【一起啃西瓜書】機器學習-期末復習(不掛科)
- 前言
- 試卷題型
- 第一章:緒論
- 一般程序
- 任務
- 資料
- 訓練集
- 驗證集
- 監督學習
- 無監督學習
- 半監督學習
- 第二章:模型評估與選擇
- 欠擬合與過擬合
- 評估方法
- 性能度量
- 錯誤率&精度
- 查準率&查全率
- 交叉驗證
- 第三章:線性模型
- 線性回歸&分類
- 基本形式
- 線性模型優點
- 引數/模型估計
- 對數線性回歸
- 對數幾率回歸
- 多分類學習
- 一對其余
- 兩種策略比較
- 類別不平衡
- 優化提要
- 線性回歸
- 波士頓房價預測
- 線性回歸的正規方程解
- 性能評估
- MSE
- MAE
- R-Squared
- scikit-learn線性回歸實踐
- 正規方程
- 梯度下降
- 癌細胞預測
- 梯度下降
- 邏輯回歸api介紹
- 手寫數字識別
- 第四章:決策樹
- 基本流程
- 劃分選擇
- 資訊增益
- 增益率
- 基尼指數
- 剪枝處理
- 預剪枝
- 后剪枝
- ID3,C4.5和CART演算法對比
- 第五章 神經網路
- 試推匯出BP演算法中的更新公式
- Some note for comprehend
- 第六章:支持向量機
- 什么是支持向量機
- 試析SVM 對噪聲敏感的原因
- 核函式的作用
- 正則化
- 第七章:貝葉斯分類器
- 第八章:集成學習
- Boosting&Bagging
- 第九章:聚類
- 聚類任務
- 第十章:降維與度量學習
- 降維
- 總結
前言
馬上西瓜書期末考試,為了不掛科,需要有針對復習,內容來自專業各個學霸及老師的重點劃分,
推薦:【一起啃西瓜書】機器學習總覽
試卷題型
卷面共100分,含5種題型,考試時間120分鐘,
- 判斷題,8道,每題2分,共16分;
- 填空題,7道,每題2分,共14分;
- 簡答題,5道,每題4分,共20分;
- 演算題,2道,每題10分,共20分;
- 編程題,2道,一道編程填空題(10分),一道編程題(20分),共30分,
第一章:緒論

機器學習致力于研究如何通過計算的手段,利用經驗來改善系統自身的性能,從而在計算機上從資料(經驗)中產生“模型”,用于對新的情況給出判斷(利用此模型預測未來的一種方法),
分為三類:監督學習、無監督學習、強化學習,
一般程序
- 資料獲取
- 特征工程
- 模型選擇
- 模型訓練
- 模型評估
- 超引數條件
- 預測
更詳細:
機器學習程序中,通過確定兩方面的引數來找到泛化性能最好的函式:
- 函式引數,也就是我們通常所說的w和b,這類引數可以通過各種最優化演算法自動求得;
- 模型引數,比如多項式回歸中的多項式次數,規則化引數入等(即超引數),一般在模型訓練之前通過手工指定(當然也可以采用網格法等演算法進行尋優),
確定模型超引數的程序稱為模型選擇(從Algorithm選擇Models),
機器學習的一般程序:
- 確定模型的一組超引數,
- 用訓練集訓練該模型,找到使損失函式最小的最優函式,
- 在驗證集上對最優函式的性能進行度量,
- 重復1、2、3步,直到搜索完指定的超引陣列合,
- 選擇在驗證集上誤差最小的模型,并合并訓練集和驗證集作為整體訓練模型,找到最優函式,
- 在測驗集上對最優函式的泛化性能進行度量,
任務
- 分類:離散值
- 回歸:連續值
- 聚類:無標記資訊
有無標記資訊
- 監督學習:分類、回歸
- 無監督學習:聚類
- 半監督學習:兩者結合
資料
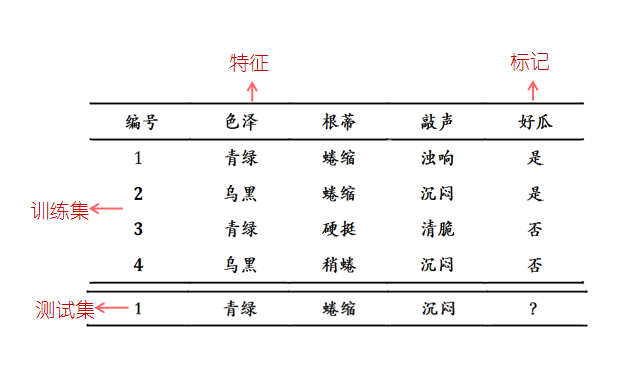
訓練集
用于模型擬合的資料樣本
驗證集
在模型訓練程序中單獨留出來的樣本集,它可以用于調整模型的超引數和用于對模型的初步評估,通常用來在模型迭代訓練時,用以驗證當前模型的泛華能力,但不能作為調參,選擇特征等演算法相關的選擇的依據,
監督學習
定義:
- 輸入資料是由輸入特征值和目標值所組成,
- 函式的輸出可以是一個連續的值(稱為回歸), 或是輸出是有限個離散值(稱作分類),
用已知某種或某些特征的樣本作為訓練集,以建立一個數學模型,再用已建立的模型來預測未知的樣本的方法.是從標簽化訓練集資料集中推斷出模型的機器學習任務.
無監督學習
定義:
- 輸入資料是由輸入特征值組成,沒有目標值
- 輸入資料沒有被標記,也沒有確定的結果,樣本資料類別未知;
- 需要根據樣本間的相似性對樣本集進行類別劃分
在演算法構建程序中不考慮標簽值,只通過特征資訊去歸納一些新的規律出來.
半監督學習
定義:訓練集同時包含有標記樣本資料和未標記樣本資料,
用少量有標注的樣本和大量為標注的樣本進行訓練分類
第二章:模型評估與選擇
欠擬合與過擬合
擬合:就是說這個曲線能不能很好的描述某些樣本,并且有較強的泛化能力.
- 過擬合(訓練集誤差小,測驗集誤差大)
學習器把訓練樣本學習的“太好”,將訓練樣本本身的特點 當做所有樣本的一般性質(不考慮資料噪聲),導致泛化性能下降 - 欠擬合(訓練集誤差大)
對訓練樣本的一般性質尚未學好
如何判斷區分二者?
- 過擬合:模型過于復雜,導致訓練誤差低,測驗誤差高
- 欠擬合:模型簡單,訓練測驗誤差均高
解決:
過擬合
- 增加訓練樣本數量
- 正則化L1.L2
- 降維
- 集成學習方法
- 減少模型復雜度
- 丟棄法Dropout
欠擬合:
- 添加新特性
- 增加模型復雜度
- 減小正則化系數
決策樹:拓展分支
神經網路:增加訓練輪數
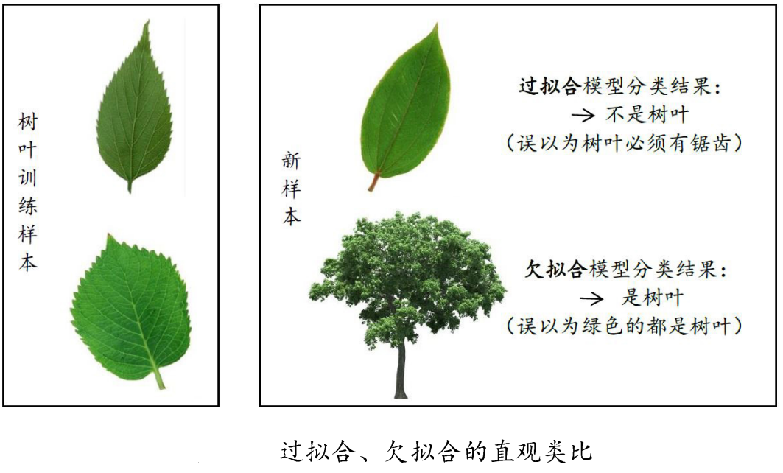
- 過擬合:學習器把訓練樣本本身特點當做所有潛在樣本都會具有的一般性質.
- 欠擬合:訓練樣本的一般性質尚未被學習器學好.
評估方法
現實任務中往往會對學習器的泛化性能、時間開銷、存盤開銷、可解釋性等方面的因素進行評估并做出選擇,
我們假設測驗集是從樣本真實分布中獨立采樣獲得,將測驗集上的“測驗誤差”作為泛化誤差的近似,所以測驗集要和訓練集中的樣本盡量互斥,
留出法:
- 直接將資料集劃分為兩個互斥集合
- 訓練/測驗集劃分要盡可能保持資料分布的一致性
- 一般若干次隨機劃分、重復實驗取平均值
- 訓練/測驗樣本比例通常為2:1~4:1
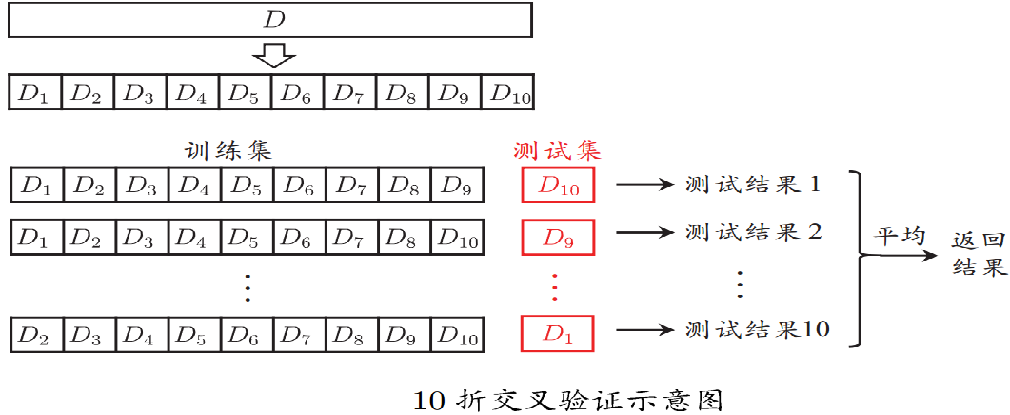
交叉驗證法:
- 將資料集分層采樣劃分為k個大小相似的互斥子集,每次用k-1個子集的并集作為訓練集,余下的一個子集作為測驗集,最侄訓傳k個測驗結果的均值,k最常用的取值是10.
自助法:
以自助采樣法為基礎,對資料集D有放回采樣m次得到訓練集D’ , D\D’用做測驗集,
-
實際模型與預期模型都使用m個訓練樣本
-
約有1/3的樣本沒在訓練集中出現
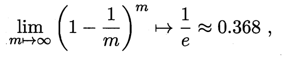
-
從初始資料集中產生多個不同的訓練集,對集成學習有很大的好處
-
自助法在資料集較小、難以有效劃分訓練/測驗集時很有用;由于改變了資料集分布可能引入估計偏差,在資料量足夠時,留出法和交叉驗證法更常用,
性能度量
性能度量是衡量模型泛化能力的評價標準,反映了任務需求;使用不同的性能度量往往會導致不同的評判結果
回歸任務最常用的性能度量是“均方誤差”:
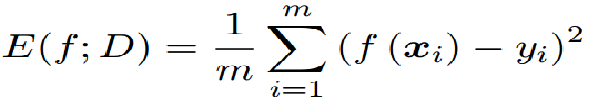
錯誤率&精度
對于分類任務,錯誤率和精度是最常用的兩種性能度量:
- 錯誤率:分錯樣本占樣本總數的比率
- 精度(正確率):分對樣本占樣本總數的比率
查準率&查全率
資訊檢索、Web搜索等場景中經常需要衡量正例被預測出來的比率或者預測出來的正例中正確的比率,此時查準率和查全率比錯誤率和精度更適合,
統計真實標記和預測結果的組合可以得到“混淆矩陣”:

查準率:在預測結果中,預測正例對了所占所有預測正例中的比例(豎著來)
查全率:在真實情況中,預測正例對了所占所有真實情況中的比例(橫著來)
在預測癌癥患者時,優先考慮查全率,因為如果有一個人漏判了便很嚴重,所以我們更看重:真實患有癌癥的情況下,模型預測正確的概率,
基于混淆矩陣,解釋什么是TPR(True Positive Rate)真正利率,FPR(False Positive Rate)假正例率,查準率(P),查全率(R)?
- TPR和R相等,都是真實正例被預測正確的比例,即:TPR=R=TP/TP+FN
- FPR:真實反例被預測為正例的比率,即:FPR=FP/FP+TN
- P:預測為正例的實體中,真正正例的比例,即:P=TP/TP+FP
在測驗集上對最優函式的泛華性能進行度量.
交叉驗證
為什么用交叉驗證法?
- 交叉驗證用于評估模型的預測性能,尤其是訓練好的模型在新資料上的表現,可以在一定程度上減小過擬合
- 還可以從有限的資料中獲取盡可能多的有效資訊
第三章:線性模型
線性回歸&分類
- 線性回歸:試圖學得一個線性模型以盡可能準確的預測實值輸出標記
- 分類:即最常見的是二分類,在線性回歸得出預測值之后,增加了一個“單位越界函式”
回歸和分類的區別:
本質都是一致的,就是模型的擬合(匹配),但是分類問題的y值(label)更離散化一些.而且同一個y值可能對應一大批的x,這些x是具有范圍的,所以分類問題更多的是(一定區域的X)對應著一個y標簽,而回歸問題的模型更傾向于(很小區域內的X或者一般是一個X)對應著一個y.
基本形式
線性模型一般形式: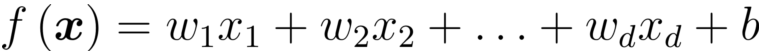
x
x
x:屬性描述的示例,
x
i
xi
xi:是
x
x
x在第
i
i
i個屬性上的取值.
向量形式:
f ( x ) = w T x + b f(x) = w^Tx + b f(x)=wTx+b
w = ( w 1 ; w 2 ; . . . ; w d ) w = (w_1;w_2;...;w_d) w=(w1?;w2?;...;wd?):向量表示
線性模型優點
- 形式簡單、易于建模
- 可解釋性
- 非線性模型的基礎
- 引入層級結構或高維映射
線性回歸(linear regression)目的
- 學得一個線性模型以盡可能準確地預測實值輸出標記
單一屬性的線性回歸目標:
- f ( x ) = w T x + b f(x) = w^Tx + b f(x)=wTx+b
引數/模型估計
引數/模型估計:最小二乘法(least square method)
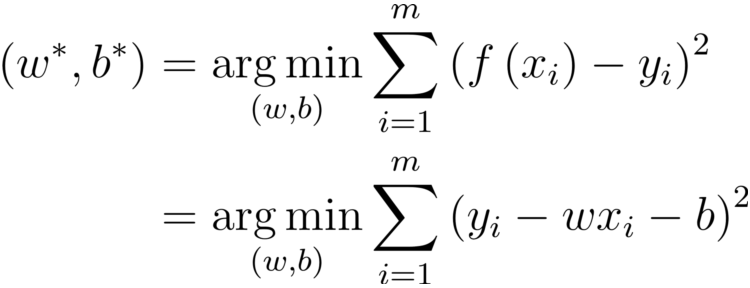
最小化均方誤差
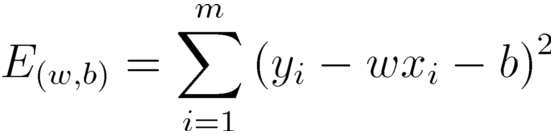
分別對
w
w
w和
b
b
b求導,可得:
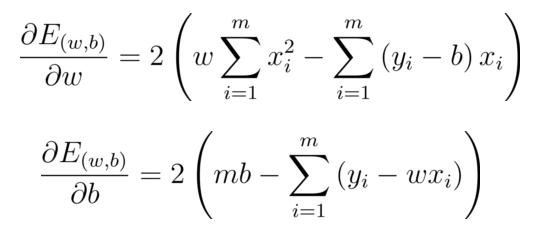
基于均方誤差最小化來進行模型求解的方法為最小二乘法.
在線性回歸中,最小二乘法就是試圖找到一條直線,使所有樣本到直線上的歐式距離之和最小,
對數線性回歸
輸出標記的對數為線性模型逼近的目標:
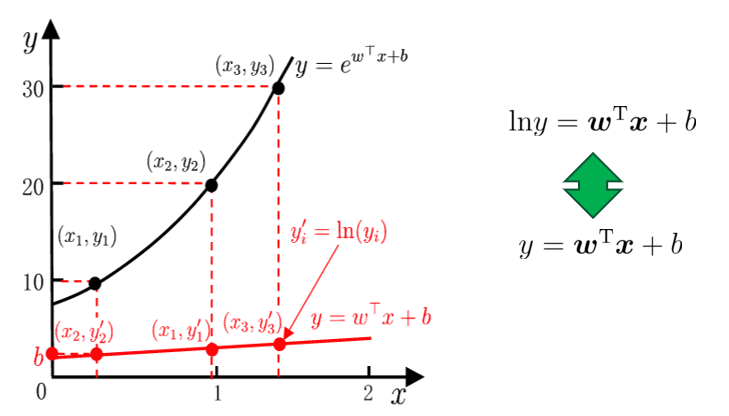
對數幾率回歸
二分類任務
z = w T x + b z = w^Tx + b z=wTx+b
尋找函式將分類標記與線性回歸模型輸出聯系起來:
最理想的函式——單位階躍函式
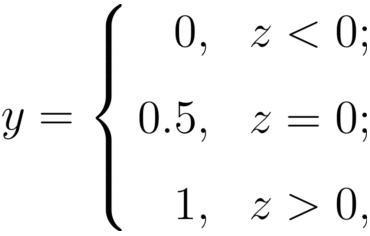
預測值大于零就判為正例,小于零就判為反例,預測值為臨界值零則可任意判別
單位階躍函式缺點:不連續
替代函式——對數幾率函式(logistic function)
- 單調可微、任意階可導
單位階躍函式與對數幾率函式的比較:
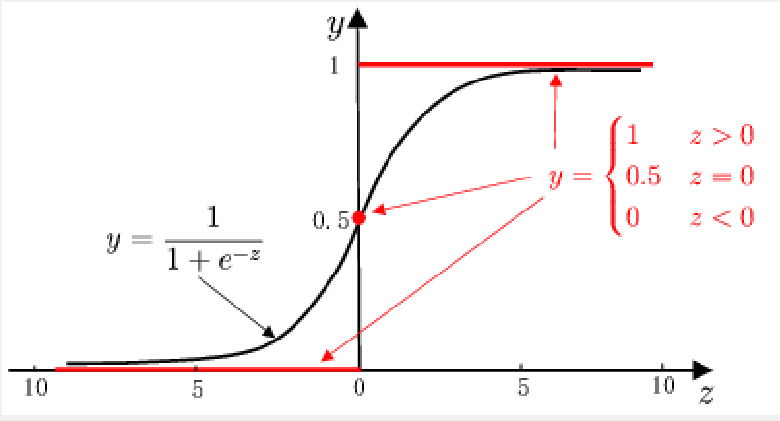
運用對數幾率函式:
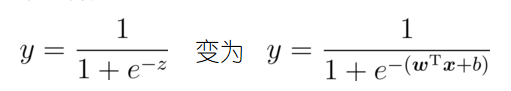
對數幾率(log odds)
-
樣本作為正例的相對可能性的對數
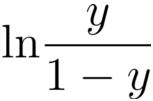
對數幾率回歸優點 -
無需事先假設資料分布
-
可得到“類別”的近似概率預測
-
可直接應用現有數值優化演算法求取最優解
多分類學習
多分類學習方法
- 二分類學習方法推廣到多類
- 利用二分類學習器解決多分類問題(常用)
- 對問題進行拆分,為拆出的每個二分類任務訓練一個分類器
- 對于每個分類器的預測結果進行集成以獲得最終的多分類結果
拆分策略
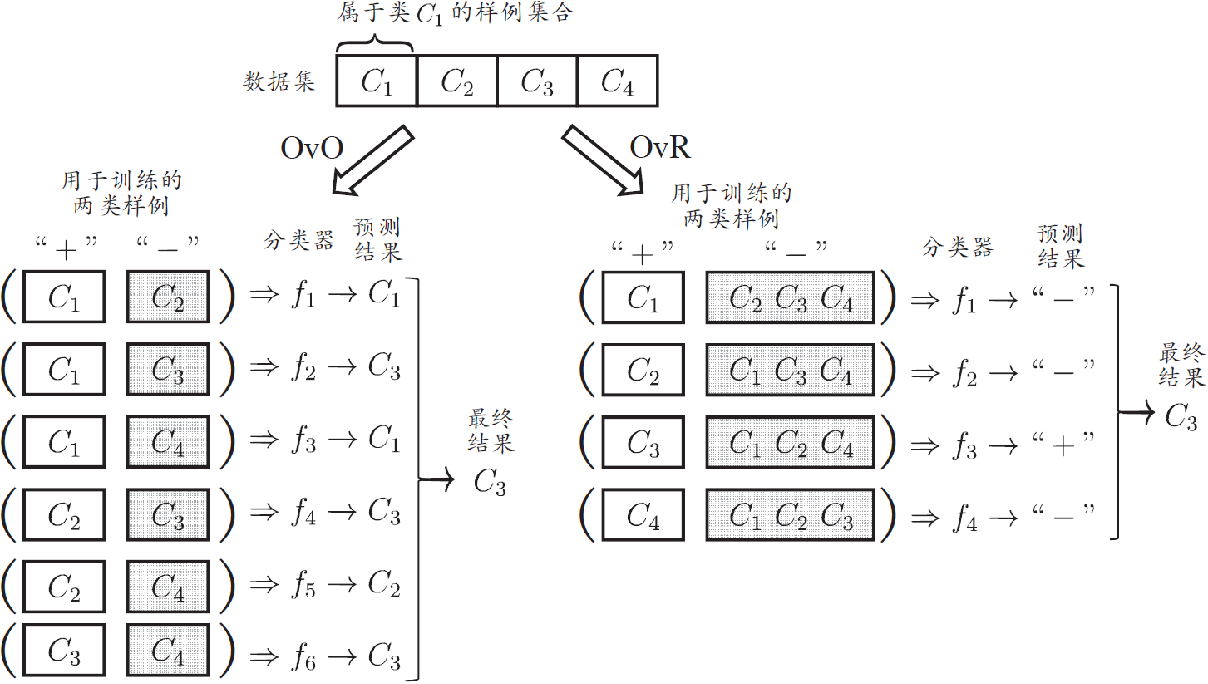
- 一對一(One vs. One, OvO)
- 一對其余(One vs. Rest, OvR)
- 多對多(Many vs. Many, MvM)
給定一個訓練集有N個預測標簽,將這N個類別兩兩配對,從而產生N(N-1)/2個分類結果,最終結果可通過投票產生:即把被預測得最多的類別作為最終分裂結果
拆分階段
- N個類別兩兩配對
- N(N-1)/2 個二類任務
- 各個二類任務學習分類器
- N(N-1)/2 個二類分類器
測驗階段
- 新樣本提交給所有分類器預測
- N(N-1)/2 個分類結果
- 投票產生最終分類結果
- 被預測最多的類別為最終類別
一對其余
任務拆分
- 某一類作為正例,其他反例
- N 個二類任務
- 各個二類任務學習分類器
- N 個二類分類器
測驗階段
- 新樣本提交給所有分類器預測
- N 個分類結果
- 比較各分類器預測置信度
- 置信度最大類別作為最終類別
兩種策略比較
一對一
- 訓練N(N-1)/2個分類器,存盤開銷和測驗時間大
- 訓練只用兩個類的樣例,訓練時間短
一對其余
- 訓練N個分類器,存盤開銷和測驗時間小
- 訓練用到全部訓練樣例,訓練時間長
預測性能取決于具體資料分布,多數情況下兩者差不多
多對多
- 多對多(Many vs Many, MvM)
若干類作為正類,若干類作為反類
糾錯輸出碼(Error Correcting Output Code, ECOC)
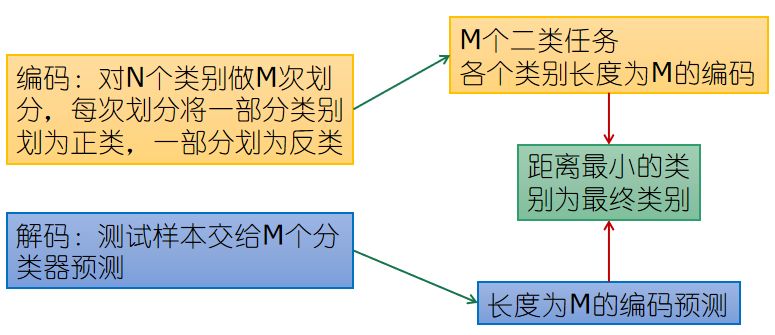
糾錯輸出碼(Error Correcting Output Code, ECOC)
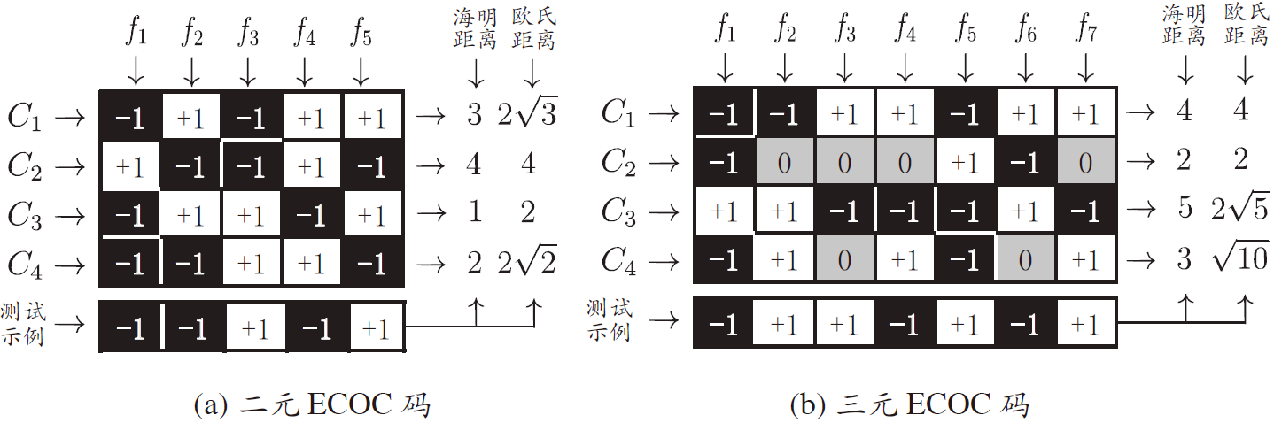
- ECOC編碼對分類器錯誤有一定容忍和修正能力,編碼越長、糾錯能力越強
- 對同等長度的編碼,理論上來說,任意兩個類別之間的編碼距離越遠,則糾錯能力越強
類別不平衡
類別不平衡(class imbalance)
- 不同類別訓練樣例數相差很大情況(正類為小類)

再縮放
- 欠采樣(undersampling)
- 去除一些反例使正反例數目接近(EasyEnsemble [Liu et al.,2009])
- 過采樣(oversampling)
- 增加一些正例使正反例數目接近(SMOTE [Chawla et al.2002])
- 直接基于原始訓練集進行學習,但在用訓練好的分類器進行預測時,將式 y ′ / 1 ? y ′ = y / 1 ? y ? m ? / m + y'/1-y' = y/1-y * m^-/m^+ y′/1?y′=y/1?y?m?/m+嵌入到其決策程序中,稱為閾值移動(threshold-moving)
優化提要
各任務下(回歸、分類)各個模型優化的目標
- 最小二乘法:最小化均方誤差
- 對數幾率回歸:最大化樣本分布似然
引數的優化方法
- 最小二乘法:線性代數
- 對數幾率回歸:凸優化梯度下降、牛頓法
線性回歸
線性回歸是屬于機器學習里面的監督學習,與分類問題不同的是,在回歸問題中,其目標是通過對訓練樣本的學習,得到從樣本特征到樣本標簽直接的映射,其中,在回歸問題中,樣本的標簽是連續值(分類是離散值),線性回歸是一類重要的回歸問題,在線性回歸中,目標值與特征直接存在線性關系,
若線性回歸方程得到多個解,下面哪些方法能夠解決此問題?
- 獲取更多的訓練樣本
- 選取樣本有效的特征,使樣本數量大于特征數
- 加入正則化項
線性回歸分析中的殘差(Residuals)
- 殘差均值總是為零
線性回歸分析中,目標是殘差最小化,殘差平方和是關于引數的函式,為了求殘差極小值,令殘差關于引數的偏導數為零,會得到殘差和為零,即殘差均值為零,
若下圖展示了兩個擬合回歸線(A 和 B),原始資料是隨機產生的,現在,我想要計算 A 和 B 各自的殘差之和,注意:兩種圖中的坐標尺度一樣,
關于 A 和 B 各自的殘差之和,下列說法正確的是?
- A 與 B 相同
A 和 B 中各自的殘差之和應該是相同的,線性回歸模型的損失函式為: L o s s = ∑ ( y ′ ? ( w x i + b ) ) 2 Loss=\sum(y'-(wxi+b))^2 Loss=∑(y′?(wxi+b))2
對損失函式求導,并令 ?Loss=0,即可得到 XW-Y=0,即殘差之和始終為零,
波士頓房價預測
sklearn中已經提供了波斯頓房價資料集的相關介面,想要使用該資料集可以使用如下代碼:
from sklearn import datasets
#加載波斯頓房價資料集
boston = datasets.load_boston()
#X表示特征,y表示目標房價
X = boston.data
y = boston.target
由資料集可以知道,每一個樣本有13個特征與目標房價,而我們要做的事就是通過這13個特征來預測房價,我們可以構建一個多元線性回歸模型,來對房價進行預測,
模型如下:
y
=
b
+
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
y=b+w_1x_1+w_2x_2+...+w_nx_n
y=b+w1?x1?+w2?x2?+...+wn?xn?
x
i
x_i
xi?:第i個特征值,
w
i
w_i
wi?:表示第i個特征對應的權重,b表示偏置,y是目標房價.
為了方便,我們稍微將模型進行變換:
y = w 0 x 0 + w 1 x 1 + w 2 x 2 + . . . + w n x n y=w_0x_0+w_1x_1+w_2x_2+...+w_nx_n y=w0?x0?+w1?x1?+w2?x2?+...+wn?xn?
其中 x 0 x_0 x0?等于1.
Y = h e t a X Y = hetaX Y=hetaX
h
e
t
a
=
(
w
0
,
w
1
,
.
.
,
w
n
)
heta=(w_0, w_1,..,w_n)
heta=(w0?,w1?,..,wn?)
X
=
(
1
,
x
1
,
.
.
.
.
,
x
n
)
X=(1,x_1,....,x_n)
X=(1,x1?,....,xn?)
而我們的目的就是找出能夠正確預測的多元線性回歸模型,即找出正確的引數heta,
那么如何尋找呢?通常在監督學習里面都會使用這么一個套路,構造一個損失函式,用來衡量真實值與預測值之間的差異,然后將問題轉化為最優化損失函式, 既然損失函式是用來衡量真實值與預測值之間的差異那么很多人自然而然的想到了用所有真實值與預測值的差的絕對值來表示損失函式,不過帶絕對值的函式不容易求導,所以采用MSE(均方誤差)作為損失函式,公式如下:
L o s s = ∑ ( y i ? p i ) 2 / m Loss=\sum(y^i-p^i)^2/m Loss=∑(yi?pi)2/m
線性回歸的正規方程解
對線性回歸模型,假設訓練集中m個訓練樣本,每個訓練樣本中有n個特征,可以使用矩陣的表示方法,預測函式可以寫為: Y = h e t a X Y = hetaX Y=hetaX
其損失函式可以表示為:
(
Y
?
h
e
t
a
X
)
T
(
Y
?
h
e
t
a
X
)
(Y-hetaX)^T(Y-hetaX)
(Y?hetaX)T(Y?hetaX)
其中,標簽Y為[m,1]的矩陣,訓練特征X為[m,(n+1)](n列特征+1列偏置)的矩陣,回歸系數heta為[(n+1), 1]的矩陣,對heta求導,并令其導數等于0,可以得到: X T ( Y ? h e t a X ) = 0 X^T(Y-hetaX)=0 XT(Y?hetaX)=0,
所以,最優解為: h e t a = ( X T X ) ? 1 X T Y heta=(X^TX)^{-1}X^TY heta=(XTX)?1XTY
這個就是正規方程解,我們可以通過最優方程解直接求得我們所需要的引數,
線性代數的知識
import numpy as np
def mse_score(y_predict,y_test):
'''
input:y_predict(ndarray):預測值
y_test(ndarray):真實值
ouput:mse(float):mse損失函式值
'''
#********* Begin *********#
mse = np.mean((y_predict-y_test)**2)
#********* End *********#
return mse
class LinearRegression :
def __init__(self):
'''初始化線性回歸模型'''
self.theta = None
def fit_normal(self,train_data,train_label):
'''
input:train_data(ndarray):訓練樣本
train_label(ndarray):訓練標簽
'''
#********* Begin *********#
# 特征值x水平拼接一列全為零的數(初始化偏置)
x = np.hstack([np.ones((len(train_data),1)),train_data])
# 計算權重的正規方程最優解
self.theta = np.linalg.inv(x.T.dot(x)).dot(x.T).dot(train_label)
#********* End *********#
return self.theta
def predict(self,test_data):
'''
input:test_data(ndarray):測驗樣本
'''
#********* Begin *********#
# 特征值x水平拼接(左右拼接)一列全為零的數(初始化偏置)
x = np.hstack([np.ones((len(test_data),1)),test_data])
return x.dot(self.theta) # WX=Y:預測值
#********* End *********#
np.ones((5,1)) # 維度必須()或[]
np.ones([5,1])
array([[1.],
[1.],
[1.],
[1.],
[1.]])
性能評估
MSE
MSE (Mean Squared Error)叫做均方誤差,公式如下:
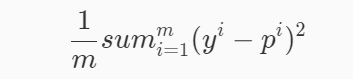
mse = np.mean((y_predict-y_test)**2)

RMSE(Root Mean Squard Error)均方根誤差,公式如下:
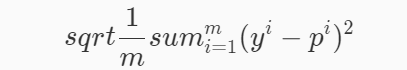
rmse = np.sqrt(np.mean((y_predict-y_test)**2))
RMSE其實就是MSE開個根號,有什么意義呢?其實實質是一樣的,只不過用于資料更好的描述,
例如:要做房價預測,每平方是萬元,我們預測結果也是萬元,那么差值的平方單位應該是千萬級別的,那我們不太好描述自己做的模型效果,怎么說呢?我們的模型誤差是多少千萬?于是干脆就開個根號就好了,我們誤差的結果就跟我們資料是一個級別的了,在描述模型的時候就說,我們模型的誤差是多少萬元,
MAE
MAE(平均絕對誤差),公式如下:
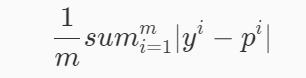
MAE雖然不作為損失函式,確是一個非常直觀的評估指標,它表示每個樣本的預測標簽值與真實標簽值的L1距離,
mae = np.mean((y_predict-y_test))

R-Squared
上面的幾種衡量標準針對不同的模型會有不同的值,比如說預測房價 那么誤差單位就是萬元,數子可能是3,4,5之類的,那么預測身高就可能是0.1,0.6之類的,沒有什么可讀性,到底多少才算好呢?不知道,那要根據模型的應用場景來,
看看分類演算法的衡量標準就是正確率,而正確率又在0~1之間,最高百分之百,最低0,如果是負數,則考慮非線性相關,很直觀,而且不同模型一樣的,那么線性回歸有沒有這樣的衡量標準呢?
R-Squared就是這么一個指標,公式如下:
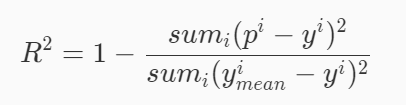
R
2
=
1
?
M
S
E
/
V
a
r
R^2=1-MSE/Var
R2=1?MSE/Var
r2 =1-mse_score(y_predict,y_test)/np.var(y_test)
r2 = 1- np.mean((y_predict-y_test)**2)/np.var(y_test)
np.var(y_test):計算方差
scikit-learn線性回歸實踐
import pandas as pd
from sklearn.linear_model import LinearRegression
#獲取訓練資料
train_data = pd.read_csv('./step3/train_data.csv')
#獲取訓練標簽
train_label = pd.read_csv('./step3/train_label.csv')
train_label = train_label['target']
#獲取測驗資料
test_data = pd.read_csv('./step3/test_data.csv')
lr = LinearRegression()
#訓練模型
lr.fit(train_data,train_label)
#獲取預測標簽
predict = lr.predict(test_data)
#將預測標簽寫入csv
df = pd.DataFrame({'result':predict})
df.to_csv('./step3/result.csv', index=False)
LinearRegression的建構式中有兩個常用的引數可以設定:
- fit_intercept:是否有截據,如果沒有則直線過原點,默認為Ture,
- normalize:是否將資料歸一化,默認為False,
LinearRegression類中的fit函式用于訓練模型,fit函式有兩個向量輸入:
- X:大小為 [樣本數量,特征數量] 的ndarray,存放訓練樣本
- Y:值為整型,大小為 [樣本數量] 的ndarray,存放訓練樣本的標簽值
LinearRegression類中的predict函式用于預測,回傳預測值,predict函式有一個向量輸入:
- X:大小為 [樣本數量,特征數量] 的ndarray,存放預測樣本
更詳細,請參考:【線性回歸】案例:波士頓房價預測
正規方程
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_squared_error
def linear_model1():
"""
線性回歸:正規方程
:return:None
"""
# 1.獲取資料
data = load_boston()
# 2.資料集劃分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征工程-標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.機器學習-線性回歸(正規方程)
estimator = LinearRegression()
estimator.fit(x_train, y_train)
# 5.模型評估
# 5.1 獲取系數等值
y_predict = estimator.predict(x_test)
print("預測值為:\n", y_predict)
print("模型中的系數為:\n", estimator.coef_)
print("模型中的偏置為:\n", estimator.intercept_)
# 5.2 評價
# 均方誤差
error = mean_squared_error(y_test, y_predict)
print("誤差為:\n", error)
return None
梯度下降
def linear_model2():
"""
線性回歸:梯度下降法
:return:None
"""
# 1.獲取資料
data = load_boston()
# 2.資料集劃分
x_train, x_test, y_train, y_test = train_test_split(data.data, data.target, random_state=22)
# 3.特征工程-標準化
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.fit_transform(x_test)
# 4.機器學習-線性回歸(特征方程)
estimator = SGDRegressor(max_iter=1000)
estimator.fit(x_train, y_train)
# 5.模型評估
# 5.1 獲取系數等值
y_predict = estimator.predict(x_test)
print("預測值為:\n", y_predict)
print("模型中的系數為:\n", estimator.coef_)
print("模型中的偏置為:\n", estimator.intercept_)
# 5.2 評價
# 均方誤差
error = mean_squared_error(y_test, y_predict)
print("誤差為:\n", error)
return None
癌細胞預測
邏輯回歸是在線性回歸的輸出結果加上激活函式進行非線性的映射,如:sigmoid函式,
σ ( t ) = 1 / ( 1 + e ? t ) σ(t)=1/(1+e^{?t}) σ(t)=1/(1+e?t)
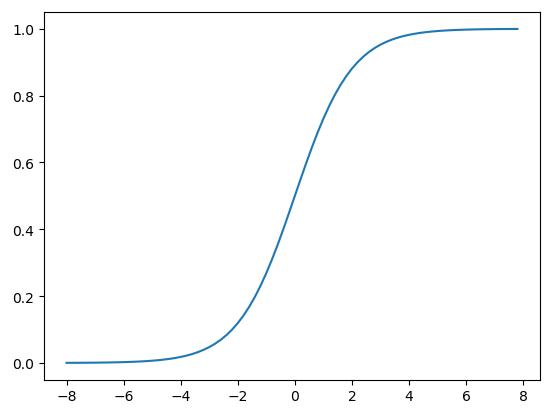
值域為(0,1),
import numpy as np
def sigmoid(t):
'''
完成sigmoid函式計算
:param t: 負無窮到正無窮的實數
:return: 轉換后的概率值
:可以考慮使用np.exp()函式
'''
return 1 / (1 + np.exp(-t))
為什么需要損失函式?
訓練邏輯回歸模型的程序其實與之前學習的線性回歸一樣,就是去尋找合適的 W T W^T WT和 b b b 使得模型的預測結果與真實結果盡可能一致,所以就需要一個函式能夠衡量模型擬合程度的好壞,也就是說當模型擬合誤差越大的時候,函式值應該比較大,反之應該比較小,這就是損失函式,
邏輯回歸的損失函式
我們已經知道了邏輯回歸計算出的樣本所屬類別的概率
p
=
σ
(
W
T
x
+
b
)
p=σ(W^T x+b)
p=σ(WTx+b),樣本所屬串列的判定條件為:
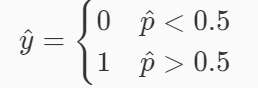
所以邏輯回歸的損失函式如下,其中 cost 表示損失函式的值, y 表示樣本的真實類別:
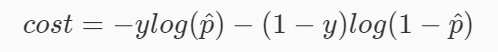
這個式子其實很好理解,當樣本的真實類別為 1 時,式子就變成了
c
o
s
t
=
?
l
o
g
(
p
)
cost=-log(p)
cost=?log(p),此時函式影像如下:
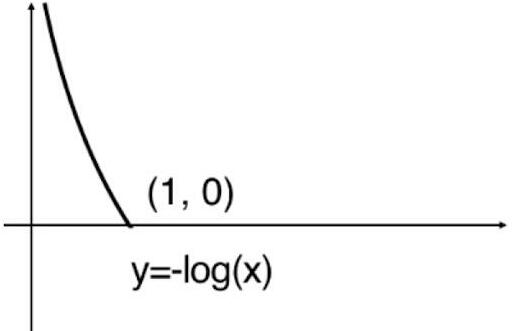
從影像能看出當樣本的真實類別為1的前提下,p越大,損失函式值就越小,因為p越大就越說明模型越認為該樣本的類別為 1,
當樣本的真實類別為 0 時,式子就變成了
c
o
s
t
=
?
l
o
g
(
1
?
p
)
cost=?log(1? p)
cost=?log(1?p) ,此時函式影像如下:
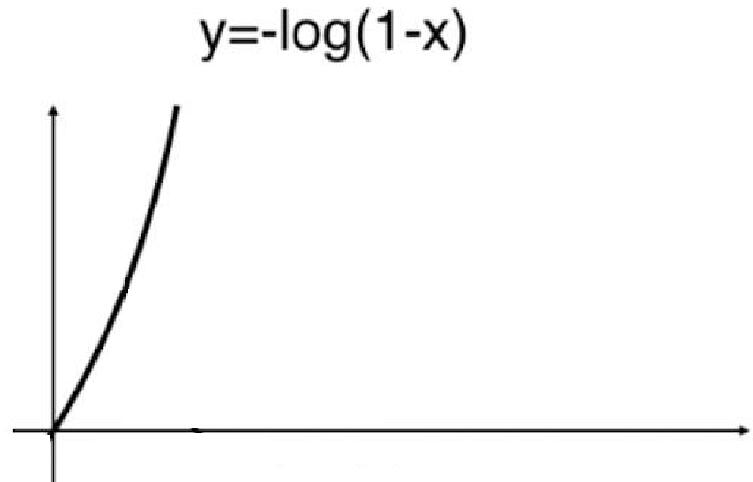
從影像能看出當樣本的真實類別為0的前提下,p越大,損失函式值就越大,因為p越大就越說明模型越認為該樣本的類別為 1,

邏輯回歸的損失函式可以寫成如下形式:
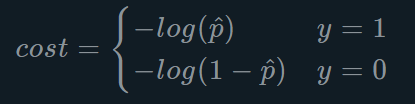
- 損失值能夠衡量模型在訓練資料集上的擬合程度
- sigmoid函式的輸入越大,輸出就越大
- 訓練的程序,就是尋找合適的引數使得損失函式值最小的程序
sigmoid函式(對數幾率函式)相對于單位階躍函式有哪些好處?
- sigmoid函式可微分
- sigmoid函式處處連續
邏輯回歸的優點有哪些?
- 可以用現有的數值優化演算法求解
梯度下降
梯度:梯度的本意是一個向量,由函式對每個引數的偏導組成,表示某一函式在該點處的方向導數沿著該方向取得最大值,即函式在該點處沿著該方向變化最快,變化率最大,
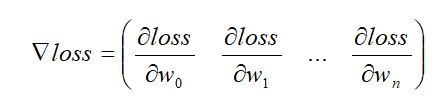
梯度下降演算法原理
演算法思想:梯度下降是一種非常通用的優化演算法,能夠為大范圍的問題找到最優解,梯度下降的中心思想就是迭代地調整引數從而使損失函式最小化,假設你迷失在山上的迷霧中,你能感覺到的只有你腳下路面的坡度,快速到達山腳的一個策略就是沿著最陡的方向下坡,這就是梯度下降的做法:通過測量引數向量 θ 相關的損失函式的區域梯度,并不斷沿著降低梯度的方向調整,直到梯度降為 0 ,達到最小值,
為了尋求損失函式的最小值,不斷沿著函式變化最快的地方(梯度),降低梯度直到梯度為0即是函式最小值,即可獲得最優引數向量,
梯度下降公式如下:
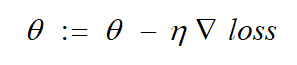
對應到每個權重公式為:
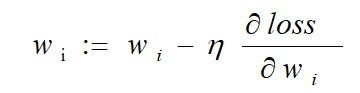
其中 η 為學習率,是 0 到 1 之間的值,是個超引數,需要我們自己來確定大小,
演算法原理:
在傳統機器學習中,損失函式通常為凸函式,假設此時只有一個引數,則損失函式對引數的梯度即損失函式對引數的導數,如果剛開始引數初始在最優解的左邊,
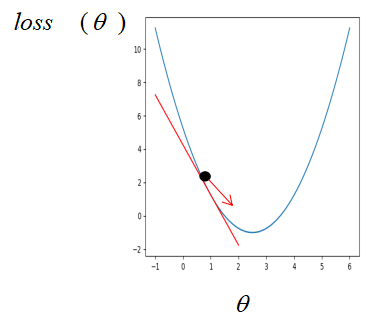
很明顯,這個時候損失函式對引數的導數是小于 0 的(函式遞減),而學習率是一個 0 到 1 之間的數,此時按照公式更新引數,初始的引數減去一個小于 0 的數是變大,也就是在坐標軸上往右走,即朝著最優解的方向走,同樣的,如果引數初始在最優解的右邊,
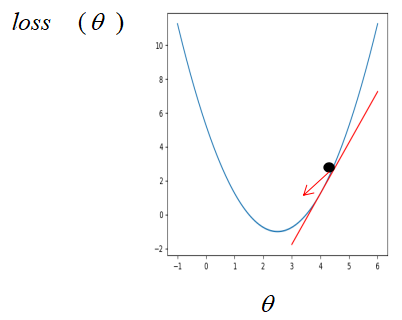
此時按照公式更新,引數將會朝左走,即最優解的方向,所以,不管剛開始引數初始在何位置,按著梯度下降公式不斷更新,引數都會朝著最優解的方向走,
梯度下降演算法流程
- 隨機初始引數;
- 確定學習率;
- 求出損失函式對引數梯度;
- 按照公式更新引數;
- 重復 3 、 4 直到滿足終止條件(如:損失函式或引數更新變化值小于某個閾值,或者訓練次數達到設定閾值),
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def gradient_descent(initial_theta,eta=0.05,n_iters=1000,epslion=1e-8):
'''
梯度下降
:param initial_theta: 引數初始值,型別為float
:param eta: 學習率,型別為float
:param n_iters: 訓練輪數,型別為int
:param epslion: 容忍誤差范圍,型別為float
:return: 訓練后得到的引數
'''
theta = initial_theta
for i in range(n_iters):
gradient = 2*(theta-3) # 梯度計算
last_theta = theta # 記錄上一次的引數向量
theta = theta - eta*gradient # 梯度下降
# 如果損失函式值或引數更新變化值小于閾值則提前結束(Loss值變化不明顯)
if (abs(theta-last_theta) < epslion):
break
return theta
動手實作邏輯回歸 - 癌細胞精準識別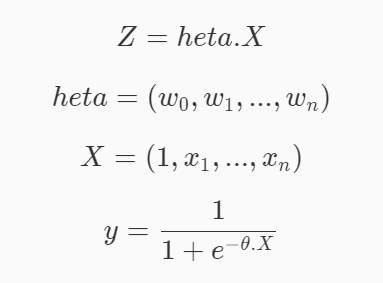
損失函式對每個引數的偏導:
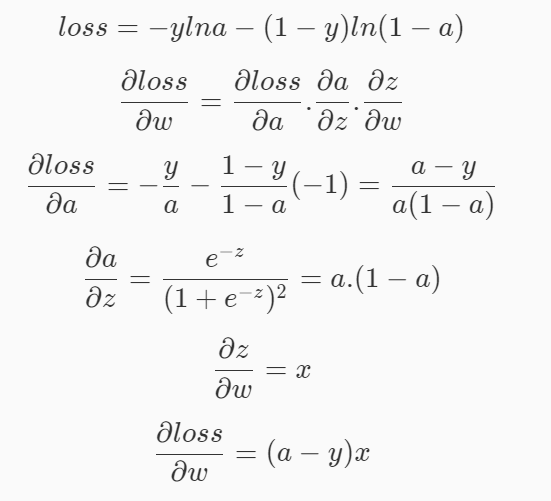
于是,在邏輯回歸中的梯度下降公式如下:
w
i
=
w
i
?
n
(
a
?
y
)
x
i
w_i=w_i-n(a-y)xi
wi?=wi??n(a?y)xi
import numpy as np
import warnings
warnings.filterwarnings("ignore")
def sigmoid(x):
'''
sigmoid函式
:param x: 轉換前的輸入
:return: 轉換后的概率
'''
return 1/(1+np.exp(-x))
def fit(x,y,eta=1e-3,n_iters=10000):
'''
訓練邏輯回歸模型
:param x: 訓練集特征資料,型別為ndarray
:param y: 訓練集標簽,型別為ndarray
:param eta: 學習率,型別為float
:param n_iters: 訓練輪數,型別為int
:return: 模型引數,型別為ndarray
'''
# 初始化權重,x.shape()形狀(m,n):m行n列,n為特征數
theta = np.zeros(x.shape[1]) # theta形狀(n,)
i = 0
while i < n_iters:
# 計算梯度
gradient = (sigmoid(x.dot(theta))-y).dot(x)
# 權重梯度下降,相當于沿著函式遞減的方向移動x軸的值即theta
# 請結合高等數學來思考
theta = theta - eta*gradient
i += 1
return theta
計算梯度:gradient = (sigmoid(x.dot(theta))-y).dot(x)代碼演示:
# 生成4個資料,每一條資料3個特征值
x = np.arange(1,13).reshape((4, 3))
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
x.shape
(4, 3)
theta = np.ones(x.shape[1])
array([1., 1., 1.])
# 初始化y值
y = np.ones(x.shape[0])
array([1., 1., 1., 1.])
# x的每一行都和theta進行向量點積得到預測的y值
x.dot(theta)
array([ 6., 15., 24., 33.])
應該懂了嘛!
邏輯回歸api介紹
-
sklearn.linear_model.LogisticRegression(solver='liblinear', penalty=‘l2’, C = 1.0)-
solver可選引數:{'liblinear', 'sag', 'saga','newton-cg', 'lbfgs'},-
默認:
'liblinear';用于優化問題的演算法, -
對于小資料集來說,
“liblinear”是個不錯的選擇,而“sag”和’saga'對于大型資料集會更快, -
對于多類問題,只有
'newton-cg', 'sag', 'saga'和'lbfgs'可以處理多項損失;“liblinear”僅限于“one-versus-rest”分類,
-
-
penalty:正則化的種類 -
C:正則化力度,默認為 1.0 ,越小代表正則化越強;
-
默認將類別數量少的當做正例
LogisticRegression方法相當于SGDClassifier(loss=“log”, penalty=" "),SGDClassifier實作了一個普通的隨機梯度下降學習,而使用LogisticRegression(實作了SAG)
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
# 1.獲取資料
names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
data = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data",
names=names)
# 2.基本資料處理
# 2.1 缺失值處理
data = data.replace(to_replace="?", value=np.NaN)
data = data.dropna()
# 2.2 確定特征值,目標值
x = data.iloc[:, 1:10]
x.head()
y = data["Class"]
y.head()
# 2.3 分割資料
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
# 3.特征工程(標準化)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 4.機器學習(邏輯回歸)
estimator = LogisticRegression()
estimator.fit(x_train, y_train)
# 5.模型評估
y_predict = estimator.predict(x_test)
y_predict
estimator.score(x_test, y_test)
更多內容,請參考:【機器學習】邏輯回歸演算法
# 0.5~1之間,越接近于1約好
y_test = np.where(y_test > 2.5, 1, 0)
print("AUC指標:", roc_auc_score(y_test, y_predict)
-
AUC的概率意義是隨機取一對正負樣本,正樣本得分大于負樣本得分的概率
-
AUC的范圍在[0, 1]之間,并且越接近1越好,越接近0.5屬于亂猜
-
AUC=1,完美分類器,采用這個預測模型時,不管設定什么閾值都能得出完美預測,絕大多數預測的場合,不存在完美分類器,
-
0.5<AUC<1,優于隨機猜測,這個分類器(模型)妥善設定閾值的話,能有預測價值,
手寫數字識別
資料簡介
本關使用的是手寫數字資料集,該資料集有 1797 個樣本,每個樣本包括 8*8 像素(實際上是一條樣本有 64 個特征,每個像素看成是一個特征,每個特征都是float型別的數值)的影像和一個 [0, 9] 整數的標簽,
比如下圖的標簽是 2 :
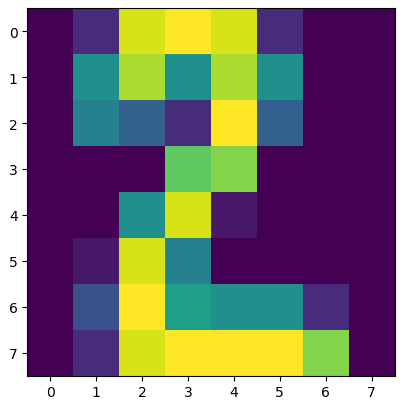
from sklearn import datasets
import matplotlib.pyplot as plt
# 加載資料集
digits = datasets.load_digits()
# X表示影像資料,y表示標簽
X = digits.data
y = digits.target
# 將第233張手寫數字可視化
plt.imshow(digits.images[232])
logreg = LogisticRegression(solver='lbfgs',max_iter =10,C=10)
logreg.fit(X_train, Y_train)
result = logreg.predict(X_test)
train_image:訓練集影像,型別為ndarray,shape=[-1, 8, 8];
from sklearn.linear_model import LogisticRegression
def digit_predict(train_image, train_label, test_image):
'''
實作功能:訓練模型并輸出預測結果
:param train_sample: 包含多條訓練樣本的樣本集,型別為ndarray,shape為[-1, 8, 8]
:param train_label: 包含多條訓練樣本標簽的標簽集,型別為ndarray
:param test_sample: 包含多條測驗樣本的測驗集,型別為ndarry
:return: test_sample對應的預測標簽
'''
# 訓練集變形
train_image = train_image.reshape(-1, 64)
# 訓練集標準化
train_min = flat_train_image.min()
train_max = flat_train_image.max()
train_image = (train_image-train_min)/(train_max-train_min)
# 測驗集變形
test_image = test_image.reshape((-1, 64))
# 測驗集標準化
test_min = test_image.min()
test_max = test_image.max()
test_image = (test_image - test_min) / (test_max - test_min)
# 訓練--預測
rf = LogisticRegression(C=4.0) # C:正則化力度,默認為 1.0 ,越小代表正則化越強;
rf.fit(train_image, train_label)
return rf.predict(test_image)
X'=(x?min)/(max??min)
特征預處理中的歸一化處理:
歸一化首先在特征(維度)非常多的時候,可以防止某一維或某幾維對資料影響過大,也是為了把不同來源的資料統一到一個參考區間下,這樣比較起來才有意義,其次可以程式可以運行更快,
例如:一個人的身高和體重兩個特征,假如體重50kg,身高175cm,由于兩個單位不一樣,數值大小不一樣,如果比較兩個人的體型差距時,那么身高的影響結果會比較大,因此在做計算之前需要先進行歸一化操作,
請參考:【機器學習】帶你搞懂什么是特征工程?(特征抽取&特征預處理&特征選擇&資料降維)
第四章:決策樹
基本流程
決策樹基于樹結構來進行預測
- 決策程序中提出的每個判定問題都是對某個屬性的“測驗”
- 決策程序的最終結論對應了我們所希望的判定結果
- 每個測驗的結果或是匯出最終結論,或者匯出進一步的判定問題,其考慮范圍是在上次決策結果的限定范圍之內
- 從根結點到每個葉結點的路徑對應了一個判定測驗序列
決策樹學習的目的是為了產生一棵泛化能力強,即處理未見示例能力強的決策樹
劃分選擇
決策樹學習的關鍵在于如何選擇最優劃分屬性,一般而言,隨著劃分程序不斷進行,我們希望決策樹的分支結點所包含的樣本盡可能屬于同一類別,即結點的“純度”(purity)越來越高
經典的屬性劃分方法:
- 資訊增益
- 增益率
- 基尼指數
資訊增益
“資訊熵”是度量樣本集合純度最常用的一種指標,假定當前樣本集合D中第k類樣本所占的比例為
p
k
p_k
pk?,則D的資訊熵定義為:
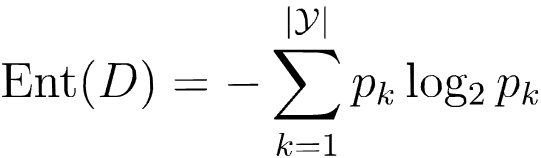
Ent(D)的值越小,則D的純度越高,
- 計算資訊熵時約定:若p=0, p ? l o g 2 p = 0 p*log2^p = 0 p?log2p=0.
- Ent(D)的最小值為0,最大值 l o g 2 y log2^y log2y.

- 一般而言,資訊增益越大,則意味著使用屬性a來進行劃分所獲得的“純度提升”越大
- ID3決策樹學習演算法[Quinlan, 1986]以資訊增益為準則來選擇劃分屬性
資訊增益實體
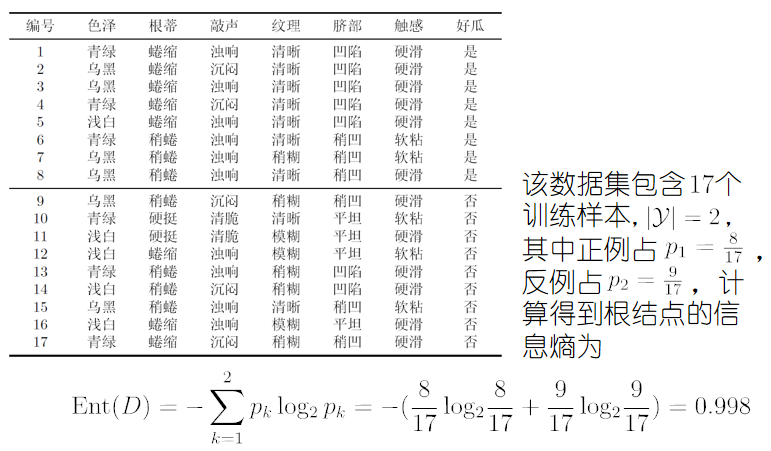

存在的問題
若把“編號”也作為一個候選劃分屬性,則其資訊增益一般遠大于其他屬性,顯然,這樣的決策樹不具有泛化能力,無法對新樣本進行有效預測,
資訊增益對可取值數目較多的屬性有所偏好
增益率

存在的問題:
- 增益率準則對可取值數目較少的屬性有所偏好
C4.5 [Quinlan, 1993]使用了一個啟發式:先從候選劃分屬性中找出資訊增益高于平均水平的屬性,再從中選取增益率最高的
基尼指數
資料集D的純度可用“基尼值”來度量:
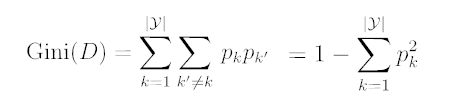
-
反映了從D中隨機抽取兩個樣本,其類別標記不一致的概率.
-
Gini(D):越小,資料集D的純度越高.

CART [Breiman et al., 1984]采用“基尼指數”來選擇劃分屬性
剪枝處理
為什么剪枝?
- “剪枝”是決策樹學習演算法對付“過擬合”的主要手段
- 可通過“剪枝”來一定程度避免因決策分支過多,以致于把訓練集自身的一些特點當做所有資料都具有的一般性質而導致的過擬合
剪枝的基本策略
- 預剪枝
- 后剪枝
判斷決策樹泛化性能是否提升的方法
- 留出法:預留一部分資料用作“驗證集”以進行性能評估
預剪枝
決策樹生成程序中,對每個結點在劃分前先進行估計,若當前結點的劃分不能帶來決策樹泛化性能提升,則停止劃分并將當前結點記為葉結點,其類別標記為訓練樣例數最多的類別
針對上述資料集,基于資訊增益準則,選取屬性“臍部”劃分訓練集,分別計算劃分前(即直接將該結點作為葉結點)及劃分后的驗證集精度,判斷是否需要劃分,若劃分后能提高驗證集精度,則劃分,對劃分后的屬性,執行同樣判斷;否則,不劃分
預剪枝的優缺點
優點
- 降低過擬合風險
- 顯著減少訓練時間和測驗時間開銷
缺點
- 欠擬合風險:有些分支的當前劃分雖然不能提升泛化性能,但在其基礎上進行的后續劃分卻有可能導致性能顯著提高,預剪枝基于“貪心”本質禁止這些分支展開,帶來了欠擬合風險
后剪枝
先從訓練集生成一棵完整的決策樹,然后自底向上地對非葉結點進行考察,若將該結點對應的子樹替換為葉結點能帶來決策樹泛化性能提升,則將該子樹替換為葉結點
后剪枝的優缺點
優點
- 后剪枝比預剪枝保留了更多的分支,欠擬合風險小,泛化性能往往優于預剪枝決策樹
缺點
- 訓練時間開銷大:后剪枝程序是在生成完全域策樹之后進行的,需要自底向上對所有非葉結點逐一考察
ID3,C4.5和CART演算法對比
相同點:都采用貪心方法,以自頂向下遞回的分治方式構造,隨著樹的構建,訓練集遞回地被劃分為子集
不同點:
- ID3演算法基于資訊增益為準則來選擇劃分屬性,依賴于特征數目多的特征,沒有考慮少特征和不完整資料,抗噪性差,容易產生過擬合.
- C4.5演算法基于增益率準則來選擇劃分屬性,使用了一個啟發式:先從候選劃分屬性中找出資訊增益高于平均水平的屬性,再從中選取增益率最高的,對可取值數目較少的屬性有所偏好,
第五章 神經網路
試推匯出BP演算法中的更新公式
推導程序就是符號有點復雜,其他的就是高數里的鏈式求導,
Some note for comprehend
- 輸出層與輸入層之間的一層神經元稱為隱層或隱含層,隱含層和輸出層神經元都是擁有激活函式的神經元.
- 多層前饋神經網路:每層神經元與下層神經元全互聯,神經元之間不存在同層連接,也不存在跨層連接.
- 輸出層神經元與輸出層神經元對信號進行加工,最終結果由輸出神經元輸出. 換言之,輸入層只接受輸入,不進行函式處理,隱層與輸出層包含功能神經元.
- 包含一層隱層為兩層神經網路(西瓜書為單隱層網路)
- 神經網路的學習程序,就是訓練資料來調整神經元之間的“連接權”以及每個功能神經元的閾值;換言之,神經網路“學”到的東西,蘊含在連接權與閾值中.
- 個人理解神將網路就是由多個線性回歸組成每一層網路的神經元,具有不同的權重與閾值(具有不同的功能),每一層加入不同的激活函式,進行非線性處理,
BP誤差逆傳播演算法(error BackPropagation)
第六章:支持向量機
什么是支持向量機
支持向量機也稱為“支持向量網路”,是一種判別式機器學習分類演算法,它使用決策邊界(超平面)一次將資料點分類兩類(這并不意味著它只是一個二進制分類器,一次將資料分為兩類)支持向量分類器的主要目標是找到“最佳超平面”(決策邊界),
試析SVM 對噪聲敏感的原因
參考1:
- SVM 的特性就是"支持向量" .即線性超平面只由少數"支持向量"所決定.若噪聲成為了某個"支持向量"――這是非常有可能的.那么對整個分類的影響是巨大的.反觀對率回歸,其線性超平面由所有資料共同決定,因此一點噪聲并無法對決策平面造成太大影響.
參考2:
- 因為SVM最終只用到了若干支持向量來生成分類的超平面,如果噪聲更好成為支持向量,則整個超平面的劃分就會有問題.而噪聲往往又都是outlier離群點,容易成為支持向量.
參考3:
- SVM的基本形態是一個硬間隔分類器,它要求所有樣本都滿足硬間隔約束(即函式間隔要大于1)
- 當資料集中存在噪聲點但是仍然滿足線性可分的條件時,SVM為了把噪聲點也劃分正確,超平面就會向另外一個類的樣本靠攏,這就使得劃分超平面的幾何間距變小,從而降低了模型的泛化性能,
- 當資料集因為存在噪聲點而導致已經無法線性可分時,此時就使用了核技巧,通過將樣本映射到高維特征空間使得樣本線性可分,這樣就會得到—個復雜模型,并由此導致過擬合(原樣本空間得到的劃分超平面會是彎彎曲曲的,它確實可以把所有樣本都劃分正確,但得到的模型只對訓練集有效),泛化能力極差,
- 當資料集因為存在噪聲點而導致已經無法線性可分時,此時就使用了核技巧,通過將樣本映射到高維特征空間使得樣本線性可分,這樣就會得到—個復雜模型,并由此導致過擬合(原樣本空間得到的劃分超平面會是彎彎曲曲的,它確實可以把所有樣本都劃分正確,但得到的模型只對訓練集有效),泛化能力極差,
核函式的作用
隱含著一個從低維空間到高維空間的映射,這個映射可以把低維空間中的線性不可分的兩類點變成線性可分的.
正則化
正則化的主要作用是防止過擬合,對模型添加正則化項可以限制模型的復雜度,使模型在復雜度和性能能達到平衡.
常用方法:有L1正則化和L2正則化,L1正則化和L2正則化可以看做是損失函式的懲罰項,所謂“懲罰”是指對損失函式中的某些引數做一些限制.
L1正則化模型:Lasso回歸
L2正則化模型:Ridge回歸(嶺回歸)
第七章:貝葉斯分類器
第八章:集成學習
Boosting&Bagging
Boosting:個體學習器存在強依賴關系,必須串行生成的序列化方法.
Bagging和隨機森林(RF):個體學習器間不存在強依賴關系,可同時生成并行化方法.
區別:
1. 訓練樣本
- Boosting:每一輪的訓練集都是原始訓練集,只是每次訓練后會根據本輪的訓練結果調整訓練集中的各個樣本的權重,調整完權重的訓練集用于下一輪的訓練.
- Bagging:每個訓練集都是以原始訓練集中有放回的選取出來的,每個訓練集各不相同且相互獨立.
2. 樣本權重不同
- Boosting:根據每輪的訓練不斷調整權值,分類錯誤的樣本擁有更高的權值.
- Bagging:使用Boostraping的方式均勻抽樣,每個樣例權重相等
3. 分類器權重
- Boosting:每個弱分類器都有回應的權重,對分類誤差小的分類器有更大的權重,結果是基分類器加權結合.
- Bagging:所有若分類器權重相同,對分類任務使用簡單投票法,對回歸任務使用簡單平均法決定最終結果.
4. 并行計算
- Boosting:各個預測函式只能順序生成,因為每一個模型的訓練永遠建立在前一個模型的基礎上.
- Bagging:各個預測函式可以并行生成,因為資料集相互獨立,每個模型之間也獨立,沒有序列關系.
5. 從偏差-方差
- Boosting關注于降低偏差,Bagging關于降低方差
第九章:聚類
聚類任務
- 在“無監督學習”任務中研究最多、應用最廣.
- 聚類目標:將資料集中的樣本劃分為若干個通常不相交的子集(“簇”,cluster).
- 聚類既可以作為一個單獨程序(用于找尋資料內在的分布結構),也可作為分類等其他學習任務的前驅程序.
“簇”可能對應于一些潛在的概念(類別),如:“淺色瓜”,“有籽瓜”;這些概念對聚類演算法而言是事先未知的,聚類程序能自動形成簇結構,簇所對應的概念語意由使用者來把握和命名.
第十章:降維與度量學習
降維
-
降維是將訓練資料中的樣本從高維空間轉換到低位空間,該程序與資訊論中有損壓縮概念密切相關,不存在完全無損的降維,
-
降維是指通過保留一些比較重要的特征,去除一些冗余的特征,減少資料特征的維度,而特征的重要性取決于該特征能夠表達多少資料集的資訊,也取決于使用什么方法進行降維,一般情況會先使用線性的降維方法再使用非線性的降維方法,通過結果去判斷哪種方法比較合適,
降維的本質是學習一個映射函式 f : x->y,其中x是原始資料點的表達,目前最多使用向量表達形式, y是資料點映射后的低維向量表達,通常y的維度小于x的維度(當然提高維度也是可以的),f可能是顯式的或隱式的、線性的或非線性的,
在哪里用到降維?
1)特征維度過大,可能會導致過擬合時
2)某些樣本資料不足的情況(缺失值很多)
3)特征間的相關性比較大時
降維的好處?
(1)節省存盤空間;
(2)加速計算速度,維度越少,計算量越少,并且能夠使用那些不適合于高維度的演算法;
(3)去除一些冗余的特征(原資料中既有平方米和平方英里的特征–即相關性大的特征)
(4)便于觀察和挖掘資訊(如將資料維度降到2維或者3維使之能可視化)
(5)特征太多或者太復雜會使得模型過擬合,
總結
- 單從機器學習角度來說:想要學好ML還是需要下更多功夫去鉆研的,
- 單從考試角度來說:想考個及格/80+還是不難的,畢竟考試比較水,大家都懂,
- 考試既然水,分數就無所謂高低,重要的是我們學了多少東西,
- 如果看到這里,首先恭喜你與我同在,提前祝你考一個好的成績,
- 如果有用的話,小伙伴幫忙點贊/打賞,算是對俺無私分享的支持與鼓勵,
- 再次感謝大家的支持與陪伴,感謝其他學霸/大佬對此文的貢獻,我僅僅是一個文字搬運工,分享快樂,
加油!
感謝!
努力!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379394.html
標籤:AI
下一篇:起點