transforms用法介紹
?torchvision.transforms模塊主要用于對影像進行轉換等一系列預處理操作,其主要目的是對影像資料進行增強,進而提高模型的泛化能力,對影像預處理操作有資料中心化,縮放,裁剪,旋轉,翻轉,填充,添加噪聲,灰度變換,線性變換,仿射變換,亮度,飽和度,對比變換等,
transforms.Compose
?transforms.Compose是將一系列的影像轉換函式進行組合,實作時能夠按照這些函式的順序依次去影像進行處理操作,需要注意的是同樣的功能也可以用torch.nn.Sequential函式來實作,
CLASS torchvision.transforms.Compose(transforms)
- transforms:表示影像變換組合的列
transforms.Compose具體實體的代碼如下所示
transform_train = transforms.Compose([
transforms.RandomCrop(cut_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
])
transform_train = torch.nn.Sequential(
transforms.RandomCrop(cut_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
)
transform_test = transforms.Compose([
transforms.TenCrop(cut_size),
transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])),
])
transform_test = torch.nn.Sequential(
transforms.TenCrop(cut_size),
transforms.Lambda(lambda crops: torch.stack([transforms.ToTensor()(crop) for crop in crops])),
)
transforms.ToTensor
?transforms.ToTensor的作用是將一個PIL Image格式的圖片或者是取值范圍為 [ 0 , 255 ] [0,255] [0,255],形狀為 [ H × W × C ] [\mathrm{H} \times \mathrm{W} \times \mathrm{C}] [H×W×C]numpy.ndarray的陣列轉換為取值范圍為 [ 0.0 , 1.0 ] [0.0,1.0] [0.0,1.0],形狀為 [ C × H × W ] [\mathrm{C}\times \mathrm{H}\times \mathrm{W}] [C×H×W]的tensor格式圖片,
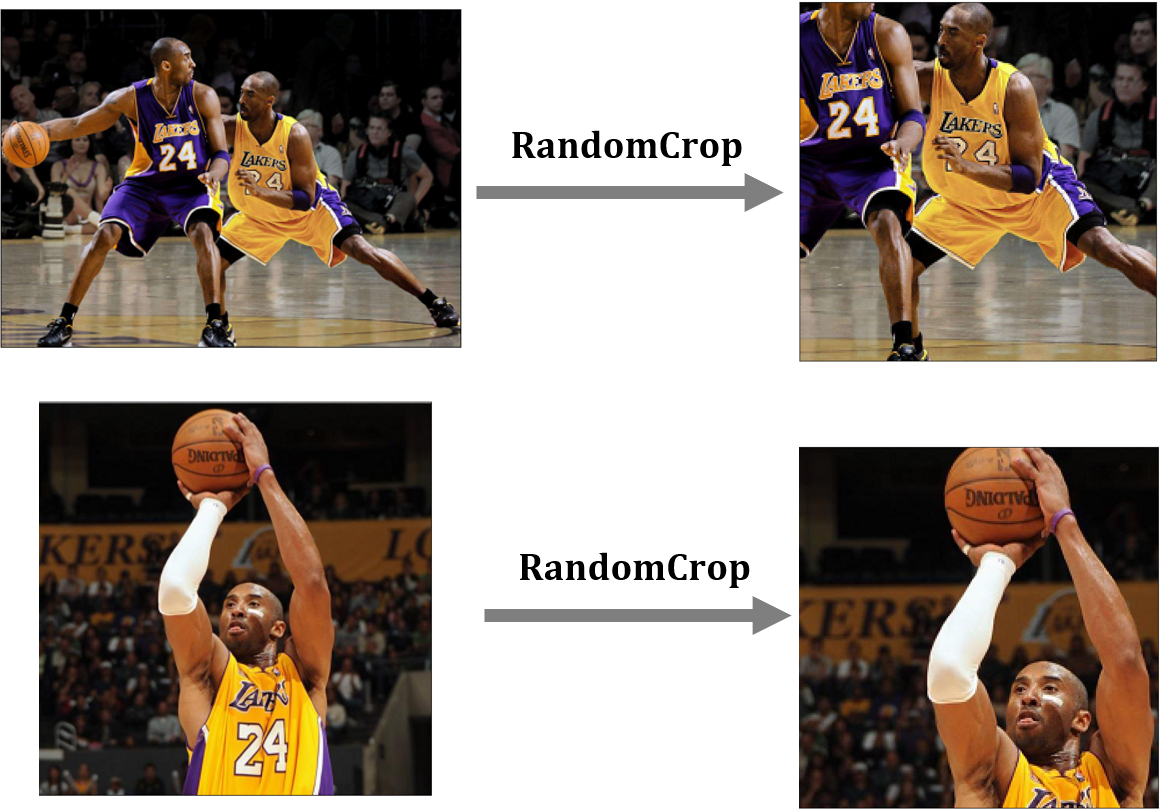
transforms.RandomCrop
?transforms.RandomCrop的作用是在圖片的隨機位置上進行裁剪并回傳新的圖片,
CLASS torchvision.transforms.RandomCrop(size, padding=None, pad_if_needed=False, fill=0, padding_mode=‘constant’)
- size:表示裁剪圖片的輸出尺寸,如果引數是一個整數則裁剪的是一個正方形
- padding:表示影像每個邊框上的可選填充,默認值是None
- pad_if_needed:如果影像小于所需大小,它將填充影像,以避免引發例外
- fill:表示像素填充值,默認值為0,如果元組長度為3,則用于分別填充R、G、B通道
- padding_mode:表示像素填充值的型別,默認是常值,也有邊緣填充,反射和對稱
transforms.RandomCrop具體實體的代碼實作和對應的可視化圖如下所示
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision.transforms as T
from torchvision.io import read_image
plt.rcParams["savefig.bbox"] = 'tight'
torch.manual_seed(1)
def show(imgs):
fix, axs = plt.subplots(ncols=len(imgs), squeeze=False)
for i, img in enumerate(imgs):
img = T.ToPILImage()(img.to('cpu'))
axs[0, i].imshow(np.asarray(img))
axs[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
plt.show()
img1 = read_image(str(Path('assets') / 'KOBE1.png'))
img2 = read_image(str(Path('assets') / 'KOBE2.png'))
show([img1, img2])
transforms = T.Compose([
T.RandomCrop(224),
])
# transforms = torch.nn.Sequential(
# T.RandomCrop(224),
# )
device = 'cuda' if torch.cuda.is_available() else 'cpu'
img1 = img1.to(device)
img2 = img2.to(device)
transformed_img1 = transforms(img1)
transformed_img2 = transforms(img2)
show([transformed_img1, transformed_img2])
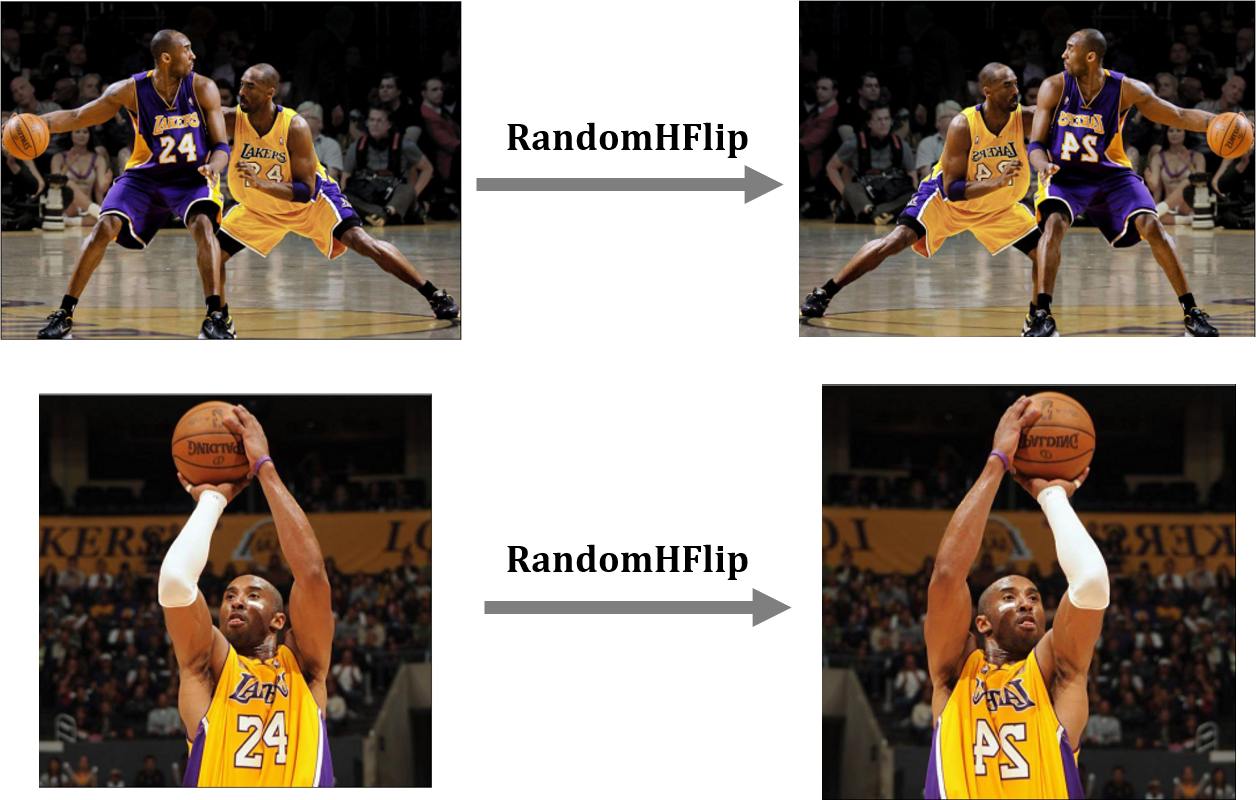
transforms.RandomHorizontalFlip
?transforms.RandomHorizontalFlip的作用是以特定的概率將圖片進行水平翻轉,
CLASS torchvision.transforms.RandomHorizontalFlip(p=0.5)
- p:表示圖片水平翻轉的概率,默認值是0.5
transforms.RandomHorizontalFlip具體實體的代碼實作和對應的可視化圖如下所示
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision.transforms as T
from torchvision.io import read_image
plt.rcParams["savefig.bbox"] = 'tight'
torch.manual_seed(1)
def show(imgs):
fix, axs = plt.subplots(ncols=len(imgs), squeeze=False)
for i, img in enumerate(imgs):
img = T.ToPILImage()(img.to('cpu'))
axs[0, i].imshow(np.asarray(img))
axs[0, i].set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
plt.show()
img1 = read_image(str(Path('assets') / 'KOBE1.png')) # type : torch
img2 = read_image(str(Path('assets') / 'KOBE2.png')) # type : torch
show([img1, img2])
transforms = T.Compose([
T.RandomHorizontalFlip(p=0.9),
])
# transforms = torch.nn.Sequential(
# T.RandomHorizontalFlip(p=0.3),
# )
device = 'cuda' if torch.cuda.is_available() else 'cpu'
img1 = img1.to(device)
img2 = img2.to(device)
transformed_img1 = transforms(img1)
transformed_img2 = transforms(img2)
show([transformed_img1, transformed_img2])
transforms.TenCrop
?transforms.RandomCrop的作用是可以將一張圖片的四個角和中心進行裁剪后,然后加上回傳的翻轉后共10張圖片,其中默認翻轉是水平翻轉,
CLASS torchvision.transforms.TenCrop(size, vertical_flip=False)
- size:表示裁剪圖片的輸出尺寸,如果引數是一個整數則裁剪的是一個正方形
- vertical_flip:表示圖片是否用垂直翻轉代替水平翻轉None
需要注意的是transforms.TenCrop函式的輸入必須是 P I L \mathrm{PIL} PIL的圖片格式,具體實體的代碼實作和對應的可視化圖如下所示
from PIL import Image
from pathlib import Path
import matplotlib.pyplot as plt
import numpy as np
import torch
import torchvision.transforms as T
plt.rcParams["savefig.bbox"] = 'tight'
torch.manual_seed(0)
def plot(imgs, with_orig=True, row_title=None, **imshow_kwargs):
if not isinstance(imgs[0], list):
# Make a 2d grid even if there's just 1 row
imgs = [imgs]
num_rows = len(imgs)
num_cols = len(imgs[0]) + with_orig
fig, axs = plt.subplots(nrows=num_rows, ncols=num_cols, squeeze=False)
for row_idx, row in enumerate(imgs):
row = [orig_img] + row if with_orig else row
for col_idx, img in enumerate(row):
ax = axs[row_idx, col_idx]
ax.imshow(np.asarray(img), **imshow_kwargs)
ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
if with_orig:
axs[0, 0].set(title='Original image')
axs[0, 0].title.set_size(8)
if row_title is not None:
for row_idx in range(num_rows):
axs[row_idx, 0].set(ylabel=row_title[row_idx])
plt.tight_layout()
plt.show()
orig_img = Image.open(Path('assets') / 'KOBE1.png') # tyep : PIL
(top_left, top_right, bottom_left, bottom_right, center,
flip_top_left, flip_top_right, flip_bottom_left, flip_bottom_right, flip_center) = T.TenCrop(size=(200,200))(orig_img)
plot([[top_left, top_right, bottom_left, bottom_right, center],
[flip_top_left, flip_top_right, flip_bottom_left, flip_bottom_right, flip_center]],with_orig=False)

格外需要注意transforms.TenCrop對于每張圖片會回傳10張變換后的圖片,尤其是在測驗階段會導致圖片數量和標簽數量不匹配,可以進行如下處理
transform = Compose([
FiveCrop(size), # this is a list of PIL Images
Lambda(lambda crops: torch.stack([ToTensor()(crop) for crop in crops])) # returns a 4D tensor
])
#In your test loop you can do the following:
input, target = batch # input is a 5d tensor, target is 2d
bs, ncrops, c, h, w = input.size()
result = model(input.view(-1, c, h, w)) # fuse batch size and ncrops
result_avg = result.view(bs, ncrops, -1).mean(1) # avg over crops
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384136.html
標籤:AI