目錄
前言
環境部署
專案使用
景色類影像使用
人像類影像使用
總結
前言
之前看到一個有意思的開源專案,主要是可以將一張照片變成卡通漫畫的風格,下面給大家放幾張官方給出的部分效果圖,


看到這個效果圖,還是非常經驗的,下面我會分享一下這個專案,并且選擇一些我自己找的圖片試驗一下,
專案Github地址:github地址
環境部署
先使用git將專案下載下來,看一下專案結構,
我們看一下需要的環境,
非常簡單,只要pytorch就可以了,如果有不太會安裝的,可以參考我的另一篇文章:機器學習基礎環境部署 | 機器學習系列_阿良的博客-CSDN博客
專案使用
看一下readme怎么說明的,
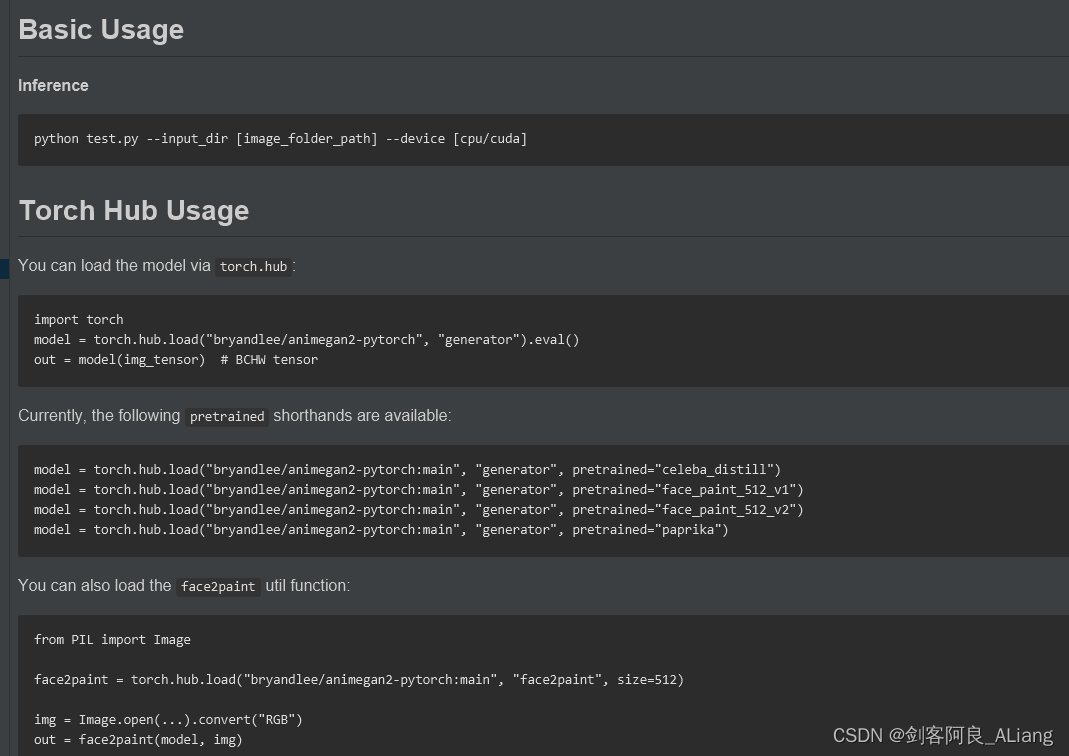
直接使用命令,或者代碼執行都可以,我們先看看如果命令操作的話都有哪些引數支持,
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument(
'--checkpoint',
type=str,
default='./weights/paprika.pt',
)
parser.add_argument(
'--input_dir',
type=str,
default='./samples/inputs',
)
parser.add_argument(
'--output_dir',
type=str,
default='./samples/results',
)
parser.add_argument(
'--device',
type=str,
default='cuda:0',
)
parser.add_argument(
'--upsample_align',
type=bool,
default=False,
help="Align corners in decoder upsampling layers"
)
parser.add_argument(
'--x32',
action="store_true",
help="Resize images to multiple of 32"
)
args = parser.parse_args()
test(args)可以通過專案結構看到,作者提供了4個模型檔案可供選擇,可以用--checkpoint引數切換,需要提供圖片的輸入檔案夾,修改--input_dir引數即可,經過我自己的幾次驗證,發現有的模型適合風景型別的圖片,有的適合人像,下面我分成兩部使用一下,
景色類影像使用
先看一下我準備的圖片,三張風景的照片,



我使用個人認為比較好用的模型是paprika.pt,下面是執行程序,

看看效果



哦,第一張圖的漫畫效果有所欠缺,但是后面兩張還是不錯的,沒有細品一波演算法,猜測一下,可能是顏色區域較多,對比度越明顯,可能漫畫后的效果會更好,
人像類影像使用
最主要的還是人像,懂的都懂,下面是我準備的圖片,



打算使用face_paint_512_v2.pt模型測驗一下,下面直接展示處理后的效果,



效果還是很好的,是不是,
總結
我反復測驗了不少圖片,有的轉化的并不是很好,但是大部分還是不錯的,瑕不掩瑜,專案還是好專案,只是可能模型本身訓練的資料不是非常全面吧,還是老樣子,這兩天我改改這個專案玩一玩,
分享:
對自己有自信時,不能對人說「期待」,所謂的「期待」是放棄時的托詞,因為別無選擇,若缺少這種無奈感,說這個詞就太虛偽了,——《冰菓》
如果本文對你有用的話,請給我點個贊吧,謝謝!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/374533.html
標籤:AI
上一篇:------針---------- 對-------- 圖------------- 考--------- 試
下一篇:GitHub 披露宕機原因;谷歌前 AI 研究員被解雇后成立獨立研究所;常用 Linux 桌面版排行榜出爐 | 開源日報