文章目錄
- 0 簡介
- 1 背景意義
- 2 資料集
- 3 資料探索
- 4 資料增廣(資料集補充)
- 5 垃圾影像分類
- 5.1 遷移學習
- 5.1.1 什么是遷移學習?
- 5.1.2 為什么要遷移學習?
- 5.2 模型選擇
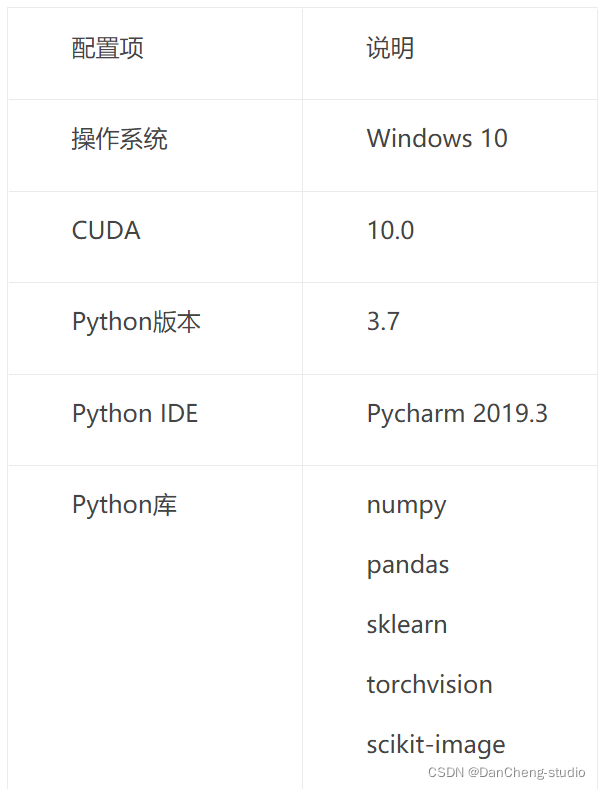
- 5.3 訓練環境
- 5.3.1 硬體配置
- 5.3.2 軟體配置
- 5.4 訓練程序
- 5.5 模型分類效果(PC端)
- 6 構建垃圾分類小程式
- 6.1 小程式功能
- 6.2 分類測驗
- 6.3 垃圾分類小提示
- 6.4 答題模塊
- 7 關鍵代碼
- 8 最后-畢設幫助
0 簡介
今天學長向大家介紹一個機器視覺專案
深度學習卷積神經網路垃圾分類系統
畢設幫助,開題指導,技術解答
🇶746876041
1 背景意義
近年來,隨著我國經濟的快速發展,國家各項建設都蒸蒸日上,成績顯著,但與此同時,也讓資源與環境受到了嚴重破壞,這種現象與垃圾分類投放時的不合理直接相關,而人們對于環境污染問題反映強烈卻束手無策,這兩者間的矛盾日益尖銳,人們日常生活中的垃圾主要包括有害垃圾、廚余垃圾、可回收垃圾以及其他垃圾這四類,對不同類別的垃圾應采取不同分類方法,如果投放不當,可能會導致各種環境污染問題,合理地進行垃圾分類是有效進行垃圾處理、減少環境污染與資源再利用中的關鍵舉措,也是目前最合適最有效的科學管理方式,利用現有的生產水平將日常垃圾按類別處理、利用有效物質和能量、填埋無用垃圾等,這樣既能夠提高垃圾資源處理效率,又能緩解環境污染問題,
而對垃圾的分類首先是在影像識別的基礎上的,因此本文想通過使用近幾年來發展迅速的深度學習方法設計一個垃圾分類系統,從而實作對日常生活中常見垃圾進行智能識別分類,提高人們垃圾分類投放意識,同時避免人們錯誤投放而產生的環境污染,
2 資料集
資料集采用了中國發布的垃圾分類標準,該標準將人們日常生活中常見的垃圾分為了四大類,其中,將廢棄的玻璃、織物、家具以及電器電子產品等適合回收同時可回圈利用的廢棄物歸為可回收垃圾,將剩菜剩飯、果皮果殼、花卉綠植以及其他餐廚垃圾等容易腐爛的廢棄物歸為廚余垃圾,將廢電池、廢藥品、廢燈管等對人們身體健康和自然環境有害而且應當門處理的廢棄物歸為有害垃圾,除以上三類垃圾之外的廢棄物都歸為其他垃圾,
該資料集是圖片資料,分為訓練集85%(Train)和測驗集15%(Test),其中O代表Organic(有機垃圾),R代表Recycle(可回收)

3 資料探索
我們先簡單的大致看看資料的情況
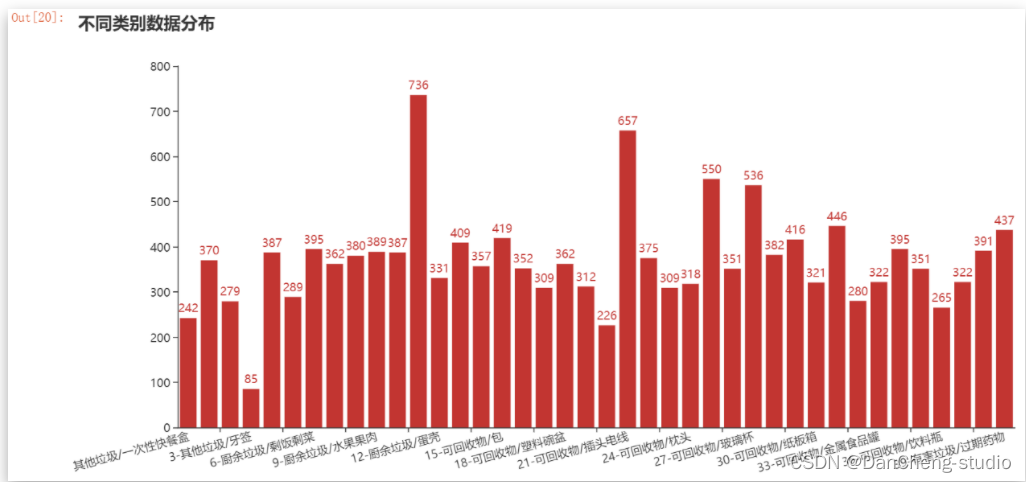
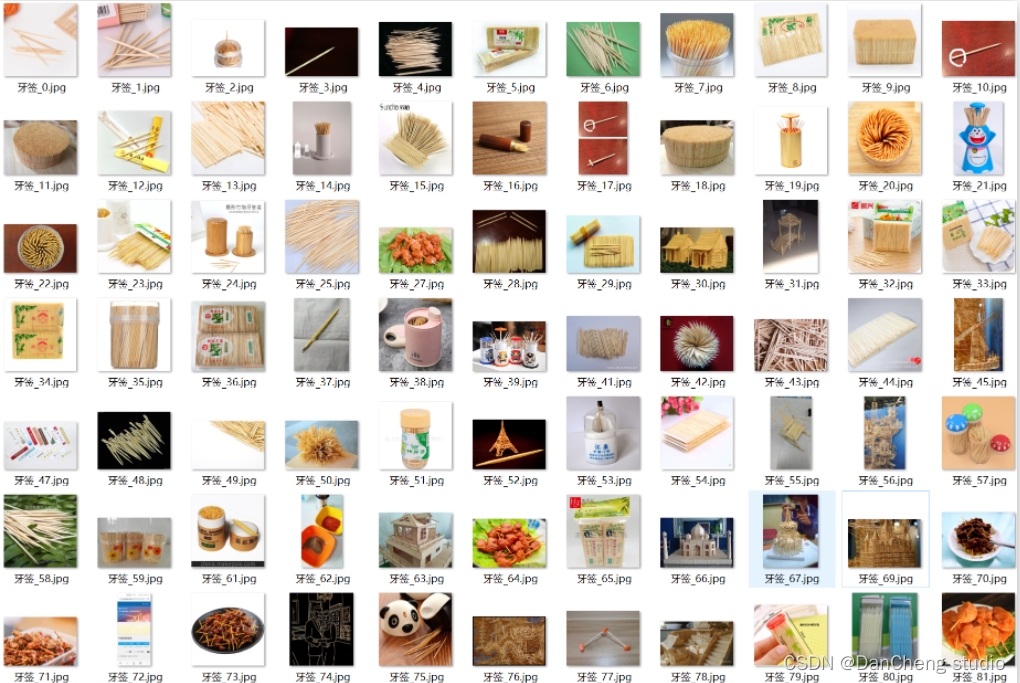
所得的垃圾圖片資料集中有40個二級類別,圖片數量合計 14802張,由圖3-1可以看出,各個垃圾類別的影像資料量不均衡,其中圖片資料量較少的類別有:類別0(一次性快餐盒)、類別3(牙簽)、類別20(快遞紙袋);資料量較多的類別是:類別11(菜葉根)、類別21(插頭電線)、類別25(毛絨玩具),
4 資料增廣(資料集補充)
資料增廣就是對基礎資料集進行擴充,避免因為資料集太少導致在模型訓練程序可能出現的過擬合現象,以此來提高模型泛化能力,達到更好的效果,根據擴充資料集的來源可分為兩類:內部資料增廣是對基礎資料集進行水平翻轉、垂直翻轉、高斯噪聲以及高斯模糊等變換操作,來產生新的特征;而外部資料增廣是引入新的高質量外部資料來擴充資料集,包括資料爬取與資料篩選兩個步驟,
資料爬取是通過網路爬蟲技術來實作的,爬蟲的流程是,首先向遠程服務器端發送請求,獲取目標網頁的HTML檔案;然后跟蹤這個鏈接檔案,獲取檔案資料,各種搜索引擎就是通過爬蟲技術來實作網頁資料更新,爬取的效率直接決定了搜索的效果,
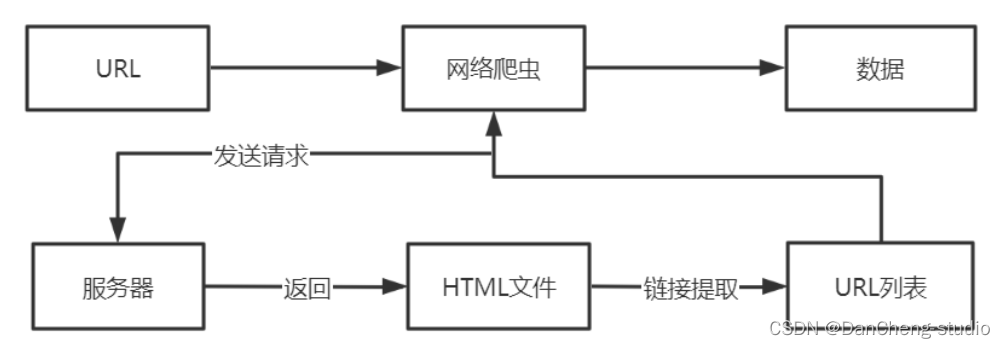
根據流程圖可以看到,爬蟲的流程與用戶瀏覽網頁的程序相似,首先輸入目標URL地址,向服務器發送請求,接著服務器端會回傳包含大量鏈接的HTML檔案,然后提取這些鏈接將其組成URL串列,通過串行或并行方式從服務器端中下載資料,
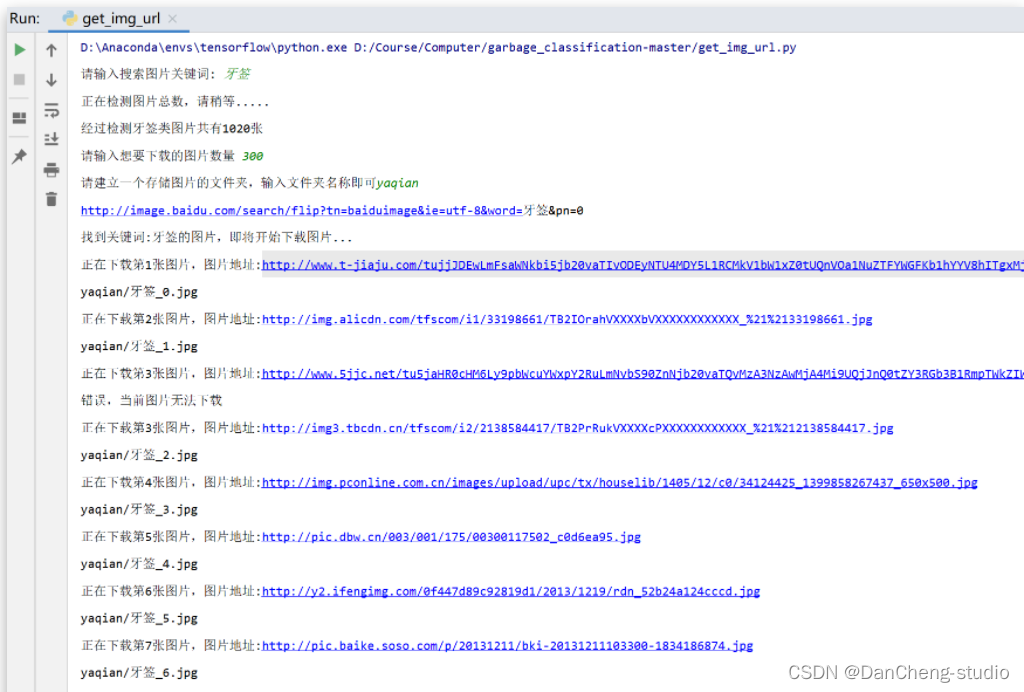
由于基礎資料集中類別數量不均衡,所以本設計使用網路爬蟲方式從百度圖庫對數量較少的類別進行資料擴充,首先輸入想要爬取的圖片名稱關鍵字,然后輸入想要爬取圖片的數量以及存放的檔案夾之后,進行圖片爬取,
5 垃圾影像分類
5.1 遷移學習
5.1.1 什么是遷移學習?
遷移學習是指在一個資料集上,重新利用之前已經訓練過的卷積神經網路,并將其遷移到另外的資料集上,
5.1.2 為什么要遷移學習?
卷積神經網路前面的層提取的是影像的紋理、色彩等特征,而越靠近網路后端,提取的特征就會越高級、抽象,所以常用的微調方法是,保持網路中其他引數不變,只修改預訓練網路的最后幾層,最后幾層的引數在新資料集上重新訓練得到,其他層的引數保持不變,作為特征提取器,之后再使用較小的學習率訓練整個網路,因為從零開始訓練整個卷積網路是非常困難的,而且要花費大量的時間以及計算資源,所以采取遷移學習的方式是一種有效策略,
通常在非常大的資料集上對ConvNet進行預訓練,然后將ConvNet用作初始化或者是固定特征提取器,以下是兩個主要的遷移學習方法:
1.微調卷積網路,使用預訓練的網路來初始化網路而不使用隨機初始化,比較常用的方法是使用在ImageNet資料集上訓練好的模型引數進行初始化,然后訓練自己的資料集,
2.將卷積網路作為固定特征提取器,凍結除了全連接層外的所有其他層的權重,將最后的那個全連接層替換為具有隨機權重的層,然后只對該層進行訓練,
要使用深度學習方法來解決垃圾影像識別分類問題,就需要大量的垃圾圖片資料集,因為當資料集太小時,一旦加深模型結構,就很可能出現過擬合的情況,訓練出的模型泛化能力不足,識別準確率不高,而基于遷移學習的方法,預訓練模型已經具備了提取影像基本特征基的能力,這就能在一定程度上級訓過擬合發生的可能性,將預模型遷移到垃圾影像資料集上進行微調訓練,提高識別準確率,
5.2 模型選擇
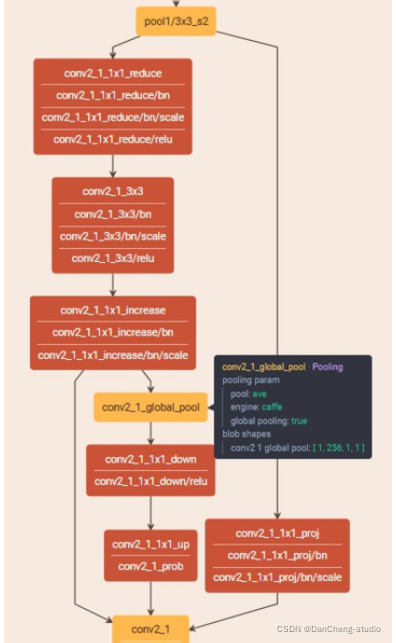
采用遷移學習的方式匯入預訓練模型,凍結特征提取層,進行微調訓練,選取了SeNet154、Se_ResNet50、Se_ResNext101、ResNext101_32x16d_WSL四種模型進行對比實驗,選取結果較好的模型進行調優,其中,ResNext101_32x16d_WS預訓練模型是由FaceBook在2019年開源的
SeNet154結構
學長采用的模型結構:
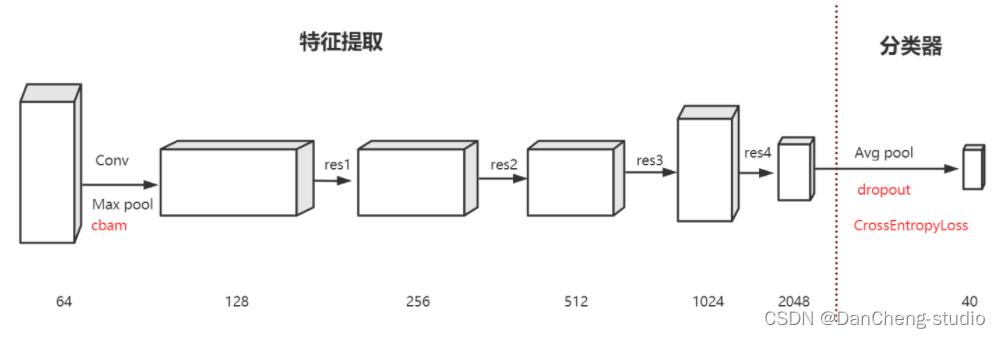
采用ResNext101_32x16d_WSL網路作為基本的網路結構進行遷移學習,將CBAM注意力機制模塊添加在首層卷積層,來增強影像特征表征能力,關注影像的重要特征抑制不必要的特征,固定除全連接層之外的其他層的權重,為降低過擬合,在模型全連接層添加了Dropout層,損失函式采用交叉熵損失函式(CrossEntropyLoss),優化函式對比了SGD和Adam,Adam在起始收斂速度快,但最終SGD精度高,所以采用了SGD,
5.3 訓練環境
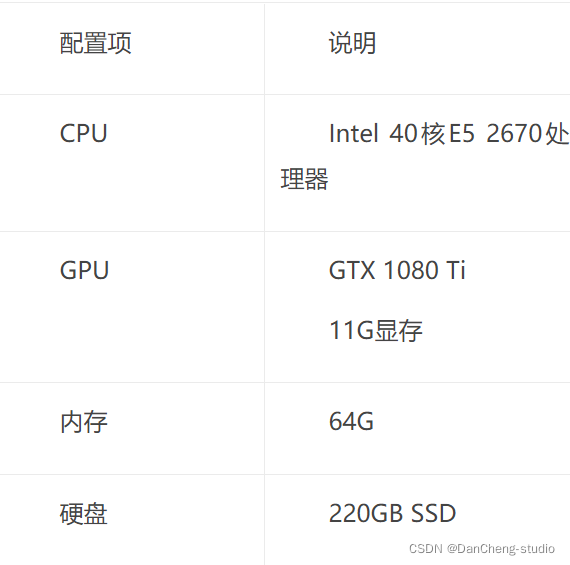
5.3.1 硬體配置
5.3.2 軟體配置
5.4 訓練程序
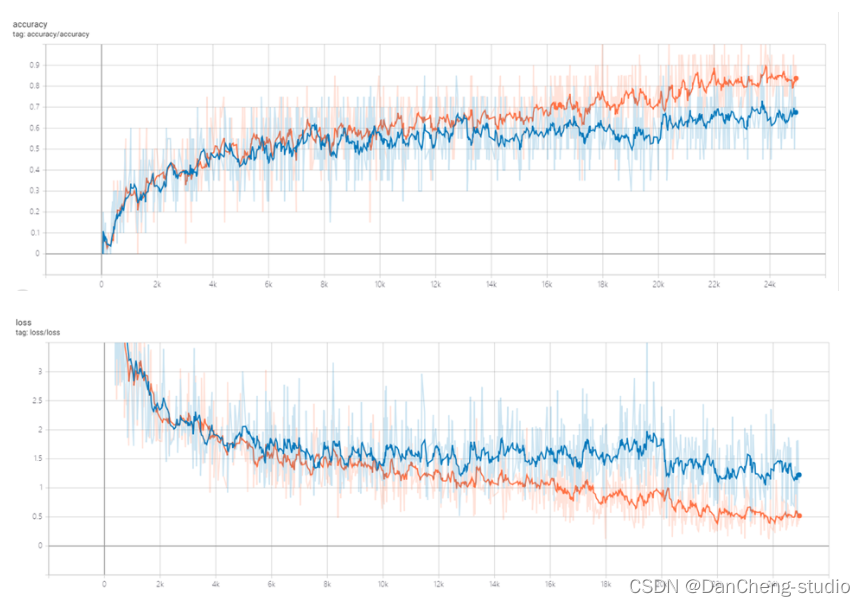
構建好模型結構后,設定資料集加載路徑,在搭建好的環境中進行模型訓練,將訓練程序中每輪迭代的Train Loss、Valid Loss、Train Acc、Valid Acc等資料保存到log日志檔案中,然后使用matplotlib庫繪制在訓練集和測驗集上的Accuracy跟Loss的變化曲線,
目前模型訓練集準確度83.8%,測驗集準確度67.5%,仍有待提高,,
5.5 模型分類效果(PC端)

6 構建垃圾分類小程式
學長設計的垃圾分類系統的核心功能是從本地相冊上傳照片或拍照上傳照片進行識別分類,除此之外,還引入了語音識別功能、文字搜索功能、垃圾分類答題功能等滿足用戶的不同需求,系統的模塊設計如下圖所示,
·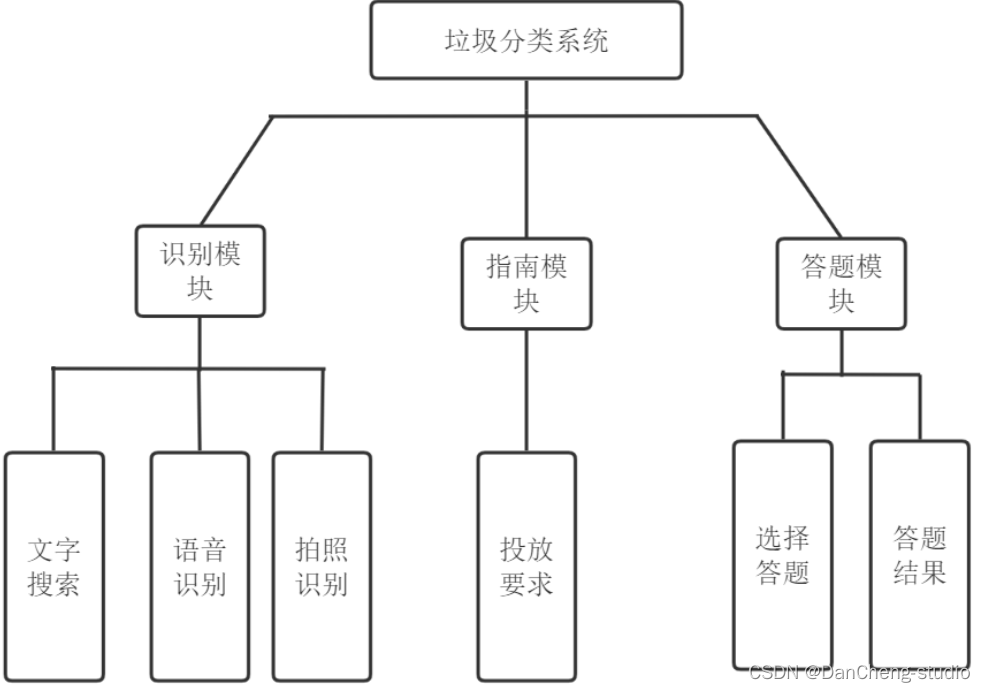
其中識別模塊是用戶選擇識別功能,包含拍照/相冊識別,語音識別、文字搜索等功能,根據所選城市的不同展示相應的垃圾類別;指南功能模塊是根據所選城市的不同介紹各種垃圾的種類以及投放要求;答題模塊實作垃圾種類的選擇答題功能,
6.1 小程式功能
識別模塊的功能包括文字搜索、語音識別、拍照識別等,該模塊界面設計如圖所示:

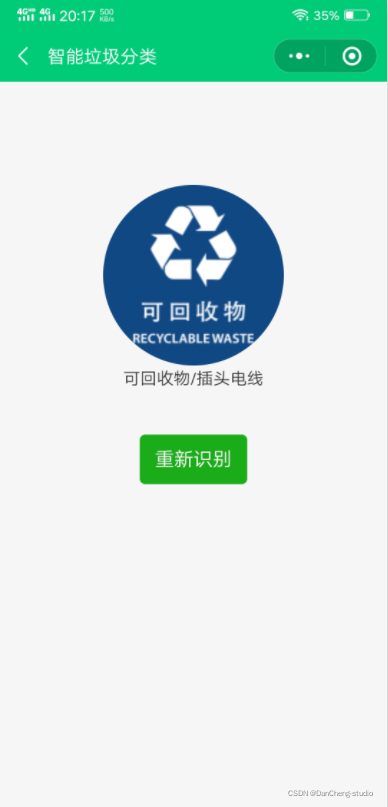
首先選擇用戶所在城市,然后選擇使用的搜索方式,當通過三種搜索方式搜索不到相應垃圾類別時,可以通過反饋功能將未識別的垃圾名稱向后臺反饋資訊,以便進一步完善系統,系統核心功能為拍照識別功能,拍照識別功能即呼叫在前面已經部署在華為云Model Arts平臺上的垃圾分類識別模型,對用戶從手機端提交的垃圾圖片進行在線識別分類并回傳識別結果,呼叫程序中用到了小程式的云函式功能,
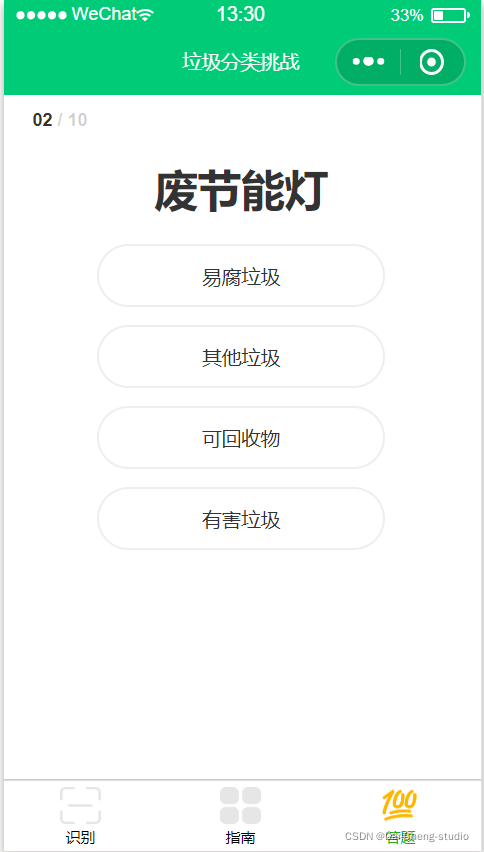
6.2 分類測驗
6.3 垃圾分類小提示
指南模塊實作的功能是根據用戶所選擇的城市,將云資料庫中的資料展示給用戶,介紹目前不同城市發布的垃圾分類規則及投放的要求,如下圖所示:



6.4 答題模塊
答題模塊也是根據用戶所選城市的不同,測評用戶對其所在城市垃圾分類規則了解的程度,以此來科普垃圾分類知識以及增強人們垃圾分類的意識,該界面如下圖所示,在答完題后顯示分數以及正確答案,

答題答案表
├─ 其他垃圾_PE塑料袋
├─ 其他垃圾_U型回形針
├─ 其他垃圾_一次性杯子
├─ 其他垃圾_一次性棉簽
├─ 其他垃圾_串串竹簽
├─ 其他垃圾_便利貼
├─ 其他垃圾_創可貼
├─ 其他垃圾_衛生紙
├─ 其他垃圾_廚房手套
├─ 其他垃圾_廚房抹布
├─ 其他垃圾_口罩
├─ 其他垃圾_唱片
├─ 其他垃圾_圖釘
├─ 其他垃圾_大龍蝦頭
├─ 其他垃圾_奶茶杯
├─ 其他垃圾_干燥劑
├─ 其他垃圾_彩票
├─ 其他垃圾_打泡網
├─ 其他垃圾_打火機
├─ 其他垃圾_搓澡巾
├─ 其他垃圾_果殼
├─ 其他垃圾_毛巾
├─ 其他垃圾_涂改帶
├─ 其他垃圾_濕紙巾
├─ 其他垃圾_煙蒂
├─ 其他垃圾_牙刷
├─ 其他垃圾_電影票
├─ 其他垃圾_電蚊香
├─ 其他垃圾_百潔布
├─ 其他垃圾_眼鏡
├─ 其他垃圾_眼鏡布
├─ 其他垃圾_空調濾芯
├─ 其他垃圾_筆
├─ 其他垃圾_膠帶
├─ 其他垃圾_膠水廢包裝
├─ 其他垃圾_蒼蠅拍
├─ 其他垃圾_茶壺碎片
├─ 其他垃圾_草帽
├─ 其他垃圾_菜板
├─ 其他垃圾_車票
├─ 其他垃圾_酒精棉
├─ 其他垃圾_防霉防蛀片
├─ 其他垃圾_除濕袋
├─ 其他垃圾_餐巾紙
├─ 其他垃圾_餐盒
├─ 其他垃圾_驗孕棒
├─ 其他垃圾_雞毛撣
├─ 廚余垃圾_八寶粥
├─ 廚余垃圾_冰激凌
├─ 廚余垃圾_冰糖葫蘆
├─ 廚余垃圾_咖啡
├─ 廚余垃圾_圣女果
├─ 廚余垃圾_地瓜
├─ 廚余垃圾_堅果
├─ 廚余垃圾_殼
├─ 廚余垃圾_巧克力
├─ 廚余垃圾_果凍
├─ 廚余垃圾_果皮
├─ 廚余垃圾_核桃
├─ 廚余垃圾_梨
├─ 廚余垃圾_橙子
├─ 廚余垃圾_殘渣剩飯
├─ 廚余垃圾_水果
├─ 廚余垃圾_泡菜
├─ 廚余垃圾_火腿
├─ 廚余垃圾_火龍果
├─ 廚余垃圾_烤雞
├─ 廚余垃圾_瓜子
├─ 廚余垃圾_甘蔗
├─ 廚余垃圾_番茄
├─ 廚余垃圾_秸稈杯
├─ 廚余垃圾_秸稈碗
├─ 廚余垃圾_粉條
├─ 廚余垃圾_肉類
├─ 廚余垃圾_腸
├─ 廚余垃圾_蘋果
├─ 廚余垃圾_茶葉
├─ 廚余垃圾_草莓
├─ 廚余垃圾_菠蘿
├─ 廚余垃圾_菠蘿蜜
├─ 廚余垃圾_蘿卜
├─ 廚余垃圾_蒜
├─ 廚余垃圾_蔬菜
├─ 廚余垃圾_薯條
├─ 廚余垃圾_薯片
├─ 廚余垃圾_蘑菇
├─ 廚余垃圾_蛋
├─ 廚余垃圾_蛋撻
├─ 廚余垃圾_蛋糕
├─ 廚余垃圾_豆
├─ 廚余垃圾_豆腐
├─ 廚余垃圾_辣椒
├─ 廚余垃圾_面包
├─ 廚余垃圾_餅干
├─ 廚余垃圾_雞翅
├─ 可回收物_不銹鋼制品
├─ 可回收物_乒乓球拍
├─ 可回收物_書
├─ 可回收物_體重秤
├─ 可回收物_保溫杯
├─ 可回收物_保鮮膜內芯
├─ 可回收物_信封
├─ 可回收物_充電頭
├─ 可回收物_充電寶
├─ 可回收物_充電牙刷
├─ 可回收物_充電線
├─ 可回收物_凳子
├─ 可回收物_刀
├─ 可回收物_包
├─ 可回收物_單車
├─ 可回收物_卡
├─ 可回收物_臺燈
├─ 可回收物_吊牌
├─ 可回收物_吹風機
├─ 可回收物_呼啦圈
├─ 可回收物_地球儀
├─ 可回收物_地鐵票
├─ 可回收物_墊子
├─ 可回收物_塑料制品
├─ 可回收物_太陽能熱水器
├─ 可回收物_奶粉桶
├─ 可回收物_尺子
├─ 可回收物_尼龍繩
├─ 可回收物_布制品
├─ 可回收物_帽子
├─ 可回收物_手機
├─ 可回收物_手電筒
├─ 可回收物_手表
├─ 可回收物_手鏈
├─ 可回收物_打包繩
├─ 可回收物_列印機
├─ 可回收物_打氣筒
├─ 可回收物_掃地機器人
├─ 可回收物_護膚品空瓶
├─ 可回收物_拉桿箱
├─ 可回收物_拖鞋
├─ 可回收物_插線板
├─ 可回收物_搓衣板
├─ 可回收物_收音機
├─ 可回收物_放大鏡
├─ 可回收物_日歷
├─ 可回收物_暖寶寶
├─ 可回收物_望遠鏡
├─ 可回收物_木制切菜板
├─ 可回收物_木桶
├─ 可回收物_木棍
├─ 可回收物_木質梳子
├─ 可回收物_木質鍋鏟
├─ 可回收物_木雕
├─ 可回收物_枕頭
├─ 可回收物_果凍杯
├─ 可回收物_桌子
├─ 可回收物_棋子
├─ 可回收物_模具
├─ 可回收物_毯子
├─ 可回收物_水壺
├─ 可回收物_水杯
├─ 可回收物_沙發
├─ 可回收物_泡沫板
├─ 可回收物_滅火器
├─ 可回收物_燈罩
├─ 可回收物_煙灰缸
├─ 可回收物_熱水瓶
├─ 可回收物_燃氣灶
├─ 可回收物_燃氣瓶
├─ 可回收物_玩具
├─ 可回收物_玻璃制品
├─ 可回收物_玻璃器皿
├─ 可回收物_玻璃壺
├─ 可回收物_玻璃球
├─ 可回收物_瑜伽球
├─ 可回收物_電動剃須刀
├─ 可回收物_電動卷發棒
├─ 可回收物_電子秤
├─ 可回收物_電熨斗
├─ 可回收物_電磁爐
├─ 可回收物_電腦螢屏
├─ 可回收物_電視機
├─ 可回收物_電話
├─ 可回收物_電路板
├─ 可回收物_電風扇
├─ 可回收物_電飯煲
├─ 可回收物_登機牌
├─ 可回收物_盒子
├─ 可回收物_蓋子
├─ 可回收物_盤子
├─ 可回收物_碗
├─ 可回收物_磁鐵
├─ 可回收物_空氣凈化器
├─ 可回收物_空氣加濕器
├─ 可回收物_籠子
├─ 可回收物_箱子
├─ 可回收物_紙制品
├─ 可回收物_紙牌
├─ 可回收物_罐子
├─ 可回收物_網卡
├─ 可回收物_耳套
├─ 可回收物_耳機
├─ 可回收物_衣架
├─ 可回收物_袋子
├─ 可回收物_襪子
├─ 可回收物_裙子
├─ 可回收物_褲子
├─ 可回收物_計算器
├─ 可回收物_訂書機
├─ 可回收物_話筒
├─ 可回收物_豆漿機
├─ 可回收物_路由器
├─ 可回收物_輪胎
├─ 可回收物_過濾網
├─ 可回收物_遙控器
├─ 可回收物_量杯
├─ 可回收物_金屬制品
├─ 可回收物_釘子
├─ 可回收物_鑰匙
├─ 可回收物_鐵絲球
├─ 可回收物_鉛球
├─ 可回收物_鋁制用品
├─ 可回收物_鍋
├─ 可回收物_鍋蓋
├─ 可回收物_鍵盤
├─ 可回收物_鑷子
├─ 可回收物_鬧鈴
├─ 可回收物_雨傘
├─ 可回收物_鞋
├─ 可回收物_音響
├─ 可回收物_餐具
├─ 可回收物_餐墊
├─ 可回收物_飾品
├─ 可回收物_魚缸
├─ 可回收物_滑鼠
├─ 有害垃圾_指甲油
├─ 有害垃圾_殺蟲劑
├─ 有害垃圾_溫度計
├─ 有害垃圾_燈
├─ 有害垃圾_電池
├─ 有害垃圾_電池板
├─ 有害垃圾_紐扣電池
├─ 有害垃圾_膠水
├─ 有害垃圾_藥品包裝
├─ 有害垃圾_藥片
├─ 有害垃圾_藥瓶
├─ 有害垃圾_藥膏
├─ 有害垃圾_蓄電池
└─ 有害垃圾_血壓計
7 關鍵代碼
import tensorflow as tf
import linecache
import cv2
import numpy as np
import os
from select_object import pretreatment_image
train_images_path = 'D:/WorkSpace/Python/trash_classify_dataset/dataset/'
train_labels_path = 'D:/WorkSpace/Python/trash_classify_dataset/train_label.txt'
test_images_path = 'D:/WorkSpace/Python/trash_classify_dataset/dataset/'
test_labels_path = 'D:/WorkSpace/Python/trash_classify_dataset/test_label.txt'
classify_num = 50
train_images_num = 29081
test_images_num = 3232
def load_train_dataset(index): # 從1開始
if index > train_images_num:
if index % train_images_num == 0:
index = train_images_num
else:
index %= train_images_num
line_str = linecache.getline(train_labels_path, index)
image_name, image_label = line_str.split(' ')
image = cv2.imread(train_images_path + image_name)
# cv2.imshow('pic',image)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
return image, image_label
def combine_train_dataset(count, size):
train_images_load = np.zeros(shape=(size, 224, 224, 3))
train_labels_load = np.zeros(shape=(size, classify_num))
for i in range(size):
train_images_load[i], train_labels_index = load_train_dataset(count + i + 1)
train_labels_load[i][int(train_labels_index) - 1] = 1.0
count += size
return train_images_load, train_labels_load, count
def load_test_dataset(index): # 從1開始
if index > test_images_num:
if index % test_images_num == 0:
index = test_images_num
else:
index %= test_images_num
line_str = linecache.getline(test_labels_path, index)
image_name, image_label = line_str.split(' ')
image = cv2.imread(test_images_path + image_name)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = cv2.resize(image, (224, 224))
return image, image_label
def combine_test_dataset(count, size):
test_images_load = np.zeros(shape=(size, 224, 224, 3))
test_labels_load = np.zeros(shape=(size, classify_num))
for i in range(size):
test_images_load[i], test_labels_index = load_test_dataset(count + i + 1)
test_labels_load[i][int(test_labels_index) - 1] = 1.0
count += size
return test_images_load, test_labels_load, count
# # 通過L2正則化防止過擬合
# def weight_variable_with_loss(shape, stddev, lam):
# weight = tf.Variable(tf.truncated_normal(shape, stddev=stddev))
# if lam is not None:
# weight_loss = tf.multiply(tf.nn.l2_loss(weight), lam, name='weight_loss')
# tf.add_to_collection('losses', weight_loss)
# return weight
def weight_variable(shape, n, use_l2, lam):
weight = tf.Variable(tf.truncated_normal(shape, stddev=1 / n))
# L2正則化
if use_l2 is True:
weight_loss = tf.multiply(tf.nn.l2_loss(weight), lam, name='weight_loss')
tf.add_to_collection('losses', weight_loss)
return weight
def bias_variable(shape):
bias = tf.Variable(tf.constant(0.1, shape=shape))
return bias
def conv2d(x, w):
return tf.nn.conv2d(x, w, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='SAME')
# 輸入層
with tf.name_scope('input_layer'):
x_input = tf.placeholder(tf.float32, [None, 224, 224, 3])
y_input = tf.placeholder(tf.float32, [None, classify_num])
keep_prob = tf.placeholder(tf.float32)
is_training = tf.placeholder(tf.bool)
is_use_l2 = tf.placeholder(tf.bool)
lam = tf.placeholder(tf.float32)
learning_rate = tf.placeholder(tf.float32)
# 資料集平均RGB值
mean = tf.constant([159.780, 139.802, 119.047], dtype=tf.float32, shape=[1, 1, 1, 3])
x_input = x_input - mean
# 第一個卷積層 size:224
# 卷積核1[3, 3, 3, 64]
# 卷積核2[3, 3, 64, 64]
with tf.name_scope('conv1_layer'):
w_conv1 = weight_variable([3, 3, 3, 64], 64, use_l2=False, lam=0)
b_conv1 = bias_variable([64])
conv_kernel1 = conv2d(x_input, w_conv1)
bn1 = tf.layers.batch_normalization(conv_kernel1, training=is_training)
conv1 = tf.nn.relu(tf.nn.bias_add(bn1, b_conv1))
w_conv2 = weight_variable([3, 3, 64, 64], 64, use_l2=False, lam=0)
b_conv2 = bias_variable([64])
conv_kernel2 = conv2d(conv1, w_conv2)
bn2 = tf.layers.batch_normalization(conv_kernel2, training=is_training)
conv2 = tf.nn.relu(tf.nn.bias_add(bn2, b_conv2))
pool1 = max_pool_2x2(conv2) # 224*224 -> 112*112
result1 = pool1
# 第二個卷積層 size:112
# 卷積核3[3, 3, 64, 128]
# 卷積核4[3, 3, 128, 128]
with tf.name_scope('conv2_layer'):
w_conv3 = weight_variable([3, 3, 64, 128], 128, use_l2=False, lam=0)
b_conv3 = bias_variable([128])
conv_kernel3 = conv2d(result1, w_conv3)
bn3 = tf.layers.batch_normalization(conv_kernel3, training=is_training)
conv3 = tf.nn.relu(tf.nn.bias_add(bn3, b_conv3))
w_conv4 = weight_variable([3, 3, 128, 128], 128, use_l2=False, lam=0)
b_conv4 = bias_variable([128])
conv_kernel4 = conv2d(conv3, w_conv4)
bn4 = tf.layers.batch_normalization(conv_kernel4, training=is_training)
conv4 = tf.nn.relu(tf.nn.bias_add(bn4, b_conv4))
pool2 = max_pool_2x2(conv4) # 112*112 -> 56*56
result2 = pool2
# 第三個卷積層 size:56
# 卷積核5[3, 3, 128, 256]
# 卷積核6[3, 3, 256, 256]
# 卷積核7[3, 3, 256, 256]
with tf.name_scope('conv3_layer'):
w_conv5 = weight_variable([3, 3, 128, 256], 256, use_l2=False, lam=0)
b_conv5 = bias_variable([256])
conv_kernel5 = conv2d(result2, w_conv5)
bn5 = tf.layers.batch_normalization(conv_kernel5, training=is_training)
conv5 = tf.nn.relu(tf.nn.bias_add(bn5, b_conv5))
w_conv6 = weight_variable([3, 3, 256, 256], 256, use_l2=False, lam=0)
b_conv6 = bias_variable([256])
conv_kernel6 = conv2d(conv5, w_conv6)
bn6 = tf.layers.batch_normalization(conv_kernel6, training=is_training)
conv6 = tf.nn.relu(tf.nn.bias_add(bn6, b_conv6))
w_conv7 = weight_variable([3, 3, 256, 256], 256, use_l2=False, lam=0)
b_conv7 = bias_variable([256])
conv_kernel7 = conv2d(conv6, w_conv7)
bn7 = tf.layers.batch_normalization(conv_kernel7, training=is_training)
conv7 = tf.nn.relu(tf.nn.bias_add(bn7, b_conv7))
pool3 = max_pool_2x2(conv7) # 56*56 -> 28*28
result3 = pool3
# 第四個卷積層 size:28
# 卷積核8[3, 3, 256, 512]
# 卷積核9[3, 3, 512, 512]
# 卷積核10[3, 3, 512, 512]
with tf.name_scope('conv4_layer'):
w_conv8 = weight_variable([3, 3, 256, 512], 512, use_l2=False, lam=0)
b_conv8 = bias_variable([512])
conv_kernel8 = conv2d(result3, w_conv8)
bn8 = tf.layers.batch_normalization(conv_kernel8, training=is_training)
conv8 = tf.nn.relu(tf.nn.bias_add(bn8, b_conv8))
w_conv9 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv9 = bias_variable([512])
conv_kernel9 = conv2d(conv8, w_conv9)
bn9 = tf.layers.batch_normalization(conv_kernel9, training=is_training)
conv9 = tf.nn.relu(tf.nn.bias_add(bn9, b_conv9))
w_conv10 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv10 = bias_variable([512])
conv_kernel10 = conv2d(conv9, w_conv10)
bn10 = tf.layers.batch_normalization(conv_kernel10, training=is_training)
conv10 = tf.nn.relu(tf.nn.bias_add(bn10, b_conv10))
pool4 = max_pool_2x2(conv10) # 28*28 -> 14*14
result4 = pool4
# 第五個卷積層 size:14
# 卷積核11[3, 3, 512, 512]
# 卷積核12[3, 3, 512, 512]
# 卷積核13[3, 3, 512, 512]
with tf.name_scope('conv5_layer'):
w_conv11 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv11 = bias_variable([512])
conv_kernel11 = conv2d(result4, w_conv11)
bn11 = tf.layers.batch_normalization(conv_kernel11, training=is_training)
conv11 = tf.nn.relu(tf.nn.bias_add(bn11, b_conv11))
w_conv12 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv12 = bias_variable([512])
conv_kernel12 = conv2d(conv11, w_conv12)
bn12 = tf.layers.batch_normalization(conv_kernel12, training=is_training)
conv12 = tf.nn.relu(tf.nn.bias_add(bn12, b_conv12))
w_conv13 = weight_variable([3, 3, 512, 512], 512, use_l2=False, lam=0)
b_conv13 = bias_variable([512])
conv_kernel13 = conv2d(conv12, w_conv13)
bn13 = tf.layers.batch_normalization(conv_kernel13, training=is_training)
conv13 = tf.nn.relu(tf.nn.bias_add(bn13, b_conv13))
pool5 = max_pool_2x2(conv13) # 14*14 -> 7*7
result5 = pool5
# 第一個全連接層 size:7
# 隱藏層節點數 4096
with tf.name_scope('fc1_layer'):
w_fc14 = weight_variable([7 * 7 * 512, 4096], 4096, use_l2=is_use_l2, lam=lam)
b_fc14 = bias_variable([4096])
result5_flat = tf.reshape(result5, [-1, 7 * 7 * 512])
fc14 = tf.nn.relu(tf.nn.bias_add(tf.matmul(result5_flat, w_fc14), b_fc14))
# result6 = fc14
result6 = tf.nn.dropout(fc14, keep_prob)
# 第二個全連接層
# 隱藏層節點數 4096
with tf.name_scope('fc2_layer'):
w_fc15 = weight_variable([4096, 4096], 4096, use_l2=is_use_l2, lam=lam)
b_fc15 = bias_variable([4096])
fc15 = tf.nn.relu(tf.nn.bias_add(tf.matmul(result6, w_fc15), b_fc15))
# result7 = fc15
result7 = tf.nn.dropout(fc15, keep_prob)
# 輸出層
with tf.name_scope('output_layer'):
w_fc16 = weight_variable([4096, classify_num], classify_num, use_l2=is_use_l2, lam=lam)
b_fc16 = bias_variable([classify_num])
fc16 = tf.matmul(result7, w_fc16) + b_fc16
logits = tf.nn.softmax(fc16)
# 損失函式
with tf.name_scope('loss'):
cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(logits=fc16, labels=y_input)
cross_entropy_mean = tf.reduce_mean(cross_entropy)
tf.add_to_collection('losses', cross_entropy_mean)
loss = tf.add_n(tf.get_collection('losses'))
tf.summary.scalar('loss', loss)
# 訓練函式
with tf.name_scope('train'):
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops): # 保證train_op在update_ops執行之后再執行,
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
# 計算準確率
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(logits, 1), tf.argmax(y_input, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 會話初始化
# sess = tf.InteractiveSession()
# tf.global_variables_initializer().run()
saver = tf.train.Saver()
save_dir = "classify_modles"
checkpoint_name = "train.ckpt"
merged = tf.summary.merge_all() # 將圖形、訓練程序等資料合并在一起
# writer_train = tf.summary.FileWriter('logs/train', sess.graph) # 將訓練日志寫入到logs檔案夾下
# writer_test = tf.summary.FileWriter('logs/test', sess.graph) # 將訓練日志寫入到logs檔案夾下
# 變數初始化
training_steps = 25000
display_step = 10
batch_size = 20
train_images_count = 0
test_images_count = 0
train_avg_accuracy = 0
test_avg_accuracy = 0
# # 訓練
# print("Training start...")
#
# # # 模型恢復
# # sess = tf.InteractiveSession()
# # saver.restore(sess, os.path.join(save_dir, checkpoint_name))
# # print("Model restore success!")
#
# for step in range(training_steps):
# train_images, train_labels, train_images_count = combine_train_dataset(train_images_count, batch_size)
# test_images, test_labels, test_images_count = combine_test_dataset(test_images_count, batch_size)
#
# # 訓練
# if step < 10000:
# train_step.run(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 0.8, is_training: True, is_use_l2: True,
# learning_rate: 0.0001, lam: 0.004})
# elif step < 20000:
# train_step.run(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 0.8, is_training: True, is_use_l2: True,
# learning_rate: 0.0001, lam: 0.001})
# else:
# train_step.run(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 0.8, is_training: True, is_use_l2: True,
# learning_rate: 0.00001, lam: 0.001})
#
# # 每訓練10步,輸出顯示訓練程序
# if step % display_step == 0:
# train_accuracy = accuracy.eval(
# feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 1.0, is_training: False,
# is_use_l2: False})
# train_loss = sess.run(loss, feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 1.0,
# is_training: False, is_use_l2: False})
# train_result = sess.run(tf.argmax(logits, 1),
# feed_dict={x_input: train_images, keep_prob: 1.0, is_training: False, is_use_l2: False})
# train_label = sess.run(tf.argmax(y_input, 1), feed_dict={y_input: train_labels})
#
# test_accuracy = accuracy.eval(
# feed_dict={x_input: test_images, y_input: test_labels, keep_prob: 1.0, is_training: False,
# is_use_l2: False})
# test_result = sess.run(tf.argmax(logits, 1),
# feed_dict={x_input: test_images, keep_prob: 1.0, is_training: False, is_use_l2: False})
# test_label = sess.run(tf.argmax(y_input, 1), feed_dict={y_input: test_labels})
#
# print("Training dataset:")
# print(train_result)
# print(train_label)
# print("Testing dataset:")
# print(test_result)
# print(test_label)
#
# print("step {}\n training accuracy {}\n loss {}\n testing accuracy {}\n".format(step, train_accuracy, train_loss, test_accuracy))
# train_avg_accuracy += train_accuracy
# test_avg_accuracy += test_accuracy
# result_train = sess.run(merged, feed_dict={x_input: train_images, y_input: train_labels, keep_prob: 1.0,
# is_training: False, is_use_l2: False}) # 計算需要寫入的日志資料
# writer_train.add_summary(result_train, step) # 將日志資料寫入檔案
#
# result_test = sess.run(merged, feed_dict={x_input: test_images, y_input: test_labels, keep_prob: 1.0,
# is_training: False, is_use_l2: False}) # 計算需要寫入的日志資料
# writer_test.add_summary(result_test, step) # 將日志資料寫入檔案
#
# # 每訓練100步,顯示輸出訓練平均準確度,保存模型
# if step % (display_step * 10) == 0 and step != 0:
# print("train_avg_accuracy {}".format(train_avg_accuracy / 10))
# train_avg_accuracy = 0
# print("test_avg_accuracy {}".format(test_avg_accuracy / 10))
# test_avg_accuracy = 0
#
# saver.save(sess, os.path.join(save_dir, checkpoint_name))
# print("Model save success!\n")
#
# print("Training finish...")
#
# # 模型保存
# saver.save(sess, os.path.join(save_dir, checkpoint_name))
# print("\nModel save success!")
#
# # print("\nTesting start...")
# # avg_accuracy = 0
# # for i in range(int(test_images_num / 30) + 1):
# # test_images, test_labels, test_images_count = combine_test_dataset(test_images_count, 30)
# # test_accuracy = accuracy.eval(
# # feed_dict={x_input: test_images, y_input: test_labels, keep_prob: 1.0, is_training: False, is_use_l2: False})
# # test_result = sess.run(tf.argmax(logits, 1),
# # feed_dict={x_input: test_images, keep_prob: 1.0, is_training: False, is_use_l2: False})
# # test_label = sess.run(tf.argmax(y_input, 1), feed_dict={y_input: test_labels})
# # print(test_result)
# # print(test_label)
# # print("test accuracy {}".format(test_accuracy))
# # avg_accuracy += test_accuracy
# #
# # print("\ntest_avg_accuracy {}".format(avg_accuracy / (int(test_images_num / 30) + 1)))
#
# sess.close()
# 識別
# 模型恢復
sess = tf.InteractiveSession()
saver.restore(sess, os.path.join(save_dir, checkpoint_name))
print("Model restore success!")
def predict_img(img_path):
img = cv2.imread(img_path)
image = np.reshape(img, [1, 224, 224, 3])
classify_result = sess.run(tf.argmax(logits, 1),
feed_dict={x_input: image, keep_prob: 1.0, is_training: False, is_use_l2: False})
probability = sess.run(logits, feed_dict={x_input: image, keep_prob: 1.0, is_training: False,
is_use_l2: False}).flatten().tolist()[
classify_result[0]]
return classify_result[0], probability
def trash_classify(img_path, img_name, upload_path):
img_name = img_name.rsplit('.', 1)[0]
# print(img_name)
pretrian_img_path, selected_img_path = pretreatment_image(img_path, img_name, upload_path)
predict_result, predict_probability = predict_img(pretrian_img_path)
return predict_result, predict_probability
8 最后-畢設幫助
畢設幫助,開題指導,技術解答
🇶746876041

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384132.html
標籤:AI
上一篇:一圖讀懂知識圖譜