MoCo 論文逐段精讀【論文精讀】
這次論文精讀李沐博士繼續邀請了亞馬遜計算機視覺專家朱毅博士來精讀 Momentum Contrast(MoCo),強烈推薦大家去看本次的論文精讀視頻,朱毅博士和上次一樣講解地非常詳細,幾乎是逐詞逐句地講解,在講解時把 MoCo 相關領域的研究也都介紹了,聽完之后識訓滿滿,
MoCo 獲得了 CVPR2020 最佳論文提名,是視覺領域使用對比學習的一個里程碑作業,對比學習目前也是機器學習領域最炙手可熱的一個研究方向,由于其簡單、有用、強大,以一己之力盤活了從2017年開始就卷的非常厲害的計算機視覺領域,MoCo 是一個無監督表征學習的作業,其不僅在分類任務,在檢測、分割和人體關鍵點檢測任務上都逼近或超越了有監督學習模型;MoCo 的出現證明我們可能并不需要大量標注好的資料去預訓練,下圖中 Yann LeCun 將機器學習比作一塊蛋糕,強化學習是蛋糕上的櫻桃、有監督學習是蛋糕上的奶油、無監督學習才是那塊大蛋糕,才是問題的本質,目前很多的大模型都是通過自監督學習得到的,

MoCo 論文鏈接:https://arxiv.org/abs/1911.05722
0. 對比學習介紹
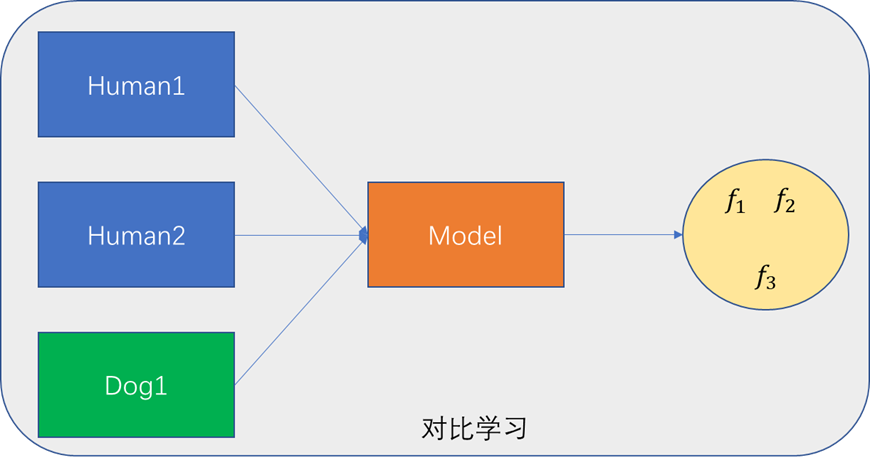
在開始精讀論文之前,朱毅博士首先介紹了什么是對比學習,如下圖所示,有三張圖片,圖1、2為同一個人不同的表情,圖3為dog,在訓練時不會為這三種圖片去標注,將三種圖片輸入到模型中,模型會得到三張圖片各自特征,由于圖1、2為同一個人、對比學習就是讓特征
f
1
、
f
2
f_1、f_2
f1?、f2? 比較接近,而特征
f
3
f_3
f3? 與另外兩個特征在特征空間相距較遠,這就是對比學習需要達到的目的,
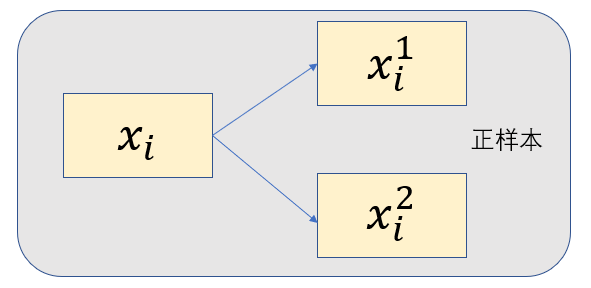
雖然在對比學習中并不需要為圖片進行標注,但是仍然需要知道哪些圖片是相似的,哪些圖片是不相似的,在計算機視覺中通常使用代理任務來完成,舉一個具體的例子 instance discrimination,假設有
n
n
n 張圖片,選取一張圖片
x
i
x_i
xi? ,經過裁剪和資料增強后得到兩張新的圖片
x
i
1
x_i^1
xi1? 和
x
i
2
x_i^2
xi2?,則這兩張圖片和原來的圖片就是相似的,也被稱為正樣本,其余圖片即
j
≠
i
j \neq i
j?=i,則為負樣本,對比學習的靈活之處就在于正負樣本的劃分,例如同一張圖片不同視角可看作為正樣本,視頻中同一段視頻任意兩幀可以看為正樣本,RGB和深度圖也可看作為正樣本等等,正是由于其靈活性,對比學習的應用才如此之廣,
1. 標題、摘要、引言、結論
先是論文標題,論文標題的意思是:使用動量對比去做無監督視覺表征學習,MoCo 就來自于論文前兩個單詞前兩個字幕,簡單介紹什么是動量,動量在數學上就是加權移動平均,例如
y
t
=
m
×
y
t
?
1
+
(
1
?
m
)
×
x
t
y_t=m \times y_{t-1}+(1-m) \times x_t
yt?=m×yt?1?+(1?m)×xt?,
y
t
?
1
y_{t-1}
yt?1? 為上一時刻的輸出,
x
t
x_t
xt? 為當前輸入,
m
m
m 為動量引數;當
m
m
m 很大時,
y
t
y_t
yt? 就取決于上一時刻輸出,其更新就很緩慢;當
m
m
m 很小時,
y
t
y_t
yt? 就取決于當前時刻輸入,
作者團隊來自于 FAIR,就不過多介紹了,五個人谷歌學術參考數達到了50萬+,

下面是論文摘要,摘要寫的很簡潔,總共只有7句話,
- 第1句話直接介紹主題,我們提出了
MoCo用于無監督視覺表征學習,第2句話意思是我們把對比學習看作是字典查詢,我們建立了一個動態字典,使用到了對列和移動平均編碼器, - 第3句話意思是使用佇列和移動平均編碼器,我們可以建立一個很大且一致的字典,有助于對比無監督學習,
- 第4-6句話是模型效果,
MoCo在ImageNet分類上取得了很有競爭力的結果,其中linear protocol的意思是說將主干網凍結,只訓練分類頭,更重要的,將 MoCo 學到的特征遷移到下流任務時,在7個檢測和分割任務上,MoCo都超過它的有監督預訓練對手,counterpart的意思是有監督和無監督訓練都使用同一個網路,例如ResNet-50, - 最后一句話的意思是,在許多視覺任務上,無監督和有監督特征學習之間的鴻溝被大幅度的填上了,

下面是論文引言部分,
2. 相關作業
3. Moco模型、實驗
轉載請註明出處,本文鏈接:https://www.uj5u.com/qita/385437.html
標籤:其他