Denoising Implicit Feedback for Recommendation
Authors: 王文杰,馮福利,何向南,聶禮強,蔡達成
WSDM‘21 新加坡國立大學,中國科學技術大學,山東大學
論文鏈接:http://staff.ustc.edu.cn/~hexn/papers/WSDM_2021_ADT.pdf,https://arxiv.org/pdf/2006.04153.pdf
本文鏈接:https://www.cnblogs.com/zihaojun/p/15704005.html
目錄
- Denoising Implicit Feedback for Recommendation
- 0. 總結
- 1.問題背景
- 2.研究目標
- 3. “偽正樣本”研究
- 4. 方法
- 4.1 Obervations 觀察
- 4.2 Adaptive Denoising Training(ADT) 適應性去噪訓練
- 4.2.1 截斷交叉熵損失 Truncated Cross-Entropy Loss(T-CE)
- 4.2.2 加權交叉熵損失函式 Reweighted Cross-Entropy Loss(R-CE)
- 5. 實驗
- 5.1 資料集
- 5.2 實驗結果
- 5.3 深入分析
- 5.3.1 “偽正樣本”的Loss情況
- 5.3.2 T-CE的性能研究
- Weakness
- 進一步閱讀
0. 總結
本文主要研究并解決推薦系統的隱式反饋資料中正樣本存在噪聲,會損害推薦系統性能的問題,
“偽正樣本”在推薦系統訓練的初始階段Loss普遍較高,利用這個規律,可以對“偽正樣本”和真正的正樣本進行區分,
本文提出了適應性去噪訓練(Adaptive Denoising Training,ADT)策略來解決上述問題,提出了截斷損失函式和加權損失函式兩種Loss函式,并基于交叉熵損失,在三個資料集上,基于三種推薦模型進行了實驗,實驗結果表明,ADT可以有效去除“偽正樣本”對模型性能的干擾,
1.問題背景
由于隱式反饋資料量比較大,容易獲得,因此隱式反饋資料已經是在線推薦系統的默認訓練資料,
但是隱式反饋資料是存在噪聲的,隱式反饋的正樣本只能反映用戶和物品之間存在互動,但是不能反映用戶對此次互動的滿意度,例如在電商中,用戶可能點擊了一個物品,但是并沒有購買;即使用戶購買了,對這個物品可能也是不滿意的,
在推薦系統訓練程序中,噪聲資料可能會損害推薦系統的性能,使得推薦系統捕捉用戶興趣的能力下降,
2.研究目標
在沒有用戶停留時間、物品特征、用戶反饋等額外資訊的情況下(這些資訊很稀疏,難以獲得),識別并去除互動資料中的“偽正樣本”,提高推薦系統訓練的效率和推薦系統的精度,
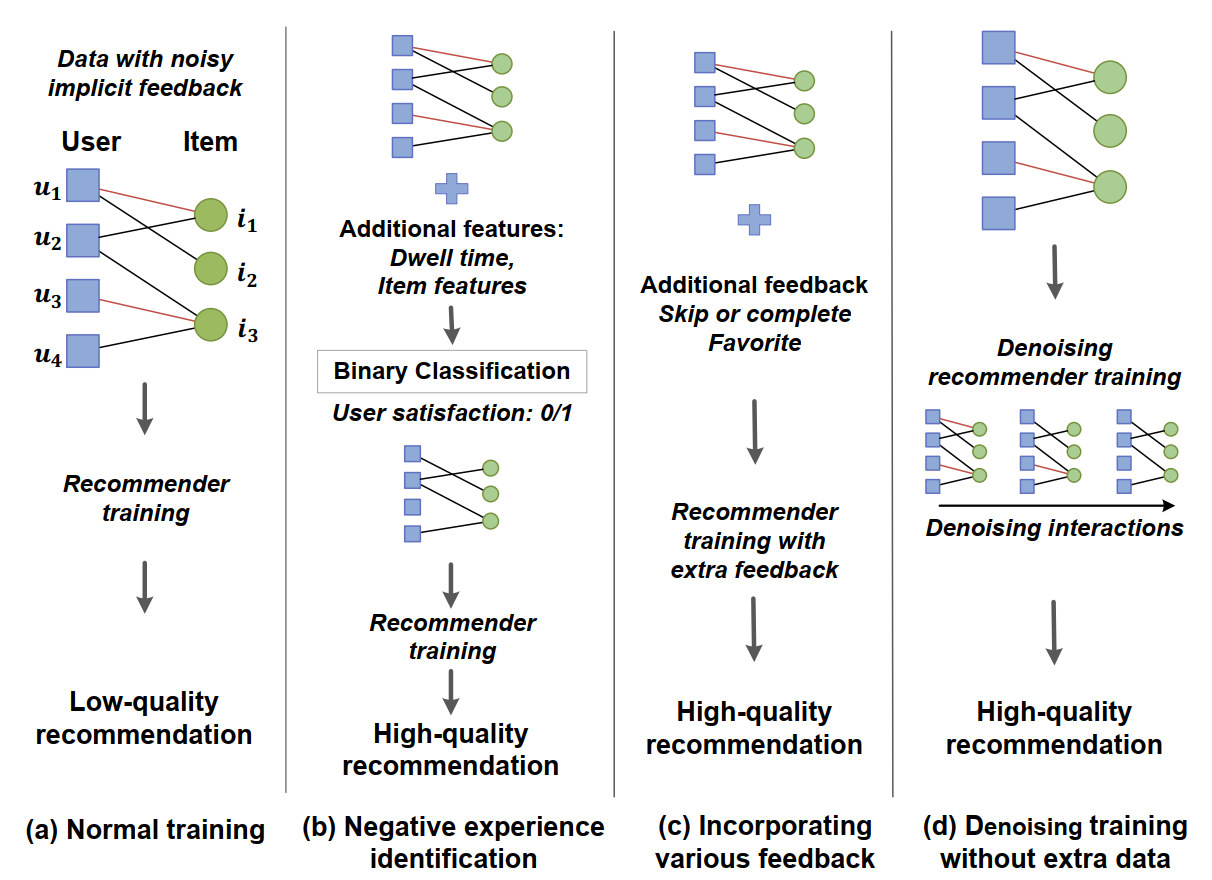
如下圖,圖中紅色的互動代表“偽正樣本”,黑色的互動代表“真正樣本”,
-
第一串列示通常的推薦模型,會受到“偽正樣本”的干擾,推薦質量差,
-
第二列和第三串列示利用額外資訊來識別“偽正樣本”,從而提高推薦質量,
-
最后一列表示本文提出的框架,在不利用額外資訊的條件下,去除“偽正樣本”的影響,生成高質量的推薦結果,
3. “偽正樣本”研究
為了驗證“偽正樣本”對推薦性能的影響,基于NeuMF模型,設計如下實驗:
- 訓練階段
- 使用所有互動資料(1-5分)的設定稱為Normal training
- 只使用3-5分的互動資料(去除“偽正樣本”)的設定成為Clean training
- 驗證階段
- 驗證集和測驗集同樣去除1-2分的互動資料,只保留3-5分的互動資料
實驗結果表明,Clean training明顯優于Normal training,說明“偽正樣本”確實會損害推薦系統的性能,
\[\begin{array}{l|cc|cc} \hline \text { Dataset } & {\text { Adressa }} && {\text { Amazon-book }} \\ \text { Metric } & \text { Recall@20 } & \text { NDCG@20 } & \text { Recall@20 } & \text { NDCG@20 } \\ \hline \hline \text { Clean training } & 0.4040 & 0.1963 & 0.0293 & 0.0159 \\ \text { Normal training } & 0.3081 & 0.1732 & 0.0265 & 0.0145 \\ \hline \text { \#Drop } & 23.74 \% & 11.77 \% & 9.56 \% & 8.81 \% \\ \hline \end{array} \]4. 方法
4.1 Obervations 觀察
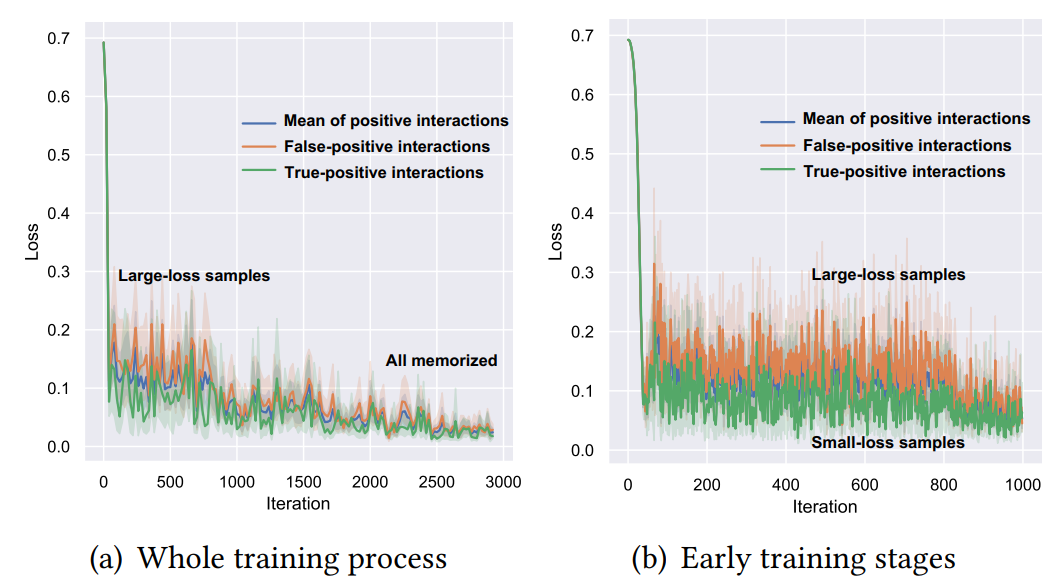
在Adressa資料集上,使用所有互動資料(1-5分)訓練NeuMF,分別觀察True-positive Interactions和False-positive Interactions的平均loss值,
從下圖所示的實驗結果中可以看出:
- 在左圖所示的完整訓練程序中,所有樣本的loss最終都收斂到很小的值,說明所有的樣本都被模型記住了,
- 在右圖表示的訓練初始階段(0-1000 Iteraions),False-positive樣本的loss值(橙色)明顯高于True-positive的loss值(綠色),這說明在False-positive樣本的訓練難度明顯更高,
這個規律可以用來區分“偽正樣本”和“真正樣本”,
4.2 Adaptive Denoising Training(ADT) 適應性去噪訓練
基于上節中的觀察,本文提出ADT模型,根據loss函式來區分“真正樣本”和“偽正樣本”,
ADT有兩種思路:
- 截斷loss(Truncated Loss):基于一個動態調整的閾值,將loss比較高的樣本loss直接置0,使得這些樣本在當前訓練輪不參與模型更新,
- 加權loss(Reweighted Loss):給難樣本(Loss大的樣本)更低的權重,
這兩種方法與Loss函式的設計無關,可以被應用到BCE和BPR等多種loss函式上,本文基于BCEloss進行實驗,
4.2.1 截斷交叉熵損失 Truncated Cross-Entropy Loss(T-CE)
\[\begin{align} \mathcal{L}_{T-C E}(u, i)= \begin{cases}0, & \mathcal{L}_{C E}(u, i)>\tau \wedge \bar{y}_{u i}=1 \\ \mathcal{L}_{C E}(u, i), & \text { otherwise }\end{cases} \\ \\ \mathcal{L}_{C E}\left(\mathcal{D}^{*}\right)=-\sum_{\left(u, i, y_{u i}^{*}\right) \in \mathcal{D}^{*}} y_{u i}^{*} \log \left(\hat{y}_{u i}\right)+\left(1-y_{u i}^{*}\right) \log \left(1-\hat{y}_{u i}\right) \end{align} \]T-CE Loss將Loss值大于\(\tau\)的正樣本損失函式置0,其中\(\tau\)是預定義的值,可以隨著訓練輪數變化而變化,
為了建模\(\tau\),定義樣本淘汰率(drop rate),也就是在第T輪訓練中,淘汰loss最高的比例為\(\epsilon(T)\)的樣本:
\[\begin{align} \epsilon(T)=\min \left(\alpha T, \epsilon_{\max }\right) \end{align} \]其中\(\alpha\)和\(\epsilon_{max}\)是超引數,
這樣的設計可以保證:
- 樣本淘汰率有上限,避免將樣本全部舍棄,
- 訓練開始時,使用全部樣本
- 樣本淘汰率從0逐漸增加到上限,使模型逐漸能分清真正樣本和假正樣本,
4.2.2 加權交叉熵損失函式 Reweighted Cross-Entropy Loss(R-CE)
\[\begin{align} \mathcal{L}_{R-C E}(u, i)=\omega(u, i) \mathcal{L}_{C E}(u, i) \end{align} \]其中\(\omega(u, i)\)是調整不同樣本損失在總損失函式中占比的權重,
\(\omega(u, i)\)應該有以下性質:
- 在訓練程序中動態變化
- 使得Loss高的正樣本權重更低
- 權重可以通過超參調整,以適用于不同模型和資料集
輸出預測值\(\hat{y}_{u i}\)與Loss函式是一一對應的,\(\hat{y}_{u i}\)越低,對應的Loss就越高,則權重應該越低;可以利用\(\hat{y}_{u i}\)來定義\(\omega(u, i)\):
\[\begin{align} \omega(u, i) = f({\hat{y}_{ui}}) = \hat{y}_{u i}^{\beta} \end{align} \]其中\(\beta\in[0,+\infin]\)是超引數,\(\hat{y}_{ui}\)表示預測值,\(\bar{y}_{ui}\)表示標簽值,
Figure 5(a)展示\(\beta\)取不同的值時,Loss函式與預測值\(\hat{y}_{ui}\)的關系,即\(\beta\)越大,難樣本(\(\hat{y}_{ui}\)較小)的Loss被壓縮的效果越明顯;當\(\beta = 0\)時,R-CE退化到普通的CE,
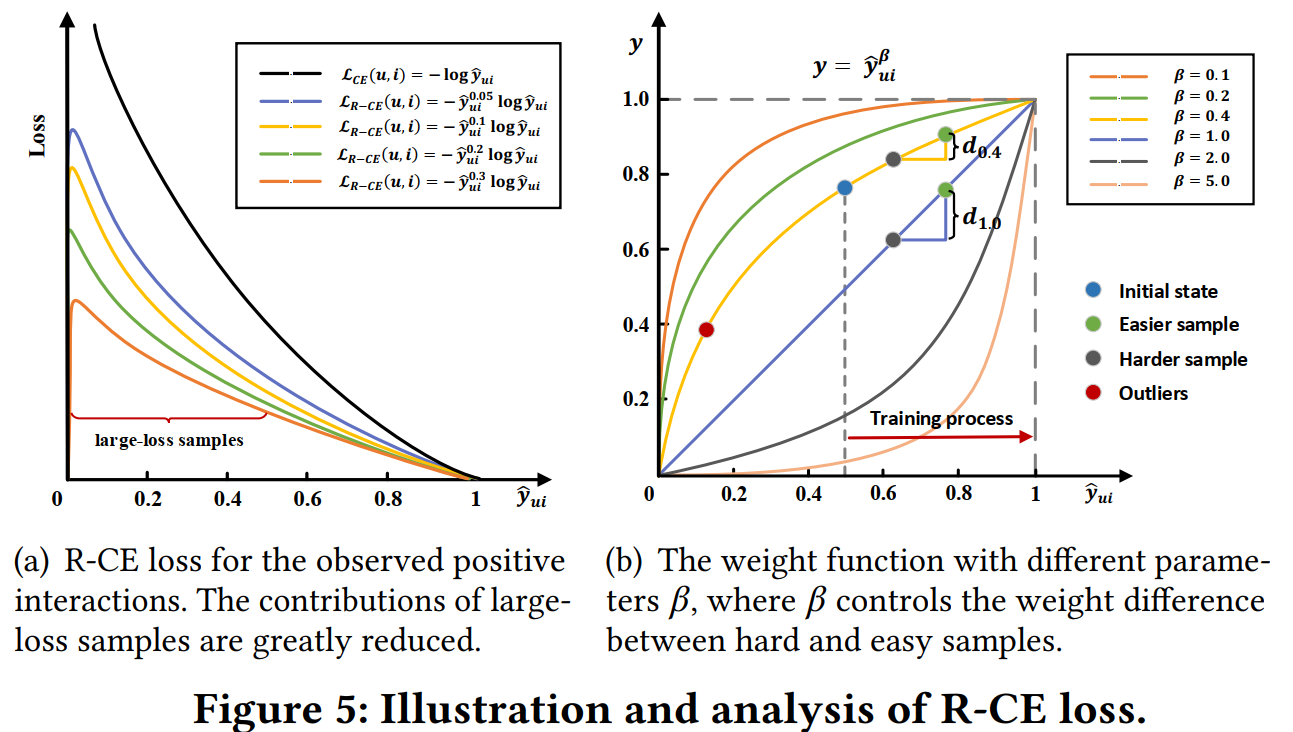
為了保證正負樣本Loss值的一致性,給負樣本也做了同樣的處理:
\[\begin{align} \omega(u, i)= \begin{cases}\hat{y}_{u i}^{\beta}, & \bar{y}_{u i}=1 \\ \left(1-\hat{y}_{u i}\right)^{\beta}, & \text { otherwise }\end{cases} \end{align} \]5. 實驗
5.1 資料集
- Adressa:新聞閱讀資料集,包含用戶的點擊資料和在頁面的停留時間;停留少于10s的點擊視為“偽正樣本”
- Amazon-book:亞馬遜評論資料集,包含用戶對物品的評分資料;評分低于3分的互動視為“偽正樣本”
- Yelp:餐廳評分資料集;評分低于3分的互動視為“偽正樣本”
訓練集和驗證集包含所有互動,測驗集只包含“真正樣本”,
5.2 實驗結果
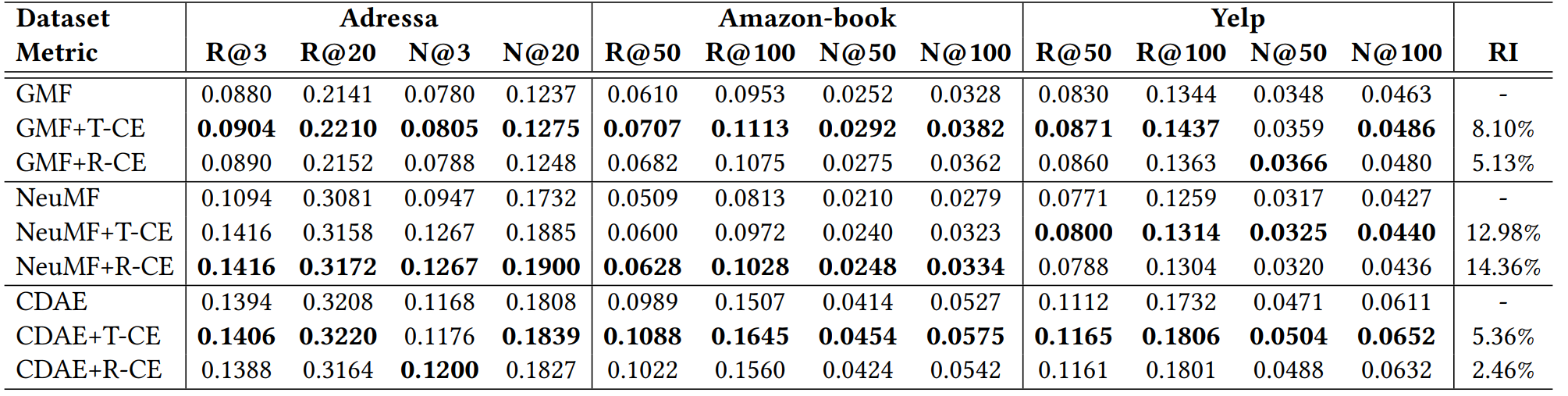
- 在三種推薦模型上,T-CE和R-CE Loss都提升了推薦性能,證明了方法的有效性
- 比較T-CE和R-CE兩種方法,T-CE的性能一般會更好,這是因為T-CE直接去除了難樣本的影響,并多了一個超引數,
- NeuMF的性能比GMF還低,這是因為訓練資料中有“偽正樣本”,NeuMF的擬合能力更強,學到了這些噪聲資訊,
- T-CE和R-CE都在NeuMF上取得了最大的性能提升,這與上一條結論一致——NMF受到“偽正樣本”的影響更大,T-CE和R-CE在CDAE上面仍然有性能提升,證明了本文的方法的合理性,
為了驗證本文的方法是否會損害不活躍用戶的推薦精度,本文將用戶按照互動數量分為四組,實驗結果表明,即便是互動數量很少的用戶組,推薦精度也得到了提升,
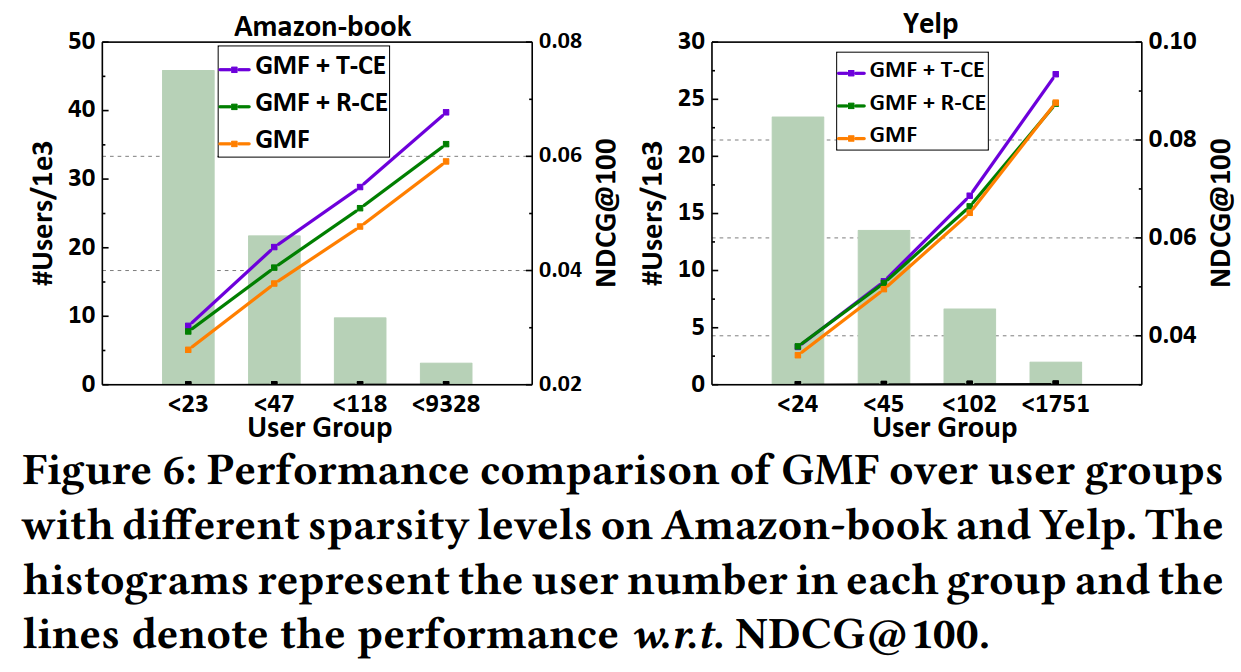
5.3 深入分析
5.3.1 “偽正樣本”的Loss情況
第三部分已經分析過,“偽正樣本”被模型記住之后,會使得模型性能降低,
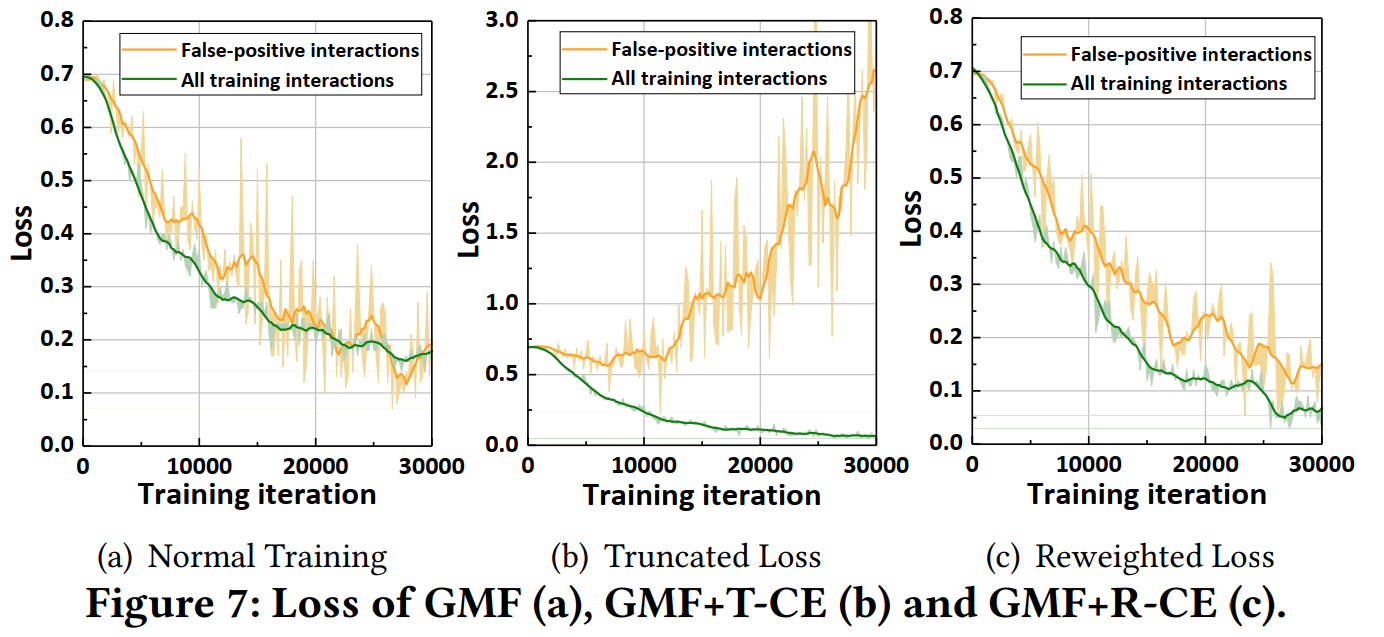
本文用實驗驗證,提出的方法能否使得“偽正樣本”不被模型記住,也就是“偽正樣本”Loss是否能更高,
- 如Figure 7(a)所示,正常訓練時,“偽正樣本”的Loss會學到跟其他正樣本一個水平
- 而使用T-CE時,“偽正樣本”的Loss隨著訓練,先幾乎不變,后迅速升高,說明模型準確識別到了這些“偽正樣本”,并把他們從訓練的正樣本集排除出去,
- 而使用R-CE時,“偽正樣本”的Loss隨著訓練程序仍然是下降的,但還是比其他樣本高一些,
這一部分驗證的是文章的核心論點,也是本文提出的模型起作用的核心機制——通過Loss函式識別并排除“偽正樣本”的影響,
5.3.2 T-CE的性能研究
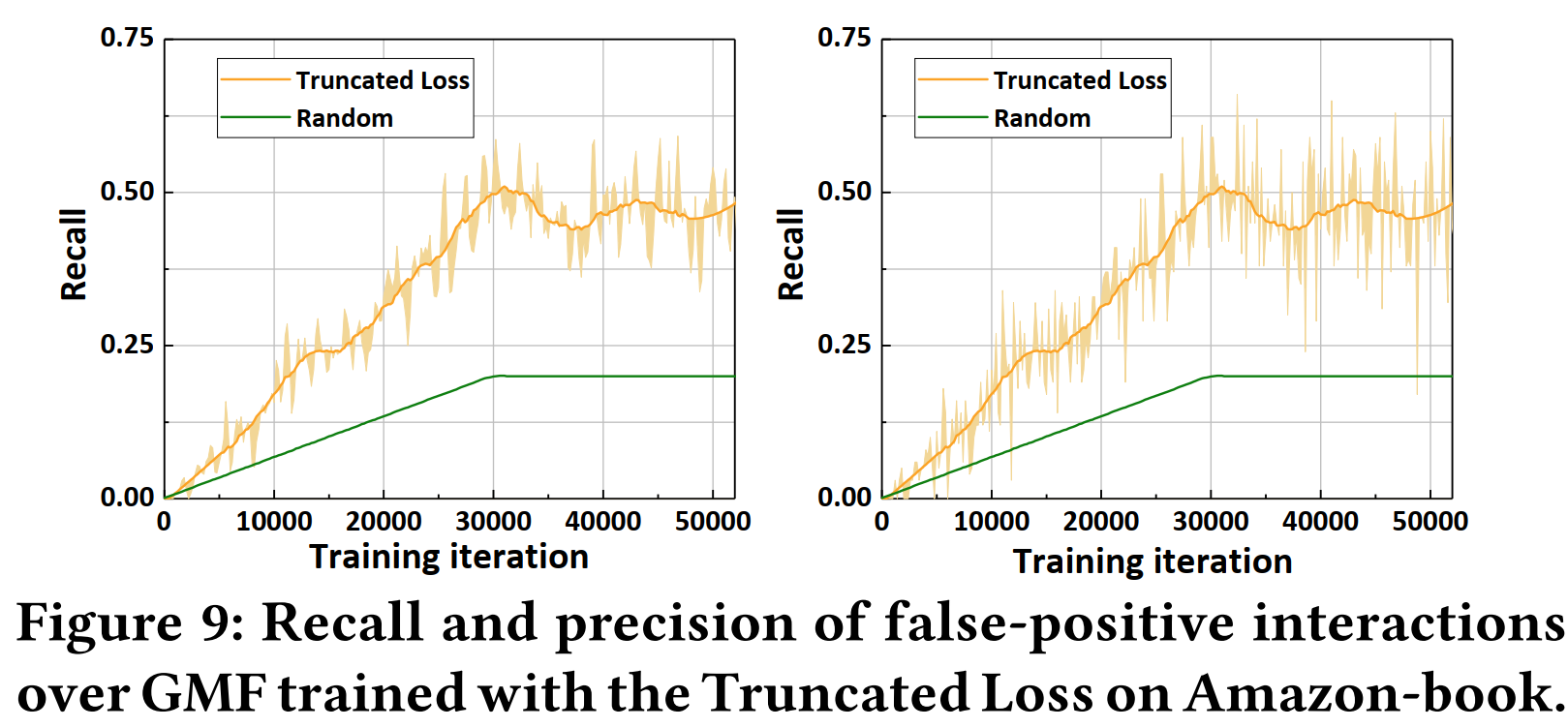
由于截斷交叉熵損失函式(T-CE)使得“偽正樣本”的Loss函式很高,作者又從T-CE過濾掉的互動與真正的“偽正樣本”之間的召回率和準確率的角度來研究T-CE,
實驗表明,T-CE選取“偽正樣本”的準確率大約是隨機選取的兩倍,但準確率(precision)仍然只有10%左右,
- 一方面,這說明,為了過濾掉“偽正樣本”,拋棄一些真正樣本是值得的
- 但另一方面,這也說明本文章提出的方法準確率仍然很低
Weakness
- R-CE中給負樣本也加了權重,而T-CE中沒有對負樣本做處理,實驗中也沒有對此做出說明,
- 識別“偽正樣本”的準確率只有10%,
進一步閱讀
[5] Yihong Chen, Bei Chen, Xiangnan He, Chen Gao, Yong Li, Jian-Guang Lou, and Yue Wang. 2019. lambdaOpt: Learn to Regularize Recommender Models in Finer Levels. In Proceedings of the 25th SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 978–986.
[6] Jingtao Ding, Guanghui Yu, Xiangnan He, Fuli Feng, Yong Li, and Depeng Jin. 2019. Sampler design for bayesian personalized ranking by leveraging view data. Transactions on Knowledge and Data Engineering (2019).
[16] Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web. IW3C2, 173–182.
[18] Y. Hu, Y. Koren, and C. Volinsky. 2008. Collaborative Filtering for Implicit Feedback Datasets. In Proceedings of the 8th International Conference on Data Mining. TEEE, 263–272.
[19] Rolf Jagerman, Harrie Oosterhuis, and Maarten de Rijke. 2019. To Model or to Intervene: A Comparison of Counterfactual and Online Learning to Rank from User Interactions. In Proceedings of the 42nd International SIGIR Conference on Research and Development in Information Retrieval. ACM, 15–24.
[39] Hongyi Wen, Longqi Yang, and Deborah Estrin. 2019. Leveraging Post-click Feedback for Content Recommendations. In Proceedings of the 13th Conference on Recommender Systems. ACM, 278–286.
[40] Yao Wu, Christopher DuBois, Alice X Zheng, and Martin Ester. 2016. Collaborative denoising auto-encoders for top-n Recommender Systems. In Proceedings of the 9th International Conference on Web Search and Data Mining. ACM, 153–162.
[41] Byoungju Yang, Sangkeun Lee, Sungchan Park, and Sang goo Lee. 2012. Exploiting Various Implicit Feedback for Collaborative Filtering. In Proceedings of the 21st International Conference on World Wide Web. IW3C2, 639–640.
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385282.html
標籤:其他