文章目錄
- TCP可靠傳輸--停止等待ARQ協議
- TCP可靠傳輸--連續ARQ+滑動視窗協議
- 如果有個包重傳N次還是失敗那么會一直重傳到成功嗎?
- TCP資料包為什么在傳輸層切片,不在網路層和資料鏈路層切片?
- 接收視窗大小比發送的資料還要大,TCP會一直等資料填滿接收視窗嗎?
- TCP流量控制
- TCP流量控制--特殊情況
- TCP擁塞控制
- TCP擁塞控制--方法
- TCP擁塞控制--慢開始演算法
- TCP擁塞控制--擁塞避免演算法
- TCP擁塞控制--快重傳演算法
- TCP擁塞控制--擁塞避免+快重傳
- TCP--擁塞控制--快恢復演算法
TCP可靠傳輸–停止等待ARQ協議
為了保證TCP的可靠傳輸,也就是保證這個資料包一定會傳輸到給對方,早期的處理手段是使用了一種體制等待ARQ的方法去解決這個問題;在早期,發送資料包給對方時候,是發送一個包,等對方確認后才可以繼續發送下一個包,
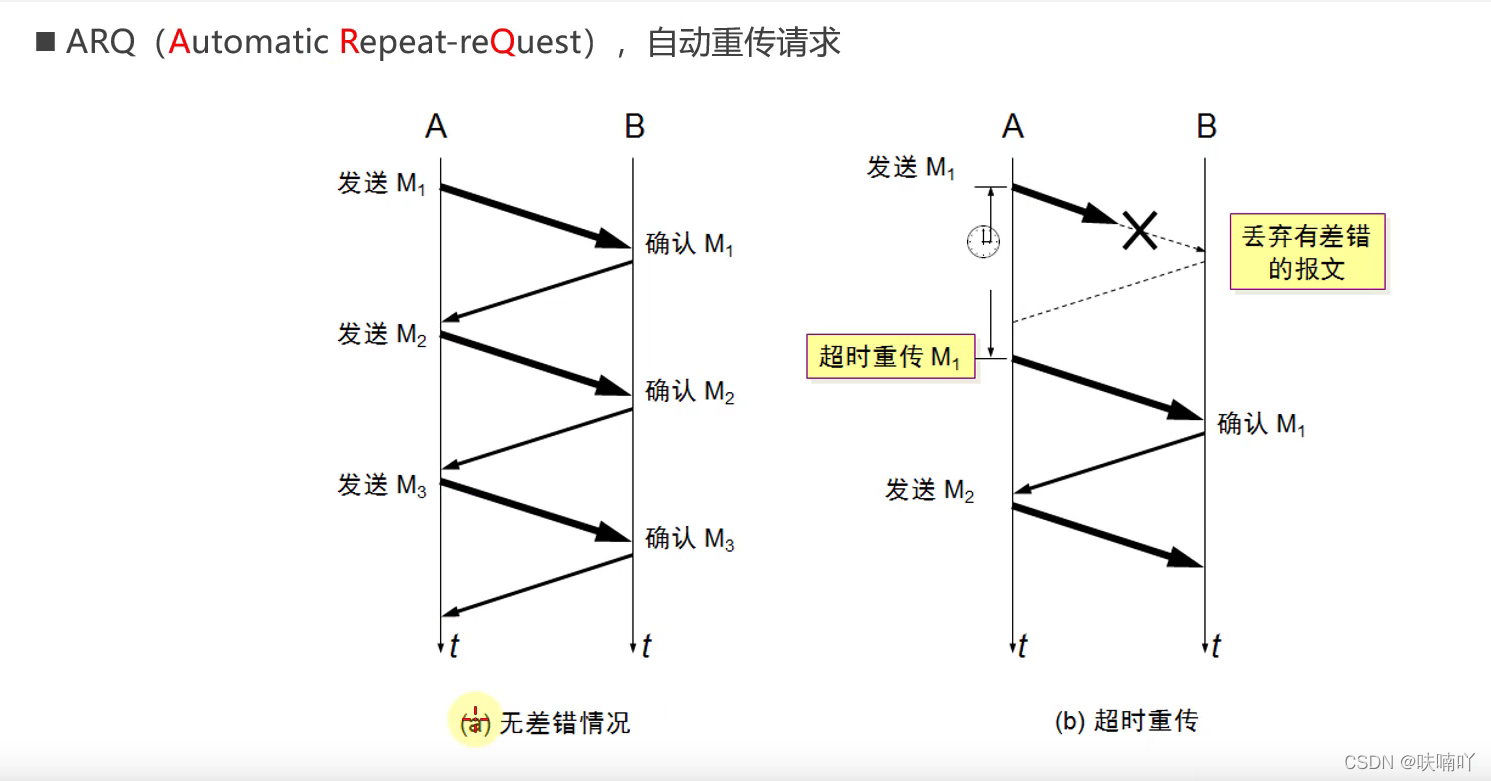
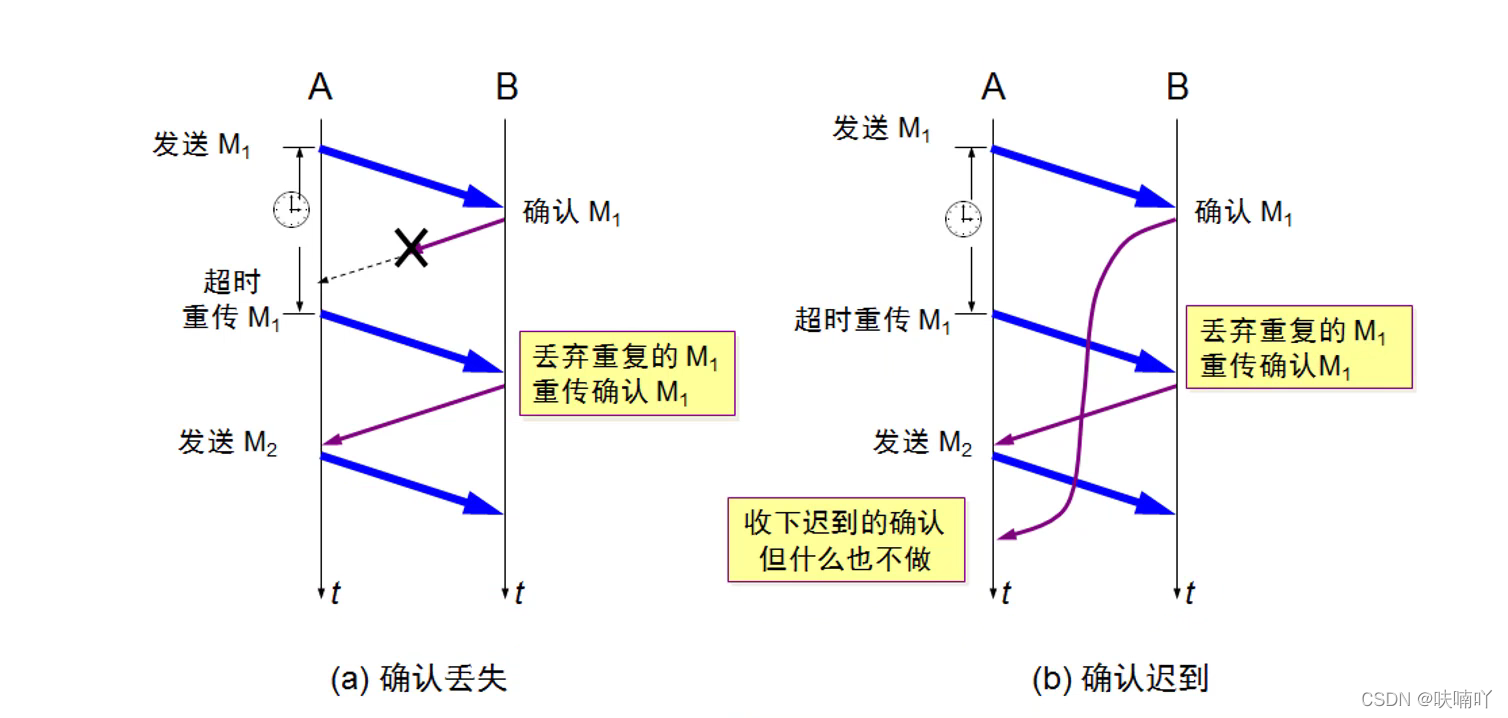
為了保證可靠傳輸,要考慮多種情況;
第一種情況,就是無差錯的情況:A發送過去,B再發一個確認包回來;如此反復知道A發完;
第二種情況,就是超時重傳:A發送過去,B沒有接收到,或者B接收到,沒有回復確認包給A,此時,超過一定時間,A就會重傳這個B沒有收到的資料包;這也是為了保證可靠傳輸;
第三種情況,確認丟失:當A給B發送資料包時候,B收到了資料包,但是B再發一個確認包給A時候,丟失了,或者超時了,此時A就會超時重新發送資料包給B,當B收到A在次發送的資料包時候,丟棄掉A原來發過的一模一樣的資料包,B確認重傳一個確認包給A;
第四種情況:就是確認遲到:當A給B發送資料包時候,B收到了,但是由于B的回復確認資料包給A時候遲到了,那么即使,A收到了確認包,但是什么也不會做,意思是,不會再發送下一個包給B了,因為它遲到了,并且在它遲到前,已經完成了發送下一個包給B了,所以確認遲到的包是不會做任何事情;
上面的停止等待協議確實可以做到保證TCP的可靠傳輸,可是這種機制效率過于低下,因為每發一個資料包過去,都需要對方一個確認包才可以繼續發送下一個包,所以說這種效率比較低下,我們現代使用的另一種連續停止等待ARQ協議+滑動視窗的機制,完美解決了可靠傳輸問題+效率的問題,接下來我會分享這種機制的思想原理,
TCP可靠傳輸–連續ARQ+滑動視窗協議
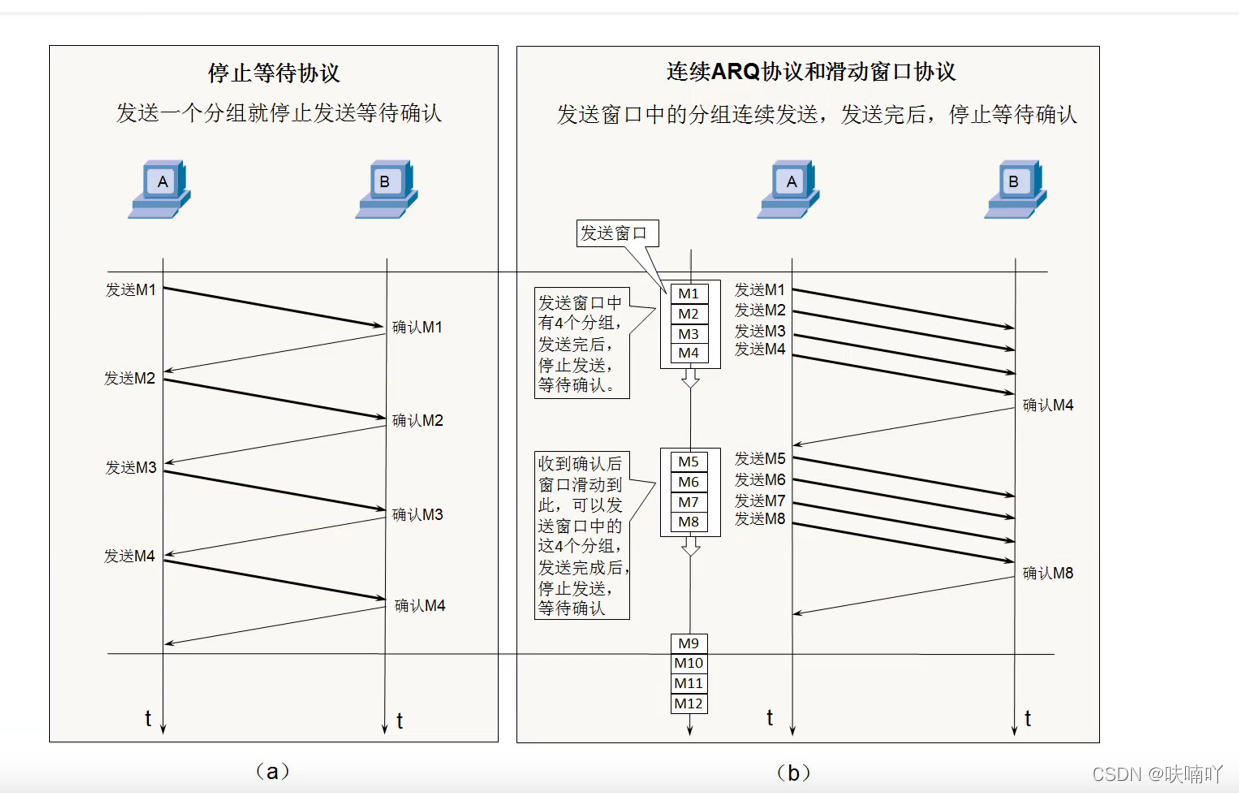
如上圖的右邊的圖要A計算機要發送M1到M12的資料過去給給計算機B,不是一個一個發,而是一段一段發的,比如一次發4個,而計算機B只需要給一個確認即可A即可,不需要給4個確認,并且確認只需要確認一次發的最后一個資料包的編號即可,比如上面的A計算機一次發M1-M4,那么也就是說B回應只需要回應確認M4即可,這表明B是收到前面4個資料包,發完后繼續滑動到M4-M8的視窗位置繼續發送,
一般來說,滑動視窗的大小都是在TCP建立連接的程序中就知道的,
舉個例子:假如有1200位元組的TCP資料部分,分成12份要發送出去;
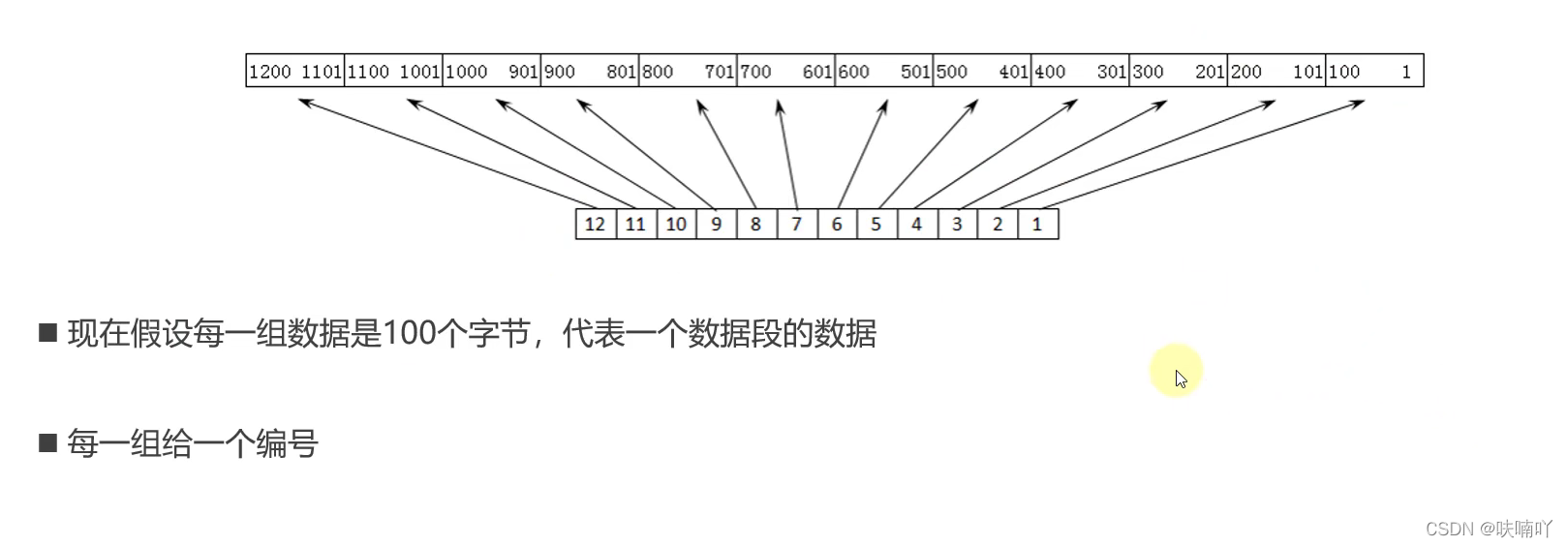
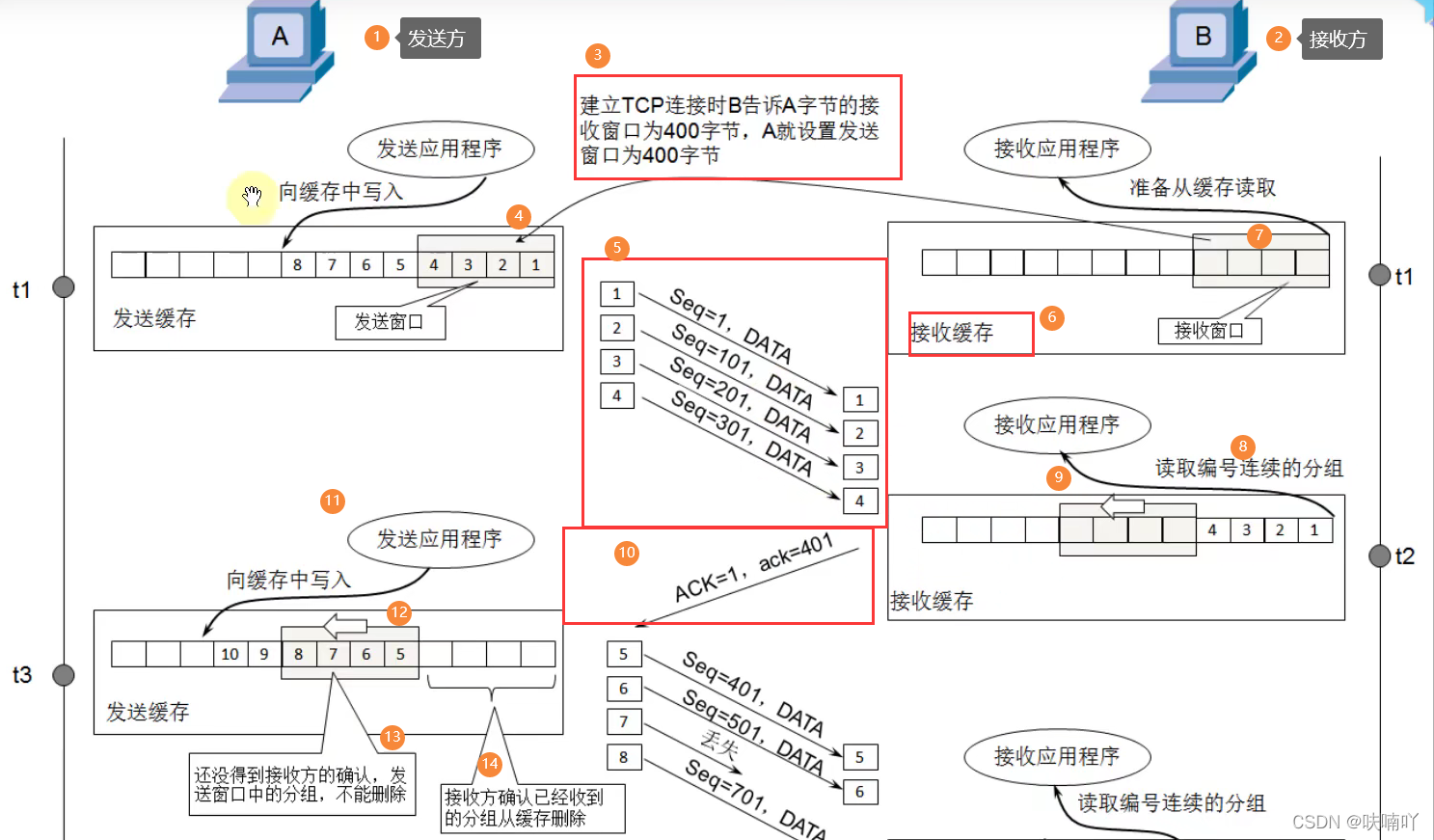
- A為發送方,B為接收方;
- 首先在發送資料前,要建立連接,建立連接程序中,B就告訴了A,B的發送視窗大小為400,那么A就會設定自己視窗大小也為400;也就是說A發送資料給B,是一次發400個位元組過去的;
- 在B中,B收到400個資料后,不是馬上交給應用層處理,而是先放到自己的接收快取中保存,并且把記得的滑動視窗移動到下一個空位,一邊接收A再次發過來的資料;
- 當B接收到A的400個位元組后,B就會給一個確認號給A,期望它從401個位元組發送過來;
- 此時A收到B的確認資料包后,就會設定自己的滑動視窗往前移動,并且在確認對方B收到了前面400個位元組后,會把自己接收快取的已經發送過去的400個位元組清除掉,繼續重復上訴步驟發送接下來的資料包,
我們可以注意觀察細節,發送資料包過去時候,我們每個包的序號為1,101,201,301,即表示這一次發送過去給B的TCP包資料部分的第一個位元組為1,101,201,301;
并且我們觀察B發回來的資料包,是ACK標志位為1,表面確認號是有用的,而此時確認號為401,表示B計算機希望A計算機下一次發送過來的資料是從401個位元組發送過來!
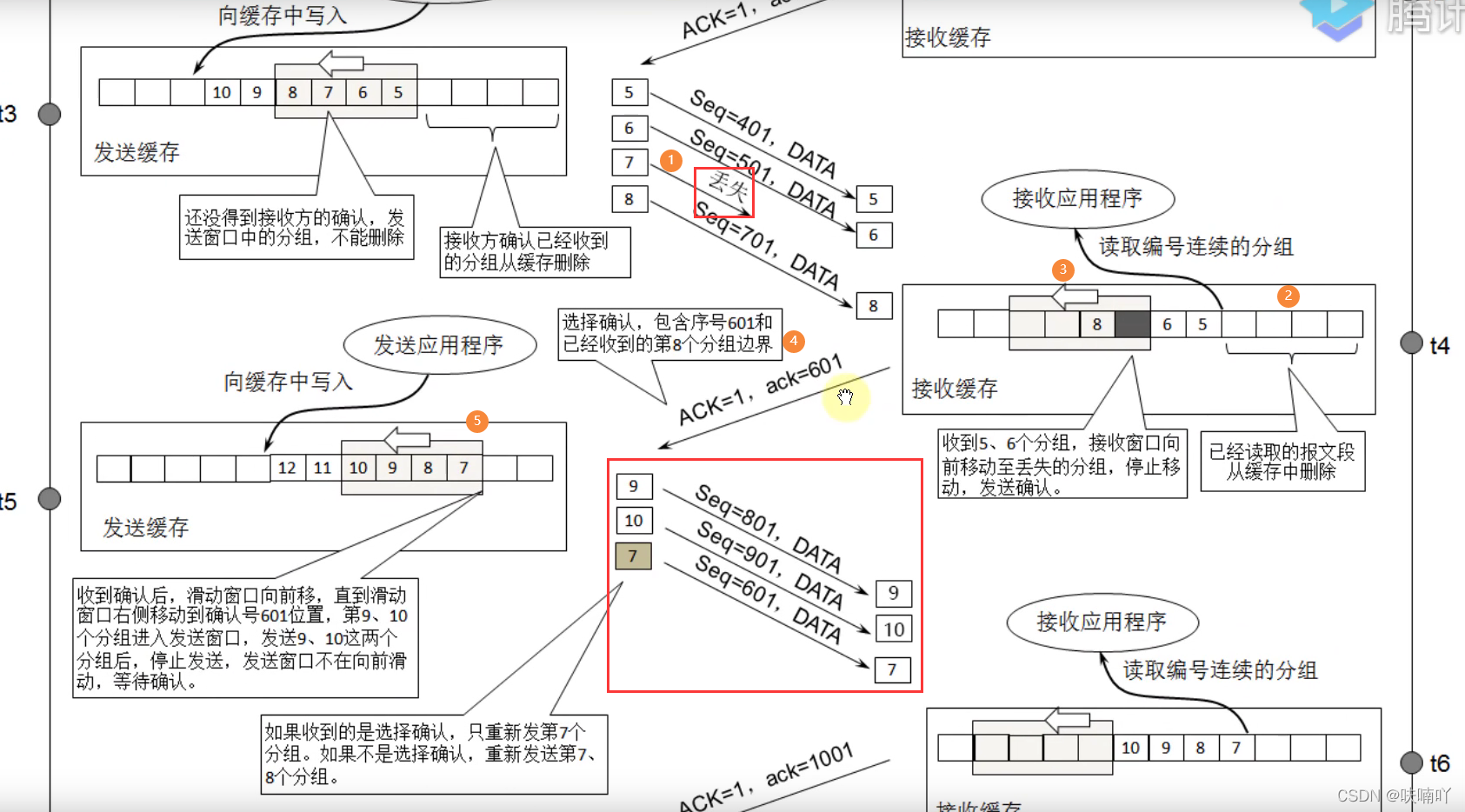
- 那么接下來我們在A發送5-8個包過去,此時假如發現第7個包丟失了;
- 那么計算機B中的滑動視窗就不會直接滑到第9個包開始了,而是滑動到丟失的第7個包開始;
- 并且計算機B回復確認包給A時候,也不會發送確認號為801,而是從601的確認號,如果發送801確認號,那么就表明前面的4個包B都收到,期待A從901開始發送,但實際上卻不是,因為丟失了一個601的包,所以確認好只能從601開始;
那么表面希望A從601開始發送,但是我們知道從601開始發送,一次發4個,一定會包含之前發送過的701資料包,那么也就是說,假如直接從601開始發送,那么701資料包就會重復發送,顯然這是浪費資源的,沒必要重發一個發過的包;
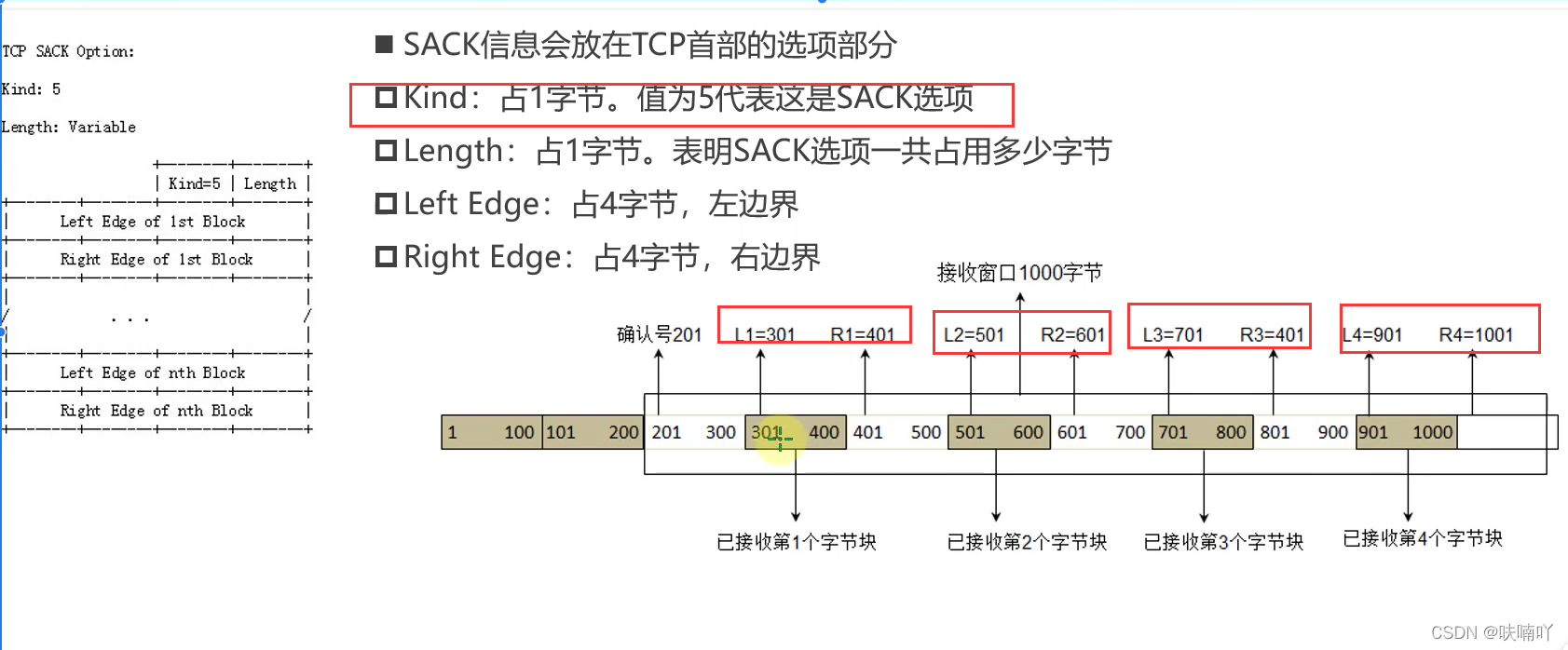
所以TCP保證發過的的包不重復發送,引入了一個機制為SACK機制,也叫選擇性確認機制,

如果有個包重傳N次還是失敗那么會一直重傳到成功嗎?
不會,一般都是重傳幾次,還是失敗后就不會重傳了,這一般都取決于作業系統的設定!
比如有些作業系統重傳5次還沒有收到確認包后,那么就不會再重傳這個包了!
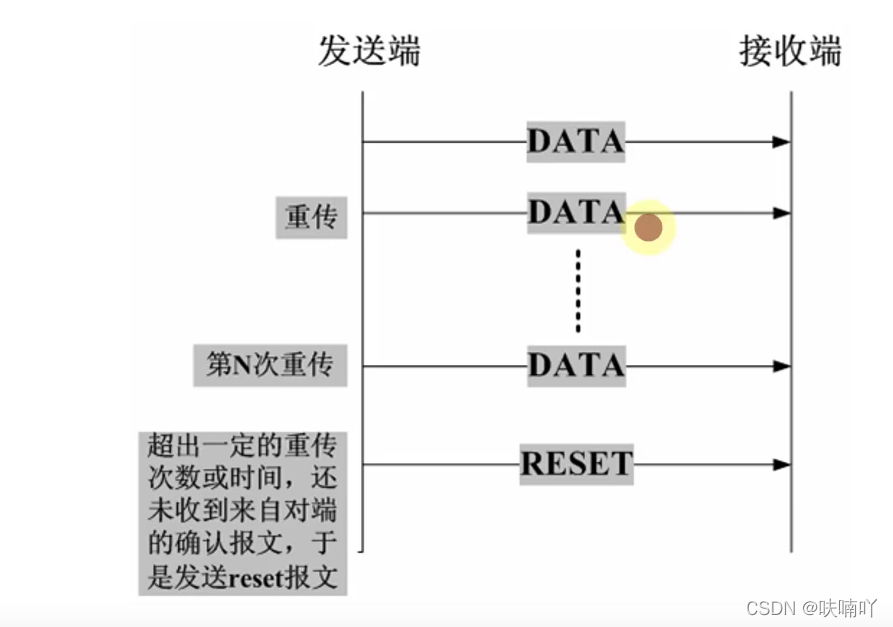
一般重傳N次還是沒有收到確認,那么就會發送一個報文首部欄位中RST為1,表示這個包傳輸失敗,即會斷開TCP連接!
TCP資料包為什么在傳輸層切片,不在網路層和資料鏈路層切片?
因為傳輸層可以保證可靠傳輸,在傳輸層把TCP大包切片,假如接受方收到的發送方的包不是完整的話,也就是說發送方發送的包有丟失的,那么就可以在傳輸層重新傳輸丟失的包,而不用重新傳輸整一個大包過去;
假如在網路層或者資料鏈路層切片,那么一旦接受方收到的TCP是不完整的,那么只能讓傳輸層重新傳送一個大的TCP包過去,很明顯丟的是少數的包,卻要傳送一個大包過去,效率及其低下,有人會問,為什么不在網路層或者資料鏈路層傳送過去丟失的包呢?因為網路層和資料鏈路層不保證可靠傳輸,沒有這個機制,也就無法確定是哪個包丟失了,只能從傳輸層重新傳!

接收視窗大小比發送的資料還要大,TCP會一直等資料填滿接收視窗嗎?
不會,因為TCP也是有一定的機制控制這個問題:
假如接收視窗時接收4個包,發送卻發了2個,接受方不會一直傻等,超過一定時間后發現沒有后序的包過來,那么就會發送一個確認包給發送方,確認收到了前面兩個包,

TCP流量控制
TCP的資料包,為什么需要流量控制,流量控制的背景來源于哪?
我們知道,接受方都會有一個接收快取區,也就是用來接收發送方發送過來的資料包的存盤區;
也就是說,假如我們的接收方的快取區滿了話,發送方還在源源不斷的發送過來給接受方,那么接收方就會丟棄發送方發過來溢位的快取區,為了保證資料不被丟棄,我們就需要控制發送方發送資料的數率,讓接受方來得及處理,

我們的視窗欄位,不是固定不變的,而是動態變化的,會根據網路的擁堵情況,發送資料速率情況而變化,這個視窗欄位一般可以控制TCP發送的速率!
TCP流量控制–特殊情況

TCP擁塞控制
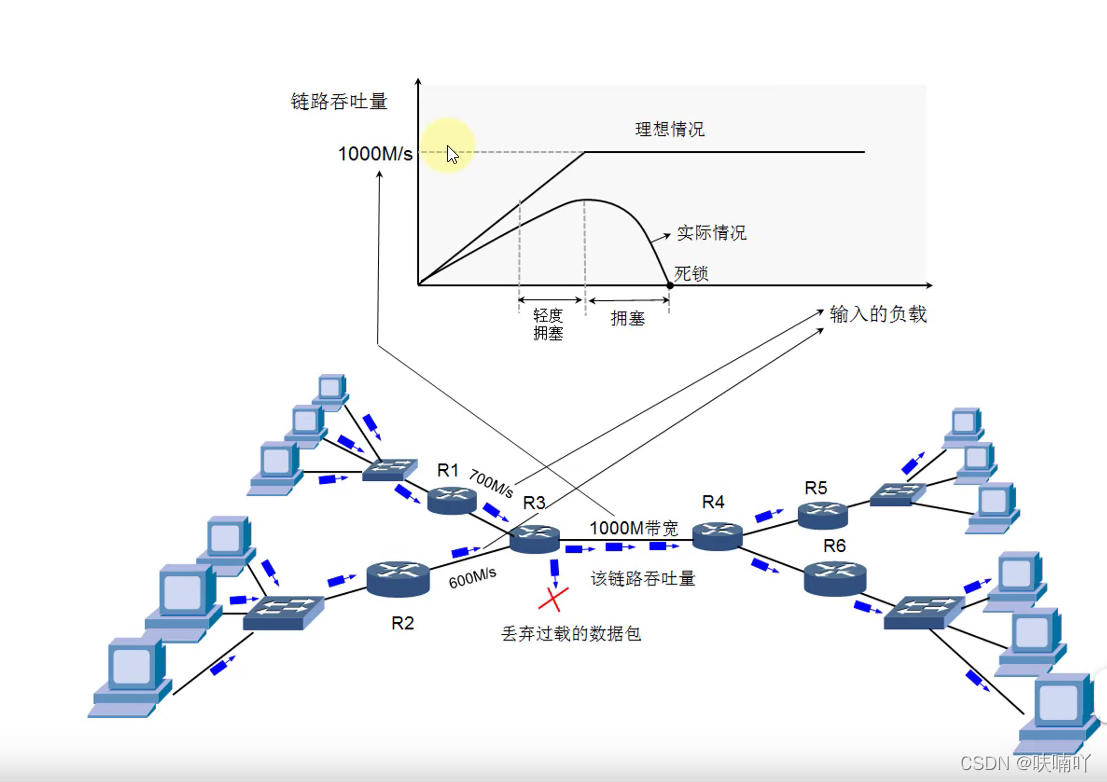
如上圖:假如通過R3路由器最大寬帶為1000M;那么R1和R2加起來的流量理論最大也為1000M;可是實際情況卻不是這樣,即使最大曠代為1000M,能通過該路由器R3也是不足1000M的,那么也就是說,通過R3會有擁塞情況!
當通過R3的寬帶越來越大時候,那么傳輸的資料包的速率就會增大的速率越來越低,到達一定的閾值后,假如害繼續增加傳輸的寬帶的話,那么傳輸速率就會開始降低,
就類似車道一樣,當車輛比較少時候,通過速度很快,當塞車時候,也是車很多時候,那么通過的速度就會變慢;
擁塞控制就是:防止過多的網路包傳入到網路中,避免路由過載!

擁塞控制時全域性的程序,需要各個主句路由器一起維護;而我們的流量控制,通常是點對點,傳輸層對傳輸層的結果!
TCP擁塞控制–方法
如何對TCP擁塞進行控制呢?我們有四種演算法來進行擁塞控制!

先看看幾個常見的縮寫:

MSS一般是TCP可選欄位才會出現,一般在建立連接時候會確定;
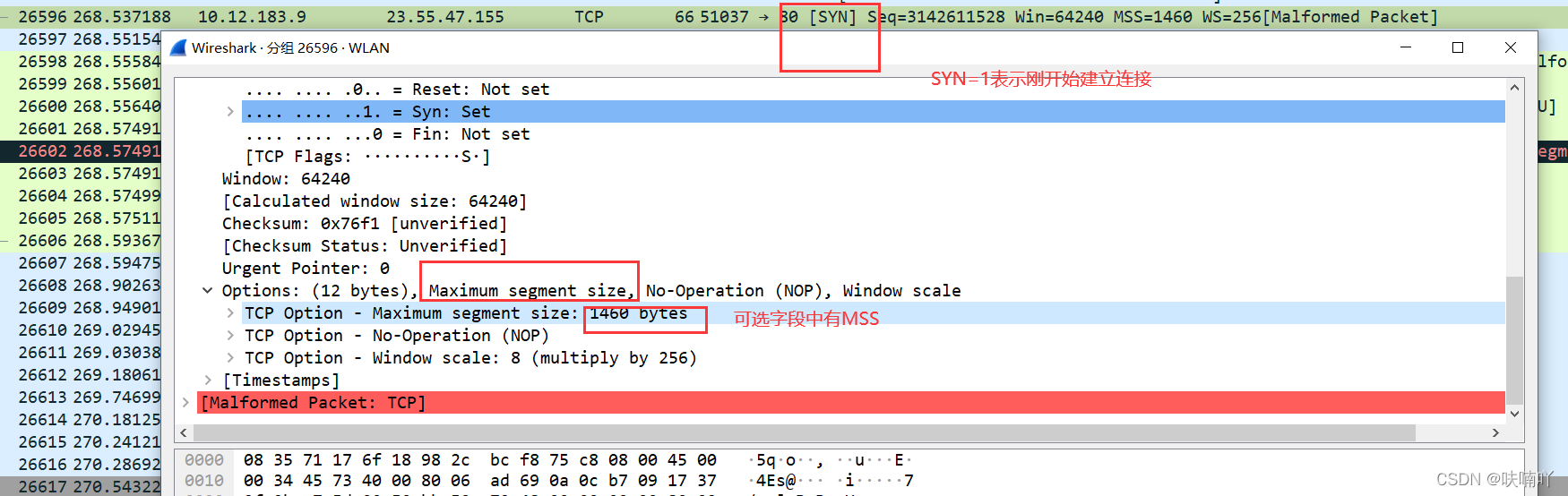
并且我們通常見到的TCP頭部都是20個位元組,一般在前兩次建立連接時候我們的TCP頭部會是32個位元組,比較常見的,多出的12個位元組是在可選部分的,一般存放一些其他資訊:
比如這里的建立連接的TCP包的可選部分,有一個資訊表示資料段的最大值是多少;
接收視窗:表示接收方的接收視窗一次最多可以接收多少位元組的資料;
擁塞視窗:它會變動的,其實就是根據網路情況變動,網路好時候,擁塞視窗比較大,網路不好擁塞視窗比較小;
發送視窗:表示發送方一次可以發送的多少個位元組資料的大小;通常發送視窗的值 = min(擁塞視窗,接收視窗)
比如發送方:有6000個位元組資料要發送,分6個包,每個包為1000個位元組,假如發送方的擁塞視窗為5000,而接收視窗的大小為3000;那么發送方的發送視窗的值就是接收視窗值得大小為3000;
也就是說發送方只能一次最多發3000個給接收方;
假如發送方擁塞視窗為2000,接受方的接收視窗為3000,那么發送視窗的為2000,即使接收方可以接收3000,但是用于網路狀況不好,擁塞視窗比較小,那么只能發送2000過去;
總的來說,擁塞視窗是可以根據網路狀況而發生變化,用來控制TCP的擁塞情況!
TCP擁塞控制–慢開始演算法
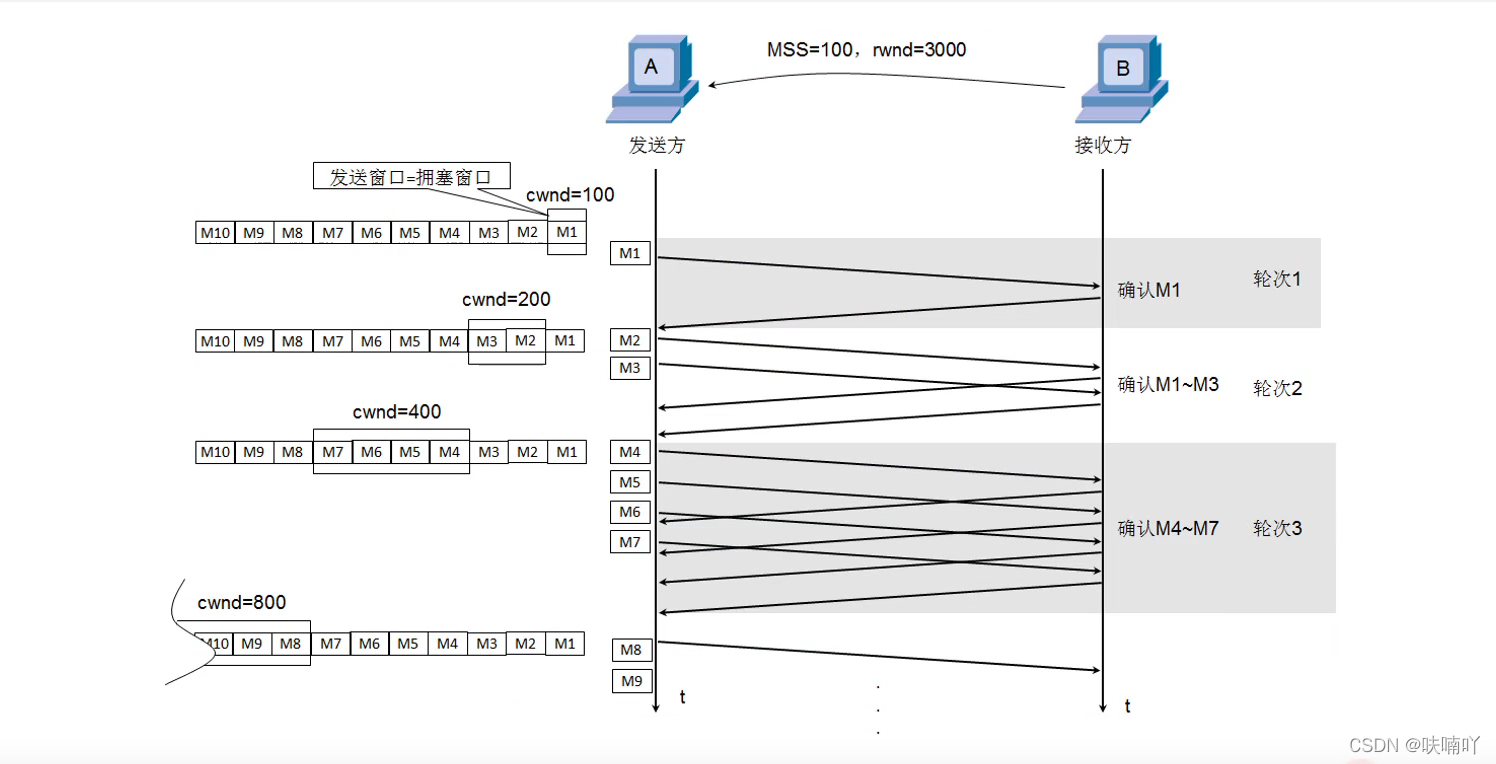
TCP如何進行擁塞控制的呢?
我們知道TCP為了保證效率,在建立連接后,不是一個包發送過去,再等對方一個確認再回來,而是多次發送對方接收視窗大小的資料,,然后再給回一個確認包,
但是TCP為了能夠擁塞控制,剛開始并不是直接一大堆包發送過去,而是使用一個包2個包4個包8個包,,,慢慢的去試探的,擁塞視窗也會慢慢的增大,也就是所謂的慢開始演算法,
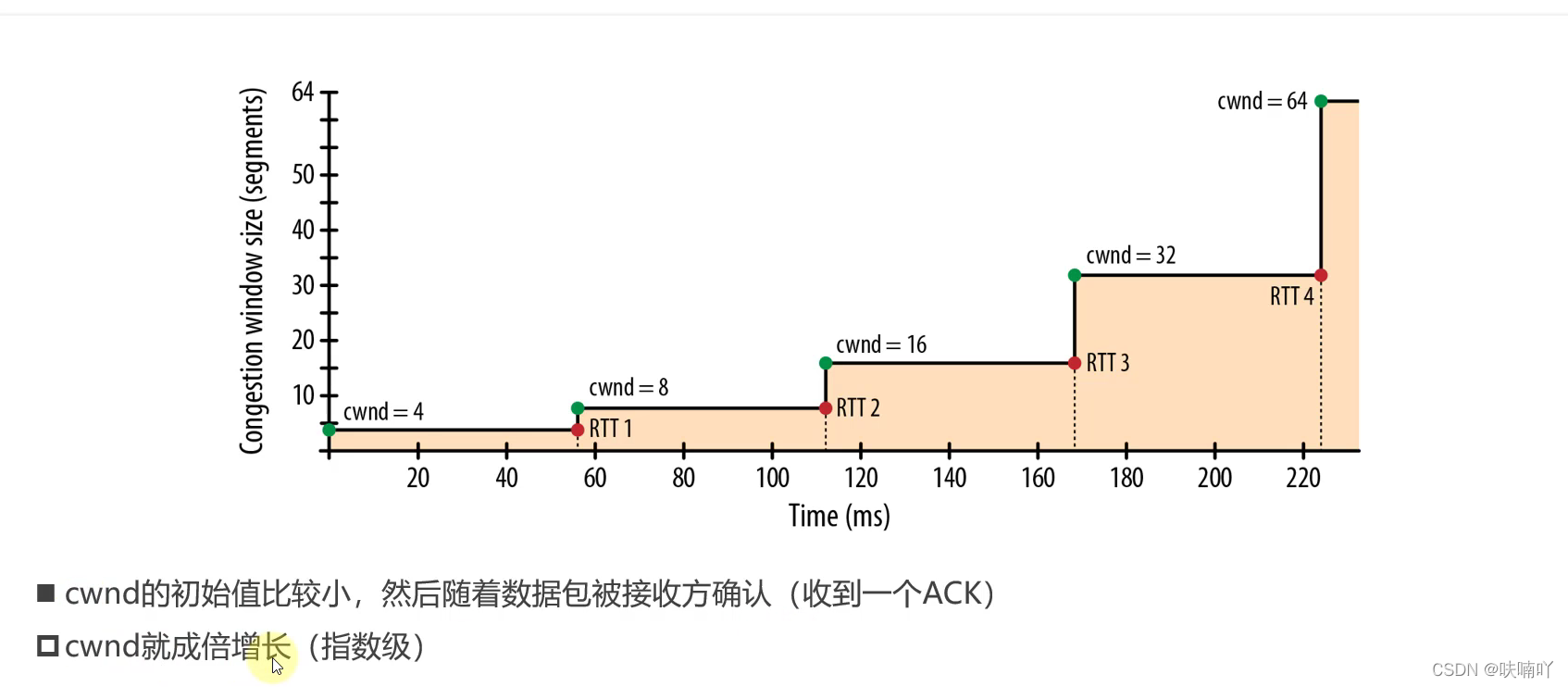
如上圖,顯示,這就是慢開始,那什么時候知道增加到的資料包到一定層度就發現網路擁塞了呢?
很容易,只要發現丟包了,就可以開始發現差不多是到達網路擁塞點了,發送方一直發送包過去,接收方都還沒有確認包回來,這時候就可以認為是網路擁塞了,
TCP擁塞控制–擁塞避免演算法
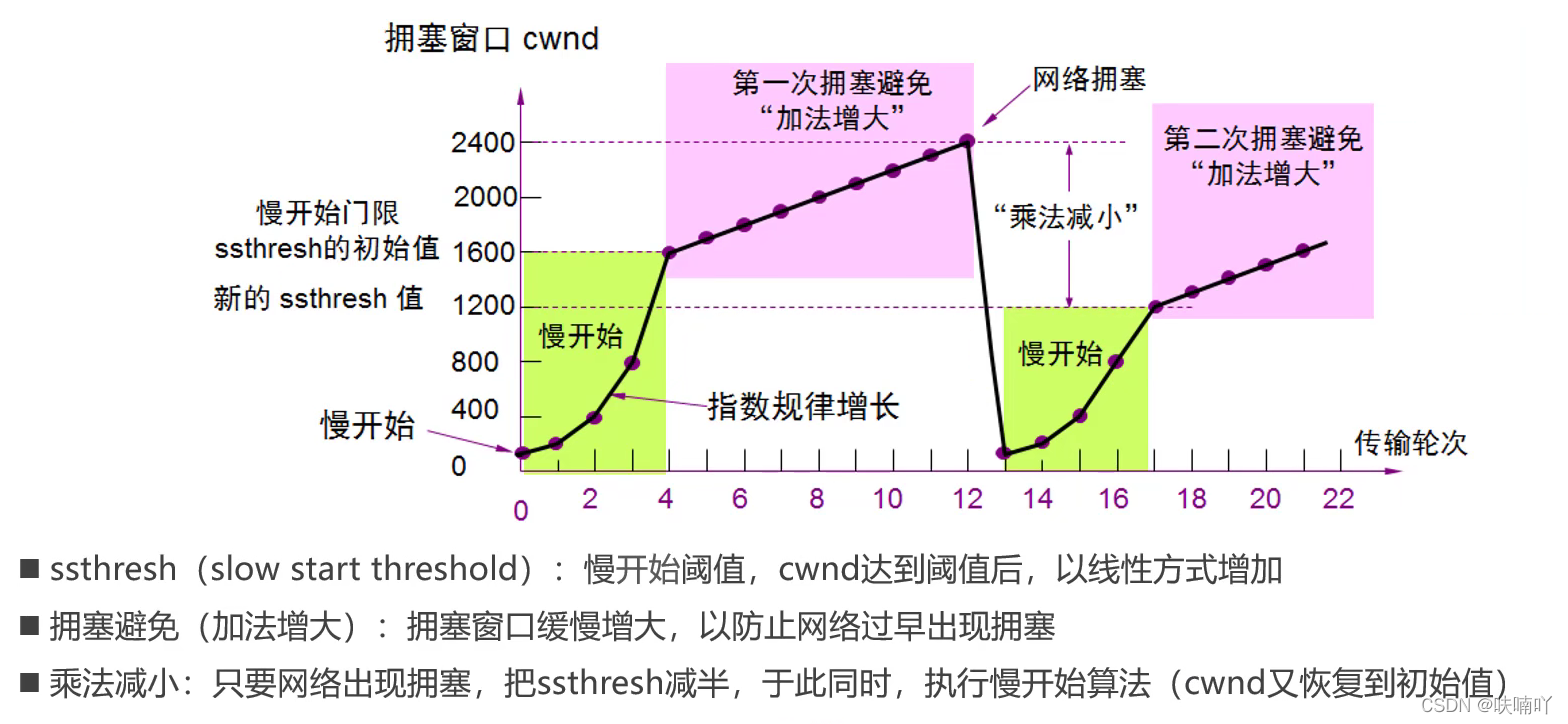
我們的TCP里面會設定一個閾值,也就是cwnd的閾值,ssthresh,一旦發現cwnd的值達到了該閾值,那么TCP包發送的速率就不會指數增長,就會開始線性增長,也就是所謂的以第一擁塞避免方式,加法增大演算法;
當增大到一定的值,也就是網路狀態不好時候,這時候就可能會丟包,然后TCP包發送速率也就會開始降低,也會把擁塞的峰值減半,如上圖峰值為2400,減半到1200;也就是所謂的乘法減少,就是乘于0.5倍的減少峰值,再開始慢開始演算法,
TCP擁塞控制–快重傳演算法
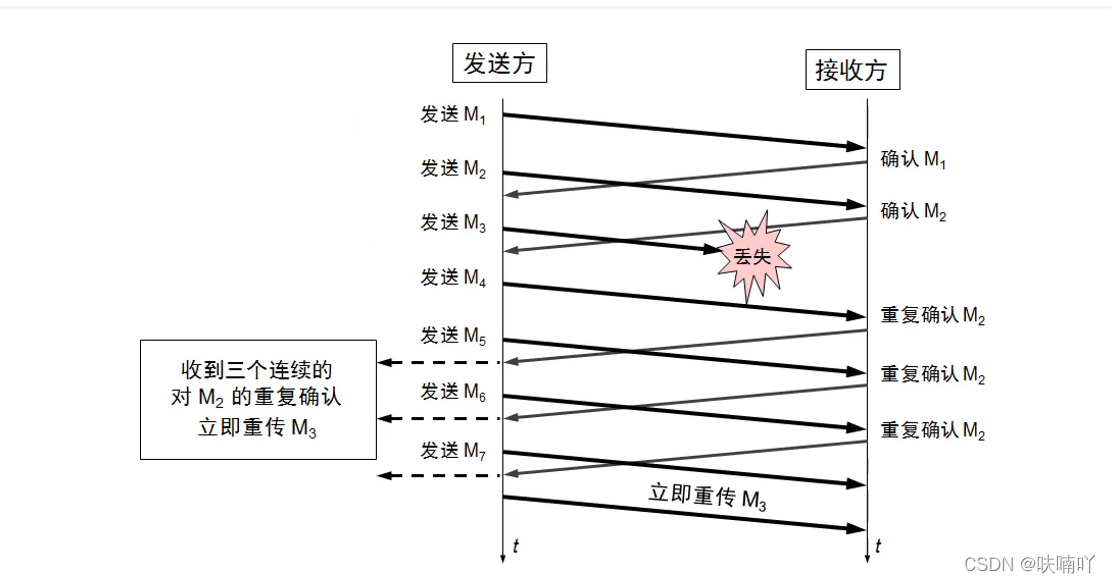
如上圖,發送方發送了一個M1包,接收方收到并回復確認包給發送方,
當發送方給接收方發送M3時候,丟失了,發送方還是會繼續發送下個M4M5M6過去,但是接收方卻不會回復確認收到M4M5M6的包過去,只會一直重復確認M2的包,表示希望發送方給我發送M3的包過來,M2的包我收到了,當接收方回復3次確認包M2給發送方時候,此時發送方就會意識到,自己的M3包已經丟失,必須重新傳,這就是快重傳;
假如沒有快重傳機制,也就是之前我們在可靠傳輸的超時重傳機制,那么接收方不會繼續發送M4M5M6,而是等待接收方發送確認收到M3包過來才會繼續,假如沒有收到,那么就會等待一定時間再重傳,然后重傳結束后再繼續傳接下來的M4M5M6,

TCP擁塞控制–擁塞避免+快重傳
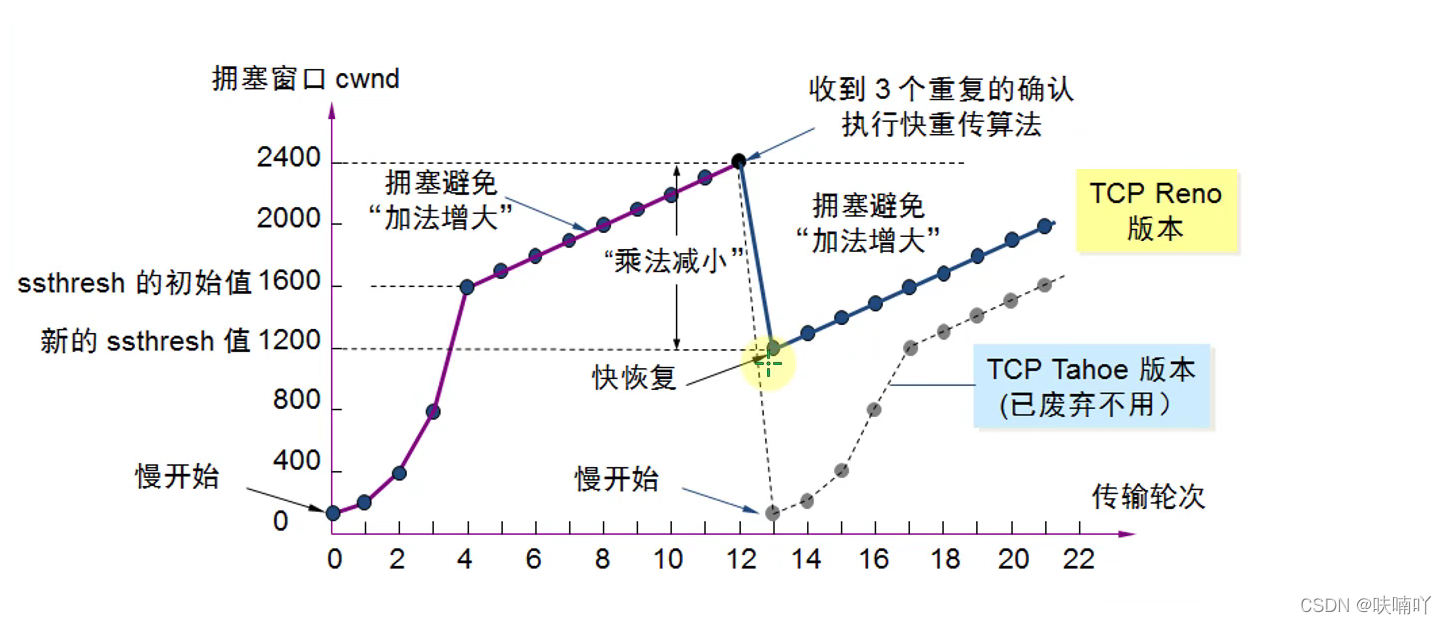
當rwnd的值達到了峰值時候,也就是發生快重傳時候就能夠知道rwnd是達到網路峰值了,這是候就會開始乘法減小,峰值減半,并且ssthresh閾值也開始減小,減小多少都是TCP設計者規定的,然后開始擁塞避免演算法,線性增加rwnd的值,此時不會開始慢開始演算法了,這種演算法被拋棄了,因為效率不夠高;
TCP–擁塞控制–快恢復演算法

轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384270.html
標籤:其他
上一篇:【資料結構】-排序-快速排序
下一篇:二叉樹oj練習打卡