點擊下方卡片,關注“OpenCV與AI深度學習”公眾號!
視覺/影像重磅干貨,第一時間送達!
導讀
本文主要為大家分享OpenCV4.5.4中語音識別實體的使用(驗證)與注意事項,
背景介紹
OpenCV4.5.4的DNN模塊中新增了對語音識別的支持,本文以Python版本實體來做驗證介紹,
使用步驟
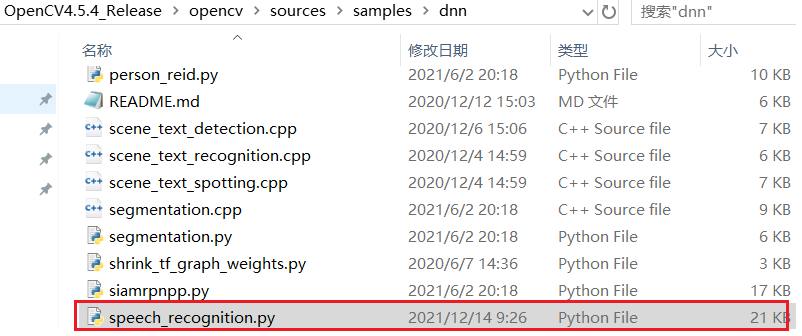
Python-OpenCV實體代碼位置:OpenCV4.5.4_Release\opencv\sources\samples\dnn\speech_recognition.py
使用步驟:
【1】下載語音識別模型:
https://drive.google.com/drive/folders/1wLtxyao4ItAg8tt4Sb63zt6qXzhcQoR6

模型下載jasper_reshape.onnx,然后重命名為:jasper.onnx,放到py檔案同目錄
【2】下載測驗音頻:
如上圖中下載audio6.flac和audio6.flac,初步測驗發現程式不支持mp3格式音頻,需轉為flac或wav格式,其他格式暫未嘗試,
【3】安裝soundfile包:
pip install soundfile 即可,
【4】cmd命令列運行:
python speech_recognition.py --input_audio=./audio/audio6.flac
audio6.flac音頻:00:00/00:11
audio6.flac識別結果:

Predicting...Audio file 1/1['an american instead of going in a leisure hour to dance merrily at some place of public resort as the fellows of his calling continued to do throughout the greater part of europe shuts himself up at home to drink']
audio10.flac音頻:00:00/00:27
audio10.flac識別結果:

Predicting...Audio file 1/1['she opened the door softly there sat missus wilson in the old rocking chair with one sick death like boy lying on her knee crying without let or pause but softly gently as fearing to disturb the troubled gasping child while behind her old alice let her fast dropping tears fall down on the dead body of the other twin which she was laying out on a board placed on a sort of sofa settee in the corner of the room']
上面兩段音頻識別結果都還不錯,注意此模型不支持中文識別,換兩段英文音頻試試:
第一段音頻:https://www.tingclass.net/show-5406-3632-1.html
python speech_recognition.py --input_audio=./audio/CET4.wav
識別結果:
Predicting...Audio file 1/1['o hom m bell amo hn haha am o waa iha me howa e al ru e hi hera morbo ao ha yur you move fore hung mo by wholl hab your hu mo ah miseur luuel u lonlur wole olla iwer home all bou o how bu olur aa men he ul um aha ol a oh a he notn ol all hole ar rule sa mer peaile hall her orha ah be a hen hom all murn a bown lok ano gerl orhehan or holy mule i ea the lol and theyn whole mon wingle all form ']
呃呃,和實際結果差別很大,結果中的單詞也很多看不懂,
換另一段音頻:https://m.kekenet.com/Article/201504/369129.shtml

python speech_recognition.py --input_audio=./audio/english.wav
識別結果:
Predicting...Audio file 1/1[" shakish am am shut shash an shi hang ca iunkun usha y oru u warm room wo o emon o chjonnoe e ah wo an o a hush e i've o ask rule ur o sqawe grewh ula u ho a o ah"]
這一段音頻識別結果還是很差,
初步分析應該是模型訓練時的音頻跟我們測驗的音頻差異較大,要想得到好的識別結果,還得自己訓練,例程代碼speech_recognition.py中還包含預訓練模型下載地址,大家有興趣可以自己嘗試,相關內容如有新的動態再分享給大家!
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/384427.html
標籤:其他
上一篇:Python對影像分割
下一篇:matlab實作影像邊緣檢測