文章目錄
前言
一、論文簡介
二、研究的資料集及其處理
1.文章研究使用的原始資料
2.對資料進行的預處理
三.文章提出的網路模型
1.文章提出的模型方法
2.UNet與UNet++
UNet
UNet++
3.損失函式與評估指標
損失函式
評估指標
四.文章提出模型的性能
本文得出的結論
本文提出存在的限制
總結與思考
前言
最近精讀了一篇關于使用語意分割的方法對災害管理系統中無人機采集影像的受災損傷區域進行估計的論文,對此做個總結
論文地址:Remote Sensing | Free Full-Text | Damage-Map Estimation Using UAV Images and Deep Learning Algorithms for Disaster Management System
一、論文簡介
論文主要介紹了一種語意分割的方法,用于對無人機拍攝的火災后的現場圖片進行處理,估計森林火災后的受損區域;文章使用了2020年韓國一場火災后搜集的圖片作為資料集,使用two-patch-level的分割方法,patch-level 1 采用UNet++并使用FL損失,patch-level 2采用UNet并使用BCE損失,最高可以達到0.7639的dicecoefficients,
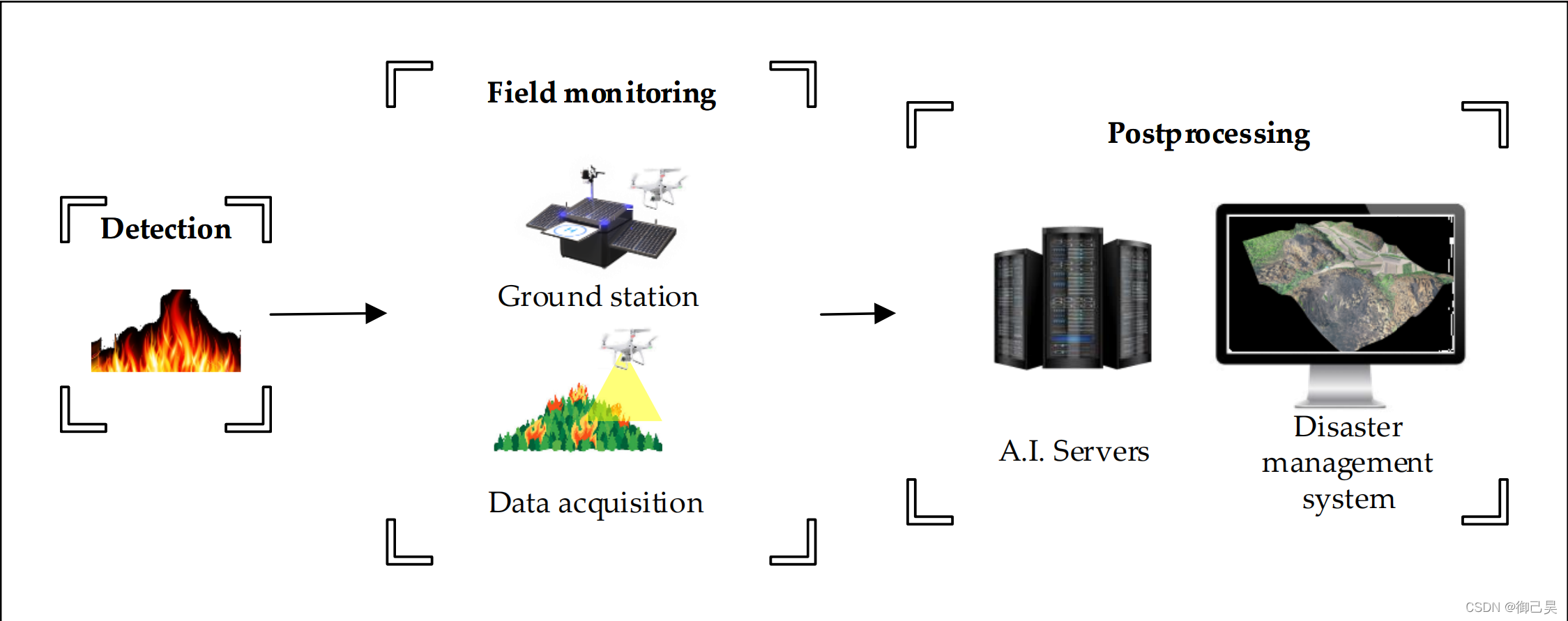
圖1:基于無人機(UAV)的森林火災監測系統的概念框架
二、研究的資料集及其處理
1.文章研究使用的原始資料
資料采集時間地點:2020年5月6日,在一場森林火災兩周后,從朝鮮慶尚北部的安東收集
無人機型號:Phantom 4 Pro V2.0 UAV
無人機拍攝高度:150m
原始影像解析度大小:5473 x 3648 x 3
資料集數量:采集了火災地區兩個區域的影像,區域一43張,區域二44張
采用的資料增強(對第一次剪裁后的影像):歸一化、旋轉、縮放、移位
2.對資料進行的預處理
因為高解析度的影像訓練起來較為困難,文章研究者先對它進行了裁剪,將區域一的43張5473 x 3648 x 3的圖片被裁剪成了1032張912 x 912 x 3的圖片,區域二的44張5473 x 3648 x 3的圖片裁剪成了1056張912 x 912 x 3的圖片,并對裁剪后的圖片進行標注,

圖二:裁剪前的影像

圖三:裁剪后的影像

圖四:對裁剪后的影像標注
三.文章提出的網路模型
1.文章提出的模型方法
(1)將被剪裁好的912 x 912 x 3影像輸入UNet++網路,得到912 x 912 x 1的預測結果;
(2)依據petch-level 1預測的結果,選取要用于petch-level 2 的128 x 128 x 3 影像和128 x 128 x 1的標注(如果筆者沒理解錯,那么原論文里的圖片即下圖是不嚴謹的,并不是把level 1的結果直接剪裁輸入)
Q:這里面128 x 128 x 3的影像是直接從912 x 912 x 3影像上裁剪而來,文章里說的不清楚,看了源代碼后發現他是類似使用一個228 x 228的滑動視窗來遍歷level 1的預測結果,只要這個視窗內只要存在被判斷為燒焦區域的像素就把從912 x 912圖片剪裁后的圖片(128 x 128)編號加入,源代碼里是直接用了兩個用絕對路徑表示的檔案夾,檔案里存放著圖片合lebel,筆者猜測是不是文章作者提前分割好了圖片和標注并按照分割順序編號,然后再來選取level 2需要的圖片,但是原碼里面每次篩選像素的視窗大小是228 x 228,為什么要用228大小的視窗而不是128的視窗,筆者這里還比較疑惑,
(3)將選取好的128 x 128 x 3的影像輸入UNet,輸出為128 x 128 x 1的預測結果,依據預測結果將輸入影像合并調整成5472 x 3648 x 3的RGB影像,即與無人機拍攝的影像shape一樣,
(4)將得到的影像上傳到DroneDeploy 平臺上進行正光生成和進一步處理,得到災害管理系統(DMS)需要的影像,
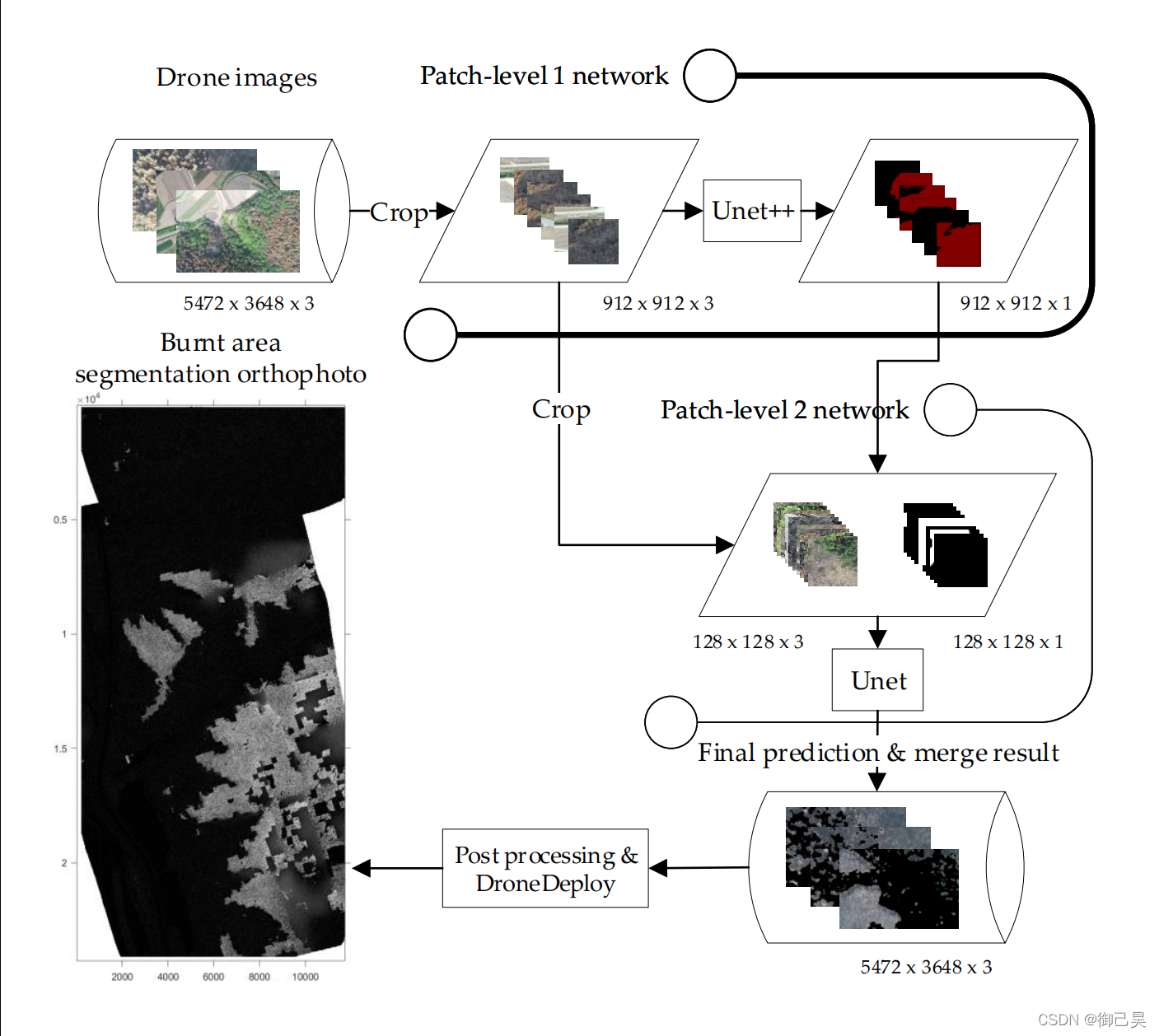
圖五:文章提出的模型結構
2.UNet與UNet++
本部分參考:【Unet系列】Unet & Unet++_OneCoder的博客-CSDN博客
UNet
- 使用的方法?
- 繼承FCN的思想,繼續進行改進,但是相對于FCN,有幾個改變的地方,U-Net是完全對稱的,且對解碼器(應該自Hinton提出編碼器、解碼器的概念來,即將影像->高語意feature map的程序看成編碼器,高語意->像素級別的分類score map的程序看作解碼器)進行了加卷積加深處理,FCN只是單純的進行了上采樣,
- Skip connection:兩者都用了這樣的結構,雖然在現在看來這樣的做法比較常見,但是對于當時,這樣的結構所帶來的明顯好處是有目共睹的,因為可以聯合高層語意和低層的細粒度表層資訊,就很好的符合了分割對這兩方面資訊的需求,
- 聯合:在FCN中,Skip connection的聯合是通過對應像素的求和,而U-Net則是對其的channel的concat程序,
- Innovation:
- overlap-tile策略
- 隨機彈性變形進行資料增強
- 使用了加權loss
- result
- 相對于當年的,在EM segmentation challenge at ISBI 2012上做到比當時的best更好,而且速度也非常的快,其有一個很好的優點,就是在小資料集上也是能做得比較好的,
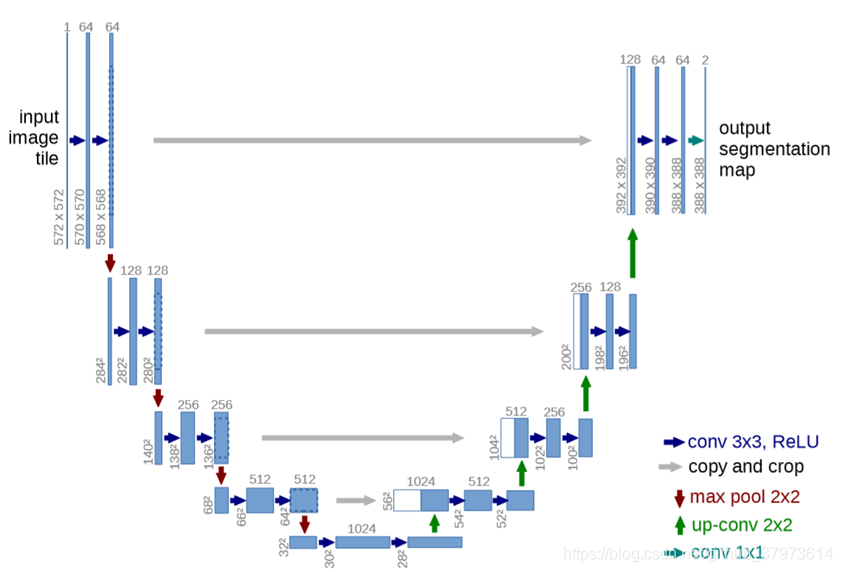
圖六:UNet結構示意圖
- 相對于當年的,在EM segmentation challenge at ISBI 2012上做到比當時的best更好,而且速度也非常的快,其有一個很好的優點,就是在小資料集上也是能做得比較好的,
UNet++
- 解決的問題?
- 對以前的論文做了一個簡短的總結:對于分割任務,都會有一個共識,就是skip connection,目前對自然影像的分割效果蠻好,對生物醫學影像的分割一般,
- 主要的原因可能還是(1)資料集的量(2)生物醫學影像相較于自然影像來說,本身分割難度大,體現在生物影像中分割目標邊界模糊、變形一類的復雜情況,
- 使用的方法?
- Unet的增強版,靈感來源于DenseNet,但實際上,在此之前有一個思想是一樣的作業,可以說是Unet的作業與其如出一轍,根據任務進行了調整而已,
- 深度監督
- result
- 想對于UNet和wide UNet(wide IOU是相對與UNet的引數增加,使其與Unet++在引數上相差無幾,減少相互對比中的不一樣的條件)各自有3.9和3.4的平均IOU的提升,
- More
- 文中提到可以將Unet++作為Mask rcnn的backbone architecture,但是文中沒有給出具體做法
- 加中間的Dense block所基于的一個假設:讓received encoder feature maps和the corresponding decoder feature maps are semantically similar,這樣會使優化器更好的優化,
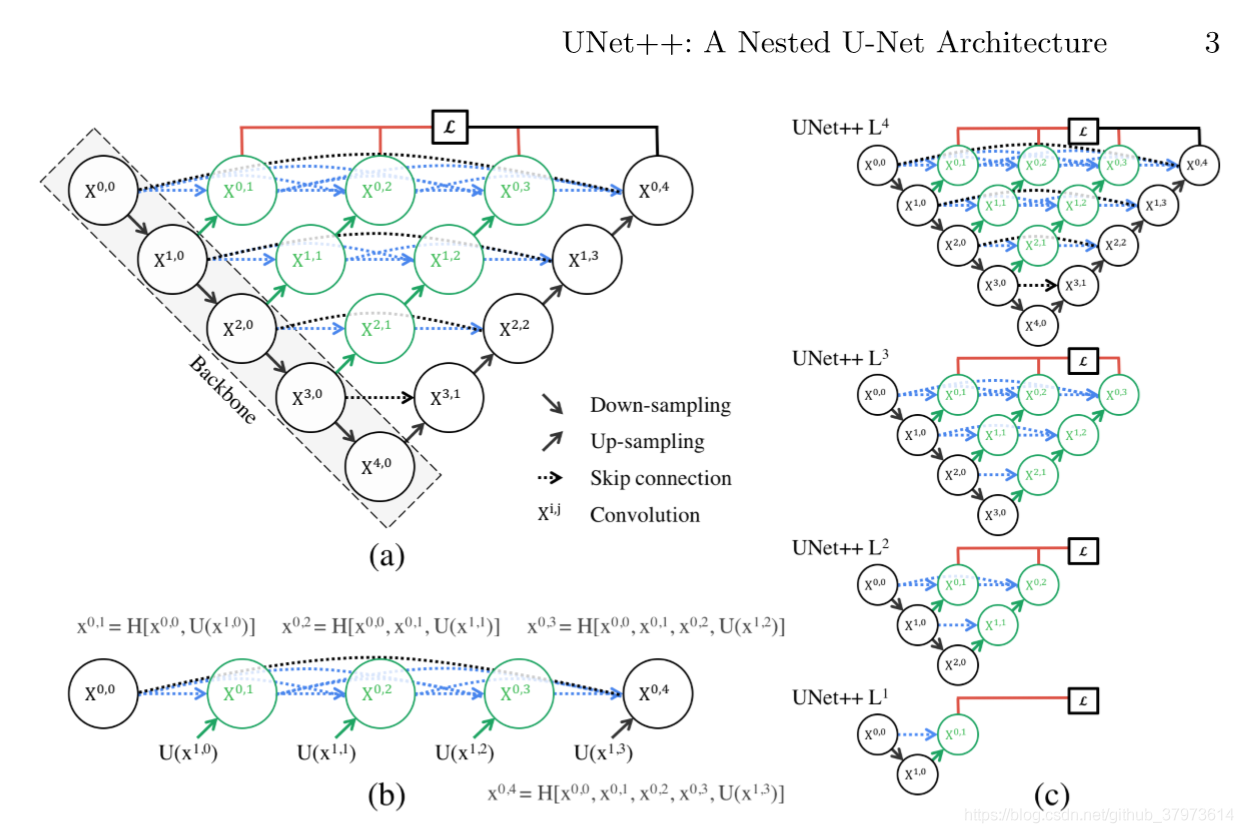
圖七:UNet++結構示意圖
3.損失函式與評估指標
損失函式
文章在petch-level 1使用了Focal Loss損失(1),petch-level 使用了Binary Cross Entropy損失(2)
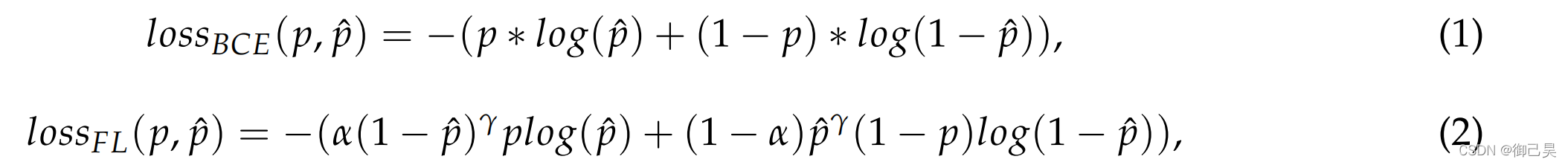
文章里比較了兩個level都使用FL損失、都使用BCE損失、兩個level分別使用其中一種損失這四種情況,發現上面提出的損失函式使用方式效果是最好的,筆者覺得可能是因為level 1的輸入因為是原始影像,存在較多資料不平衡問題,所以使用FL損失更好,而level 2的影像是經過level 1的結果篩選的,而篩選方式是預測結果存在燒焦的部分,那么level 2輸入的資料,其資料不平衡問題就不會那么突出,主要需要區分預測像素是否是被燒焦區域,那么使用二值交叉熵損失就更為合適了,
表1:損失函式有效性-在區域1上進行訓練,并在區域2上進行測驗,

表2:損失函式有效性-在區域2進行訓練,并在區域1進行測驗,

評估指標
經典的影像分割評價指標,DiceCoefficient(3)測量了真實值和預測值之間的重疊部分;Sensitivity(4)測量了在正樣本中被正確分割的像素的百分比;Specifificity(5)值測量了被預測為負樣本的準確性,
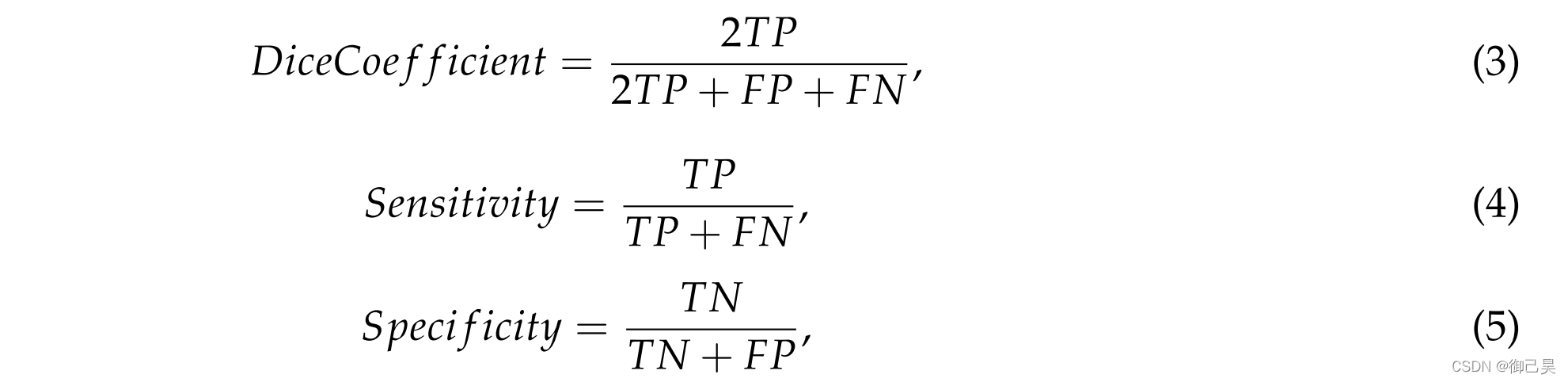
四.文章提出模型的性能
論文作者對比了只使用Patch-Level 1 Network、只使用Patch-Level 2 Network者和Patch-Level 2 Network Proposed Method,證明其性能,
使用的共同引數
優化器:Adam
學習率:0.0001
epoch:30
batch size:1
輸入的圖片大小及數量(對同一資料集使用了不同的裁剪和輸入方式)
表3:來自兩個區域的訓練影像的數量

表4:該模型在區域1上進行訓練,并在區域2上進行測驗的表現

表5:該模型在區域2上進行訓練,并在區域1上進行測驗的表現

圖八:在合并后的原始影像上得到不同模型的分割結果
本文得出的結論
1.雙補丁級模型比單影像分割模型效果更好,同時對于農場道路這種易混淆難分割的目標分割效果更好;(作者認為petch-level 2網路可以細化第一個模型的結果,使得預測可以有更好的性能)
2.證明FL作為損失函式在優化模型和提高模型在測驗集上的性能方面的有效性;
3.介紹了一種無人機影像預處理和后處理方法,并公開,(似乎就是利用DroneDeploy平臺來處理)
本文提出存在的限制
1.雙補丁級模型需要在不同天氣條件下的不同地點進行訓練,以提高其性能;
2.該方法現在已在本地進行處理,需要將其轉換為一個在線平臺,以提高其實用性,減少其時間消耗,
總結與思考
1.從資料來看,本文使用的是火災發生后,天氣良好情況下從150m高空無人機拍攝的照片,考慮到拍攝角度位置問題,作者使用了旋轉、縮放、位移的資料增強,同時文章提出該模型需要在不同天氣下進行訓練,但如果在資料集有限的情況下,應對這種情況,還可以嘗試采用ColorJitter,對影像顏色的對比度、飽和度、亮度、色相等進行變換;
2.文章只對比了UNet,UNet++,和他們組合使用的效果,但是使用資料的解析度和數量都不一樣,這種比對的合理性有待考察(相同資料集不同處理方式,如果使用了相同的處理方式又是什么樣呢);另外作者沒有解釋為什么petch-level 1用UNet++,但是level 2就用了UNet,如果使用UNet++效果會不會更好呢,還有文章對比的UNet++只輸入了一千張左右的高解析度照片,如果把裁剪成128 x 128 x 3后的一萬多張小照片再放進去對比又是什么樣的呢;
3.作者對于level 1到 level 2過度這一塊講的比較模糊,只說是依據level 1的結果選出存在燒焦預測值小區域輸入到level 2,但是這里面如何再次分割和編號沒有說明,同時level 使用的lebel是直接使用原始lebel分割,還是結合了第一次的預測結果進行了處理呢,源代碼里面使用了兩個突然出現的絕對路徑的檔案夾,這里面的檔案是否是提前分割好的還無從查證;
4.感覺本篇文章的作者對演算法的描述都不算很詳細(或者說本文的創新點不在于演算法而是在于對資料的使用?),像如何進一步分割和合并預測結果這些細節都是一筆帶過,同時也沒有公開它的資料集,也沒有說明它采用的預訓練權重是什么,文章里沒有提到,源代碼里是直接呼叫絕對路徑里的檔案,如果要想把本篇論文的代碼放入實際應用之中,還有很多細節要解決,
PS:這是筆者寫的第一篇博客,對于計算機視覺方向筆者也只是個新手,如果有不對的地方,還請大家批評指正,也歡迎各位一起討論,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375067.html
標籤:其他
上一篇:Introspective Distillation for Robust Question Answering 論文筆記