機讀,因為其有明確的offset,有了offset就可通過seek讀取指定資料,明確的物理偏移量;
??LSM Tree要解決的是不需要讀取全部資料、無需物理偏移量的讀場景下的高性能讀的問題;
寫資料
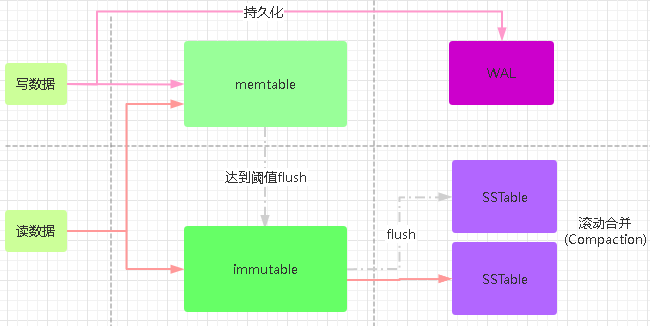
??外部資料是無序的,但LSM Tree所有寫操作為順序寫,直接無差別的追加并不能雖然實作了順序寫但不能保證資料的有序;在LSM Tree中會在記憶體中使用一個有序結構(memtable)如(AVL樹、紅黑樹等),寫資料時都寫入其有序樹中,始終保持資料的有序性,當寫入資料達到閾值時觸發有序樹的flush刷盤操作,將資料有序的順序寫入到磁盤中,生成segment,有序樹開始新的周期,
SSTable
??LSM Tree持久化后的資料稱為SSTable(Sorted Strings Table),SSTable為按Key排序后的資料,每個SSTable可能包含多個檔案成為segment,其內部資料一樣為有序結構,segment為immutable(不可修改);
讀取資料
??先從mentable有序樹中查找資料,如未找到資料則從SSTable中讀取指定資料,從最新segment開始依序掃描segment,在每個segment中其內部都是有序資料,可使用二分查找演算法進行查詢,可在O(log n)時間內得到結果;
??二分查找有兩種情況:一次性把資料全部讀到記憶體、每次二分時讀取資料;在segment非常大時兩者性能都不夠理想,可在記憶體內部維護一個稀疏索引(sparse index)【稀疏索引是指將有序資料切分為固定大小的塊,僅對每塊開頭一條資料做索引】,引入稀疏索引后,可在索引表中用二分查找定位key 在哪小塊資料中,后僅從磁盤中讀取一塊資料即可獲得查詢結果,此時加載資料量僅是整個 segment 的一小部分,IO大大降低,
??查找的資料存在時不需全盤掃描,但如讀取的資料不存在SSTable中時,此時需要掃描所有segment才能得到最終結果,但此時性能會非常差;
修改、洗掉資料
??在LSM Tree的SSTabe中資料是不可修改的,也就是不可修改、洗掉;此處的修改資料并不是傳統意義上的找到某條記錄并修改它,只是追加一條新的資料記錄當讀取資料是自然會只讀到新資料從而忽略掉老的資料;洗掉資料同理,其洗掉邏輯為:追加一條資料其值為墓碑,就替換掉了老資料;當SSTable執行合并資料邏輯時,這些“洗掉”、“修改”的資料將會被真正的洗掉掉;
性能優化
??這時可使用布隆過濾器(bloom filter)進行優化,寫入資料之前在布隆過濾器中標記,在讀取時可斷定某條資料是否存在,布隆過濾器有假陽性的概率,但其認為一條資料沒出現過,那該資料一定沒出現過,其認為一條資料出現過,那么該資料很有可能出現過;
檔案合并(Compaction)
??系統運行越久SSTable的segment資料會越多,讀取時的IO次數越多,性能會降低,此時需要控制segment的數量;LSM Tree會定期執行segment合并操作,將多個segment合并為一個大的segment,清理舊segment,由于segment的有序特性,使用并歸排序就能快速的對資料進行合并,時間復雜度接近O(n);
memtable持久化
??為避免memtable有序樹資料還未持久化為SSTable檔案時系統就崩潰,可在將資料寫入到memtable時同時將資料寫入到WAL日志中,當程式崩潰時可通過此檔案恢復資料;持久化SSTable時需要對memtable與WAL日志做統一的清空處理;
LSM Tree基本流程
??1、寫資料:將資料快取到記憶體有序樹結構中(memtable),以此同時更新稀疏索引、布隆過濾器;
??2、memtable達到預設的閾值,將該有序樹資料flush刷盤到磁盤中,生成有序資料檔案segment,此檔案為immutable性質,不可修改;
??3、讀取資料時,如存在布隆過濾器,先用其驗證如不存在資料就不存在,否則先從mentable有序樹中查找資料如找到資料,依次從新到老順序查詢每個segment,查詢segment使用二分查找對應稀疏索引,知道對應資料offset范圍,讀取磁盤范圍內資料,再次二分查找獲取資料;
??4、LSM Tree定期執行compaction操作,將多個segment檔案合并為更大的檔案;
參考資料:
Log Structured Merge Trees - ben stopford
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/373793.html
標籤:其他
上一篇:A與B的對話之線索二叉樹
下一篇:【影片筆記】二分查找(折半查找)