
題 目:搜索演算法的性能分析與比較
包含完整的論文(字數近4000)+源程式+PPT報告一份,可作為資料結構、資料分析、演算法與資料結構等相關課程的課程設計或者大作業;末尾有下載地址
目 錄
前言
一、課題來源
1.1課程設計題目
1.2 問題描述
1.3 問題分析
1.4課題內容
二、課題的概要設計和流程
2.1 課題的概要設計
2.2 部分演算法的設計流程
三、課題的詳細設計
3.1隨機生成資料
3.2順序查找
3.3二分法查找
3.4哈希查找
四、運行與除錯
4.1測驗結果截圖
五、用戶手冊
六、不足與改進
七、設計心得
八、課程設計專案進度表及任務分配表
8.1組員任務分配表
8.2組員任務安排表
九、參考書目
一、課題來源
—————————————————————————————————
此處省略幾百字
—————————————————————————————————
1、 問題描述
(1)順序表查找的問題描述
順序查找又稱為線性查找,它是一種最簡單、最基本的查找方法,從第一個資料開始逐步查找目標元素,找到后計算所用時間,如果沒有找到會遍歷所有資料后回傳所用時間,
(2)折半查找問題描述
折半查找也稱為二分查找,作為二分查找物件的資料必須是順序存盤的有序表,如果資料無序則需排序后查找,將目標資料分為兩份查找不斷縮小目標所在區間直到得到和目標元素相等的元素然后計算出所用時間,
(3)哈希查找的問題描述
哈希表是在關鍵字和存盤位置之間直接建立了映像,哈希函式的“好壞”首先影響出現沖突的頻率,假設哈希函式是均勻的,即它對同樣一組隨機的資料出現沖突的可能性是相同的,因此哈希表的查找效率主要取決于構造哈希表時處理沖突的方法,
(4)比較三種演算法搜索的問題描述
對生成的隨機資料,可以進行選擇一個數查找,三種演算法都進行查找,可以得出相對應的搜索時間,然后再對其三種搜索演算法所需要的時間進行比較,如若無此數則都回傳未找到,但會記錄其搜索時間,也可進行比較,
(5)界面設計模塊問題描述
設計一個選單模式界面,讓用戶可以選擇要查找的方式,界面上還有退出按鈕,可以退出程式,界面要求簡潔明了,便于使用,
(6)按鈕動作命令模塊問題描述
在設計好圖形界面后,就必須對相應的按鈕進行事件驅動程式設計,運行Java圖形用戶界面程式時,程式與用戶互動,比如說,在框架中顯示多個按鈕,當點擊按鈕時,就會從按鈕觸發一個事件,同時,查找的操作必須要有輸入和輸出,則需要使用對話框和命令視窗進行輸入關鍵字和輸出結果,
2、問題分析
要完成如下要求:順序查找、二分查找、哈希查找三者的搜索時間進行比較,本程式的實作需要解決以下幾個問題:
(1)如何設計一組隨機資料;
(2)如何設計順序查找的搜索;
(3)如何設計二分查找的搜索;
(4) 如何設計哈希查找的搜索;
(5)如何設計時間記錄;
(6)如何讓各個程式同時運行正常;
—————————————————————————————————
此處省略幾百字
—————————————————————————————————
二、概要設計
2.1 課題的概要設計.
本設計涉及到的資料結構為:散列、順序搜索、二分法搜索,
2.2 部分演算法的設計流程.
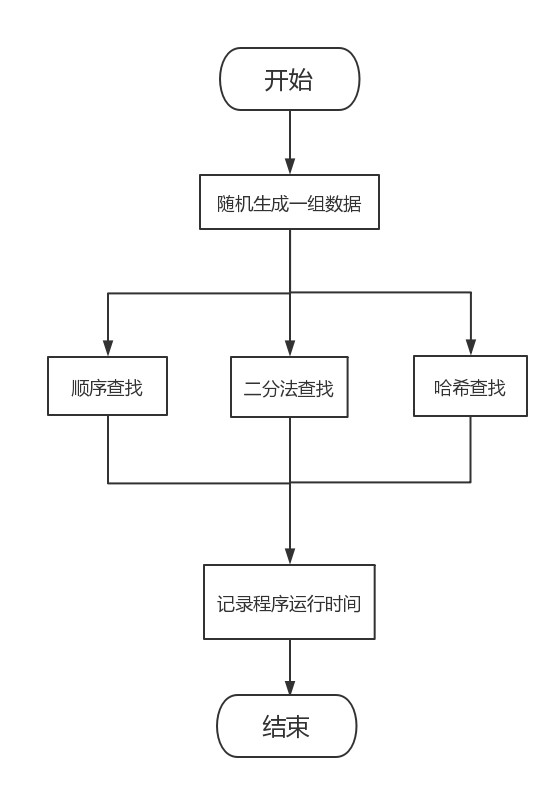
三、詳細設計
1、查找所需資料
通過自己創建的程式生成的一組隨機資料(資料長度可由自己決定,資料大小最大為為陣列長度的四分之一,最小即為0,
2、順序查找
在資料序列中,按照從前往后或者從后往前的順序依次查找,如果查找到關鍵字和給定值相等,則回傳給定值的位置,查找成功;如果查找值最后一個元素仍未找到,則查找失敗,
3 、二分法查找
二分法進行查找時,查找物件的陣列必須是有序的,即各陣列元素的次序是按其值的大小順序存盤的,
其基本思想是先確定待查資料的范圍(可用 [left,right] 區間表示),然后逐步縮小范圍直到找到或找不到該記錄為止,具體做法是:先取陣列中間位置(mid=(left+right)/2)的資料元素與給定值比較,若相等,則查找成功;否則,若給定值比該資料元素的值小(或大),則給定值必在陣列的前半部分[left,mid-1](或后半部分[mid+1,right]),然后在新的查找范圍內進行同樣的查找,如此反復進行,直到找到陣列元素值與給定值相等的元素或確定陣列中沒有待查找的資料為止,因此,二分查找每查找一次,或成功,或使查找陣列中元素的個數減少一半,當查找陣列中不再有資料元素時,查找失敗,
4、哈希查找—鏈地址法
將一個哈希值產生沖突關鍵字放進一個鏈表里面,某個哈希值產生沖突了,就把這個關鍵字放到這個哈希值槽的鏈表里面,Java中的HashMap就是這樣解決沖突的,
5、哈希查找—線性探測法
線性探測法中函式是位置i的函式,這相當于當發生沖突的時候,逐個單元甚至回繞查詢到一個空單元,也就是說資料都需要放置在這一個表格中,當發生沖突的時候就出發上面的機制,不過這樣做,花費的時間是相當多的,這樣單元會形成一些區域塊,其結果稱作為一次聚焦,也就是是說經過多次的查找才能找到一個空的單元:
Hkey(x) = Hkey(n)% 資料長度;
也就是當出現和n重復的hash值的時候,則需要逐個進行探測,因為可以回繞,所以可以只取一個方向繼續查找空單元,
四、程式代碼
1、順序查找演算法
public class OrderSearch {
public static String orderSearch(int [] data, int target){
int len = data.length;
for(int i = 0; i < len; i++){
if(data[i] == target){
System.out.println("找到目標 索引"+i+"目標值"+data[i]);
return "";
}
}
return "未找到";
}
}2、二分查找演算法
public class BinarySearch {
public static String binarySearch(int[] data, int target){
RandowDataCreate ra = new RandowDataCreate();
long start = System.currentTimeMillis();
Arrays.sort(data);
long end = System.currentTimeMillis();
double deltaTime = (end-start)*1000;
int count = 0;
int l = 0, r = data.length-1;
int mid = l + r;
mid = mid/2;
while(data[mid]!=target){
if(data[mid] < target){
l = mid + 1;
}else if(data[mid] > target){
r = mid - 1;
}
mid = (l + r)/2;
count++;
if(l > r){
return "未找到";
}
}
System.out.println("找到目標 索引"+mid+"目標值"+data[mid]);
System.out.println("排序耗時"+deltaTime);
count++;
String s = "排序耗時"+deltaTime;
return s;
}
}3、哈希查找演算法
public class HashSearch {
private static ArrayList<LinkedList<Integer>> myList = null;
public static String hashSearch(int[] data, int target){
int count = 0;
long s = System.currentTimeMillis();
count = hashTable(data, data.length);
long e = System.currentTimeMillis();
double deltaTime = (e-s)*1000;
int index = hashCode(target, data.length);
List<Integer> list = myList.get(index);
int i = list.indexOf(target);
if(i==-1){
System.out.println("未找到元素");
return "未找到元素";
}else{
System.out.println("已找到目標元素:"+list.get(i));
}
System.out.println(deltaTime);
System.out.println("哈希表建表耗時"+deltaTime);
String msg = "哈希表建表耗時"+deltaTime;
count+=i;
return msg;
}
}
public class HashSearch2 {
static Object[] objects;
RandowDataCreate r = new RandowDataCreate();
public static void createHashTable(int[] data){
objects = new Object[data.length];
int len = data.length;
for(int i = 0; i < len; i++){
int value = getValue(data[i]);
objects[value] = data[i];
}
}
public static String hashSearch2(int[] data, int target){
long start = System.currentTimeMillis();
createHashTable(data);
long end = System.currentTimeMillis();
int value = getValue(target);
if((int)objects[value]==target){
System.out.println(objects[value]);
}
double deltaTime = (end-start)*1000;
String s = "哈希表建表耗時" + deltaTime;
return s;
}
public static int getValue(int key){
int len = objects.length;
int value = key%len;
while(objects[value]!=null){
if(key==(int)objects[value]){
break;
}
value++;
if(value>=len){
value-=len;
}
}
return value;
}
@Test
public void t(){
int[] nums = r.createData(100);
String s = r.printInts(nums);
System.out.println(s);
hashSearch2(nums, nums[5]);
}
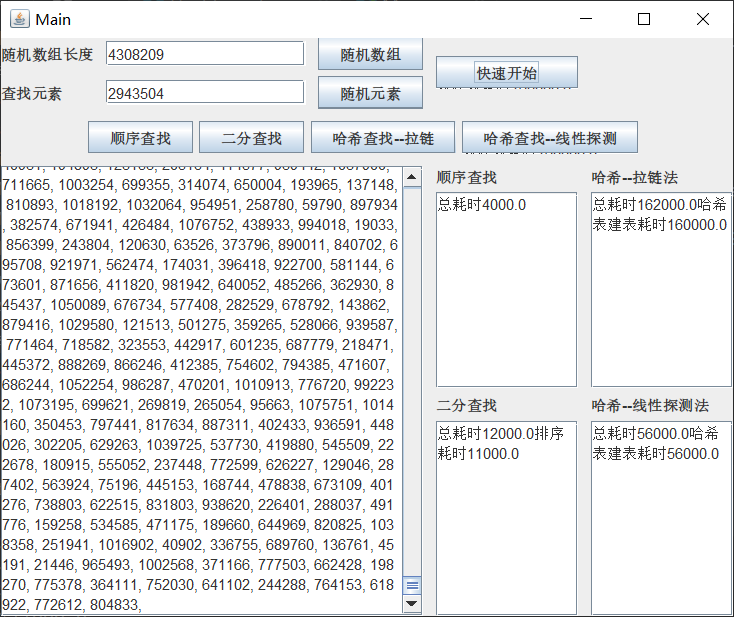
}4、測驗運行截圖(部分)
—————————————————————————————————
此處省略幾百字
—————————————————————————————————
五、設計心得
通過課程設計,從剛開始得覺得很難,到最后把這個做出來我們小組付出了很多,也得到了很多,知道編程時要認真仔細,出現錯誤要及時找出并改正,遇到問題要去查相關的資料,反復的除錯程式,最好是多找幾個同學來對你的程式進行除錯并聽其對你的程式的建議,在他們不知道程式怎么寫的時候完全以一個用戶的身份來用對你的用戶界面做一些建議,把各個注意的問題要想到,通過近一周的學習與實踐,體驗了一下離開課堂的學習,也可以理解為一次實踐與理論的很好的連接,特別是本組所做的題目都是課堂上所講的例子,所以對我們小組的要求就更為嚴格,實訓程序中讓我們對懂得的知識做了進一步深入了解,讓我們的理解與記憶更深刻,對不懂的知識與不清楚的東西也做了一定的了解,也形成了一定的個人做事風格,通過這次課程設計,讓我們小組對一個程式的資料結構有更全面更進一步的認識,也體會到了學以致用、突出自己勞動成果的喜悅心情,也從中發現我們自己平時學習的不足和薄榷訓節,從而加以彌補,
—————————————————————————————————
此處省略幾百字
—————————————————————————————————
六、下載地址
對應完整的論文+源程式+資料庫下載:資料結構課程設計搜索演算法的性能分析與比較資料結構與演算法課程設計【完整論文+源程式+報告PPT】-演算法與資料結構檔案類資源-CSDN下載包含完整的論文(字數近4000)+源程式+PPT報告一份,可作為資料結構、資料分析、演算法與資料結構等更多下載資源、學習資料請訪問CSDN下載頻道.https://download.csdn.net/download/frank2102/65296899
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384258.html
標籤:其他
下一篇:帶傀儡頭結點的雙向鏈表