目錄
sparkstreaming+flume+kafka實時流式處理完整流程 一、前期準備 二、實作步驟 1.引入依賴 2.日志收集服務器 3.日志接收服務器 4、spark集群處理接收資料并寫入資料庫 5、測驗結果
sparkstreaming+flume+kafka實時流式處理完整流程 ? 一、前期準備
1、環境準備,四臺測驗服務器
spark集群三臺,hadoop02,hadoop03,hadoop04
kafka集群三臺,hadoop02,hadoop03,hadoop04
zookeeper集群三臺,hadoop02,hadoop03,hadoop04
日志接收服務器, hadoop02
日志收集流程:
日志收集服務器->日志接收服務器->kafka集群->spark集群處理
說明: 日志收集服務器,在實際生產中很有可能是應用系統服務器,日志接收服務器為大資料服務器中一臺,日志通過網路傳輸到日志接收服務器,再入集群處理,
因為,生產環境中,往往網路只是單向開放給某臺服務器的某個埠訪問的,
Flume版本:apache-flume-1.9.0-bin.tar.gz,該版本已經較好地集成了對kafka的支持
2.1 實時計算
跟實時系統類似(能在嚴格的時間限制內回應請求的系統),例如在股票交易中,市場資料瞬息萬變,決策通常需要秒級甚至毫秒級,通俗來說,就是一個任務需要在非常短的單位時間內計算出來,這個計算通常是多次的,
2.2 流式計算
通常指源源不斷的資料流過系統,系統能夠不停地連續計算,這里對時間上可能沒什么特別限制,資料流入系統到產生結果,可能經過很長時間,比如系統中的日志資料、電商中的每日用戶訪問瀏覽資料等,
2.3 實時流式計算
將實時計算和流式資料結合起來,就是實時流式計算,也就是大資料中通常說的實時流處理,資料源源不斷的產生的同時,計算時間上也有了嚴格的限制,比如,目前電商中的商品推薦,往往在你點了某個商品之后,推薦的商品都是變化的,也就是實時的計算出來推薦給你的,再比如你的手機號,在你話費或者流量快用完時,實時的給你推薦流量包套餐等,
二、實作步驟
1.引入依賴
!注意:需要與自己安裝對應版本一致
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ScalaProject</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.4.8</spark.version>
<spark.artifact.version>2.11</spark.artifact.version>
<hadoop.version>2.7.3</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${spark.artifact.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- 使用scala2.11.8進行編譯和打包 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- 引入MySQL驅動 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>${spark.version}</version>
<!--<scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
</dependency>
</dependencies>
<build>
<!-- 指定scala源代碼所在的目錄 -->
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/main/scala</testSourceDirectory>
<plugins>
<!--對src/main/java下的后綴名為.java的檔案進行編譯 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
</plugin>
<!-- scala的打包插件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.5.4</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</build>
</project>
2.日志收集服務器
配置flume動態收集特定的日志,collect.conf 配置如下:
# Name the components on this agent
a1.sources = tailsource-1
a1.sinks = remotesink
a1.channels = memoryChnanel-1
# Describe/configure the source
a1.sources.tailsource-1.type = exec
a1.sources.tailsource-1.command = tail -F /training/data/logs/1.log
a1.sources.tailsource-1.channels = memoryChnanel-1
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.memoryChnanel-1.type = memory
a1.channels.memoryChnanel-1.keep-alive = 10
a1.channels.memoryChnanel-1.capacity = 100000
a1.channels.memoryChnanel-1.transactionCapacity = 100000
# Bind the source and sink to the channel
a1.sinks.remotesink.type = avro
a1.sinks.remotesink.hostname = hadoo02
a1.sinks.remotesink.port = 6666
a1.sinks.remotesink.channel = memoryChnanel-1
注意:需創建/training/data/logs/1.log
啟動日志收集端腳本:
bin/flume-ng agent --conf conf --conf-file conf/collect.conf --name a1 -Dflume.root.logger=INFO,console
3.日志接收服務器
配置flume實時接收日志,kafka-flume.conf 配置如下:
| |
#agent section
producer.sources = s
producer.channels = c
producer.sinks = r
#source section
producer.sources.s.type = avro
producer.sources.s.bind = hadoop02
producer.sources.s.port = 6666
producer.sources.s.channels = c
# Each sink's type must be defined
producer.sinks.r.type = org.apache.flume.sink.kafka.KafkaSink
producer.sinks.r.topic = flumetopic
producer.sinks.r.brokerList = hadoop02:9092,hadoop03:9092,hadoop04:9092
producer.sinks.r.requiredAcks = 1
producer.sinks.r.batchSize = 20
producer.sinks.r.channel = c1
#Specify the channel the sink should use
producer.sinks.r.channel = c
# Each channel's type is defined.
producer.channels.c.type = org.apache.flume.channel.kafka.KafkaChannel
producer.channels.c.capacity = 10000
producer.channels.c.transactionCapacity = 1000
producer.channels.c.brokerList=hadoop02:9092,hadoop03:9092,hadoop04:9092
producer.channels.c.topic=channel1
producer.channels.c.zookeeperConnect=hadoop02:2181,hadoop03:2181,hadoop04:2181
啟動接收端腳本:
bin/flume-ng agent --conf conf --conf-file conf/kafka-flume.conf --name producer -Dflume.root.logger=INFO,console
| |
4、spark集群處理接收資料并寫入資料庫 package sparkclass.sparkstreaming
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.kafka010.KafkaUtils
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.StreamingContext
import org.apache.log4j.Level
import org.apache.log4j.Logger
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.ConsumerStrategies.Subscribe
import org.apache.spark.streaming.kafka010.LocationStrategies.PreferConsistent
import java.sql.{Connection, DriverManager, PreparedStatement}
/**
* @author Administrator
*/
object KafkaDataTest1 {
def main(args: Array[String]): Unit = {
Logger.getLogger("org.apache.spark").setLevel(Level.WARN);
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.ERROR);
val conf = new SparkConf().setAppName("stocker").setMaster("local[2]")
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc, Seconds(3))
val sc1 = ssc.sparkContext
ssc.checkpoint("hdfs://hadoop02:9000/spark/checkpoint")
// Kafka configurations
val topics = Set("flumetopic")
val brokers = "hadoop02:9092,hadoop03:9092,hadoop04:9092"
val kafkaParams = Map[String,Object](
"bootstrap.servers" -> "hadoop02:9092", //從那些broker消費資料
"key.deserializer" -> classOf[StringDeserializer], //發序列化的引數,因為寫入kafka的資料經過序列化
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "test-consumer-group", //指定group.id
"auto.offset.reset" -> "latest",//指定消費的offset從哪里開始:① earliest:從頭開始 ;② latest從消費者啟動之后開始
"enable.auto.commit" -> (false: java.lang.Boolean)
//是否自動提交偏移量 offset ,默認值就是true【5秒鐘更新一次】,
// true 消費者定期會更新偏移量 groupid,topic,parition -> offset ;
// "false" 不讓kafka自動維護偏移量 手動維護偏移
)
val kafkaStream = KafkaUtils.createDirectStream[String, String]
(ssc,PreferConsistent,Subscribe[String,String](topics, kafkaParams))
val mapDStream: DStream[(String, String)] = kafkaStream.map(record =>
(record.key,record.value))
val urlClickLogPairsDStream: DStream[(String, Int)] =
mapDStream.flatMap(_._2.split(" ")).map((_, 1))
val urlClickCountDaysDStream = urlClickLogPairsDStream.reduceByKeyAndWindow(
(v1: Int, v2: Int) => {
v1 + v2
},
Seconds(30),
Seconds(3)
);
//寫入資料庫
//定義函式用于累計每個單詞出現的次數
val addWordFunction = (currentValues:Seq[Int],previousValueState:Option[Int])=>{
//通過spark內部的reduceByKey按key規約,然后這里傳入某key當前批次的Seq/List,再計算當前批次的總和
val currentCount = currentValues.sum
//已經進行累加的值
val previousCount = previousValueState.getOrElse(0)
//回傳累加后的結果,是一個Option[Int]型別
Some(currentCount+previousCount)
}
val result = urlClickLogPairsDStream.updateStateByKey(addWordFunction)
//將DStream中的資料存盤到mysql資料庫中
result.foreachRDD(
rdd=>{
val url = "jdbc:mysql://localhost:3306/hadoop?useUnicode=true&characterEncoding=UTF-8"
val user = "root"
val password = "LIUJIANG1313"
Class.forName("com.mysql.jdbc.Driver").newInstance()
//截斷資料表,將資料表原有的資料進行洗掉
var conn1: Connection = DriverManager.getConnection(url,user,password)
//此句是清空資料表
val sql1 = "truncate table word"
var stmt1 : PreparedStatement = conn1.prepareStatement(sql1)
stmt1.executeUpdate()
conn1.close()
rdd.foreach(
data=>{
//將資料庫資料更新為最新的RDD中的資料集
var conn2: Connection = DriverManager.getConnection(url,user,password)
val sql2 = "insert into word(wordName,count) values(?,?)"
var stmt2 : PreparedStatement = conn2.prepareStatement(sql2)
stmt2.setString(1,data._1.toString)
stmt2.setString(2,data._2.toString)
stmt2.executeUpdate()
conn2.close()
})
})
urlClickCountDaysDStream.print();
ssc.start()
ssc.awaitTermination()
}
}
5、測驗結果
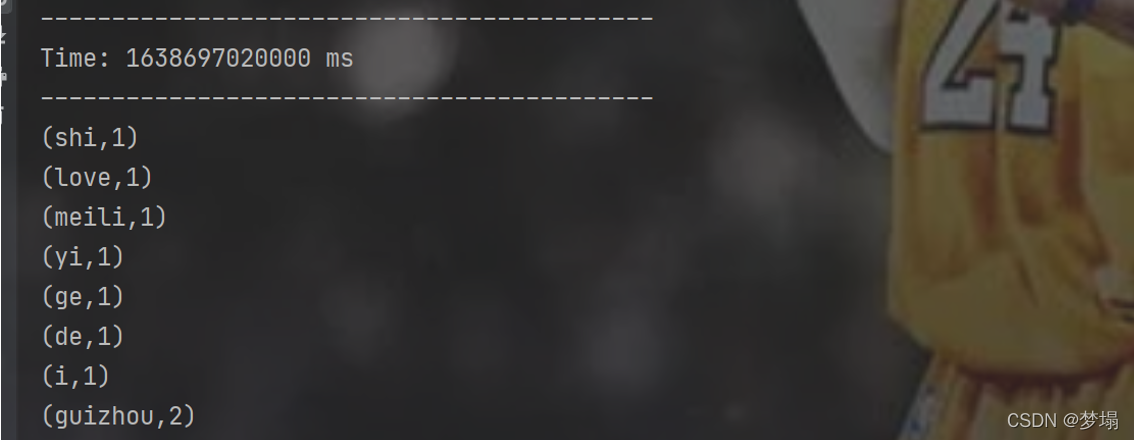
往日志中依次追加三次日志

idea運行結果
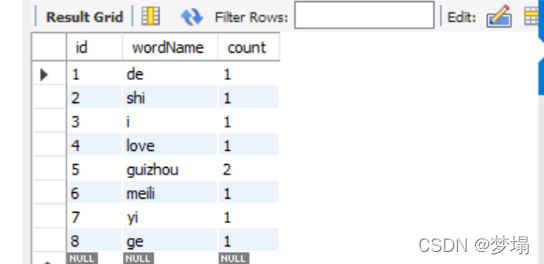
查看資料庫
| |