手把手教你使用YOLOV5訓練自己的目標檢測模型
大家好,這里是肆十二(dejahu),好幾個月沒有更新了,這兩天看了一下關注量,突然多了1k多個朋友關注,想必都是大作業系列教程來的小伙伴,既然有這么多朋友關注這個大作業系列,并且也差不多到了畢設開題和大作業提交的時間了,那我直接就是一波更新,這期的內容相對于上期的果蔬分類和垃圾識別無論是在內容還是新意上我們都進行了船新的升級,我們這次要使用YOLOV5來訓練一個口罩檢測模型,比較契合當下的疫情,并且目標檢測涉及到的知識點也比較多,這次的內容除了可以作為大家的大作業之外,也可以作為一些小伙伴的畢業設計,廢話不多說,我們直接開始今天的內容,
B站講解視頻:手把手教你使用YOLOV5訓練自己的目標檢測模型_嗶哩嗶哩_bilibili
CSDN博客:手把手教你使用YOLOV5訓練自己的目標檢測模型-口罩檢測-視頻教程_dejahu的博客-CSDN博客
代碼地址:YOLOV5-mask-42: 基于YOLOV5的口罩檢測系統-提供教學視頻 (gitee.com)
處理好的資料集和訓練好的模型:YOLOV5口罩檢測資料集+代碼+模型2000張標注好的資料+教學視頻.zip-深度學習檔案類資源-CSDN文庫
更多相關的資料集:目標檢測資料集清單-附贈YOLOV5模型訓練和使用教程_dejahu的博客-CSDN博客
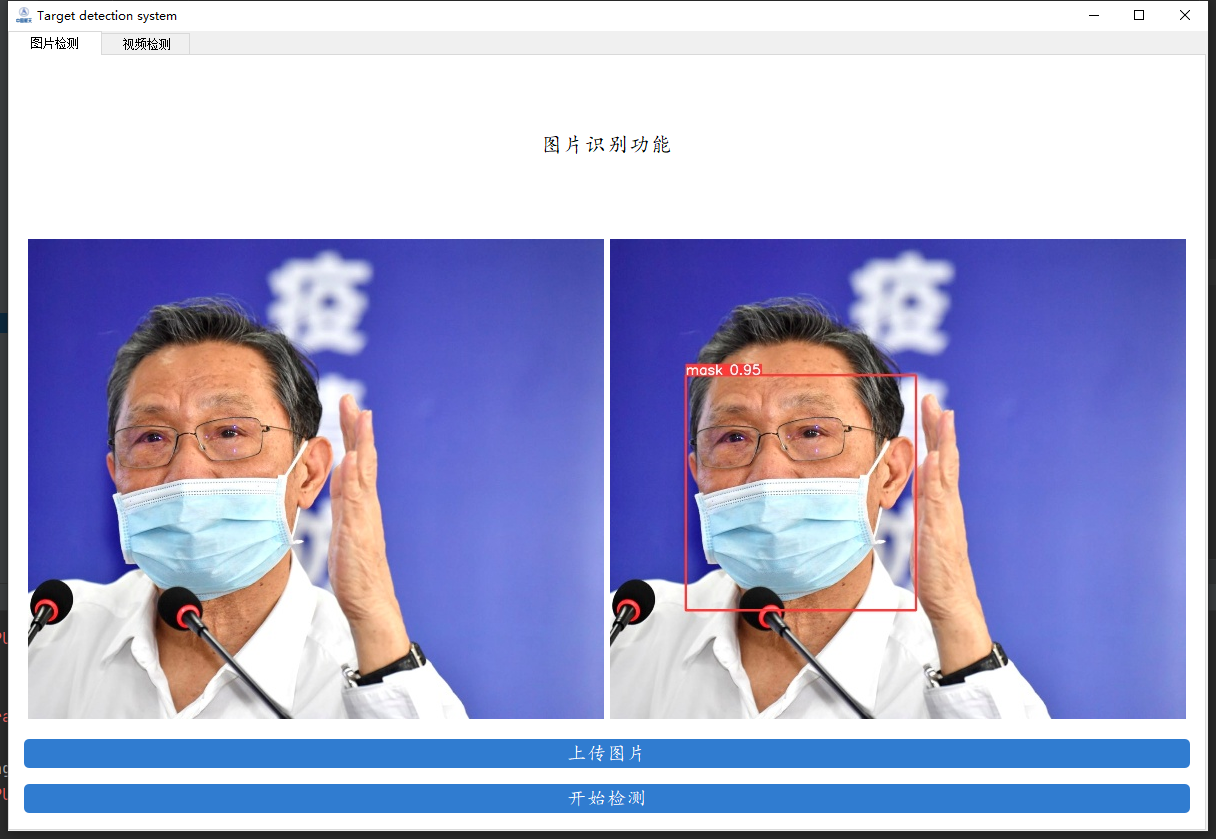
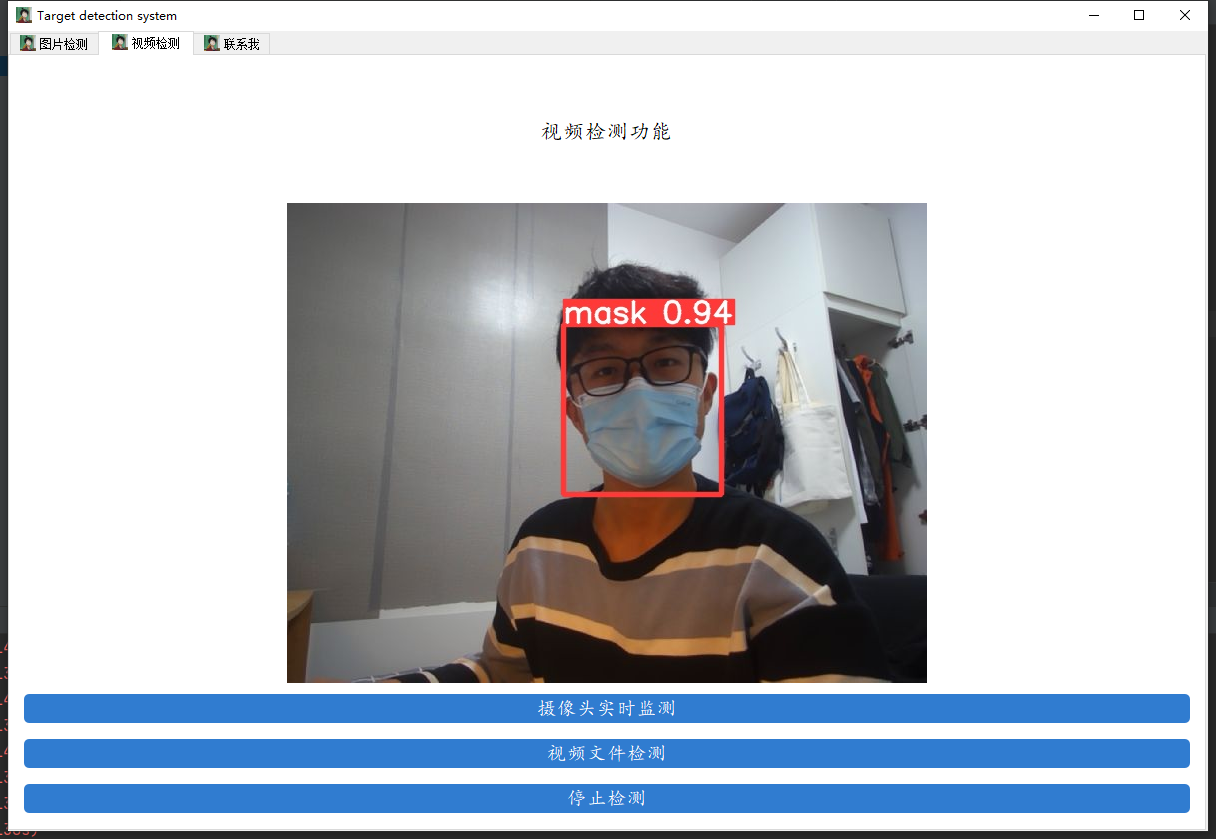
先來看看我們要實作的效果,我們將會通過資料來訓練一個口罩檢測的模型,并用pyqt5進行封裝,實作圖片口罩檢測、視頻口罩檢測和攝像頭實時口罩檢測的功能,
下載代碼
代碼的下載地址是:[YOLOV5-mask-42: 基于YOLOV5的口罩檢測系統-提供教學視頻 (gitee.com)](https://github.com/ultralytics/yolov5)
配置環境
不熟悉pycharm的anaconda的小伙伴請先看這篇csdn博客,了解pycharm和anaconda的基本操作
如何在pycharm中配置anaconda的虛擬環境_dejahu的博客-CSDN博客_如何在pycharm中配置anaconda
anaconda安裝完成之后請切換到國內的源來提高下載速度 ,命令如下:
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
首先創建python3.8的虛擬環境,請在命令列中執行下列操作:
conda create -n yolo5 python==3.8.5
conda activate yolo5
pytorch安裝(gpu版本和cpu版本的安裝)
實際測驗情況是YOLOv5在CPU和GPU的情況下均可使用,不過在CPU的條件下訓練那個速度會令人發指,所以有條件的小伙伴一定要安裝GPU版本的Pytorch,沒有條件的小伙伴最好是租服務器來使用,
GPU版本安裝的具體步驟可以參考這篇文章:2021年Windows下安裝GPU版本的Tensorflow和Pytorch_dejahu的博客-CSDN博客
需要注意以下幾點:
- 安裝之前一定要先更新你的顯卡驅動,去官網下載對應型號的驅動安裝
- 30系顯卡只能使用cuda11的版本
- 一定要創建虛擬環境,這樣的話各個深度學習框架之間不發生沖突
我這里創建的是python3.8的環境,安裝的Pytorch的版本是1.8.0,命令如下:
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意這條命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接執行這條命令即可
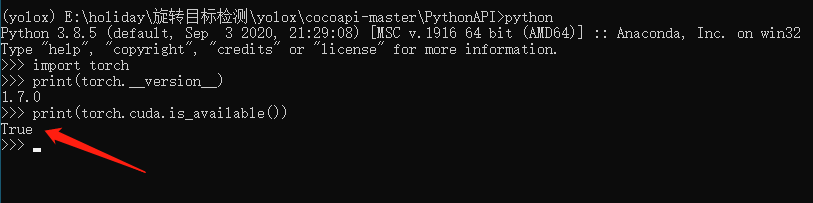
安裝完畢之后,我們來測驗一下GPU是否
pycocotools的安裝
后面我發現了windows下更簡單的安裝方法,大家可以使用下面這個指令來直接進行安裝,不需要下載之后再來安裝
pip install pycocotools-windows
其他包的安裝
另外的話大家還需要安裝程式其他所需的包,包括opencv,matplotlib這些包,不過這些包的安裝比較簡單,直接通過pip指令執行即可,我們cd到yolov5代碼的目錄下,直接執行下列指令即可完成包的安裝,
pip install -r requirements.txt
pip install pyqt5
pip install labelme
測驗一下
在yolov5目錄下執行下列代碼
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt
執行完畢之后將會輸出下列資訊

在runs目錄下可以找到檢測之后的結果
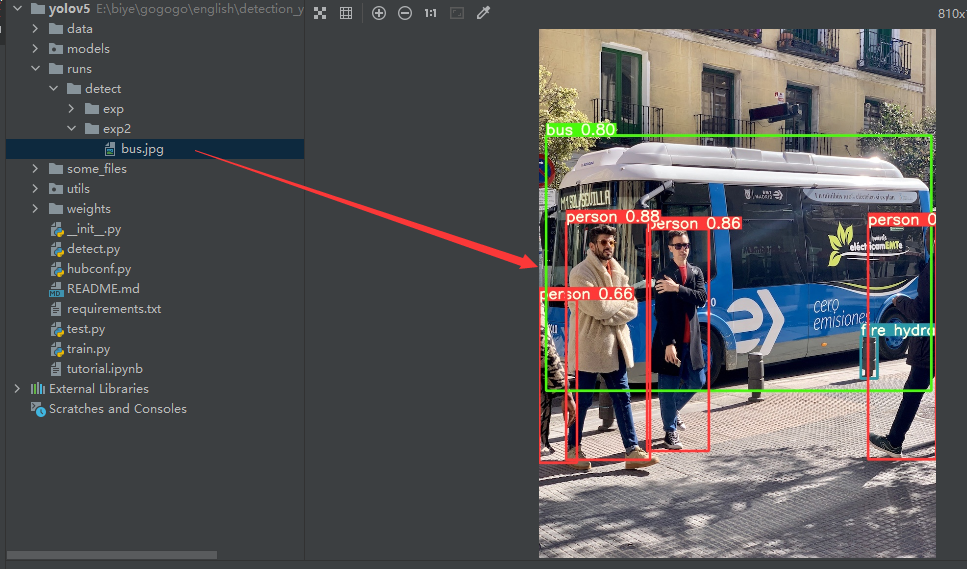
按照官方給出的指令,這里的檢測代碼功能十分強大,是支持對多種影像和視頻流進行檢測的,具體的使用方法如下:
python detect.py --source 0 # webcam
file.jpg # image
file.mp4 # video
path/ # directory
path/*.jpg # glob
'https://youtu.be/NUsoVlDFqZg' # YouTube video
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
資料處理
這里改成yolo的標注形式,之后專門出一期資料轉換的內容,
資料標注這里推薦的軟體是labelimg,通過pip指令即可安裝
在你的虛擬環境下執行pip install labelimg -i https://mirror.baidu.com/pypi/simple命令進行安裝,然后在命令列中直接執行labelimg軟體即可啟動資料標注軟體,
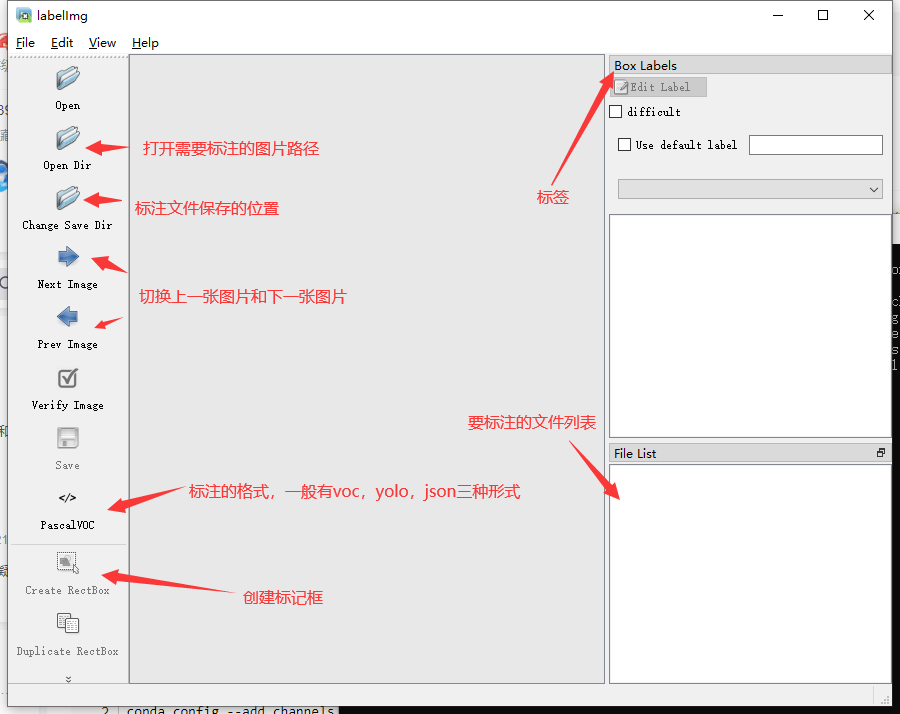
軟體啟動后的界面如下:
資料標注
雖然是yolo的模型訓練,但是這里我們還是選擇進行voc格式的標注,一是方便在其他的代碼中使用資料集,二是我提供了資料格式轉化
標注的程序是:
1.打開圖片目錄
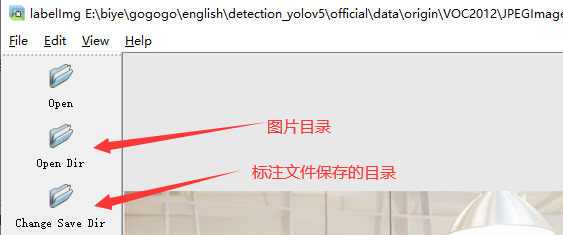
2.設定標注檔案保存的目錄并設定自動保存
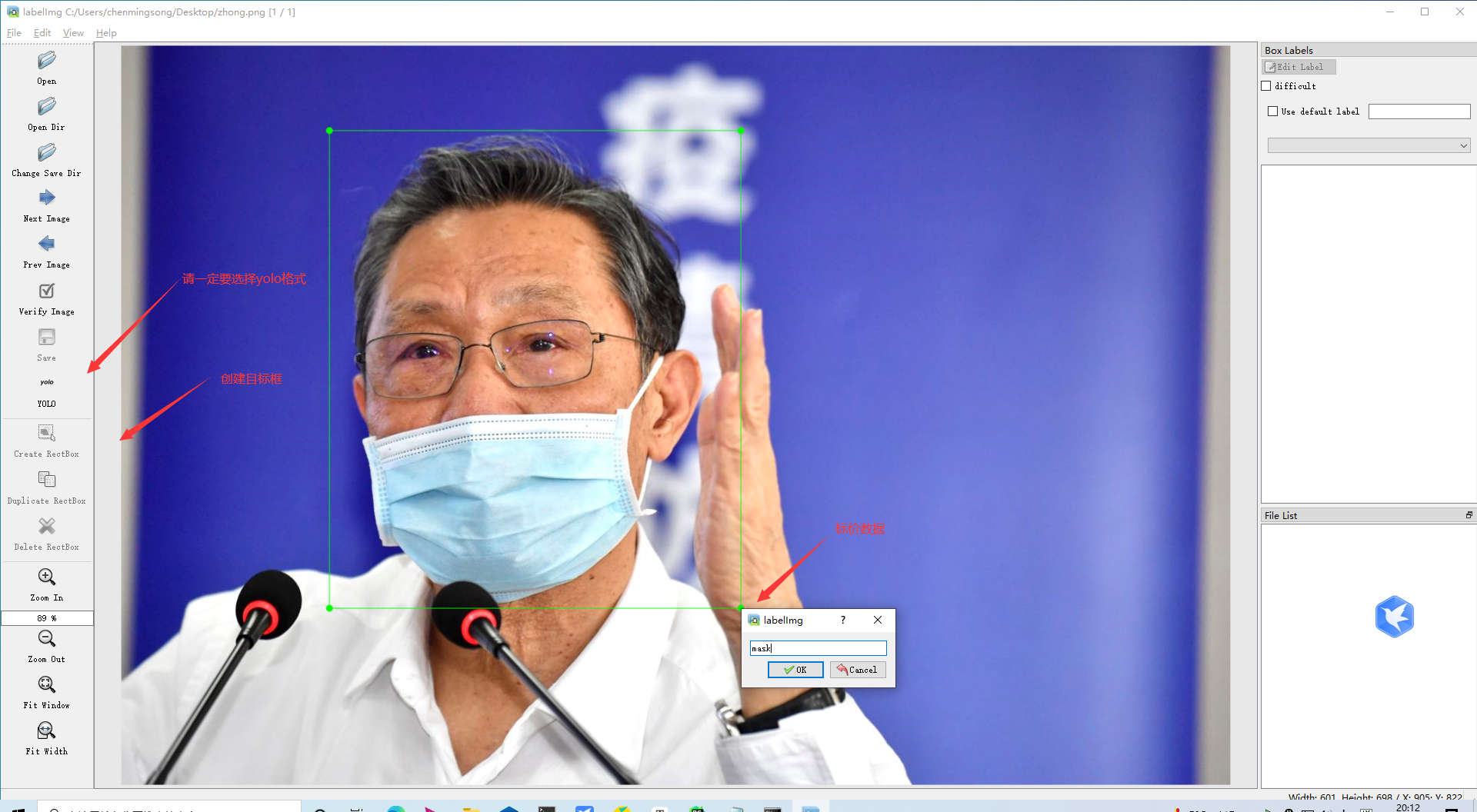
3.開始標注,畫框,標記目標的label,crtl+s保存,然后d切換到下一張繼續標注,不斷重復重復
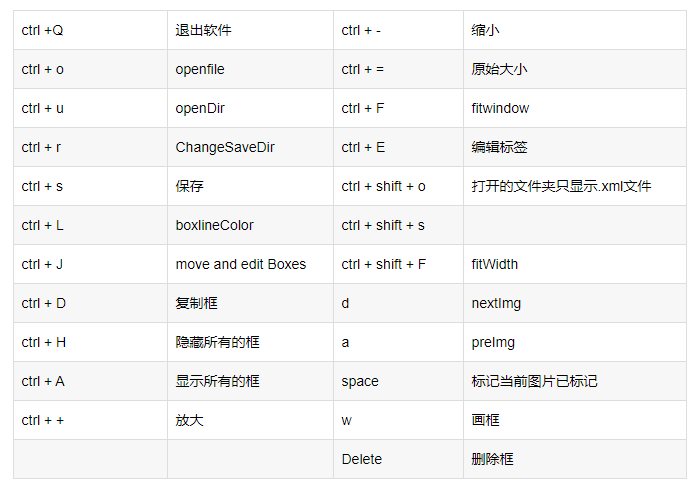
labelimg的快捷鍵如下,學會快捷鍵可以幫助你提高資料標注的效率,
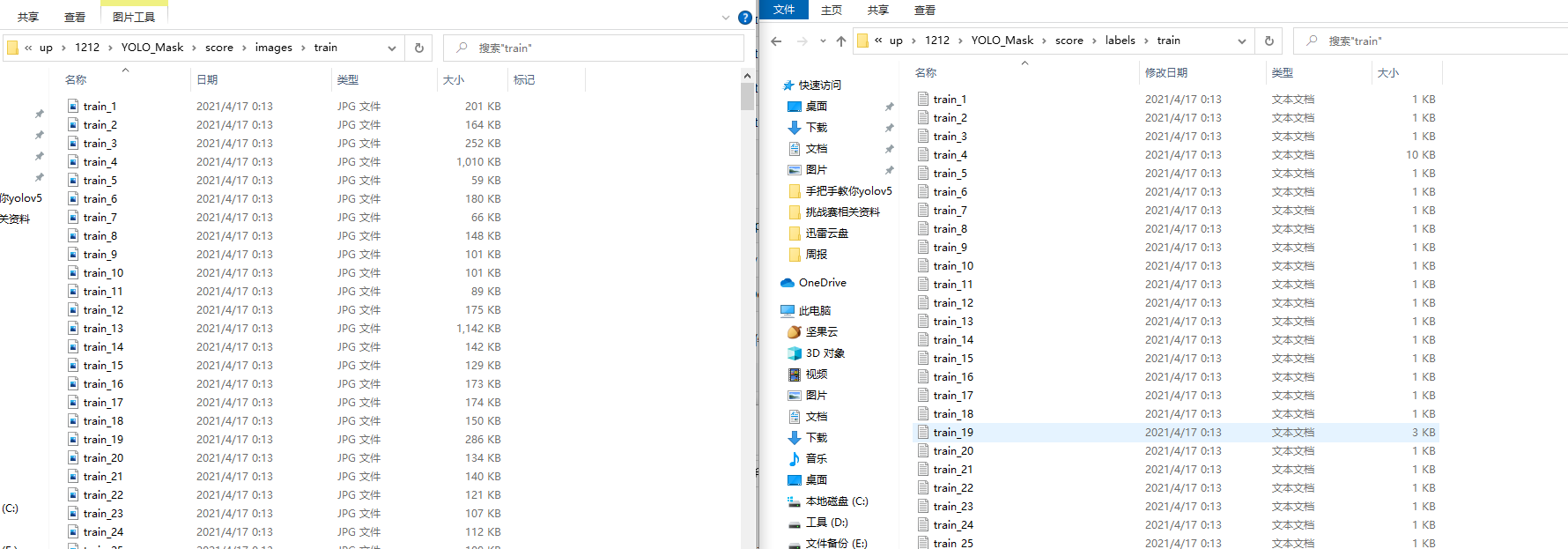
標注完成之后你會得到一系列的txt檔案,這里的txt檔案就是目標檢測的標注檔案,其中txt檔案和圖片檔案的名稱是一一對應的,如下圖所示:
打開具體的標注檔案,你將會看到下面的內容,txt檔案中每一行表示一個目標,以空格進行區分,分別表示目標的類別id,歸一化處理之后的中心點x坐標、y坐標、目標框的w和h,

4.修改資料集組態檔
標記完成的資料請按照下面的格式進行放置,方便程式進行索引,
YOLO_Mask
└─ score
├─ images
│ ├─ test # 下面放測驗集圖片
│ ├─ train # 下面放訓練集圖片
│ └─ val # 下面放驗證集圖片
└─ labels
├─ test # 下面放測驗集標簽
├─ train # 下面放訓練集標簽
├─ val # 下面放驗證集標簽
這里的組態檔是為了方便我們后期訓練使用,我們需要在data目錄下創建一個mask_data.yaml的檔案,如下圖所示:
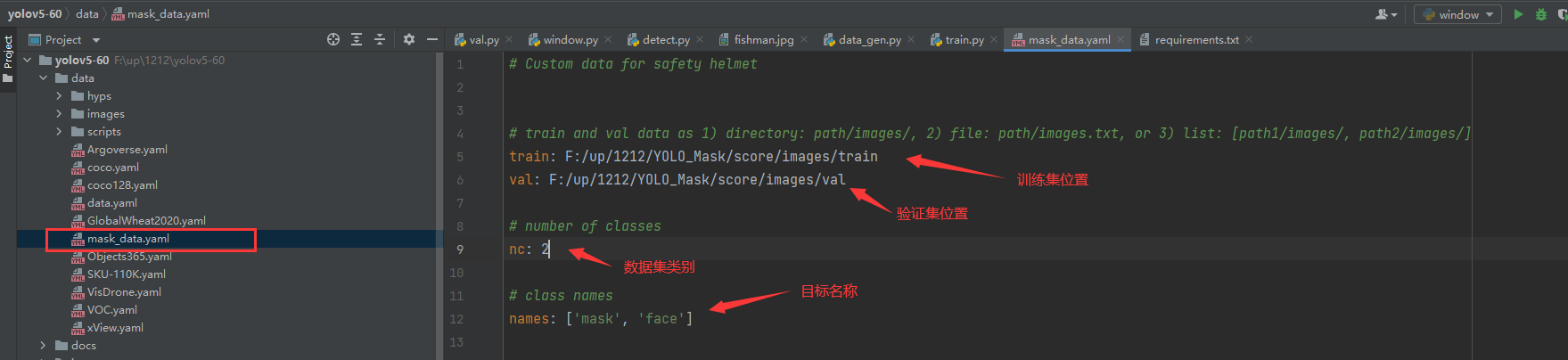
到這里,資料集處理部分基本完結撒花了,下面的內容將會是模型訓練!
模型訓練
模型的基本訓練
在models下建立一個mask_yolov5s.yaml的模型組態檔,內容如下:
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-qYQ5eEe6-1639544279066)(C:\Users\chenmingsong\AppData\Roaming\Typora\typora-user-images\image-20211212174749558.png)]
模型訓練之前,請確保代碼目錄下有以下檔案
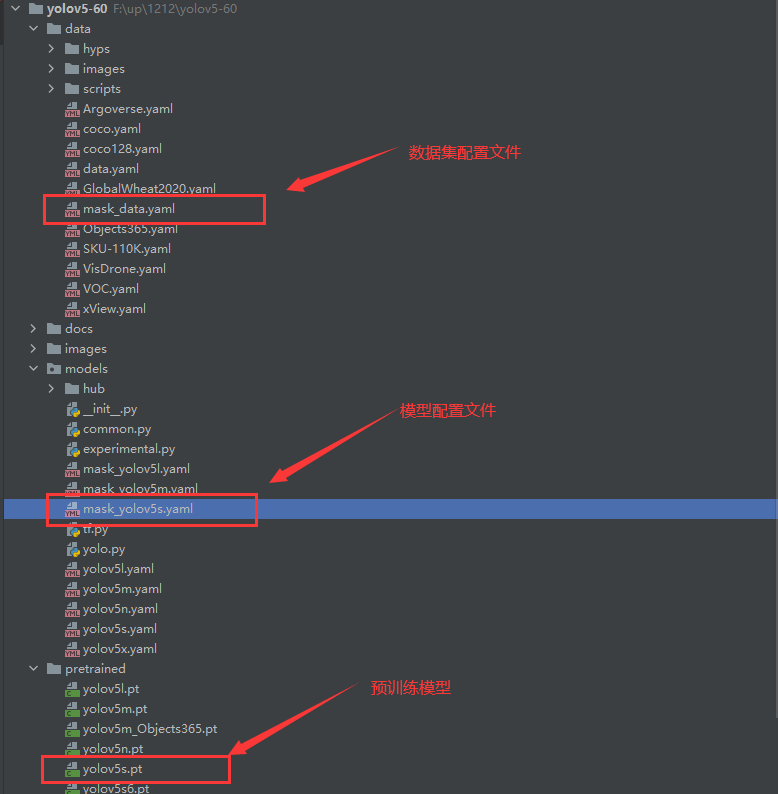
執行下列代碼運行程式即可:
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu
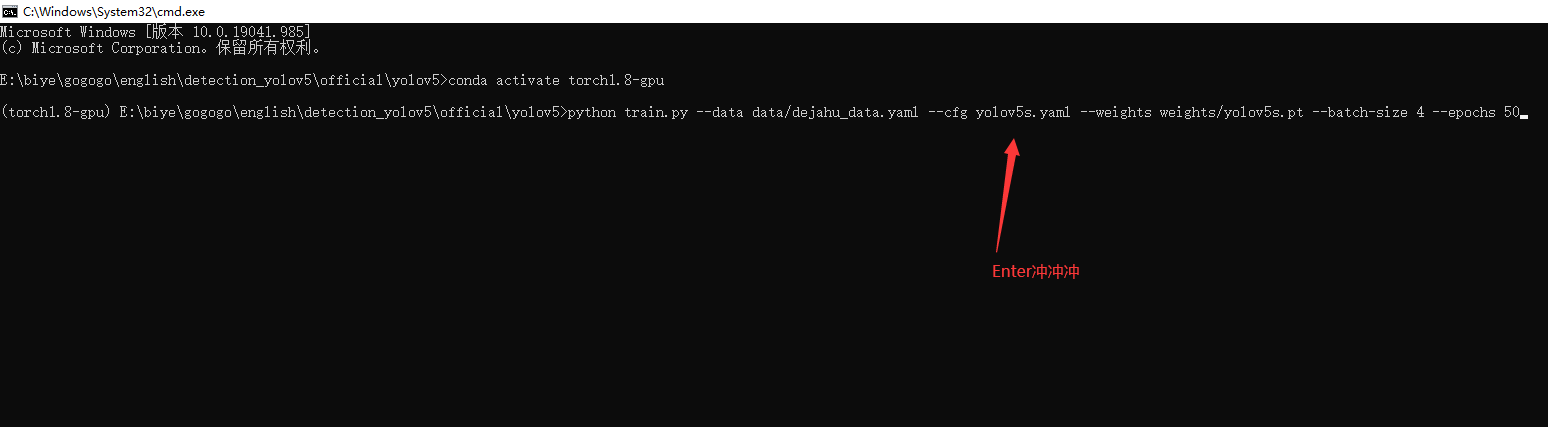
訓練代碼成功執行之后會在命令列中輸出下列資訊,接下來就是安心等待模型訓練結束即可,

根據資料集的大小和設備的性能,經過漫長的等待之后模型就訓練完了,輸出如下:

在train/runs/exp3的目錄下可以找到訓練得到的模型和日志檔案
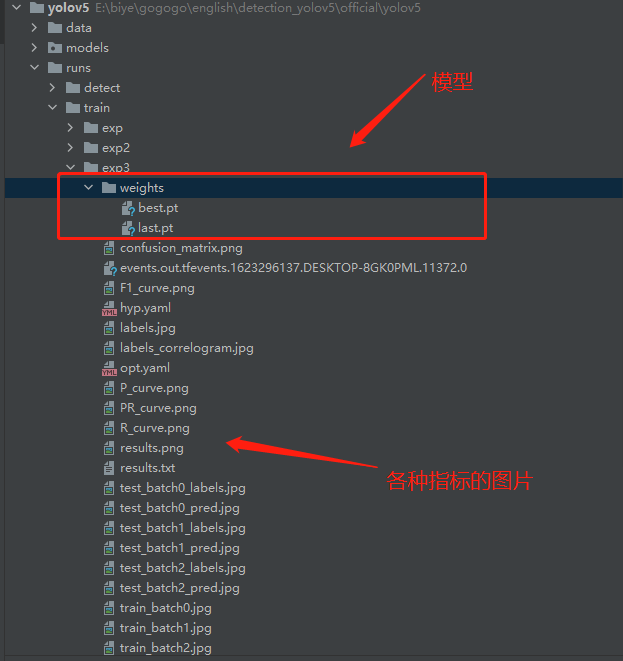
當然還有一些騷操作,比如模型訓練到一半可以從中斷點繼續訓練,這些就交給大家下去自行探索嘍,
模型評估
出了在博客一開頭你就能看到的檢測效果之外,還有一些學術上的評價指標用來表示我們模型的性能,其中目標檢測最常用的評價指標是mAP,mAP是介于0到1之間的一個數字,這個數字越接近于1,就表示你的模型的性能更好,
一般我們會接觸到兩個指標,分別是召回率recall和精度precision,兩個指標p和r都是簡單地從一個角度來判斷模型的好壞,均是介于0到1之間的數值,其中接近于1表示模型的性能越好,接近于0表示模型的性能越差,為了綜合評價目標檢測的性能,一般采用均值平均密度map來進一步評估模型的好壞,我們通過設定不同的置信度的閾值,可以得到在模型在不同的閾值下所計算出的p值和r值,一般情況下,p值和r值是負相關的,繪制出來可以得到如下圖所示的曲線,其中曲線的面積我們稱AP,目標檢測模型中每種目標可計算出一個AP值,對所有的AP值求平均則可以得到模型的mAP值,以本文為例,我們可以計算佩戴安全帽和未佩戴安全帽的兩個目標的AP值,我們對兩組AP值求平均,可以得到整個模型的mAP值,該值越接近1表示模型的性能越好,
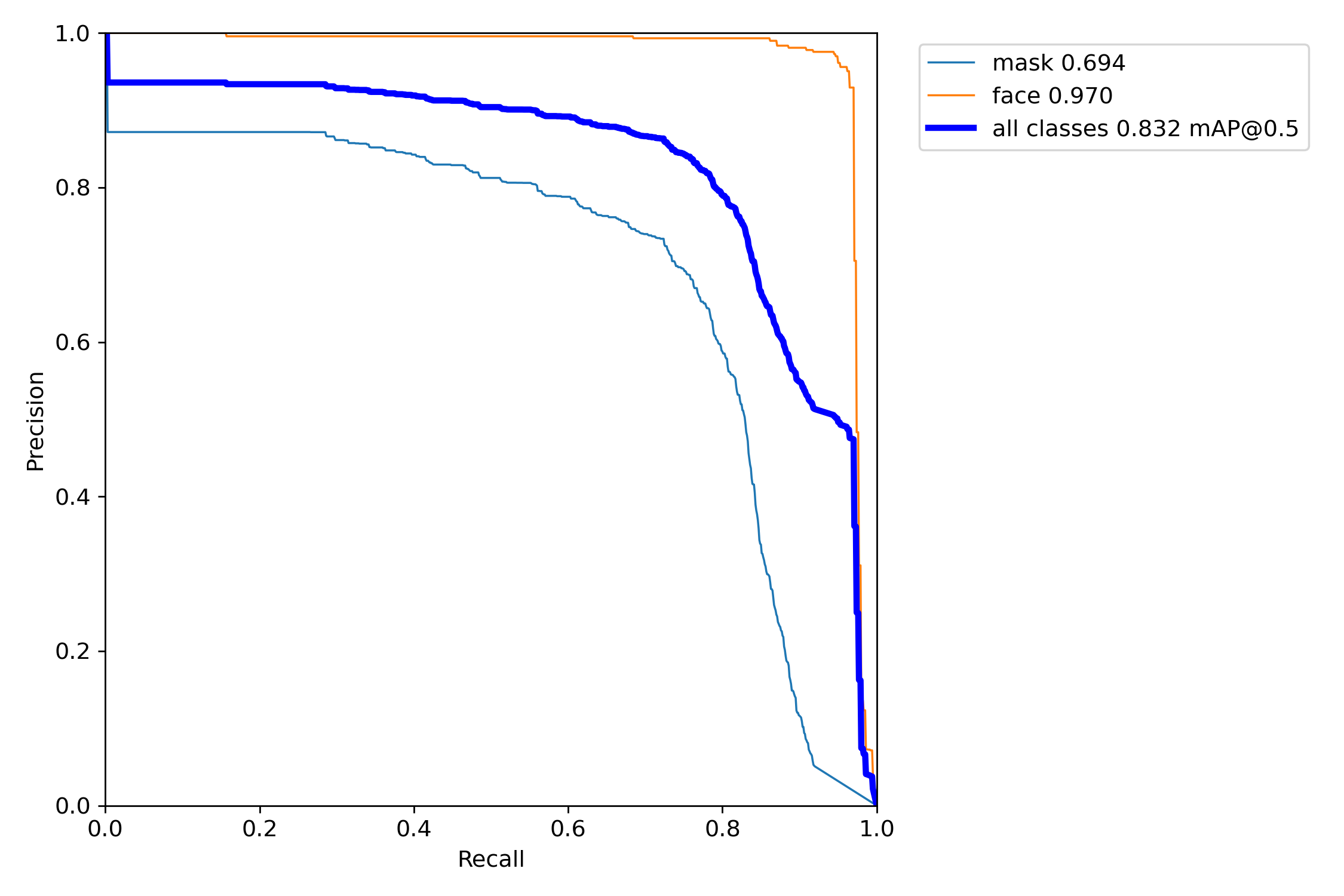
關于更加學術的定義大家可以在知憾訓者csdn上自行查閱,以我們本次訓練的模型為例,在模型結束之后你會找到三張影像,分別表示我們模型在驗證集上的召回率、準確率和均值平均密度,
以PR-curve為例,你可以看到我們的模型在驗證集上的均值平均密度為0.832,
如果你的目錄下沒有這樣的曲線,可能是因為你的模型訓練一半就停止了,沒有執行驗證的程序,你可以通過下面的命令來生成這些圖片,
python val.py --data data/mask_data.yaml --weights runs/train/exp_yolov5s/weights/best.pt --img 640
最后,這里是一張詳細的評價指標的解釋清單,可以說是最原始的定義了,

模型使用
模型的使用全部集成在了detect.py目錄下,你按照下面的指令指你要檢測的內容即可
# 檢測攝像頭
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source 0 # webcam
# 檢測圖片檔案
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.jpg # image
# 檢測視頻檔案
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source file.mp4 # video
# 檢測一個目錄下的檔案
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt path/ # directory
# 檢測網路視頻
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'https://youtu.be/NUsoVlDFqZg' # YouTube video
# 檢測流媒體
python detect.py --weights runs/train/exp_yolov5s/weights/best.pt 'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
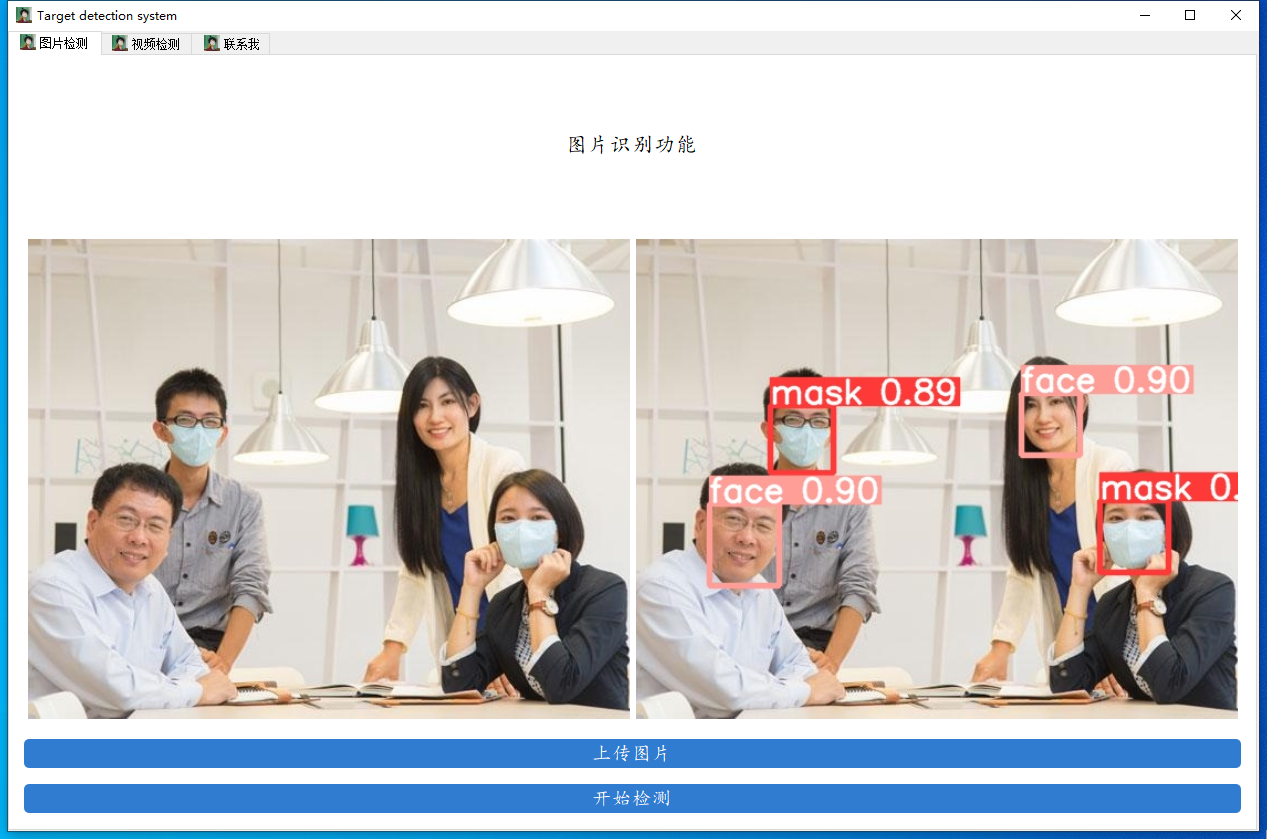
比如以我們的口罩模型為例,如果我們執行python detect.py --weights runs/train/exp_yolov5s/weights/best.pt --source data/images/fishman.jpg的命令便可以得到這樣的一張檢測結果,

構建可視化界面
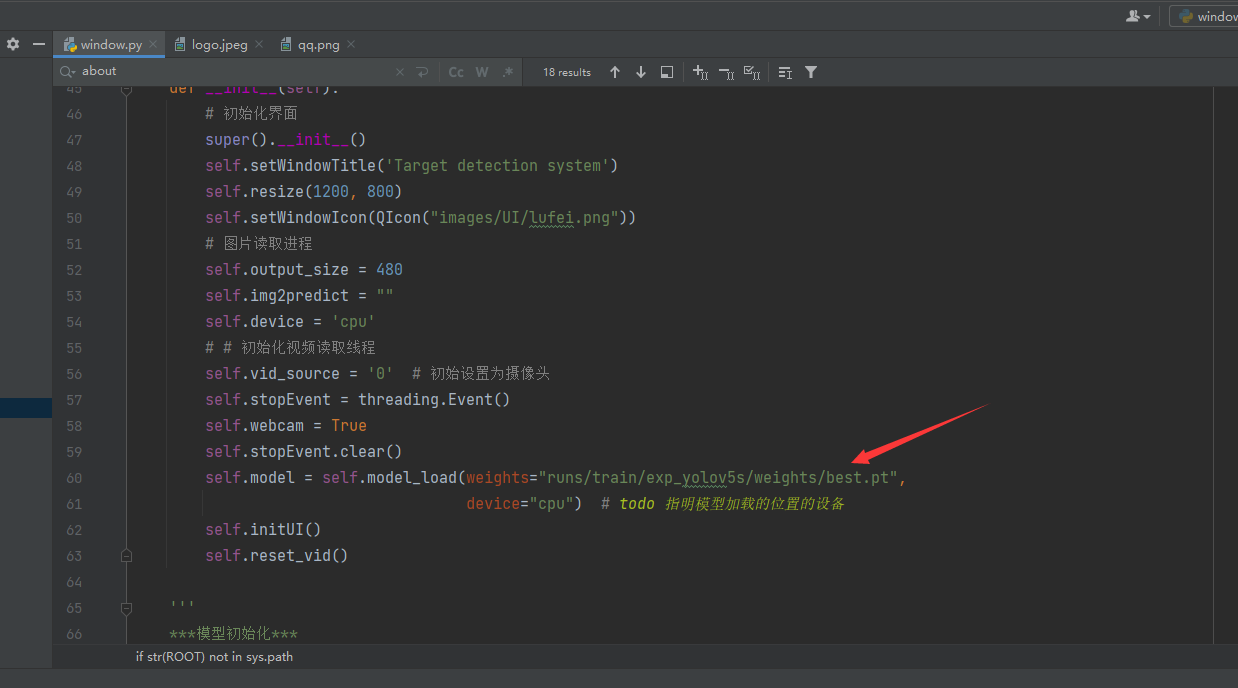
可視化界面的部分在window.py檔案中,是通過pyqt5完成的界面設計,在啟動界面前,你需要將模型替換成你訓練好的模型,替換的位置在window.py的第60行,修改成你的模型地址即可,如果你有GPU的話,可以將device設定為0,表示使用第0行GPU,這樣可以加快模型的識別速度嗷,
替換之后直接右鍵run即可啟動圖形化界面了,快去自己測驗一下看看效果吧
找到我
你可以通過這些方式來尋找我,
B站:肆十二-
CSDN:肆十二
知乎:肆十二
微博:肆十二-
現在關注以后就是老朋友嘍!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/382138.html
標籤:其他