文章目錄
- 1 需求分析
- 1.1 資料一覽
- 1.2 資料清洗
- 1.3 分類下的統計與排序
- 1.4 分類下的求均值與排序
- 1.5 多維度下的綜合統計
- 2 技術實作
- 2.1 環境搭建
- 2.2 實作:資料清洗
- 2.3 實作:分類下的統計與排序
- 2.4 實作:分類下的求均值與排序
- 2.5 實作:多維度下的綜合統計
- 3 完整代碼與資料檔案
1 需求分析
1.1 資料一覽
如下圖所示,共一萬多條資料,除去首行,共 13036 條酒店資料,
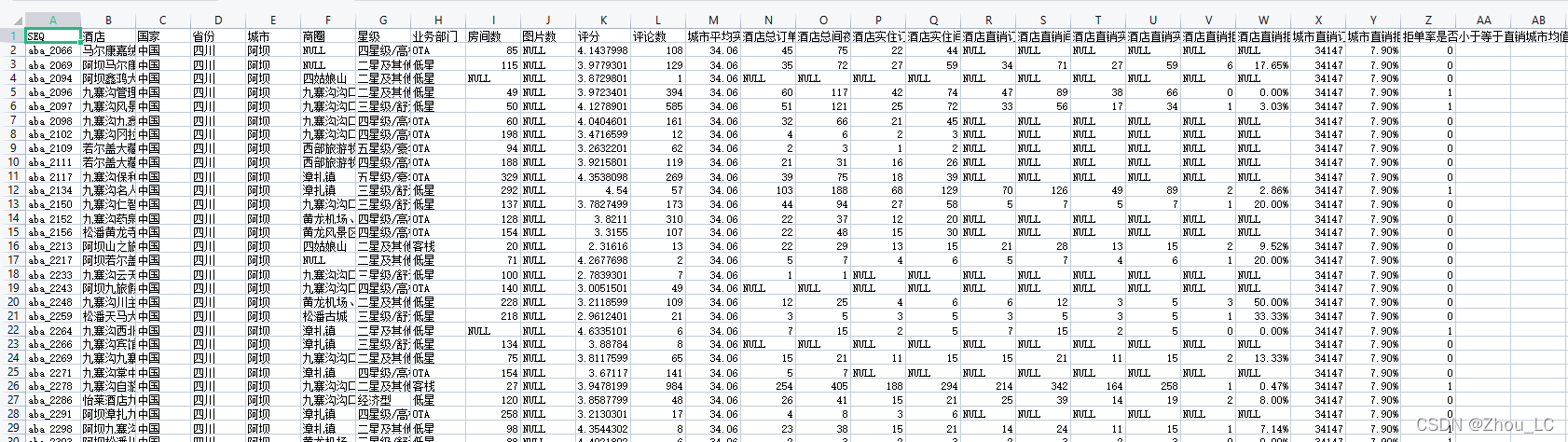
…

1.2 資料清洗
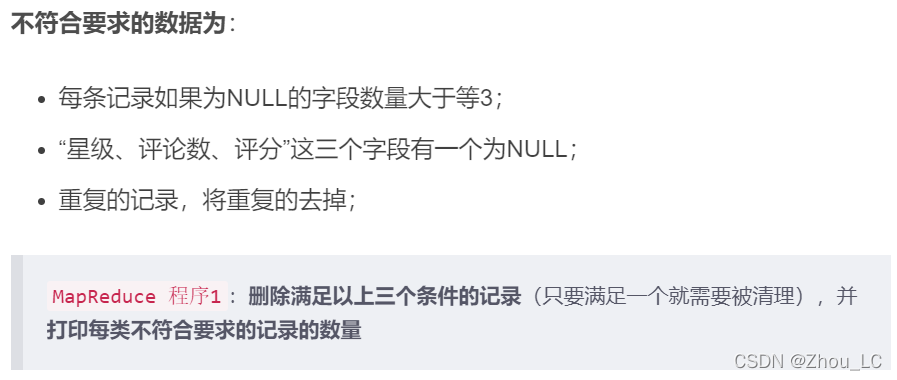
不符合要求的資料為:
- 每條記錄如果為NULL的欄位數量大于等3;
- “星級、評論數、評分”這三個欄位有一個為NULL;
- 重復的記錄,將重復的去掉;
MapReduce 程式1:洗掉滿足以上三個條件的記錄(只要滿足一個就需要被清理),并列印每類不符合要求的記錄的數量
1.3 分類下的統計與排序
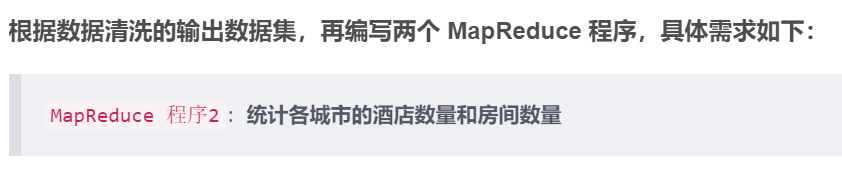
根據資料清洗的輸出資料集,再撰寫兩個 MapReduce 程式,具體需求如下:
MapReduce 程式2:統計各城市的酒店數量和房間數量
資料定義如下:
| 資料項 | 欄位名 | 備注 |
|---|---|---|
| 省份 | province | - |
| 城市 | city | - |
| 酒店數量 | hotel_num | - |
| 房間數量 | room_num |
資料樣式如下:
| province | city | hotel_num | room_num |
|---|---|---|---|
| 山東 | 濟南 | 1234 | 123456 |
| … | … | … | … |
MapReduce 程式3:以城市房間數量降序排列并輸出前10條統計結果
1.4 分類下的求均值與排序
MapReduce 程式4:請根據資料清洗的輸出資料集,撰寫Mapreduce程式統計各省直銷拒單率,以城市直銷拒單率升序排列并輸出前10條統計結果,要求保留6為小數
資料定義如下:
| 資料項 | 欄位名 | 備注 |
|---|---|---|
| 省份 | province | - |
| 直銷拒單率 | norate | - |
資料樣式如下:
| province | norate |
|---|---|
| 山東 | 0.123456 |
| … | … |
1.5 多維度下的綜合統計
MapReduce 程式5:以內蒙古、遼寧、四川、陜西、安徽為例,多維度分析說明幾個省酒店的綜合運營情況:分析維度:平均評分、酒店直銷拒單率
2 技術實作
2.1 環境搭建
本專案基于 Java 撰寫,在這里首先新建一個 Maven 工程,匯入相關依賴如下,
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
2.2 實作:資料清洗
在這里回顧一下上文的具體需求:
【開始撰寫代碼】
1、首先寫一個工具類,用來封裝判斷上面三種條件的靜態方法,并進行合理的單元測驗,通過后再寫接下來的邏輯代碼,
public class ClearUtil {
/**
* 1)每條記錄如果為NULL的欄位數量大于等3;
* @param line
* @return
*/
public static boolean ifNullFieldGreaterThree(String line) {
String[] split = line.split(",");
int count = 0; //記錄每行NULL欄位的數量
for (String field : split) {
if (field.equals("NULL")) {
count++;
}
if (count >= 3) {
return true;
}
}
return false;
}
/**
* 2)“星級、評論數、評分”這三個欄位有一個為NULL;
* @param line
* @return
*/
public static boolean ifOneOfThreeIsNull(String line) {
String[] split = line.split(",");
if (split[6].equals("NULL")
|| split[10].equals("NULL")
|| split[11].equals("NULL")) {
return true;
}
return false;
}
/**
* 3)重復的記錄,將重復的去掉;
* @param line
*/
public static boolean ifRepeat(String line, HashSet hashSet, HashSet repeatSet) {
if (!hashSet.contains(line)) {
hashSet.add(line);
return false;
}
repeatSet.add(line);
return true;
}
public static boolean ifHotelNumIsNull(String line) {
String[] split = line.split(",");
return split[8].equals("NULL");
}
}
2、在 Mapper 類(用 Mapper 類這個詞老是讓我聯想到 SSM 架構中的 Mapper 層,一直感覺很別扭,但實作的介面確實就是 Mapper<…>)的 map 方法中我們處理前兩個條件(“每條記錄如果為NULL的欄位數量大于等3”、““星級、評論數、評分”這三個欄位有一個為NULL”),我的思路是進入 map 方法時用一個布爾型別的遍歷來記錄狀態,開始默認為 true,若是在 map 方法的接下來的處理程序中,并未遇到上述兩個條件之一,那么便仍是 true,否則,便被賦值為 false,這樣,通過這個布爾型別的狀態變數,便可以操作此資料是否可以繼續通行到 Reducer 中,而程序中的這兩種情況的次數記錄,可用 hadoop-client 提供的 Counter 類來解決,用 increment 方法進行每次的自增,最終配合 log4j 列印出來每種情況的次數,下面第三個條件的次數統計也同理,
(注:這個 Mapper 類中,我在撰寫時也額外補充了一段代碼 if(ClearUtil.ifHotelNumIsNull(line)){...},主要是后續的一個需求中,要求統計酒店的房間數量,而房間數量這個欄位在給定的資料表中,本身就存在大量為 NULL 的情況,但在課上,我看老師是在后續的那步操作中用 try catch 來拋出例外,真是讓我哭笑不得,這難道不是資料清洗階段就要做好的嗎,而且你那么多例外,多少也是很消耗資源的寫法吧,十分無奈)
/**
* 資料清洗
*/
public class ClearMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
IntWritable iw = new IntWritable(1);
HashSet<String> hashSet = null;
HashSet<String> repeatSet = null;
int noOne = 0; //第1種不滿足的情況
int noTwo = 0; //第2種不滿足的情況
int noThree = 0; //第3種不滿足的情況
@Override
protected void setup(Context context) throws IOException, InterruptedException {
hashSet = new HashSet();
repeatSet = new HashSet();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
Counter counter1 = context.getCounter("NUMS", "counter1");
Counter counter2 = context.getCounter("NUMS", "counter2");
boolean go = true; //是否進入 reducer 處理
String line = value.toString();
if (ClearUtil.ifNullFieldGreaterThree(line)) {
counter1.increment(1);
go = false;
}
if (ClearUtil.ifOneOfThreeIsNull(line)) {
counter2.increment(1);
go = false;
}
//【額外補充】
if (ClearUtil.ifHotelNumIsNull(line)) {
go = false;
}
//可能包含重復,也可能不包含重復:使用 reduce 去重
if (go) {
context.write(value, iw);
}
}
}
3、第三個條件(重復的記錄,將重復的去掉)的判斷我讓經歷了前兩個條件的判斷后狀態變數仍為 true 的資料進入到 Reducer 中進行,因為這第三個條件涉及統計次數,因此我們讓這一整條記錄作為鍵,而讓 1 來作為值,這樣便可以在 Reducer 中將同一鍵的記錄進行歸并,進而我們可以進行值的加和,從而判斷出是否有重復的記錄,值大于 2 時,鍵對應的記錄就是出現了多次,是重復出現的情況,(注:其實這樣也不一定能保證第三個條件的 Counter 次數統計就是正確的,因為可能其余資料也有重復的情況,只是在 Mapper 中就因為觸犯了前兩個條件,導致布爾狀態變數為 false,進而根本就沒有進入到 Reducer 中,因此,但是如果要改進的話,我能想到的方法大多都是需要犧牲很多空間的和降低效率的,因此十分得不償失,暫時為想到好的改進方法,如果有知道的大佬也請在評論區一起交流),
public class ClearReducer extends Reducer<Text, IntWritable, NullWritable, Text> {
@Override
protected void reduce(Text key, Iterable<IntWritable> iter, Context context) throws IOException, InterruptedException {
//記錄重復數量
Counter counter3 = context.getCounter("NUMS", "counter3");
int sum = 0;
for (IntWritable iw : iter) {
sum += iw.get();
}
//sum > 1 說明有重復的 value,使用計數器記錄多出的數量
if (sum > 1) {
counter3.increment(sum - 1);
}
context.write(NullWritable.get(), key);
}
}
4、主啟動類
MapReduce 的啟動類十分模板化,此處不再細講,
public class MainClear {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 獲取配置資訊以及獲取job物件
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 關聯本Driver程式的jar
job.setJarByClass(MainClear.class);
// 3 關聯Mapper和Reducer的jar
job.setMapperClass(ClearMapper.class);
job.setReducerClass(ClearReducer.class);
// 4 設定Mapper輸出的kv型別
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 設定最終輸出kv型別
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(Text.class);
// 6 設定輸入和輸出路徑
FileInputFormat.setInputPaths(job, new Path("C:\\Users\\DELL\\Desktop\\hadoop課設\\課設\\hadoop-hotel\\hotel.csv"));
FileOutputFormat.setOutputPath(job, new Path("C:\\Users\\DELL\\Desktop\\hadoop課設\\課設\\hadoop-hotel\\src\\main\\java\\com\\zlc\\mapreduce\\clear\\out"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
5、測驗效果截圖
(1)三個條件統計次數的各自情況(我這個是正確的結果,反而在課上時,老師給出的答案讓我哭笑不得,分別是 2842,7148,2,而我這里的 9990 本身就等于 2842 + 7148,所以問題出在哪也就可見一斑了,那位老師她錯把第一種條件的計數統計條件,”且“上了第二種條件,導致第一種情況的統計數量直接少了一大半)
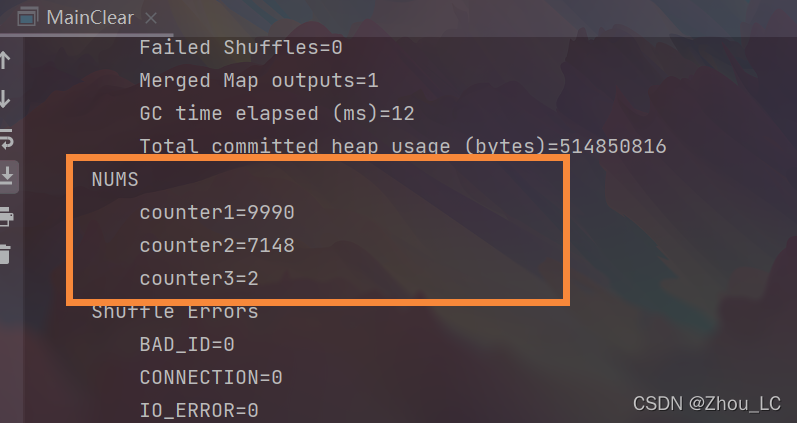
(2)清洗后的資料,有 2983 行
2.3 實作:分類下的統計與排序
在這里回顧一下上文的具體需求:
【開始撰寫代碼】
1、針對此需求,我們自然可以想到以 省,市 作為 Key,以 酒店數量,房間數量 作為 Value,因為這樣就可以在 Mapper 結束之后根據 省,市 來進行分組,從而 在 Reducer 中接收相同分組的資料,進而對之前的 VALUEOUT- 酒店數量,房間數量,也就是現在的 VALUEIN 進行字串的轉換、拆分、加和,從而最終統計成功,大體思路也就是這樣,只要理解 Mapper 和 Reducer 類中的 map、reduce 方法的作業原理,那么實作這個功能并不困難,本文是屬于專案記錄型的文章,這些具體的作業原理不再贅述,讀者如有需求可去搜索細節型的文章或資料,
代碼直接都給出,這里沒什么需要過多解釋的,可能直接看代碼也比文字更能表達思路,
2、Mapper
public class CensusMapper extends Mapper<LongWritable, Text, Text, Text> {
Text newKey = null;
Text newValue = null;
@Override
protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException {
newKey = new Text();
newValue = new Text();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//Key:省,市
//Value:酒店數量,房間數量
String[] split = value.toString().split(",");
String province = split[3];
String city = split[4];
int hotelNum = 1; //一行記錄就是一個酒店
String roomNum = split[8];
newKey.set(province + "," + city);
newValue.set(hotelNum + "," + roomNum);
context.write(newKey, newValue);
}
}
3、Reducer
public class CensusReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
int hotelNum = 0;
int roomNum = 0;
for (Text value : values) {
String[] split = value.toString().split(",");
try {
hotelNum += Integer.parseInt(split[0]);
roomNum += Integer.parseInt(split[1]);
} catch (NumberFormatException e) {}
}
context.write(key, new Text(hotelNum + "," + roomNum));
}
}
4、主啟動類
與上面資料清理步驟的啟動類幾乎相同,只需改一下類名、Key-Value 的型別,路徑指向即可(這里的輸入路徑的指向是第一步資料清洗的結果檔案,即對應的 p art-r-00000 檔案)
5、測驗效果截圖
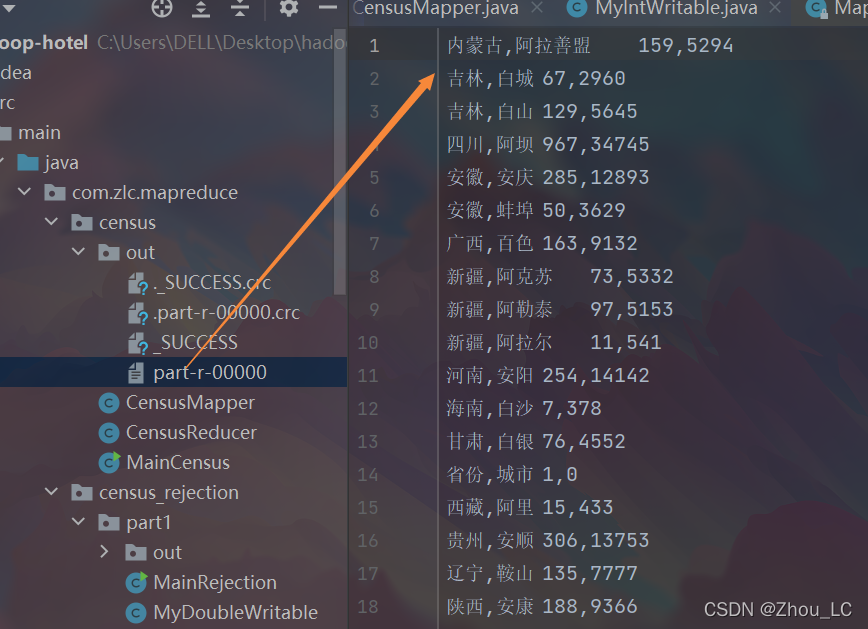
在這里回顧一下上文的具體需求:

【開始撰寫代碼】
1、針對此需求,我們仍然可以以 省,市 作為 Key,以 房間數量 作為 Value,這樣就可以在 Mapper 結束之后根據 省,市 來進行分組,從而 在 Reducer 中接收相同分組的資料,進而對 VALUEIN 房間數量進行字串的轉換、拆分、加和,從而最終統計成功,當然,這只是能滿足統計數量的需求,但是,本需求需要的是還要對這個房間數量進行降序,在 Hadoop依賴中的 IntWritable,也就是表示正數的這個變數,有一個public int compareTo(IntWritable o) 方法,我們可以通過重寫這個方法,來使得我們的結果有序,而還有一個條件也要滿足,也即是我們重寫后的 MyIntWritable 類,必須作為 Reducer 輸出的鍵的型別,這樣才可以進行排序顯示,
2、MyIntWritable
public class MyIntWritable extends IntWritable {
public MyIntWritable() {
super();
}
public MyIntWritable(int roomNum) {
super(roomNum);
}
@Override
public int compareTo(IntWritable o) {
int thisValue = super.get();
int thatValue = o.get();
return thatValue - thisValue; //倒序
}
}
2、Mapper
public class OrderMapper extends Mapper<LongWritable, Text, MyIntWritable, Text> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, MyIntWritable, Text>.Context context) throws IOException, InterruptedException {
//Key:省,市
//Value:房間數量
String[] split = value.toString().split("\t");
String[] splitRight = split[1].split(",");
int roomNum = Integer.parseInt(splitRight[1]);
context.write(new MyIntWritable(roomNum), new Text(split[0]));
}
}
3、Reducer
public class OrderReducer extends Reducer<MyIntWritable, Text, MyIntWritable, Text> {
int count = 1;
@Override
protected void reduce(MyIntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
if (count <= 10) {
for (Text value : values) {
context.write(key, value);
}
count++;
}
}
}
4、主啟動類
(結構同上,略)
5、測驗效果截圖
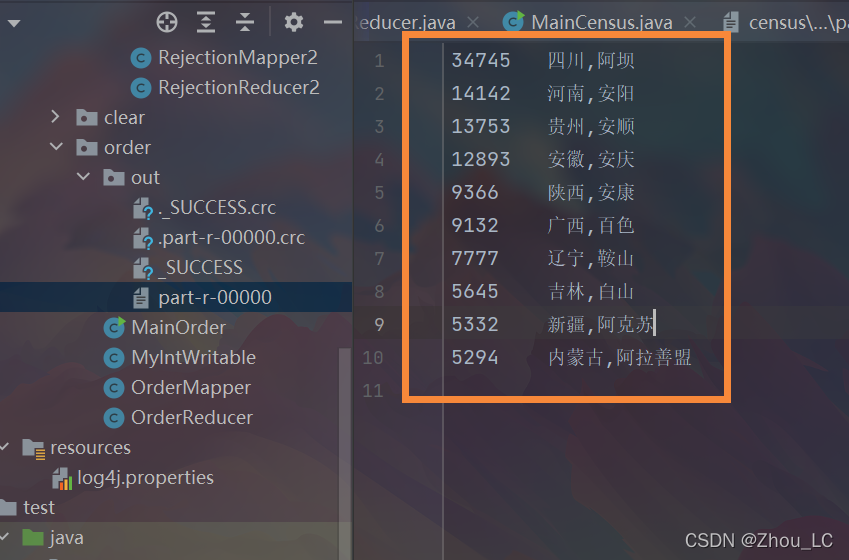
2.4 實作:分類下的求均值與排序
在這里回顧一下上文的具體需求:

【開始撰寫代碼】
1、此 2.4 的實作與 2.3 的實作幾乎相同,只是 2.3 中的統計在這里變成了求均值,結果變為了限定小數位數浮點型小數,不再是整數,而解決均值,也就是在 Reducer 中預先統計當前來到 map 分組的資料個數,然后再用統計的結果除以個數即可,解決限定位數的小數問題,我這里的思路十分簡單粗暴,也就是再寫一個 Mapper、Reducer,對之前的 Value 再進行單獨的小數處理,并且程序中除了一開始的 id 為 LongWritable 型別,當然,由于要升序排序,因此這里繼承了 DoubleWritable 類,重寫了 compareTo 方法,因此前一階段的 part1 統計并排序中的 Reducer 的輸出鍵的型別為我自定義的 MyDoubleWritable ,其他都為 Text 型別,包括在后續為了處理小數位數而出現的階段二,也就是 part2,我這種分兩步處理的方式十分簡單粗暴,但自然效率可能會低一些,
MyDoubleWritable
public class MyDoubleWritable extends DoubleWritable {
public MyDoubleWritable() {
super();
}
public MyDoubleWritable(double roomNum) {
super(roomNum);
}
@Override
public int compareTo(DoubleWritable o) {
double thisValue = super.get();
double thatValue = o.get();
if (thatValue > thisValue) {
return -1;
}
return 1;
}
}
2、Mapper1
public class RejectionMapper extends Mapper<LongWritable, Text, Text, Text> {
Text newKey = null;
Text newValue = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
newKey = new Text();
newValue = new Text();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (key.get() == 0) return;
String line = value.toString();
String[] split = line.split(",");
newKey.set(split[3]); //省份作為鍵
newValue.set(split[24]);//直銷拒單率作為值
context.write(newKey, newValue);
}
}
3、Reducer1
public class RejectionReducer extends Reducer<Text, Text, MyDoubleWritable, Text> {
MyDoubleWritable md = null;
Text newValue = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
md = new MyDoubleWritable();
newValue = new Text();
}
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
double sum = 0;
double num = 0;
for (Text value : values) {
String rate = value.toString();
try {
sum += Double.parseDouble(rate.substring(0, rate.length() - 1));
} catch (NumberFormatException e) {}
num++;
}
double result = sum / (num * 100);
//result = Double.parseDouble(new DecimalFormat("0.000000").format(result));
md.set(result); //平均直銷拒單率作為鍵
newValue.set(key); //省份作為值
context.write(md, newValue);
}
}
4、主啟動類
(結果同上,略)
5、此步的效果截圖
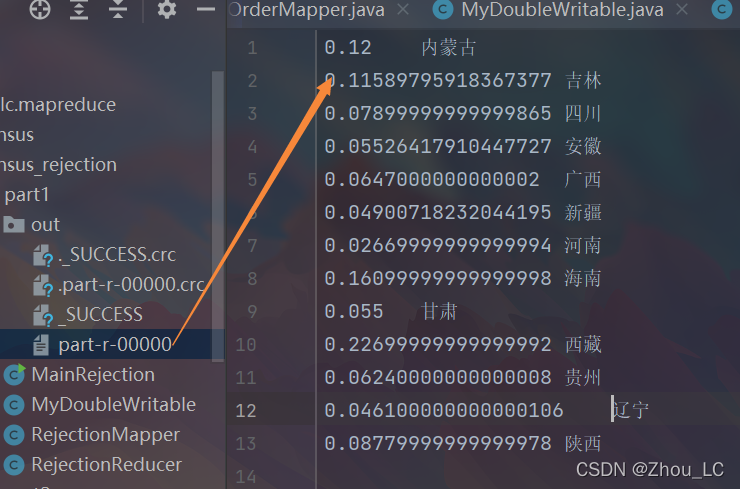
6、接下來我們再寫一對 Mapper、Recuder 來處理這個結果
7、Mapper2
public class RejectionMapper2 extends Mapper<LongWritable, Text, Text, Text> {
Text newKey = null;
Text newValue = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
newKey = new Text();
newValue = new Text();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] split = line.split("\t");
double result = Double.parseDouble(split[0]);
newValue.set(new DecimalFormat("0.000000").format(result));
newKey.set(split[1]); //省份作為建,拒銷率不能作為鍵,因為可能有重復的情況
context.write(newKey, newValue);
}
}
8、Recuder2
public class RejectionReducer2 extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (int i = 0; i < 10; i++) {
for (Text value : values) {
context.write(key, value);
}
}
}
}
9、主啟動類
(結果同上,略)
10、此步的效果截圖
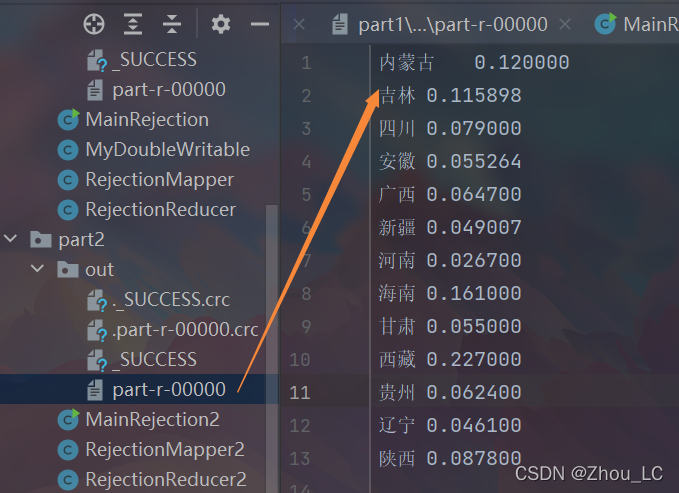
2.5 實作:多維度下的綜合統計
在這里回顧一下上文的具體需求:

【開始撰寫代碼】
1、針對此需求,我們仍然可以以 省 作為 Key,以 平均評分,酒店直銷拒單率 作為 Value,這樣就可以在 Mapper 結束之后根據 省 來進行分組,從而在 Reducer 中接收相同省份分組的資料,進而對 VALUEIN 平均評分,酒店直銷拒單率 進行字串的轉換、拆分、加和,求均值,從而最終統計成功,
Mapper
public class CensusManyMapper extends Mapper<LongWritable, Text, Text, Text> {
Text newKey = null;
Text newValue = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
newKey = new Text();
newValue = new Text();
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
if (key.get() == 0) return;
String line = value.toString();
String[] split = line.split(",");
String province = split[3];
String score = split[10];
String hotelRejectRate = split[22];
if (!(province.equals("內蒙古")
|| province.equals("遼寧")
|| province.equals("四川")
|| province.equals("陜西")
|| province.equals("安徽"))) {
return;
}
newKey.set(province); //省份作為鍵
newValue.set(score + "," + hotelRejectRate);//評分、酒店直銷拒單率作為值
context.write(newKey, newValue);
}
}
2、Reducer
public class CensusManyReducer extends Reducer<Text, Text, Text, Text> {
Text newValue = null;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
newValue = new Text();
}
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
double scoreSum = 0;
double hotelRejectRateSum = 0;
double num = 0;
for (Text value : values) {
String line = value.toString();
String[] split = line.split(",");
scoreSum += Double.parseDouble(split[0]);
hotelRejectRateSum += Double.parseDouble(split[1].substring(0, split[1].length() - 1));
num++;
}
double scoreResult = scoreSum / num;
double hotelRejectRateResult = hotelRejectRateSum / (num * 100);
newValue.set(scoreResult + "," + hotelRejectRateResult);
context.write(key, newValue);
}
}
3、主啟動類
(結果同上,略)
4、效果截圖
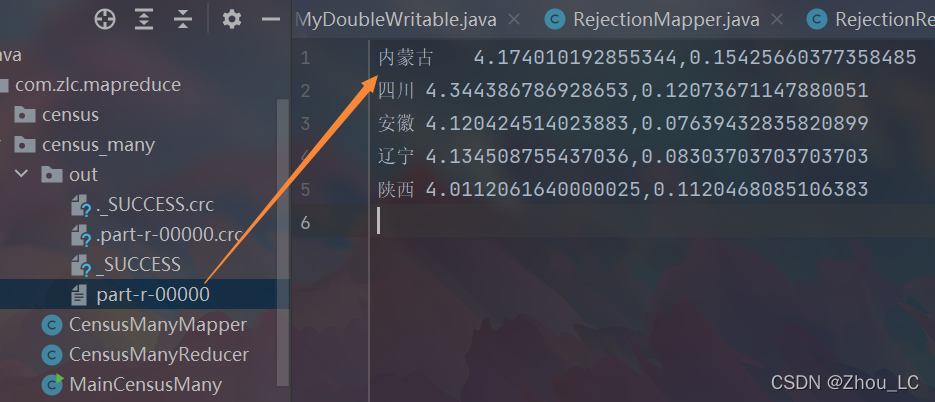
3 完整代碼與資料檔案
下載鏈接
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/379504.html
標籤:其他