Introspective Distillation for Robust Question Answering 論文筆記
- 一、Abstract
- 二、引言
- 三、Related work
- 3.1 視覺問答
- 3.2 Extractive Question Answering
- 3.3 Ensemble-based methods for debiasing
- 3.4 Knowledge Distillation
- 四、內省蒸餾
- 4.1 ID-Teacher and OOD-Teacher
- 4.2 Introspection of Inductive Bias
- 4.2.1 Introspecting the bias
- 4.2.2 Weighting the bias
- 4.2.3 Distillation of Fair Knowledge
- 五、Experiments
- 5.1 Visual QA
- 5.1.1 資料集
- 5.1.2 Metric and setting
- 5.1.3 Methods
- 5.1.4 Overall results
- 5.1.5 Ablation studies
- Can we use the predicted probability of the ground-truth answer (“Prob.” for short) as the matching scores? Better not.
- Can the student learn more from the more accurate teacher, i.e. w ∝ s w\propto{s} w∝s?No.
- Can the student equally learn from ID and OOD teachers, i.e. w I D = w O O D = 0.5 w^{ID}=w^{OOD}=0.5 wID=wOOD=0.5? No.
- Can the student only learn from OOD-teacher? Yes, but worse than IntroD.
- Should we use the hard or soft variant to calculate the knowledge weights? It depends on the debiasing ability of the causal teacher.
- Can we use the ID-Prediction P I D \text{ID-Prediction} P^{ID} ID-PredictionPID as the ID-Knowledge \text{ID-Knowledge} ID-Knowledge? No.
- Can we ensemble the two teacher models and directly use that without distillation? In other words, is IntroD just an ensemble method? No.
- 5.2 Extractive QA
- 5.2.1 Dataset and settings
- 5.2.2 Metrics and method.
- 5.2.3 Results
- 六、Conclusion
- 附錄
- A1、Causal QA Model
- A2、Datasets
- A3、Training Details
- A3.1 Implementation of LMH
- A3.2 Implementation of CSS
- A3.3 Implementation of RUBi
- A3.4 Implementation of CF-VQA
- A3.5 Implementation of LM
- A4、Additional Experimental Results
- A4.1 Compared with State-of-the-art Methods
- A4.2 Evaluations on Feature Quality
- A4.3 Error Bars
- A4.4 Results on Natural Language Inference
- A5、Social Impacts
寫在前面
??這是一篇關于VQA de-bias的文章,出自獲得2021年的CCF優秀博士論文之一的牛玉磊大神,之前有一篇CF-VQA也是這位大佬的作業,本文看問題角度與其他方法不一樣,結合了知識蒸餾的部分,不知道咋想出來的?
- 論文地址:Introspective Distillation for Robust Question Answering
- 代碼地址:Github,開源了但沒完全開~
- 收錄于:NeurIPS 2021
一、Abstract
??開始點出語言bia普遍存在于QA模型中,引出本文的VQA和閱讀理解任務,接著指出現有的de-bias的方法精度高的原因:提前知道了測驗集資料的分布,換句話說,能夠利用測驗集的bias,本文提出一種新穎的de-bias方法——IntroD,能夠在這兩種任務中發揮出最大的作用,本文主要貢獻在于通過introspecting內省是否訓練樣本符合ID的事實或者OOD的事實,從而融合ID和OOD的bias,實驗在VQAv2,CPv2,SQuAD資料集進行,在犧牲少量精度的情況下,能夠維持OOD的性能,甚至超過了之前的那些no-bias方法,
二、引言
??引入問答的基礎概念→模型利用資料集中的bias→在out-of-distribution(OOD)的資料分布中性能下降→本文認為雖然有一些方法提升了ID和OOD的性能,但是源于大部分的模型都存在假設:訓練和測驗分布非常不同甚至完全相反,所以模型可能在ID內面臨嚴重的性能下降?能解釋通嗎?理論上可以,因為這些方法降低了原來模型在ID內的性能,這就引出本文的主題了,能夠使得模型同時在ID和OOD分布上的精度都很高嗎?下圖為作者給出的證據:

??接下來突出本文的核心,建立一個魯棒性的模型能夠同時在ID和OOD上保持足夠的精度,而這一點使得作者認為模型需要公平的利用這兩種分布的bias,因此,作者提出introD來融合/混合這兩種bias,
??綜的框架:兩種專家模型:ID-教師,OOD-教師,每一個教師負責捕捉相應的bias,再蒸餾出一個內省學術來學習這兩類教師,而這存在三種情況:
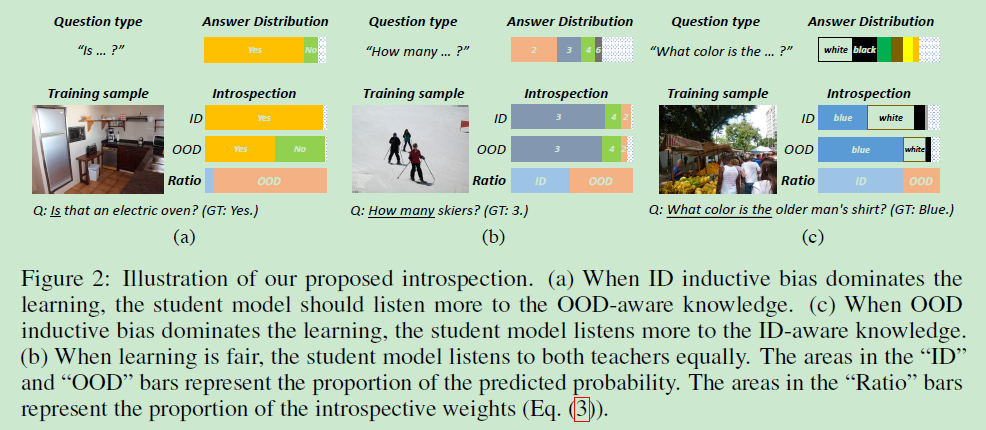
- 如果ID-bias > OOD-bias, 那么 ID-teacher < OOD-teacher,即ID教師過擬合,所以學生需要從OOD教師中學到更多,
這種情況存在于ID教師的損失<OOD教師的損失時,即上圖a所示, - 如果ID-bias < OOD-bias, 那么 ID-teacher > OOD-teacher,即OOD教師過擬合,所以學生需要從ID教師中學到更多,
這種情況存在于ID教師的損失<OOD教師的損失時,即上圖c所示, - 如果ID-bias ≈ OOD-bias, 那么 ID-teacher ≈ OOD-teacher,即兩個教師正常擬合,所以學生需要同等地學習兩位教師,
這種情況存在于ID教師的損失≈ OOD教師的損失時,即上圖b所示,
接下來就是講的蒸餾了,在這部分之前,主要問題就是教師模型的獲得,特別是OOD的教師,因為OOD分布在訓練程序中不可視,然后作者也是用了自己之前發表的文章內容,即反事實VQA,CF-VQA,根據因果模型來進行反事實推理,從而想象出未知的OOD分布,從而獲得OOD教師模型,另外,作者表明:本文方法成功的來源之處在于因果反省,而非簡單的ensemble嵌入,
三、Related work
3.1 視覺問答
??概念的介紹→bias的存在→VQA-CP資料集→影響VQAv2資料集的精度,目前仍有待解決,
3.2 Extractive Question Answering
??該任務旨在回答所給自然語言背景關系(段落)的問題,同時是個位置預測的分類問題,因此這種分類問題也存在bias,從而引入資料集SQuAd用于評估語言模型是否存在位置bias,
3.3 Ensemble-based methods for debiasing
??該方法顯式地構建并包含了捷徑bias,這種捷徑能夠通過一個單獨的分支或者統計先驗進行捕捉,這些方法雖在OOD的分布上取得了很高的精度,但是在ID分布上確是降低了很多精度,原因在于這些方法是根據訓練集和測驗集的分布有著完全不同甚至相反的比例這種假設來進行訓練的,本文采用之前提出的CF-VQA和ID-OOD教師模型,實作了ID-OOD評估的平衡,
3.4 Knowledge Distillation
??知識蒸餾將教師的知識蒸餾到一個小型的學生模型上,本文提出的Introspection反省與自蒸餾相關,只不過自蒸餾是將學生模型自身作為下一次訓練中的教師,其不同之處:自蒸餾仍處于ID分布內,并不存在對于看見的事實或者看不見的反事實進行比較推理,這也是為啥本文的自反省引入了融合/混血知識而不是直接copy自蒸餾,另外有一點不同在于本文的蒸餾并未使用一個固定的權重超引數,而是基于反省角度的權重,并不需要額外的超引數選擇,
四、內省蒸餾
??輸入為視徑訓者自然文本 C = c , Q = q C=c,Q=q C=c,Q=q,QA模型旨在產生答案 A = a A=a A=a,本質為多分類問題,即 a ∈ A a\in \mathbb{A} a∈A,作者提出的IntroD旨在平等地融合ID和OOD-bias,該方法由三個模塊組成:
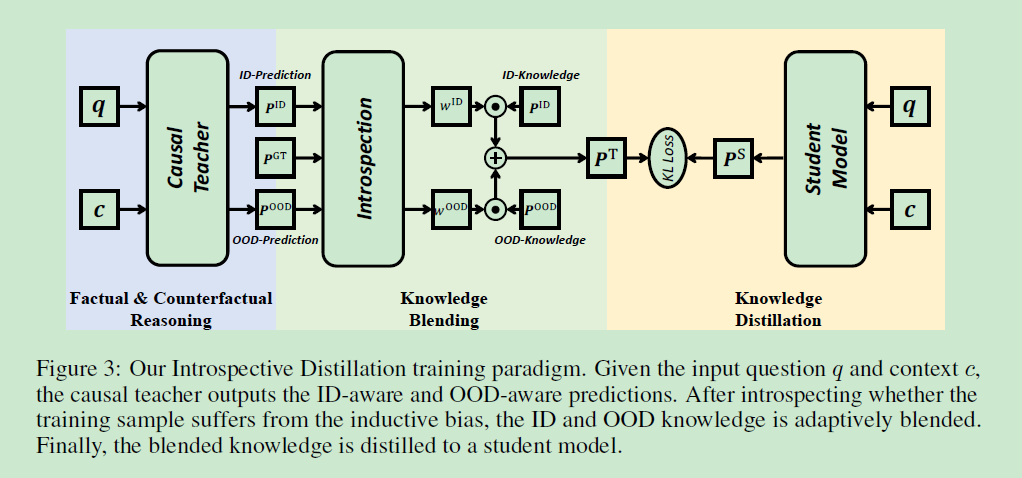
- casual teacher:用于捕捉ID和OOD-bias
- introspection:用于融合/混合這兩種不同的bias
- distillation:用于蒸餾出魯棒性的學生模型
4.1 ID-Teacher and OOD-Teacher
??由于無法得到OOD分布,所以沒辦法得到OOD教師模型,這里引入CF-VQA方法,采用反事實推理得到OOD教師模型,同時ID教師也能近似地通過事實推理使用相同的casual模型來得到,
??根據反事實推理,casual模型能夠想象出OOD分布,因此使用相同的casual模型部署ID和OOD教師,通過事實推理,casual模型能夠預測出答案
P
I
D
P^{ID}
PID,該答案包含了ID-bias;通過反事實推理,casual模型能夠估計直接的影響來排除掉bias,并產生反事實的預測
P
O
O
D
P^{OOD}
POOD,即,非直接的影響或者自然的非直接的影響反映著看不見的OOD分布,教師模型采用交叉熵損失在ID資料上訓練,并未分別訓練ID和OOD教師模型,
4.2 Introspection of Inductive Bias
?? Introspection 模塊首先測驗是否模型過度利用了ID或者OOD的bias,如果ID-bias主導了學習,那么學生模型就應該傾向于OOD的教師模型,因此引出兩個問題,如何定義“主導”和“更傾向”,換句話說,如何反省和權衡這兩種bias,
4.2.1 Introspecting the bias
??通過比較ID和OOD教師的預測來反省bias的影響,如果ID內的主導了樣本的學習,那么ID教師的置信度將會大于OOD教師的,用公式表示如下:
s
I
D
=
∑
a
∈
A
G
T
P
I
D
(
a
)
,
s
O
O
D
=
∑
a
∈
A
G
T
P
O
O
D
(
a
)
,
s^{\mathrm{ID}}=\sum_{a \in \mathcal{A}^{\mathrm{GT}}} P^{\mathrm{ID}}(a), \quad s^{\mathrm{OOD}}=\sum_{a \in \mathcal{A}^{\mathrm{GT}}} P^{\mathrm{OOD}}(a),
sID=a∈AGT∑?PID(a),sOOD=a∈AGT∑?POOD(a),
其中
A
G
T
\mathcal{A}^{\mathrm{GT}}
AGT為gt answer,
S
S
S得分反映了訓練樣本與bias的契合程度,如果
s
I
D
>
s
O
O
D
s^{\mathrm{ID}}>s^{\mathrm{OOD}}
sID>sOOD,那么樣本的學習由ID-bias主導反之亦然,接下來就是
s
I
D
,
s
O
O
D
s^{\mathrm{ID}},s^{\mathrm{OOD}}
sID,sOOD的確定了,表示如下:
s
I
D
=
1
X
E
(
P
G
T
,
P
I
D
)
=
1
∑
a
∈
A
?
P
G
T
(
a
)
log
?
P
I
D
(
a
)
,
s
O
O
D
=
1
X
E
(
P
G
T
,
P
O
O
D
)
=
1
∑
a
∈
A
?
P
G
T
(
a
)
log
?
P
O
O
D
(
a
)
,
\begin{aligned} s^{\mathrm{ID}} &=\frac{1}{X E\left(P^{\mathrm{GT}}, P^{\mathrm{ID}}\right)}=\frac{1}{\sum_{a \in \mathcal{A}}-P^{\mathrm{GT}}(a) \log P^{\mathrm{ID}}(a)}, \\ s^{\mathrm{OOD}} &=\frac{1}{X E\left(P^{\mathrm{GT}}, P^{\mathrm{OOD}}\right)}=\frac{1}{\sum_{a \in \mathcal{A}}-P^{\mathrm{GT}}(a) \log P^{\mathrm{OOD}}(a)}, \end{aligned}
sIDsOOD?=XE(PGT,PID)1?=∑a∈A??PGT(a)logPID(a)1?,=XE(PGT,POOD)1?=∑a∈A??PGT(a)logPOOD(a)1?,?其中
P
G
T
P^{GT}
PGT為真實標簽,采用交叉熵來訓練比之前的相加效果要好,
4.2.2 Weighting the bias
??利用知識的權重求和來融合/混合ID和OOD的知識,目的在于公平的混合ID或者OOD的bias,因此就有前面說的三種情況,如果
s
I
D
>
s
O
O
D
s^{\mathrm{ID}}>s^{\mathrm{OOD}}
sID>sOOD,那么學生模型就應該從OOD教師模型中學習的更多,因此就要增加
w
O
O
D
w^{OOD}
wOOD,使得
w
O
O
D
>
w
I
D
w^{OOD}>w^{ID}
wOOD>wID,類似的,當
s
I
D
<
s
O
O
D
s^{\mathrm{ID}}<s^{\mathrm{OOD}}
sID<sOOD,則要令
w
O
O
D
<
w
I
D
w^{OOD}<w^{ID}
wOOD<wID,而相應的知識權重需要設定成與得分相反的比例,即
w
∝
s
?
1
w\propto{s}^{-1}
w∝s?1,本文通過尺度將權重縮放至0,1:
w
I
D
=
(
s
I
D
)
?
1
(
s
I
D
)
?
1
+
(
s
O
O
D
)
?
1
=
s
O
O
D
s
I
D
+
s
O
O
D
,
w
O
O
D
=
1
?
w
I
D
=
s
I
D
s
I
D
+
s
O
O
D
w^{\mathrm{ID}}=\frac{\left(s^{\mathrm{ID}}\right)^{-1}}{\left(s^{\mathrm{ID}}\right)^{-1}+\left(s^{\mathrm{OOD}}\right)^{-1}}=\frac{s^{\mathrm{OOD}}}{s^{\mathrm{ID}}+s^{\mathrm{OOD}}}, \quad w^{\mathrm{OOD}}=1-w^{\mathrm{ID}}=\frac{s^{\mathrm{ID}}}{s^{\mathrm{ID}}+s^{\mathrm{OOD}}}
wID=(sID)?1+(sOOD)?1(sID)?1?=sID+sOODsOOD?,wOOD=1?wID=sID+sOODsID?
??作者之后利用CF-VQA作為教師模型繪制出了VQA-CPv2及VQAv2訓練資料集的
w
I
D
w^{ID}
wID分布情況:
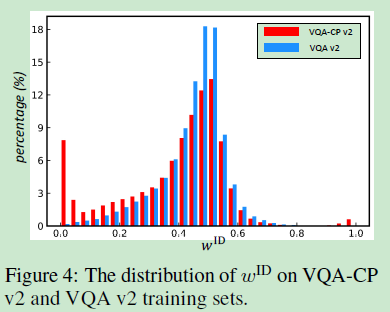
??對于上圖來說,
w
I
D
w^{ID}
wID越小則說明ID-bias越大,對上圖的三種觀察發現:
- 所有資料集的 w I D w^{ID} wID在0.5左右,說明大多數樣本仍然可以無bias的學習預測,
- 所有的資料集bias分布都呈現一種左偏的趨勢,隨著 w I D w^{ID} wID在0.5范圍內減小,兩種資料集的差異越發明顯,這表明了VQA模型傾向于利用VQA-CPv2中不平衡的bias,而不是平衡的樣本部分,換句話說,VQA-CP資料集是在鼓勵模型學習語言bias(這也是在佐證作者提出的觀點),在沒有這些記憶先驗的情況下,VQA模型無法正確回答極端情況下的問題,
作者也定義了一種stochastic hard variant(隨機硬變體?)來加權bias:
w
I
D
=
{
1
,
if
s
I
D
≤
s
O
O
D
0
,
otherwise
w^{\mathrm{ID}}=\left\{\begin{array}{ll} 1 & , \text { if } s^{\mathrm{ID}} \leq s^{\mathrm{OOD}} \\ 0 & , \text { otherwise } \end{array}\right.
wID={10?, if sID≤sOOD, otherwise ?
??這樣一種公式使得學生模型能夠完整學習OOD教師模型中的大多數樣本并維持其OOD性能,接下來,融合/混合這兩種知識:
P
T
=
w
I
D
?
ID-Knowledge
+
w
OOD
?
OOD-Knowledge.
P^{\mathrm{T}}=w^{\mathrm{ID}} \cdot \text{ ID-Knowledge }+w^{\text {OOD }} \cdot \text { OOD-Knowledge. }
PT=wID? ID-Knowledge +wOOD ? OOD-Knowledge. 其中
ID-Knowledge
\text { ID-Knowledge }
ID-Knowledge 為gt lables
P
G
T
P^{GT}
PGT,
ID-Knowledge
\text { ID-Knowledge }
ID-Knowledge 為OOD預測
P
O
O
D
P^{OOD}
POOD的近似,
4.2.3 Distillation of Fair Knowledge
??學生模型的訓練:
L
=
K
L
(
P
T
,
P
S
)
=
∑
a
∈
A
P
T
(
a
)
log
?
P
T
(
a
)
P
S
(
a
)
\mathcal{L}=K L\left(P^{\mathrm{T}}, P^{\mathrm{S}}\right)=\sum_{a \in \mathcal{A}} P^{\mathrm{T}}(a) \log \frac{P^{\mathrm{T}}(a)}{P^{\mathrm{S}}(a)}
L=KL(PT,PS)=a∈A∑?PT(a)logPS(a)PT(a)?其中
P
S
P^{S}
PS為學生模型,例如UpDn,BERT等模型,與學生模型不同,教師模型還嵌入了一個單獨的分支來構成捷徑bias,所以相比于casual教師模型,學生模型能夠更有效的利用引數和推理速度,在蒸餾時固定casual模型,僅更新學生模型,
五、Experiments
5.1 Visual QA
5.1.1 資料集
??VQA v2;VQA-CP v2
5.1.2 Metric and setting
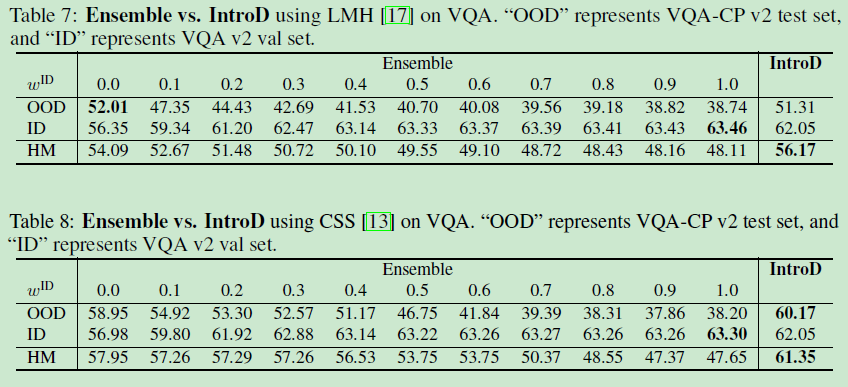
??采用標準的VQA評估方法,采用兩種設定,ID→VQA v2,OOD→VQA-CP test,還有在VQA-CP v2測驗集上及VQA v2驗證集上的HM調和平均數,
5.1.3 Methods
??反事實教師:RUBi,LMH,CSS,CF-VQA
??Backbone:UpDn,S-MRL
??軟變體(soft variant)權重:LMH,CSS,RUBi-CF,CF-VQA
??硬變體(hard variant)權重:RUBi
5.1.4 Overall results

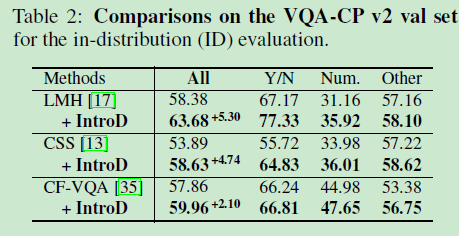
5.1.5 Ablation studies
??本文的消融實驗旨在解決下列問題:
Can we use the predicted probability of the ground-truth answer (“Prob.” for short) as the matching scores? Better not.
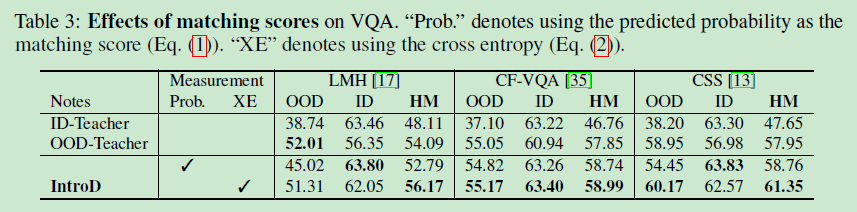
??對比2,3列,劃不來,
Can the student learn more from the more accurate teacher, i.e. w ∝ s w\propto{s} w∝s?No.
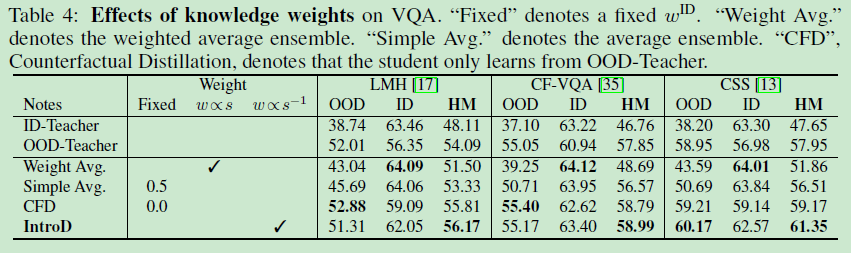
Can the student equally learn from ID and OOD teachers, i.e. w I D = w O O D = 0.5 w^{ID}=w^{OOD}=0.5 wID=wOOD=0.5? No.
??如上圖,
Can the student only learn from OOD-teacher? Yes, but worse than IntroD.
??如上圖,
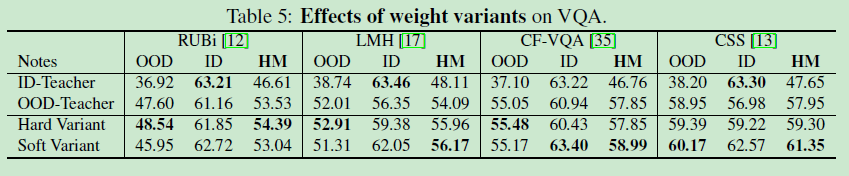
Should we use the hard or soft variant to calculate the knowledge weights? It depends on the debiasing ability of the causal teacher.
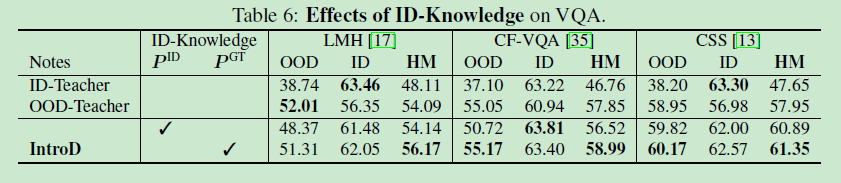
Can we use the ID-Prediction P I D \text{ID-Prediction} P^{ID} ID-PredictionPID as the ID-Knowledge \text{ID-Knowledge} ID-Knowledge? No.
Can we ensemble the two teacher models and directly use that without distillation? In other words, is IntroD just an ensemble method? No.
5.2 Extractive QA
5.2.1 Dataset and settings
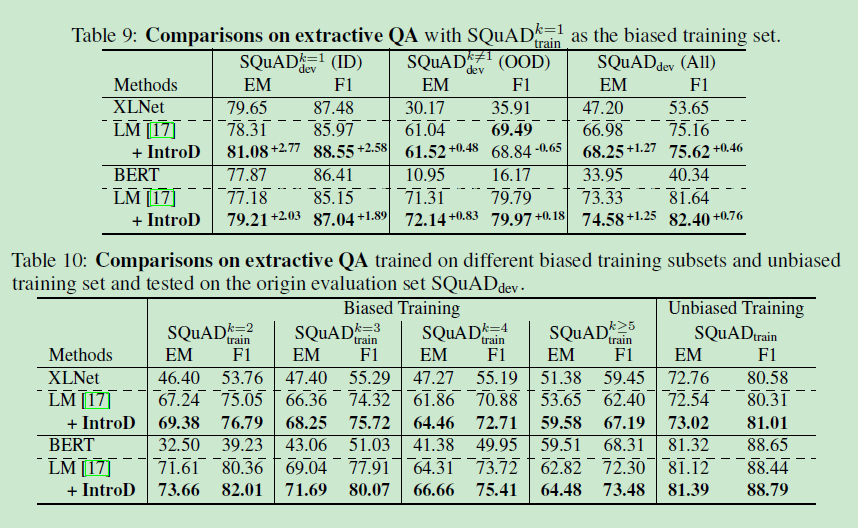
??SQuAD
5.2.2 Metrics and method.
??exact match (EM) 、F1 score
??Backbone:XLNet、BERT
??casual教師:LM
??知識權重計算:hard variant硬變體
5.2.3 Results
六、Conclusion
??本文提出了IntroD,在ID和OOD-bias分布上能夠平衡bias,采用VQA和extract QA評估本文的方法,大致步驟為采用casual教師來評估ID和OOD的bias,然后內省是否這兩種bias主導了學資訊,之后公平的融合/混合這兩種bias,并將其蒸餾到學生模型上,實驗證明效果很高,IntroD的主要限制在于OOD的性能極度依賴于OOD教師模型,
附錄
A1、Causal QA Model
??推薦查看CF-VQA論文
A2、Datasets
??VQA和Extract QA資料集的介紹
A3、Training Details
A3.1 Implementation of LMH
??RTX 2080Ti, Batch 512,
A3.2 Implementation of CSS
??RTX 2080Ti, Batch 512,
A3.3 Implementation of RUBi
??RTX 2080Ti, Batch 256,22Epoch, l r = 1.5 × 1 0 ? 4 , 6 × 1 0 ? 4 lr=1.5\times10^{-4},6\times10^{-4} lr=1.5×10?4,6×10?4 7epoch,14個epoch x0.25/2epoch
A3.4 Implementation of CF-VQA
??RTX 2080Ti, Batch 256,
A3.5 Implementation of LM
2個RTX 2080Ti, Batch 10,12, l r = 3 × 1 0 ? 5 lr=3\times10^{-5} lr=3×10?5
A4、Additional Experimental Results
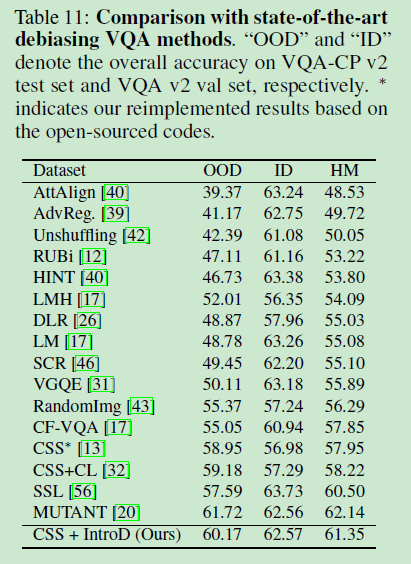
A4.1 Compared with State-of-the-art Methods
A4.2 Evaluations on Feature Quality
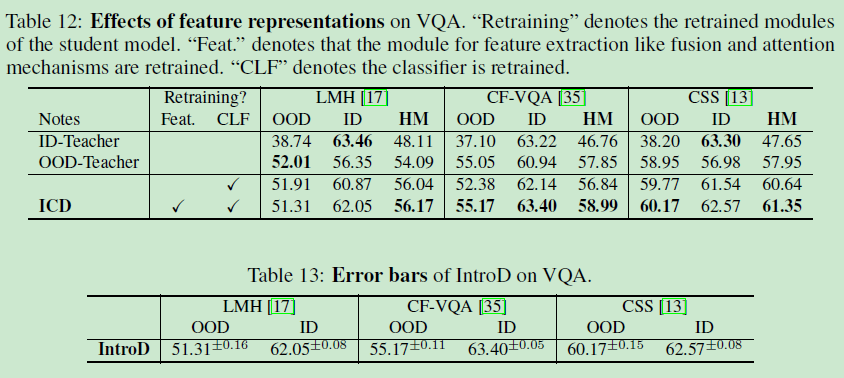
A4.3 Error Bars
??表13,
A4.4 Results on Natural Language Inference
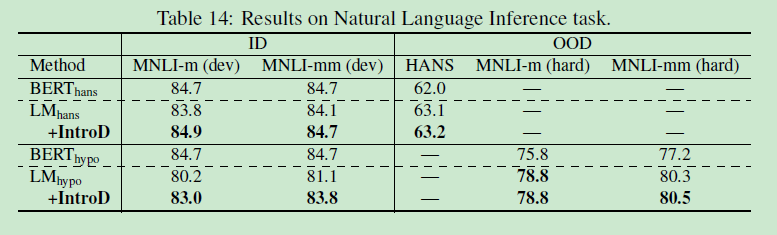
A5、Social Impacts
??提出的方法使得VQA模型更魯棒,但是非端到端的方法比較耗時,
寫在后面
??本文為消除VQA任務中的bias提供了另一種角度,不光只是在VQA-CPv2資料集上進行試驗,同時也在VQAv2上進行對比實驗,角度新奇,另外作者用了之前發表的文章,使得本文一脈相承,確實思路很好,缺點作者也說了方法需要兩段式訓練,費時,另外我個人吐槽下,文中這些對比實驗真的寫的比較繁瑣,有點頭大😅,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375064.html
標籤:其他
上一篇:【OpenCV-Python】3.OpenCV的影像基礎操作
下一篇:【論文總結】Damage-Map Estimation Using UAV Images and Deep Learning Algorithms for DMS