本案例源自ML-Agents官方的示例,Github地址:https://github.com/Unity-Technologies/ml-agents,本文是詳細的配套講解,
本文基于我前面發的兩篇文章,需要對ML-Agents有一定的了解,詳情請見:Unity強化學習之ML-Agents的使用、ML-Agents命令及配置大全,
我前面的相關文章有:
ML-Agents案例之Crawler
ML-Agents案例之推箱子游戲
ML-Agents案例之跳墻游戲
ML-Agents案例之食物收集者
ML-Agents案例之雙人足球
Unity人工智能之不斷自我進化的五人足球賽
ML-Agents案例之地牢逃脫
ML-Agents案例之金字塔
ML-Agents案例之蠕蟲
ML-Agents案例之機器人學走路
ML-Agents案例之看圖配對
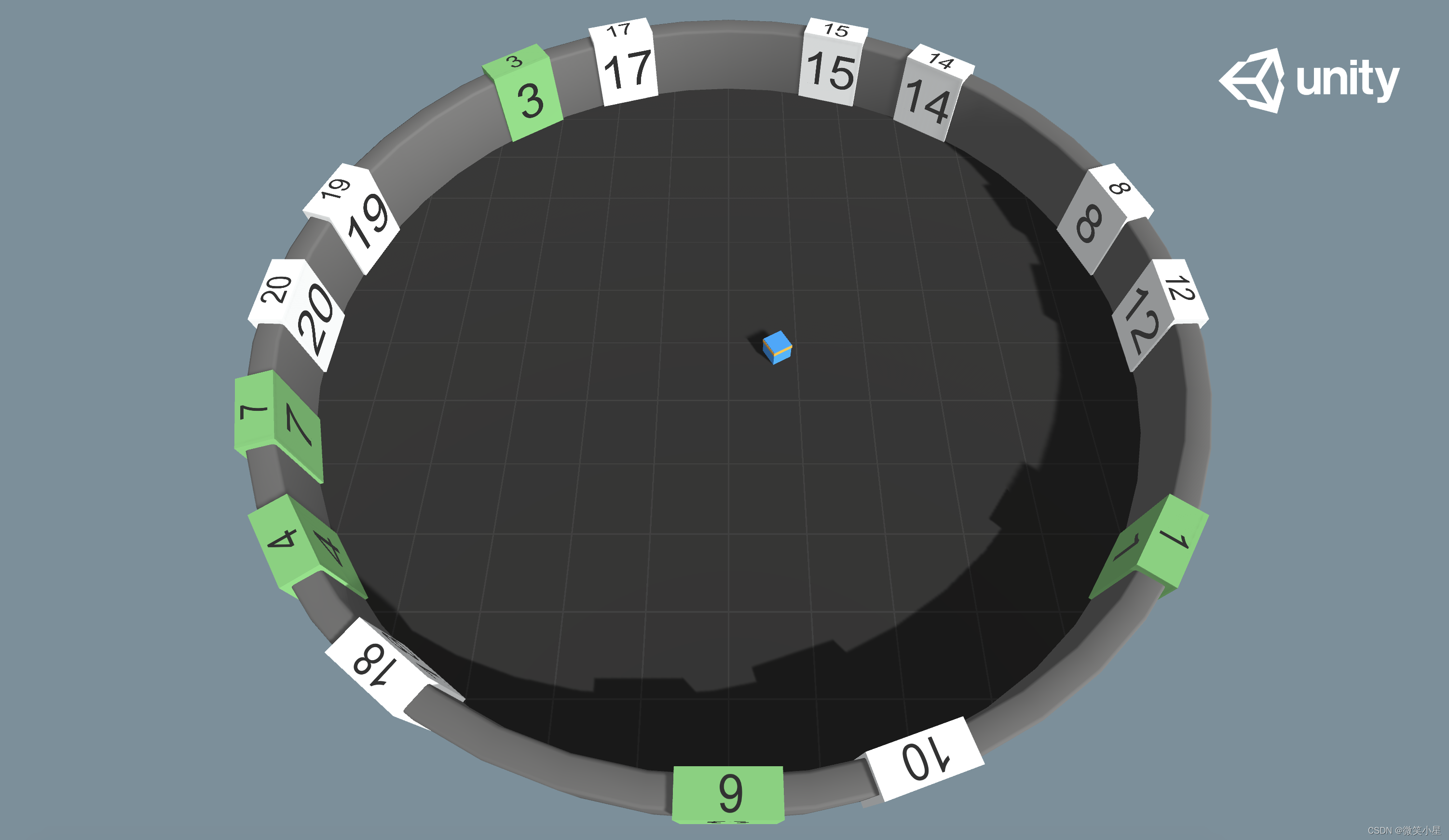
環境說明
如圖所示,智能體在一個圓形的房間中,墻壁上會隨機出現帶有數字的方塊,智能體需要按照數字從小到大與方塊進行碰撞,碰撞過的方塊會變成綠色,分數+1,一旦碰撞順序不對,游戲結束,分數-1,
這個案例的挑戰是,我們不會告訴智能體怎么排序是對的,智能體需要在環境中試錯,從而自己學習到這種從小到大排序,碰撞對應方塊的行為模式,同時墻壁上出現的數字方塊的個數是不定的,也就是說每個episode我們都需要接收不同個數的輸入,這應該怎么處理呢?
狀態輸入:這里用到了一個新的傳感器Buffer Sensor,
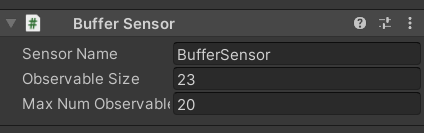
這個傳感器的作用是可以接收個數變化的狀態輸入,我們需要每次傳入一個向量,這個向量我們可以用陣列listObservation表示,通過 m_BufferSensor.AppendObservation(listObservation)傳入到BufferSensor中,而BufferSensor可以接收無數個這樣的向量輸入,但是每個向量的維度必須相同,也就是說即使我們輸入的向量個數每次都不同,我們還是能訓練網路還是產生我們所期望的輸出,具體是怎么實作的專案代碼中沒有,集成在了ML-Agents包中,根據我的經驗,應該用了Self-attention這種網路的結構,這樣就能接收不同個數向量的輸入了,
除了傳給BufferSensor的輸入之外,還傳入了四維的向量,分別是智能體位置到場地中心的向量在x軸和z軸上的分量,智能體前進方向在x軸和z軸的分量,
動作輸出:輸出三個離散值,每個離散值包含0-2三個數,第一個離散值決定了前進后退,第二個離散值決定了左移右移,第三個離散值決定了左轉右轉,
代碼講解
智能體下掛載的腳本除去萬年不變的Decesion Requester,Model Overrider,Behavior Parameters,以及剛剛說明的Buffer Sensor,就只剩下智能體的只有檔案SorterAgent.cs了:
頭檔案:
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Actuators;
using Unity.MLAgents.Sensors;
using Random = UnityEngine.Random;
定義變數:
// 默認數字方塊的最大數量,可在編輯器中滑動調節,調節范圍為1 - 20
[Range(1, 20)]
public int DefaultMaxNumTiles;
// 方塊數字的最大值
private const int k_HighestTileValue = 20;
// 生成方塊的數量
int m_NumberOfTilesToSpawn;
// 方塊的最大數量
int m_MaxNumberOfTiles;
// 剛體
Rigidbody m_AgentRb;
// BufferSensorComponent 是一個傳感器,允許觀察不同數量的輸入
BufferSensorComponent m_BufferSensor;
// 數字方塊的串列
public List<NumberTile> NumberTilesList = new List<NumberTile>();
// 出現在場景中的方塊串列
private List<NumberTile> CurrentlyVisibleTilesList = new List<NumberTile>();
// 已經被接觸過的方塊串列
private List<Transform> AlreadyTouchedList = new List<Transform>();
private List<int> m_UsedPositionsList = new List<int>();
// 初始位置
private Vector3 m_StartingPos;
// 整個場景
GameObject m_Area;
// 環境引數,可以從組態檔中獲取
EnvironmentParameters m_ResetParams;
// 下一個想要碰撞的數字方塊的索引
private int m_NextExpectedTileIndex;
初始化方法Initialize():
public override void Initialize()
{
// 獲取父物體
m_Area = transform.parent.gameObject;
// 獲取方塊的最大數量
m_MaxNumberOfTiles = k_HighestTileValue;
// 從組態檔中獲取環境引數
m_ResetParams = Academy.Instance.EnvironmentParameters;
// 獲取傳感器腳本
m_BufferSensor = GetComponent<BufferSensorComponent>();
// 獲取剛體
m_AgentRb = GetComponent<Rigidbody>();
// 起始位置
m_StartingPos = transform.position;
}
狀態輸入方法:
public override void CollectObservations(VectorSensor sensor)
{
// 獲取智能體到場地中心的x軸和z軸上的距離
sensor.AddObservation((transform.position.x - m_Area.transform.position.x) / 20f);
sensor.AddObservation((transform.position.z - m_Area.transform.position.z) / 20f);
// 獲取智能體前進方向的x軸和z軸的值
sensor.AddObservation(transform.forward.x);
sensor.AddObservation(transform.forward.z);
foreach (var item in CurrentlyVisibleTilesList)
{
// 定義一個陣列,存放一系列觀察值,陣列長度為數字方塊最大數量 + 3,默認初始化全部為0
float[] listObservation = new float[k_HighestTileValue + 3];
// 獲取方塊的數字,設定對應的one-hot向量
listObservation[item.NumberValue] = 1.0f;
// 獲取方塊的坐標(子物體坐標才是真實坐標的,transform本身的位置保持在場景中央,方便旋轉)
var tileTransform = item.transform.GetChild(1);
// 輸入數字方塊和智能體的x分量和z分量
listObservation[k_HighestTileValue] = (tileTransform.position.x - transform.position.x) / 20f;
listObservation[k_HighestTileValue + 1] = (tileTransform.position.z - transform.position.z) / 20f;
// 該方塊是否已經被碰撞過
listObservation[k_HighestTileValue + 2] = item.IsVisited ? 1.0f : 0.0f;
// 把陣列添加到Buffer Sensor中(不直接輸入到網路的原因是需要添加的陣列個數個數是變化的)
m_BufferSensor.AppendObservation(listObservation);
}
}
動作輸出方法OnActionReceived:
public override void OnActionReceived(ActionBuffers actionBuffers)
{
// 移動智能體
MoveAgent(actionBuffers.DiscreteActions);
// 時間懲罰,激勵智能體越快完成越好
AddReward(-1f / MaxStep);
}
public void MoveAgent(ActionSegment<int> act)
{
var dirToGo = Vector3.zero;
var rotateDir = Vector3.zero;
// 獲取神經網路三個離散輸出
var forwardAxis = act[0];
var rightAxis = act[1];
var rotateAxis = act[2];
// 第一個離散輸出決定了前進后退
switch (forwardAxis)
{
case 1:
dirToGo = transform.forward * 1f;
break;
case 2:
dirToGo = transform.forward * -1f;
break;
}
// 第二個離散輸出決定了左移右移
switch (rightAxis)
{
case 1:
dirToGo = transform.right * 1f;
break;
case 2:
dirToGo = transform.right * -1f;
break;
}
// 第三個離散輸出決定了左轉右轉
switch (rotateAxis)
{
case 1:
rotateDir = transform.up * -1f;
break;
case 2:
rotateDir = transform.up * 1f;
break;
}
// 執行動作
transform.Rotate(rotateDir, Time.deltaTime * 200f);
m_AgentRb.AddForce(dirToGo * 2, ForceMode.VelocityChange);
}
每一個episode(回合)開始時執行的方法OnEpisodeBegin:
public override void OnEpisodeBegin()
{
// 從組態檔中獲取方塊的數量,沒有的話設為DefaultMaxNumTiles
m_MaxNumberOfTiles = (int)m_ResetParams.GetWithDefault("num_tiles", DefaultMaxNumTiles);
// 隨機生成方塊的數量
m_NumberOfTilesToSpawn = Random.Range(1, m_MaxNumberOfTiles + 1);
// 選擇將要生成的對應的方塊并加入串列中
SelectTilesToShow();
// 生成方塊及調整位置
SetTilePositions();
transform.position = m_StartingPos;
m_AgentRb.velocity = Vector3.zero;
m_AgentRb.angularVelocity = Vector3.zero;
}
void SelectTilesToShow()
{
// 清除兩個串列
CurrentlyVisibleTilesList.Clear();
AlreadyTouchedList.Clear();
// 共生成nunLeft個方塊
int numLeft = m_NumberOfTilesToSpawn;
while (numLeft > 0)
{
// 在范圍內取亂數生成對應方塊
int rndInt = Random.Range(0, k_HighestTileValue);
var tmp = NumberTilesList[rndInt];
// 如果對應的方塊串列中沒有才進行添加
if (!CurrentlyVisibleTilesList.Contains(tmp))
{
CurrentlyVisibleTilesList.Add(tmp);
numLeft--;
}
}
// 給方塊串列串列按照數字升序進行排序
CurrentlyVisibleTilesList.Sort((x, y) => x.NumberValue.CompareTo(y.NumberValue));
m_NextExpectedTileIndex = 0;
}
void SetTilePositions()
{
// 清空串列
m_UsedPositionsList.Clear();
// 重置所有方塊的狀態,ResetTile方法可以在數字方塊的腳本中看到
foreach (var item in NumberTilesList)
{
item.ResetTile();
item.gameObject.SetActive(false);
}
foreach (var item in CurrentlyVisibleTilesList)
{
bool posChosen = false;
// rndPosIndx決定了我們方塊的旋轉角度(即在圓形場地的哪里)
int rndPosIndx = 0;
while (!posChosen)
{
rndPosIndx = Random.Range(0, k_HighestTileValue);
// 這個旋轉角度是否被選了,沒被選就加入串列中
if (!m_UsedPositionsList.Contains(rndPosIndx))
{
m_UsedPositionsList.Add(rndPosIndx);
posChosen = true;
}
}
// 執行方塊角度的旋轉并激活物體
item.transform.localRotation = Quaternion.Euler(0, rndPosIndx * (360f / k_HighestTileValue), 0);
item.gameObject.SetActive(true);
}
}
當與別的物體開始發生碰撞執行方法OnCollisionEnter:
private void OnCollisionEnter(Collision col)
{
// 只檢測和數字方塊的碰撞
if (!col.gameObject.CompareTag("tile"))
{
return;
}
// 如果方塊已經碰撞過,也排除在碰撞物件之外
if (AlreadyTouchedList.Contains(col.transform))
{
return;
}
// 如果碰撞的順序錯誤,獎勵-1,結束游戲
if (col.transform.parent != CurrentlyVisibleTilesList[m_NextExpectedTileIndex].transform)
{
AddReward(-1);
EndEpisode();
}
// 碰撞到正確的方塊的情況
else
{
// 獎勵+1
AddReward(1);
// 改變方塊的材質
var tile = col.gameObject.GetComponentInParent<NumberTile>();
tile.VisitTile();
// 索引+1
m_NextExpectedTileIndex++;
// 把方塊加入到已接觸串列中
AlreadyTouchedList.Add(col.transform);
// 如果完成了所有的任務,游戲結束
if (m_NextExpectedTileIndex == m_NumberOfTilesToSpawn)
{
EndEpisode();
}
}
}
當智能體沒有模型,人想手動錄制示例時可以采用Heuristic方法:
public override void Heuristic(in ActionBuffers actionsOut)
{
var discreteActionsOut = actionsOut.DiscreteActions;
//forward
if (Input.GetKey(KeyCode.W))
{
discreteActionsOut[0] = 1;
}
if (Input.GetKey(KeyCode.S))
{
discreteActionsOut[0] = 2;
}
//rotate
if (Input.GetKey(KeyCode.A))
{
discreteActionsOut[2] = 1;
}
if (Input.GetKey(KeyCode.D))
{
discreteActionsOut[2] = 2;
}
//right
if (Input.GetKey(KeyCode.E))
{
discreteActionsOut[1] = 1;
}
if (Input.GetKey(KeyCode.Q))
{
discreteActionsOut[1] = 2;
}
}
掛載在數字方塊上的腳本NumberTile.cs:
using UnityEngine;
public class NumberTile : MonoBehaviour
{
// 方塊上的數字
public int NumberValue;
// 默認材質和成功時轉換用的材質
public Material DefaultMaterial;
public Material SuccessMaterial;
// 是否已經碰撞過
private bool m_Visited;
// 渲染,用于轉換材質
private MeshRenderer m_Renderer;
public bool IsVisited
{
get { return m_Visited; }
}
// 用于轉換材質的方法
public void VisitTile()
{
m_Renderer.sharedMaterial = SuccessMaterial;
m_Visited = true;
}
// 重置方塊的方法,材質還原,m_Visited狀態還原
public void ResetTile()
{
if (m_Renderer is null)
{
m_Renderer = GetComponentInChildren<MeshRenderer>();
}
m_Renderer.sharedMaterial = DefaultMaterial;
m_Visited = false;
}
}
組態檔
behaviors:
Sorter:
trainer_type: ppo
hyperparameters:
batch_size: 512
buffer_size: 40960
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: constant
network_settings:
normalize: False
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
max_steps: 5000000
time_horizon: 256
summary_freq: 10000
environment_parameters:
num_tiles:
curriculum:
- name: Lesson0 # The '-' is important as this is a list
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.3
value: 2.0
- name: Lesson1
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.4
value: 4.0
- name: Lesson2
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.45
value: 6.0
- name: Lesson3
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.5
value: 8.0
- name: Lesson4
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.55
value: 10.0
- name: Lesson5
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.6
value: 12.0
- name: Lesson6
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.65
value: 14.0
- name: Lesson7
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.7
value: 16.0
- name: Lesson8
completion_criteria:
measure: progress
behavior: Sorter
signal_smoothing: true
min_lesson_length: 100
threshold: 0.75
value: 18.0
- name: Lesson9
value: 20.0
可以看到組態檔采用了最為常用的PPO演算法,而且是沒有帶其他“配件”例如LSTM,內在獎勵機制等模塊的普通PPO,唯一的不同是這里加入了Curriculum Learning(課程學習),也就是說,這種能夠數十個方塊的排序的智能體是很難一下子訓練出來的,因此我們需要從易到難給它安排任務,從一開始能排序兩個方塊逐漸兩個兩個遞增,最后達到20個,關于Curriculum Learning有關引數的詳細解釋,請查看我前面的文章ML-Agents案例之跳墻游戲,
效果演示

后記
本案例相比于之前的案例的創新點在于引入了Buffer Sensor,這個傳感器是用于接收不同個數向量的輸入的,而并非像以往的傳感器一樣掛在智能體下就能用,這是為了處理類似該案例情況下接收資訊數量隨環境改變的情況的,這種情況有很多,例如智能體在面對敵人時,敵人的個數是不確定的,敵人發射子彈的數量也是不確定的,這時候,我們就需要用到Buffer Sensor,用來接受不同個數的輸入,當然這樣的訓練往往也需要更多的樣本,各種數量的輸入都需要覆寫到,否則就會過擬合,為了達到這個目的,這里用到了之前的Curriculum Learning(課程學習)來使訓練樣本多樣化,同時使得訓練從易到難,使得智能體的策略具有魯棒性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/382125.html
標籤:其他