錄
- 一、Selenium
- 1.1 簡介
- 1.2 配置
- 二、對百度進行自動化測驗
- 2.1 進入百度搜索界面
- 2.2 自動填充百度網頁的查詢關鍵字并完成自動搜索
- 三、爬取指定網頁的名言
- 3.1 找到元素
- 3.2 代碼實作
- 3.3 運行結果
- 四、Selenium:requests+Selenum爬取京東圖書
- 4.1 查看頁面元素
- 4.2 代碼
- 4.3 運行
- 小小的總結
- 參考文獻
注:因為某些原因,原本的圖片被判定為違規,咱就說很委屈,
Github源檔案下載:https://github.com/longl118/Selenium
一、Selenium
1.1 簡介
Selenium是一個Web的自動化測驗工具,最初是為網站自動化測驗而開發的,型別像我們玩游戲用的按鍵精靈,可以按指定的命令自動操作,不同是Selenium 可以直接運行在瀏覽器上,它支持所有主流的瀏覽器(包括PhantomJS這些無界面的瀏覽器),
Selenium 可以根據我們的指令,讓瀏覽器自動加載頁面,獲取需要的資料,甚至頁面截屏,或者判斷網站上某些動作是否發生,
Selenium 自己不帶瀏覽器,不支持瀏覽器的功能,它需要與第三方瀏覽器結合在一起才能使用,但是我們有時候需要讓它內嵌在代碼中運行,所以我們可以用一個叫 PhantomJS 的工具代替真實的瀏覽器,
1.2 配置
- 安裝依賴
要開始使用selenium,需要安裝一些依賴,打開Anaconda Prompt
conda install selenium
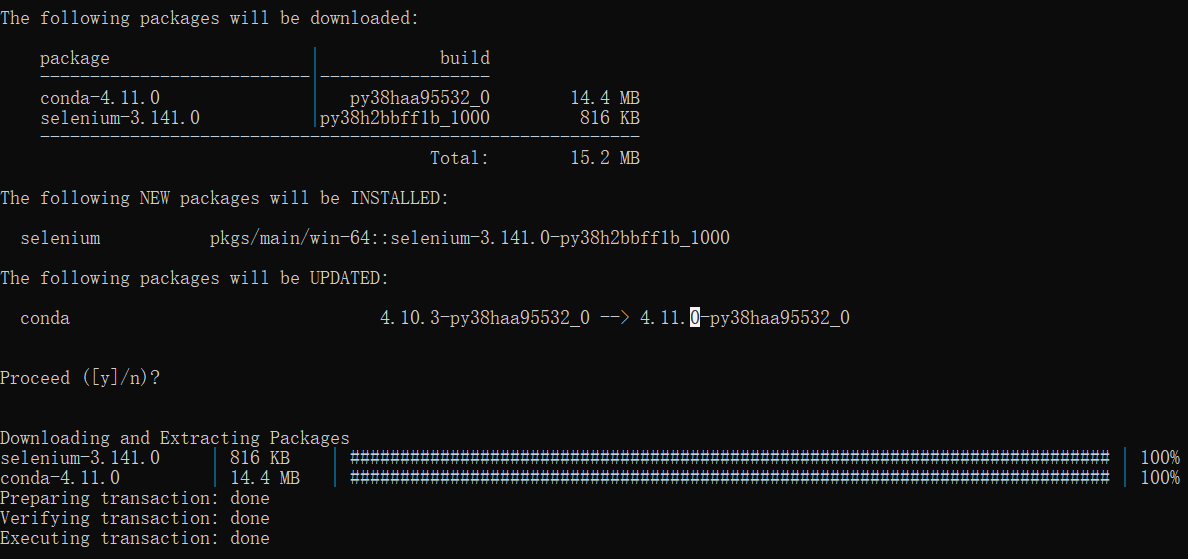
- 安裝驅動
要使用selenium去呼叫瀏覽器,還需要一個驅動,不同瀏覽器的webdriver需要獨立安裝
各瀏覽器下載地址:selenium官網驅動下載(https://www.selenium.dev/downloads/)
Firefox瀏覽器驅動:geckodriver
Chrome瀏覽器驅動:chromedriver , taobao備用地址
IE瀏覽器驅動:IEDriverServer
Edge瀏覽器驅動:MicrosoftWebDriver
Opera瀏覽器驅動:operadriver
PhantomJS瀏覽器驅動:phantomjs
- 筆主這里下載 Chrome的 https://npm.taobao.org/mirrors/chromedriver/
- 進去下載
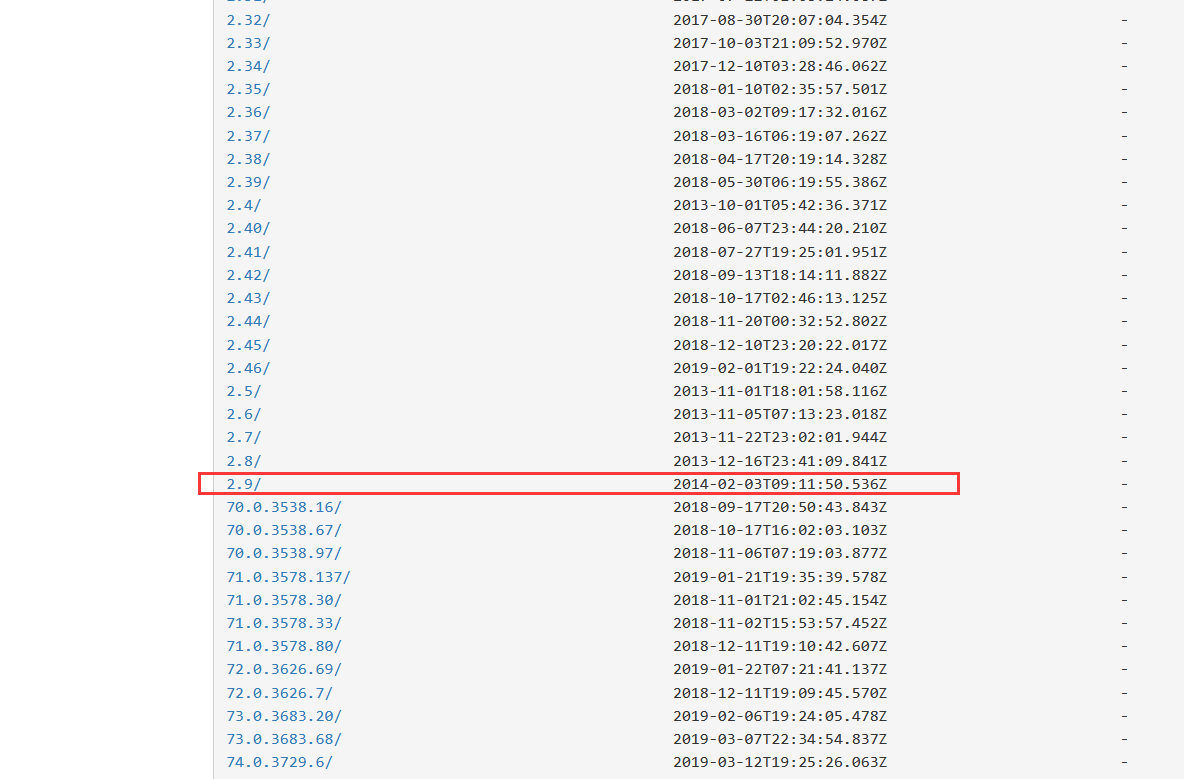
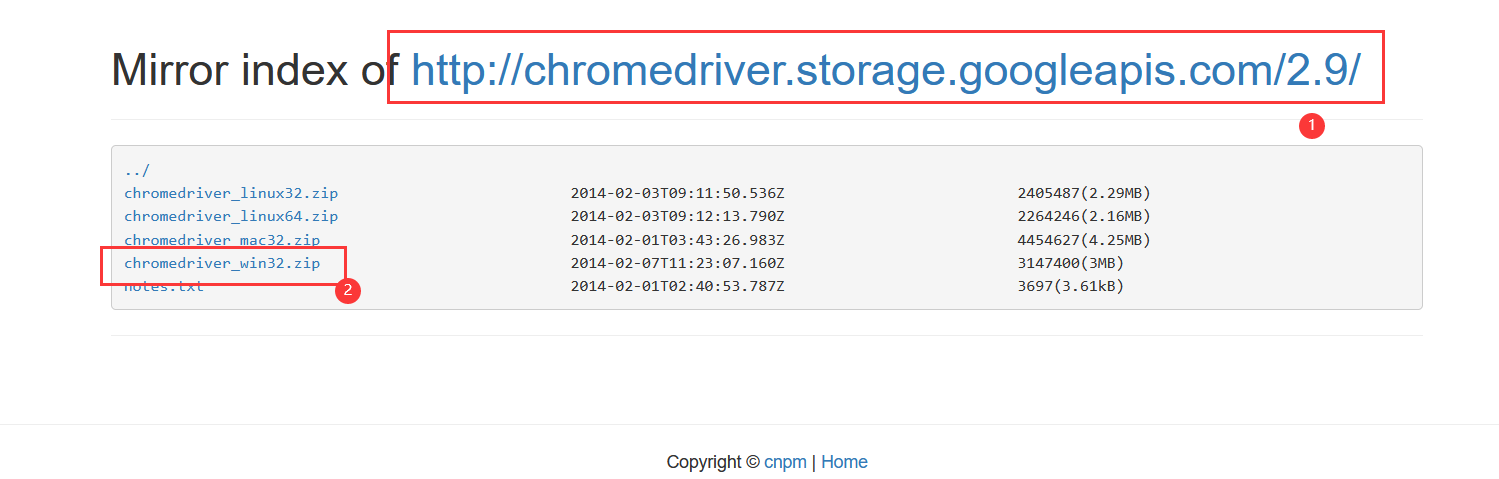
- 下載后解壓,將解壓的chromedriver.exe檔案添加到系統的環境變數(不知道有沒有用,大佬的博客都是這樣做的)
二、對百度進行自動化測驗
2.1 進入百度搜索界面
- 在Anaconda的jupyter中寫入代碼
from selenium import webdriver
driver=webdriver.Chrome('D:\\***\\chromedriver.exe')
#進入網頁
driver.get("https://www.baidu.com/")
- 這時會報錯,我們就再次打開Anaconda Prompt,安裝webdriver_manager:
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
#進入網頁
driver.get("https://www.baidu.com/")
- 運行得到:
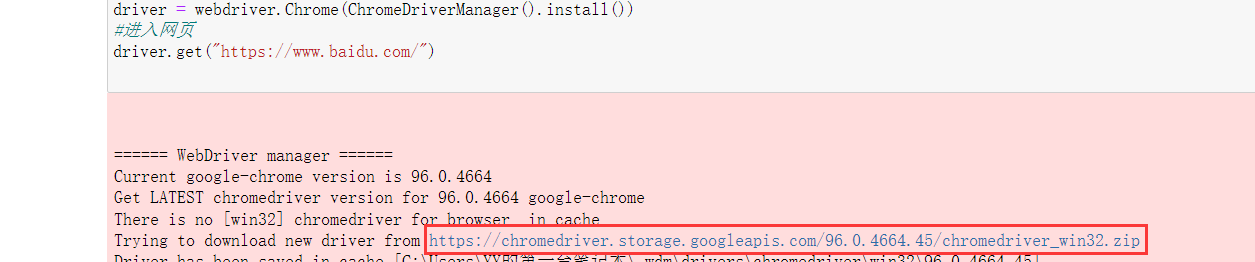
- 點擊那個鏈接,得到:

2.2 自動填充百度網頁的查詢關鍵字并完成自動搜索
- 在百度頁面右鍵,點擊 檢查
- 我們可以看到 搜索框的id是 kw

- 用代碼找到該元素,并填取相應的值
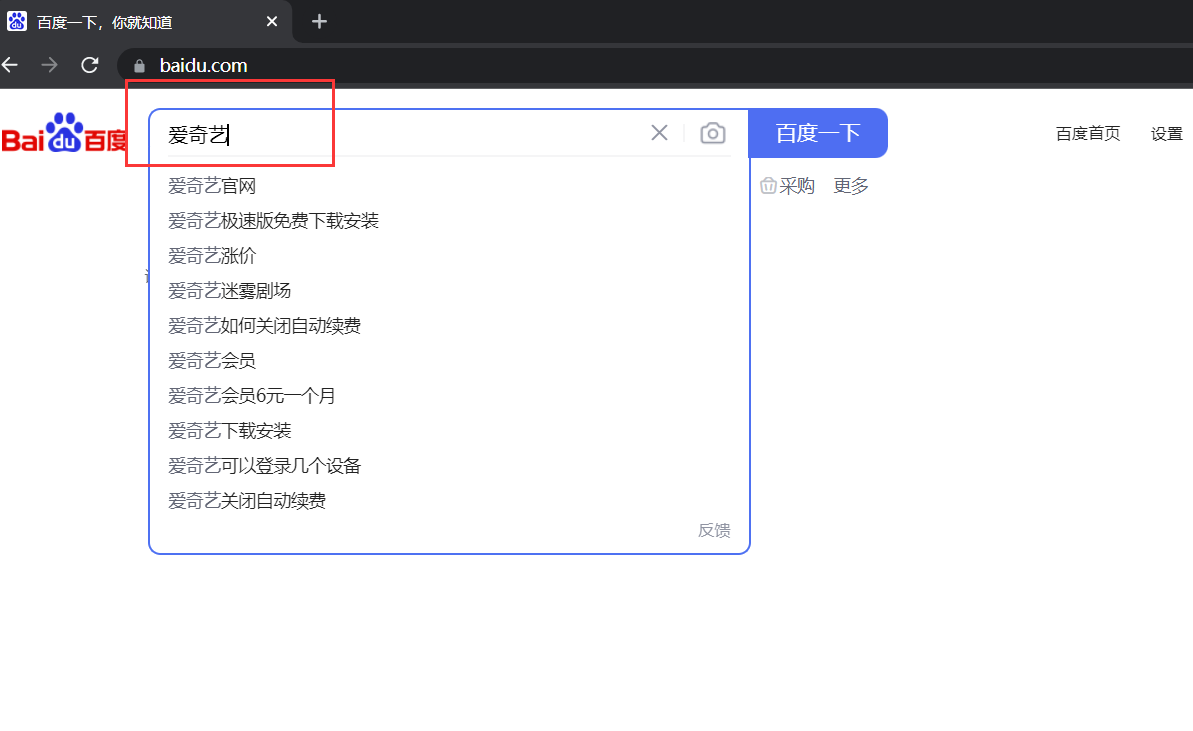
p_input = driver.find_element_by_id("kw")
p_input.send_keys('愛奇藝')
- 運行結果
- 同樣找到搜索按鈕的 id ,為su

- 點擊該按鈕
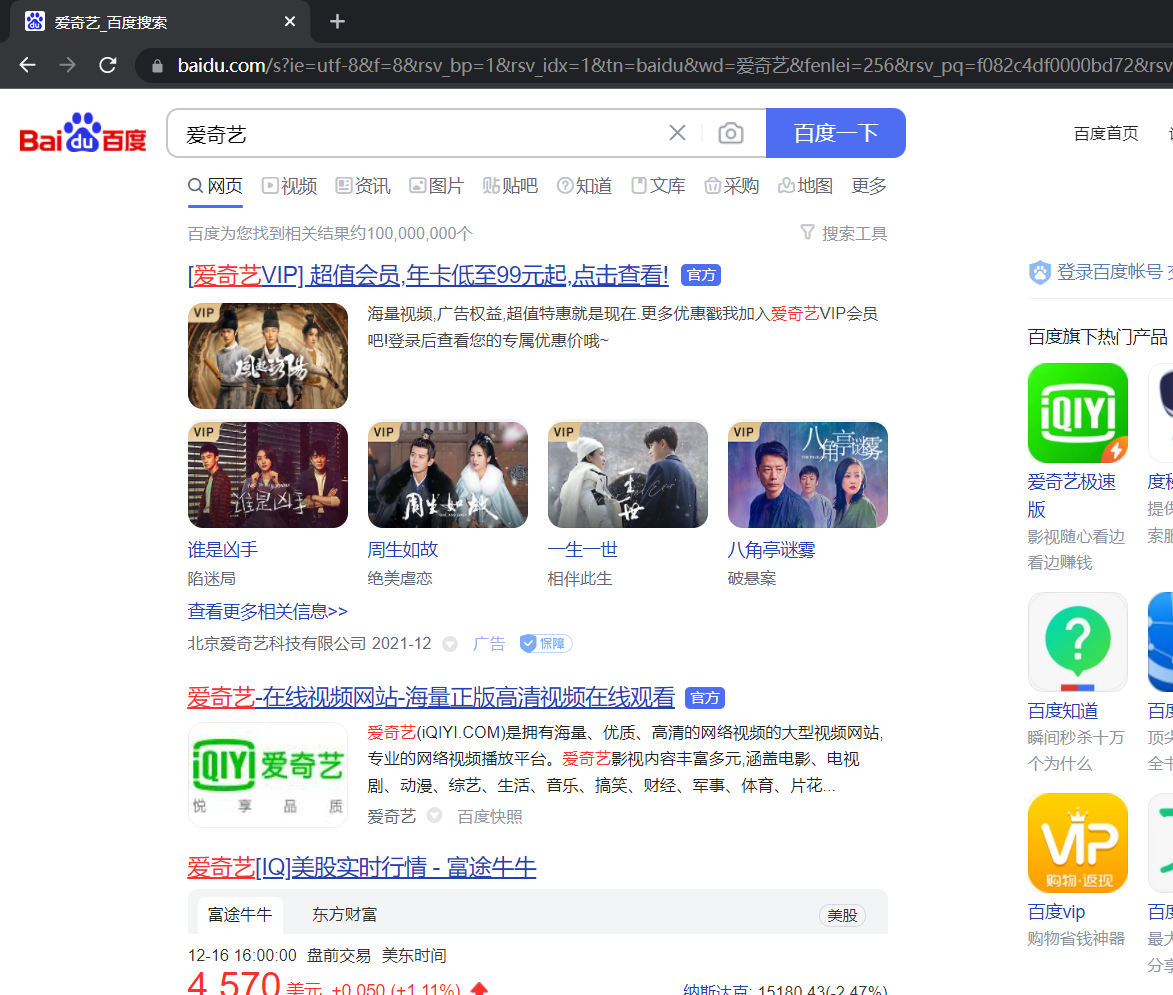
#點擊搜索按鈕
p_btn=driver.find_element_by_id('su')
p_btn.click()
- 運行結果
三、爬取指定網頁的名言
3.1 找到元素
- 網頁:http://quotes.toscrape.com/page/1/
- 選擇一段名言,右鍵
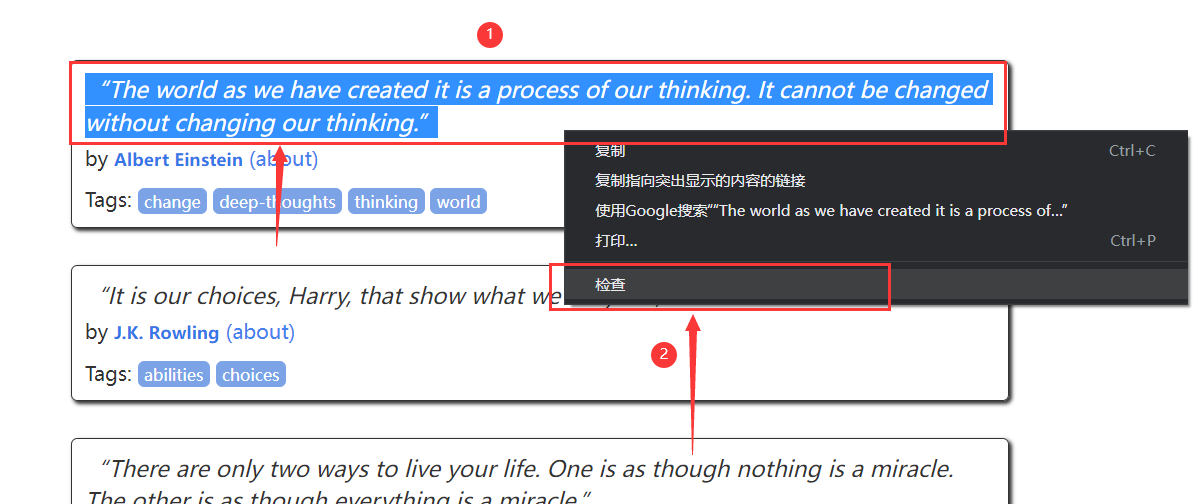
- 可以看到class為text

3.2 代碼實作
- 代碼
from bs4 import BeautifulSoup as bs
from selenium import webdriver
import csv
from selenium.webdriver.chrome.options import Options
from tqdm import tqdm#在電腦終端上顯示進度,使代碼可視化進度加快
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get('http://quotes.toscrape.com/js/')
#定義csv表頭
quote_head=['名言','作者']
#csv檔案的路徑和名字
quote_path='C:\\Users\\28205\\Documents\\Tencent Files\\2820535964\\FileRecv\\quote_csv.csv'
#存放內容的串列
quote_content=[]
'''
function_name:write_csv
parameters: csv_head,csv_content,csv_path
csv_head: the csv file head
csv_content: the csv file content,the number of columns equal to length of csv_head
csv_path: the csv file route
'''
def write_csv(csv_head,csv_content,csv_path):
with open(csv_path, 'w', newline='') as file:
fileWriter =csv.writer(file)
fileWriter.writerow(csv_head)
fileWriter.writerows(csv_content)
print('爬取資訊成功')
###
#可以用find_elements_by_class_name獲取所有含這個元素的集合(串列也有可能)
#然后把這個提取出來之后再用繼續提取
quote=driver.find_elements_by_class_name("quote")
#將要收集的資訊放在quote_content里
for i in tqdm(range(len(quote))):
quote_text=quote[i].find_element_by_class_name("text")
quote_author=quote[i].find_element_by_class_name("author")
temp=[]
temp.append(quote_text.text)
temp.append(quote_author.text)
quote_content.append(temp)
write_csv(quote_head,quote_content,quote_path)
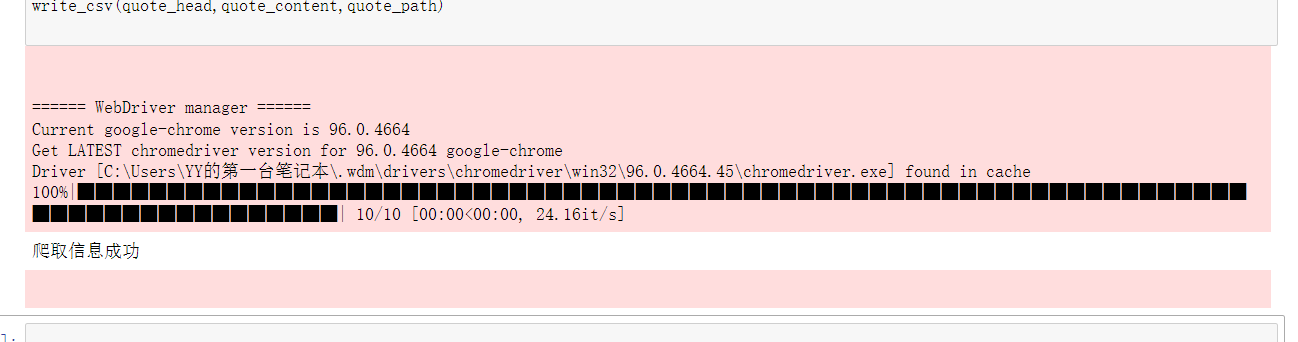
3.3 運行結果
- 運行結果
- csv檔案:
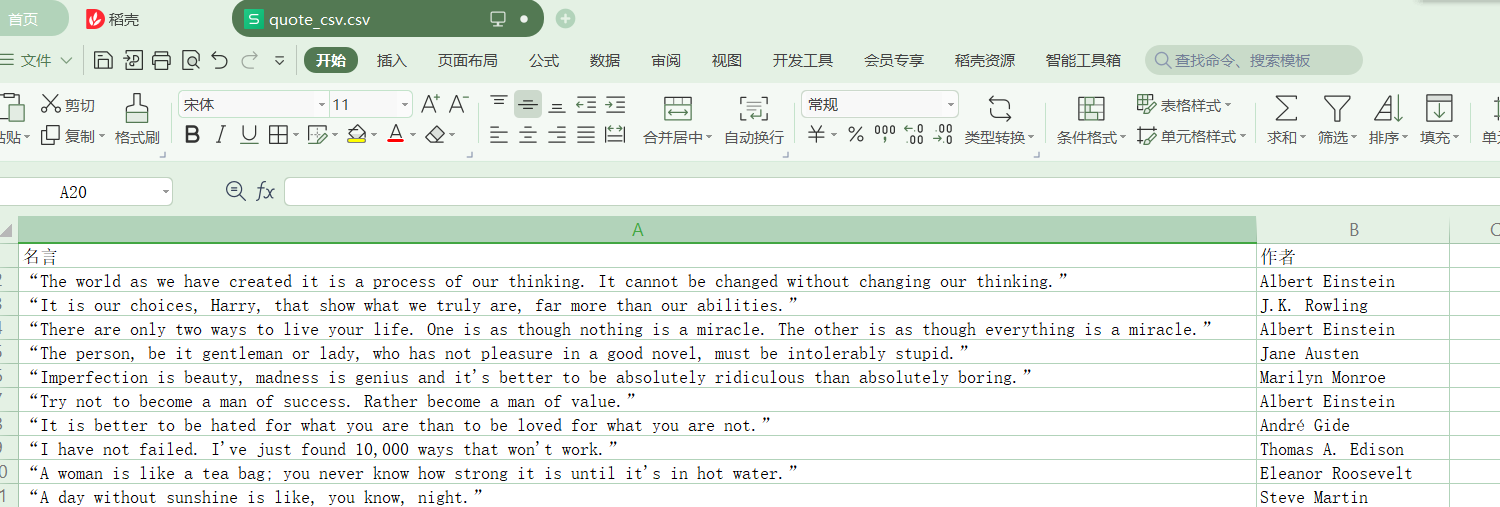
四、Selenium:requests+Selenum爬取京東圖書
4.1 查看頁面元素
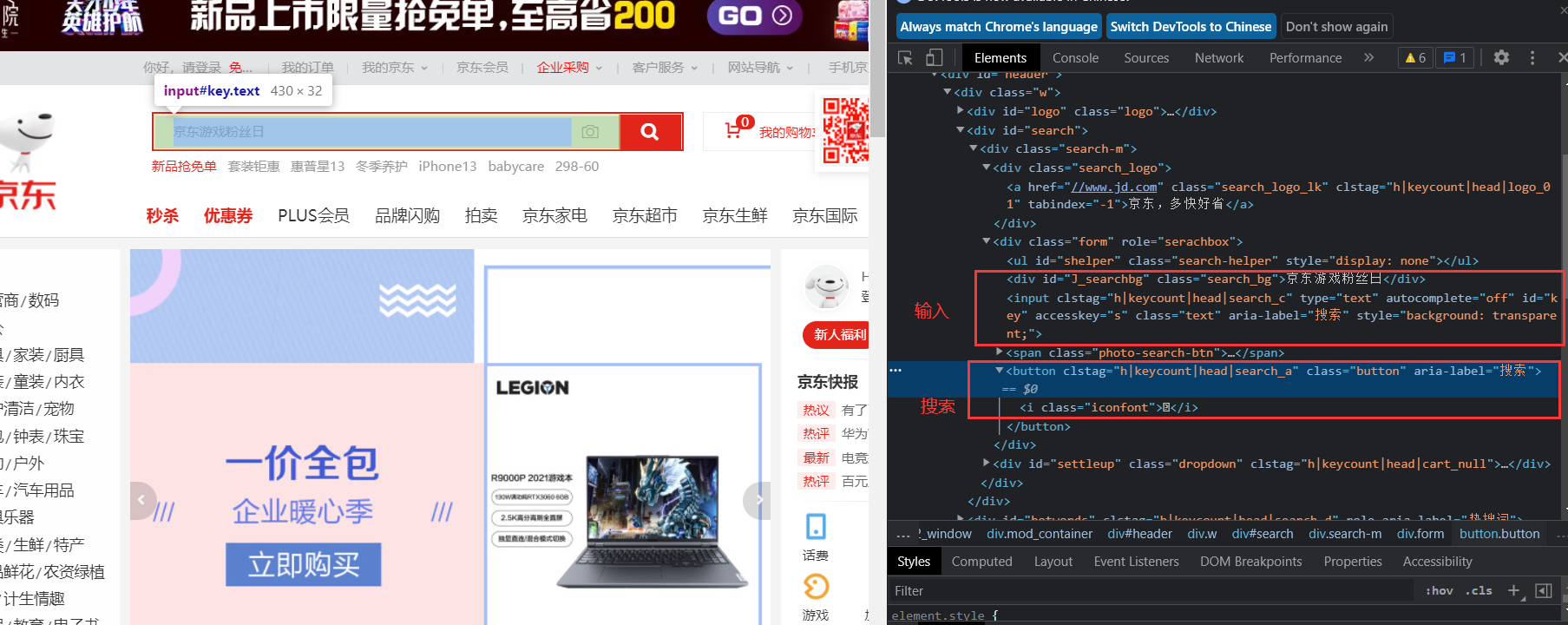
- 打開京東頁面查看頁面元素,分析需要爬取資訊的標簽id:
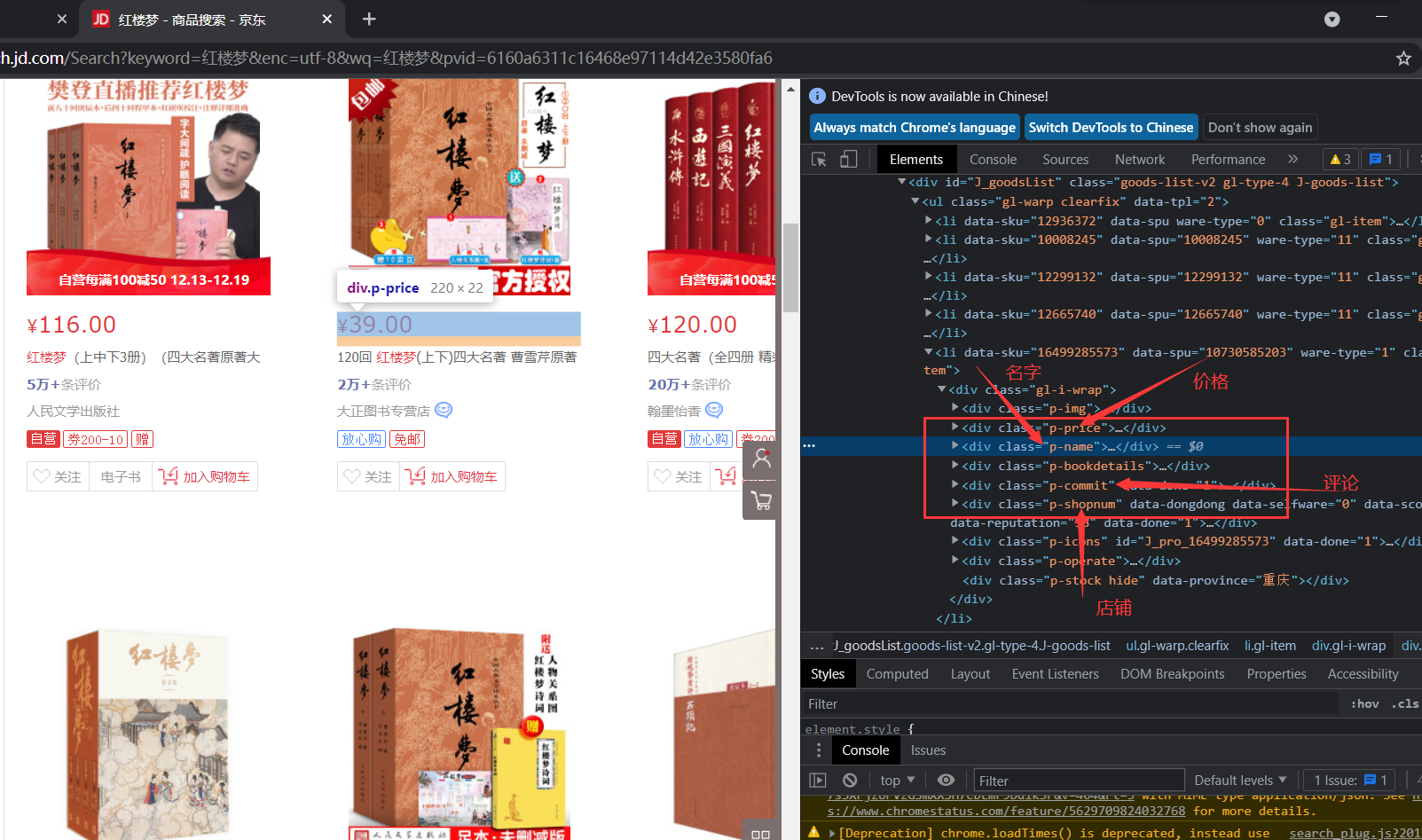
- 搜索紅樓夢,查看元素
4.2 代碼
from selenium import webdriver
import time
import csv
from tqdm import tqdm#在電腦終端上顯示進度,使代碼可視化進度加快
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(ChromeDriverManager().install())
#加載頁面
driver.get("https://www.jd.com/")
time.sleep(3)
#定義存放圖書資訊的串列
goods_info_list=[]
#爬取200本
goods_num=200
#定義表頭
goods_head=['名字','價格','評價條數','店鋪','鏈接']
#csv檔案的路徑和名字
goods_path='D:\\1azanshi\\a\\honglou1.csv'
#向輸入框里輸入Java
p_input = driver.find_element_by_id("key")
p_input.send_keys('紅樓夢')
#button好像不能根據類名直接獲取,先獲取大的div,再獲取按鈕
from_filed=driver.find_element_by_class_name('form')
s_btn=from_filed.find_element_by_tag_name('button')
s_btn.click()#實作點擊
#獲取商品名字,價格,評價條數,店鋪,鏈接
def get_prince_and_name(goods):
#直接用css定位元素
#獲取名字
goods_price=goods.find_element_by_css_selector('div.p-name')
#獲取價格
goods_name=goods.find_element_by_css_selector('div.p-price')
#獲取評價條數
goods_commit=goods.find_element_by_css_selector('div.p-commit')
#獲取店鋪名稱
goods_shopnum=goods.find_element_by_css_selector('div.p-shopnum')
#獲取鏈接
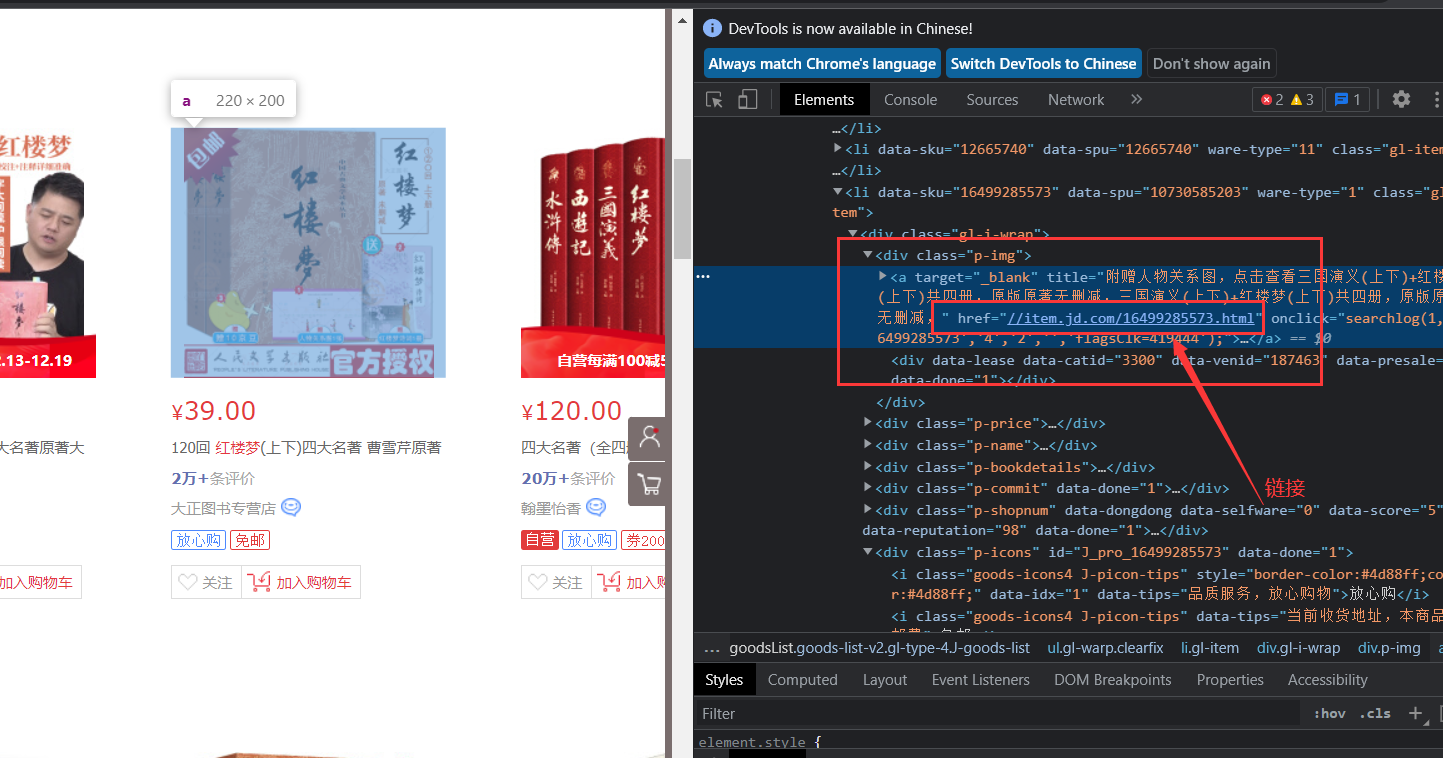
goods_herf=goods.find_element_by_css_selector('div.p-img>a').get_property('href')
return goods_name,goods_price,goods_commit,goods_shopnum,goods_herf
def drop_down(web_driver):
#將滾動條調整至頁面底部
web_driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(3)
#獲取爬取一頁
def crawl_a_page(web_driver,goods_num):
#獲取圖書串列
drop_down(web_driver)
goods_list=web_driver.find_elements_by_css_selector('div#J_goodsList>ul>li')
#獲取一個圖書的價格、名字、鏈接
for i in tqdm(range(len(goods_list))):
goods_num-=1
goods_price,goods_name,goods_commit,goods_shopnum,goods_herf=get_prince_and_name(goods_list[i])
goods=[]
goods.append(goods_price.text)
goods.append(goods_name.text)
goods.append(goods_commit.text)
goods.append(goods_shopnum.text)
goods.append(goods_herf)
goods_info_list.append(goods)
if goods_num==0:
break
return goods_num
while goods_num!=0:
goods_num=crawl_a_page(driver,goods_num)
btn=driver.find_element_by_class_name('pn-next').click()
time.sleep(1)
write_csv(goods_head,goods_info_list,goods_path)
4.3 運行
- 運行效果
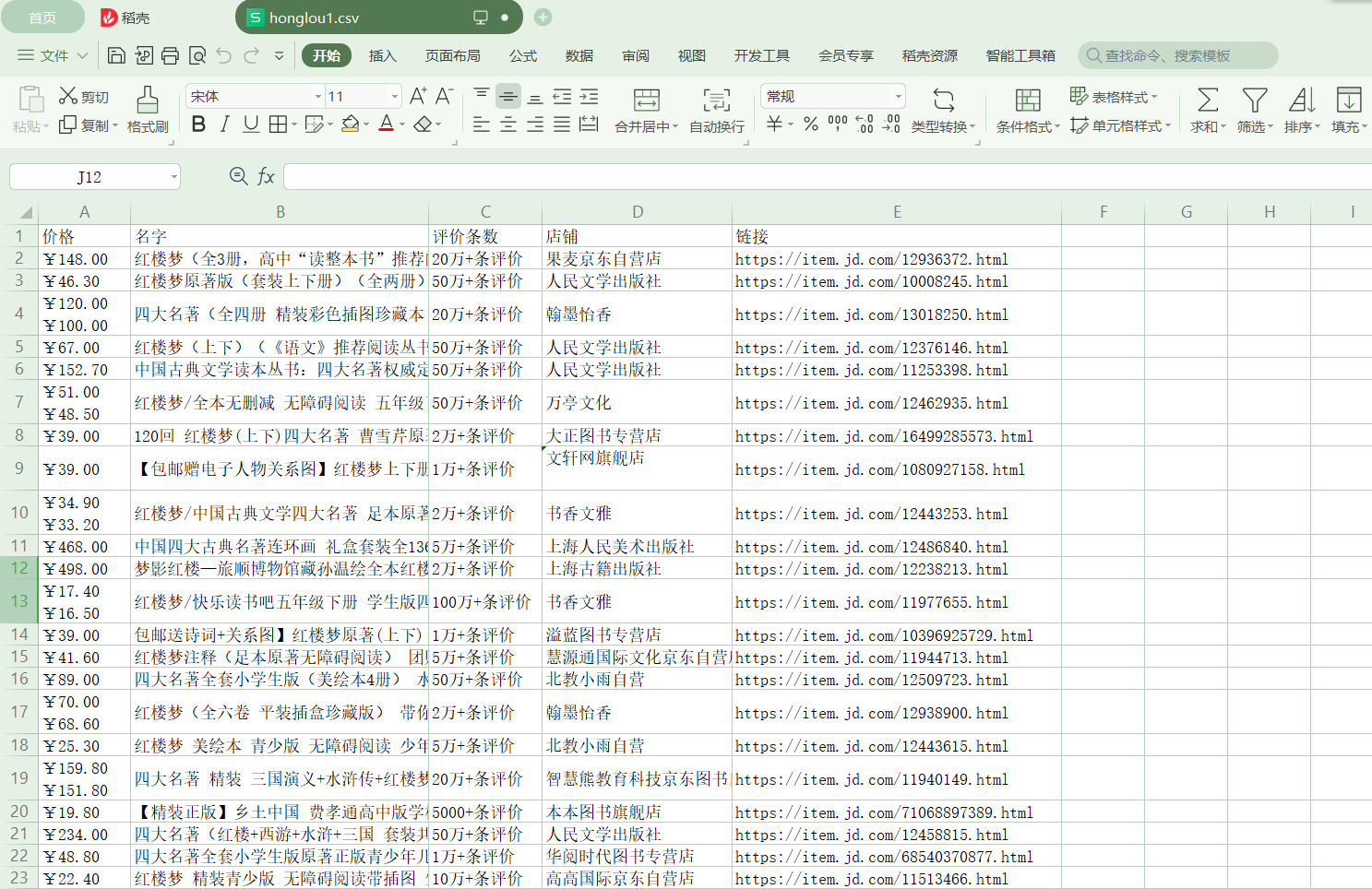
- .csv檔案
小小的總結
- 運行看自己的電腦被操縱,莫名有點有趣,
- 本次實驗,完成動態網頁的資訊爬取,和靜態網頁一樣需要查看網頁結構,找到元素id或者利用相關函式得到元素,最后將資訊獲取,存盤,以及對Selenium爬取網頁的原理程序也有一定的了解,
參考文獻
- 動態網頁爬蟲:https://blog.csdn.net/qq_45659777/article/details/121722475
- Python+Selenium動態網頁的資訊爬取:
https://blog.csdn.net/weixin_56102526/article/details/121870172 - 動態網頁的資訊爬取:https://blog.csdn.net/qq_46359931/article/details/121918256
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384406.html
標籤:其他
上一篇:netty 物聯網專案總結