線性回歸:
- 最小二乘法:
- 從概率角度來看
- 線性回歸正則化(L1,L2)
首先我們來看一個資料:
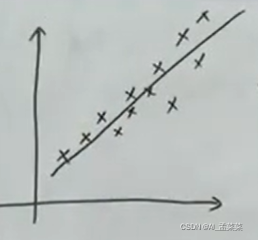
有這么一組樣本點,線性回歸就是找出一條擬合樣本點的線,
樣本:
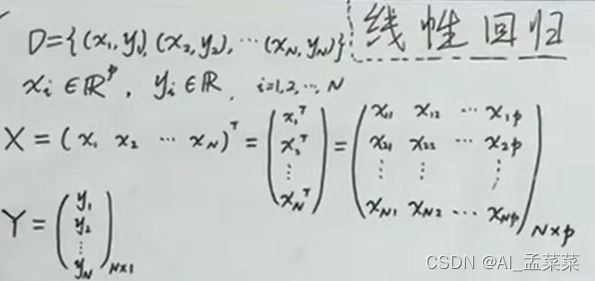
一般我們說線性回歸的運算式:
Y = wTX + b
最小二乘推導:

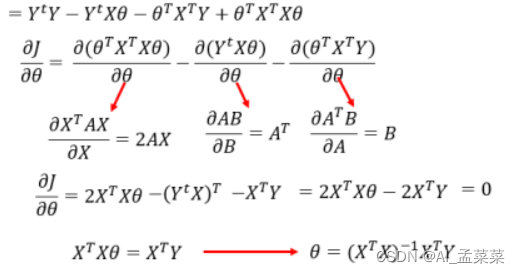
當然我們直接看結果發現有求逆的程序,但是在現實生活中我們會發現也有矩陣不可逆的情況,因此我們要引入正則化,從矩陣的角度來說,解決矩陣不可逆,從模型來說,為了防止過擬合,例如一個樣本點,p維的一個資料,那么那是不是有無數條擬合的直線,因此很容易就陷入了過擬合,
解決過擬合的方法:1.增加資料,2.降維(特征選擇,特征提取)3.正則化
正則化其實就是對代價函式加上一個約束:
L(w)【loss】 + λP(w)【懲罰項】
L1 :lasso :p(w)=||w||1 L1范數
L2 :ridge(嶺回歸) :p(w)= ||w||2 L2范數
L2正則化為什么可以防止過擬合并且矩陣求逆?
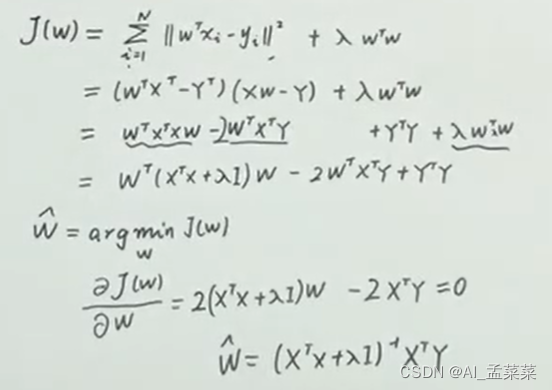
我們觀察嶺回歸的出來的決議解,是不是多了一個λI(對角矩陣),半正定矩陣+對角矩陣就一定是一個可逆的矩陣,
中心極限定理:
給定一個任意的分布,從中抽取m次,每次抽取n個樣本,然后把這些m組樣本求平均值,這些平均值是接近正態分布的,
回歸問題的評估方法:

MSE均方誤差方法:mean_squared_error
計算每一個樣本得預測值和真實值之間得差得平方,然后求和再平均
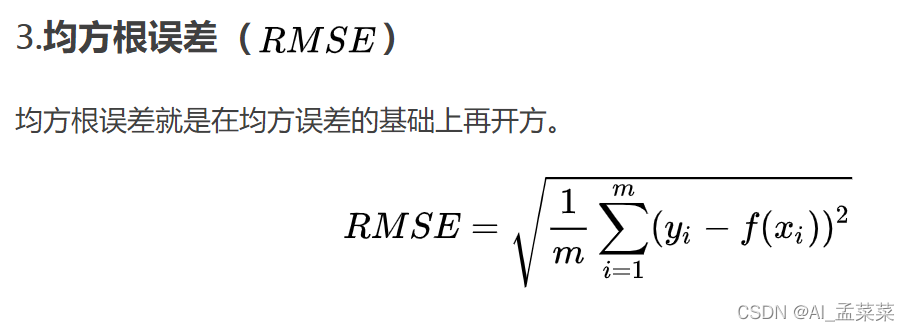

方法:mean_absolute_error

方法:r2_score()
1.![]() ,
, ![]() ,
, ![]() 可以準確的計算出預測結果和真實的結果的誤差大小,但卻無法衡量模型的好壞程度,但是這些指標可以指導我們的模型改進作業,如調參,特征選擇等,
可以準確的計算出預測結果和真實的結果的誤差大小,但卻無法衡量模型的好壞程度,但是這些指標可以指導我們的模型改進作業,如調參,特征選擇等,
2.![]() 的結果可以很清楚的說明模型的好壞,該值越接近于1,表明模型的效果越好,該值越接近于0,表明模型的效果越差,
的結果可以很清楚的說明模型的好壞,該值越接近于1,表明模型的效果越好,該值越接近于0,表明模型的效果越差,
多項式回歸:
多項式回歸是線性回歸的一種擴展,它可以使我們對非線性關系進行建模,線性回歸使用直線來擬合資料,如一次函式y = k x + b等,而多項式回歸則使用曲線來擬合資料,如二次函式y=ax^2+bx+c,三次函式y=ax^3+bx^2+cx+d,
多項式回歸得作用:
有時直線難以擬合全部的資料,需要曲線來適應資料,如二次模型、三次模型等等,
次數的選擇:
多項式函式有多種,一般來說,需要先觀察資料的形狀,再去決定選用什么形式的多項式函式來處理問題,比如,從資料的散點圖觀察,如果有一個“彎”,就可以考慮用二次多項式;有兩個“彎”,可以考慮用三次多項式;有三個“彎”,則考慮用四次多項式,以此類推,
雖然真實的回歸函式不一定是某個次數的多項式,但只要擬合的好,用適當的多項式來近似模擬真實的回歸函式是可行的,
Pipline包,PolynomialFeatures包,StandardScaler包
歸一化:
作用:
- 歸一化后加快了梯度下降求最優解的速度;
- 歸一化有可能提高精度;
標準差標準化(standardScale)使得經過處理的資料符合標準正態分布,即均值為0,標準差為1,其轉化函式為:
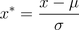
其中μ為所有樣本資料的均值,σ為所有樣本資料的標準差,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384135.html
標籤:AI