文章目錄
- 第三周作業 - 帶有一個隱藏層的平面資料分類
- 一、加載和查看資料集
- 二、構建神經網路的一般方法是:
- 2.1定義神經網路結構
- 2.2 初始化模型的引數
- 2.3 回圈
- 2.3.1 前向傳播
- 2.3.2計算損失
- 2.3.3 向后傳播
- 2.3.4更新引數
- 整合
- 三、預測
- 正式運行
- 探索:
- 1.更改隱藏層節點數量
- 2.當改變sigmoid激活或ReLU激活的tanh激活時會發生什么?
- 3.改變learning_rate的數值會發生什么
- 4.如果我們改變資料集呢?
第三周作業 - 帶有一個隱藏層的平面資料分類
我們簡單說一下我們要做什么,我們要建立一個神經網路,它有一個隱藏層,你會發現這個模型和上一個邏輯回歸實作的模型有很大的區別,
實作:
構建具有單隱藏層的2類分類神經網路,
使用具有非線性激活功能激活函式,例如tanh,
計算交叉熵損失(損失函式),
實作向前和向后傳播,
numpy:是用Python進行科學計算的基本軟體包,
sklearn:為資料挖掘和資料分析提供的簡單高效的工具,
matplotlib :是一個用于在Python中繪制圖表的庫,
testCases:提供了一些測驗示例來評估函式的正確性,參見下載的資料或者在底部查看它的代碼,
planar_utils :提供了在這個任務中使用的各種有用的功能,參見下載的資料或者在底部查看它的代碼,
import numpy as np
import matplotlib.pyplot as plt
from testCases import *
import sklearn
import sklearn.datasets
import sklearn.linear_model
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset, load_extra_datasets
%matplotlib inline #如果你使用用的是Jupyter Notebook的話請取消注釋,
np.random.seed(1) #設定一個固定的隨機種子,以保證接下來的步驟中我們的結果是一致的,
一、加載和查看資料集
首先,我們來看看我們將要使用的資料集, 下面的代碼會將一個花的圖案的2類資料集加載到變數X和Y中,
X,Y = load_planar_dataset()
#把資料集加載完成了,然后使用matplotlib可視化資料集,代碼如下:
plt.scatter(X[0,:],X[1,:],c=Y,s=40,cmap=plt.cm.Spectral) ##繪制散點圖
#X包含了這些資料的數值
#Y標簽 紅色 y=0,藍色 y=1
#s=40,表示散點的大小為40,可以輸入與樣本數量相同的串列,表示不同點的不同大小;
# c=y,c表示顏色,可以使用c='b’這樣的命令將所有散點表示為同一顏色,
# 也可以是一個與樣本數量相同的序列,因為y中的取值有兩個(0或1),
# 散點根據y的索引表示為兩種不同的顏色用以區分不用類別;
# cmap表示Colormap物體或者是一個colormap的名字,cmap =
# plt.cm.Spectral實作的功能是給label為1的點一種顏色,給label為0的點另一種顏色,
shape_X = X.shape
shape_Y = Y.shape
m = Y.shape[1] # 訓練集里面的數量
print ("X的維度為: " + str(shape_X))
print ("Y的維度為: " + str(shape_Y))
print ("資料集里面的資料有:" + str(m) + " 個")
#X - 維度為(n_x,m)的輸入資料, 所以這里輸入為2
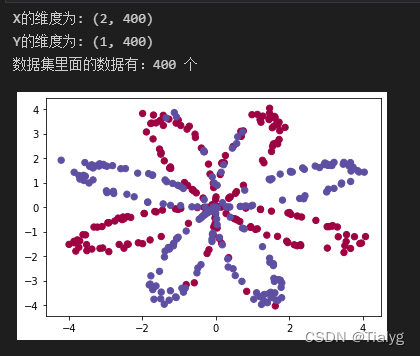
在構建完整的神經網路之前,先讓我們看看邏輯回歸在這個問題上的表現如何,我們可以使用sklearn的內置函式來做到這一點, 運行下面的代碼來訓練資料集上的邏輯回歸分類器,
clf = sklearn.linear_model.LogisticRegressionCV() #邏輯回歸
clf.fit(X.T,Y.T)
#lambda x: clf.predict(x), 輸入為x,輸出為clf.predict(x)
plot_decision_boundary(lambda x: clf.predict(x), X, Y) #繪制決策邊界 # 預測X, Y對應坐標
plt.title("Logistic Regression") #圖示題
LR_predictions = clf.predict(X.T) #預測結果
print ("邏輯回歸的準確性: %d " % float((np.dot(Y, LR_predictions) +
np.dot(1 - Y,1 - LR_predictions)) / float(Y.size) * 100) +
"% " + "(正確標記的資料點所占的百分比)")
#準確性只有47%的原因是資料集不是線性可分的,所以邏輯回歸表現不佳,現在我們正式開始構建神經網路,
二、構建神經網路的一般方法是:
1.定義神經網路結構(輸入單元的數量,隱藏單元的數量等),
2.初始化模型的引數
3.回圈:
3.1實施前向傳播
3.2計算損失
3.3實作向后傳播
3.4更新引數(梯度下降)
我們要它們合并到一個nn_model() 函式中,當我們構建好了nn_model()并學習了正確的引數,我們就可以預測新的資料,
2.1定義神經網路結構
在構建之前,我們要先把神經網路的結構給定義好:
n_x: 輸入層的數量
n_h: 隱藏層的數量(這里設定為4)
n_y: 輸出層的數量
def layer_sizes(X,Y):
"""
引數:
X - 輸入資料集,維度為(輸入的數量,訓練/測驗的數量)
Y - 標簽,維度為(輸出的數量,訓練/測驗數量)
回傳:
n_x - 輸入層的數量
n_h - 隱藏層的數量
n_y - 輸出層的數量
"""
n_x = X.shape[0]
n_h = 4
n_y = Y.shape[0]
return (n_x,n_h,n_y)
#測驗一下
#測驗layer_sizes
print("=========================測驗layer_sizes=========================")
X_asses , Y_asses = layer_sizes_test_case()
(n_x,n_h,n_y) = layer_sizes(X_asses,Y_asses)
print("輸入層的節點數量為: n_x = " + str(n_x))
print("隱藏層的節點數量為: n_h = " + str(n_h))
print("輸出層的節點數量為: n_y = " + str(n_y))
2.2 初始化模型的引數
我們要實作函式initialize_parameters(),我們要確保我們的引數大小合適,如果需要的話,請參考上面的神經網路圖,
我們將會用隨機值初始化權重矩陣
p.random.randn(a,b)* 0.01來隨機初始化一個維度為(a,b)的矩陣,
將偏向量初始化為零,
np.zeros((a,b))用零初始化矩陣(a,b),
def initialize_parameters(n_x,n_h,n_y):
"""
引數:
n_x - 輸入層節點的數量
n_h - 隱藏層節點的數量
n_y - 輸出層節點的數量
回傳:
parameters - 包含引數的字典:
W1 - 權重矩陣,維度為(n_h,n_x)
b1 - 偏向量,維度為(n_h,1)
W2 - 權重矩陣,維度為(n_y,n_h)
b2 - 偏向量,維度為(n_y,1)
"""
np.random.seed(2) #指定一個隨機種子,以便你的輸出與我們的一樣,
# seed( ) 用于指定亂數生成時所用演算法開始的整數值,
# 1.如果使用相同的seed( )值,則每次生成的隨即數都相同;
# 2.如果不設定這個值,則系統根據時間來自己選擇這個值,此時每次生成的亂數因時間差異而不同,
# 3.設定的seed()值僅一次有效
W1 = np.random.randn(n_h,n_x)*0.01
b1 = np.zeros(shape = (n_h,1))
W2 = np.random.randn(n_y,n_h) * 0.01
b2 = np.zeros(shape=(n_y, 1))
#使用斷言確保我的資料格式是正確的
assert(W1.shape == ( n_h , n_x ))
assert(b1.shape == ( n_h , 1 ))
assert(W2.shape == ( n_y , n_h ))
assert(b2.shape == ( n_y , 1 ))
parameters = {"W1" : W1,
"b1" : b1,
"W2" : W2,
"b2" : b2 }
return parameters
#測驗initialize_parameters
print("=========================測驗initialize_parameters=========================")
n_x , n_h , n_y = initialize_parameters_test_case()
parameters = initialize_parameters(n_x , n_h , n_y)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
2.3 回圈
2.3.1 前向傳播
我們現在要實作前向傳播函式forward_propagation(),
我們可以使用sigmoid()函式,也可以使用np.tanh()函式,
步驟:
使用字典型別的parameters(它是initialize_parameters() 的輸出)檢索每個引數,
實作向前傳播, ( 訓練集里面所有例子的預測向量),
反向傳播所需的值存盤在“cache”中,cache將作為反向傳播函式的輸入,
def forward_propagation(X,parameters):
"""
引數:
X - 維度為(n_x,m)的輸入資料,
parameters - 初始化函式(initialize_parameters)的輸出
回傳:
A2 - 使用sigmoid()函式計算的第二次激活后的數值
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典型別變數
"""
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
#前向傳播計算A2
Z1 = np.dot(W1,X)+b1
A1 = np.tanh(Z1) #第一層的激活函式
#A1=np.where(Z1>0,Z1,0) #relu激活函式
Z2 = np.dot(W2 , A1) + b2
A2 = sigmoid(Z2) #輸出層用的sigmioid的激活函式
#使用斷言確保我的資料格式是正確的
assert(A2.shape == (1,X.shape[1]))
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return (A2, cache)
#測驗forward_propagation
print("=========================測驗forward_propagation=========================")
X_assess, parameters = forward_propagation_test_case()
A2, cache = forward_propagation(X_assess, parameters)
#print(cache["Z1"])
print(np.mean(cache["Z1"]), np.mean(cache["A1"]), np.mean(cache["Z2"]), np.mean(cache["A2"]))
# mean()函式功能:求取均值
# 經常操作的引數為axis,以m * n矩陣舉例:
# axis 不設定值,對 m*n 個數求均值,回傳一個實數
# axis = 0:壓縮行,對各列求均值,回傳 1* n 矩陣
# axis =1 :壓縮列,對各行求均值,回傳 m *1 矩陣
2.3.2計算損失
正式開始構建計算成本的函式:
def compute_cost(A2,Y,parameters):
"""
計算方程(6)中給出的交叉熵成本,
引數:
A2 - 使用sigmoid()函式計算的第二次激活后的數值
Y - "True"標簽向量,維度為(1,數量)
parameters - 一個包含W1,B1,W2和B2的字典型別的變數
回傳:
成本 - 交叉熵成本給出方程(13)
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
#計算成本
logprobs = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = float(np.squeeze(cost)) #numpy.squeeze()函式 作用:從陣列的形狀中洗掉單維度條目,即把shape中為1的維度去掉
assert(isinstance(cost,float))
return cost
#測驗一下我們的成本函式:
#測驗compute_cost
print("=========================測驗compute_cost=========================")
A2 , Y_assess , parameters = compute_cost_test_case()
print("cost = " + str(compute_cost(A2,Y_assess,parameters)))
2.3.3 向后傳播
使用正向傳播期間計算的cache,現在可以利用它實作反向傳播,
向量化表示
需要使用六個方程
def backward_propagation(parameters,cache,X,Y):
"""
搭建反向傳播函式,
引數:
parameters - 包含我們的引數的一個字典型別的變數,
cache - 包含“Z1”,“A1”,“Z2”和“A2”的字典型別的變數,
X - 輸入資料,維度為(2,數量)
Y - “True”標簽,維度為(1,數量)
回傳:
grads - 包含W和b的導數一個字典型別的變數,
"""
m = X.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
A1 = cache["A1"]
A2 = cache["A2"]
dZ2= A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis=1, keepdims=True) #axis為1是壓縮列,即將每一行的元素相加,將矩陣壓縮為一列
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis=1, keepdims=True)
grads = {"dW1": dW1,
"db1": db1,
"dW2": dW2,
"db2": db2 }
return grads
#測驗backward_propagation
print("=========================測驗backward_propagation=========================")
parameters, cache, X_assess, Y_assess = backward_propagation_test_case()
grads = backward_propagation(parameters, cache, X_assess, Y_assess)
print ("dW1 = "+ str(grads["dW1"]))
print ("db1 = "+ str(grads["db1"]))
print ("dW2 = "+ str(grads["dW2"]))
print ("db2 = "+ str(grads["db2"]))
2.3.4更新引數
我們需要使用(dW1, db1, dW2, db2)來更新(W1, b1, W2, b2),
def update_parameters(parameters,grads,learning_rate=1.2):
"""
使用上面給出的梯度下降更新規則更新引數
引數:
parameters - 包含引數的字典型別的變數,
grads - 包含導數值的字典型別的變數,
learning_rate - 學習速率
回傳:
parameters - 包含更新引數的字典型別的變數,
"""
W1,W2 = parameters["W1"],parameters["W2"]
b1,b2 = parameters["b1"],parameters["b2"]
dW1,dW2 = grads["dW1"],grads["dW2"]
db1,db2 = grads["db1"],grads["db2"]
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
parameters = {"W1": W1,
"b1": b1,
"W2": W2,
"b2": b2}
return parameters
#測驗update_parameters
print("=========================測驗update_parameters=========================")
parameters, grads = update_parameters_test_case()
parameters = update_parameters(parameters, grads)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
整合
把前面的函式都呼叫過來,
模型中傳入的引數是,X,Y,和迭代次數
首先需要得到你要設計的神經網路結構,呼叫layer_sizes()得到了n_x,n_y,也就是輸入層和輸出層,
初始化引數initialize_parameters(n_x, n_h, n_y),得到初始化的 W1, b1, W2, b2
然后開始回圈
使用forward_propagation(X, parameters),先得到各個神經元的計算值,
然后compute_cost(A2, Y, parameters),得到cost
backward_propagation(parameters, cache, X, Y)計算出每一步的梯度
update_parameters(parameters, grads)更新一下引數
回傳訓練完的parameters
def nn_model(X,Y,n_h,num_iterations,learning_rate,print_cost=False):
"""
引數:
X - 資料集,維度為(2,示例數)
Y - 標簽,維度為(1,示例數)
n_h - 隱藏層的數量
num_iterations - 梯度下降回圈中的迭代次數
print_cost - 如果為True,則每1000次迭代列印一次成本數值
回傳:
parameters - 模型學習的引數,它們可以用來進行預測,
"""
np.random.seed(3) #指定隨機種子
n_x = layer_sizes(X, Y)[0]
n_y = layer_sizes(X, Y)[2]
parameters = initialize_parameters(n_x,n_h,n_y)
W1 = parameters["W1"]
b1 = parameters["b1"]
W2 = parameters["W2"]
b2 = parameters["b2"]
for i in range(num_iterations):
A2 , cache = forward_propagation(X,parameters)
cost = compute_cost(A2,Y,parameters)
grads = backward_propagation(parameters,cache,X,Y)
parameters = update_parameters(parameters,grads,learning_rate)
if print_cost:
if i%1000 == 0:
print("第 ",i," 次回圈,成本為:"+str(cost))
return parameters
#測驗nn_model
print("=========================測驗nn_model=========================")
X_assess, Y_assess = nn_model_test_case()
parameters = nn_model(X_assess, Y_assess, 4, num_iterations=10000, learning_rate = 0.5,print_cost=False)
print("W1 = " + str(parameters["W1"]))
print("b1 = " + str(parameters["b1"]))
print("W2 = " + str(parameters["W2"]))
print("b2 = " + str(parameters["b2"]))
三、預測
構建predict()來使用模型進行預測, 使用向前傳播來預測結果,
def predict(parameters,X):
"""
使用學習的引數,為X中的每個示例預測一個類
引數:
parameters - 包含引數的字典型別的變數,
X - 輸入資料(n_x,m)
回傳
predictions - 我們模型預測的向量(紅色:0 /藍色:1)
"""
A2 , cache = forward_propagation(X,parameters)
predictions = np.round(A2)
return predictions
#測驗predict
print("=========================測驗predict=========================")
parameters, X_assess = predict_test_case()
predictions = predict(parameters, X_assess)
print("預測的平均值 = " + str(np.mean(predictions)))
正式運行
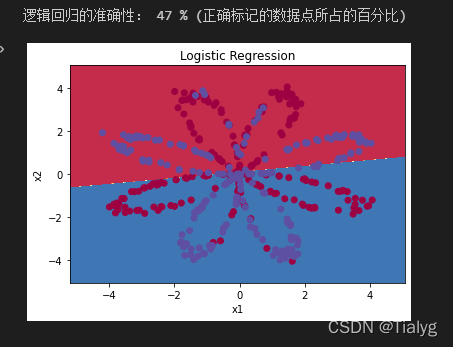
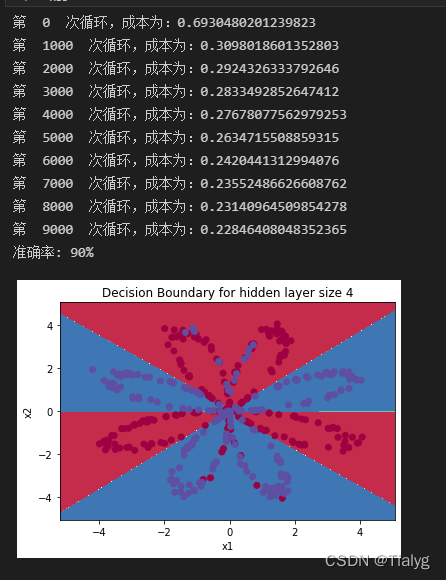
parameters = nn_model(X, Y, n_h = 4, num_iterations=10000,learning_rate=0.5, print_cost=True)
#繪制邊界
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, X)
print ('準確率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
探索:
1.更改隱藏層節點數量
plt.figure(figsize=(16, 32))
hidden_layer_sizes = [1, 2, 3, 4, 5, 20, 50] #隱藏層數量
for i, n_h in enumerate(hidden_layer_sizes):
plt.subplot(5, 2, i + 1)
plt.title('Hidden Layer of size %d' % n_h)
parameters = nn_model(X, Y, n_h, num_iterations=5000,learning_rate=0.5)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100)
print ("隱藏層的節點數量: {} ,準確率: {} %".format(n_h, accuracy))
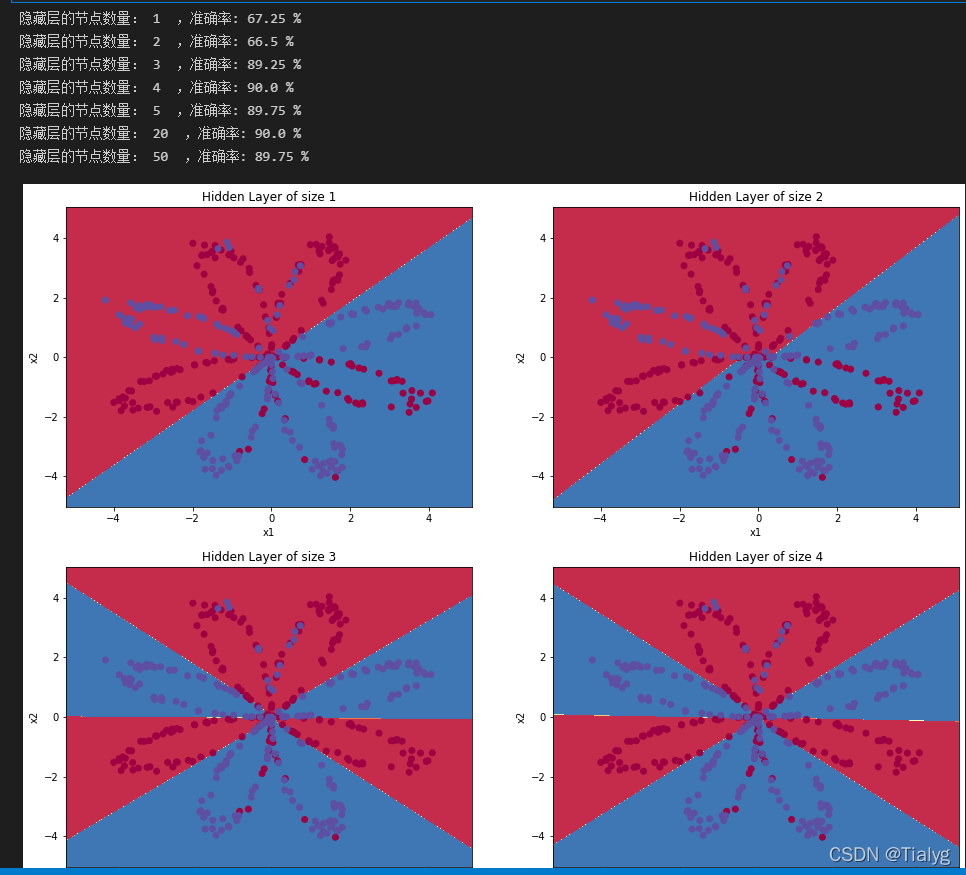
較大的模型(具有更多隱藏單元)能夠更好地適應訓練集,直到最終的最大模型過度擬合資料,
最好的隱藏層大小似乎在n_h = 5附近,實際上,這里的值似乎很適合資料,而且不會引起過度擬合,
2.當改變sigmoid激活或ReLU激活的tanh激活時會發生什么?
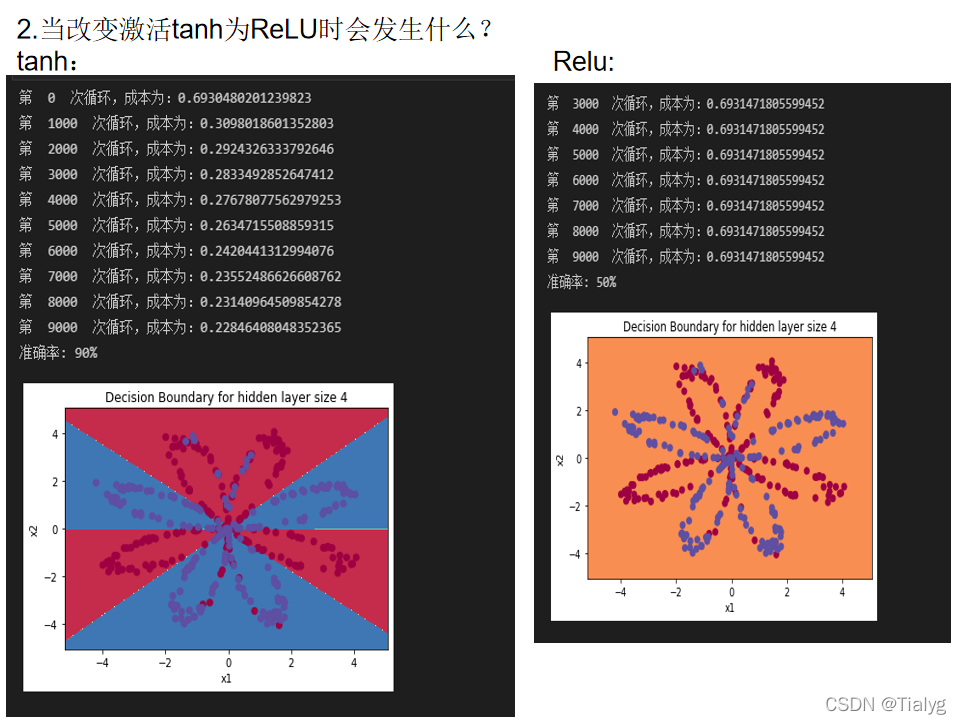
注意:這邊有點問題! 有待解決
這里:如何選擇激活函式? 實際應用中先想我想要實作什么效果,再去選擇激活函式,再查看是否符合我的預期
3.改變learning_rate的數值會發生什么
learning_rates= [1,0.9,0.5,0.05,0.005,0.0005]
for i,learning_rate in enumerate(learning_rates):
parameters = nn_model(X, Y, n_h, num_iterations=10000,learning_rate=learning_rate)
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
predictions = predict(parameters, X)
accuracy = float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100)
print ("學習率的大小: {} ,準確率: {} %".format(learning_rate, accuracy))
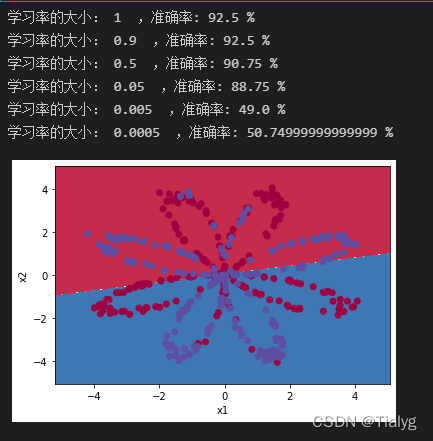
這里:去看論文中對于學習率的設定是怎么設定的?
4.如果我們改變資料集呢?
# 資料集
noisy_circles, noisy_moons, blobs, gaussian_quantiles, no_structure = load_extra_datasets()
datasets = {"noisy_circles": noisy_circles,
"noisy_moons": noisy_moons,
"blobs": blobs,
"gaussian_quantiles": gaussian_quantiles}
dataset = "noisy_moons"
X, Y = datasets[dataset]
X, Y = X.T, Y.reshape(1, Y.shape[0])
if dataset == "blobs":
Y = Y % 2
plt.scatter(X[0, :], X[1, :], c=Y, s=40, cmap=plt.cm.Spectral)
#上一陳述句如出現問題請使用下面的陳述句:
plt.scatter(X[0, :], X[1, :], c=np.squeeze(Y), s=40, cmap=plt.cm.Spectral)
parameters = nn_model(X, Y, n_h = 4, num_iterations=10000,learning_rate=0.5, print_cost=True)
#繪制邊界
plot_decision_boundary(lambda x: predict(parameters, x.T), X, Y)
plt.title("Decision Boundary for hidden layer size " + str(4))
predictions = predict(parameters, X)
print ('準確率: %d' % float((np.dot(Y, predictions.T) + np.dot(1 - Y, 1 - predictions.T)) / float(Y.size) * 100) + '%')
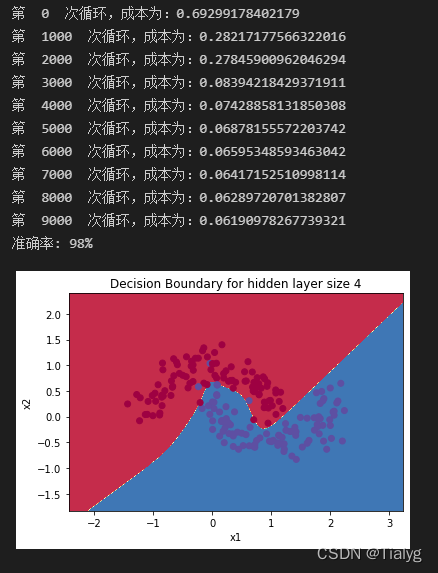
這里:改變資料集的依據是什么?任何一個資料集都可以?怎么判斷是否線性可分?
留了三個問題,下篇博客解決
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375177.html
標籤:AI
上一篇:2021熱乎的位元組跳動軟體測驗工程師面試題及答案分享
下一篇:一、TensorFlow基礎