【AI達人創造營】基于PaddleDetection的紅細胞形狀例外檢測
此專案是基于PaddleDetection做的紅細胞形狀例外檢測,屬于醫學中目標檢測類的專案,
一、專案背景
- 此專案可以幫醫生減輕負擔,提高檢測的準確性和速度,一般每張紅細胞形狀例外檢測圖都有好多紅細胞,并且這個樣本量還是成千上萬的,這時候醫生容易眼花繚亂,甚至可能漏掉一些重疊的紅細胞,
- 并且可以讓醫生避免重復的不必要的作業,
- 將醫學與AI科技結合,讓科技為醫學賦能,
# 1.將PaddleDetection套件進行解壓,路徑看具體情況,
!unzip -oq /home/aistudio/data/data102742/PaddleDetection-2.1.0.zip
二.專案使用的套件
此專案使用的是PaddleDetection套件,下載地址為:
github:https://github.com/PaddlePaddle/PaddleDetection(因為國外網站,訪問比較慢,不太推薦);
飛槳AI Studio平臺上:https://aistudio.baidu.com/aistudio/datasetdetail/102742(考慮到大部分用戶訪問github比較慢,故我從github上搬運過來),
# 2.將PaddleDetection套件進行改名
!mv PaddleDetection-2.1.0 PaddleDetection
三、資料集簡介
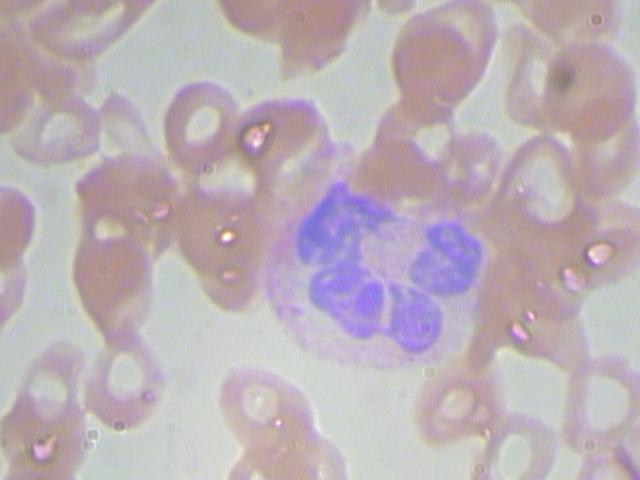
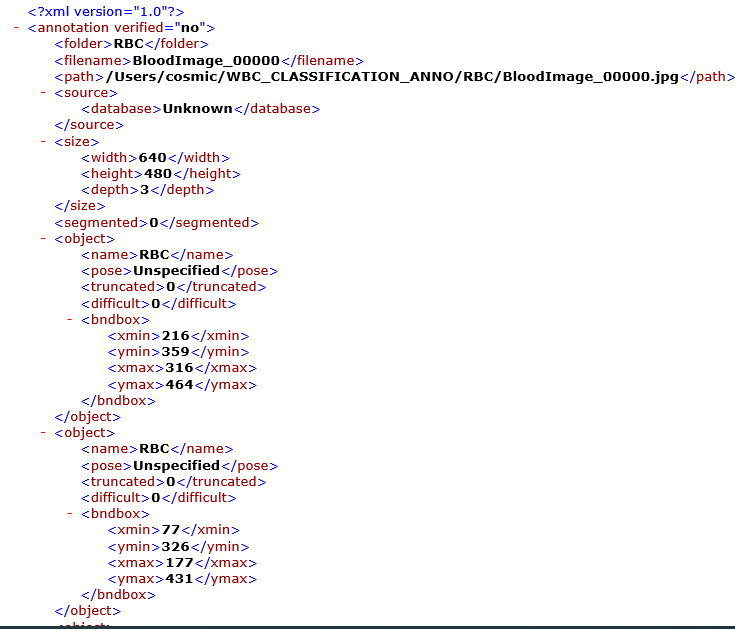
此專案使用了AI Studio平臺上RBC資料集,一共有366條資料,資料是xml格式的圖片標注檔案,

# 1.解壓資料集
!unzip -o data/data85839/RBC.zip -d PaddleDetection/dataset/
# 2.資料集檔案夾改名
!mv PaddleDetection/dataset/RBC PaddleDetection/dataset/test_det
# 3.將資料集劃分為訓練集和驗證集
import os
import random
# 類別數量
file_saved = [] # 保存資料
random.seed(2021)
# voc資料路徑問題
# 根目錄資訊,子目錄資訊,files_img--該檔案夾下的檔案名稱
for _, _, files_img in os.walk('PaddleDetection/dataset/test_det/JPEGImages'):
random.shuffle(files_img)
for _, _, files_xml in os.walk('PaddleDetection/dataset/test_det/Annotations'):
# indexs = 0
# 1.jpg
# 1.xml
for i in range(len(files_img)): # 遍歷圖片檔案--一張一張的
for j in range(len(files_xml)):
# 匹配,與圖片前綴名稱一致的xml檔案
# 前綴是否一致
if files_img[i][:-4] == files_xml[j][:-4]:
# 圖片的相對路徑 + 空格 + 標注檔案的相對路徑 + '\n'
# jpeg, img -- join -> jpeg/img
# JPEGImages/files_img[i]
file_maked = os.path.join('JPEGImages', files_img[i]) + ' ' + os.path.join('Annotations', files_xml[j]) + '\n'
file_saved.append(file_maked) # 每一個類別放在對應的快取空間中
break
# example: 圖片的相對路徑 + 空格 + 標注檔案的相對路徑 + '\n'
# 訓練集的劃分
# 訓練集占80%的資料
# 驗證集/評估資料集:1-80% = 20%
Train_percent = 0.8
# train.txt保存
with open('PaddleDetection/dataset/test_det/train.txt', 'w') as f:
# int(Train_percent * len(file_saved))
# final_index = int(len(file_saved)*Train_percent) - 1
f.writelines(file_saved[:int(len(file_saved)*Train_percent)]) # 寫入多行資料
print('train.txt Has Writed {0} records!'.format(len(file_saved[:int(len(file_saved)*Train_percent)])))
# eval.txt保存
with open('PaddleDetection/dataset/test_det/eval.txt', 'w') as f:
# final_index + 1 == int(len(file_saved)*Train_percent)
f.writelines(file_saved[int(len(file_saved)*Train_percent):])
print('eval.txt Has Writed {0} records!'.format(len(file_saved[int(len(file_saved)*Train_percent):])))
輸出結果為:
train.txt Has Writed 274 records!
eval.txt Has Writed 69 records!
訓練集樣本量: 274,驗證集樣本量: 69
四、模型選擇、開發、訓練和驗證
此專案使用的是ppyolo中的ppyolo_r18vd_coco.yml模型,
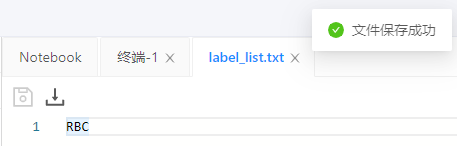
1.新建label_list.txt檔案
在dataset/test_det下新建label_list.txt,然后在里面寫上你的標注型別(如本專案中的RBC,意思為只標注了紅細胞),
# 2.下載依賴庫
%cd /home/aistudio/PaddleDetection/
!pip install -r requirements.txt
%cd + 路徑:進入某路徑下,
2.調參
a.修改voc.yml檔案中的配置
將num_classes改為你的標注型別數,(如本專案只標注了紅細胞這一種型別,故num_clases為1,若不為ppyo或ssd,如果為fast rcnn檢測模型的話,就需要增加一個背景類別,)將TrainDatest下的dataset_dir改為你的資料集放置路徑(如本專案中的dataset/test_det,此處路徑為相對路徑,下同),anno_path改為你標注檔案的訓練集檔案(如本專案中的train.txt),
將EvalDataset下的dataset_dir改為你的資料集放置路徑如(本專案中的dataset/test_det),anno_path改為你標注檔案的驗證集檔案(如本專案中的eval.txt), 將TestDataset下的anno_path改為你標注檔案的測驗集檔案(如本專案中的dataset/test_det/label_list.txt),
b.修改ppyolo_r18vd_coco.yml檔案中的配置
因為本專案中用的資料集為voc格式,所以要將_BASE_下的第二行代碼用Ctrl+/注釋掉,將它用Ctrl+C和Ctrl+V復制粘貼修改為'../dataset/voc.yml',若資料集為coco格式,則不用改,snapshot_epoch為迭代輪次以及引數保存輪次、周期,這要根據你的具體樣數本來決定,可以先保持默認數值(本專案資料為366條,就先設為默認的10),
TrainReader下的batch_size為批次大小,這得看具體的樣本數,最好為2的n次方(本專案資料不太大,所以把默認的32調成了8), EvalReader下的batch_size先改為1,
將LearningRate學習率下的base_lr默認值修改為除以4后的值,
# 3.模型訓練
%cd /home/aistudio/PaddleDetection/
!python tools/train.py -c configs/ppyolo/ppyolo_r18vd_coco.yml\
--eval\
--use_vdl True
訓練最終模型精度為77.86%(0.780),
訓練程序中指令解釋:
- –c:指定組態檔,
- –eval:邊訓練邊驗證,
- –use_vdl True:使用VisualDL記錄資料,進而在VisualDL面板中顯示,
- !python + 某路徑下的python檔案:執行某python檔案,
訓練中出現的問題解決方法: - 斷次問題
如果你的模型訓練不小心斷在了某個輪次,沒訓練完,可以使用 -r output/模型的yml檔案/停在的輪次數(如果你一共要訓練200輪次,卻停在第20輪次,用的是ppyolo_r18vd_coco模型,你可以使用 -r output/ppyolo_r18vd_coco.yml/20繼續進行訓練), - 指令多的問題
只要后面有指令,可以在每個指令最末尾后加\(\前不能加空格,最后一個指令末尾不用加\),
五、模型預測
%cd /home/aistudio/PaddleDetection/
!python tools/infer.py -c configs/ppyolo/ppyolo_r18vd_coco.yml\
-o weights='output/ppyolo_r18vd_coco/model_final.pdparams'\
--infer_dir 'dataset/test_det/JPEGImages'\
--output_dir 'output'\
--draw_threshold 0.1\
--save_txt True
-o:設定或更改組態檔里的引數內容
–infer_dir:用于預測的圖片檔案夾路徑
–output_dir:預測后結果或匯出模型保存路徑
–draw_threshold:可視化時分數閾值
–save_txt:是否在檔案夾下將圖片的預測結果保存到文本檔案中
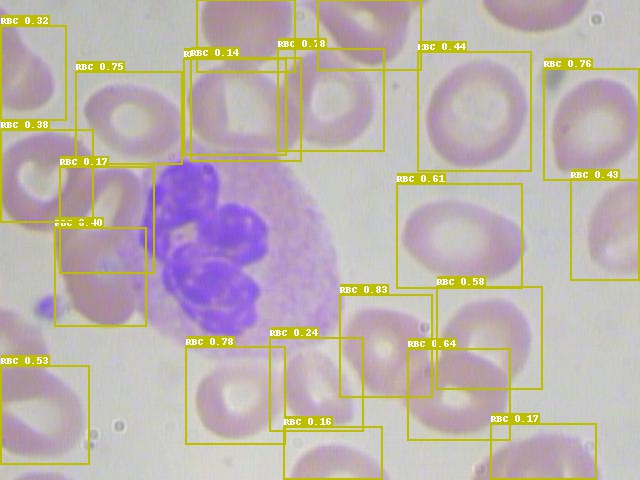
預測圖其中一張:
六、總結與升華
專案最重要的一步就是訓練,訓練離不開調參,你得根據具體情況來調整引數,在這程序中,把Train_Reader中的batch_size、snapshot_epoch調高,LearningRate下的base_lr調低,loss越來越大,評測模型也很重要,
希望這個專案可以幫助到大家,
個人簡介
大家好,我是初學者,第一次做AI Studio專案,請大家多多支持,歡迎fork、喜歡、分享,本人能力有限,經驗不足,若有不足,歡迎指正,謝謝大家!
我在AI Studio上獲得白銀等級,點亮3個徽章,來互關呀~
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/691883
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/382139.html
標籤:其他