前言
本文隸屬于專欄《1000個問題搞定大資料技術體系》,該專欄為筆者原創,參考請注明來源,不足和錯誤之處請在評論區幫忙指出,謝謝!
本專欄目錄結構和參考文獻請見1000個問題搞定大資料技術體系
目錄
Spark RDD 論文詳解(一)摘要和介紹
Spark RDD 論文詳解(二)RDDs
Spark RDD 論文詳解(三)Spark 編程介面
Spark RDD 論文詳解(四)表達 RDDs
Spark RDD 論文詳解(五)實作
Spark RDD 論文詳解(六)評估
Spark RDD 論文詳解(七)討論
Spark RDD 論文詳解(八)相關作業和結尾
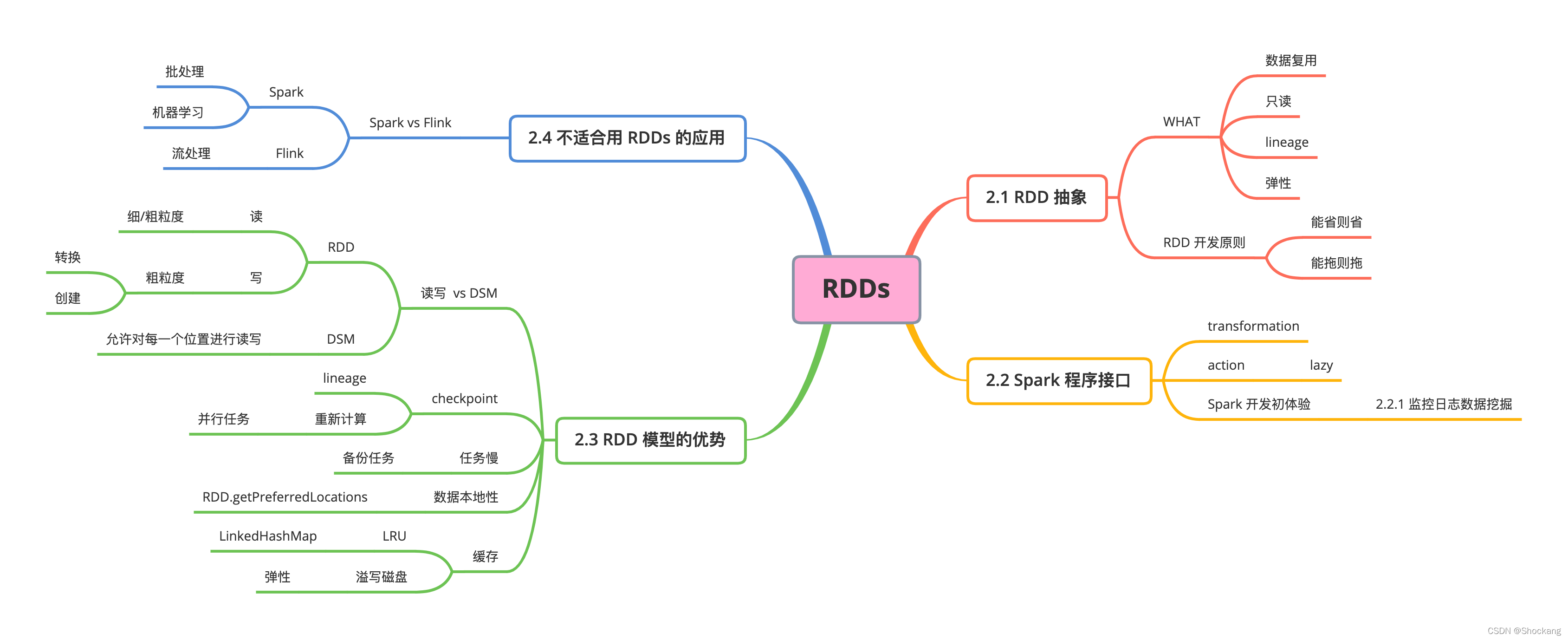
思維導圖
正文
這里分享一下 RDD 論文下載鏈接:
Resilient Distributed Datasets: A Fault-tolerant Abstraction for In-memory Cluster Computing
2、RDDs
這節主要講述 RDDs 的概要
首先定義 RDDs 以及介紹 RDDs 在 spark 中的編程介面
然后對 RDDs 和細粒度共享記憶體抽象進行的對比
最后我們討論了 RDD 模型的限制性
2.1 RDD 抽象
原文翻譯
一個 RDD 是一個只讀,可磁區的資料集,
我們通過對穩定的存盤系統或者其他的 RDDs 進行操作可以創建出一個新的 RDDs,
為了區別開 RDDs 的其他操作,我們稱這些操作為 transformations,比如 map,filter 以及 join 等都是 transformations 操作,
雖然各個RDD是不可變的,但是可以通過多個RDD表示資料集的多個版本來實作可變狀態, 為了更容易的描述血緣(
lineage)關系圖,我們使RDD不可變,但是我們讓資料抽象基于版本化的資料集并且可以通過血緣關系圖來追蹤這些版本,這實際上是等效的,
RDDs 并不要始終需要被具象化,
為了計算穩定存盤里面的磁區資料,一個 RDD 是有足夠的資訊知道自己是從哪個資料集計算而來的(就是所謂的 lineage),
這是一個非常強大的屬性:實際上,如果一個 RDD 不能在失敗后重新構建,那么程式就不能參考它,
最后,用戶可以控制 RDDs 的兩個方面:資料存盤和磁區,
對于需要復用的 RDD,用戶可以明確的選擇一個資料存盤策略(比如記憶體快取),
他們也可以基于一個元素的 key 來為 RDD 所有的元素在機器節點間進行資料磁區,
這樣非常利于資料分布優化,比如給兩個資料集進行相同的 hash 磁區,然后進行 join,可以提高 join 的性能,
決議
RDD 是什么?
RDD 的初衷就是為了資料復用,所以 Spark 團隊就設計了這個分布式記憶體抽象,
RDD 代表的其實就是大資料中最核心的資產——資料,這個資料可以存盤在磁盤或者記憶體中,但是優先會考慮存盤在記憶體中,當然用戶可以自己控制它存盤在哪里?是否需要序列化?是否需要保存多個副本?
RDD 代表的資料是只讀不可變的,但是資料一定要不斷變化才能滿足用戶的需求,所以,給這些資料加上版本就好了,這些隨著版本變化不斷生成的一連串的資料實際上就構成了一條血緣鏈路,
RDD 如果每個版本的資料都保存,會帶來很多存盤和性能上的損耗,同時也是沒有必要的,沒有不管什么版本的資料都會用,用戶很多時候只關心結果資料有沒有到達預期而已,最多,有時候考慮到資料復用來提升一下性能,“我已經計算過的資料總不能讓我重新計算一次吧?”,所以才需要把一些重復計算的資料物化,
RDD 除了存盤實際的資料以外,如果能夠存盤上游的血緣關系就更好了,因為這樣,就算我當前的 RDD 因為什么原因丟失了,有了血緣關系,我能通過其他 RDD 的資料加上轉換邏輯還能重新生成這個 RDD,
關于 RDD 的概念中其實最令人難以理解的是這個 “彈性”,
根據徐文浩老師在《大資料經典論文解讀》中的說法,這個彈性體現在兩個方面:
- 第一個是資料存盤上,資料不再是存放在硬碟上的,而是可以快取在記憶體中,只有當記憶體不足的時候,才會把它們換出到硬碟上,同時,資料的持久化,也支持硬碟、序列化后的記憶體存盤,以及反序列化后 Java 物件的記憶體存盤三種形式,每一種都比另一種需要占用更多的記憶體,但是計算速度會更快,
- 第二個是選擇把什么資料輸出到硬碟上,Spark 會根據資料計算的 Lineage,來判斷某一個 RDD 對于前置資料是寬依賴,還是窄依賴的,如果是寬依賴的,意味著一個節點的故障,可能會導致大量的資料要進行重新計算,乃至資料網路傳輸的需求,那么,它就會把資料計算的中間結果存盤到硬碟上,
根據王家林老師在《Spark大資料商業實戰三部曲:內核解密商業案例性能調優》中的說法,彈性可以體現在 7 個方面:
- 自動進行記憶體和磁盤資料存盤的轉換
- 基于 Lineage(血統)的高效容錯機制
- Task 如果失敗,會自動進行特定次數的重試
- Stage 如果失敗,會自動進行特定次數的重試
- checkpoint 和 persist(檢查點和持久化),可主動或被動觸發
- 資料調度彈性,DAGScheduler、TaskScheduler 和資源管理無關
- 資料分片的高度彈性(coalesce)
我比較贊同徐文浩老師的觀點,個人認為王家林老師的說法有點牽強,3 到 7 其實應該屬于 Spark 這個框架體現出來的彈性,如果只是單純的討論彈性分布式資料集 RDD 的彈性,其實 1 和 2 就已經足夠了,順便說一句,如果 3 到 7 都算彈性,我自己也可以加幾個,比方說,Spark 的統一記憶體模型中執行記憶體和存盤記憶體實際上是具有彈性的,它們之間可以相互借用,還比如,Spark 的 Sort Shuffle 是具備彈性能力的,可以視排序聚合序列化等因素自動切換成 Tungsten Sort Shuffle,還比如,Spark 3.0 的 AQE,join 策略自動調整、自動磁區合并、資料傾斜自動處理,這些其實都是彈性的體現,
RDD 開發原則
RDD 的資料為了支持龐大的資料量和可伸縮性,支持可磁區是必然的結果,
那資料就不可避免的存放在不同的節點上面,那此時就有了新問題了:
如果所有的資料都放到同一個節點上面去執行該有多爽!
因為這樣就可以告別特別特別損耗性能的網路開銷了,
但是大資料的需求決定了有時候把所有資料匯總到一起得到一個最終的結果是不可避免的,也就是聚合不可避免,
此時網路開銷也不可避免,
顯而易見,網路傳輸的資料越少越好,那么怎么能使得網路傳輸資料減少呢?
此時,一個開發原則就被提了出來:
- 資料輸入——能省則省!
- 網路傳輸——能拖則拖!
大家可以思考下,遵循了上面的開發原則,網路實際傳輸的資料量是不是少了很多呢,
這個開發原則參考自吳磊老師的專欄《Spark 性能調優實戰》
08 | 應用開發三原則:如何拓展自己的開發邊界?
2.2 Spark 程式介面
原文翻譯
Spark 和 DryadLINQ 和 FlumeJava 一樣通過集成編程語言 API 來暴露 RDDs,這樣的話,每一個資料集就代表一個物件,我們可以呼叫這個物件中的方法來操作這個物件,
編程者可以通過對穩定存盤的資料進行轉換操作(即 transformations,比如 map 和 filter 等)來得到一個或者多個 RDDs,
然后可以對這些 RDDs 進行 actions 操作,這些操作可以回傳結果給應用,也可以將結果資料寫入到存盤系統中,
actions 包括:
- count(表示回傳這個資料集的元素的個數)
- collect(表示回傳資料集的所有元素)
- save(表示將輸出結果寫入到存盤系統中)
- …
和 DryadLINQ 一樣,spark 在定義 RDDs 的時候并不會真正的計算,而是要等到對這個 RDDs 觸發了 actions 操作才會真正的觸發計算,這個稱之為 RDDs 的lazy 特性,所以我們可以先對 transformations 進行組裝一系列的 pipelines,然后再計算,
另外,編程者可以通過呼叫 RDDs 的 persist 方法來快取后續需要復用的 RDDs,
Spark 默認是將快取資料放在記憶體中,但是如果記憶體不足的話則會寫入到磁盤中,
用戶可以通過 persist 的引數來調整快取策略,比如只將資料存盤在磁盤中或者復制備份資料到多臺機器,
最后,用戶可以為每一個 RDDs 的快取設定優先級,這樣可以決定哪些記憶體資料會先被溢位到磁盤,
決議
lazy(延遲加載/懶加載)實際上在程式開發中很多地方都能見到,比如 Java 領域中的著名框架 - Spring 就利用了懶加載機制可以實作指定的 bean 不在啟動時立即創建,而是在后續第一次用到時才創建,從而減輕在啟動程序中對時間和記憶體的消耗,
Scala 中甚至有個 lazy關鍵字來定義惰性變數,實作延遲加載(懶加載), 惰性變數只能是不可變變數,并且只有在呼叫惰性變數時,才會去實體化這個變數,
Spark 中的 RDD 同樣具有 lazy 的特性,一方面,用戶使用 RDD 實際上不關心內部到底怎么轉換的,他們只關心輸出結果是否復合預期,而只有 action 操作才能觸發輸出,另一方面,如果每一步操作都實際執行會使得調度系統“不堪重負”,而且不方便實作一些優化操作,
transformations 操作實際上對應的就是 RDD 內部的轉換,無非就是從一個 RDD 轉換成另一個 RDD,都是 RDD 型別,而 action 操作是將 RDD 輸出為用戶想要具體的非 RDD 型別,
比方說,原始資料總共有 100 條,但是我只需要其中 10 條資料
rdd.map(...).filter(...).count()
如果按照上面每一步都操作的話,實際上另外的 90 條完全沒必要來進行 map 轉換的,因為最后都會過濾掉,所以完全可以將 filter 操作優化到 map 之前,這樣可以減少大量的CPU、記憶體和磁盤消耗,
2.2.1 監控日志資料挖掘
原文翻譯
假設一個 web 服務正發生了大量的錯誤,然后運維人員想從存盤在 HDFS 中的幾 TB 的日志中找出錯誤的原因,
運維人員可以通過 spark 將日志中的錯誤資訊加載到分布式的記憶體中,然后對這些記憶體中的資料進行互動式查詢,
她首先需要寫下面的 scala 代碼:
line = spark.textFile("hdfs://..")
errors = lines.filter(_.startsWith("ERROR"))
errors.persist()
第一行表示從一個 HDFS 檔案(許多行的檔案資料集)上定義了一個 RDD,第二行表示基于前面定義的 RDD 進行過濾資料,第三行將過濾后的 RDD 結果存盤在記憶體中,以達到多個對這個共享 RDD 的查詢,需要注意的事,filter 的引數是 scala 語法中的閉包,
到目前為止,集群上還沒有真正的觸發計算,
然而,用戶可以對RDD進行action操作,比如對錯誤資訊的計數:
errors.count()
用戶也可以繼續對 RDD 進行 transformations 操作,然后計算其結果,比如:
//對錯誤中含有 ”MySQL” 單詞的資料進行計數
errors.filters(_.contains("MySQL")).count()
//回傳錯誤資訊中含有 "HDFS" 字樣的資訊中的時間欄位的值(假設每行資料的欄位是以 tab 來切分的,時間欄位是第 3 個欄位)
errors.filter(_.contains("HDFS"))
.map(_.split("\t")(3))
.collect()
在對 errors 第一次做 action 操作的后,spark 會將 errors 的所有磁區的資料存盤在記憶體中,這樣后面對 errors 的計算速度會有很大的提升,
需要注意的是,像 lines 這種基礎資料的 RDD 是不會存盤在記憶體中的,
因為包含錯誤資訊的資料可能只是整個日志資料的一小部分,所以將包含錯誤資料的日志放在記憶體中是比較合理的,
最后,為了說明我們的模型是如何達到容錯的,我們在圖一中展示了第三個查詢的血緣關系圖(lineage graph),
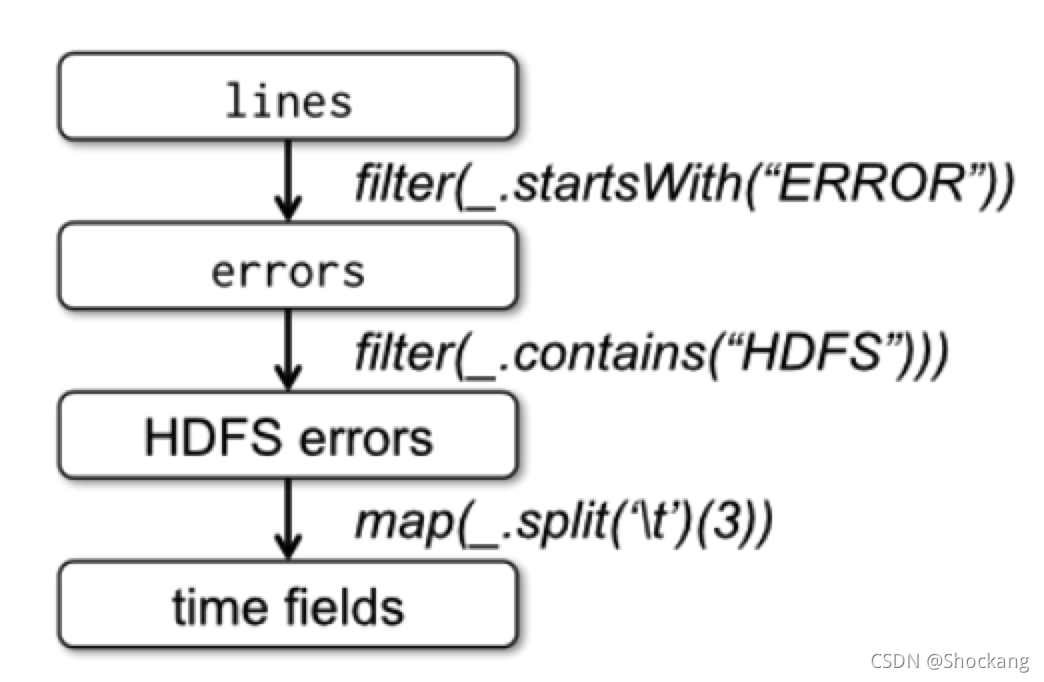
圖一:我們例子中第三個查詢的血緣關系圖,其中方框表示 RDDs,箭頭表示轉換
在這個查詢中,我們以對 lines 進行過濾后的 errors 開始,然后在對 errors 進行了 filter 和 map 操作,最后做了 action 操作即 collect,
Spark 會最后兩個 transformations 組成一個 pipeline,然后將這個 pipeline 分解成一系列的 task,最后將這些 task 調度到含有 errors 快取資料的機器上進行執行,
此外,如果 errors 的一個磁區的資料丟失了,spark 會對 lines 的相對應的磁區應用 filter 函式來重新創建 errors 這個磁區的資料,
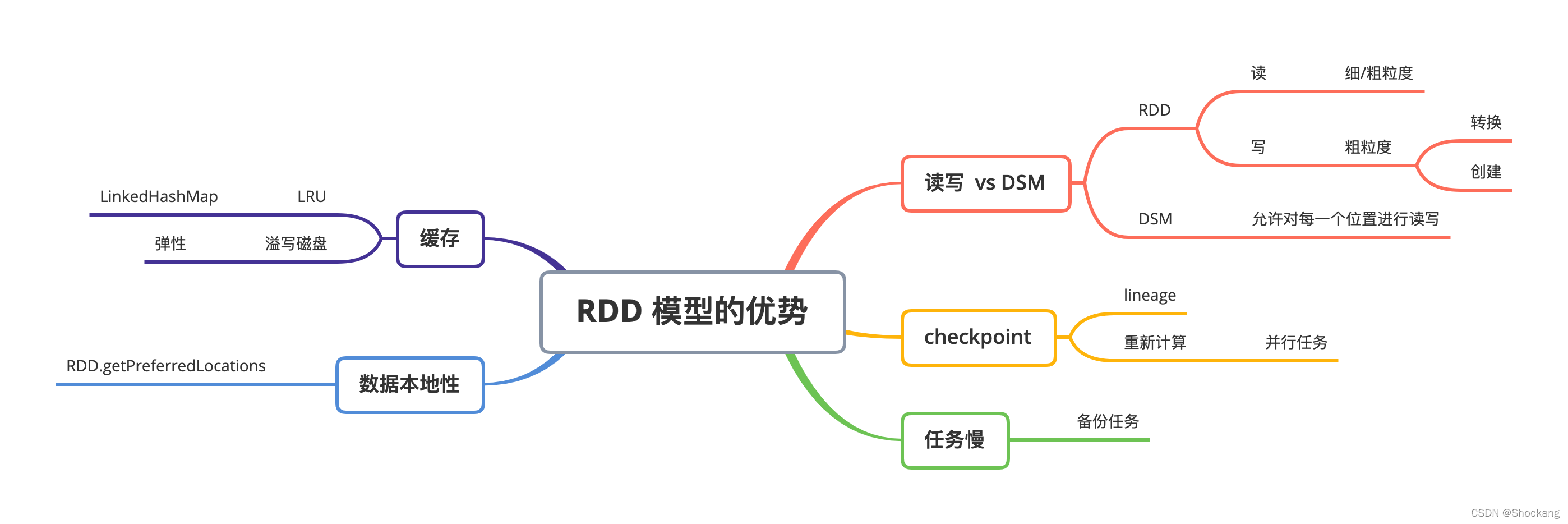
2.3 RDD 模型的優勢
原文翻譯
為了理解作為分布式記憶體抽象的 RDDs 的好處,我們在下面的表一中用 RDDs 和分布式共享記憶體系統(Distributed shared memory 即 DSM)進行了對比,
| 概念 | RDDs | Distribute shared memory(分布式共享記憶體) |
|---|---|---|
| Reads | 粗粒度或者細粒度 | 細粒度 |
| Writes | 粗粒度 | 細粒度 |
| 資料一致性 | 不重要的(因為RDD是不可變的) | 取決于app 或者 runtime |
| 容錯 | 利用lineage達到細粒度且低延遲的容錯 | 需要應用checkpoints(就是需要寫磁盤)并且需要程式回滾 |
| 計算慢的任務 | 可以利用備份的任務來解決 | 很難做到 |
| 計算資料的位置 | 基于資料本地性自動實作 | 取決于app(runtime是以透明為目標的) |
| 記憶體不足時的行為 | 和已經存在的資料流處理系統一樣,寫磁盤 | 非常糟糕的性能(需要記憶體的交換?) |
在所有的 DSM 系統中,應用從一個全域的地址空間中的任意位置中讀寫資料,
需要注意的是,依據這個定義,我們所說的 DSM 系統不僅包含了傳統的共享記憶體系統,還包含了對共享狀態的細粒度寫操作的其他系統(比如 Piccolo),以及分布式資料庫,
DSM 是一個很普遍的抽象,但是這個普遍性使得它在商用集群中實作高效且容錯的系統比較困難,
RDDs 只能通過粗粒度的轉換被創建(或者被寫),然而 DSM 允許對每一個記憶體位置進行讀寫,這個是 RDDs 和 DSM 最主要的區別,
注意在RDD上讀取仍然可以進行細粒度, 例如,應用程式可以將RDD視為一個龐大的只讀查找表,
這樣使都 RDDs在 應用中大量寫資料受到了限制,但是可以使的容錯變的更加高效,
特別是,RDDs 不需要發生非常耗時的 checkpoint 操作,因為它可以根據 lineage 進行恢復資料,
在某些應用程式中,使用很長的血緣鏈路來為RDD設定檢查點,這依然很有用處,我們在第5.4節中將會討論, 但是,這可以在后臺完成,因為RDD是不可變的,并且不需要在 DSM 中拍攝整個應用程式的快照,
而且,只有丟掉了資料的磁區才會需要重新計算,并不需要回滾整個程式,并且這些重新計算的任務是在多臺機器上并行運算的,
RDDs 的第二個好處是:它不變的特性可以使得它可以和 MapReduce 一樣,任務執行很慢,那就運行備份任務來緩解節點計算慢的問題,
在 DSM 中,備份任務是很難實作的,因為原始任務和備份任務可能會同時更新訪問同一個記憶體地址和介面,
最后,RDDs 比 DSM 多提供了兩個好處,
第一,在對 RDDs 進行大量寫操作的程序中,我們可以根據資料的本地性來調度 task 以提高性能,
第二,如果在 scan-based 的操作中,且這個時候記憶體不足以存盤這個 RDDs,那么 RDDs 可以慢慢的從記憶體中清理掉,在記憶體中存盤不下的磁區資料會被寫到磁盤中,且提供了和現有并行資料處理系統相同的性能保證,
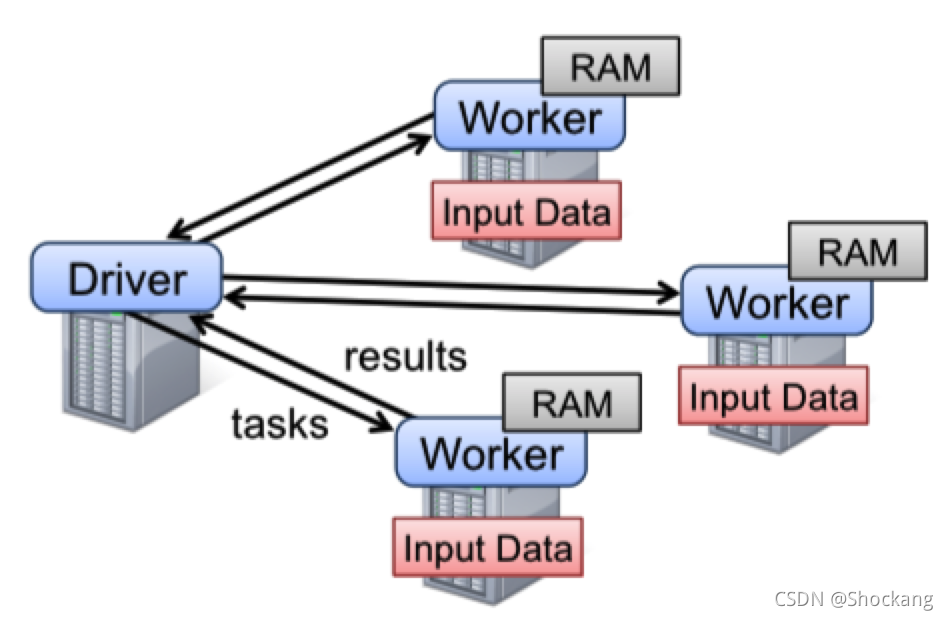
圖二:這個是 Spark 運行時的圖,用戶寫的 driver 端程式啟動多個 workers,這些 workers 可以從分布式檔案系統中讀取資料塊并且可以將計算出來的 RDD 磁區資料存放在記憶體中,
思維導圖
2.4 不適合用 RDDs 的應用
原文翻譯
經過上面的討論介紹,我們知道 RDDs 非常適合將相同操作應用在整個資料集所有元素上的批處理應用,
在這些場景下,RDDs 可以利用血緣關系圖來高效的記住每一個 transformations 的步驟,并且不需要記錄大量的資料就可以恢復丟失的磁區資料,
RDDs 不太適合用于需要異步且細粒度更新共享狀態的應用,比如一個 web 應用或者資料遞增的 web 爬蟲應用的存盤系統,
對于這些應用,使用傳統的紀錄更新日志以及對資料進行 checkpoint 會更加高效,
比如使用資料庫、RAMCloud、Percolator 以及 Piccolo,
我們的目標是給批量分析提供一個高效的編程模型,對于這些異步的應用需要其他的特殊系統來實作,
決議
RDD 的資料模型就決定了 Spark 實際上只適合批處理,而 Spark Streaming 通過微積分思想使用微批處理來替代流處理實際上只適合對實時性要求不高的場景(一般最快是 0.5 秒左右),同樣的,Spark Structured Streaming 通過將流處理看成往一張無限大的表上面不斷添加一行一行的資料,但是底層還是逃脫不了 RDD 的限制(因為 Spark 的這兩種流處理框架底層都是 RDD), 所以,從某種角度上來說,除非 RDD 的資料模型參考 Google 的 DataFlow 模型(這個可以自行百度)做出了某種改變,不然單純的流資料處理領域永遠也無法超過 Flink,
實際上,很多剛學大資料的新人就在學習 Spark 和 Flink 之間難以抉擇,Spark 目前來講只是流資料處理領域比不上 Flink,但是在 批處理/機器學習領域 讓 Flink 也是望塵莫及的,
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384175.html
標籤:其他