文章目錄
- 1. 初識kafka框架
- 高吞吐量/低延時
- 訊息持久化
- 負載均衡和故障轉移
- 伸縮性
- 2. kafka單節點使用
- 2.1 搭建環境
- 2.2 topic 主題
- 2.3 生產/消費訊息
- 2.3.1 單播消費
- 2.3.2 多播消費
- 2.3.3 消費組資訊
- 2.4 TOPIC概念
- 2.5. 訊息設計
- 2.6 replica副本
- 2.7 kafka的使用場景
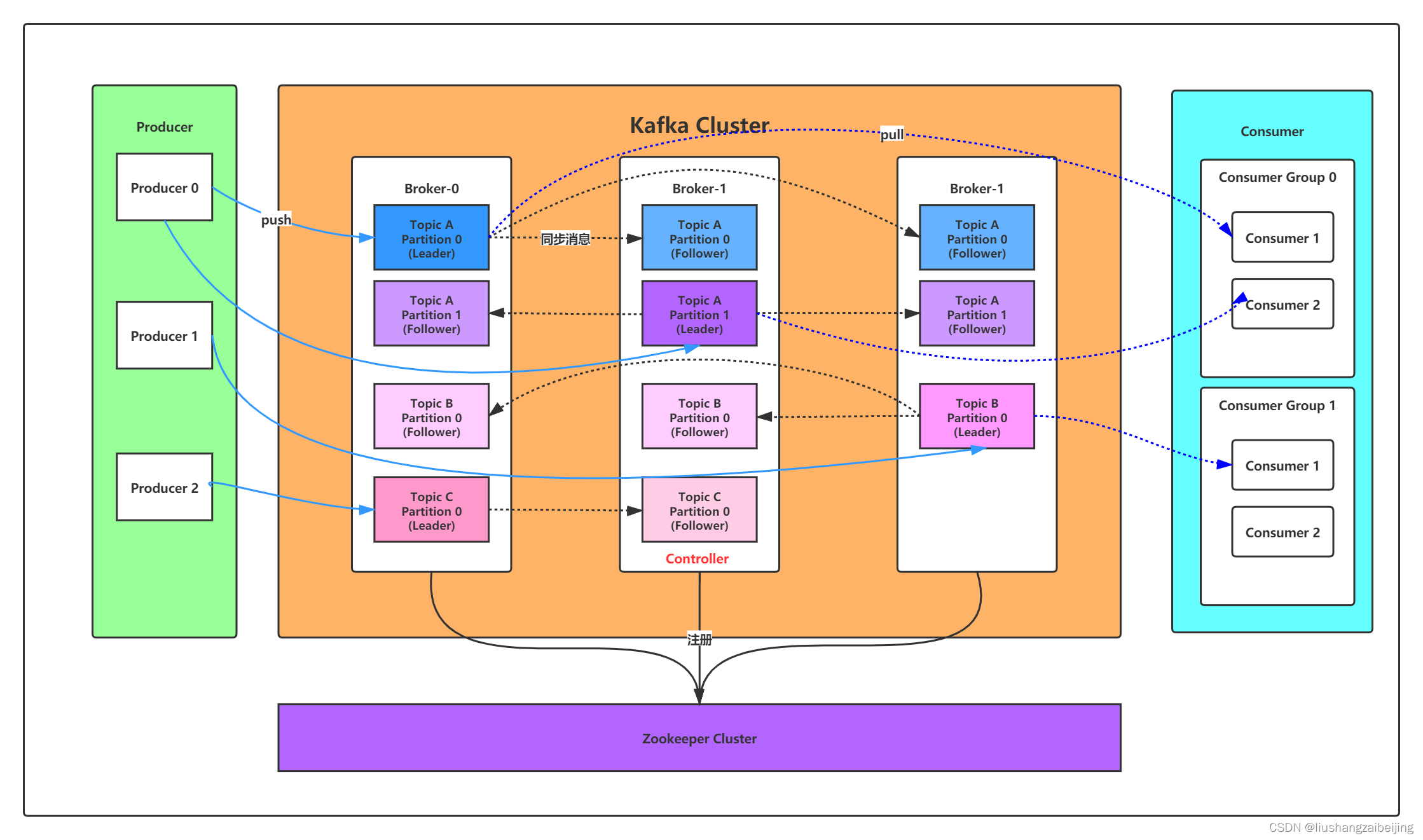
- 3. kafka集群使用
- 3.1 集群搭建
- 3.2 kafka集群特性
- kafka的容錯性
- kafka集群資料同步流程
- kafka集群情況下的消費順序
1. 初識kafka框架
? kafka是一個分布式、支持磁區的(partition)、多副本的(replica),基于zookeeper協調的分布式訊息系統(所謂訊息系統:用于在不同應用之間傳輸資料的訊息引擎系統),
其設定初衷是為了解決互聯網公司超大量級資料的實時傳輸,其具備如下能力
- 高吞吐量/低延時
- 訊息持久化
- 負載均衡和故障轉移
- 伸縮性
高吞吐量/低延時
-
kafka訊息持久化大量使用頁快取,讀寫訊息大概率可以命中作業系統頁快取(此處需要明晰:kafka的訊息持久化是直接追加到磁盤上的(磁盤為了存盤快捷使用了頁快取))
-
kafka不直接參與物理IO,而是由作業系統進行操作
-
寫訊息采用追加的方式,使用了磁盤順序寫(避免了磁盤隨機寫性能慢的問題)
-
讀訊息使用了liunx的sendfile的零拷貝技術
訊息持久化
? kafka框架設計的時候和別的mq框架不同,別的mq框架對于訊息先使用快取(記憶體),在一定時機再將快取持久化到磁盤,而是一反常態直接使用追加寫>(利用了磁盤的屬性寫和記憶體寫性能相同的場景), kafka訊息持久化是直接持久化到磁盤(順序寫),并沒有采用先快取到記憶體進而持久化到磁盤,因為順序寫到磁盤的速度和記憶體隨機寫的速度相當,
負載均衡和故障轉移
? kafka實作負載均衡是通過磁區領導者選舉(partition leader election)來實作的,使得機器上以均等的機會分散各個partition的leader從而整體上實作負載均衡,
? kafka實作故障轉移使用所有服務節點都會以會話的形式將自己注冊到zk上,服務器出現宕機情況則會出現會話超時失效,此時kafka集群會選舉出新的機器來提供服務,
伸縮性
? 伸縮性是指向某個分布式系統添加(伸)和去除(縮)服務資源從而動態改變其吞吐量的能力,阻礙線性擴容的常見因素之一是服務節點之間狀態的保存,服務器之間需要保存很多內部狀態,自己保存的化需要處理之間的資料一致性問題,如果服務無狀態(少量狀態)則狀態管理可以交給分布式協調服務(比如zk)來處理,進而可以很容易的擴縮容(啟動新節點、下線節點)等,
而kafka就是使用zk來保管其服務節點狀態(也并非使用zk來保管其所有狀態,kafka節點還會自己保存少量狀態),
適用于如下需求場景:
- 基于hadoop的批處理系統、
- 低延遲的實時系統、
- Storm/Spark流式處理引擎,
- 監控日志收集
- 訊息服務
設計一個訊息系統需要關注兩方面因素:
- 訊息體的設計:常見的訊息體格式有xml,json、二進制等
- 傳輸協議的設計:常見的訊息傳輸有兩種形式 訊息佇列形式、發布/訂閱模式
kafka采用的訊息體是二進制的形式,傳輸協議是基于發布/訂閱
2. kafka單節點使用
2.1 搭建環境
? 說明:此處kafka的版本是2.10版本,所有環境搭建和使用均基于該版本進行(其他版本可能會命令會有不同,其他版本自行百度)
#kafka是使用scala語言開發(運行在jvm上) 需要確保環境安裝了jdk
#同時需要確保安裝了zk (kafka需要注冊到zk上使用)
#1、下載kafka kafka_2.11-2.10.tgz 2.11是scala版本 2.10是kafka的版本
wget https://archive.apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.tgz
#2、解壓檔案
tar -zxvf /home/kafka_2.12-3.0.0.tgz -C /usr/local/
#3、 啟動kafka,運行日志在logs目錄的server.log檔案里
#后臺啟動,不會列印日志到控制臺
./bin/kafka-server-start.sh -daemon config/server.properties
#或者用
bin/kafka-server-start.sh config/server.properties &
# 我們進入zookeeper目錄通過zookeeper客戶端查看下zookeeper的目錄樹
bin/zkCli.sh
#查看zk的根目錄kafka相關節點
ls /brokers/ids #查看kafka節點
[zk: localhost:2181(CONNECTED) 5] ls /brokers/ids
[0] #顯示出現brokers id為0的節點已經在zk上創建(與我們server.properties配置的brokers.id=0一致)
#4、停止kafka
bin/kafka-server-stop.sh
出現問題:
啟動kafka 因為分配記憶體報錯(學習使用的是阿里云 運行總記憶體1G ),因為kafka中啟動腳本默認分配記憶體大小為1G所以報記憶體分配不足的錯誤

需要調整kafka-server-start-sh中的啟動命令,調整后如下:

server.properties核心配置詳解:
| Property | Default | Description |
|---|---|---|
| broker.id | 0 | 每個broker都可以用一個唯一的非負整數id進行標識;這個id可以作為broker的“名字”,你可以選擇任意你喜歡的數字作為id,只要id是唯一的即可, |
| log.dirs | /tmp/kafka-logs | kafka存放資料的路徑,這個路徑并不是唯一的,可以是多個,路徑之間只需要使用逗號分隔即可;每當創建新partition時,都會選擇在包含最少partitions的路徑下進行, |
| listeners | PLAINTEXT://ip:9092 | server接受客戶端連接的埠,ip配置kafka本機ip即可 |
| zookeeper.connect | localhost:2181 | zooKeeper連接字串的格式為:hostname:port,此處hostname和port分別是ZooKeeper集群中某個節點的host和port;zookeeper如果是集群,連接方式為 hostname1:port1, hostname2:port2, hostname3:port3 |
| log.retention.hours | 168 | 每個日志檔案洗掉之前保存的時間,默認資料保存時間對所有topic都一樣, |
| num.partitions | 1 | 創建topic的默認磁區數 |
| default.replication.factor | 1 | 自動創建topic的默認副本數量,建議設定為大于等于2 |
| min.insync.replicas | 1 | 當producer設定acks為-1時,min.insync.replicas指定replicas的最小數目(必須確認每一個repica的寫資料都是成功的),如果這個數目沒有達到,producer發送訊息會產生例外 |
| delete.topic.enable | false | 是否允許洗掉主題 |
2.2 topic 主題
#一、 2.2之前的版本 Kafka 使用如下明細
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 1 --partitions 1 --topic test
#二、 查看kafka存在的topic
bin/kafka-topics.sh --list --zookeeper 127.0.0.1:2181
#三、 洗掉topic
bin/kafka-topics.sh --delete --topic test --zookeeper 127.0.0.1:2181
創建topic

查看topic

2.3 生產/消費訊息
# 開啟生產者 以命令列的方式
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic test
# 訂閱topic中最新的訊息
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --topic test
# 消費(訂閱)topic中所有訊息
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic test
#消費多個主題
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --whitelist "test|test-2"
2.3.1 單播消費
? 單播消費是多個消費者只有一個消費成功,類似于佇列queue形式,只需讓所有消費者在同一個消費組里即可
# 創建多個消費者時候使用--consumer-property group.id=${消費組標識} 設定同一個消費組
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --consumer-property group.id=testGroup --topic test
2.3.2 多播消費
一條訊息能被多個消費者消費的模式,類似publish-subscribe模式費,針對Kafka同一條訊息只能被同一個消費組下的某一個消費者消費的特性,要實作多播只要保證這些消費者屬于不同的消費組即可,
# 創建多個消費者時候使用--consumer-property group.id=${消費組標識} 設定同一個消費組
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --consumer-property group.id=testGroup2 --topic test
#查看訊息分組
bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --list
2.3.3 消費組資訊
#查看消費組詳情資訊
bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --describe --group testGroup

| 屬性 | 說明 |
|---|---|
| TOPIC | 該消費組需要消費的主題(topic) |
| PARTITION | 該消費組需要消費的磁區 Kafka中的一個topic出于性能考慮每個kafka的topic都有若干個partition組成,kafka的Partition實際上沒有太多的業務含義,它的引入就是單純地為了提升系統的吞吐量 |
| CURRENT-OFFSET | 當前消費組的已消費偏移量 |
| LOG_END_OFFSET | 主題對應磁區訊息的結束偏移量(HW) |
| LAG | 當前消費組未消費的訊息數 |
| CONSUMER-ID | 消費者id |
2.4 TOPIC概念
# 查看topic資訊
bin/kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic test1
# 增加topic的磁區資訊
bin/kafka-topics.sh -alter --partitions 3 --zookeeper 127.0.0.1:2181 --topic test

第一行是所有磁區的概要資訊,之后的每一行表示每一個partition的資訊,
- leader節點負責給定partition的所有讀寫請求,
- replicas 表示某個partition在哪幾個broker上存在備份,不管這個幾點是不是”leader“,甚至這個節點掛了,也會列出,
- isr 是replicas的一個子集,它只列出當前還存活著的,并且已同步備份了該partition的節點,
-
Topic: 是一個類別的名稱,同類訊息發送到同一個Topic下面,為了提高系統吞吐量(并行度)topic下分為多個多個磁區(Partition)日志檔案
-
Partition: 磁區(物理概念),topic內部劃分多個partition來分片存盤資料,不同的partition可以位于不同的機器上進行分布式存盤,磁區對應一個commit log檔案(.log結尾的檔案),里面包含有序的message序列,
-
message: kakfa中的訊息 每個訊息都有一個唯一的編號,稱之為offset,用來唯一標示某個磁區中的message,每個consumer是基于自己在commit log中的消費進度(offset)來進行作業的,在kafka中消費offset由consumer自己來維護,通過指定offset可以來重復消費或者跳過某些訊息,
2.5. 訊息設計
? kafka的訊息格式的設計采用如下
-
CRC (4B)
-
version (1B)
-
版本號
-
屬性(1B)保存訊息的壓縮型別
-
時間戳(8B)
-
key的長度 (4B)
-
key (位元組不固定)
-
value長度
-
value值(訊息值)
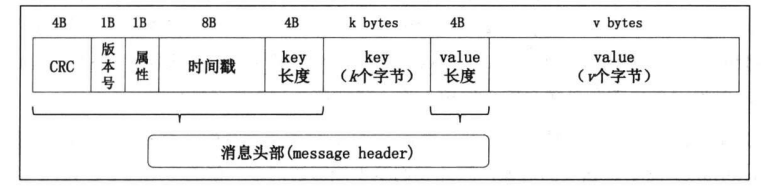
同時該訊息體使用緊湊的二進制陣列來避免存盤空間的浪費,
2.6 replica副本
? 創建topic的時候可以通過修改replica的數量備份多份保證資料的可靠性,同時多個副本一定是保存在不同的broker上的但是只有leader對應的broker的副本是負責回應訊息寫入和消費的,flower對應的副本是有主leader宕機的時候被選舉為主的broker才會進行處理訊息寫入和消費,
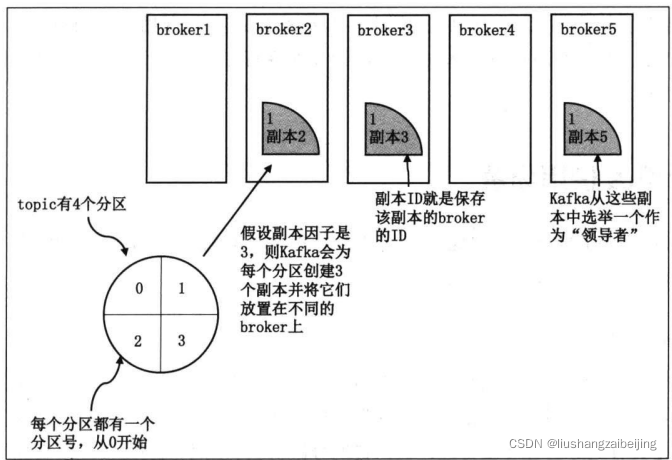
- kafka為partition動態維護了一個replica集合叫做ISR(in-sync replica)與leader 的保持同步的replica集合,只有isr中的所有replica都收到訊息,kafka才將該訊息置為已提交的狀態,訊息才能不丟失,
- kafka會將isr中與leader的replica資料落后太多的replica自動剔除,如果剔除的replica資料重新‘追上’主 則會被自動的加入,
2.7 kafka的使用場景
訊息佇列
? kafka是以訊息引擎聞名,所有可以當做mq來進行解耦生產者和消費者和批量處理訊息,kafka的高吞吐量、磁區和副本機制保證了訊息傳輸的可靠性和高容錯性,為實作一個大資料量的訊息處理應用提供了很好的基礎,
日志收集
- 網站行為日志追蹤 很多網站的用戶點擊操點擊流資料量很大使用高吞吐性能的kafkak收集資訊后續進行資料處理或者機器學習分析用戶行為,
- 審計資料日志收集
- 分布式日志收集
流式處理
kafka推出了一個流式處理框架 kafka stream 可以用來像spark stream、apache flink一樣處理流式資料,
3. kafka集群使用
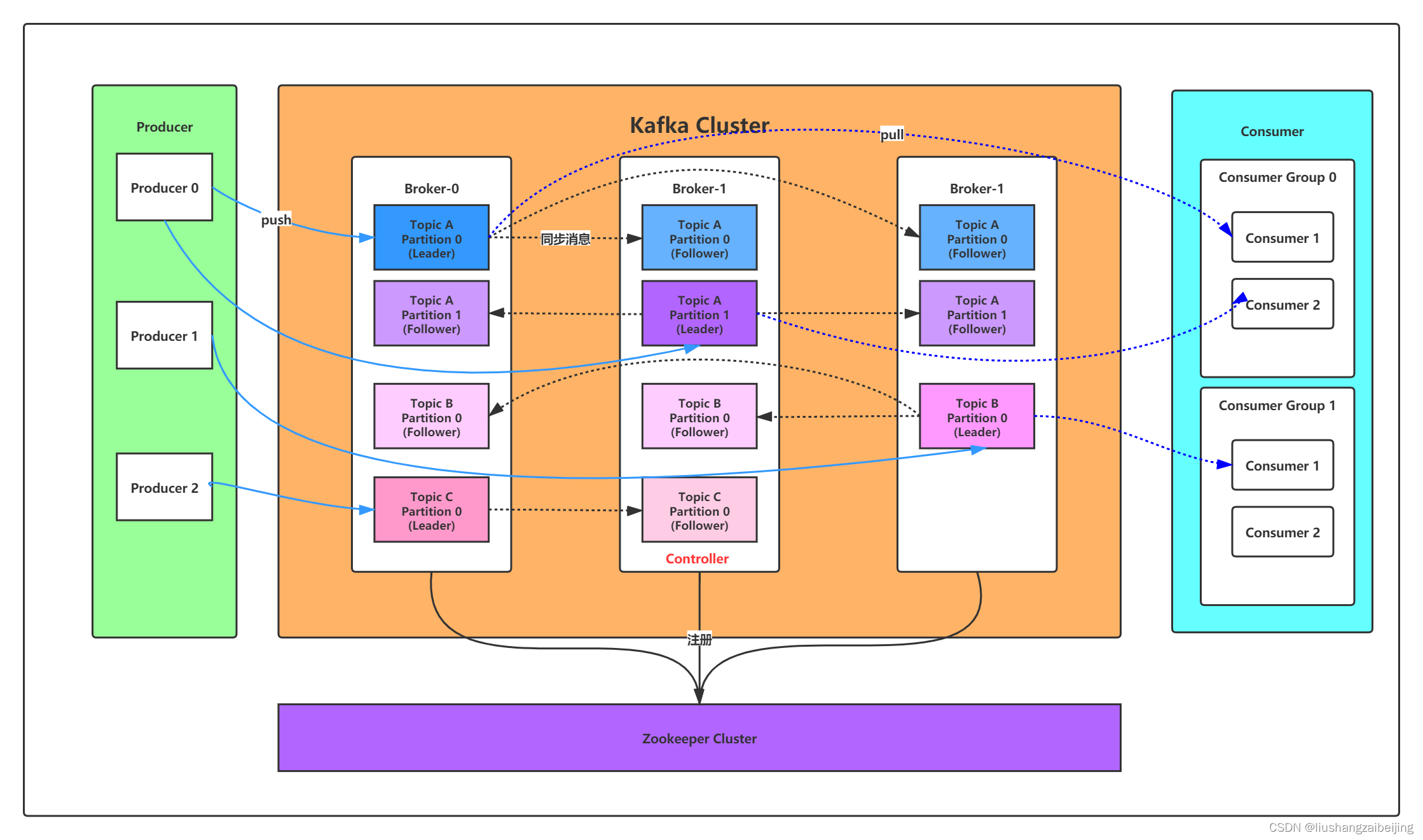
3.1 集群搭建
對于kafka來說,一個單獨的broker意味著kafka集群中只有一個節點,要想增加kafka集群中的節點數量,只需要多啟動幾個broker實體即可,這里啟動三個實體
# 復制兩個配置
cp config/server.properties config/server-1.properties
cp config/server.properties config/server-2.properties
修改組態檔
#broker.id屬性在kafka集群中必須要是唯一
broker.id=1
#kafka部署的機器ip和提供服務的埠號
listeners=PLAINTEXT://9093
log.dir=/usr/local/data/kafka-logs-1
#kafka連接zookeeper的地址,要把多個kafka實體組成集群,對應連接的zookeeper必須相同
zookeeper.connect=127.0.0.1:2181
# 啟動兩個節點
bin/kafka-server-start.sh config/server1.properties &
bin/kafka-server-start.sh config/server2.properties &
#創建一個新的topic,副本數設定為3,磁區數設定為2:
bin/kafka-topics.sh --create --zookeeper 127.0.0.1:2181 --replication-factor 3 --partitions 2 --topic my-replicated-topic
#查看下topic的情況
bin/kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic my-replicated-topic

以下是輸出內容的解釋,第一行是所有磁區的概要資訊,之后的每一行表示每一個partition的資訊,
- leader節點負責給定partition的所有讀寫請求,同一個主題不同磁區leader副本一般不一樣(為了容災)
- replicas 表示某個partition在哪幾個broker上存在備份,不管這個幾點是不是”leader“,甚至這個節點掛了,也會列出,
- isr 是replicas的一個子集,它只列出當前還存活著的,并且已同步備份了該partition的節點,
#集群發送訊息
bin/kafka-console-producer.sh --broker-list 127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094 --topic my-replicated-topic
#集群消費訊息
bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092,127.0.0.1:9093,127.0.0.1:9094 --from-beginning --topic my-replicated-topic
生產者生產訊息到kafka

消費者消費kafka集群消費
3.2 kafka集群特性
kafka的容錯性
my-replicated-topic的資訊

查看到 my-replicated-topic 有兩個磁區 partition 0和partition 1 對該磁區的進行讀寫請求的是brokerId=3,這里殺死brokerId=3的進行再次查看my-replicated-topic 如下

對my-replicated-topic 兩個磁區的讀寫變成了brokerid = 1和brokerId =0 且能正常的生產和消費訊息,kafka將很多集群關鍵資訊記錄在zookeeper里,保證自己的無狀態,從而在水平擴容時非常方便,
kafka集群資料同步流程
-
topic的partitions分布在kafka集群中不同的broker上,每個broker可以請求備份其他broker上partition上的資料,
-
針對每個partition,都有一個broker起到“leader”的作用,0個或多個其他的broker作為“follwers”的作用,
-
leader處理所有的針對這個partition的讀寫請求,而followers被動復制leader的結果,不提供讀寫(主要是為了保證多副本資料與消費的一致性),如果這個leader失效了,其中的一個follower將會自動的變成新的leader,、
-
生產者將訊息發送到topic中去,同時負責選擇將message發送到topic的哪一個partition中,通過round-robin做簡單的負載均衡,也可以根據訊息中的某一個關鍵字來進行區分,通常第二種方式使用的更多,
kafka集群情況下的消費順序
-
一個partition同一個時刻在一個consumer group中只能有一個consumer instance在消費,從而保證消費順序,
-
consumer group中的consumer instance的數量不能比一個Topic中的partition的數量多,否則,多出來的consumer消費不到訊息,
-
Kafka只在partition的范圍內保證訊息消費的區域順序性,不能在同一個topic中的多個partition中保證總的消費順序性,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384174.html
標籤:其他