
本文發表于第32屆神經資訊處理系統會議(NIPS 2018),是法國汽車零部件供應商法雷奧集團(Valeo)研究提出的一種用于自動駕駛領域的多任務神經網路,可同時執行目標檢測與語意分割任務,
代碼開源地址:https://github.com/MarvinTeichmann/MultiNet
Abstract
卷積神經網路(CNN)被成功地用于各種視覺感知任務,包括目標檢測、語意分割、光流、深度估計和視覺SLAM,通常,這些任務是獨立探索和建模的,
本文提出了一種同時進行學習目標檢測和語意分割的聯合多任務網路設計,主要目的是通過共享兩個任務的編碼器來實作低功耗嵌入式SOC的實時性能,我們使用一個類似于ResNet10的小型編碼器構建了一個高效的體系結構,該編碼器為兩個解碼器所共享,目標檢測使用YOLOv2類解碼器,語意分割使用FCN作為解碼器,
我們在兩個公共資料集(Kitti,Cityscapes)和我們的私有魚眼攝像機資料集中對所提出的網路進行了評估,并證明了聯合網路與單獨網路具有相同的準確率,我們進一步優化了網路,使1280x384解析度的影像達到30fps,
1. Introduction
卷積神經網路(CNNs)已經成為自動車輛中大多數視覺感知任務的標準構件,目標檢測是CNN在行人和車輛檢測中的首批成功應用之一,近年來,語意分割逐漸成熟,從檢測道路、車道、路緣等道路物件開始,盡管嵌入式系統的計算能力有了很大提高,專用CNN硬體加速器的趨勢也在不斷發展,但高精度的語意分割的實時性能仍然具有挑戰性,本文提出了一種語意分割和目標檢測的實時聯合網路,覆寫了自動駕駛中所有的關鍵物件,
論文的其余部分結構如下,第二節回顧了目標檢測在自動駕駛中的應用,并提供了使用多任務網路解決該問題的動機,第三部分詳細介紹了實驗裝置,討論了所提出的體系結構和實驗結果,最后,第四部分對論文進行了總結,并提出了未來可能的研究方向,

2. Multi-task learning in Automated Driving
多任務的聯合學習屬于機器學習的一個子分支,稱為多任務學習,多任務聯合學習背后的基本理論是,網路在接受多任務訓練時可以表現得更好,因為它們通過利用任務間規則來更快地學習游戲規則,這些網路不僅具有較好的通用性,而且降低了計算復雜度,使其在低功耗嵌入式系統中非常有效,最近的進展表明,CNN可以用于各種任務[6],包括運動目標檢測[13]、深度估計[8]和視覺SLAM[9],
我們的作業最接近于最近的MultiNet[14],我們的不同之處在于,我們關注的是更小的網路,更多類的兩個任務,以及在三個資料集中進行的更廣泛的實驗,
2.1 Important Objects for Automated Driving
流行的語意分割汽車資料集有CamVid[1]和較新的City Scenes[3],后者具有5000個注釋幀的大小,這是相對較小的,在這個資料集上訓練的演算法不能很好地推廣到在其他城市和隧道等看不見的物件上測驗的資料,為了彌補這一點,我們創建了像Synthia[11]和Virtual Kitti[4]這樣的合成資料集,有一些文獻表明,在較小的資料集中,組合會產生合理的結果,但對于自動駕駛系統的商業部署來說,它們仍然有限,因此,最近正在努力構建更大的語意細分資料集,如Mapillary vistas資料集[10]和ApolloScape[7],Mapillary資料集由25,000幅影像組成,共100類,ApolloScape資料集由50個類別的143,000張影像組成,
2.2 Pros and Cons of MTL
在本文中,我們提出了一種具有共享編碼器的網路結構,該編碼器可以共同學習,其主要優點是提高了效率、可伸縮性,可以利用先前的功能添加更多任務,并通過歸納遷移(任務的學習可轉移特征)實作更好的泛化,我們將在下面更詳細地討論共享網路的優缺點,
共享網路的優點:
- 計算效率:共享功能背后簡單易懂的直覺提高了計算效率,假設有兩個類和兩個獨立的網路,分別占用50%的處理能力,如果有可能在兩個網路之間共享30%,則每個網路都可以重復使用額外的15%來單獨創建一個稍大的網路,有大量的經驗證據表明,網路的初始層是與任務無關的(oriented Gabor filters),我們應該能夠進行一定程度的共享,越多越好,
- 泛化和準確性:在忽略計算效率的情況下,共同學習的網路往往泛化得更好、更準確,這就是為什么ImageNet上的遷移學習非常流行的原因,那里有網路學習非常復雜的類別,比如區分特定種類的狗,因為拉布拉多犬和博美拉多犬這兩個物種之間的細微差別是后天習得的,所以它們更善于檢測一項更簡單的犬類檢測任務,另一個論點是,當他們共同學習時,過度適應某項特定任務的可能性較小,
- 可擴展到更多任務,如流量估計、深度、通信和跟蹤,因此,可以協調共同的CNN特寫流水線,以用于各種任務,
共享網路的缺點:
- 在非共享網路的情況下,演算法是完全獨立的,這可以使資料集設計、體系結構設計、調優、硬負面挖掘等變得更簡單、更容易管理,
- 除錯共享網路(尤其是當它不作業時)相對較難,
3. Proposed Algorithm and Results
3.1 Network Architecture
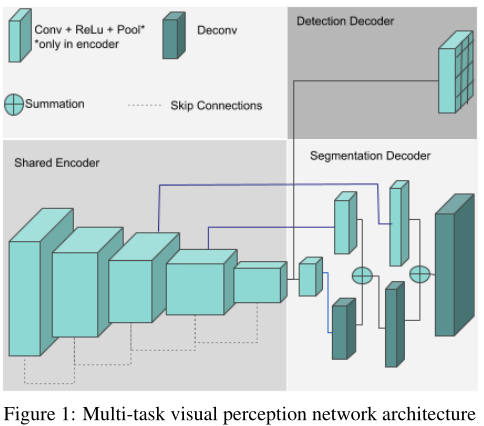
在本節中,我們將報告我們計劃改進的基線網路設計的結果,我們在圖1的高級框圖中提出了一種聯合學習的共享編碼器網路體系結構,我們實作了一個由3個分割類(背景、道路、人行道)和3個物件類(汽車、人、騎車人)組成的兩任務網路,
為了在低功耗嵌入式系統上實作可行性,我們使用了一個名為 Resnet10 的小型編碼器,該編碼器完全共享這兩個任務,FCN8 作為語意分割的解碼器,YOLO 作為目標檢測的解碼器,語意分割的損失函式是最小化誤分類的交叉熵損失,對于幾何函式,以平方誤差損失的形式將目標定位的平均精度作為誤差函式,對于這兩個任務,我們使用單個損失的加權和 L = w s e g ? L s e g + w d e t ? L d e t L=w_{seg}?L_{seg}+w_{det}?L_{det} L=wseg??Lseg?+wdet??Ldet?,在魚眼相機具有較大空間變異畸變的情況下,我們使用多項式模型實作了鏡頭畸變校正,
3.2 Experiments
在這一部分中,我們將解釋實驗設定,包括使用的資料集、訓練演算法細節等,并討論結果,
我們在包含5000張影像和兩個公開可用的資料集Kitti[5]和CitySces[3]的內部魚眼資料集上進行了訓練和評估,我們使用Keras[2]實作了不同提出的多任務架構,我們使用了來自ImageNet的預先訓練好的Resnet10編碼器權重,然后針對這兩個任務進行了微調,FCN8上采樣層使用隨機權重進行初始化,
我們使用ADAM優化器,因為它提供了更快的收斂速度,學習率為0.0005,優化器采用分類交叉熵損失和平方誤差損失作為損失函式,以平均類IOU(交集)和每類IOU作為語意分割的精度度量,以平均平均精度(MAP)和每類平均精度作為目標檢測的精度度量,由于多個任務需要記憶體,所有輸入影像的大小都調整為1280x384,
表1總結了在Kitti、Citycapes和我們的內部魚眼資料集上STL網路和MTL網路所獲得的結果,這旨在為合并更復雜的多任務學習技術提供基準精度,我們將分割網路(STL Seg)和檢測網路(STL Det)與執行分割和檢測的MTL網路(MTL、MTL100和MTL100)進行比較,
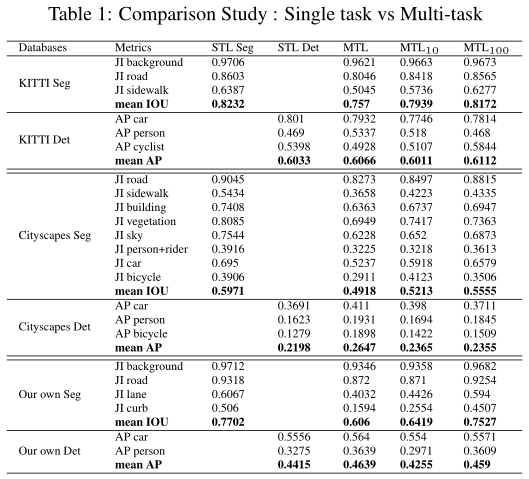
我們測驗了MTL損耗的3種配置,第一種配置(MTL)使用分割損耗和檢測損耗的簡單和 ( w s e g = w d e t = 1 ) (w_{seg}=w_{det}=1) (wseg?=wdet?=1),另外兩個配置MTL10和MTL100使用任務損失的加權和,其中分割損失分別用權重 w s e g = 10 w_{seg}=10 wseg?=10 和 w s e g = 100 w_{seg}=100 wseg?=100加權,這彌補了任務損失尺度的差異:在訓練程序中,分割損失是檢測損失的10-100倍,
MTL網路中的這種加權提高了3個資料集的分割任務的性能,即使分割任務的MTL結果略低于STL(Single-task Learning)結果,本實驗也表明,通過正確調整引數,多任務網路具有學習更多的能力,此外,通過保持幾乎相同的精度,我們在記憶體和計算效率方面有了顯著的提高,我們利用幾種標準的優化技術來進一步改善運行時間,并在汽車級低功耗SOC上實作30fps,
4 Conclusion
本文中,我們討論了多任務學習在自動駕駛環境中的應用,用于聯合語意分割和目標檢測任務,首先,我們激發了完成這兩項任務的需要而不僅僅是語意分割,
然后我們討論了使用多任務方法的利弊,我們通過精心選擇編解碼器,構建了一個高效的聯合網路,并對其進行了進一步優化,在低功耗的嵌入式系統上達到了30fps,
我們分享了在三個資料集上的實驗結果,證明了聯合網路的有效性,在未來的作業中,我們計劃探索增加視覺感知任務,如深度估計、流量估計和視覺SLAM,
更多精彩內容,請關注我的公眾號【AI 修煉之路】!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379393.html
標籤:AI