文章目錄
- Hadoop大資料技術課程總結
- 1.大資料概述
- 1.1大資料時代的4V
- 1.2大資料時代的三次浪潮
- 1.3大資料時代的技術支撐
- 1.4谷歌的3篇論文
- 1.5Hadoop集群規模
- 1.6Hadoop安裝程序
- 2.HDFS專題
- 2.1 HDFS簡介及作用
- 2.2 HDFS架構
- 2.3HDFS服務角色
- 2.4 HDFS 如何讀取檔案
- 2.5 HDFS 如何寫檔案
- 2.6HDFS 副本存放策略
- 2.7HDFS基本命令
- 3.MapReduce專題
- 3.1.三個層面上的基本構思
- 3.2.一個MapReduce的完整程序
- 3.3.MR的shuffle環節
- 3.4.MR的編程
- 4.Yarn專題
- 4.1.yarn簡介
- 4.2.yarn架構與服務角色
- 4.3.Scheduler調度器
- 4.4.YARN 作業執行流程
- 5.HIVE專題
- 5.1HIVE簡介
- 5.2HIVE如何執行一條HQL陳述句
- 5.3HIVE資料存盤
- 5.4HIVE常用陳述句
- 6.Zookeeper專題
- 6.1 Zookeeper概念
- 6.2 Zookeeper應用場景
- 6.3 Zookeeper原理
- 6.4 Zookeeper實作服務動態上下線通知原理
- 6.5 Zookeeper實作分布式鎖原理
- 6.6 Zookeeper常用命令
- 7 Flume專題
- 7.1Flume簡介
- 7.2 Sources,Channels,Sinks配置
- 7.3 可靠性
- 7.4 可恢復性
- 7.5 Flume組態檔與用法舉例
Hadoop大資料技術課程總結
1.大資料概述
1.1大資料時代的4V
資料量大Volume
第一個特征是資料量大,大資料的起始計量單位可以達到P(1000個T)、E(100萬個T)或Z(10億個T)級別,
型別繁多(Variety)
第二個特征是資料型別繁多,包括網路日志、音頻、視頻、圖片、地理位置資訊等等,多型別的資料對資料的處理能力提出了更高的要求,
價值密度低(Value)
第三個特征是資料價值密度相對較低,如隨著物聯網的廣泛應用,資訊感知無處不在,資訊海量,但價值密度較低,如何通過強大的機器演算法更迅速地完成資料的價值"提純",是大資料時代亟待解決的難題,
速度快、時效高(Velocity)
第四個特征是處理速度快,時效性要求高,這是大資料區分于傳統資料挖掘最顯著的特征,既有的技術架構和路線,已經無法高效處理如此海量的資料,而對于相關組織來說,如果投入巨大采集的資訊無法通過及時處理反饋有效資訊,那將是得不償失的,可以說,大資料時代對人類的資料駕馭能力提出了新的挑戰,也為人們獲得更為深刻、全面的洞察能力提供了前所未有的空間與潛力,
1.2大資料時代的三次浪潮
第一波浪潮
第一波浪潮起源于90年代,當時從計算機到軟體大多還是企業級的,而資料分析就已經開始,這個時代也還是集中式軟體時代,存盤資料的成本也非常昂貴,所以大部分企業以KPI角度,抽取少量結構化資料,采取特定資料,代表企業如MicroStrategy、Microsoft、Oracle,代表產品諸如Sybase、Congos,這個時代能產生的資料有限,能處理資料的能力有限,
第二波浪潮
發展到2000年左右,互聯網的興起,帶動了計算機和軟體從工具型走向消費級,由于互聯網基礎設施的發展,以下三點帶來了資料的爆發式增長,1) 網路帶寬的升級優化,從2g到4g,從撥號上網到光纖入戶,2) 圍繞互聯網資訊化帶來大量的資料產生,如門戶網站,社交平臺,內容和視頻平臺等,3) 科技發展,從PC到移動設備到各種智能設備,都可以采集傳輸資料,資料的存盤成本越來越低,資料的產生速度越來越快,資料量越來越大,第一波浪潮時的技術體系無法滿足需求,并且由于摩爾定律基礎硬體設備和條件也在優化,處理資料的能力越來越強,此時帶來了大資料平臺第二波浪潮的發展:
第三波浪潮
發展到2010左右,互聯網發展從資訊化走向了服務化,創業方向也從之前的“門戶時代”、“社交時代”,“垂直化門戶時代”,“內容視頻時代”走向了電商、 出行、外賣、O2O等本地服務,如果說面向資訊化的時代更多的是基于流量廣告等商業模式,面向服務化時代更多的是直接面對客戶價值的變現商業模式,或者說 消費者服務,所以從行業發展來看,服務類對分析的需求也要旺盛很多,我們可以用破木桶蓄水程序來類比,到處都是水源的時候,并且外部水源流入率大于自身流失率的時候,更多的思考的是抓緊圈水源而不是找短板,從2000年到2014年,流量勢頭猛進,到處都是用戶,對于企業而言更多的思考是如何圈用戶,而不是如何留住用戶并去分析流失原因,當外部沒有更多水源進入并且四處水源有限的時候,我們需要的是盡可能修復木桶,并且找到木桶的短板,在2014到2015年之間,互聯網流量紅利也初現消退 之勢,國內的經濟下行壓力也逐漸增大,就好比水源有限一樣,企業更多的需要分析自身原因了,去提高各種轉化率,增加用戶的忠誠度和黏性,減少用戶的流失, 因此分析需求開始逐步提升,各個業務部門也都需要自我分析優化成本,提高產出和利潤,過去企業更多面臨的是由上而下的KPI中心化式分析,形成了分析中心化體系,基本上整個公司有統一關注的指標和資料看板,但是各業務部門的分析需要單獨處理,資料分析從行業、角色、部門和場景而言,都是差異化的,比如行業上,電商關注的是購買相關指標,內容關注的是閱讀相關指標,社交關注的是參與度相關指標,工 具關注的是功能使用情況,角色上,CEO關注的是整體、財務各部門的KPI;市場VP關注的是營銷相關的子專案KPI;銷售VP關注的是銷售階段狀態和結果相關的指標;如部門上,市場關注的是投放轉化率等指標;產品關注的是功能留存率等指標,如果要更充分的滿足分析需求,需要從KPI中心化分析轉向分析去 中心化,也就面臨著又一次大資料平臺的技術革新,也因此推動了大資料平臺第三波浪潮的變革,
1.3大資料時代的技術支撐
虛擬化和云計算技術
美國國家標準技術研究所認為,云計算是通過網路使得一組可配置的計算資源(例如網 絡、計算機、存盤、應用程式、服務等)能夠在任何地點進行訪問的模型,資源的提供和 釋放可以快速完成,管理開銷低,與提供商的互動簡便易行,
云計算的關鍵技術有三大點:⑴虛擬化技術:云計算的虛擬化技術不同于傳統的單一虛擬化,它是涵蓋整個IT架構的,包括資 源、網路、應用和桌面在內的全系統虛擬化,⑵分布式資源管理技術:資訊系統仿真系統在大多數情況下會處在多節點并發執行環境中,要保證 系統狀態的正確性,必須保證分布資料的一致性,⑶并行編程技術:云計算采用并行編程模式,在并行編程模式下,并發處理、容錯、資料分布、負 載均衡等細節都被抽象到一個函式庫中,通過統一介面,用戶大尺度的計算任務被自動并發和分布 執行,即將一個任務自動分成多個子任務,并行地處理海量資料,
基于分布式的Hadoop生態系統
分布式計算的產生:單臺計算機的能力是有限的,而需要處理的問題規模在不斷地增長,為此,人們開始探索用多臺計 算機組成一個系統進行協同處理,因此遇到很多新問題: 網路帶寬有限 當部分機器出現故障時,我們希望多機系統作為一個整體還能正常作業用戶撰寫的程式要同時在不同的機器上運行,還要確保能夠容易使用分布式計算就是為了解決這些問題而出現的,Hadoop生態系統:主流的開源分布式大資料處理軟體,主要用Java語言撰寫,具有較好的平臺移植性,關于Hadoop有幾個概念需要理解清楚: HDFS 是Hadoop的分布式檔案系統 MapReduce是Hadoop的一代計算資源管理和調度系統,YARN是Hadoop的二代計算資源管理和調度系統,接受任務請求,并根據請求的需要來分配 資源,調度任務的執行,除了可以執行MapReduce外,還可以執行MPI等傳統并行程式,HBase是一個開源的非關系型分布式資料庫(NoSQL),它參考了谷歌的BigTable建模,實 現的編程語言為 Java,它是Hadoop專案的一部分,運行于HDFS檔案系統之上,Hive和Pig能讓用戶用較為簡便的方式來查詢保存在HDFS或HBase中的資料, Mahout是用Hadoop實作的機器學習演算法庫,包括聚類、分類、推薦,以及線性代數中的一 些常用演算法, Spark是比MapReduce更豐富靈活的計算框架,由Scala語言撰寫,設計核心是一種叫做可靠 分布式資料集,
NoSQL
NoSQL資料庫比SQL更滿足Web應用對資料規模和讀寫性能的要求, 常見的NoSQL資料庫大致可分為以下幾類:基于列的存盤,例如HBase、Cassandra等等 基于檔案的存盤,例如MongoDB、CouchDB等 鍵值對存盤,分三種型別:
1.4谷歌的3篇論文
GFS :分布式檔案系統
MapReduce :分布式計算引擎
BigTable :分布式列族資料庫
1.5Hadoop集群規模
注意:本部分資料來源于網路,資料時間較久,但也足以說明問題,
1.百度
百度在2006年就開始關注Hadoop并開始調研和使用,在2012年其總的集群規模達到近十個,單集群超過2800臺機器節點,Hadoop機器總數有上萬臺機器,總的存盤容量超過100PB,已經使用的超過74PB,每天提交的作業數目有數千個之多,每天的輸入資料量已經超過7500TB,輸出超過1700TB,
百度的Hadoop集群為整個公司的資料團隊、大搜索團隊、社區產品團隊、廣告團隊,以及LBS團體提供統一的計算和存盤服務,主要應用包括:
資料挖掘與分析
日志分析平臺
資料倉庫系統
推薦引擎系統
用戶行為分析系統
同時百度在Hadoop的基礎上還開發了自己的日志分析平臺、資料倉庫系統,以及統一的C++編程介面,并對Hadoop進行深度改造,開發了HadoopC++擴展HCE系統,
2.阿里巴巴(舊的資料,現在已轉而使用阿里云了)
阿里巴巴的Hadoop集群截至2012年大約有3200臺服務器,大約30?000物理CPU核心,總記憶體100TB,總的存盤容量超過60PB,每天的作業數目超過150?000個,每天hivequery查詢大于6000個,每天掃描資料量約為7.5PB,每天掃描檔案數約為4億,存盤利用率大約為80%,CPU利用率平均為65%,峰值可以達到80%,阿里巴巴的Hadoop集群擁有150個用戶組、4500個集群用戶,為淘寶、天貓、一淘、聚劃算、CBU、支付寶提供底層的基礎計算和存盤服務,主要應用包括:
資料平臺系統
搜索支撐
廣告系統
資料魔方
量子統計
淘資料
推薦引擎系統
搜索排行榜
為了便于開發,其還開發了WebIDE繼承開發環境,使用的相關系統包括:Hive、Pig、Mahout、Hbase等,
3.騰訊
騰訊也是使用Hadoop最早的中國互聯網公司之一,截至2012年年底,騰訊的Hadoop集群機器總量超過5000臺,最大單集群約為2000個節點,并利用Hadoop-Hive構建了自己的資料倉庫系統TDW,同時還開發了自己的TDW-IDE基礎開發環境,騰訊的Hadoop為騰訊各個產品線提供基礎云計算和云存盤服務,其支持以下產品:
騰訊社交廣告平臺,
搜搜(SOSO),
拍拍網,
騰訊微博,
騰訊羅盤,
QQ會員,
騰訊游戲支撐,
QQ空間,
朋友網,
騰訊開放平臺,
財付通,
手機QQ,
QQ音樂,
4.奇虎360
奇虎360主要使用Hadoop-HBase作為其搜索引擎so.com的底層網頁存盤架構系統,360搜索的網頁可到千億記錄,資料量在PB級別,截至2012年年底,其HBase集群規模超過300節點,region個數大于10萬個,使用的平臺版本如下,
HBase版本:facebook0.89-fb,
HDFS版本:facebookHadoop-20,
奇虎360在Hadoop-HBase方面的作業主要為了優化減少HBase集群的啟停時間,并優化減少RS例外退出后的恢復時間,
5.華為
華為公司也是Hadoop主要做出貢獻的公司之一,排在Google和Cisco的前面,華為對Hadoop的HA方案,以及HBase領域有深入研究,并已經向業界推出了自己的基于Hadoop的大資料解決方案,
6.中國移動
中國移動于2010年5月正式推出大云BigCloud1.0,集群節點達到了1024,中國移動的大云基于Hadoop的MapReduce實作了分布式計算,并利用了HDFS來實作分布式存盤,并開發了基于Hadoop的資料倉庫系統HugeTable,并行資料挖掘工具集BC-PDM,以及并行資料抽取轉化BC-ETL,物件存盤系統BC-ONestd等系統,并開源了自己的BC-Hadoop版本,
中國移動主要在電信領域應用Hadoop,其規劃的應用領域包括:
經分KPI集中運算,
經分系統ETL/DM,
結算系統,
信令系統,
云計算資源池系統,
物聯網應用系統,
E-mail,
IDC服務等,
7.Facebook
Facebook使用Hadoop存盤內部日志與多維資料,并以此作為報告、分析和機器學習的資料源,目前Hadoop集群的機器節點超過1400臺,共計11200個核心CPU,超過15PB原始存盤容量,每個商用機器節點配置了8核CPU,12TB資料存盤,主要使用StreamingAPI和JavaAPI編程介面,Facebook同時在Hadoop基礎上建立了一個名為Hive的高級資料倉庫框架,Hive已經正式成為基于Hadoop的Apache一級專案,此外,還開發了HDFS上的FUSE實作,
1.6Hadoop安裝程序
1)安裝centos7或ubuntu16.04系統
2)修改 IP
3)修改 host 主機名
4)配置 SSH 免密碼登錄
5)關閉防火墻
6)安裝 JDK
7)解壓 hadoop 安裝包
8)配置 hadoop 的核心檔案 hadoop-env.sh,core-site.xml,mapred-site.xml,hdfs-site.xml
9)配置 hadoop 環境變數
10)格式化 hadoop namenode-format
11)啟動節點 start-all.sh
2.HDFS專題
參考:
https://blog.csdn.net/weixin_38750084/article/details/82963235
https://www.cnblogs.com/codeOfLife/p/5375120.html
2.1 HDFS簡介及作用
HDFS(Hadoop Distributed File System,Hadoop分布式檔案系統),它是一個高度容錯性的系統,適合部署在廉價的機器上,HDFS能提供高吞吐量的資料訪問,適合那些有著超大資料集(large data set)的應用程式,
HDFS的設計特點是:
1、大資料檔案,非常適合上T級別的大檔案或者一堆大資料檔案的存盤,如果檔案只有幾個G甚至更小就沒啥意思了,
2、檔案分塊存盤,HDFS會將一個完整的大檔案平均分塊存盤到不同計算器上,它的意義在于讀取檔案時可以同時從多個主機取不同區塊的檔案,多主機讀取比單主機讀取效率要高得多得多,
3、流式資料訪問,一次寫入多次讀寫,這種模式跟傳統檔案不同,它不支持動態改變檔案內容,而是要求讓檔案一次寫入就不做變化,要變化也只能在檔案末添加內容,
4、廉價硬體,HDFS可以應用在普通PC機上,這種機制能夠讓給一些公司用幾十臺廉價的計算機就可以撐起一個大資料集群,
5、硬體故障,HDFS認為所有計算機都可能會出問題,為了防止某個主機失效讀取不到該主機的塊檔案,它將同一個檔案塊副本分配到其它某幾個主機上,如果其中一臺主機失效,可以迅速找另一塊副本取檔案,
重要特性:
1.HDFS中的檔案在物理上是分塊存盤(block),塊的大小可以通過配置引數( dfs.blocksize)來規定,默認大小在hadoop2.x版本中是128M,老版本中是64M
2.HDFS檔案系統會給客戶端提供一個統一的抽象目錄樹,客戶端通過路徑來訪問檔案
3.目錄結構及檔案分塊資訊(元資料)的管理由namenode節點承擔——namenode是HDFS集群主節點,負責維護整個hdfs檔案系統的目錄樹,以及每一個路徑(檔案)所對應的block塊資訊(block的id,及所在的datanode服務器)
4.檔案的各個block的存盤管理由datanode節點承擔----datanode是HDFS集群從節點,每一個block都可以在多個datanode上存盤多個副本(副本數量也可以通過引數設定dfs.replication)
5.HDFS是設計成適應一次寫入,多次讀出的場景,且不支持檔案的修改
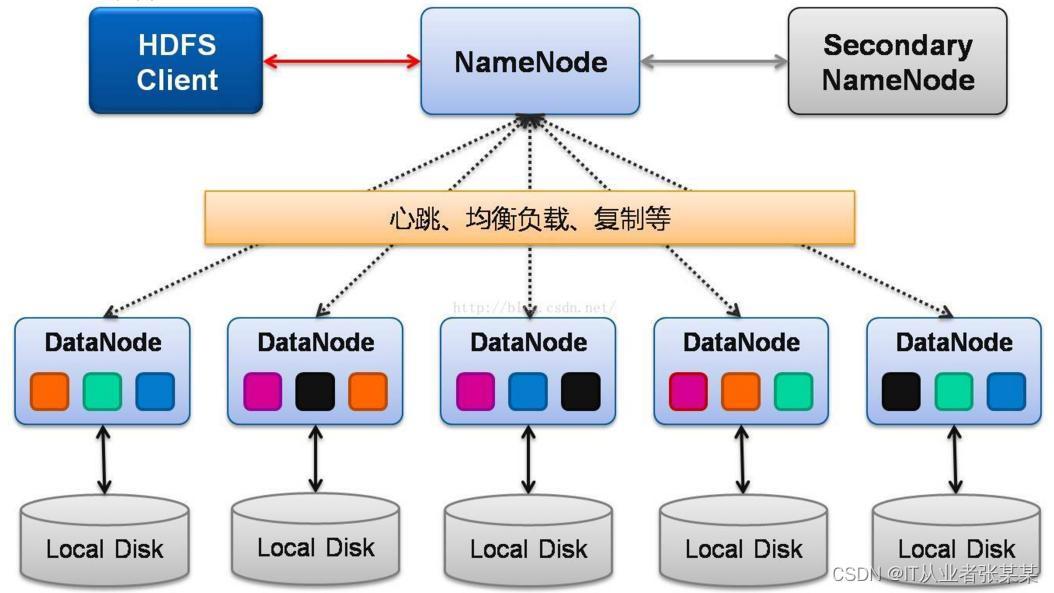
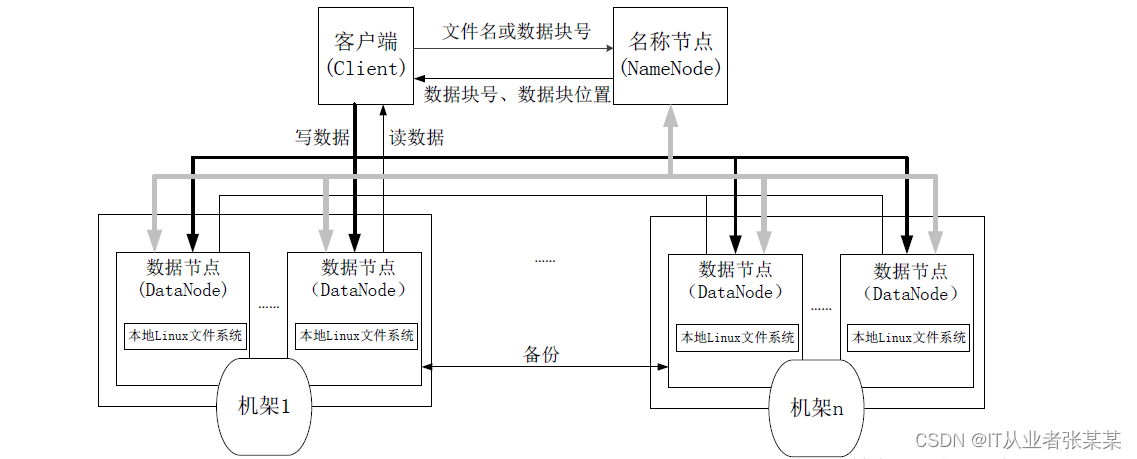
2.2 HDFS架構
先放上2張圖:
2.3HDFS服務角色
Namenode
namenode又稱為名稱節點,是負責管理分布式檔案系統的命名空間(Namespace),保存了兩個核心的資料結構,即FsImage和EditLog, 你可以把它理解成大管家,它不負責存盤具體的資料,
FsImage用于維護檔案系統樹以及檔案樹中所有的檔案和檔案夾的元資料
操作日志檔案EditLog中記錄了所有針對檔案的創建、洗掉、重命名等操作
注意,這個兩個都是檔案,也會加載決議到記憶體中,
為啥會拆成兩個呢? 主要是因為fsimage這個檔案會很大的,多了之后就不好操作了,就拆分成兩個,把后續增量的修改放到EditLog中, 一個FsImage和一個Editlog 進行合并會得到一個新的FsImage.FsImage就相當于你系統的引導區,如果FsImage壞了,那檔案系統就崩潰了, 所以,這個重要的東西,需要備份,備份的功能就交給SecondaryNameNode實作
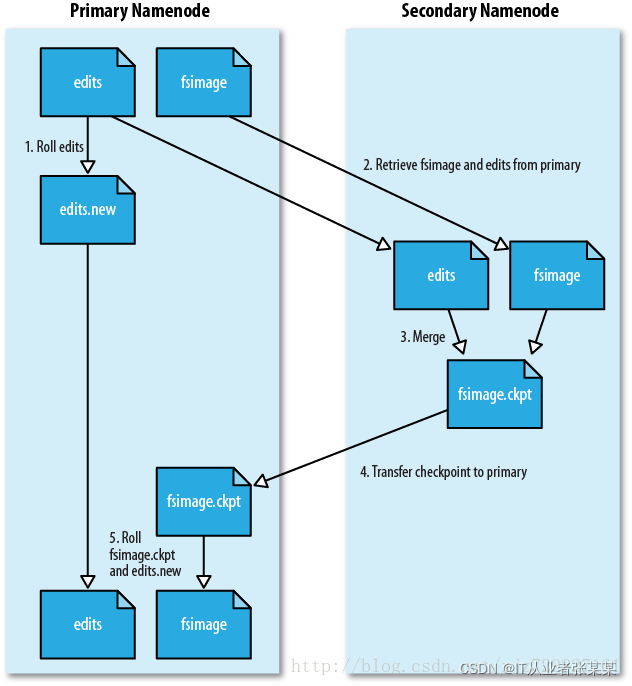
SecondaryNameNode
SecondaryNameNode作業程序
- SecondaryNameNode會定期和NameNode通信,請求其停止使用EditLog檔案,暫時將新的寫操作寫到一個新的檔案edit.new上來,這個操作是瞬間完成,上層寫日志的函式完全感覺不到差別;
- SecondaryNameNode通過HTTP GET方式從NameNode上獲取到FsImage和EditLog檔案,并下載到本地的相應目錄下;
- SecondaryNameNode將下載下來的FsImage載入到記憶體,然后一條一條地執行EditLog檔案中的各項更新操作,使得記憶體中的FsImage保持最新;這個程序就是EditLog和FsImage檔案合并;
- SecondaryNameNode執行完(3)操作之后,會通過post方式將新的FsImage檔案發送到NameNode節點上
- NameNode將從SecondaryNameNode接收到的新的FsImage替換舊的FsImage檔案,同時將edit.new替換EditLog檔案,通過這個程序EditLog就變小了
 DataNode
DataNode
datanode資料節點,用來具體的存盤檔案,維護了blockId 與 datanode本地檔案的映射, 需要不斷的與namenode節點通信,來告知其自己的資訊,方便nameode來管控整個系統,
這里還提到一個塊的概念,就想linux本地檔案系統中也有塊的概念一樣,這里也有塊的概念,這里的塊會默認是128m 每個塊都會默認儲存三份,
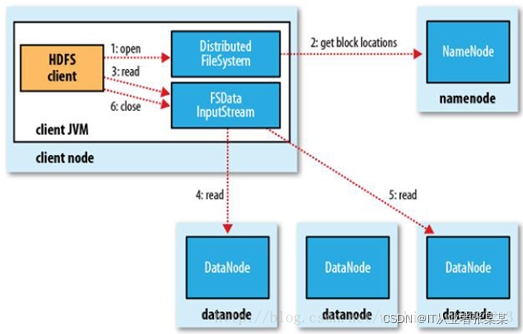
2.4 HDFS 如何讀取檔案
HDFS的檔案讀取原理,主要包括以下幾個步驟:
- 首先呼叫FileSystem物件的open方法,其實獲取的是一個DistributedFileSystem的實體,
- DistributedFileSystem通過RPC(遠程程序呼叫)獲得檔案的第一批block的locations,同一block按照重復數會回傳多個locations,這些locations按照hadoop拓撲結構排序,距離客戶端近的排在前面,
- 前兩步會回傳一個FSDataInputStream物件,該物件會被封裝成 DFSInputStream物件,DFSInputStream可以方便的管理datanode和namenode資料流,客戶端呼叫read方法,DFSInputStream就會找出離客戶端最近的datanode并連接datanode,
- 資料從datanode源源不斷的流向客戶端,
- 如果第一個block塊的資料讀完了,就會關閉指向第一個block塊的datanode連接,接著讀取下一個block塊,這些操作對客戶端來說是透明的,從客戶端的角度來看只是讀一個持續不斷的流,
- 如果第一批block都讀完了,DFSInputStream就會去namenode拿下一批blocks的location,然后繼續讀,如果所有的block塊都讀完,這時就會關閉掉所有的流,
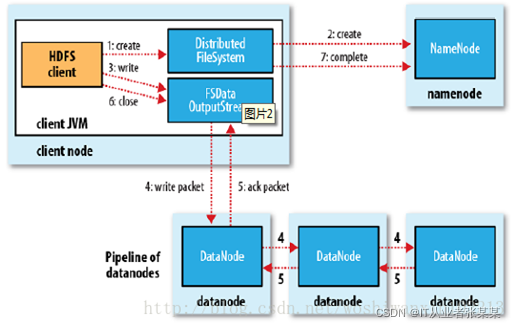
2.5 HDFS 如何寫檔案
HDFS的檔案寫入原理,主要包括以下幾個步驟:
- 客戶端通過呼叫 DistributedFileSystem 的create方法,創建一個新的檔案,
- DistributedFileSystem 通過 RPC(遠程程序呼叫)呼叫 NameNode,去創建一個沒有blocks關聯的新檔案,創建前,NameNode 會做各種校驗,比如檔案是否存在,客戶端有無權限去創建等,如果校驗通過,NameNode 就會記錄下新檔案,否則就會拋出IO例外,
- 前兩步結束后會回傳 FSDataOutputStream 的物件,和讀檔案的時候相似,FSDataOutputStream 被封裝成 DFSOutputStream,DFSOutputStream 可以協調 NameNode和 DataNode,客戶端開始寫資料到DFSOutputStream,DFSOutputStream會把資料切成一個個小packet,然后排成佇列 data queue,
- DataStreamer 會去處理接受 data queue,它先問詢 NameNode 這個新的 block 最適合存盤的在哪幾個DataNode里,比如重復數是3,那么就找到3個最適合的 DataNode,把它們排成一個 pipeline,DataStreamer 把 packet 按佇列輸出到管道的第一個 DataNode 中,第一個 DataNode又把 packet 輸出到第二個 DataNode 中,以此類推,
- DFSOutputStream 還有一個佇列叫 ack queue,也是由 packet 組成,等待DataNode的收到回應,當pipeline中的所有DataNode都表示已經收到的時候,這時akc queue才會把對應的packet包移除掉,
- 客戶端完成寫資料后,呼叫close方法關閉寫入流,
- DataStreamer 把剩余的包都刷到 pipeline 里,然后等待 ack 資訊,收到最后一個 ack 后,通知 DataNode 把檔案標示為已完成,
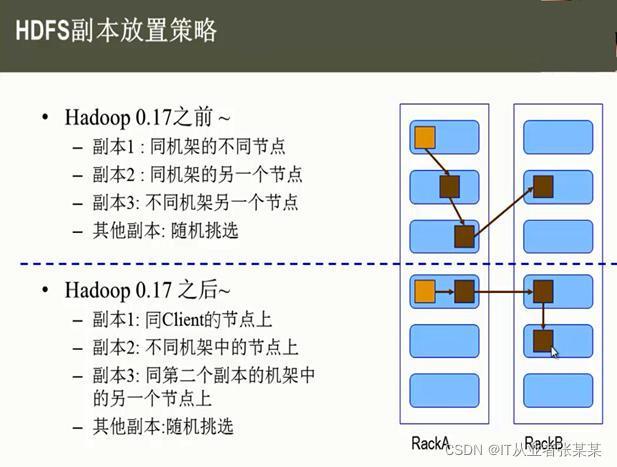
2.6HDFS 副本存放策略
namenode如何選擇在哪個datanode 存盤副本(replication)?
這里需要對可靠性、寫入帶寬和讀取帶寬進行權衡,Hadoop對datanode存盤副本有自己的副本策略,在其發展程序中一共有兩個版本的副本策略,分別如下所示
2.7HDFS基本命令
查看檔案常用命令
hdfs dfs -ls path #查看檔案串列
hdfs dfs -ls -R path #遞回查看檔案串列
hdfs dfs -du path #查看path下的磁盤情況,單位位元組
創建檔案夾
hdfs dfs -mkdir path
創建檔案
hdfs dfs -touchz path
hdfs dfs -touchz /user/iron/iron.txt #該命令不可遞回創建檔案,即當該檔案的上級目錄不存在時無法創建該檔案,如果重復創建會覆寫原有的內容
復制檔案和目錄
hdfs dfs -cp 源目錄 目標目錄
hdfs dfs -cp /user/iron /user/iron01 #該命令會將源目錄的整個目錄結構都復制到目標目錄中
hdfs dfs -cp /user/iron/* /user/iron01 #該命令只會將源目錄中的檔案及其檔案夾都復制到目標目錄中
移動檔案和目錄
hdfs dfs -mv 源目錄 目標目錄
hdfs dfs -mv /user/iron /user/iron01
hdfs dfs -mv /user/aa.txt /user/bb.txt #將/user/aa.txt檔案重命名為/user/bb.txt
賦予權限
hdfs dfs -chmod [權限引數][擁有者][:[組]] path
hdfs dfs -chmod 777 /user/* #該命令是將user目錄下的所用檔案及其檔案夾(不包含子檔案夾中的檔案)賦予最高權限:讀,寫,執行 777表示該用戶,該用戶的同組用戶,其他用戶都具有最高權限
上傳檔案
hdfs dfs -put 源檔案夾 目標檔案夾
hdfs dfs -put /home/hadoop01/iron /user/iron01 #該命令上傳Linux檔案系統中iron整個檔案夾
hdfs dfs -put /home/hadoop01/iron/* /user/iron01 #該命令上傳Linux檔案系統中iron檔案夾中的所有檔案(不包括檔案夾)
下載檔案
hdfs dfs -get 源檔案夾 目標檔案夾
hdfs dfs -get /user/iron01 /home/hadoop01/iron #該命令下載hdfs檔案系統中的iron01整個檔案夾到Linux檔案系統中
hdfs dfs -get /user/iron01/* /home/hadoop01/iron #該命令下載hdfs檔案系統中的iron01整個檔案夾到Linux檔案系統中(不包含檔案夾)
查看檔案內容
hadoop fs -cat path #從頭查看這個檔案
hadoop fs -tail path #從尾部查看最后1K
hadoop fs -cat /userjzl/home/book/aa.txt #查看/userjzl/home/book目錄下檔案aa.txt的內容(將-cat 換成-text效果一樣)
hadoop fs -tail /userjzl/home/book/aa.txt
洗掉檔案
hdfs dfs -rm 目標檔案 #rm不可以洗掉檔案夾
hdfs dfs -rm -R 目標檔案 #遞回洗掉(慎用)
hdfs dfs -rm /user/test.txt #洗掉test.txt檔案
hdfs dfs -rm -R /user/testdir #遞回洗掉testdir檔案夾
3.MapReduce專題
參考:
https://blog.csdn.net/fanxin_i/article/details/80388221
https://www.cnblogs.com/cjsblog/p/8168642.html
https://www.cnblogs.com/cheng5350/p/11872221.html
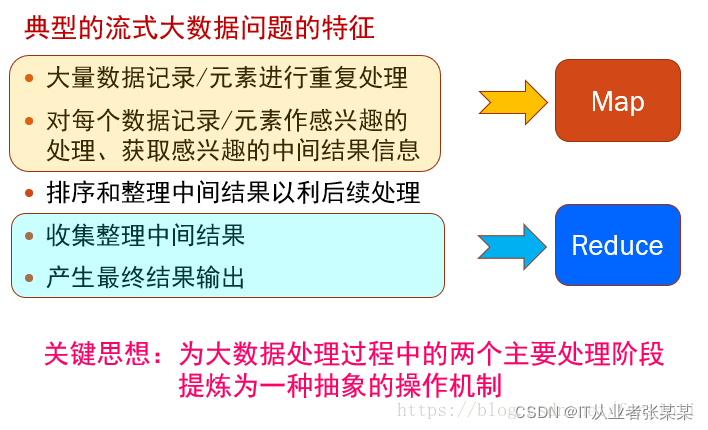
MapReduce的基本模型和處理思想:
3.1.三個層面上的基本構思
1.如果對付大資料處理:分而治之
對相互之間不具有計算依賴關系的大資料,實作并行最自然的辦法就是采取分而治之的策略,
2.上升到抽象模型:Mapper與Reduce
MPI等并行計算方法缺少高層并行編程模型,程式員需要自行指定存盤,計算,分發等任務,為了克服這一缺陷,MapReduce借鑒了Lisp函式式語言中的思想,用Map和Reduce兩個函式提供了高層的并發編程模型抽象,
3.上升到架構:統一架構,為程式員隱藏系統層細節
MPI等并行計算方法缺少統一的計算框架支持,程式員需要考慮資料存盤、劃分、分發、結果收集、錯誤恢復等諸多細節;為此,MapReduce設計并提供了同意的計算框架,為程式員隱藏了絕大多數系統層面的處理系統,
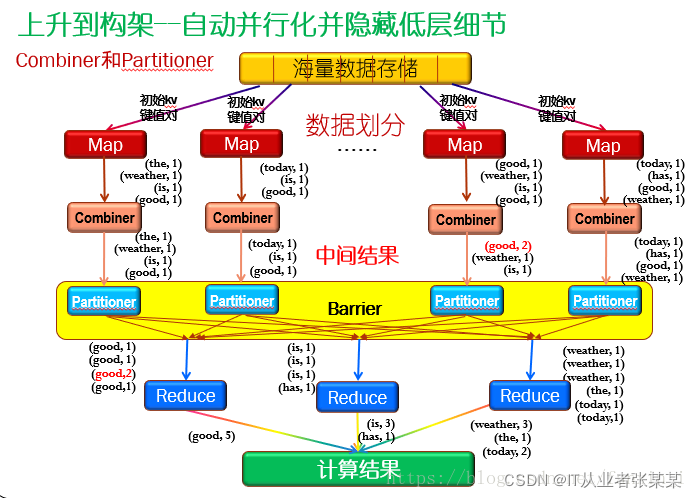
3.2.一個MapReduce的完整程序
在MapReduce整個程序可以概括為以下程序:
輸入 --> map --> shuffle --> reduce -->輸出
輸入檔案會被切分成多個塊,每一塊都有一個map task
map階段的輸出結果會先寫到記憶體緩沖區,然后由緩沖區寫到磁盤上,默認的緩沖區大小是100M,溢位的百分比是0.8,也就是說當緩沖區中達到80M的時候就會往磁盤上寫,如果map計算完成后的中間結果沒有達到80M,最終也是要寫到磁盤上的,因為它最侄訓是要形成檔案,那么,在往磁盤上寫的時候會進行磁區和排序,一個map的輸出可能有多個這個的檔案,這些檔案最侄訓合并成一個,這就是這個map的輸出檔案,
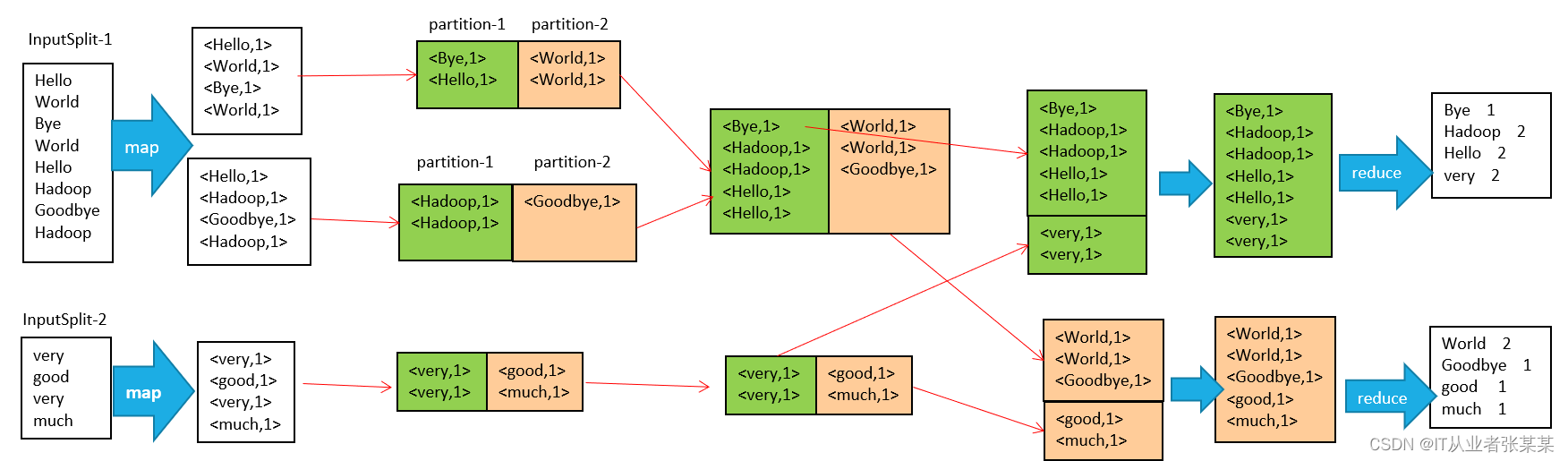 流程說明如下:
流程說明如下:
1、輸入檔案分片,每一片都由一個MapTask來處理
2、Map輸出的中間結果會先放在記憶體緩沖區中,這個緩沖區的大小默認是100M,當緩沖區中的內容達到80%時(80M)會將緩沖區的內容寫到磁盤上,也就是說,一個map會輸出一個或者多個這樣的檔案,如果一個map輸出的全部內容沒有超過限制,那么最終也會發生這個寫磁盤的操作,只不過是寫幾次的問題,
3、從緩沖區寫到磁盤的時候,會進行磁區并排序,磁區指的是某個key應該進入到哪個磁區,同一磁區中的key會進行排序,如果定義了Combiner的話,也會進行combine操作
4、如果一個map產生的中間結果存放到多個檔案,那么這些檔案最侄訓合并成一個檔案,這個合并程序不會改變磁區數量,只會減少檔案數量,例如,假設分了3個區,4個檔案,那么最侄訓合并成1個檔案,3個區
5、以上只是一個map的輸出,接下來進入reduce階段
6、每個reducer對應一個ReduceTask,在真正開始reduce之前,先要從磁區中抓取資料
7、相同的磁區的資料會進入同一個reduce,這一步中會從所有map輸出中抓取某一磁區的資料,在抓取的程序中伴隨著排序、合并,
8、reduce輸出
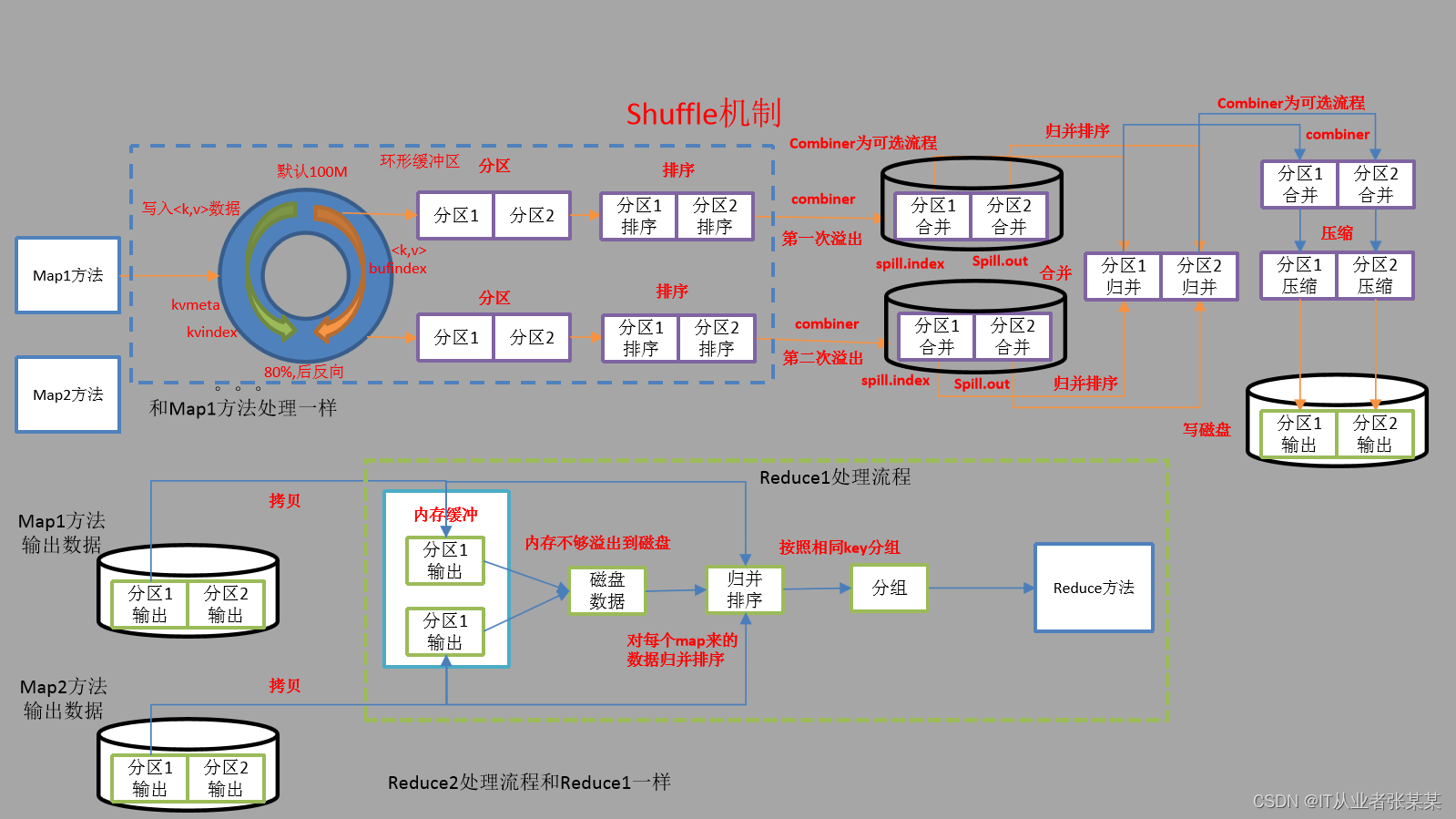
3.3.MR的shuffle環節
在Map端的shuffle程序是對Map的結果進行磁區、排序、分割,然后將屬于同一劃分(磁區)的輸出合并在一起并寫在磁盤上,最終得到一個磁區有序的檔案,磁區有序的含義是map輸出的鍵值對按磁區進行排列,具有相同partition值的鍵值對存盤在一起,每個磁區里面的鍵值對又按key值進行升序排列(默認),其流程大致如下:
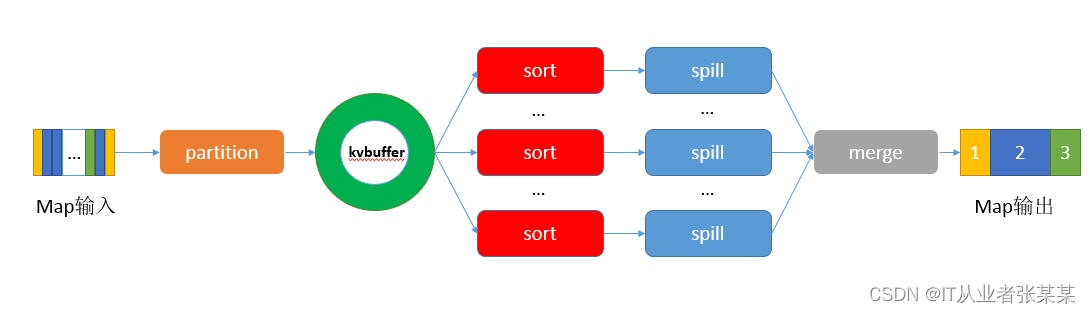
Map的輸出給進入Shuffle環節:Shuffle環節如下:
3.4.MR的編程
編程分析:
map任務處理:
讀取輸入檔案內容,決議成key、value對,對輸入檔案的每一行,決議成key、value對,每一個鍵值對呼叫一次map函式,
寫自己的邏輯,對輸入的key、value處理,轉換成新的key、value輸出,
對輸出的key、value進行磁區,
對不同磁區的資料,按照key進行排序、分組,相同key的value放到一個集合中,
(可選)分組后的資料進行歸約,
reduce任務處理:
對多個map任務的輸出,按照不同的磁區,通過網路copy到不同的reduce節點,
對多個map任務的輸出進行合并、排序,寫reduce函式自己的邏輯,對輸入的key、value處理,轉換成新的key、value輸出,
把reduce的輸出保存到檔案中,
編程代碼:
public class WordCount {
//繼承mapper介面,設定map的輸入型別為<Object,Text>
//輸出型別為<Text,IntWritable>
public static class Map extends Mapper<Object,Text,Text,IntWritable>{
//one表示單詞出現一次
private static IntWritable one = new IntWritable(1);
//word存盤切下的單詞
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
//對輸入的行切詞
StringTokenizer st = new StringTokenizer(value.toString());
while(st.hasMoreTokens()){
word.set(st.nextToken());//切下的單詞存入word
context.write(word, one);
}
}
}
//繼承reducer介面,設定reduce的輸入型別<Text,IntWritable>
//輸出型別為<Text,IntWritable>
public static class Reduce extends Reducer<Text,IntWritable,Text,IntWritable>{
//result記錄單詞的頻數
private static IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{
int sum = 0;
//對獲取的<key,value-list>計算value的和
for(IntWritable val:values){
sum += val.get();
}
//將頻數設定到result
result.set(sum);
//收集結果
context.write(key, result);
}
}
/**
* @param args
*/
public static void main(String[] args) throws Exception{
// TODO Auto-generated method stub
Configuration conf = new Configuration();
conf.set("mapred.job.tracker", "localhost:9001");
args = new String[]{"hdfs://localhost:9000/user/hadoop/input/count_in","hdfs://localhost:9000/user/hadoop/output/count_out"};
//檢查運行命令
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage WordCount <int> <out>");
System.exit(2);
}
//配置作業名
Job job = new Job(conf,"word count");
//配置作業各個類
job.setJarByClass(WordCount.class);
job.setMapperClass(Map.class);
job.setCombinerClass(Reduce.class);
job.setReducerClass(Reduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
4.Yarn專題
參考:
https://blog.csdn.net/weixin_43930865/article/details/115708202
4.1.yarn簡介
YARN 是一個資源調度平臺,負責為運算程式提供服務器運算資源,相當于一個分布式的作業系統平臺,Spark、Storm 等運算框架都可以整合在 YARN 上運行,只要他們各自的框架中有符合 YARN 規范的資源請求機制即可
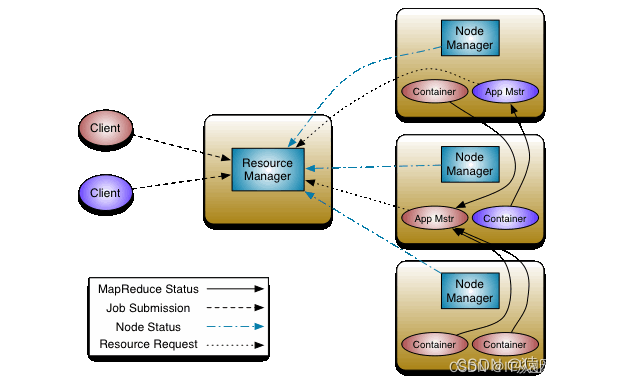
設計思想
YARN 的基本思想是將資源管理和作業調度/監控的功能拆分為單獨的守護行程,這個想法是有一個全域 ResourceManager ( RM ) 和每個應用程式 ApplicationMaster ( AM ),應用程式是單個作業或作業的 DAG,
ResourceManager 和 NodeManager 構成了資料計算框架,ResourceManager 是在系統中的所有應用程式之間仲裁資源的最終權威,NodeManager 是每臺機器的框架代理,負責容器、監控它們的資源使用情況(cpu、記憶體、磁盤、網路)并將其報告給 ResourceManager/Scheduler,
每個應用程式的 ApplicationMaster 實際上是一個特定于框架的庫,其任務是協商來自 ResourceManager 的資源并與 NodeManager 一起執行和監視任務,
4.2.yarn架構與服務角色
架構圖如下:
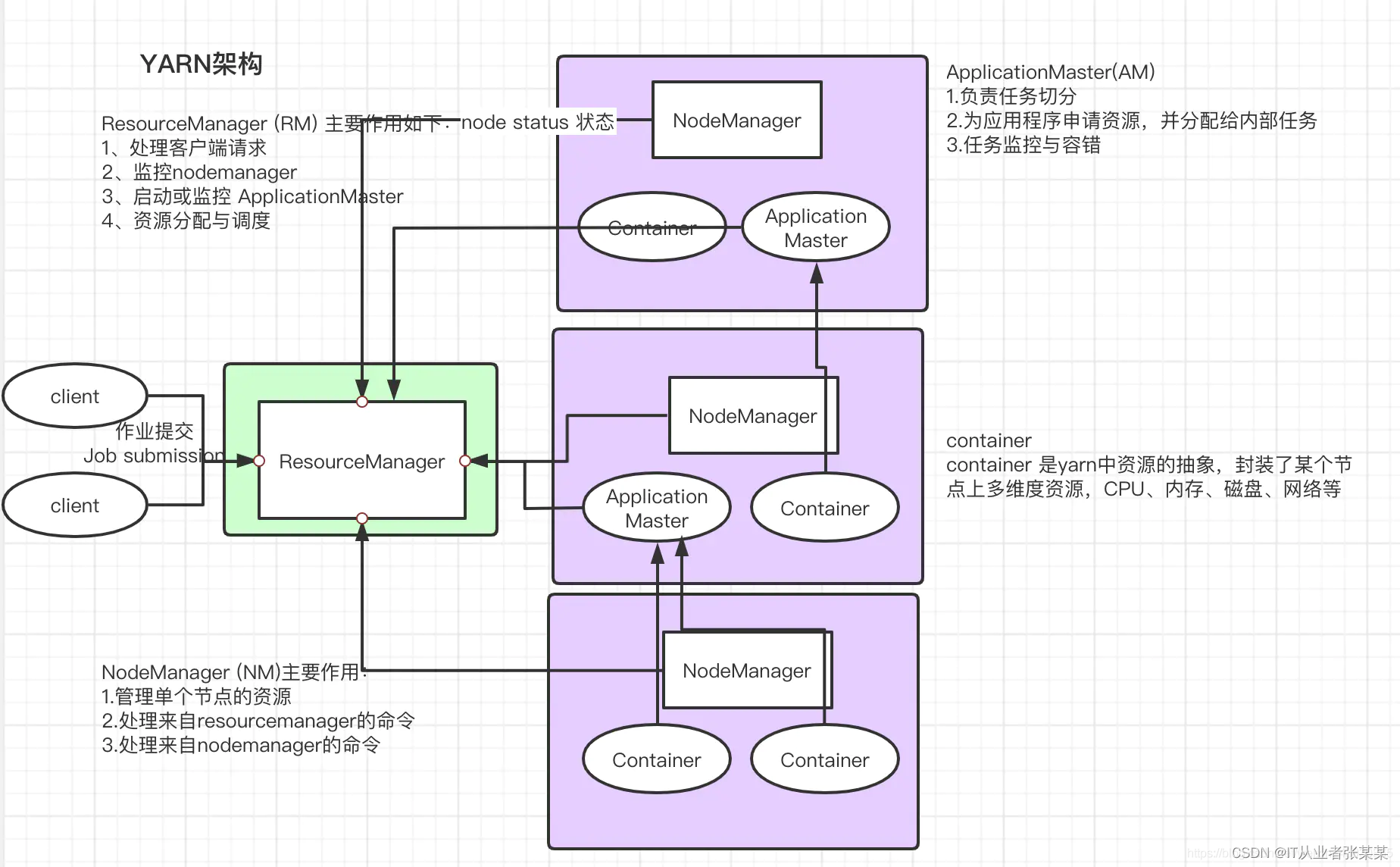
2.1ResourceManager
RM(ResourceManager)是 YARN 集群主控節點,負責協調和管理整個集群(所有 NodeManager)的資源,ResourceManager 會為每一個 Application 啟動一個 AppMaster,并且 AppMaster 分散在各個 NodeManager 節點,
ResourceManager 的職責:
1、處理客戶端請求,比如程式提交
2、啟動或監控 MRAppMaster
3、監控 NodeManager健康狀態
4、資源的分配與調度
ResourceManager 有兩個主要組件:Scheduler 和 ApplicationsManager,
Scheduler 調度器負責根據熟悉的容量、佇列等約束將資源分配給各種正在運行的應用程式,調度器是純粹的調度器,因為它不執行應用程式的狀態監控或跟蹤,此外,它不保證由于應用程式故障或硬體故障而重新啟動失敗的任務,調度器根據應用程式的資源需求執行其調度功能;它是基于資源容器的抽象概念來實作的,該容器包含記憶體、CPU、磁盤、網路等元素,
2.2NodeManager
NodeManager 是 YARN 集群當中真正資源的提供者,是真正執行應用程式的容器的提供者,監控應用程式的資源使用情況(CPU,記憶體,硬碟,網路),并通過心跳向集群資源調度器ResourceManager 進行匯報以更新自己的健康狀態,同時其也會監督 Container 的生命周期管理,監控每個 Container 的資源使用(記憶體、CPU 等)情況,追蹤節點健康狀況,管理日志和不同應用程式用到的附屬服務(auxiliary service),
2.3AppMaster
AppMaster對應一個應用程式,職責是:向YARN資源調度器申請執行任務的資源容器,運行任務,監控整個任務的執行,跟蹤整個任務的狀態,處理任務失敗以例外情況
2.4Container容器
Container 容器是一個抽象出來的邏輯資源單位,容器是由 ResourceManager Scheduler 服務動態分配的資源構成,它包括了一個節點上的一定量 CPU,記憶體,磁盤,網路等資訊,容器的大小是可以動態調整的,其最大大小就是一個nodemanger的資源,一個container只能在一個容器上,
4.3.Scheduler調度器
調度器根據應用程式的資源需求進行資源分配,不參與應用程式具體的執行和監控等作業,調度器會將總資源分為不同的佇列供共享資源進行分配,資源分配的單位就是 Container,YARN 本身為我們提供了多種直接可用的調度器,比如 FIFO佇列調度器,Fair 公平調度器和 Capacity 容量調度器等,可以在conf/yarn-site.xml 中配置調度器,
1.CapacityScheduler容量調度器
其中心思想是 Hadoop 集群中的可用資源在多個組織之間共享,這些組織根據其計算需求共同資助集群,為了保證集群總資源的安全和穩定性,CapacityScheduler提供了一組嚴格的限制,以確保單個應用程式或用戶或佇列不能在集群中消耗的資源的量不成比例,此外,CapacityScheduler對來自單個用戶和佇列的初始化和掛起的應用程式提供限制,以確保集群的公平性和穩定性,簡單說就是當目前使用佇列資源不夠時,動態分配其他佇列資源進行使用,引數配置指定調度器:yarn.resourcemanager.scheduler.class=指定掛起和運行最大程式個數:默認是10000:maximum-applications集群中程式最大可占用的運行資源:maximum-am-resource-percent默認是1-10%=90%的最大資源使用率,留10%給系統指定某用戶的最大運行程式數:yarn.scheduler.capacity.user..max-parallel-apps 可以設定單個佇列的資源占比,運行app任務數等,
2.Fair 公平調度器公平調度
是一種將資源分配給應用程式的方法,以便所有應用程式在一段時間內平均獲得相等的資源份額,默認情況下,Fair Scheduler 僅基于記憶體進行調度公平性決策,簡單來說就是對于兩個程式搶奪同一資源時進行均分資源,保證都能得到一半,
3.FIFO Scheduler(先進先出調度器)
FIFO Scheduler把應用按提交的順序排成一個佇列,這是一個先進先出佇列,在進行資源分配的時候,先給佇列中最頭上的應用進行分配資源,待最頭上的應用需求滿足后再給下一個分配,以此類推,FIFO Scheduler是最簡單也是最容易理解的調度器,也不需要任何配置,但它并不適用于共享集群,大的應用可能會占用所有集群資源,這就導致其它應用被阻塞,在共享集群中,更適合采用Capacity Scheduler或Fair Scheduler,這兩個調度器都允許大任務和小任務在提交的同時獲得一定的系統資源,
4.4.YARN 作業執行流程
利用yarn進行資源調度的程式,基本流程都和下面一致,包括spark,MR等資料處理組件
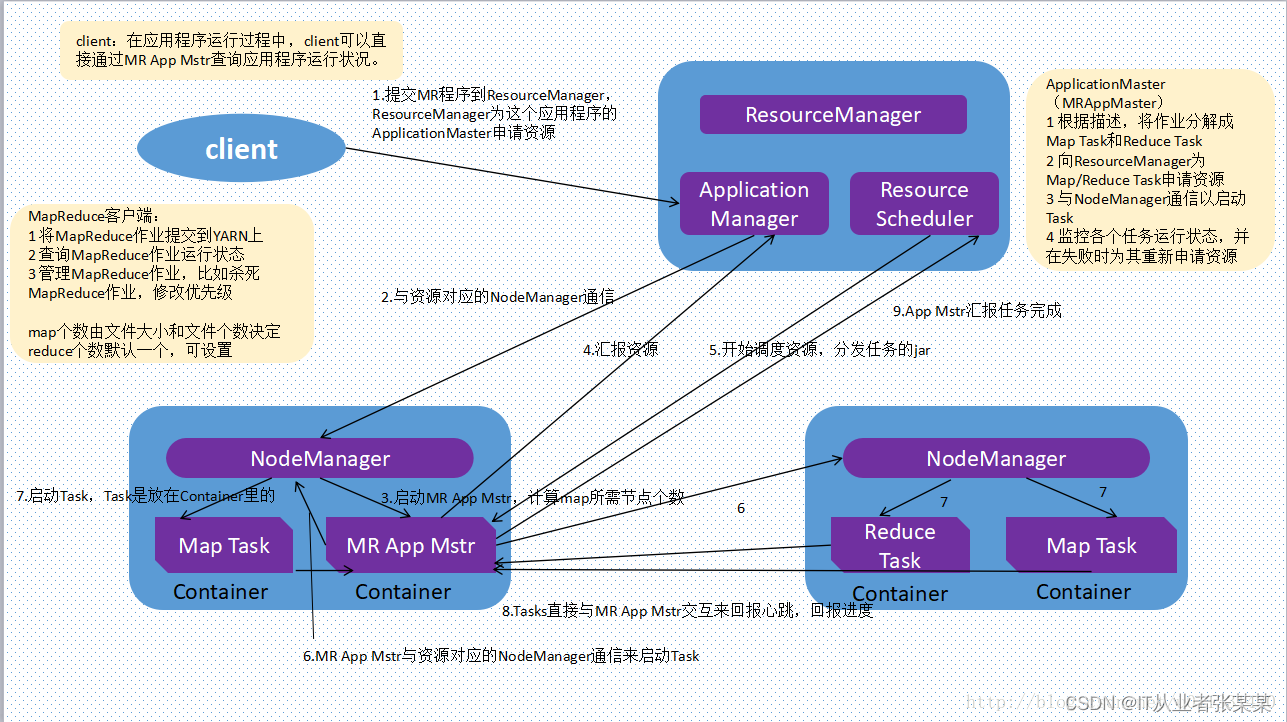
1.client向yarn提交job,首先找ResourceManager分配資源,
2.ResourceManager開啟一個Container,在Container中運行一個Application manager
3.Application manager找一臺nodemanager啟動Application master,計算任務所需的計算
4.Application master向Application manager(Yarn)申請運行任務所需的資源
5.Resource scheduler將資源封裝發給Application master
6.Application master將獲取到的資源分配給各個nodemanager
7.各個nodemanager得到任務和資源開始執行map task
8.map task執行結束后,開始執行reduce task
9.map task和 reduce task將執行結果反饋給Application master
10.Application master將任務執行的結果反饋pplication manager
5.HIVE專題
參考:
https://blog.csdn.net/qq_32727095/article/details/120512994
5.1HIVE簡介
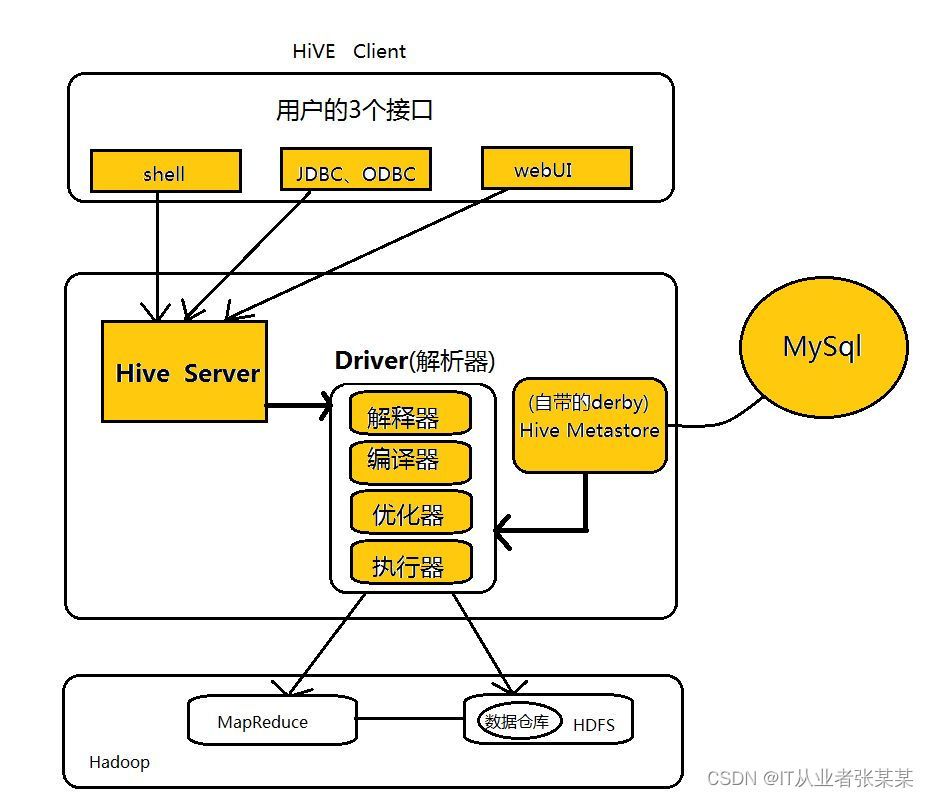
Hive是一個資料倉庫基礎工具在Hadoop中用來處理結構化資料,它架構在Hadoop之上,總歸為大資料,并使得查詢和分析方便,并提供簡單的sql查詢功能,可以將sql陳述句轉換為MapReduce任務進行運行,
最初,Hive是由Facebook開發,后來由Apache軟體基金會開發,并作為進一步將它作為名義下Apache Hive為一個開源專案,Hive 沒有專門的資料格式, Hive 可以很好的作業在 Thrift 之上,控制分隔符,也允許用戶指定資料格式,Hive不適用于在線事務處理, 它最適用于傳統的資料倉庫任務,
Hive 構建在基于靜態批處理的Hadoop 之上,Hadoop 通常都有較高的延遲并且在作業提交和調度的時候需要大量的開銷,因此,Hive 并不能夠在大規模資料集上實作低延遲快速的查詢,例如,Hive 在幾百MB 的資料集上執行查詢一般有分鐘級的時間延遲,因此,
Hive 并不適合那些需要低延遲的應用,例如,聯機事務處理(OLTP),Hive 查詢操作程序嚴格遵守Hadoop MapReduce 的作業執行模型,Hive 將用戶的HiveQL 陳述句通過解釋器轉換為MapReduce 作業提交到Hadoop 集群上,Hadoop 監控作業執行程序,然后回傳作業執行結果給用戶,Hive 并非為聯機事務處理而設計,Hive 并不提供實時的查詢和基于行級的資料更新操作,Hive 的最佳使用場合是大資料集的批處理作業,例如,網路日志分析,
直接使用hadoop所面臨的問題:
人員學習成本太高
專案周期要求太短
MapReduce實作復雜查詢邏輯開發難度太大
使用HIVE可解決的問題:
操作介面采用類SQL語法,提供快速開發的能力,
避免了去寫MapReduce,減少開發人員的學習成本,
擴展功能很方便,
HIVE架構
5.2HIVE如何執行一條HQL陳述句
概述:
第一步:輸入一條HQL查詢陳述句(select * from tab)
第二步:決議器對這條Hql陳述句進行語法分析,
第三步:編譯器對這條Hql陳述句生成HQL的執行計劃,
第四步:優化器生成最佳的Hql的執行計劃,
第五步:執行這條最佳Hql陳述句,
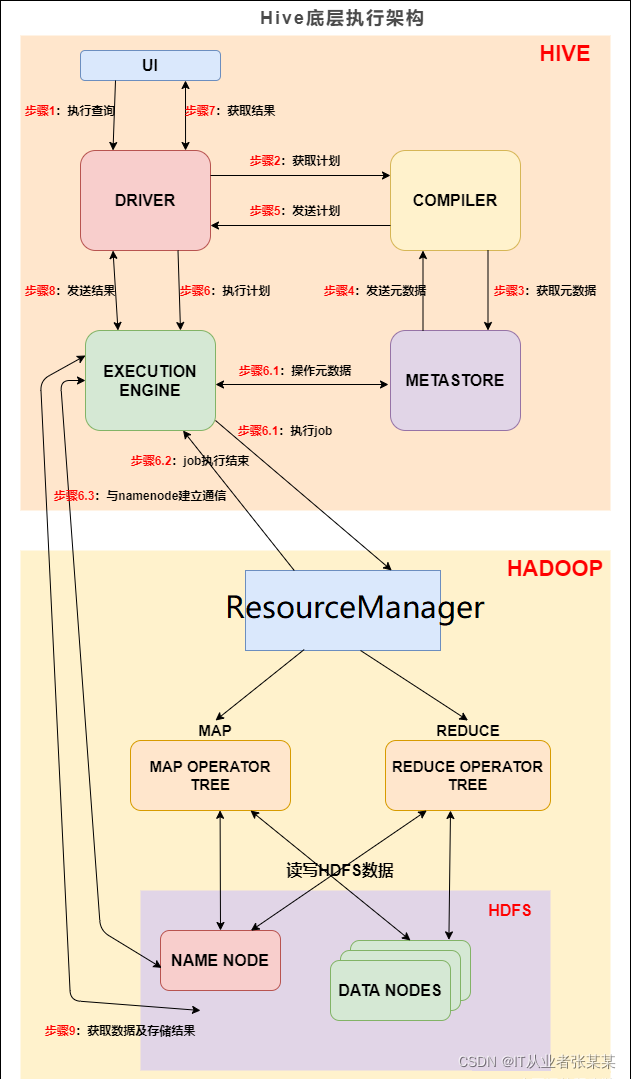
比如如下HQL陳述句:
select dept, sum(salary) from emp group by dept;
考慮下這個東西你自己寫會怎么計算:你有一張表在hdfs上,這個表是一張員工表,有幾個欄位:
id:integer,name:varchar,dept:varchar,memo: string,salary:Integer
1,張三,總裁辦,暫缺,1000
2,李四,總裁辦,暫缺,1000
3,王五,外聯部,無,2000
上面資料采樣的第一列是ID,后面是名字,接著是DEPT(部門),最后是備注和工資,然后SQL是用來統計每個部門工資支出的,GROUP BY DEPT就是按照DEPT分組,把相同的放在一起,然后各自算出工資總額,單機做的話就是先按照部門排個序,然后一個大回圈單獨統計每個部門的總額,最后一個部門輸出一條結果,
如果是Hive呢,大致上也類似,只是搬到分布式環境下了,
Hive基本上會遵循AST->邏輯執行計劃->優化的邏輯執行計劃->物理執行計劃->打包提交->分布式執行,這樣的順序來開展計算,
現在詳細的說明開始,從SQL字串輸入開始,
SQL輸入是個字串,Hive需要先把字串分解成自己能明白的結構,Hive的決議不是徒手擼的,用的是ANTLR,一個決議器生成器,可以用類似BNF的范式定義語法然后產生對應的決議代碼,BNF是大學編譯原理必學的東西,另外Hive的語法定義是一種后綴是.g的特殊檔案,可以自己去Hive的代碼里搜一下,
ANTLR生成的代碼會回傳給你ASTNode,AST是抽象語法樹的簡寫,比如上面的SELECT,會轉化為一個以TOK_SELECT標記為根節點的樹,樹的葉子節點需要包含Projection List子樹(dept,count(*)),FROM子樹,Filter子樹(上面的例子空缺了)等等,也就是說,AST會把一個長字串轉化成樹結構,樹本身的結構設計取決于你的語法定義,ANTLR會按照你的定義把樹排列好,Hive自身的代碼而言,也要根據樹結構定義去遍歷整個樹,把需要的資訊抽取出來,AST的好處是,你不再糾結于Token的決議和排列問題,你只需要在一個固定結構的樹上抽取資訊,比如SELECT根節點以下你必然能找到SELECT_EXPR子節點(就是Projection部分的資訊),很適合做這件事情,
遍歷完整個AST,Hive把它關心的資訊分類組織排列到一個結構中,但是還沒有進行元資訊系結和檢查整理,而這個系結整理的程序叫Semantics Analyze(語意分析),對應上面的例子,Hive會分別抽取:
Projection串列,上述例子就是DEPT,sum(salary),這里拿到的資訊表示,用戶希望結果是什么運算式;
FROM串列,表示資料源;
GROUP BY,表示如何分組,
然后要做的是元資料系結,這里首先需要從Hive元資料庫中查詢到相關的元資訊,對上面的查詢,Hive知道了用戶希望從emp表中查詢資料,那么Hive呼叫MetastoreClient介面,從Metadata Service中抽取了emp表的元資訊,所謂元資訊最基本地包含了表的schema,比如id是Integer型別,dept是string型別,這些資訊都會注入本次之行Hive的符號決議空間,同時被注入的符號還有內建函式(比如我們用的sum)和UDF等等,然后Hive對Projection串列中的運算式進行決議,首先是dept,Hive會去搜索剛才提到的符號決議空間,找到了DEPT代表源表中的一個欄位,型別是String,因為這里就是一個簡單的欄位參考,因此不涉及型別檢查之類的;但是如果你寫DEPT+1,這里就會有型別檢查和隱式轉換等,比如是強型別的設計,看到string+integer的組合就會拋出例外結束執行,而弱型別的系統會偷偷插入一個CAST,把1轉換成字串“1”,第二列是sum(salary),這里Hive看到一個函式呼叫,于是它搜索了函式表,找到了sum函式,并看到它是一個聚合函式(sum不是簡單的一行資料能獨立計算的函式,需要整個組一起算),這里就先標記起來,后面還有相關的語意檢查,而繼續遍歷sum的子樹又發現了一個salary列參考運算式,一樣做一次決議找到salary列定義是Integer,
最后是Group By檢查,根據SQL語義,出現在聚合函式外的欄位參考必須出現在Group By中,于是Hive開始檢查sum(SALARY)之外的列參考,發現了DEPT,然后遍歷Group By的串列進行匹配,發現所有非聚合列都已經在GROUP BY中定義了,于是Hive很滿意,繼續執行下去了,
到這里為止Hive得到了一個語意正確的SQL查詢資訊結構,接下去需要的是,產生邏輯執行計劃,
邏輯執行計劃可以簡單地認為就是,按照順序在單機上跑是能跑出結果的一個計算計劃,
按照最初我們分析的演算法,首先你需要掃描整個表,因此Hive先產生一個TableScanOperator;接下去,需要做的是抽取DEPT欄位和SALARY(sum的輸入引數需要比sum先計算完),因此這兩個操作在一起生成一個ProjectionOperator;然后是AggregationOperator,就是sum本身的計算,當然這個計算還需要攜帶DEPT的部分;最后是輸出,就是SinkOperator,需要把結果寫到HDFS上,
接下去Hive會對執行計劃進行優化,最常見的優化可能是PartitionPrune,比如你在Hive中定義了磁區表,那么如果有Where條件中出現了磁區欄位,比如WHERE date = ‘2016-08-25’,而且磁區就是date,那么我需要在TableScanOperator中加入磁區資訊,指定Scan的時候只掃描2016-8-25的資訊;或者如果你有子查詢,Hive會將內層的查詢條件推送到外層,這樣需要計算的資料就會減少;再或者如果底層存盤支持列裁剪,那么剛才那張表其實我只用到了DEPT和SALARY兩個欄位,ID和名字以及備注我都不關心,那么Scan的時候可以少讀一些資訊,更復雜的還有比如CBO相關優化,可以交換Join順序,讓多次Join產生的中間資料盡可能小,或者選擇不同的JOIN策略等等,
優化完畢之后,Hive接著生成物理執行計劃,所謂物理執行計劃才是真正映射底層計算引擎的計算策略,根據底層引擎不同(現在Hive支持Spark,Tez和MapReduce),Hive會生成不同的物理對應,拿MapReduce來說,剛才的SQL到這個階段,需要拆解成Mapper和Reducer不同的步驟,TableScan,Projection計算以及Sum的前半段都是需要塞到Mapper做的,比較特殊的是Sum,因為Sum在MapReduce環境下需要在Mapper中計算Sum括號內的運算式(這里就是簡單的提取SALARY),并且在每個Mapper中進行本地累加(Combiner中根據分組進行本地加和),然后分發到Reducer進行最終累加,因此AggregationOperator在物理執行計劃產生的時候會拆解成兩部分,一部分是PartialAggregation對應Mapper端的Sum,一部分是FinalAggregation對應Reducer端的最終Sum,這樣我們的執行計劃就變成:
Stage1:
Mapper - <TableScanOperator,ProjectionOperator,ParitialAggregationOperator>
Reducer - <FinalAggregationOperator, ReducerSinkOperator>
寫到這里發現選取的例子并沒有復雜運算式,比如我其實要計算大家統一加薪10%之后的成本,那我其實會寫Salary * 1.1,如果是這樣的話,Salary * 1.1這樣的運算式會被封裝成一個可以求值的求值器,很多類似Hive的SQL On Hadoop系統選擇進行代碼生成,比如Spark,Impala或者Presto(其實基本Hive之后的都進行了代碼生成,而Hive應該還沒有進行代碼生成,這個我并不確定),
不管Hive現在有沒有代碼生成,就算有,也和很多人想象中的代碼生成并不同,Hive并不會直接產生一個MapReduce作業的全部代碼,Hive會將剛才說的Operator資訊進行封裝,產生一個可以序列化傳輸的包,這個包里包涵了各個Operator求值所需的資訊,然后提交作業分發給Mapper和Reducer,Hive使用的Mapper和Reducer是兩個特定的Hive類,它們的一部分初始化資訊來自于Job階段根據Operator的資訊進行設定(比如TableScan相關的資訊一部分在Job生成的時候就已經設定好),另一部分會在每個Task啟動的時候裝載剛才序列化的Operator資訊并產生一個可以求值的求值器,當map和reduce函式被呼叫的時候,求值器也被呼叫,每個輸入資料都被求值一遍,
這樣一次Mapper和Reducer走完,SQL就計算完畢了,
具體Hive使用的MapReduce類是
org.apache.hadoop.hive.ql.exec.mr.ExecMapper,ExecReducer
好奇的同學可以去翻翻看,到底邏輯是如何的,
實際上上面的SQL基本上可以說是最最簡單的場景了,如果有諸如Join,視窗函式,子查詢等,整個執行計劃會一下子變的復雜,另外元資料管理,權限,HiveServer2和JDBC等等,就沒有那么令人感興趣了,在此略過不提,用過Hive的人多少可以自己想得出這幾個部分如何作業,
5.3HIVE資料存盤
Hive的資料存盤
1、Hive中所有的資料都存盤在 HDFS 中,沒有專門的資料存盤格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在創建表的時候告訴 Hive 資料中的列分隔符和行分隔符,Hive 就可以決議資料,
3、Hive 中包含以下資料模型:DB、Table,External Table,Partition,Bucket,
db:在hdfs中表現為${hive.metastore.warehouse.dir}目錄下一個檔案夾
table:在hdfs中表現所屬db目錄下一個檔案夾
external table:外部表, 與table類似,不過其資料存放位置可以在任意指定路徑
普通表: 洗掉表后, hdfs上的檔案都刪了
External外部表洗掉后, hdfs上的檔案沒有洗掉, 只是把檔案洗掉了
partition:在hdfs中表現為table目錄下的子目錄
bucket:桶, 在hdfs中表現為同一個表目錄下根據hash散列之后的多個檔案, 會根據不同的檔案把資料放到不同的檔案中
5.4HIVE常用陳述句
常用陳述句
創建資料庫
>create database db_name;
>create database if not exists db_name;//創建一個不存在的資料庫final
查看資料庫
>show databases;
選擇性查看資料庫
>show databases like 'f.*';
查看某一個資料庫的詳細資訊
>describe database db_name;
洗掉非空資料庫
>drop database db_name CASCADE;
創建資料庫時,指定資料庫位置
>create database db_name location '/home/database/'
創建資料庫的時候希望能夠給資料庫增加一些描述性東西
>create database db_name comment 'helloworld';
創建資料庫的時候,需要為資料庫增加屬性資訊,可以使用with dbproperties資訊
>create database db_name with dbproperties<'createor'='hello','date'='2018-3-3');
如果要使用自己已經存在的資料庫
>use db_name;
修改資料庫的屬性資訊
>alter database db_name set dbproperties('edited-by'='hello');
創建表
>create table tab_name(id int,name string) row format delimited fields terminated by '\t';
創建一個表,該表和已有的某一個表的結構一樣(復制表結構)
>create table if not exists emp like employeel;
查看當前資料庫下的所有表
>show tables;
洗掉一個已經存在的表
>drop table employee;
修改一個表明,重命名
>alter table old_name rename to new_name;
將hdfs上面的檔案資訊匯入到hive表中(/home/bigdata代表檔案在在HDFS上位置)使用改命令時一定要注意資料與資料之間在txt檔案編輯的時候一定要Tab間隔
>load data local inpath '/home/bigdata' into table hive.dep;
修改某一個表的某一列的資訊
>alter table tab_name change column key key_1 int comment 'h' after value;
給某一個表增加某一列的資訊
>alter table tab_name add columns(value1 string,value2 string);
如果想替換表中的某一個列
>alter table tab_name replace columns(values string,value11 string);
修改表中某一列的屬性
>alter table tab_name set tblproperties('value'='hello');
hive成批向某一表插入資料
>insert overwrite table tab_name select * from tab_name2;
將 查詢結果保留到一個新表中去
>create table tab_name as select * from t_name2;
將查詢結果保存到指定的檔案目錄(可以是本地,也可以HDFS)
>insert overwrite local directory '/home/hadoop/test' select *from t_name;
>insert overwrite directory '/aaa/bbb/' select *from t_p;
兩表內連
>select *from dual a join dual b on a.key=b.key;
將hive查詢結果輸出到本地特定目錄
insert overwrite local directory '/home/bigdata1/mydir' select *from test;
將hive查詢結果輸出到HDFS特定目錄
insert overwrite directory '/home/mydir' select *from test;
案例:EMP DEPT表
(1)命令列視窗通過輸入hive,連接到hive,查看資料庫
hive
show databases;
通過location指定資料庫路徑,本例中資料庫路徑為當前用戶桌面上目錄
create database hadoop_hive location '/home/ubuntu/Desktop/hadoop_hive';
使用創建好的資料庫
use hadoop_hive;
(2)創建員工表(emp+學號,如:emp001)
create table emp001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int) row format delimited fields terminated by ',';
(3)創建部門表(dept+學號,如:dept001)
create table dept001(deptno int,dname string,loc string) row format delimited fields terminated by ',';
(4)匯入資料
load data inpath '/001/hive/emp.csv' into table emp001;
load data inpath '/001/hive/dept.csv' into table dept001;
(5)根據員工的部門號創建磁區,表名emp_part+學號,如:emp_part001
create table emp_part001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int)partitioned by (deptno int)row format delimited fields terminated by ',';
往磁區表中插入資料:指明匯入的資料的磁區(通過子查詢匯入資料)
insert into table emp_part001 partition(deptno=10) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=10;
insert into table emp_part001 partition(deptno=20) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=20;
insert into table emp_part001 partition(deptno=30) select empno,ename,job,mgr,hiredate,sal,comm from emp001 where deptno=30;
select * from emp_part001;
(6)創建一個桶表,表名emp_bucket+學號,如:emp_bucket001,根據員工的職位(job)進行分桶:
create table emp_bucket001(empno int,ename string,job string,mgr int,hiredate string,sal int,comm int,deptno int)clustered by (job) into 4 buckets row format delimited fields terminated by ',';
(7)通過子查詢插入資料:
insert into emp_bucket001 select * from emp001;
(8)查詢員工資訊:員工號 姓名 薪水
select empno,ename,sal from emp001;
(9)多表查詢
select dept001.dname,emp001.ename from emp001,dept001 where emp001.deptno=dept001.deptno;
(10)做報表,根據職位給員工漲工資,把漲前、漲后的薪水顯示出來
select empno,ename,job,sal,case job when 'PRESIDENT' then sal+1000 when 'MANAGER' then sal+800 else sal+400 end from emp001;
6.Zookeeper專題
6.1 Zookeeper概念
1.Zookeeper作用:
Zookeeper是針對大型分布式系統的高可靠的協調系統,
由這個定義我們知道 zookeeper是個協調系統,作用的物件是分布式系統,
zookeeper主要是檔案系統和通知機制
檔案系統主要是用來存盤資料
通知機制主要是服務器或者客戶端進行通知,并且監督
2.Zookeeper檔案系統節點型別
有4種型別的znode
1、PERSISTENT--持久化目錄節點
客戶端與zookeeper斷開連接后,該節點依舊存在
2、PERSISTENT_SEQUENTIAL-持久化順序編號目錄節點
客戶端與zookeeper斷開連接后,該節點依舊存在,只是Zookeeper給該節點名稱進行順序編號
3、EPHEMERAL-臨時目錄節點
客戶端與zookeeper斷開連接后,該節點被洗掉
4、EPHEMERAL_SEQUENTIAL-臨時順序編號目錄節點
客戶端與zookeeper斷開連接后,該節點被洗掉,只是Zookeeper給該節點名稱進行順序編號
3.Zookeeper特點
一個leader,多個follower的集群
集群只要有半數以上包括半數就可正常服務,一般安裝奇數臺服務器
全域資料一致,每個服務器都保存同樣的資料,實時更新
更新的請求順序保持順序(來自同一個服務器)
資料更新的原子性,資料要么成功要么失敗
資料實時更新性很快
6.2 Zookeeper應用場景
1.服務動態上下線通知
2.分布式鎖
3.資料配置
4.集群管理
6.3 Zookeeper原理
PAXOS演算法:
參考:https://www.cnblogs.com/linbingdong/p/6253479.html
ZAB演算法:
參考:https://blog.csdn.net/liuchang19950703/article/details/111406622
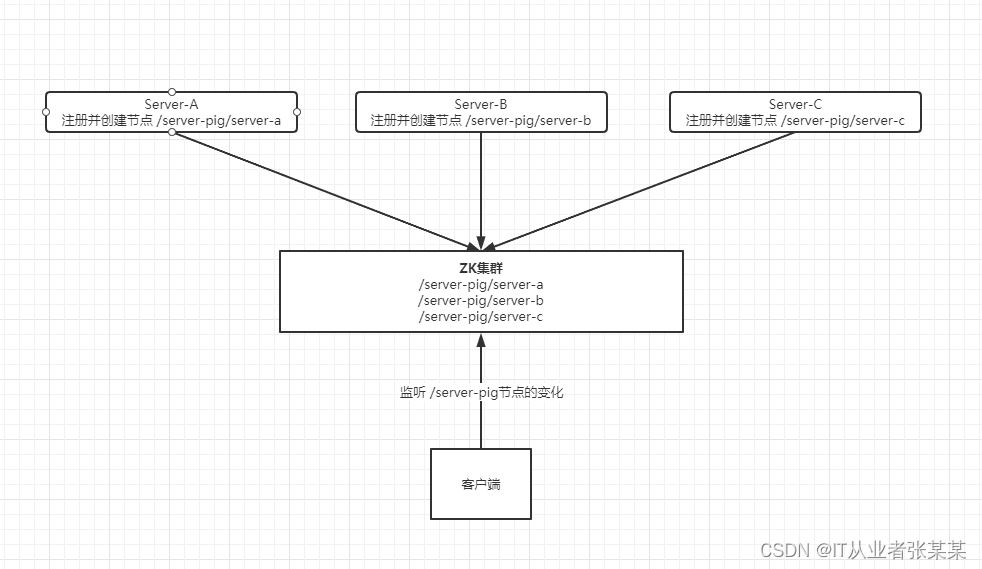
6.4 Zookeeper實作服務動態上下線通知原理
如圖:
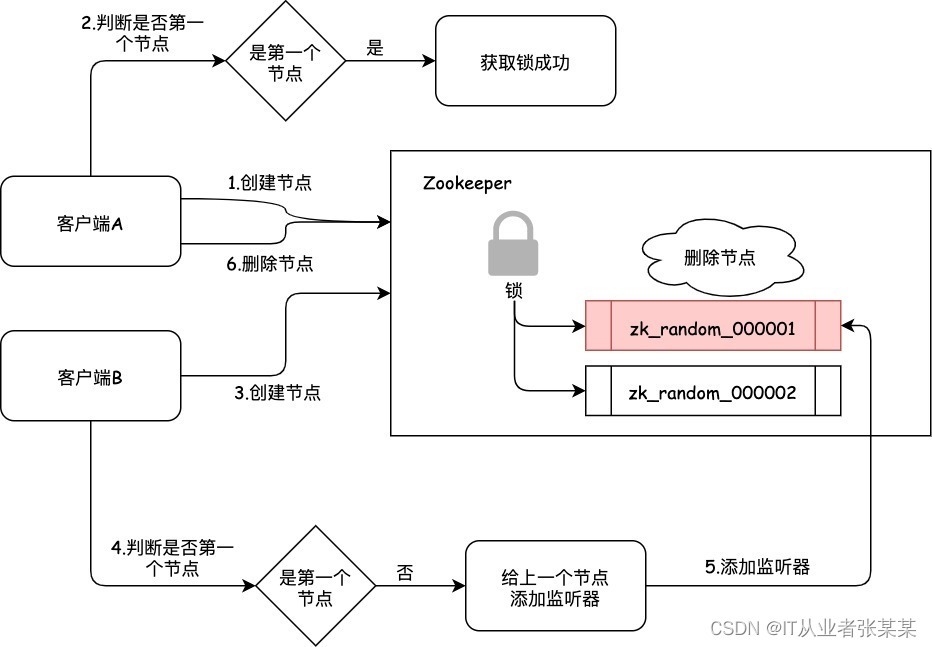
6.5 Zookeeper實作分布式鎖原理
如圖:
6.6 Zookeeper常用命令
1、zk服務命令
- 啟動ZK服務: bin/zkServer.sh start
- 查看ZK服務狀態: bin/zkServer.sh status
- 停止ZK服務: bin/zkServer.sh stop
- 重啟ZK服務: bin/zkServer.sh restart
- 連接服務器: zkCli.sh -server 127.0.0.1:2181
2、連接zk
啟動ZooKeeper服務之后,我們可以使用如下命令連接到 ZooKeeper 服務:
eg、zookeeper-3.4.8\bin>zkCli.cmd -server 127.0.0.1:2181
Linux環境下:
eg、zkCli.sh -server 127.0.0.1:2181
連接成功后,系統會輸出 ZooKeeper 的相關環境以及配置資訊,如下:
3、zk客戶端命令
我們可以使用 help命令來查看幫助:
命令列工具的一些常用操作命令如下:
1.ls – 查看某個目錄包含的所有檔案,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] ls /
2.ls2 – 查看某個目錄包含的所有檔案,與ls不同的是它查看到time、version等資訊,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] ls2 /
3.create – 創建znode,并設定初始內容,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] create /test “test”
Created /test
創建一個新的 znode節點“ test ”以及與它關聯的字串
4.get – 獲取znode的資料,如下:
[zk: 127.0.0.1:2181(CONNECTED) 1] get /test
5.set – 修改znode內容,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] set /test “ricky”
6.delete – 洗掉znode,例如:
[zk: 127.0.0.1:2181(CONNECTED) 1] delete /test
7.quit – 退出客戶端
8.help – 幫助命令
7 Flume專題
7.1Flume簡介
Flume是一種分布式的、可靠的、可用的服務,用于高效地收集、聚合和移動大量的日志資料,它具有基于流資料流的簡單而靈活的架構,它具有可調的可靠性機制和許多故障轉移和恢復機制,具有健壯性和容錯能力,它使用一個簡單的可擴展資料模型,允許在線分析應用程式,
Flume中的資料傳遞被稱為event事件,event就是資料流單元,Flume中的agent被稱為代理,agent的本質是一個(JVM)行程,每個agent中包含了source,channel,sink這幾個組件,這些組件會把資料從一個地方(source)采集到目的地(sink)中(被稱為一個hop,跳),
7.2 Sources,Channels,Sinks配置
Flume的source配置,見
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-sources
Flume的channel配置,見
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-channels
Flume的sink配置,見
http://flume.apache.org/releases/content/1.9.0/FlumeUserGuide.html#flume-sinks
7.3 可靠性
在每個agent中,event都會暫存在channel中,然后將event傳遞給下一個agent或是終端存盤庫中(如sink的型別為HDFS時),這些event在存盤到下一個agent的channel中或是存盤到終端存盤中(如HDFS)中后,才會在當前agent的channel中將event洗掉,這樣只有在將事件存盤到下一個代理的通道或終端存盤庫中之后,它們才會從通道中洗掉,這種方式提供了Flume在訊息傳遞時的端到端可靠性,
7.4 可恢復性
當訊息傳遞失敗時,event由于已經暫存在channel中,可以從channel中恢復,Flume支持持久化channel(比如采用本地檔案系統作為channel),如果追求性能,也可采用memory作為channel,但這樣有可能存在資料丟失無法恢復的情況,
7.5 Flume組態檔與用法舉例
# example.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 6666
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
上面的組態檔定義了一個agent的name為a1,a1的source監聽6666埠,并且讀取6666埠傳過來的資料, a1的channel 采用記憶體作為快取,a1的sink 型別為logs,具體含義可以參考官網,或是留言,
在flume的安裝目錄下執行如下命令,即可使用flume采集資料:
$ bin/flume-ng agent -n a1 -c conf -f conf/netcat2logger.conf -Dflume.root.logger=INFO,console
flume-ng agent :表示flume的啟動一個agent,ng是表示這是new的版本命令
-n a1:-n 表示name ,a1表示agent的名字為a1 對應組態檔中的a1
-c conf :表示flume的組態檔目錄所在位置
-f conf/netcat2logger.conf: 表示自定義的資料采集組態檔位置,
-Dflume.root.logger=INFO,console:表示我們制定flume的日志格式,并且輸出到控制臺,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/374657.html
標籤:其他
上一篇:Hadoop學習筆記(3)