1、TensorFlow框架介紹
TensorFlow是什么
- 谷歌基于DistBelief進行研發的第二代人工智能學習系統
- 用于語音識別或影像識別等多項機器學習和深度學習領域
- 將復雜的資料結構傳輸至人工智能神經網中進行分析和處理·支持CNN、RNN和LSTM演算法,是目前在lmage,Speech和NLP最流行的深度神經網路模型
2、TensorFlow系統框架
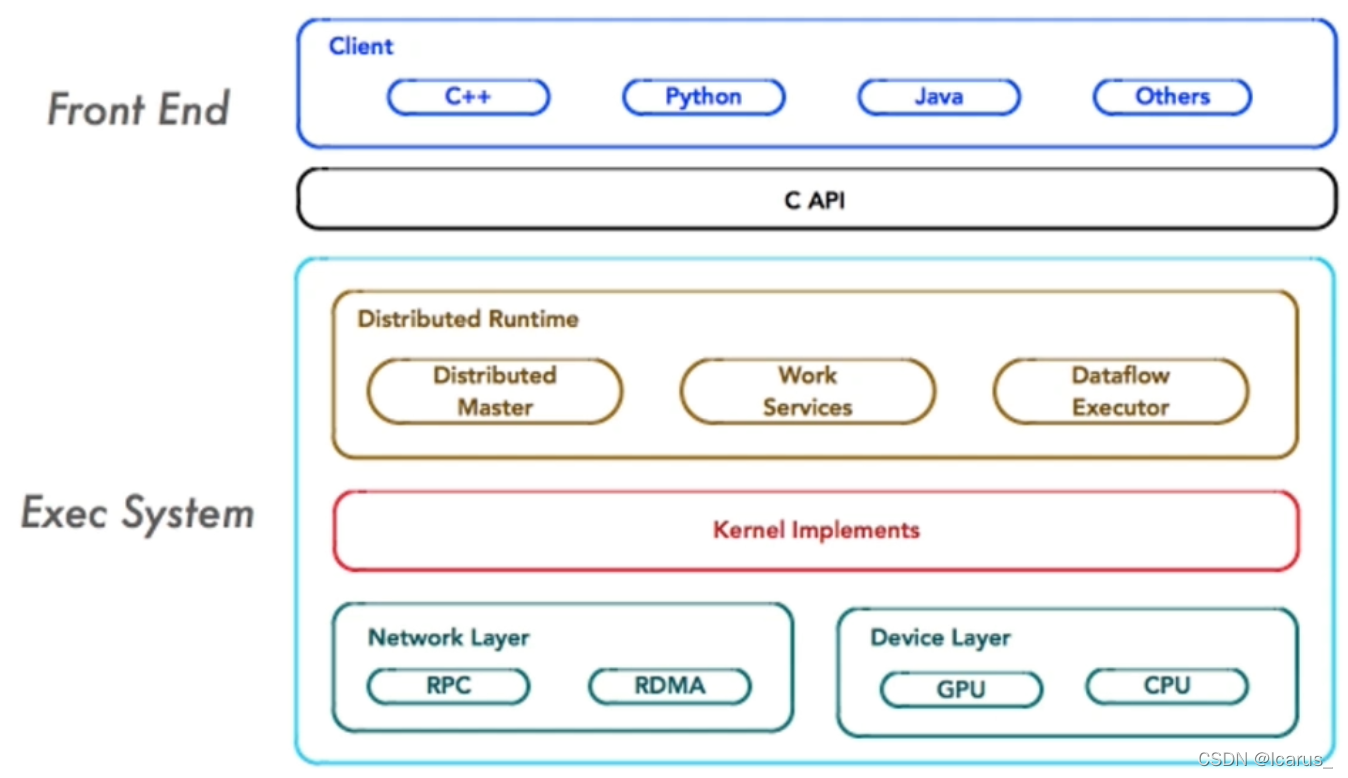
從圖中可以看到有三大部分組成,第一部分是一個前端框架,Front End,第二部分,就是中間的這個capi,第三部分是一個后端的Exec System執行的一個作業系統,
前端系統:它主要是負責提供TensorFlow的一個編程模型,構造計算圖和管理session的周期,
什么是TensorFlow的編程模型呢?實際上是我們所訓練的模型 ,構造計算圖,也就是說,我們里面有大量的輸入輸出,圖的計算,圖的構造,一些函式,一些激活,一些神經網路這些構造圖,還有管理session周期,一個TensorFlow的模型的訓練,或者說任何的一個任務的啟動,我們都是要通過session,就是會話進行啟動的,我們可以把前端框架理解為給TensorFlow底層用戶暴露出來的一個api介面,那么開發者可以使用python,Java,c++等多種開發語言,后端的系統中所提供的api基礎上根據自身要求,來設計和開發自己所需要的模型,并將模型進行訓練,
后端系統:提供運行時環境,負責執行計算圖,
后端系統的設計和實作可以進一步分解為 4 層,
- 運行時:分別提供本地模式和分布式模式,并共享大部分設計和實作 ;
- 計算層:由各個 OP 的 Kernel 實作組成;在運行時,Kernel 實作執行 OP 的具 體數學運算;
- 通信層:基于 gRPC 實作組件間的資料交換,并能夠在支持 IB 網路的節點間實 現 RDMA 通信;
- 設備層:計算設備是 OP 執行的主要載體,TensorFlow 支持多種異構的計算設備 型別,
3、TensorFlow的基本要素
3.1 張量(Tensor)
TensorFlow中的一個非常基本的一個要素,對神經網路高維度的表達方式,
張量(Tensor)在TensorFlow中,張量的維度被描述為“階”,但是,張量的階和矩陣的階并不是同一個概念,張量的階,是張量維度的一個數量的描述,
x=3零階張量 (純量)
v=[1.1,2.2,3.3] 一階張量(向量)
t=[[1,2,3],[4,5,6],[7,8,9]] 二階張量(矩陣)379373142
m=[[[2],[4], [6]],[[8],[10],[12]],[[14],[16],[18]]] 三階張量(立方體)
3.2圖(Graph)
一個TensorFlow在運行的程序中,它會有需要進行計算,計算中會有很多節點,很多操作,這些節點和操作就組成了一個圖,代表模型的資料流,由多個ops(操作即節點)和tensor(資料流即邊)組成,演算法都會表示成計算圖(資料流圖),可看作是有向圖,張量就是通過各種操作在有向圖中流動,
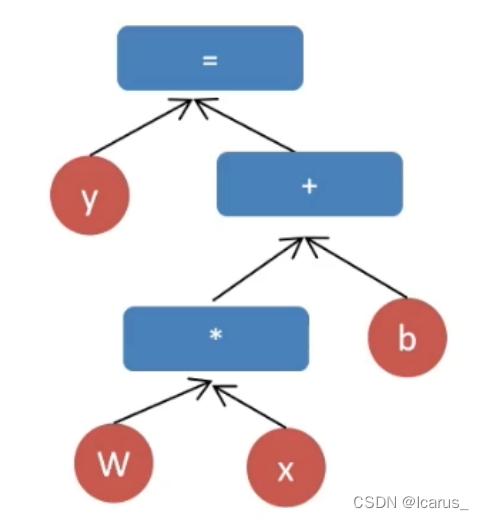
3.3會話(Session)
無論是在TensorFlow也好,或者是來任何框架,任何語言中,都有這么一個會話的概念,會話實際量就是管理著一個模型或者一個函式或者說一個操作開始到結尾整個的這么一場流程,
在TensorFlow中,要想啟動一個圖的前提是要先創建一個會話(Session) -TensorFlow的所有對圖的操作, 都必須放在會話中進行,
import tensorfiow as tf
Hello=tf.constant('Hello Tensorflow!')
sess = tf.Session()
print(sess.run(Hello))四、TensorFlow模型訓練
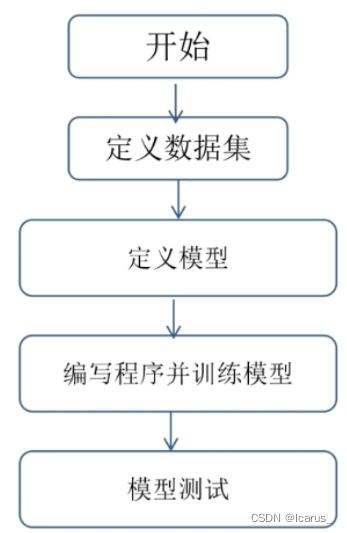
TensorFlow是如何進行模型訓練的?首先,我們要定義資料集,無論是影像的一個資料訓練也好,還是文本的訓練,或者說一些語音,一些視頻的訓練等等,
第一步要做的就是定義資料集,一般來講有兩種方式,第一種方式呢是我們使用現成的資料集,
第二步對定義模型,有了資料集之后,那我們會先對這個資料進行一個處理,處理成我們所想要的所需要的這么一個數理集,
第三步就是定義模型,比如說這個模型的輸入是什么,輸出是什么?輸入和輸出之間,我這個模型是如何運算的,是如何進行處理,比如說影像的話,我可能需要用卷積用池化做一些操作, 訓練這個模型的之前,我們就要把這個模型的定義好,
第四步就可以撰寫程式,那么這個模型我們要去練多少輪,用多少資料,訓練資料是多少?測驗資料是多少?訓練資料是什么樣,資料什么樣的,一般來講,我們訓練資料和測驗資料是一個互斥關系,也就是說,訓練資料一般不會包含測驗資料的內容,測驗資料集中呢,也不會包含訓練資料內容,
第五步模型訓練好之后,進的一個測驗,測驗資料集局,或者說用一些正常的或者我們最終真要使用的這個資料進行一個測驗來驗證一下我們這個模型準確率有多少,效果如何等等,
訓練模型這個程序中,我們有幾點要注意的,
注意資料集,訓練影像和文本,它的資料集是不同的,我們要保證第一訓練集和測驗集要給它區分開,第二,訓練集盡可能要大,一般是先用大批量的資料來進行訓練,比如說,我訓練一個文本處理任務,那幾十潭訓者說100多條要進行訓練,這個時候訓練給可能不是很堵準,因為深度學習實際是讓計算機自己學習一個規律,找到他的特征,我們給他的訓練集比較少的時候呢,他學習到的特征可能不是特別明顯,特學習到的特征不是特別多,我們用一個新的測驗集進行測驗的時候,會導致這個測驗的不準確,我們要注意的就是說,我們這個訓練集要盡可能比較大,或者說盡可能力要一定得統一性,也可以說是有一定的多樣化,但是要有比較大批量的資料才能給他進行訓練,
另外,我們來撰寫模型和訓練模型的時候呢,我們也要去調里面的一些引數,比如說訓練多少輪,并不說我訓練的輪次多越好,有的人說我這資料量很多,那么我一次性給他訓練個一百萬,200萬輪,訓練完了之后我們拿測驗集來測,發現結果100%,很好,是我想要的,但是呢,跑到真實環境中就會發現為什么真實環境準確率不高呢,
訓練的輪次很多,這導致它的擬和程度很強,這個時候,我們把這個訓練稱之為過你和, 就是用我們理想化的資料進行訓練,這個理想化的資料進行驗證,當我們用普通化的或者一般形式的資料區驗證去進行測驗的時候,他的效果就不是很好,這個就是過擬合的概念,
訓練輪次少就是一個欠擬合的概念,整個就是反著的,在TensorFlow的這個模型訓練里,我們主要就是要注意這幾點,一個是資料集,第二個是資料的一個大小,種類,還有結構,還有就是這個模型訓練的訓練輪次,還有一點在模型訓練程序中,比如說我們訓練到一半,或者說訓練出來的結果發現他這個損失不下降, 因為我們的訓面有一個loss就么一個引數,它不下降,這或者說下降的非常快,或者說下降非常慢或者下降到一半又升上去了,這個時候就要去找損失函式是否用的對,是不會要換一種優化系,所以說這個是在深度學習程序中叫做引數調優程序,TensorFlow的訓練,或者任和深度學習的訓練,他最主要的一個是對數命級的訓練,第二個是對模型的引數的一個優化,一個調優,使它能夠達到一個最理理想的,或者說我們最需要的這么一個狀態,整個這么一套就是TensorFlow基本的原理和基本的一個訓練模型,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375179.html
標籤:AI