熵和spike train—資訊和熵
在這一節中我們將利用資訊理論來探索神經系統的編碼特性,
spike train
- spike train:在一個時間序列中,我們在給定的timebin上標記有無spike出現,此時問題轉換為yes or no question,即我們可以用二元變數對于spike train進行描述
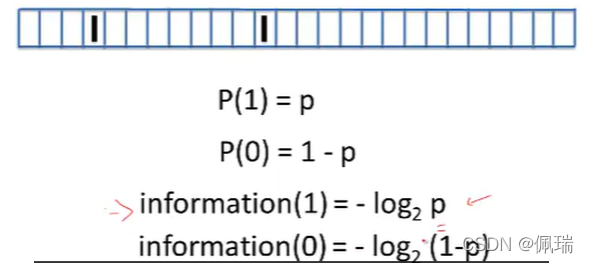
這里的 P ( 1 ) P(1) P(1)是假設spike出現在某個timebin里的概率, P ( 0 ) P(0) P(0)指的是某個timebin沒有fire(即為沉默狀態)的概率
i n f o r m a t i o n ( 1 ) information(1) information(1)以及 i n f o r m a t i o n ( 0 ) information(0) information(0)和則是在此種情況下得到的資訊,這是根據資訊理論所得出的計算結果,
熵
- 熵:熵即隨機變數的平均資訊,換句話說熵衡量了變數的混亂程度(變異性),即encoding的內在可變性,
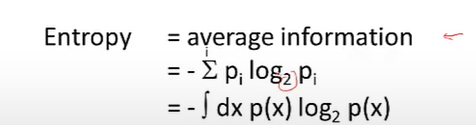
encoding是靠在output中生成刺激驅動的可變性來進行編碼的,那么一個好的encoding程序也就意味著output具有明顯的內在可變性,即有一定熵值,
而內在可變性越大,encoding程序的表征能力也就越強(包含的資訊也就越多),但是考慮到熵所表的混亂程度,對于刺激和回應我們還需要更進一步的理解:
案例引入
在這里我們引入一個猴子觀察箭頭方向的例子,當出現右箭頭的視覺刺激時,猴子視覺皮層會產生一個spike:
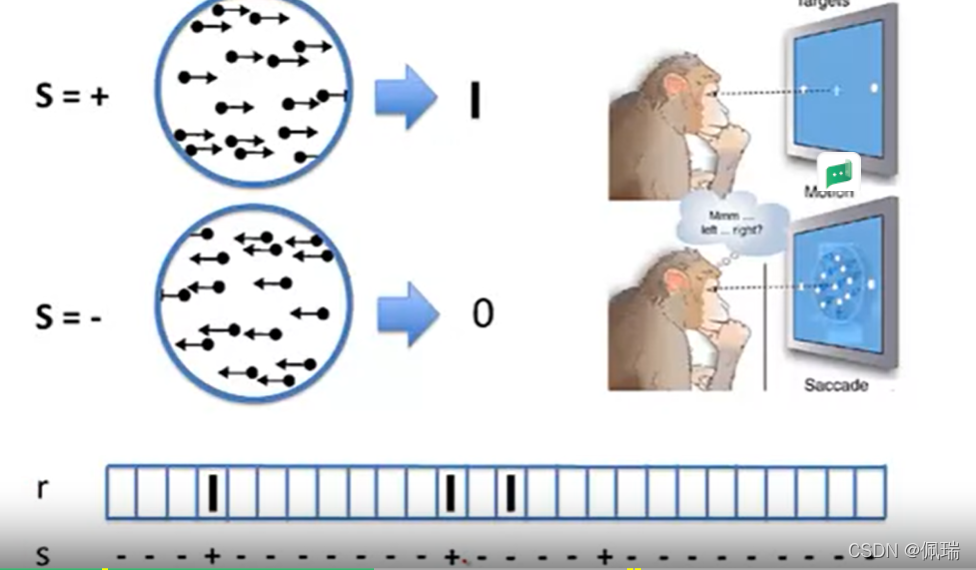
我們可以發現前兩個刺激和回應是明顯相關的,而最后一個刺激和回應呈現了一種“misfire”的現象,這里涉及到有關noisy data的處理在簡單神經編碼模型—特征選擇已有涉及,那么我們今天所要探討的便是另外一個問題:我們在 r 中看到的可變性有多少是實際上用來編碼 s 的?
noisy encoding
面對noisy encoding的情況,我們需要考慮出錯的可能性:
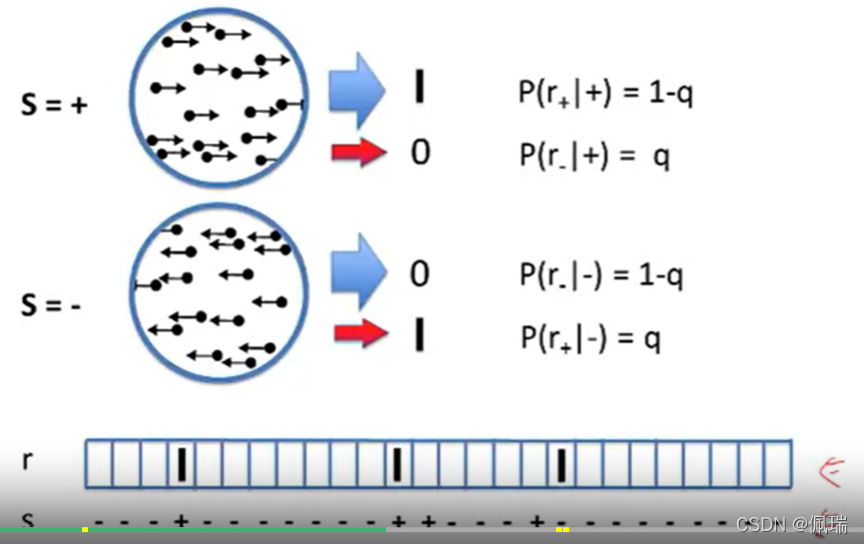
即對于刺激s生成的回應r(spike),存在錯誤概率q/1-q(刺激時沒有回應發生或沒有刺激時出現回應),正確概率1-q/q,在這里我們可以將一部分錯誤概率歸結為沉默回應的狀態,
所以我們現在需要做的就是量化有多少回應的熵是分配給noise的,并將其減去以排除其對于encoding程序內在可變性的影響,
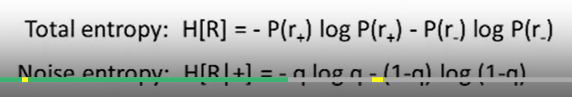
因此在這里我們引入了總熵和噪聲熵兩個變數,這里的總熵為刺激情況下產生回應或是沒有刺激情況下保持沉默的熵值,而噪聲熵則是misfire狀態(刺激時沒有回應發生或沒有刺激時出現回應)下的熵值,
互資訊
在這里我們引入互資訊,即回應攜帶的有關刺激的資訊和,

回應和刺激之間的互資訊則是用上一節的總熵減去噪聲熵來實作的,
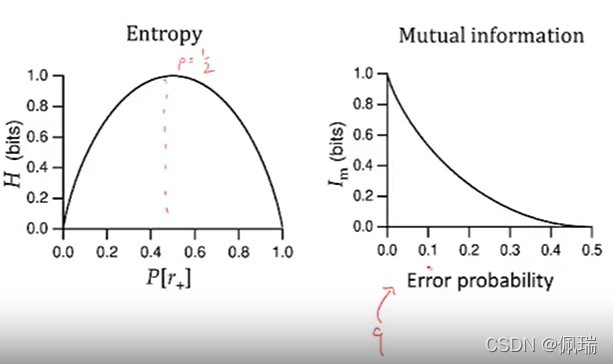
為了更好的理解互資訊,我們作以下假設:當我們的概率p一定時(=1/2),隨錯誤概率(這里將錯誤概率與沉默概率都設定為q)q增大,spike回應r對于刺激s的表征能力逐漸降低,回應r與刺激s的相關性逐漸降低,并且在q=1/2時相關性消失,這也是符合生物學意義的,
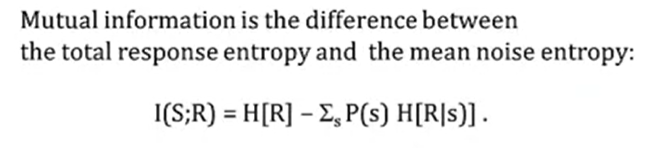
因此我們可以說互資訊量化了變數R和S之間的相關性,

歡迎大家關注公眾號奇趣多多一起交流!

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/375181.html
標籤:AI
上一篇:一、TensorFlow基礎
下一篇:Metasploit實驗