【Pytorch】
? vgg
官網vgg學習傳送門
vgg特點
堆疊多個3 * 3 卷積核來替代大尺度卷積核 (減少所需的引數)
并且,論文中提出 堆疊 2個 3 * 3 卷積核 可以代替 5 * 5 的卷積核, 3個 3 * 3 卷積核 可代替 7 * 7
說明
我們假設 輸入輸出的channel數為C :
對于 7 * 7 的卷積核來說,它所需要的引數為:
7 * 7 * C * C = 49C^2
而對于1個 3 * 3 的卷積核來說, 需要的引數為:
3 * 3 * C * C = 9C^2
3個即為:
27C^2<49C^2
很顯然,所需的引數大大減少!
注意,這邊的代替是指 他們具有相同的感受野,
補充
感受野: 卷積神經網路每層輸出的特征圖上的一個點映射到輸入圖片的一塊區域,
計算:從最后一層開始向上算,
F(i) = (F(i+1) - 1) * Stride + Ksize
F(i): 第i層的感受野Stride: 第i層的步距Ksize:卷積核或采樣核的個數
詳情可參考這里
vgg模型決議
下圖是 vgg模型圖
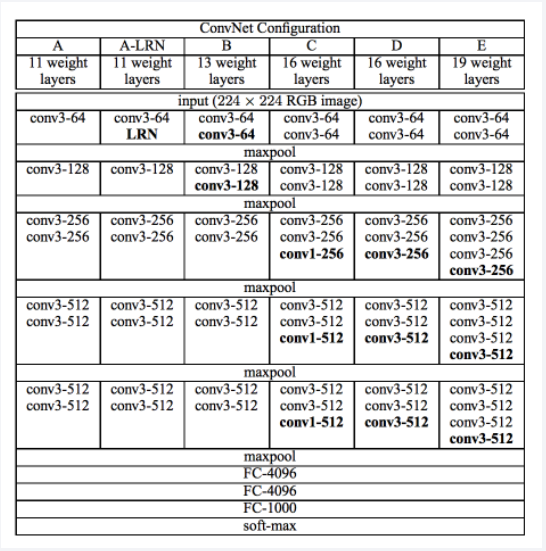
以 vgg16 為例
首先輸入是一張 224 * 224 的RGB三通道圖片, 經過 兩層 3 * 3 卷積層 --> 最大池化 --> 三層 3 * 3 卷積層 --> 最大池化 --> 三層 3 * 3 卷積層 --> 最大池化 --> 3 * 3 卷積層 --> 最大池化 --> 三個全連接層 --> softmax
這里卷積層的stride = 1, padding = 1
最大池化 kernel_size = 2,stride = 2

pytorch 實作 vgg搭建
# @Time : 2021/11/15
# @Author: J1ay
# @File : vgg_model.py
import torch
from torch import nn
# vgg后面都是經過三個全連接層以及soft-max函式
# 采用前面引數區分,后面統一構建
class VGG(nn.Module):
def __init__(self, features, class_num=1000, init_weight=False):
super(VGG, self).__init__()
self.features = features
# 全連接
self.classifier = nn.Sequential(
nn.Dropout(), # 減小過擬合,50%失活神經元
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Linear(4096, class_num)
)
if init_weight:
self._initialize_weights()
def forward(self, x):
# 前面模型搭建
x = self.features(x)
# 展平操作
# N * 512 * 7 * 7
x = torch.flatten(x, start_dim=1)
# 全連接
x = self.classifier(x)
return x
# 初始化權重函式
def _initialize_weights(self):
for m in self.modules:
# 若是卷積層,則利用xavier進行初始化
if isinstance(m, nn.Conv2d):
nn.init.xavier_uniform_(m.weight)
# 若使用偏置
if m.bias is not None:
nn.init.constant_(m.bias, 0) # 將偏置置為0
# 若是全連接層
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
# 以串列形式記錄vgg各個模型的引數
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M']
}
# 構建前半部分模型
def make_feature(cfgs):
layers = []
in_channels = 3 # 最初輸入cannel為3
for v in cfgs:
# 最大池化
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels=in_channels, out_channels=v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(inplace=True)] # 采用ReLu激活函式
in_channels = v # 卷積后,卷積層輸入channel變成上一層的channel
# torch.nn.Sequential(* args) 按順序添加到容器
return nn.Sequential(*layers)
# 實體化vgg
def vgg(model_name="vgg16", **kwargs):
try:
cfg = cfgs[model_name]
except:
print("Warning: Model {} not in cfs dict!".format(model_name))
exit(-1)
model = VGG(make_feature(cfg), **kwargs)
return model
if __name__ == '__main__':
# 默認是vgg16,可修改model名字
vgg_model = vgg(model_name="vgg13")
print(vgg_model)
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/373826.html
標籤:其他