進入大二以來一直把學資料結構和演算法這事藏在心里,畢竟大學破事太多了,最近實在是按捺不住了,拿起《演算法圖解》,結合網路上的總結,準備循序漸進入門資料結構和演算法...
目前筆記里代碼示例我都是用的Python語言(正好學校在教,趁熱打鐵),日后打C/C++基礎后我應該會回來再增加示例,

二分查找的前提
- 查找的資料目標需要是有順序的儲存結構,比如Python中的串列
list, - 這個資料目標還需要按一個順序排列(升序or降序),
寫寫練練
Don't try to understand it.Feel it.
廢話不多說了,關于二分查找,我最開始寫了個錯誤的玩意:
# 錯誤寫法例子
my_list = [1, 3, 4, 5, 8, 16, 24, 56, 78]
def find(from_list, which_one):
start = 0
end = len(from_list)-1
while start < end:
middle_ind = (start+end)//2
middle = from_list[middle_ind]
print(start, end)
if middle == which_one:
return middle_ind
elif middle > which_one:
end = middle_ind # 搜索范圍尾部前移
elif middle < which_one:
start = middle_ind # 搜索范圍頭部后移
return False
found_ind = find(my_list, 78)
print(found_ind)
這個例子的問題體現在兩個方面:
-
一旦尋找的是順序儲存結構中沒有的值,會卡在回圈里,
-
一旦尋找的是末尾的邊緣值,也會卡在回圈里,
-
無論是奇數個資料還是偶數個資料都有這個問題,
從輸出能看到原因:start和end滿足不了end == start的條件,到最后兩值會永遠差1,
我試著用影片展示一下這個有問題的執行程序:
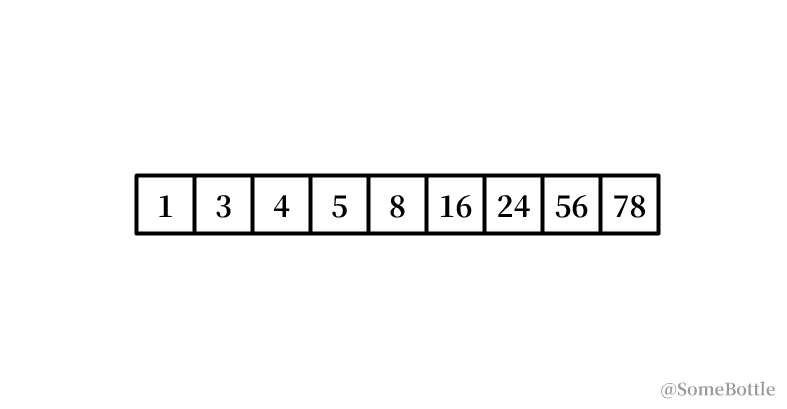
到最后死回圈的時候因為我們將中間值采用了向下取整,導致當start指向倒數第二個索引時卡死在start=7,
通過觀察,咱發現每次卡死的時候 start和end永遠會相差 1,

很明顯了,問題就出現在 每次查找后對start和end的處理 上,就上面這個有問題的代碼而言,其實每次搜索后 如果中間項 < 搜索專案,進行start=middle_ind+1的操作就可以,列個表格:
- 搜尋的值:
78
| 搜尋范圍 (start,end) | middle_ind (中間項的索引) | start=middle_ind+1 | end | 回圈繼續 |
|---|---|---|---|---|
| (0,8) | 4 | 5 | 8 | 是 |
| (5,8) | 6 (向下取整) | 7 | 8 | 是 |
| (7,8) | 7 (向下取整) | 8 | 8 | 否 |
↑ 這樣的話就能順利達到查找回圈的終止條件start=end了
我的理解:在本次搜索中我們已經檢查了middle_ind對應的專案,下一次搜索范圍的開始(start)就應該從這一項的下一位開始,也就是middle_ind+1,

但是吧,上面我們找的是末尾的值78,如果找的是開頭的值 1 呢?
照葫蘆畫瓢唄~依照上面的思路,每次搜索后的下一次搜索就應該從這一項的前一位了,也就是middle_ind-1,(上面影片中能直觀看出來范圍下限索引start是趨于增大的,反之范圍上限索引end值就是趨于減小的),再列個表:
- 搜尋的值:
1
| 搜尋范圍 (start,end) | middle_ind (中間項的索引) | start | end=middle_ind-1 | 回圈繼續 |
|---|---|---|---|---|
| (0,8) | 4 | 0 | 3 | 是 |
| (0,3) | 1 (向下取整) | 0 | 0 | 否 |
方便直觀對照,我放個靜態圖在這里:

在尋找既不是開頭也不是末尾的值時,搜索程序中往往會交替有start和end的增和減,所以在二分查找程式中關鍵部分就要兼顧上述兩種處理:
if middle == which_one:
return middle_ind
elif middle > which_one:
end = middle_ind-1 # 搜索范圍尾部前移,注意是middle_ind-1
elif middle < which_one:
start = middle_ind+1 # 搜索范圍頭部后移,注意是middle_ind+1
(這也是為什么之前尋找串列中沒有的值時會卡在回圈里)
經過這些處理后,咱成功彌補了這個問題,

等等...在搜索串列中開頭或末尾的值時回圈在start=end后就停止了...程式仍然無法搜索到開頭或末尾的值,而是回傳了False!
通過觀察發現,其實只要再執行一次回圈,問題就完美解決了:把回圈條件start < end 換成 start <= end (start等于end時繼續回圈一次)
最后寫成的二分查找代碼如下:
def find(from_list, which_one):
start = 0 # 開始的索引
end = len(from_list)-1 # 結尾的索引
while start <= end: # 當范圍沒有縮減至start>end時,不停二分查找(易錯點:為什么用<=?因為當start=end的時候會遺漏一個處理項)
middle_ind = (start+end)//2 # 找到二分中間專案的索引,這里向下取整(floordiv)
middle = from_list[middle_ind] # 獲得中間項
if middle == which_one: # 找到了,回傳對應的索引
return middle_ind # 找到就停車跑路
elif middle > which_one: # 要尋找的值小于中間值
end = middle_ind-1 # 將范圍尾部索引減小到中間值索引-1(易錯點)
elif middle < which_one: # 要尋找的值大于中間值
start = middle_ind+1 # 將范圍頭部索引start增大到中間值索引+1(易錯點)
return False # 啥都沒找到
最后咱基于上面的寫法整了幾個影片:
-
尋找串列最開頭的值:
my_list = [1, 3, 4, 5, 8, 16, 24, 56, 78] found_ind = find(my_list, 1) # 0
-
尋找串列中間的一個值:
my_list = [1, 3, 4, 5, 8, 16, 24, 56, 78] found_ind = find(my_list, 16) # 5
-
尋找一個找不到的值:
my_list = [1, 3, 4, 5, 8, 16, 24, 56, 78] found_ind = find(my_list, 6) # False
時間復雜度
通過大O表示法咱可以寫成 O(f(n)) 這樣,其中:
n是操作的資料的規模,f(n)是操作的次數(程式執行的次數),- 大O的量和
f(n)成正比(這是不是說明看O其實就可以粗略地看f(n)?),

上面例子的串列中有9個元素,資料規模 n=9,這些例子中除了卡死回圈的情況外,我發現程式 最多 執行檢查4次,而不是9次——
——因為每次執行操作后會將搜索范圍折半,也就是每次操作后資料規模會成半縮減:
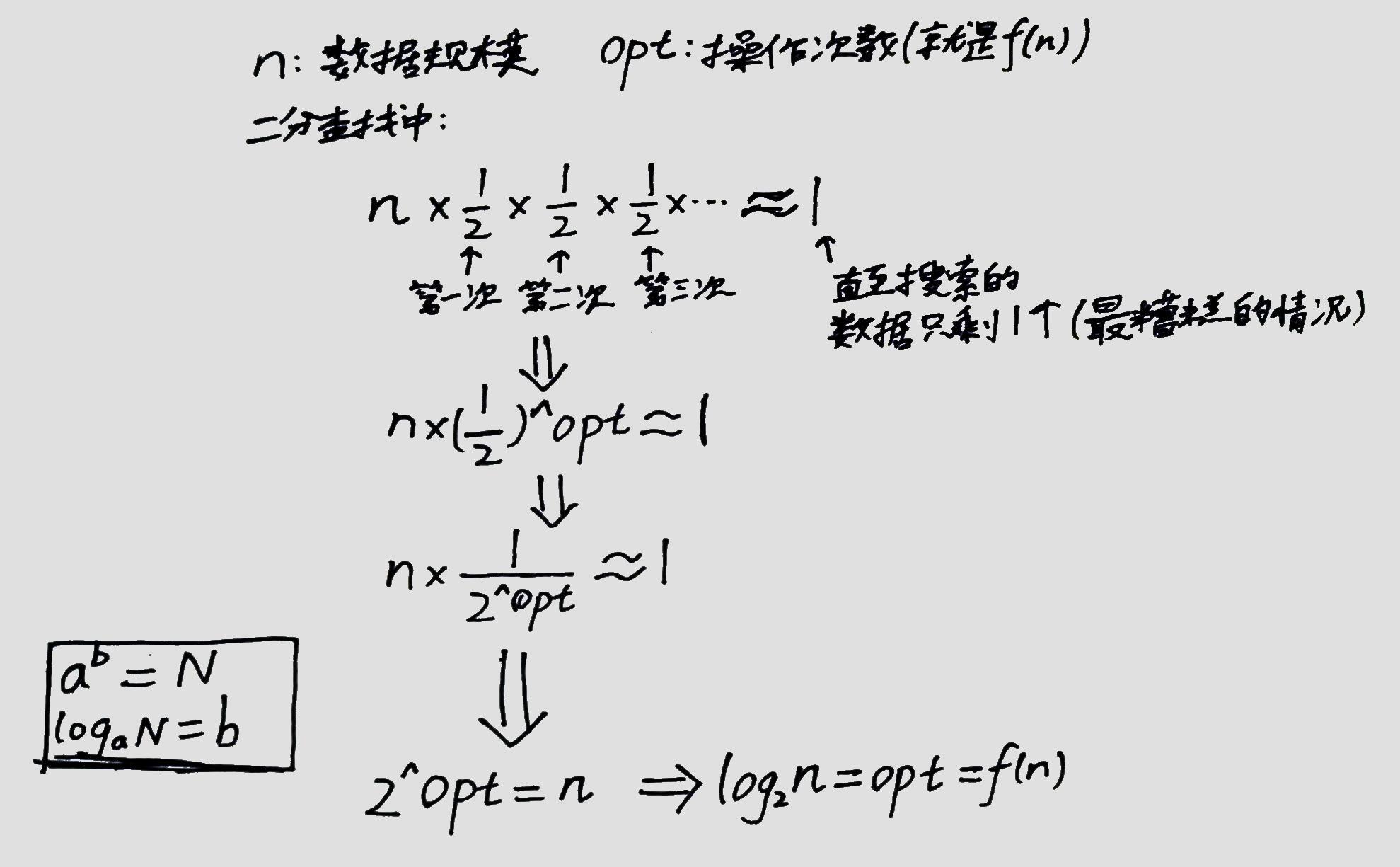
(字丑勿cue ┑( ̄Д  ̄)┍)
所以二分查找的時間復雜度表示為 O(log2n),
為什么說到“最多”這個詞呢?因為大O時間體現的是最不理想情況下的運行時間,也就是該演算法的時間復雜度的上界,
更多的寫法
這篇筆記里的二分查找寫法只是所有寫法中的一種,我認為掌握一個演算法并不是要對每種寫法都了如指掌,而是要去理解其中的原理,
這里貼個知乎問題貼:
- https://www.zhihu.com/question/36132386/answer/155438728
注意這個鏈接里的回答說 median = ( low + high ) / 2 寫法會溢位是 C/C++ 里的一個小坑,
該筆記于Github倉庫撰寫: https://github.com/cat-note/bottleofcat/blob/main/Algo/BinarySearch.md
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/373794.html
標籤:其他
上一篇:LSM-Tree:原理與介紹
下一篇:Python編程環境設定